Paimon——底层核心设计
Paimon——底层核心设计:从 LSM Tree 到 Compaction
底层磁盘读写的区别
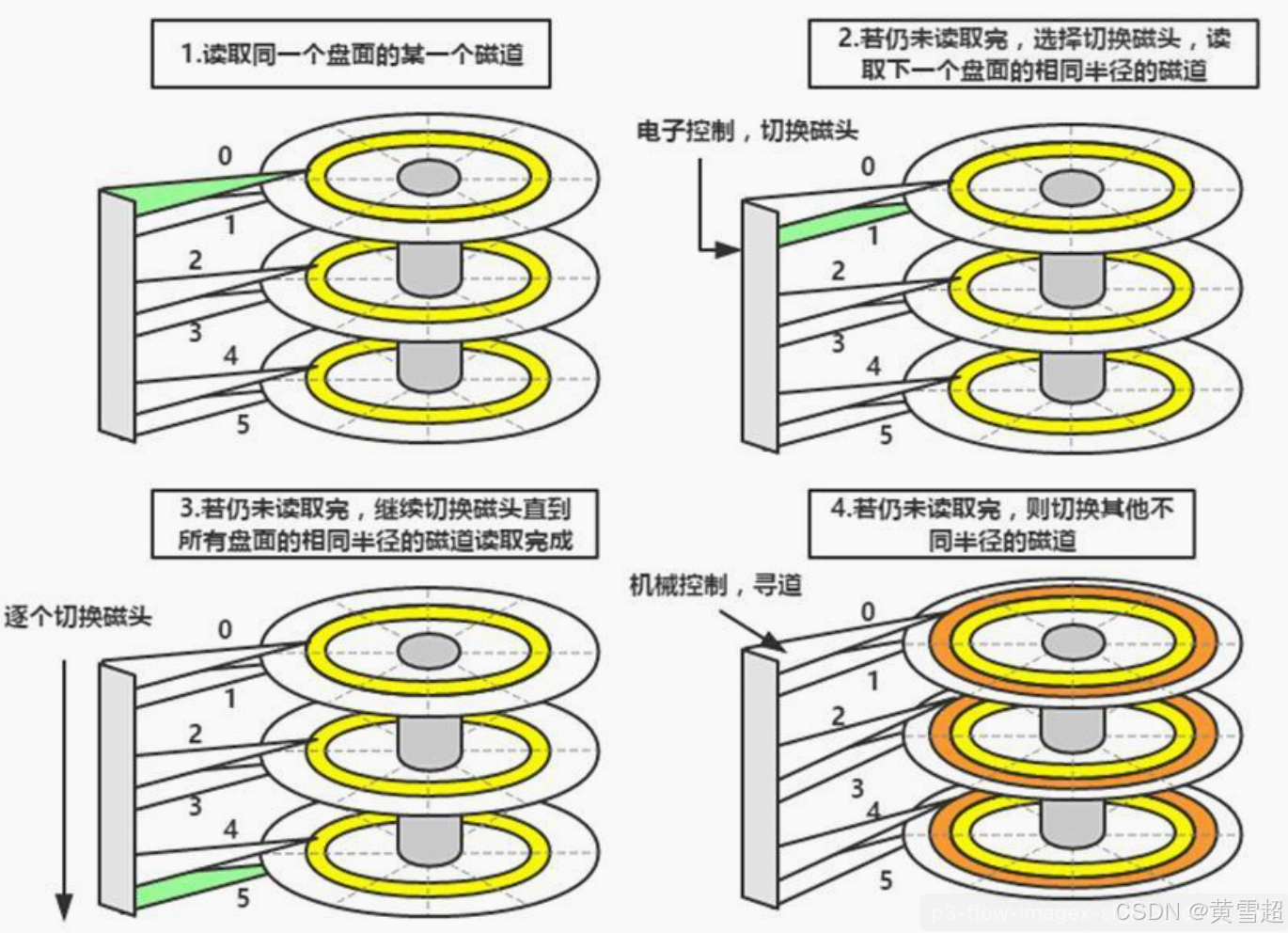
在深入探讨 Paimon 之前,让我们先回顾一下数据存储的底层基石 —— 磁盘读写原理,尤其是机械硬盘与固态硬盘在顺序读写和随机读写上的巨大差异,这是理解 Paimon 高性能奥秘的关键前导知识。
机械硬盘与固态硬盘的核心差异解析
机械硬盘与固态硬盘作为数据存储的两大主力,其内部结构和工作原理大相径庭,这些差异直接决定了它们在顺序读写和随机读写场景下的性能表现。
机械硬盘
机械硬盘(HDD, Hard Disk Drive)采用的是 “盘片 + 磁头” 的经典机械结构,就像一个精密的唱片播放机。数据以磁性的形式存储在高速旋转的盘片上,而磁头则负责在盘片表面进行数据的读写操作。其读写流程宛如一场精心编排的机械舞蹈,需历经寻道定位、旋转等待、数据传输这三个关键阶段 。
- 寻道定位:当接到读写指令,磁头臂需要将磁头移动到目标磁道,这一过程如同在图书馆书架中寻找特定书籍,平均寻道时间大约在 5 - 10ms,是整个读写过程中耗时较长的部分。
- 旋转等待:磁头到达目标磁道后,还需等待盘片将目标扇区旋转到磁头下方,就像等待唱片转到正确的播放位置,平均旋转延迟约为 4 - 6ms。
- 数据传输:只有前两个步骤完成,才能开始数据的读写传输,这才是我们真正想要的数据交互环节。
如此繁琐的机械操作流程,使得寻道时间和旋转延迟成为机械硬盘性能的主要瓶颈,尤其在随机读写场景下,磁头频繁的跳跃式移动,极大地降低了读写效率。
固态硬盘
固态硬盘(SSD, Solid State Drive)则是一场存储技术的革命,它基于 NAND 闪存芯片,彻底摒弃了机械结构,数据存储和读写都通过电子信号完成,如同电子图书馆般便捷高效。
在固态硬盘内部,控制器扮演着 “大管家” 的角色,负责实现逻辑地址到物理地址的映射(FTL 技术) ,确保数据能准确无误地存储和读取。存储单元以页(通常 4 - 16KB)为读写单位、块(4 - 128MB)为擦除单位。由于没有机械部件的束缚,固态硬盘的随机访问延迟可低至 0.1ms,连续读写速度更是能达到 3500MB/s 以上,轻松突破了机械硬盘的寻道瓶颈,在数据读写的赛道上一路飞驰。
顺序读写碾压随机读写的技术本质
无论是机械硬盘还是固态硬盘,顺序读写的速度往往远快于随机读写,这背后蕴含着深刻的技术原理。
机械硬盘
在机械硬盘的世界里,顺序读写就像是在一条畅通无阻的高速公路上行驶,磁头可以沿着磁道连续移动,无需频繁寻道。数据如同排列整齐的车队,依次被读取或写入,数据传输率可达 150MB/s。而随机读写则像是在错综复杂的城市街道中穿梭,磁头需要频繁地在不同磁道间跳跃,每次寻道都伴随着时间的消耗,实际 IOPS(每秒输入输出操作次数)仅在 50 - 200 之间,性能与顺序读写相比,相差了 2 - 3 个数量级,这巨大的差距犹如天堑。
固态硬盘
