AIF-SFDA: Autonomous Information Filter-driven Source-Free Domain Adaptation for Medical Image Segme
基于深度学习(DL)的医学图像分割方法虽有显著进步,但实际场景中测试数据(目标域)与训练数据(源域)常存在,源于设备、患者人群、图像质量等差异,会严重降低模型在目标域的性能。
一、研究背景与待解决问题
-
医学图像分割的域偏移挑战
基于深度学习(DL)的医学图像分割方法虽有显著进步,但实际场景中测试数据(目标域)与训练数据(源域)常存在域偏移,源于设备、患者人群、图像质量等差异,会严重降低模型在目标域的性能。 -
现有域适应方法的局限性
- 无监督域适应(UDA):需同时使用有标签源数据与无标签目标数据,通过解耦域变异信息(DVI)和域不变信息(DII)实现泛化,但医疗场景中数据隐私、收集难度等问题限制了源数据访问,难以应用。
- 无源源域适应(SFDA):仅用无标签目标数据适配预训练源模型,是医疗场景的理想方案,但面临三大挑战:① 缺乏源数据指导,DVI/DII解耦困难;② 仅靠无标签目标数据,DII保留难度大;③ 现有频率基方法依赖经验性滤波器配置,不适用于SFDA。
二、AIF-SFDA算法设计
(一)算法核心目标
通过基于频率的可学习信息过滤器,结合信息瓶颈(IB)和自监督(SS),仅依赖无标签目标数据,自主解耦DVI与DII,实现医学图像分割的SFDA。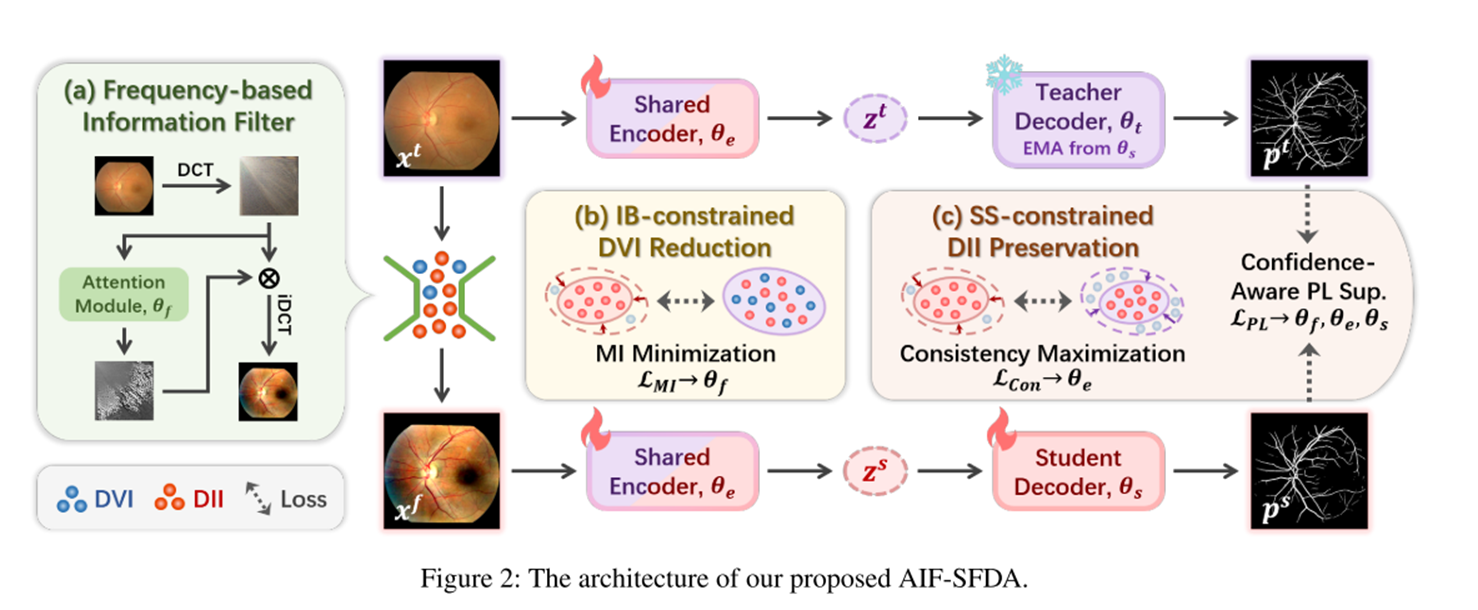
(二)关键组件与原理
-
频率基信息过滤器
-
基于二维离散余弦变换(DCT)将目标图像转换至频率域,公式为:

-
引入注意力模块生成注意力图,通过哈达玛积(⊙)与逆DCT变换,得到过滤后图像x^f,公式为:
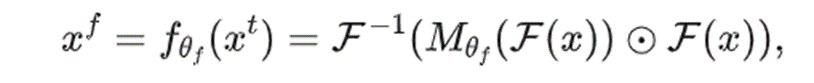
-
特性:具备可学习参数,能根据输入图像自适应选择/移除信息。
-
-
IB约束的DVI减少
- 核心思想:将过滤后图像视为中间变量,通过最小化输入与中间变量的互信息(MI),减少冗余DVI。
- 实现方式:因直接计算图像MI复杂度高,转而约束共享编码器输出特征与特征的MI,通过变分分布近似真实分布,优化损失和负对数似然损失。
-
SS约束的DII保留
- 置信度伪标签(PL)监督:采用师生架构,教师解码器生成伪标签及置信度,通过置信度阈值(\tau=0.8)过滤低置信度伪标签,计算交叉熵损失
- 特征一致性约束:用余弦相似度最小化的距离,确保DII保留
(三)优化流程(Algorithm 1)

三、实验设计与结果
(一)实验设置
-
数据集
任务 数据集(源域标记*) 样本量 数据类型 视网膜血管分割 DRIVE*、AVRDB、CHASEDB1、DRHAGIS、LES-AV、STARE 40、100、28、40、22、20 眼底图像(公开) 关节软骨分割 A*、B、C 956、982、750 超声图像(私有) - 所有数据集按1:1随机划分为训练集与测试集。
