Meta-Chunking (2024.8.16) Late Chunking(jina 2024.8.4)Anthropic (2024.9.20)Small Language Model
它们不生成完整的文本块,而是输出关键点或子主题。简单来说,因为它只提取关键点或子主题,这就相当于抓住了片段的核心意思,通过文本的语义转换,来更准确地识别边界,保证文本块的连贯性。topic-qwen-0.5: 这个模型受到了思维链 (Chain-of-Thought) 推理的启发,它会先识别文本中的主题,比如“第二次世界大战的开始”,然后用这些主题来定义分块边界。
Meta-Chunking (2024.8.16)
Margin Sampling Chunking:
- 将文本分割成一系列句子。
对于相邻的句子,使用 LLM 进行二元分类,判断是否需要分割。
LLM 输出两个选项的概率,计算概率差异 Margin。
将 Margin 与预设阈值进行比较,如果 Margin 大于阈值,则分割句子;否则,合并句子。- 优点:可以有效地降低对模型规模的需求,使得小模型也能胜任文本分块任务。
- 缺点:分割结果可能受到 LLM 模型的影响,且效率相对较低。
Perplexity Chunking:
- 将文本分割成一系列句子。
使用 LLM 计算每个句子基于其上下文的 PPL 值。
分析 PPL 值的分布特征,识别潜在的文本块边界(即 PPL 值的局部最小值)。
将句子分割成多个文本块,每个文本块包含一个或多个连续的句子。- 优点:分割结果更加客观,效率更高,并能够有效地捕捉文本的逻辑结构。
- 缺点:需要分析 PPL 值的分布特征,可能需要一定的计算量。
Late Chunking(jina 2024.8.4)
论文Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models:
github:https://github.com/jina-ai/late-chunking
jina博客:https://jina.ai/news/late-chunking-in-long-context-embedding-models/
项目链接:https://colab.research.google.com/drive/15vNZb6AsU7byjYoaEtXuNu567JWNzXOz?usp=sharing
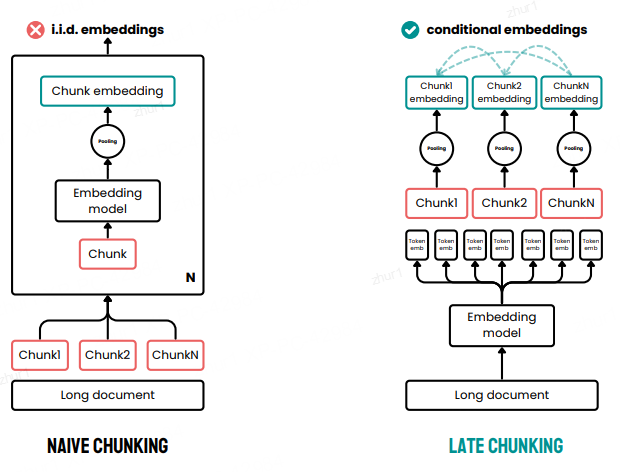
先用一个长上下文嵌入模型(比如 jina-embeddings-v2-small-en,具有 8K 上下文长度)"读懂"整个文档
然后再把这个"理解"切成小块
Late Chunking is now available in jina-embeddings-v3 API. 8192-token
文档越长,后期分块策略就越有效。
Anthropic (2024.9.20)
链接:https://www.anthropic.com/news/contextual-retrieval
Anthropic 引入了一种称为上下文检索的单独策略。 Anthropic 的方法是一种解决上下文丢失问题的强力方法
其工作原理如下:
每个块都会与完整的文档一起发送给LLM 。
LLM为每个块添加相关上下文。
这会产生更丰富、信息更丰富的嵌入。
这本质上是上下文丰富,其中全局上下文使用LLM显式硬编码到每个块中,这在成本、时间和存储方面都很昂贵。此外,尚不清楚这种方法是否能够适应块边界,因为LLM依赖于准确且可读的块来有效地丰富上下文
Small Language Model, SLM–qwen0.5
simple-qwen-0.5: 这是最简单的模型,主要根据文档的结构元素识别边界。它简单高效,适合基本的分块需求。https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5b
topic-qwen-0.5: 这个模型受到了思维链 (Chain-of-Thought) 推理的启发,它会先识别文本中的主题,比如“第二次世界大战的开始”,然后用这些主题来定义分块边界。它能保证每个文本块在主题上保持连贯,特别适合处理复杂的多主题文档。初步测试表明,它分块的效果很不错,很接近人类的直觉。https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5b-cot-topic-chunking
summary-qwen-0.5: 这个模型不仅能识别文本边界,还能给每个文本块生成摘要。在 RAG 应用里,文本块摘要很有用,尤其是在长文档问答这种任务上。当然,代价就是训练时需要更多的数据。https://huggingface.co/jinaai/text-seg-lm-qwen2-0.5b-summary-chunking
这三个模型都只返回文本块的头部,也就是每个文本块的截断版本。它们不生成完整的文本块,而是输出关键点或子主题。简单来说,因为它只提取关键点或子主题,这就相当于抓住了片段的核心意思,通过文本的语义转换,来更准确地识别边界,保证文本块的连贯性。检索的时候,会根据这些 “文本块头部” 把文档文本切片,然后再根据切片结果重建完整的片段。相当于先用 “文本块头部” 做了个索引,需要的时候再根据索引找到对应的完整片段。这样既能保证检索的精准度,又能提高效率,避免处理过多的冗余信息。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)