固态硬盘虽没有机械寻道的烦恼,但在随机读写时,仍会受到一些因素的制约。由于闪存芯片的并行访问能力有限(单 Die 队列深度限制),就像一个繁忙的港口,船只(数据请求)不能无限制地同时进出。而且,随机读写会频繁触发垃圾回收机制,这一过程需要清理和整理无效数据块,就像定期打扫仓库,耗时费力。因此,固态硬盘的随机读写性能(约 10 万 IOPS)仍低于顺序读写(20 万 + IOPS) 。而顺序操作则能充分利用控制器的队列合并、预取策略及存储介质的批量处理特性,如同高效的物流配送,将数据快速准确地送达目的地。
总结
顺序和随机读写: 不管在机械硬盘还是固态硬盘,顺序读写都是最好的。
- 机械硬盘慢的原因主要是寻道时间和旋转延迟时间。
- 固态硬盘主要原因是Block擦除机制,垃圾回收。
机械硬盘和固态硬盘在工作原理、性能特点和适用场景上存在本质区别:
- 工作原理的本质区别:
- 机械硬盘基于磁性存储原理,依赖磁头在高速旋转的盘片上进行读写操作,这导致了寻道时间和旋转延迟的存在。
- 固态硬盘基于闪存存储原理,通过电子信号直接访问存储单元,无需任何机械运动,大大减少了访问延迟。
- 性能特点的本质区别:
- 机械硬盘的顺序读写性能相对较好,但随机读写性能极差,受寻道时间和旋转延迟的严重限制。
- 固态硬盘在顺序读写和随机读写方面都表现出色,尤其是随机读写性能比机械硬盘高出数千倍。
- 适用场景的本质区别:
- 机械硬盘适合大容量、低成本的冷数据存储场景,但在性能要求高的场景中表现不佳。
- 固态硬盘适合对性能要求高的场景,如操作系统盘、企业级应用等,但每 GB 成本较高。
从 LSM Tree 到 Compaction
因为磁盘随机读写慢,顺序读写快的特性,如果要提高写操作性能,就需要尽可能避免随机写,设计成顺序写。但是读取却要花费很多时间,因为查询具体的内容需要扫描所有数据。所以为了高效的读和写,就需要根据具体的场景做一个权衡,LSM-Tree也就因此诞生。
什么是 LSM-Tree
LSM-Tree全称是Log Structured Merge Tree,是一种分层,有序,面向磁盘的数据结构,其核心思想是充分了利用磁盘批量的顺序写要远比随机写性能高出很多。
在传统的存储结构中,写操作往往是随机的,就像在一本杂乱无章的笔记本上随意记录信息,这对于磁盘来说,就需要频繁地移动磁头,寻找合适的存储位置,从而大大降低了写入效率。而 LSM-Tree 则另辟蹊径,它将写操作先缓存到内存中的 MemTable(一种有序的数据结构,如跳表 SkipList ),当 MemTable 达到一定阈值后,再将其数据批量、顺序地写入磁盘,生成 SSTable(Sorted String Table)文件 。这就好比先在一个整洁的草稿本上记录信息,等草稿本写满了,再将这些信息有条理地抄写到正式的笔记本上,极大地提高了写入性能。
