Transformer入门第一课:文本如何被转换成模型能理解的数据?
本文讲解了Transformer模型的输入处理机制,包括词嵌入和位置编码两个核心组件。首先介绍了传统方法(如One-Hot编码)的局限性,然后详细阐述了嵌入矩阵的构建过程,说明如何通过查找获取词嵌入。针对Transformer无法感知序列位置的问题,重点讲解了位置编码的计算公式和实现原理。文章还配以思维导图和结构图,清晰展现了输入处理在Transformer中的位置和作用。最后提供了大模型学习路线
0 前言
今天终于到了Transformer,这一步步其实也基本上是按照NLP的发展历程来演进的,那么就再为大家唠叨几句。
- RNN解决了CNN难以处理序列的问题,但是序列太长的话,距离远信息就丢了,记不住;
- LSTM在RNN的基础上改进,加入了好几个门控机制,使得有效信息得以保留,丢弃无效信息;即使后来的一系列衍生体,比如GRU、双向LSTM等,但是本质上还是RNN那套循环机制,无法并进行计算,换汤不换药;
- 一直到了Transformer,由《Attention is all you need》论文提出,是深度学习领域的里程碑,也是现代LLM(大语言模型)的基础。
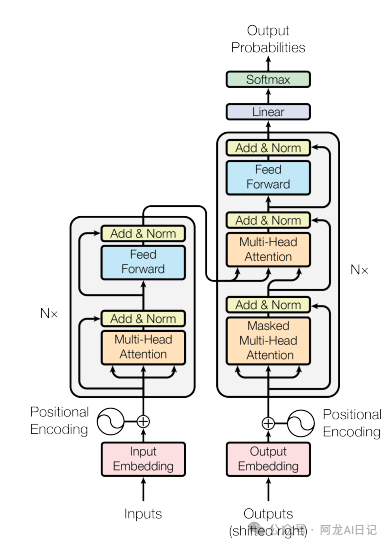
在基础架构上,Transformer彻底摈弃了之前的循环结构,并且引入了注意力机制,同时可以高度并行化计算,可以捕捉序列中任意两个位置词汇的关系,解决了远程依赖的问题。看一下Transformer的整体结构图:
1 思维导图
由于Transformer的内容非常多,想要一篇文章全部详细解释还是比较困难,因此我的打算分几篇文章为大家讲解这其中的玄机。
Transformer主要由编码器和解码器组成,而要了解编码器和解码器,我们只需要了解五个核心组件,而我们今天要了解的是输入处理:词嵌入与位置编码。
- 输入处理:词嵌入与位置编码
- 自注意力机制
- 多头注意力
- 前馈神经网络
- 残差连接与层归一化
思维导图如下,分成四个部分。大家都知道我们模型处理的数据一般是向量和矩阵,下面我们将一步步学习,文本究竟是怎么变成向量和矩阵的。
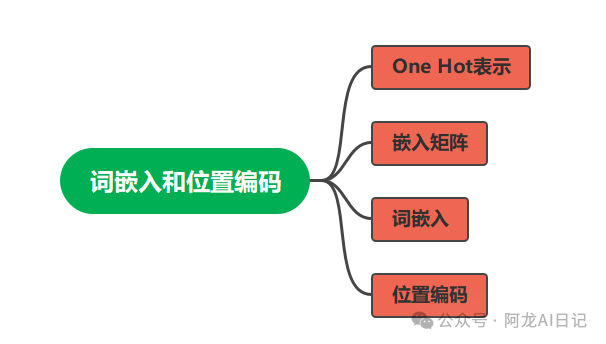
是随便找几个数填进去吗?
矩阵长和宽是多少呢?
什么时候是向量什么时候是矩阵呢?
为什么不用纯数字?
带着这些疑问跟我一起往下走。
2 One Hot
假设我们现在有一句话:我喜欢深度学习。
这句话我们把它按照词语划分成3个部分:
我 喜欢 深度学习
此时要把它转化为数据,一般人可能会想到什么呢?直接用1 2 3表示不就行了吗?
