【Transformer】从零训练一个LLaMA2大模型(一)
本文介绍了如何从工程实践角度构建一个简化版的LLaMA2模型。首先概述了LLaMA2基于Transformer架构的总体设计,包括输入嵌入层、多层Transformer块(使用RMSNorm和SwiGLU激活函数)和旋转位置编码(RoPE)。然后详细讲解了各模块的实现:1)定义超参数管理类ModelConfig;2)实现RMSNorm归一化层;3)构建分组查询注意力机制(GQA)和旋转位置编码;4
从工程实践角度出发,动手实现一个简化版的 LLaMA 模型。
一、LLaMA2 的总体架构
LLaMA2 模型的核心依然是 Transformer 架构。Transformer 由 Google 在 2017 年提出,凭借“自注意力机制”(Self-Attention)彻底改变了自然语言处理的研究格局。它能让模型在理解一个词语时,同时关注到句子中其他所有词,从而捕捉更丰富的语义关系。
LLaMA2 在 Transformer 的基础上进行了多项改进,使其更适合大规模语言建模任务。其整体结构可以用下图表示:
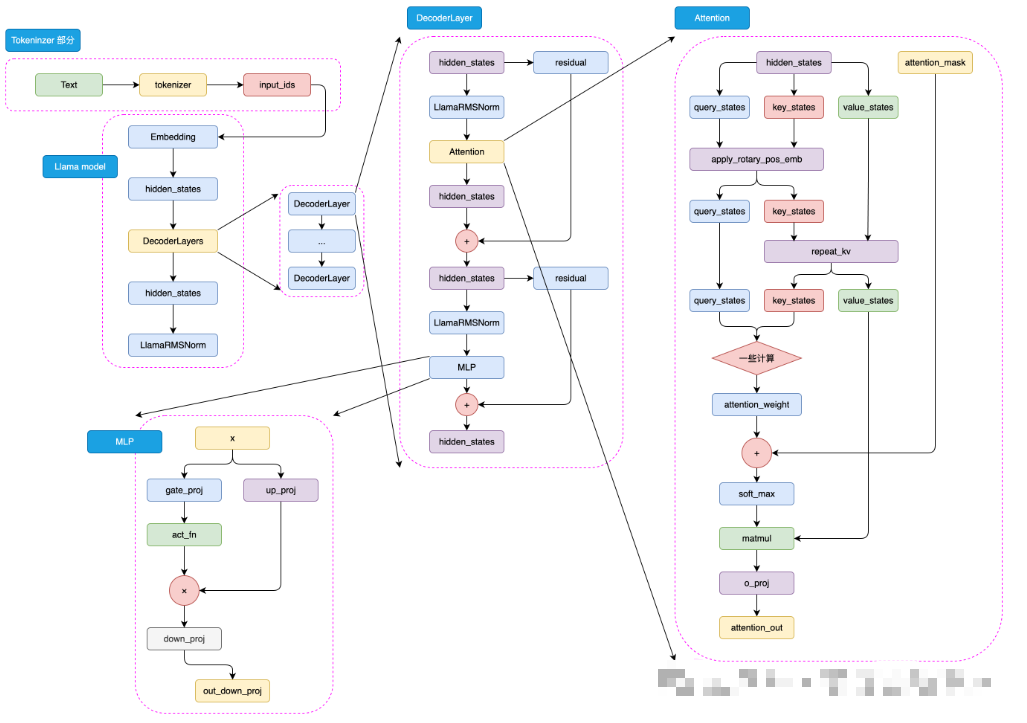
-
输入嵌入层(Embedding Layer)
将输入的词语(或子词)映射为向量表示,形成模型可处理的数值形式。 -
多层 Transformer 块(Transformer Blocks)
这是模型的核心部分,由多头自注意力层(Multi-Head Self-Attention)与前馈神经网络(Feed Forward Network, FFN)交替堆叠组成。LLaMA2 采用了 RMSNorm 替代传统的 LayerNorm,并使用 SwiGLU 激活函数来提升性能与稳定性。 -
旋转位置编码(Rotary Positional Embedding, RoPE)
为了让模型感知词序信息,LLaMA2 使用了 RoPE 技术,将位置信息直接嵌入到注意力计算中。这比传统的绝对位置编码更灵活,可支持更长的上下文窗口。 -
输出层(Output Layer)
将模型的隐藏状态映射回词汇表空间,用于生成下一个可能的词语。
在接下来的内容中,我们将:
-
构建一个简化的 Transformer 模型框架;
-
实现核心模块(自注意力机制、前馈层、位置编码等);
-
模拟小规模文本数据训练;
-
观察模型在语言生成任务中的表现。
通过这些步骤,你将更直观地理解:
-
Transformer 是如何捕捉语言规律的;
-
LLaMA2 如何优化训练与结构设计;
-
大语言模型的工作原理和实现思路。
1.1 定义超参数
在构建一个语言模型(比如 LLaMA2 或我们要实现的简化版模型)之前,第一步就是要确定模型的“基因”——也就是一系列的超参数(Hyperparameters)。
这些超参数相当于模型的“蓝图”,决定了模型的大小、深度、记忆能力以及计算复杂度。简单来说,模型能理解多少信息、学习多复杂的语言模式,往往就取决于这些超参数的配置。
常见的超参数包括:
-
dim(模型维度):每个词在模型内部的向量表示长度。维度越高,模型能捕捉到的语义信息越细致,但计算量也随之增加。
-
n_layers(层数):Transformer 的堆叠层数。层数越多,模型的“理解深度”越强,但训练难度和显存消耗也更大。
-
n_heads(注意力头数):多头注意力机制中的“头”的数量。每个头可以独立关注输入中的不同部分,帮助模型同时捕捉多种语义关系。
-
vocab_size(词汇表大小):模型能识别的词或子词的总数。
-
max_seq_len(最大序列长度):模型一次能处理的最大文本长度。超过这个长度的内容需要被截断或分段输入。