LSM-Tree 采用了分层存储架构,由内存中的 MemTable 和磁盘上的多层 SST 文件共同组成。在写入时,数据先被记录在预写日志(WAL,Write Ahead Log)中,这就像是给数据上了一道保险,确保在系统崩溃时数据不会丢失。然后,数据被插入到 MemTable 中,在 MemTable 中,数据按照键值有序排列,方便快速查找。当 MemTable 满了之后,就会被标记为 Immutable MemTable(只读的 MemTable),并触发后台线程将其内容刷入磁盘,生成 Level-0 的 SST 文件 。而磁盘上的 SST 文件会随着时间的推移不断增多,为了避免文件过多影响查询性能,LSM-Tree 引入了 Compaction 机制,它就像一个勤劳的整理员,定期将多个较小的 SSTable 文件合并成一个更大的 SSTable 文件,在这个过程中,会去除重复的数据,清理已经删除的数据,从而减少文件数量,提高查询效率 。
在读取数据时,LSM-Tree 会先从 MemTable 中查找,如果没找到,再依次从 Immutable MemTable 和各级 SST 文件中查找。为了减少不必要的磁盘 I/O 操作,SST 文件通常会配备布隆过滤器,去快速判断某个键值是否不存在于 SST 文件中,避免了在大量数据中进行无效的查找。
LSM Tree 写数据流程
- WAL 预写日志:当写操作降临,LSM-Tree 首先将数据记录在预写日志(WAL)中。这一操作就像是在账本上记录每一笔交易,确保即使系统突然崩溃,数据也能从日志中恢复,保障了数据的持久性和一致性 。
- MemTable 写入:紧接着,数据会被插入到内存中的 MemTable。MemTable 就像是一个有序的书架,采用跳表(SkipList)等数据结构,确保数据按键值有序排列,这种有序性为后续的查找和处理提供了极大的便利 。
- MemTable 刷盘与 SSTable 生成:随着数据的不断涌入,当 MemTable 达到预设的大小阈值时,它会被标记为 Immutable MemTable,转变为只读状态。此时,一个新的 MemTable 会被创建,随时准备接收新的写入数据。而 Immutable MemTable 中的数据则会被后台线程有序地刷入磁盘,生成 Level - 0 的 SSTable 文件,这个过程就像是将书架上满了的书籍整理打包,搬到更大的仓库(磁盘)中存储 。
- Compaction 合并操作:在磁盘上,随着时间的推移,SSTable 文件会越来越多,就像仓库里的包裹堆积如山。当多个 SSTable 文件达到一定数量时,就会触发 Compaction 合并操作。这个过程如同仓库管理员对包裹进行整理合并,将多个小包裹合并成大包裹,去除重复和过期的数据,减少文件数量,提升存储效率和查询性能 。在合并过程中,会根据键值对的顺序进行归并排序,确保新生成的 SSTable 文件中的数据依然有序。
思考:LSM-Tree 的特点
- 顺序写入优势:LSM-Tree 充分发挥了磁盘顺序写的优势,将离散的随机写请求转化为批量的顺序写请求,极大地提升了写入性能。就像在高速公路上,车辆可以快速、顺畅地行驶,而不是在小道上频繁地停车、启动 。
- 分层存储架构:采用内存与磁盘相结合的分层存储架构,内存中的 MemTable 负责快速接收和处理写入数据,磁盘上的 SSTable 则用于长期存储数据。这种分层设计既保证了写入的高效性,又兼顾了数据的持久性,就像一个高效的物流系统,不同的仓库负责不同阶段的货物存储和流转 。