-
评价指标
- Dice相似系数(DSC):衡量分割重叠度,越高越好。
- 交并比(IoU):衡量分割准确性,越高越好。
-
基线算法与实现细节
- 基线算法(共9种):
类型 算法名称 普通分割 Rolling-Unet(Liu et al. 2024)、DTMFormer(Wang et al. 2024) UDA CS-CADA(Gu et al. 2022)、DAMAN(Mukherjee et al. 2022)、MAAL(Zhou et al. 2023) SFDA SFODA(Niloy et al. 2024)、UPL-SFDA(Wu et al. 2023)、UBNA(Klingner et al. 2022)、TSFCT(Li et al. 2023b) - 实现细节:采用Adam优化器(初始学习率0.001),批大小2;分割模型为U-net(Ronneberger et al. 2015);过滤器注意力模块为3层轻量级U-net;变分分布为多元高斯分布(参数由2层MLP生成,隐藏层大小1024)。
- 基线算法(共9种):
(二)实验结果
-
视网膜血管分割结果
算法 SF标记* AVRDB(DSC/IoU) CHASEDB1(DSC/IoU) DRHAGIS(DSC/IoU) LES-AV(DSC/IoU) STARE(DSC/IoU) Source / 54.34/39.47 52.36/37.87 54.65/39.48 58.12/42.18 58.53/42.69 CS-CADA(UDA) ✗ 65.16/48.58 64.15/47.48 69.94/55.56 75.22/60.48 74.71/60.26 SFODA(SFDA) ✓ 64.69/48.79 63.88/46.87 66.25/51.03 76.83/62.69 74.69/61.65 AIF-SFDA(SFDA) ✓ 66.22/49.85 64.44/47.49 69.99/55.16 78.08/63.15 76.68/63.01 - 结论:AIF-SFDA在所有目标数据集上DSC和IoU均最优,优于普通分割、UDA和其他SFDA算法;TSFCT出现负适应,证明SFDA难度。
-
关节软骨分割结果
算法 B(DSC/IoU) C(DSC/IoU) Source 63.43/57.98 51.57/52.20 SFODA 66.69/60.11 55.14/55.21 TSFCT 67.03/57.13 51.02/47.27 AIF-SFDA 69.14/62.07 55.16/55.70 - 结论:AIF-SFDA在B、C数据集上指标最优;C数据集与源域差异更大,UPL-SFDA、TSFCT出现负适应,而AIF-SFDA因融合PL与特征约束,泛化性更强。