除了这些关键参数外,还有一些用于细化模型行为的配置,比如:
-
norm_eps:归一化时用来防止除零错误的微小常数;
-
dropout:一种防止模型过拟合的技术,训练时会随机丢弃部分神经元;
-
flash_attn:是否启用 Flash Attention,一种高效计算注意力的优化算法,可显著提升训练速度;
-
multiple_of:用于控制隐藏层维度与主维度的倍数关系,使矩阵计算更高效。
用一个类来管理超参数:ModelConfig
为了让模型的配置更清晰、更容易管理,我们可以把这些超参数封装到一个专门的类中。例如,下面这段代码定义了一个名为 ModelConfig 的配置类,用来保存模型的全部参数设定:
from transformers import PretrainedConfigclass ModelConfig(PretrainedConfig):model_type = "Tiny-K" # 模型名称,可自定义def __init__(self,dim: int = 768, # 模型维度n_layers: int = 12, # Transformer 层数n_heads: int = 16, # 注意力头数n_kv_heads: int = 8, # 键值头数量(多头注意力的一种优化)vocab_size: int = 6144, # 词汇表大小hidden_dim: int = None, # 隐藏层维度multiple_of: int = 64,norm_eps: float = 1e-5, # 归一化层中的 epsilonmax_seq_len: int = 512, # 最大输入序列长度dropout: float = 0.0, # dropout 概率flash_attn: bool = True, # 是否使用 Flash Attention**kwargs,):self.dim = dimself.n_layers = n_layersself.n_heads = n_headsself.n_kv_heads = n_kv_headsself.vocab_size = vocab_sizeself.hidden_dim = hidden_dimself.multiple_of = multiple_ofself.norm_eps = norm_epsself.max_seq_len = max_seq_lenself.dropout = dropoutself.flash_attn = flash_attnsuper().__init__(**kwargs)
这个类继承自 transformers 库中的 PretrainedConfig。
这么做有两个好处:
-
它让我们可以无缝使用 Hugging Face Transformers 提供的训练、加载、导出工具;
-
当我们想要保存或分享模型时,只需保存这个配置文件,就能完整记录模型的结构信息。
换句话说,ModelConfig 就像模型的“身份证”,它描述了模型的结构参数,让我们在不同环境中都能轻松地重现模型。
1.2 构建归一化层:RMSNormm
在大型语言模型中,归一化层(Normalization Layer) 是一个非常关键的组件。它的作用就像是“模型的体温调节器”,可以让不同层之间的数据保持在合适的数值范围,避免训练过程中出现“梯度爆炸”或“梯度消失”的问题。
在早期的 Transformer 架构中,通常使用的是 LayerNorm(层归一化)。但在 LLaMA 系列中,Meta 团队引入了一种计算更高效、效果更稳定的替代方案 —— RMSNorm(Root Mean Square Normalization)。
什么是 RMSNorm?