[我 喜欢 深度学习]——>[1 2 3]
完美,好了我们已经将文本转化为数据了,现在1仅仅就代表我,2就仅仅代表喜欢,3就仅仅代表深度学习,然后呢?无法表示其他的信息。
比方说我是主语,喜欢是谓语,深度学习是宾语;这句话是在表明一个喜好等等信息,这些信息根本没有办法只用一个数字来表示。况且我们网络里面的运算铺天盖地都是矩阵和向量的,很少说把某一个数拿来直接计算。
一个数字可表示浓缩的信息太少了,也不利于网络的计算。 有小伙伴继续想到了用矩阵来表示,
[我 喜欢 深度学习]——>[1 2 3]
那么我们可以转化为:
我: [1,0,0]
喜欢: [0,1,0]
深度学习:[0,0,1]
这样看起来是将一个词用向量表示了,几个词还好,但是如果我们有100000个单词呢?到时候我们的矩阵只有对角线是1,其余地方全部是0,这样太浪费计算资源了,而且可以表示的信息依然太少,还是得继续优化方案,既要能使用向量表示词语,还要尽可能多的表示信息。
我们的解决方案就是嵌入矩阵和词嵌入。
3 嵌入矩阵
有小伙伴进一步思考,既然单纯的0和1没有办法表示更多的信息,那我把这个矩阵的内容不止放0和1不就行了,这样就可以表示更多的信息。这就是我们的词嵌入。
假设我们现在有一万个单词,我们每个单词用一个向量来表示,这个向量的长度可以自己定义,比如我们定义成6。
这些向量一开始是随机的,可以随着训练更新,比如喜欢和爱两个词含义相近,一开始它们区别很大,但是随着训练越来越接近。
相当于我们有一个词汇表,表里面有单词,每个单词索引对应一个随机向量。
举个例子,我们的词汇表有7个词:
[我 喜欢 吃 苹果 也 爱 深度学习]
它们的索引是:
[1 2 3 4 5 6 7],
为每个词随机分配一个向量,每个向量长度(d_model)是6。
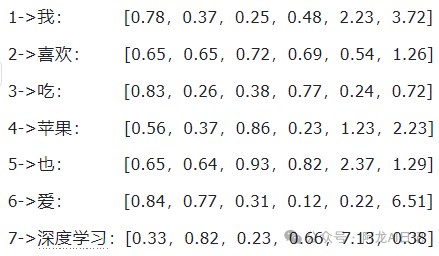
这个时候,我们就将上述向量组成的矩阵称为嵌入矩阵,这个矩阵是可以被训练学习的。
4 词嵌入
此时我们已经得到了嵌入矩阵,那么词嵌入又是什么呢?
通常情况下,我们的词汇表不止7个词,是成千上万的,但是我们的输入只是词汇表中的部分,比如我们要输入
[我 爱 深度学习]
我们从词汇表
[我 喜欢 吃 苹果 也 爱 深度学习]
依据三个词的索引1 6 7,从词嵌入矩阵中取出这几个词对应的词向量,此时组成的矩阵便是词嵌入。
嵌入矩阵:
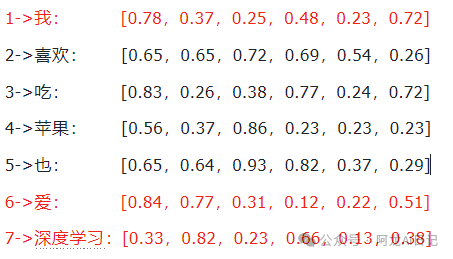
