AI不再只会“说“:MCP技术让大模型具备代码执行能力,开发实战全解析
MCP的全称是Model Context Protocol,直译过来就是"模型上下文协议"。但这个名字听起来有点晦涩,我更愿意称它为“AI的USB-C接口”。还记得智能手机刚兴起时,每个品牌都有自己的充电接口吗?那时候出门得带一堆不同的充电线,简直噩梦。直到USB-C统一标准后,才真正实现了"一线走天下"。MCP就是AI世界的USB-C标准。它定义了一套通用协议,让任何AI应用都能即插即用地连接外
文章介绍Anthropic的MCP技术,让AI大模型从"纸上谈兵"到实际执行代码。MCP采用统一协议连接AI与外部工具,通过安全沙盒确保执行安全,性能优化显著。文章详细解析其架构、安全机制和优化方案,展示在数据分析、开发调试等场景的应用价值,提供开发实战指南和避坑技巧,展望未来智能开发环境等应用前景。
还在为大模型只能"纸上谈兵"而烦恼?看看Anthropic的最新黑科技如何让AI真正"动起手来"。
开篇:一个程序员的烦恼
老王最近很苦恼。作为公司的资深架构师,他花了半年时间训练了一个智能代码助手,理论上能帮他处理各种开发任务。但现实却很骨感:
- • 想让它分析日志文件?对不起,只能看文本内容
- • 想让它调用API接口?抱歉,没有网络访问权限
- • 想让它执行代码验证?抱歉,只能给出建议
这感觉就像培养了一个理论满分但手无缚鸡之力的"秀才"——知识储备惊人,动手能力为零。
相信很多朋友都有类似体验:大模型在对话中表现得像个全栈专家,但一到实际操作就"露馅"了。这种"知行分离"的痛点,正是Anthropic推出MCP(Model Context Protocol)想要解决的问题。
什么是MCP?给AI装上一双"手"
MCP的全称是Model Context Protocol,直译过来就是"模型上下文协议"。但这个名字听起来有点晦涩,我更愿意称它为“AI的USB-C接口”。
还记得智能手机刚兴起时,每个品牌都有自己的充电接口吗?那时候出门得带一堆不同的充电线,简直噩梦。直到USB-C统一标准后,才真正实现了"一线走天下"。
MCP就是AI世界的USB-C标准。它定义了一套通用协议,让任何AI应用都能即插即用地连接外部工具和数据源。
核心架构揭秘

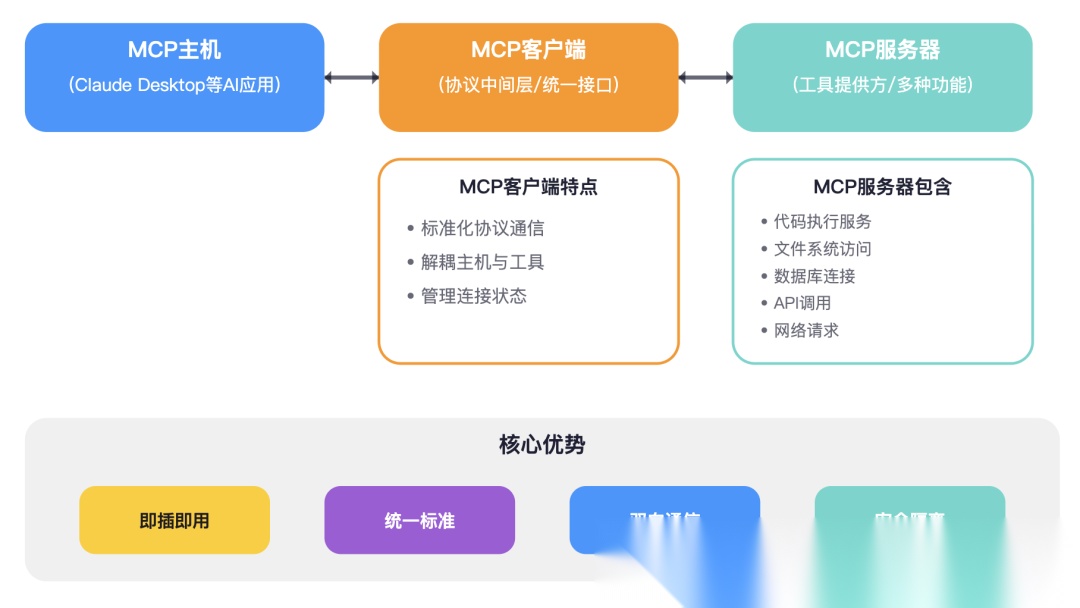
MCP的架构设计非常巧妙,采用了经典的客户端-服务器模式:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐│ MCP主机 │ │ MCP客户端 │ │ MCP服务器 ││ (Claude等) │◄──►│ (协议中间层) │◄──►│ (工具提供方) │└─────────────────┘ └─────────────────┘ └─────────────────┘
- • MCP主机:发起连接的AI应用,比如Claude Desktop
- • MCP客户端:在主机内部维护与服务器连接的协议客户端
- • MCP服务器:通过标准化协议暴露特定功能的轻量级程序
这种设计的妙处在于:解耦。AI应用不需要知道具体工具的实现细节,只需要通过统一协议调用即可。
实战演示:代码执行的"魔法时刻"
说了这么多理论,让我们看一个实际的例子,感受一下MCP如何让AI真正"动起手来"。
假设我们想让Claude帮我们分析一个大型日志文件,找出其中的错误模式。在MCP出现之前,我们只能:
-
- 把日志内容复制粘贴给Claude(超过token限制就GG)
-
- 让Claude给出分析建议(纯理论,无法验证)
-