-
消融实验(AVRDB数据集)
验证IB(MI Min.)、PL(PL Sel.)、Cons.(Cons.)模块的作用:MI Min. PL Sel. Cons. DSC IoU - - - 58.62 42.79 ✓ - - 62.34 46.22 ✓ - ✓ 65.25 49.08 ✓ ✓ - 63.22 46.88 ✓ ✓ ✓ 66.22 49.85 - 结论:三个模块均能提升性能,且三者结合时效果最佳,证明各模块设计合理。
-
自适应vs固定过滤器对比
- 固定过滤器:采用阈值0.01-0.1的高通滤波器,无MI损失优化。
- 结果:AIF-SFDA的自适应过滤器能提升血管像素边缘梯度,减少伪影,DSC高于所有固定阈值过滤器,证明自适应过滤对域解耦的重要性。
四、研究贡献与结论
-
核心贡献
- 提出AIF-SFDA算法,首次将可学习频率过滤器用于医学图像分割SFDA,实现DVI/DII自适应解耦。
- 构建仅依赖目标数据的自主信息过滤器,通过IB约束减少DVI,SS约束保留DII,无需源数据指导。
- 在跨模态(眼底、超声)、多任务实验中验证算法有效性,优于现有SOTA方法。
-
结论
AIF-SFDA通过频率基自主信息过滤机制,有效解决了SFDA场景下医学图像分割的域偏移问题,为医疗隐私场景下的模型泛化提供了可行方案。
4. 关键问题
问题1:AIF-SFDA算法如何在无源源域适应(SFDA)场景下实现域变异信息(DVI)与域不变信息(DII)的自主解耦?其核心技术路径是什么?
答案
AIF-SFDA通过“频率基信息过滤器+双约束机制”实现自主解耦,核心技术路径如下:
- 频率基可学习信息过滤器:以二维DCT变换为基础,将目标图像转换至频率域,结合注意力模块生成自适应注意力图,通过哈达玛积与逆DCT变换,得到过滤后图像,过滤器参数可学习,能根据输入图像特性调整信息选择/移除策略;
- IB约束的DVI减少:将过滤后图像视为中间变量,通过最小化输入目标图像与过滤后图像的特征互信息(MI),减少冗余DVI——因直接计算图像MI复杂度高,转而约束共享编码器输出的特征互信息,用变分分布近似真实分布,优化MI损失(\mathcal{L}{MI})和负对数似然损失(\mathcal{L}{Li});
- SS约束的DII保留:采用师生架构生成置信度伪标签(阈值(\tau=0.8)过滤低置信度标签),通过交叉熵损失(\mathcal{L}{PL})引导过滤器学习任务相关DII;同时用余弦相似度约束输入图像与过滤后图像的特征距离,通过(\mathcal{L}{Con})确保DII不丢失;
- 优化闭环:仅依赖无标签目标数据,迭代优化过滤器参数与模型参数,用EMA更新教师模型,实现无需源数据的自主域解耦。
问题2:在医学图像分割任务中,AIF-SFDA与现有先进算法(如SFODA、CS-CADA等)相比,核心优势体现在哪些方面?实验数据如何支撑这些优势?