- 数据更新方式:LSM-Tree 的更新操作并非直接在原数据上进行修改,而是通过追加新记录来实现。这种方式避免了随机写操作,保证了数据写入的顺序性。对于删除操作,它采用墓碑标记(tombstone)的方式,在合并过程中再真正删除数据,这就像是在文件上做个删除标记,等整理文件时再彻底删除,减少了即时删除带来的复杂性和性能损耗 。
- 查询性能挑战:虽然 LSM-Tree 在写入性能上表现出色,但查询时需要遍历多个层级的存储结构,从 MemTable 到各级 SSTable,这可能导致查询路径变长,查询性能相对下降。尤其是在数据量庞大、文件层级较多的情况下,查询效率会受到一定影响,就像在一个多层的大型图书馆中查找一本书,需要花费更多的时间和精力 。
写入放大的困境:LSM-Tree 的写入放大问题是其性能的一大挑战。由于每次写入操作都会生成新的 SSTable 文件,而旧版本的数据需要通过 Compaction 合并清理,这就导致了同一数据可能会被多次写入磁盘。在频繁写入的场景下,写入放大可能会使磁盘写入的数据量远远超过实际写入的数据量,就像复印文件时,反复复印同一份文件,不仅浪费纸张(磁盘空间),还降低了复印速度(写入性能) 。
Compaction 的关键作用:Compaction 机制是解决写入放大问题的关键,也是 LSM-Tree 性能优化的核心。它通过合并 SSTable 文件,去除重复和过期的数据,有效地减少了文件数量,降低了存储开销,提高了查询性能 。但如果 Compaction 策略不当,比如合并过于频繁或合并时机不合适,可能会占用大量的磁盘 I/O 和 CPU 资源,导致系统性能抖动 。
Paimon Sorted Runs
Paimon 底层就是采用 LSM 树作为文件存储的数据结构,将文件组织成多个 Sorted Run,Sorted Run 就像是一个个有序的数据集合。每个 Sorted Run 由一个或多个数据文件组成,并且每个数据文件都精确地属于一个 Sorted Run,这种归属关系保证了数据的有序管理 。
在数据文件中,记录按照其主键进行严格排序,就像图书馆的书籍按照分类编号有序摆放。在同一个 Sorted Run 中,不同数据文件的主键范围永远不会重叠,这使得在查询时能够快速定位到相关数据文件 。然而,不同的 Sorted Run 之间可能具有重叠的主键范围,甚至可能包含相同的主键,这就需要在查询时进行特殊处理 。
当查询 LSM 树时,就如同在一个大型图书馆中查找多本相关书籍,必须将所有 Sorted Run 合并起来,综合考虑各个 Sorted Run 中的数据 。并且,对于具有相同主键的所有记录,Paimon 会根据用户指定的合并引擎和每条记录的时间戳来进行合并,以确保查询结果的准确性和一致性 。
Paimon vs Hudi vs Iceberg 的 Compaction 策略对比
|
特性 |
Paimon |
Hudi |
Iceberg |
|
合并触发机制 |
主键表自动触发(Flink Sink 内置) |