- 手动执行Claude建议的命令(效率低下)
有了MCP之后,整个流程变得丝滑无比:
// 直接在对话中调用代码执行工具const result = await codeExecutor.run({code: ` import pandas as pd import re # 读取日志文件 logs = pd.read_csv('/workspace/app.log', sep='\', header=None) logs.columns = ['raw_log'] # 提取错误信息 error_pattern = r'ERROR.*?:(.*?)$' errors = logs[logs['raw_log'].str.contains('ERROR', na=False)] error_details = errors['raw_log'].str.extract(error_pattern) # 统计错误类型 error_summary = error_details[0].value_counts().head(10) print("Top 10 Error Types:") print(error_summary) `,timeout: 30000,sandbox: {filesystem: 'restricted',network: 'disabled',memory_limit: '1GB' }});// 获取执行结果并继续对话console.log(result.output);
看到了吗?AI不再只是纸上谈兵,而是真正执行了代码!
安全沙盒:给"动手能力"加上"安全带"
等等,有些朋友可能会担心:让AI执行代码?这安全吗?万一它执行了恶意代码怎么办?
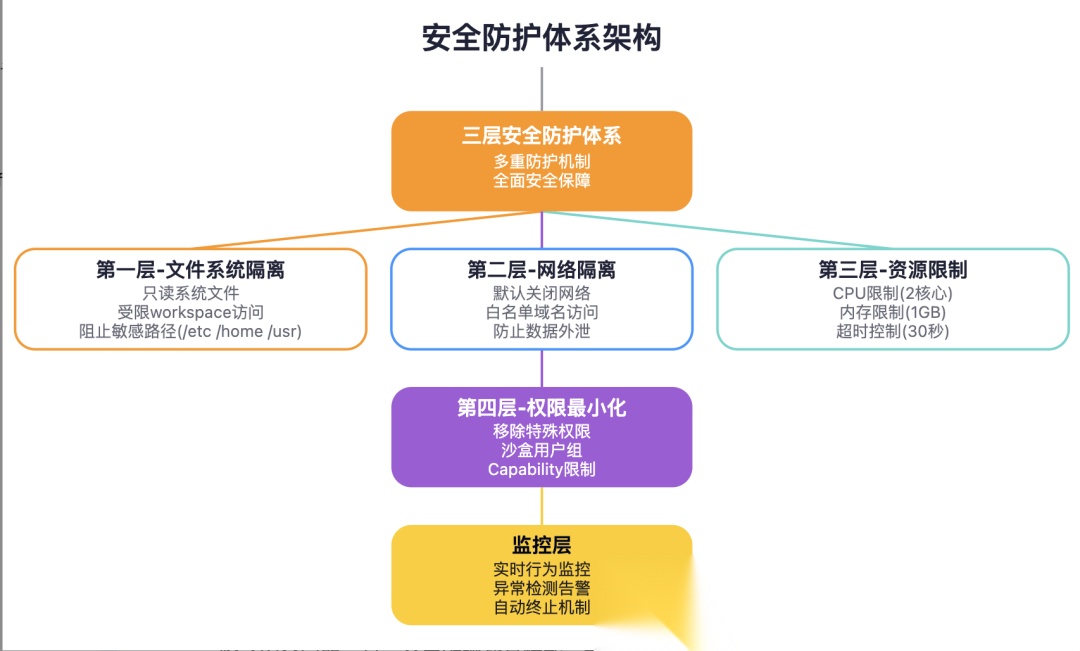
别急,Anthropic早就想到了这一点。MCP的代码执行功能运行在安全沙盒中,就像给调皮的孩子戴上安全帽:
# 沙盒配置示例sandbox_config:filesystem:read_paths: ["/workspace/input"]write_paths: ["/workspace/output"]blocked_paths: ["/etc", "/home", "/usr"]network:enabled:false# 默认关闭网络访问allowed_hosts: [] # 允许访问的域名白名单resources:cpu_limit:"2 cores"memory_limit:"1GB"timeout:"30s"security:user_id:"sandbox_user"group_id:"sandbox_group"capabilities: [] # 移除所有特殊权限
这个沙盒有以下几个关键特性:
-
- 文件系统隔离:只能访问指定的workspace目录,系统文件完全隔离
-
- 网络隔离:默认关闭网络,防止数据外泄
-
- 资源限制:CPU、内存、执行时间都有严格限制
-
- 权限最小化:移除所有不必要的系统权限
换句话说,AI可以在沙盒里"为所欲为",但绝对逃不出这个"笼子"。
性能优化:从"蜗牛"到"猎豹"
除了安全问题,另一个关键挑战是性能。如果每次代码执行都要启动一个完整的容器,那效率简直惨不忍睹。
Anthropic在这方面也做了深度优化。根据官方数据,MCP的代码执行相比传统方案减少了98.7%的token消耗!
他们是怎么做到的?让我揭秘几个关键技术点:
1. 智能预加载