得到的词嵌入:
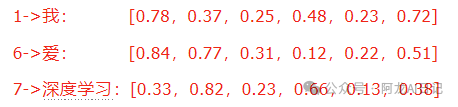
所以说我们平时说的词嵌入矩阵是一个全集,而词嵌入是嵌入矩阵的子集。
因此词嵌入的获取本质是一个查找过程:
- 1、我们首先构建一个词汇表,词汇表里的词有对应的索引;
- 2、为每个词汇对应生成一个词向量,词向量的维度(d_model)可以自己决定(一般是512),所有词向量组成一个矩阵就是嵌入矩阵;
- 3、我们依据部分词的索引,从嵌入矩阵中查找出对应的词向量,此时找出的词向量组成的矩阵就是词嵌入。
5 位置编码
通过以上部分,我们已经了解了如何将文本转化为词嵌入,但是由于 Transformer 没有循环和卷积结构,它本身无法感知词语的前后顺序。
因此,我们必须考虑如何将它的位置信息也注入到输入数据中。
我们采用的是位置编码,通过将词嵌入每一个位置计算出一个值,再与它相加,具体怎么操作呢?我们来举一个例子一看便知。 先给出位置编码的公式:
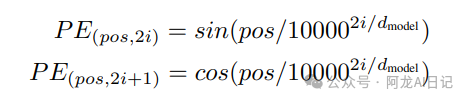
通过公式可以看到,每个位置的值计算方法是不同的,当i为偶数的时候,用的是sin函数;当i为奇数的时候,用的是cos函数,并且公式中有三个变量:pos、i以及dmodel。
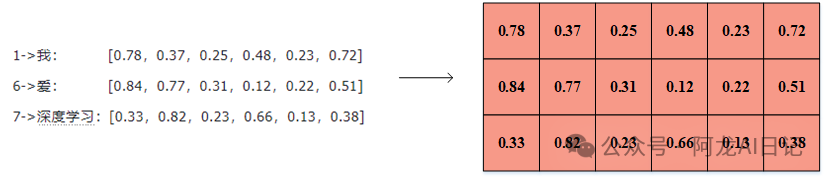
我们搞清楚了这三个变量分别是什么,就知道了PE位置编码的计算方法。 1、我们将刚才的三个向量转化为矩阵:
2、在这个图上标出pos和i以及dmodel:
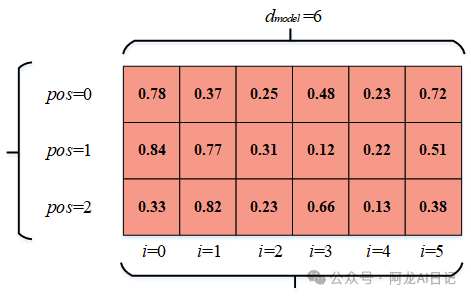
3、我们直接将每个位置的参数带入到上述公式中,就可以得到位置编码了:
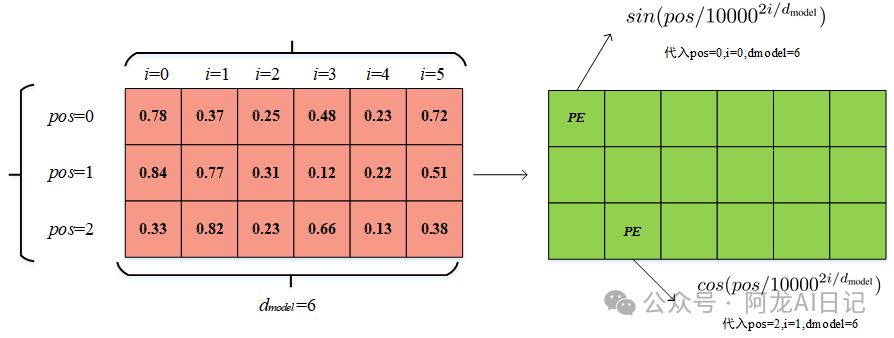
因此可以看出来pos其实就是每个词向量在词嵌入中的行坐标,i是列坐标,当然这么说挺不专业的,我们说:

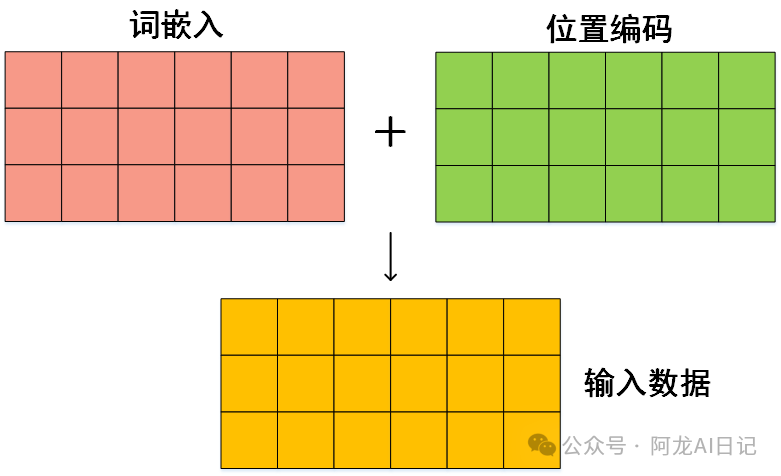
因此我们得到了位置编码和词嵌入,再将二者相加,就是transformer的输入了:
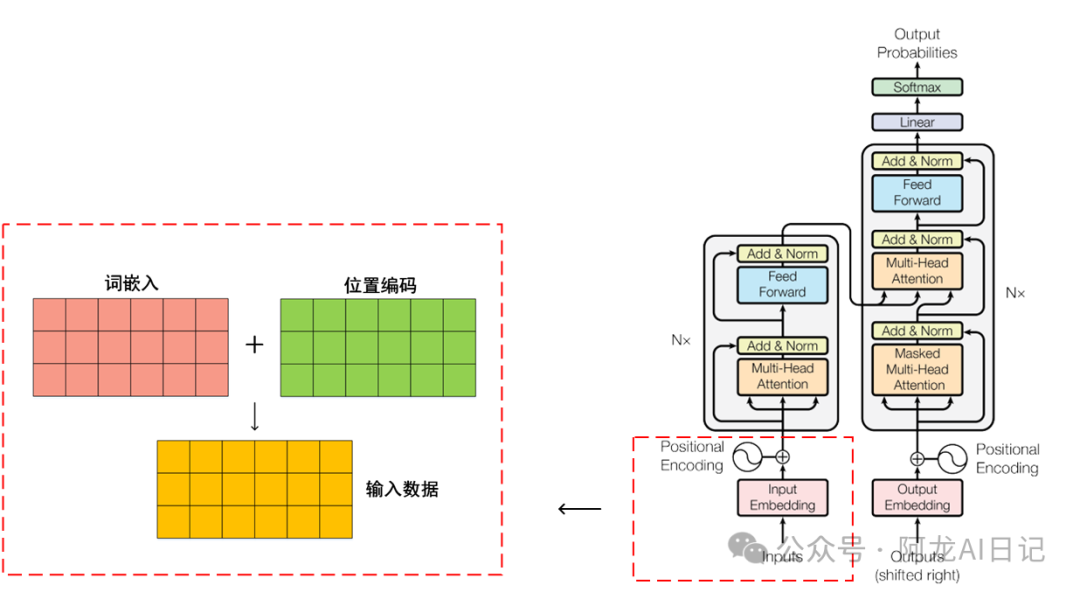
看看我们位于transformer的哪一部分:
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)