顾名思义,RMSNorm 是通过“均方根”(Root Mean Square, RMS)来实现归一化的。
它的核心思想是:
不去减掉均值,只对输入向量的平方和进行归一化,从而保持模型数值的平衡。
其数学表达式如下:
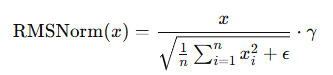

与 LayerNorm 相比,RMSNorm 不需要计算均值,因此计算量更小、速度更快,而且在深层模型中表现更稳定。
在像 LLaMA 这样的超深网络中,模型层数通常达到数十层甚至上百层。
如果每一层的输出尺度波动过大,会导致训练不稳定。
RMSNorm 通过“平方求平均再开根号”的方式控制输出的幅度,使得模型层与层之间的信号更加平稳,提升了训练的稳定性和收敛速度。
实现一个 RMSNorm 模块
我们可以用 PyTorch 来轻松实现 RMSNorm。以下代码定义了一个简洁的 RMSNorm 类:
import torchimport torch.nn as nnclass RMSNorm(nn.Module):def __init__(self, dim: int, eps: float):super().__init__()# eps 用于防止除以 0 的情况self.eps = eps# weight 是一个可学习的参数,初始值为 1self.weight = nn.Parameter(torch.ones(dim))def _norm(self, x):# RMSNorm 的核心计算# 1. 对输入 x 的平方取平均(按最后一个维度)# 2. 加上 eps 后求倒数平方根# 3. 与原始 x 相乘,完成归一化return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, x):# 前向传播:执行归一化并应用可学习权重output = self._norm(x.float()).type_as(x)return output * self.weight
代码中的 torch.rsqrt() 表示对输入取平方根的倒数,这是 RMSNorm 的关键操作。
整个过程可以理解为:“让每个输入向量的长度变得相似,但方向保持不变”。
测试我们的 RMSNorm 模块
我们可以通过下面的简单代码来验证 RMSNorm 的正确性:
norm = RMSNorm(args.dim, args.norm_eps)x = torch.randn(1, 50, args.dim) # 模拟输入:batch=1,序列长度=50,维度=768output = norm(x)print(output.shape)
输出结果为:
torch.Size([1, 50, 768])可以看到,输出的形状与输入完全一致,这说明 RMSNorm 只是对数值进行了归一化处理,而不会改变输入的结构或维度。
这也是归一化层的重要特征——它只调整“尺度”,不改变“形状”。
1.3 构建 LLaMA2 的注意力机制(Attention)
在 Transformer 模型中,注意力机制(Attention) 是最核心的模块之一。它决定了模型如何“关注”输入序列中的不同位置,从而理解上下文关系。
可以说,如果没有注意力机制,就没有今天的大语言模型。
LLaMA2 使用的是一种名为 多头自注意力机制(Multi-Head Self-Attention) 的结构。它允许模型同时从多个“角度”去观察同一句话,就像一个团队中不同的专家分别关注句子的语法、语义和上下文逻辑,然后再将结果整合起来。
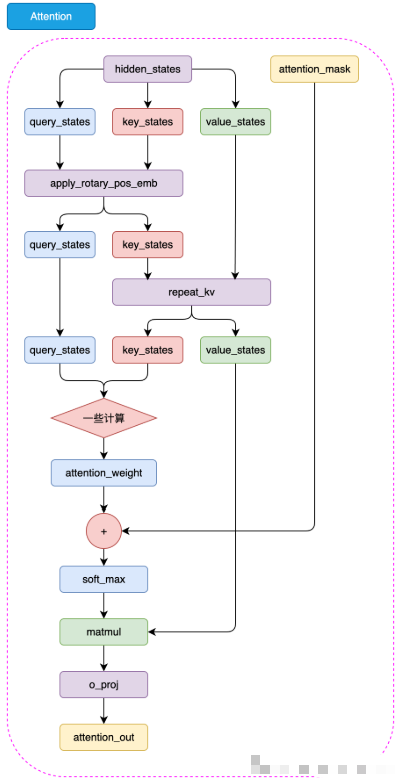
从普通注意力到分组查询注意力(GQA)
在传统的多头注意力(Multi-Head Attention)中,每一个注意力“头”(head)都会独立地计算三种矩阵:
-
查询矩阵(Query, Q)
-
键矩阵(Key, K)
-
值矩阵(Value, V)
这种方式虽然功能强大,但在模型规模很大时(例如 LLaMA2-70B),计算和显存开销会变得极其庞大。
为了解决这一问题,Meta 在 LLaMA2 的高配版本中引入了 分组查询注意力(Grouped-Query Attention, GQA)。
GQA 的思想非常简单:
不是每个查询头都要拥有独立的键(K)和值(V),而是让多个查询头共享同一组 K 和 V,从而减少重复计算。
这样一来:
-
模型的显存占用减少;
-
注意力计算的速度提升;
-
而且几乎不会影响最终性能。
因此,在我们的 LLaMA2 模块中,即使不是大规模模型,也选择实现 GQA —— 因为它更高效、更现代。
(1)键值共享的核心操作:repeat_kv
在 GQA 中,查询头(Q)的数量通常大于键值头(K/V)的数量。
为了让它们在计算时维度一致,我们需要“复制”键和值的张量,让它们的形状与查询匹配。
这就是 repeat_kv 函数要做的事情。
下面是它的实现代码:
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:# 获取输入张量的形状bs, slen, n_kv_heads, head_dim = x.shape# 如果只需要一个副本,直接返回if n_rep == 1:return x# 否则,对 K/V 进行扩展和重塑return (x[:, :, :, None, :] # 在头维度前增加一个新维度.expand(bs, slen, n_kv_heads, n_rep, head_dim) # 扩展到 n_rep 次.reshape(bs, slen, n_kv_heads * n_rep, head_dim) # 合并维度,形状匹配查询头数)
我们来理解一下这段代码
假设我们有一个键(K)张量,它的形状是:
[batch_size, seq_len, n_kv_heads, head_dim]例如:[2, 100, 8, 64]
而查询(Q)张量有 16 个头(n_heads=16),那就意味着每个键需要被复制 n_rep = n_heads / n_kv_heads = 2 次,这样才能一一对应。
函数的执行过程如下:
-
检查是否需要复制
如果n_rep=1,直接返回输入,节省计算。 -
添加新维度
通过x[:, :, :, None, :],在原本的头部维度后面加一个新维度,方便后续扩展。 -
扩展维度实现复制
使用.expand()方法,把每个键值头“复制”成多个副本,让不同的查询头可以共用这些键值。 -
合并维度回原结构
用.reshape()把扩展后的维度合并,最终得到新的张量形状:
[batch_size, seq_len, n_heads, head_dim]这就与查询矩阵的形状完美对齐,可以继续进行注意力计算。
为什么这一步很重要?
这一步虽然看起来只是“复制张量”,但它实际上是 分组查询注意力(GQA) 能高效运行的关键所在。
通过这种方式:
-
模型不需要为每个查询头独立计算键值;
-
大幅减少显存占用;
-
提升了推理和训练速度。
这也是 LLaMA2 在设计上非常“工程化”的体现之一:
在保持高性能的同时,通过结构优化来降低计算资源的消耗。
(2)旋转嵌入(RoPE)
在 LLaMA2 模型中,有一个关键的小技巧叫做 旋转嵌入(Rotary Embedding,简称 RoPE)。
它的作用是让模型“理解”序列中不同单词之间的相对位置关系,从而让注意力机制在处理上下文时更聪明。
相比传统的“位置编码”只是简单地把位置信息加到词向量上,
旋转嵌入则更精妙——它通过对向量进行“旋转变换”,把位置信息藏进了 Query 和 Key 向量的角度变化中。
换句话说,每个 token 的位置不再用数字表示,而是体现在向量的“旋转方向”上。
⚙️ 第一步:计算旋转角度
我们先定义一个函数,用来预先计算每个位置需要旋转的角度。
在代码中,这一步由 precompute_freqs_cis() 完成:
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))t = torch.arange(end, device=freqs.device)freqs = torch.outer(t, freqs).float()freqs_cos = torch.cos(freqs)freqs_sin = torch.sin(freqs)return freqs_cos, freqs_sin
我们一步步拆解来看:
-
生成频率序列(freqs)
模型会为每个注意力头生成一组不同的“频率”,就像不同音调的波动一样。
这些频率决定了每个维度在旋转时的角速度。 -
生成位置序列(t)
用torch.arange(end)生成从 0 到序列长度的编号(即每个 token 的位置)。 -
计算角度矩阵
通过外积(outer product)计算出“每个位置 × 每个频率”对应的旋转角度。 -
求出正弦和余弦
把这些角度分别取sin和cos,得到旋转的“实部”和“虚部”。
后续我们会用它们来构造旋转矩阵。
最终输出的两个矩阵:
-
freqs_cos:旋转角度的余弦部分(实部) -
freqs_sin:旋转角度的正弦部分(虚部
🧩 第二步:对齐张量形状(为广播做准备)
在矩阵运算中,不同张量的形状必须能“对齐”才能做加减乘除。
为此,我们写一个小工具函数 reshape_for_broadcast():
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):ndim = x.ndimassert freqs_cis.shape == (x.shape[1], x.shape[-1])shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]return freqs_cis.view(shape)
这个函数的作用是:
把 freqs_cos 和 freqs_sin 调整成与输入张量 x 能自动广播匹配的形状。
这样在后续运算时,不需要显式复制数据,就能让每个 token 使用对应的旋转角度。
🔄 第三步:应用旋转嵌入
接下来是关键一步:真正把旋转嵌入应用到 Query(xq)和 Key(xk)向量上。
def apply_rotary_emb(xq, xk, freqs_cos, freqs_sin):xq_r, xq_i = xq.float().reshape(xq.shape[:-1] + (-1, 2)).unbind(-1)xk_r, xk_i = xk.float().reshape(xk.shape[:-1] + (-1, 2)).unbind(-1)freqs_cos = reshape_for_broadcast(freqs_cos, xq_r)freqs_sin = reshape_for_broadcast(freqs_sin, xq_r)xq_out_r = xq_r * freqs_cos - xq_i * freqs_sinxq_out_i = xq_r * freqs_sin + xq_i * freqs_cosxk_out_r = xk_r * freqs_cos - xk_i * freqs_sinxk_out_i = xk_r * freqs_sin + xk_i * freqs_cosxq_out = torch.stack([xq_out_r, xq_out_i], dim=-1).flatten(3)xk_out = torch.stack([xk_out_r, xk_out_i], dim=-1).flatten(3)return xq_out.type_as(xq), xk_out.type_as(xk)
💡 理解这段代码的关键是:
每个二维向量 (x_r, x_i) 都会被旋转一个角度 θ。
数学上等价于二维旋转矩阵:
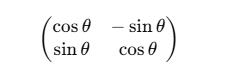
通过这种旋转,模型自然地学会了“第 5 个词”和“第 6 个词”之间的相对位置信息。
🧪 第四步:测试旋转嵌入
下面我们来实际验证一下:
xq = torch.randn(1, 50, 6, 48) # batch_size, seq_len, n_head, head_dimxk = torch.randn(1, 50, 6, 48)cos, sin = precompute_freqs_cis(288//6, 50)print(cos.shape, sin.shape)xq_out, xk_out = apply_rotary_emb(xq, xk, cos, sin)print(xq_out.shape, xk_out.shape)
输出结果:
torch.Size([50, 24]) torch.Size([50, 24])
(torch.Size([1, 50, 6, 48]), torch.Size([1, 50, 6, 48]))
这表明旋转嵌入成功应用,形状保持一致。
(3)组装 LLaMA2 Attention
在上面我们已经完成了GQA和旋转嵌入的实现,接下来我们就可以构建 LLaMA2 Attention 模块了。