答案
AIF-SFDA的核心优势体现在泛化性更强、适配场景更广、依赖数据更少,实验数据支撑如下:
- 泛化性更强:在跨域场景下,AIF-SFDA在DSC、IoU指标上全面优于普通分割、UDA、其他SFDA算法
- 视网膜血管分割(AVRDB数据集):AIF-SFDA的DSC=66.22%、IoU=49.85%,高于SFODA(DSC=64.69%、IoU=48.79%)和UDA算法CS-CADA(DSC=65.16%、IoU=48.58%);
- 关节软骨分割(B数据集):AIF-SFDA的DSC=69.14%、IoU=62.07%,高于SFODA(DSC=66.69%、IoU=60.11%)和TSFCT(DSC=67.03%、IoU=57.13%)。
- 适配场景更广:能应对目标域与源域差异更大的场景,避免负适应
- 关节软骨分割(C数据集,与源域差异大于B):UPL-SFDA(DSC=49.75%)、TSFCT(DSC=51.02%)出现负适应(低于源模型的51.57%),而AIF-SFDA的DSC=55.16%,仍保持正向提升;
- 依赖数据更少:无需源数据,且无需经验性参数配置
- 对比固定频率过滤器(依赖人工设定阈值0.01-0.1):AIF-SFDA的自适应过滤器无需人工调参,且DSC高于所有固定阈值过滤器,同时能减少伪影、提升边缘梯度,证明其数据依赖性更低、鲁棒性更强。
问题3:AIF-SFDA中的自监督(SS)约束包含置信度伪标签监督(PL)和特征一致性约束(Cons.),这两个子约束分别解决了SFDA场景下的什么问题?消融实验如何验证它们的必要性?
答案
(1)两个子约束解决的问题
- 置信度伪标签监督(PL):解决SFDA场景下“无标签指导导致DII学习缺乏任务相关性”的问题
- SFDA仅有无标签目标数据,模型难以判断哪些信息与分割任务相关(即DII);PL通过师生架构生成伪标签,并基于置信度阈值((\tau=0.8))过滤低置信度标签,避免错误标签干扰,引导过滤器优先保留与任务相关的DII(如视网膜血管、软骨区域特征),同时帮助分割模型适配过滤后图像。
- 特征一致性约束(Cons.):解决SFDA场景下“IB约束仅减少DVI,可能误删DII”的问题
- IB约束通过最小化互信息减少DVI,但可能过度过滤导致DII丢失;Cons.通过余弦相似度最小化输入图像与过滤后图像的特征距离,确保两者包含相同的任务相关语义信息,在减少DVI的同时,强制保留DII,避免模型因信息过度丢失导致性能下降。
(2)消融实验验证(AVRDB数据集)
消融实验通过逐步添加三个关键模块(IB的MI Min.、SS的PL Sel.、SS的Cons.),观察指标变化,验证PL和Cons.的必要性:
| 模块组合 | DSC | IoU | 关键结论 |
|---|---|---|---|
| 仅MI Min.(无PL、无Cons.) | 62.34 | 46.22 | 仅IB能提升性能,但缺乏DII保留机制,指标较低 |
| MI Min. + Cons.(无PL) | 65.25 | 49.08 | 加入Cons.后,DII保留更充分,DSC提升2.91个百分点,证明Cons.能弥补IB的DII丢失问题 |
| MI Min. + PL(无Cons.) | 63.22 | 46.88 | 加入PL后,DSC提升0.88个百分点,证明PL能提供任务相关指导,帮助过滤器定位DII |
| MI Min. + PL + Cons.(完整模型) | 66.22 | 49.85 | 两者结合时指标最优,DSC较“仅MI Min.”提升3.88个百分点,证明PL和Cons.相辅相成,均为必要模块 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)