# 传统方案:每次都从头开始for task in tasks: container = create_container() install_dependencies() execute_code() cleanup()# MCP方案:预加载常用环境base_image = preload_environment("python-data-science")for task in tasks: sandbox = base_image.clone() execute_code(sandbox)
2. 流式处理
// 边执行边返回结果,不需要等全部完成const execution = codeExecutor.stream({code: largeDataProcessingCode,onProgress: (result) => {// 实时显示处理进度updateUI(result.partialOutput); }});
3. 智能缓存
# 代码分析缓存@lru_cache(maxsize=1000)defanalyze_code(code_hash):return {'imports': extract_imports(code_hash),'dependencies': analyze_dependencies(code_hash),'resource_needs': estimate_resources(code_hash) }# 根据分析结果优化执行环境execution_plan = analyze_code(user_code)optimized_env = prepare_environment(execution_plan)
实际应用场景:从理论到实践
说了这么多技术细节,让我们看看MCP代码执行在实际工作中能解决哪些问题。
场景1:数据分析师的得力助手
小张是公司的数据分析师,每天需要处理大量的销售数据。以前的工作流程是:
-
- 写SQL提取数据(10分钟)
-
- 导出到Excel(5分钟)
-
- 写Python做分析(30分钟)
-
- 生成图表(15分钟)
-
- 整理报告(20分钟)
总计:80分钟
有了MCP之后,他只需要对AI说:"帮我分析一下上个月的销售数据,重点关注区域差异和产品类别表现。"然后AI会自动:
# AI自动生成的分析代码import pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# 连接数据库sales_data = query_database(""" SELECT region, product_category, sales_amount, date FROM sales WHERE date >= DATE_SUB(CURDATE(), INTERVAL 1 MONTH)""")# 区域销售分析region_analysis = sales_data.groupby('region')['sales_amount'].agg(['sum', 'mean', 'count'])# 产品类别分析category_analysis = sales_data.groupby('product_category')['sales_amount'].sum().sort_values(ascending=False)# 生成可视化图表fig, axes = plt.subplots(2, 2, figsize=(15, 10))# ... 绘图代码# 生成分析报告report = generate_report(region_analysis, category_analysis, visualizations)
时间缩短到:5分钟对话 + 2分钟执行 = 7分钟
效率提升了10倍!