class Attention(nn.Module):def __init__(self, args: ModelConfig):super().__init__()# 根据是否指定n_kv_heads,确定用于键(key)和值(value)的头的数量。self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads# 确保总头数可以被键值头数整除。assert args.n_heads % self.n_kv_heads == 0# 模型并行处理大小,默认为1。model_parallel_size = 1# 本地计算头数,等于总头数除以模型并行处理大小。self.n_local_heads = args.n_heads // model_parallel_size# 本地键值头数,等于键值头数除以模型并行处理大小。self.n_local_kv_heads = self.n_kv_heads // model_parallel_size# 重复次数,用于扩展键和值的尺寸。self.n_rep = self.n_local_heads // self.n_local_kv_heads# 每个头的维度,等于模型维度除以头的总数。self.head_dim = args.dim // args.n_heads# 定义权重矩阵。self.wq = nn.Linear(args.dim, args.n_heads * self.head_dim, bias=False)self.wk = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)self.wv = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)# 输出权重矩阵。self.wo = nn.Linear(args.n_heads * self.head_dim, args.dim, bias=False)# 定义dropout。self.attn_dropout = nn.Dropout(args.dropout)self.resid_dropout = nn.Dropout(args.dropout)# 保存dropout概率。self.dropout = args.dropout# 检查是否使用Flash Attention(需要PyTorch >= 2.0)。self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')if not self.flash:# 若不支持Flash Attention,则使用手动实现的注意力机制,并设置mask。print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")# 创建一个上三角矩阵,用于遮蔽未来信息。mask = torch.full((1, 1, args.max_seq_len, args.max_seq_len), float("-inf"))mask = torch.triu(mask, diagonal=1)# 注册为模型的缓冲区self.register_buffer("mask", mask)def forward(self, x: torch.Tensor, freqs_cos: torch.Tensor, freqs_sin: torch.Tensor):# 获取批次大小和序列长度,[batch_size, seq_len, dim]bsz, seqlen, _ = x.shape# 计算查询(Q)、键(K)、值(V)。xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)# 调整形状以适应头的维度。xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)# 应用旋转位置嵌入(RoPE)。xq, xk = apply_rotary_emb(xq, xk, freqs_cos, freqs_sin)# 对键和值进行扩展以适应重复次数。xk = repeat_kv(xk, self.n_rep)xv = repeat_kv(xv, self.n_rep)# 将头作为批次维度处理。xq = xq.transpose(1, 2)xk = xk.transpose(1, 2)xv = xv.transpose(1, 2)# 根据是否支持Flash Attention,选择实现方式。if self.flash:# 使用Flash Attention。output = torch.nn.functional.scaled_dot_product_attention(xq, xk, xv, attn_mask=None, dropout_p=self.dropout if self.training else 0.0, is_causal=True)else:# 使用手动实现的注意力机制。scores = torch.matmul(xq, xk.transpose(2, 3)) / math.sqrt(self.head_dim)assert hasattr(self, 'mask')scores = scores + self.mask[:, :, :seqlen, :seqlen]scores = F.softmax(scores.float(), dim=-1).type_as(xq)scores = self.attn_dropout(scores)output = torch.matmul(scores, xv)# 恢复时间维度并合并头。output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)# 最终投影回残差流。output = self.wo(output)output = self.resid_dropout(output)return output
同样大家可以使用下面的代码来对注意力模块进行测试,可以看到代码最终输出的形状为torch.Size([1, 50, 768]),与我们输入的形状一致,说明模块的实现是正确的。