时间 / 大小双重阈值 |
手动触发为主,支持自动策略 |
|
文件组织方式 |
LSM 分层 + Manifest 索引 |
基于文件组(File Group) |
表级元数据 + 数据文件 |
|
合并粒度 |
支持分区内层级合并 |
文件组级合并 |
分区级合并 |
|
核心优势 |
流批一体自动合并 |
写入时预合并优化 |
事务一致性强 |
思考:Compaction 主要是为了解决什么问题?
- 小文件合并与查询效率提升:随着数据不断写入 Paimon 的 LSM 树,Sorted Run 的数量会如雨后春笋般不断增加 。由于查询 LSM 树时需要将所有 Sorted Run 合并起来,过多的 Sorted Run 就像图书馆里过多的书架,会导致查询性能急剧下降,甚至可能引发内存不足的问题 。为了避免这种情况,就必须适时地将多个 Sorted Run 合并为一个大的 Sorted Run,这个合并过程就是 Compaction 。通过 Compaction,就像将多个小书架合并成一个大书架,减少了数据查询时的遍历范围,提高了查询效率 。
- 数据一致性与完整性维护:在数据的不断更新和写入过程中,可能会出现数据不一致或不完整的情况。Compaction 过程不仅可以合并小文件,还能对数据进行整理和校验 。它会去除重复的数据记录,清理已删除数据的残留标记(墓碑记录),确保数据的一致性和完整性 。这就好比定期对图书馆的书籍进行盘点和整理,去除重复的书籍,清理损坏或过期的书籍,使图书馆的藏书始终保持准确和完整 。
思考:Paimon Compaction 需要注意什么?
Compaction虽然会解决小问题的问题,但是合并本身会读取历史数据,消耗CPU和磁盘IO。
因此如果合并处理频繁、定时合并设置不合理会导致速度越来越慢,带来很大的资源消耗。如果有离线任务在读取当前表也会影响整体效率。因此在查询和写入之间要做一个衡量。
除此之外,未及时清理的历史版本是会占用大量存储空间,导致成本飙升。
Paimon也有对应的自定义配置能力:
- 写入聚合配置:配置 Write Buffer 阈值,累积至阈值后批量刷写 SSTable,通过调大阈值,减少小文件数量;
- 分离式合并:支持独立 Compaction 集群部署,与读写集群物理隔离,避免资源竞争;
- 版本过期配置:通过retention-time配置自动清理过期版本。
结语
Paimon 的核心竞争力在于对 LSM Tree 与数据湖特性的深度融合:既继承了 LSM 顺序写的高吞吐量优势,又通过湖格式的元数据管理实现了 ACID 事务与多引擎兼容。其 Compaction 机制的自动化设计(如主键表自动合并)大幅降低了运维成本,这也是其区别于 Hudi、Iceberg 的关键创新点。理解这些设计思路,不仅能掌握 Paimon 的优化精髓,更能触类旁通,在分布式存储系统设计中把握 "数据局部性"、"IO 效率 "、"一致性模型" 三大核心要素。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)