场景2:开发者的智能调试伙伴
程序员小李遇到了一个棘手的bug,传统的调试流程是:
-
- 重现问题(随机,可能很久)
-
- 查看日志(大海捞针)
-
- 猜测原因(靠经验)
-
- 修改代码(可能引入新问题)
-
- 测试验证(循环往复)
有了MCP,他可以这样:
小李:我的应用在用户登录时会偶尔崩溃,能帮我分析一下吗?AI:我来帮你分析。首先让我查看一下最近的错误日志:```python# AI自动执行日志分析import refrom datetime import datetime, timedelta# 分析错误日志error_pattern = r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).*?(ERROR|EXCEPTION).*?(.*?)(?=\d{4}-\d{2}-\d{2}|$)'with open('/app/logs/auth.log', 'r') as f: content = f.read()errors = re.findall(error_pattern, content, re.DOTALL)login_errors = [e for e in errors if 'login' in e[2].lower()]print(f"发现 {len(login_errors)} 个登录相关错误")for error in login_errors[-5:]: # 显示最近5个 print(f"时间: {error[0]}") print(f"错误: {error[2][:200]}...") print("-" * 50)
AI:根据日志分析,我发现了一个模式:所有登录崩溃都发生在内存使用超过85%的时候。让我进一步检查内存泄漏的可能性…
### 场景3:运维工程师的自动化助手运维工程师小王每天要检查几十个服务器的健康状态。以前他需要:1. 逐个SSH登录服务器2. 执行各种检查命令3. 收集结果并分析4. 生成报告**耗时2小时,还容易遗漏**现在有了MCP:```python# AI自动生成的健康检查脚本import asyncioimport aiohttpimport jsonfrom datetime import datetimeasync def check_server_health(server): """检查单个服务器健康状态""" checks = { 'cpu_usage': f"ssh {server} 'top -bn1 | grep load'", 'memory_usage': f"ssh {server} 'free -m'", 'disk_space': f"ssh {server} 'df -h'", 'service_status': f"ssh {server} 'systemctl status nginx'", 'response_time': f"curl -w '%{time_total}' -o /dev/null -s {server}" } results = {} for check_name, command in checks.items(): result = await execute_command(command) results[check_name] = parse_result(result) return results# 并发检查所有服务器servers = ['web-server-01', 'web-server-02', 'db-server-01', 'cache-server-01']results = await asyncio.gather(*[check_server_health(server) for server in servers])# 生成健康报告health_report = generate_health_report(dict(zip(servers, results)))
5分钟完成所有检查,还能预测潜在问题
开发实战:30分钟上手MCP
理论讲得够多了,让我们动手实践一下。下面我会带你一步步搭建一个MCP代码执行环境。
第一步:环境准备
# 安装MCP SDKnpm install @modelcontextprotocol/sdk# 安装代码执行服务器npm install @mcp-servers/code-executor# 安装开发工具npm install -g mcp-cli
第二步:创建配置文件
{"mcpServers":{"codeExecutor":{"command":"npx","args":["@mcp-servers/code-executor","--config","./executor-config.json"],"env":{"LOG_LEVEL":"info","MAX_CONCURRENT_EXECUTIONS":"10"}}}}
第三步:配置安全沙盒
{"sandbox":{"type":"docker","image":"mcp-executor-python:latest","resource_limits":{"cpu":"2","memory":"1g","timeout":"30000"},"filesystem":{"read_only":true,"allowed_paths":["/workspace"],"blocked_paths":["/etc","/home","/usr"]},"network":{"enabled":false}},"supported_languages":["python","javascript","bash"],"preinstalled_packages":{"python":["pandas","numpy","matplotlib","requests"],"javascript":["lodash","axios","moment"]}}
第四步:编写简单的MCP客户端