# 创建Attention实例attention_model = Attention(args)# 模拟输入数据batch_size = 1seq_len = 50 # 假设实际使用的序列长度为50dim = args.dimx = torch.rand(batch_size, seq_len, dim) # 随机生成输入张量# freqs_cos = torch.rand(seq_len, dim // 2) # 模拟cos频率,用于RoPE# freqs_sin = torch.rand(seq_len, dim // 2) # 模拟sin频率,用于RoPEfreqs_cos, freqs_sin = precompute_freqs_cis(dim//args.n_heads, seq_len)# 运行Attention模型output = attention_model(x, freqs_cos, freqs_sin)# attention出来之后的形状 依然是[batch_size, seq_len, dim]print("Output shape:", output.shape)
前向传播:Attention 的计算流程
在 forward() 中,流程如下:
1️⃣ 输入形状
输入 x 的形状是 [batch_size, seq_len, dim]。
比如 [1, 50, 768] 表示:一条长度 50 的句子,每个词有 768 个特征。
2️⃣ 生成 Q、K、V 向量
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
每个词都会生成三个向量:
-
Q:想要“询问”的内容
-
K:用来“被匹配”的内容
-
V:携带的信息内容
3️⃣ 加入旋转位置编码(RoPE)
xq, xk = apply_rotary_emb(xq, xk, freqs_cos, freqs_sin)
RoPE 让模型拥有位置信息,但又不依赖固定的索引编码方式。
这使得模型在长文本推理时更稳定。
4️⃣ 计算注意力
如果支持 Flash Attention:
output = F.scaled_dot_product_attention(xq, xk, xv, is_causal=True)否则手动计算:
scores = (xq @ xk.transpose(2, 3)) / sqrt(self.head_dim)scores = softmax(scores)output = scores @ xv
这一步的本质是:
“查询 Q” 去“匹配”所有“键 K”,根据匹配程度从“值 V”中提取加权信息。5️⃣ 合并多头结果
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)output = self.wo(output)
最终输出的形状和输入保持一致 [batch_size, seq_len, dim]
,只是内容已经是经过注意力机制加权后的结果。
1.4 构建 LLaMA2 MLP模块
相较于前面实现的 LLaMA2 Attention(注意力)模块,LLaMA2 的 MLP 模块(即前馈网络)要简单得多。它主要负责对每个位置的向量进行非线性变换,从而增强模型的表达能力。
在代码中,我们可以这样实现一个简化版的 MLP:
class MLP(nn.Module):def __init__(self, dim: int, hidden_dim: int, multiple_of: int, dropout: float):super().__init__()# 如果没有指定隐藏层大小,则默认按照 LLaMA2 的经验规则计算# 先将输入维度扩大 4 倍,再缩小为原来的 2/3,# 最后确保隐藏层维度是 multiple_of 的倍数,以便高效计算if hidden_dim is None:hidden_dim = 4 * dimhidden_dim = int(2 * hidden_dim / 3)hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)# 定义三层线性变换self.w1 = nn.Linear(dim, hidden_dim, bias=False)self.w2 = nn.Linear(hidden_dim, dim, bias=False)self.w3 = nn.Linear(dim, hidden_dim, bias=False)# dropout用于防止过拟合self.dropout = nn.Dropout(dropout)def forward(self, x):# 前向传播逻辑:# 1. 先将输入 x 通过 w1,并使用 SiLU 激活函数;# 2. 然后与另一条支路(x 经过 w3 的线性变换)相乘;# 3. 最后通过 w2 和 dropout 输出结果。return self.dropout(self.w2(F.silu(self.w1(x)) * self.w3(x)))
这段代码的核心思想是:
MLP 不仅仅是简单的“线性 + 激活”组合,而是通过两条路径(w1 和 w3)对输入进行不同的线性变换,再将结果相乘后映射回原维度。这种结构能够更好地捕捉特征之间的非线性关系,是 LLaMA2 的关键设计之一。
接下来,我们可以简单验证模块是否工作正常:
# 创建一个 MLP 实例mlp = MLP(args.dim, args.hidden_dim, args.multiple_of, args.dropout)# 随机生成输入数据,形状为 [batch=1, seq_len=50, dim=768]x = torch.randn(1, 50, args.dim)# 运行 MLP 模块output = mlp(x)print(output.shape)
输出结果为:
torch.Size([1, 50, 768])
可以看到,输出的形状与输入完全一致,说明 MLP 模块的实现逻辑是正确的。
在 LLaMA2 的完整结构中,这个 MLP 通常与注意力模块交替堆叠,形成强大的 Transformer 块,从而赋予模型理解和生成自然语言的能力。
1.5 构建Decoder Layer
在完成了 LLaMA2 的 Attention 模块 和 MLP 模块 之后,我们终于可以组装出它的核心结构——Decoder Layer(解码层)。
在 LLaMA2 中,每一层 Decoder 都由这两个模块交替组成,它是模型进行语言理解和生成的基本单元。
🧩 Decoder Layer 的结构组成