import { MCPClient } from'@modelcontextprotocol/sdk';classCodeExecutionClient {privateclient: MCPClient;constructor() {this.client = newMCPClient({serverUrl: 'http://localhost:8080',timeout: 30000 }); }asyncexecuteCode(code: string, language: string = 'python') {try {const result = awaitthis.client.callTool('codeExecutor', 'execute', { code, language,timeout: 30000 });return {success: true,output: result.output,executionTime: result.metadata.executionTime,resourceUsage: result.metadata.resourceUsage }; } catch (error) {return {success: false,error: error.message,details: error.details }; } }}// 使用示例const client = newCodeExecutionClient();const result = await client.executeCode(`import pandas as pdimport matplotlib.pyplot as plt# 生成示例数据data = pd.DataFrame({ 'x': range(1, 11), 'y': [x**2 for x in range(1, 11)]})# 创建图表plt.figure(figsize=(10, 6))plt.plot(data['x'], data['y'], 'b-', linewidth=2)plt.title('Simple Quadratic Plot')plt.xlabel('X')plt.ylabel('Y')plt.grid(True, alpha=0.3)plt.savefig('/workspace/plot.png', dpi=150, bbox_inches='tight')plt.show()print("图表已生成并保存!")`);console.log(result);
第五步:错误处理和监控
classMonitoredCodeExecutor {private executionMetrics = {totalExecutions: 0,successfulExecutions: 0,failedExecutions: 0,averageExecutionTime: 0,resourceUsage: [] };asyncexecuteWithMonitoring(code: string, options: ExecutionOptions) {const startTime = Date.now();try {// 预检查awaitthis.preFlightCheck(code, options);// 执行代码const result = awaitthis.client.executeCode(code, options);// 更新指标const executionTime = Date.now() - startTime;this.updateMetrics(result, executionTime);// 后处理awaitthis.postExecutionProcessing(result);return result; } catch (error) {this.handleExecutionError(error, code, options);throw error; } }privateasyncpreFlightCheck(code: string, options: ExecutionOptions) {// 检查代码安全性const securityIssues = awaitthis.securityScanner.scan(code);if (securityIssues.length > 0) {thrownewSecurityError(`Security issues detected: ${securityIssues.join(', ')}`); }// 检查资源需求const resourceEstimate = awaitthis.resourceEstimator.estimate(code);if (resourceEstimate.memory > options.maxMemory) {thrownewResourceError(`Estimated memory usage (${resourceEstimate.memory}MB) exceeds limit (${options.maxMemory}MB)`); } }privatehandleExecutionError(error: Error, code: string, options: ExecutionOptions) {// 记录错误详情this.logger.error('Code execution failed', {error: error.message,code: code.substring(0, 500), // 记录代码片段 options,timestamp: newDate().toISOString() });// 根据错误类型提供建议if (error instanceofTimeoutError) {this.logger.info('Consider increasing timeout or optimizing code performance'); } elseif (error instanceofMemoryError) {this.logger.info('Consider reducing data size or using more memory-efficient algorithms'); } }}
避坑指南:常见问题与解决方案
在实际使用MCP的过程中,我总结了一些常见问题和解决方案:
1. 超时问题
问题:代码执行时间超过限制,被强制终止。
解决方案:
// 方案1:分批处理大数据asyncfunctionprocessLargeDataset(data: any[], batchSize: number = 1000) {const results = [];for (let i = 0; i < data.length; i += batchSize) {const batch = data.slice(i, i + batchSize);// 每批数据在独立的执行环境中处理const batchResult = await executor.executeCode(` import pandas as pd # 处理当前批次数据 batch_data = ${JSON.stringify(batch)} df = pd.DataFrame(batch_data) # 执行分析 result = analyze_batch(df) result `); results.push(batchResult); }returnthis.mergeResults(results);}// 方案2:异步处理asyncfunctionasyncProcessing(data: any[]) {const promises = data.map((item, index) => limiter.schedule(() =>this.processItem(item, index)) );const results = awaitPromise.allSettled(promises);return results .filter(result => result.status === 'fulfilled') .map(result => result.value);}