class DecoderLayer(nn.Module):def __init__(self, layer_id: int, args: ModelConfig):super().__init__()# 定义多头注意力的头数self.n_heads = args.n_heads# 输入向量的维度self.dim = args.dim# 每个注意力头的维度self.head_dim = args.dim // args.n_heads# 多头注意力模块(前面实现的 Attention)self.attention = Attention(args)# 前馈神经网络模块(前面实现的 MLP)self.feed_forward = MLP(dim=args.dim,hidden_dim=args.hidden_dim,multiple_of=args.multiple_of,dropout=args.dropout,)# 层编号(主要用于调试或分层控制)self.layer_id = layer_id# 注意力模块前的归一化层self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)# MLP 模块前的归一化层self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)def forward(self, x, freqs_cos, freqs_sin):# 1️⃣ 先对输入进行归一化,然后送入注意力模块# 注意力输出与原始输入相加,形成残差连接h = x + self.attention.forward(self.attention_norm(x), freqs_cos, freqs_sin)# 2️⃣ 将结果送入前馈网络(MLP),同样做残差连接out = h + self.feed_forward.forward(self.ffn_norm(h))# 返回输出结果return out
🔍 结构解析
整个 Decoder Layer 的运作流程可以分为两步:
-
自注意力层(Self-Attention Block)
-
输入先经过归一化(
attention_norm),再进入多头注意力模块。 -
输出结果与原输入相加,形成 残差连接(residual connection)。
-
这样做的目的是让模型在学习新特征的同时,保留原始信息,避免梯度消失。
-
-
前馈层(Feed Forward Block)
-
上一步的输出再经过第二个归一化层(
ffn_norm)并送入 MLP 模块。 -
同样,结果与输入相加形成新的残差结构。
-
这一部分负责非线性映射,让模型能捕捉更复杂的模式。
-
这种「归一化 → 子层计算 → 残差连接」的模式,是 Transformer 结构的标准模板,也是 LLaMA2 训练稳定、高效的关键。
🧪 测试 Decoder Layer
下面我们用一段代码来验证实现是否正确:
# 创建 LLaMA DecoderLayer 实例decoderlayer = DecoderLayer(0, args)# 模拟输入数据dim = args.dimseq_len = 50x = torch.randn(1, seq_len, dim) # [batch_size, seq_len, dim]# 生成旋转位置编码所需参数freqs_cos, freqs_sin = precompute_freqs_cis(dim // args.n_heads, seq_len)# 运行 Decoder Layerout = decoderlayer(x, freqs_cos, freqs_sin)# 查看输出形状print(out.shape)
输出结果为:
torch.Size([1, 50, 768])
可以看到,输出的形状与输入完全一致,说明我们的 Decoder Layer 实现是正确的。
1.6 构建完整 LLaMA2 模型
好了,我们已经完了上述所有的模块的实现,接下来就是激动人心的时刻,我们可以构建LLaMA2模型了,LLaMA2模型就是将DecoderLayer模块堆叠起来,构成一个完整的Transformer模型。
class Transformer(PreTrainedModel):config_class = ModelConfig # 配置类last_loss: Optional[torch.Tensor] # 记录最后一次计算的损失def __init__(self, args: ModelConfig = None):super().__init__(args)# 初始化模型参数self.args = args# 词汇表大小self.vocab_size = args.vocab_size# 层数self.n_layers = args.n_layers# 词嵌入层self.tok_embeddings = nn.Embedding(args.vocab_size, args.dim)# Dropout层self.dropout = nn.Dropout(args.dropout)# Decoder层self.layers = torch.nn.ModuleList()for layer_id in range(args.n_layers):self.layers.append(DecoderLayer(layer_id, args))# 归一化层self.norm = RMSNorm(args.dim, eps=args.norm_eps)# 输出层self.output = nn.Linear(args.dim, args.vocab_size, bias=False)# 将词嵌入层的权重与输出层的权重共享self.tok_embeddings.weight = self.output.weight# 预计算相对位置嵌入的频率freqs_cos, freqs_sin = precompute_freqs_cis(self.args.dim // self.args.n_heads, self.args.max_seq_len)self.register_buffer("freqs_cos", freqs_cos, persistent=False)self.register_buffer("freqs_sin", freqs_sin, persistent=False)# 初始化所有权重self.apply(self._init_weights)# 对残差投影进行特殊的缩放初始化for pn, p in self.named_parameters():if pn.endswith('w3.weight') or pn.endswith('wo.weight'):torch.nn.init.normal_(p, mean=0.0, std=0.02/math.sqrt(2 * args.n_layers))# 初始化最后一次前向传播的损失属性self.last_loss = Noneself.OUT = CausalLMOutputWithPast() # 输出容器self._no_split_modules = [name for name, _ in self.named_modules()] # 不分割的模块列表def _init_weights(self, module):# 初始化权重的函数if isinstance(module, nn.Linear):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)if module.bias is not None:torch.nn.init.zeros_(module.bias)elif isinstance(module, nn.Embedding):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)def forward(self, tokens: torch.Tensor, targets: Optional[torch.Tensor] = None, **kwargs) -> torch.Tensor:"""- tokens: Optional[torch.Tensor], 输入 token 张量。- targets: Optional[torch.Tensor], 目标 token 张量。- kv_cache: bool, 是否使用键值缓存。- kwargs: 其他关键字参数。- self.OUT: CausalLMOutputWithPast, 包含 logits 和损失。"""if 'input_ids' in kwargs:tokens = kwargs['input_ids']if 'attention_mask' in kwargs:targets = kwargs['attention_mask']# 前向传播函数_bsz, seqlen = tokens.shape# 通过词嵌入层和Dropout层h = self.tok_embeddings(tokens)h = self.dropout(h)# 获取相对位置嵌入的频率freqs_cos = self.freqs_cos[:seqlen]freqs_sin = self.freqs_sin[:seqlen]# 通过Decoder层for layer in self.layers:h = layer(h, freqs_cos, freqs_sin)# 通过归一化层h = self.norm(h)if targets is not None:# 如果给定了目标,计算损失logits = self.output(h)self.last_loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=0, reduction='none')else:# 推理时的小优化:只对最后一个位置的输出进行前向传播logits = self.output(h[:, [-1], :])self.last_loss = None# 设置输出self.OUT.__setitem__('logits', logits)self.OUT.__setitem__('last_loss', self.last_loss)return self.OUT@torch.inference_mode()def generate(self, idx, stop_id=None, max_new_tokens=256, temperature=1.0, top_k=None):"""给定输入序列 idx(形状为 (bz,seq_len) 的长整型张量),通过多次生成新 token 来完成序列。在 model.eval() 模式下运行。效率较低的采样版本,没有使用键k/v cache。"""index = idx.shape[1]for _ in range(max_new_tokens):# 如果序列上下文过长,截断它到最大长度idx_cond = idx if idx.size(1) <= self.args.max_seq_len else idx[:, -self.args.max_seq_len:]# 前向传播获取序列中最后一个位置的 logitslogits = self(idx_cond).logitslogits = logits[:, -1, :] # 只保留最后一个时间步的输出if temperature == 0.0:# 选择最有可能的索引_, idx_next = torch.topk(logits, k=1, dim=-1)else:# 缩放 logits 并应用 softmaxlogits = logits / temperatureif top_k is not None:v, _ = torch.topk(logits, min(top_k, logits.size(-1)))logits[logits < v[:, [-1]]] = -float('Inf')probs = F.softmax(logits, dim=-1)idx_next = torch.multinomial(probs, num_samples=1)if idx_next == stop_id:break# 将采样的索引添加到序列中并继续idx = torch.cat((idx, idx_next), dim=1)return idx[:, index:] # 只返回生成的token
同样大家可以使用下面的代码来对Transformer模块进行测试,可以看到代码最终输出的形状为torch.Size([1, 1, 6144]),与我们输入的形状一致,说明模块的实现是正确的。
# LLaMA2Model.forward 接受两个参数,tokens和targets,其中tokens是输入的张量, 应为int类型x = torch.randint(0, 6144, (1, 50)) # [bs, seq_len]# 实例化LLaMA2Modelmodel = Transformer(args=args)# 计算model的全部参数num_params = sum(p.numel() for p in model.parameters())print('Number of parameters:', num_params)out = model(x)print(out.logits.shape) # [batch_size, 1, vocab_size]
Number of parameters: 82594560
torch.Size([1, 1, 6144])篇幅所限,本篇只讲述了构建小型LLaMA 2模型架构和代码,后面一篇将介绍如何进行训练。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)