2. 内存不足问题
问题:代码执行过程中内存使用超出限制。
解决方案:
// 方案1:内存友好的数据处理functionmemoryEfficientProcessing(largeFilePath: string): void {// 使用流式处理而不是一次性加载const stream = createReadStream(largeFilePath); stream .pipe(createLineParser()) .pipe(createBatchProcessor({ batchSize: 100 })) .pipe(createResultAggregator()) .pipe(createOutputWriter());}// 方案2:分阶段垃圾回收asyncfunctionprocessingWithGC(data: any[]): Promise<any> {const results = [];for (let i = 0; i < data.length; i += 100) {const chunk = data.slice(i, i + 100);// 处理当前块const chunkResult = awaitthis.processChunk(chunk); results.push(chunkResult);// 显式触发垃圾回收(如果环境支持)if (global.gc) {global.gc(); } }return results;}</any>
3. 依赖包缺失问题
问题:代码需要特定的依赖包,但沙盒环境中没有安装。
解决方案:
// 方案1:声明式依赖管理interfaceDependencyDeclaration {language: string;packages: Array<{name: string;version?: string;source?: 'pypi' | 'npm' | 'github'; }>;}asyncfunctionexecuteWithDependencies(code: string,dependencies: DependencyDeclaration): Promise<executionresult> {// 检查依赖是否可用const missingDeps = awaitthis.checkMissingDependencies(dependencies);if (missingDeps.length > 0) {// 尝试安装缺失的依赖awaitthis.installDependencies(missingDeps); }// 执行代码returnawaitthis.executor.executeCode(code);}// 方案2:自包含代码包asyncfunctioncreateSelfContainedPackage(code: string,dependencies: string[]): Promise<string> {// 创建包含所有依赖的代码包const packageCode = ` # 自包含的依赖安装 import subprocess import sys def install_dependencies(): dependencies = ${JSON.stringify(dependencies)} for dep in dependencies: try: __import__(dep) except ImportError: subprocess.check_call([sys.executable, "-m", "pip", "install", dep]) # 安装依赖 install_dependencies() # 原始代码${code} `;return packageCode;}</string></executionresult>
未来展望:MCP的无限可能
MCP代码执行功能的出现,让我看到了AI应用的无限可能。想象一下这些场景:
1. 智能开发环境
未来的IDE可能完全由AI驱动:
- • 智能重构:AI分析代码结构,自动执行重构操作
- • 自动化测试:AI根据代码变更自动生成和运行测试用例
- • 性能优化:AI识别性能瓶颈,自动优化代码
- • bug修复:AI分析错误日志,自动生成修复方案并验证
2. 自主数据分析
数据分析师只需要提出问题,AI就能:
- • 自动数据收集:从各种数据源收集相关数据
- • 智能清洗:识别并处理数据质量问题
- • 自动分析:选择合适的分析方法并执行
- • 生成报告:创建包含图表和洞察的综合报告
3. 智能运维系统
运维工作将变得更加自动化:
- • 预测性维护:AI监控系统状态,预测潜在问题
- • 自动扩缩容:根据负载情况自动调整资源配置
- • 智能告警:AI分析告警信息,过滤噪音,识别根本原因
- • 自动修复:对于已知问题,AI可以自动执行修复操作
4. 个性化教育助手
每个学生都可以有自己的AI导师:
- • 个性化练习:根据学生水平生成适合的练习题
- • 实时反馈:学生做题时提供即时指导和解释
- • 进度跟踪:分析学习进度,调整学习计划
- • 智能评估:通过代码执行验证学生的编程作业
结语:AI的"动手能力"革命
回顾整个MCP代码执行功能,我看到的不只是一个技术特性,而是AI能力的一次质的飞跃。
从"纸上谈兵"到"真刀真枪",从"理论家"到"实践者",MCP让AI真正具备了改变世界的"动手能力"。这不仅仅是技术的进步,更是人机协作模式的革命。
作为技术人员,我们应该积极拥抱这种变化:
-
- 学习MCP协议:理解其工作原理和最佳实践
-
- 开发MCP服务器:为特定领域创建专业的工具
-
- 集成MCP功能:在现有应用中添加AI代码执行能力
-
- 探索新场景:思考哪些工作可以由AI自动化
未来已来,只是尚未普及。MCP代码执行功能就像一把钥匙,为我们打开了AI应用的新世界。让我们一起探索这个充满无限可能的新领域!
https://www.anthropic.com/engineering/code-execution-with-mcp
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)