hello-agents第三章笔记
🔗教程链接https://datawhalechina.github.io/hello-agents/#/
·
🔗教程链接https://datawhalechina.github.io/hello-agents/#/
3.1 语言模型与Transformer架构
3.1.1 从N-gram到RNN
基础概念:
- 语言模型(LM):计算句子概率的模型,目标是生成通顺自然的文本。
- 演进逻辑与驱动力:
- N-gram模型:解决了纯统计方法的计算难题,但引入了固定窗口和数据稀疏的局限。
- 神经网络语言模型:引入词嵌入,解决了N-gram的泛化能力差问题,但仍有固定窗口限制。
- RNN/LSTM:引入循环结构,解决了可变长度序列问题,但串行计算导致效率低下,且存在梯度消失/爆炸问题。
- Transformer:完全基于注意力机制,一举解决了并行计算和长距离依赖两大核心瓶颈,成为现代LLM的奠基性架构。
3.1.2 Transformer架构解析
基础概念:
- 核心创新:完全基于注意力机制,抛弃循环结构,实现并行计算。
- Encoder-Decoder结构:
- Encoder:理解输入序列,生成上下文向量。
- Decoder:参考Encoder输出和已生成内容,自回归生成目标序列。
- 自注意力(Self-Attention):
- 为每个词生成Q(查询)、K(键)、V(值)向量,通过点积计算词间关联权重。
- 公式:Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dkQKT)V。
- 多头注意力:多个注意力头并行捕捉不同维度的依赖关系(如语法、语义)。
- 位置编码(Positional Encoding):
- 使用正弦/余弦函数为词嵌入添加位置信息,解决Transformer无顺序感知的问题。
- 公式:PE(pos,2i)=sin(pos/100002i/dmodel)PE_{(pos,2i)} = \sin(pos/10000^{2i/d_{\text{model}}})PE(pos,2i)=sin(pos/100002i/dmodel)。
- 残差连接与层归一化:
- 残差连接:缓解梯度消失,公式为 Output=x+Sublayer(x)\text{Output} = x + \text{Sublayer}(x)Output=x+Sublayer(x)。
- 层归一化:稳定训练,加速收敛。
关键原理:
- 注意力机制允许模型动态聚焦于不同位置的词,优于固定窗口的RNN。
- 并行化使Transformer适合大规模预训练,成为现代LLM基石。
学习提示(坑):
- 位置编码是必须的,否则Transformer无法区分序列顺序。
- 解码器在训练时使用掩码,防止“偷看”未来信息。
3.1.3 Decoder-Only架构
基础概念:
- 代表模型:GPT系列,仅保留解码器,专注于自回归生成(预测下一个词)。
- 掩码自注意力:在注意力分数矩阵中,将未来位置掩码为负无穷,确保生成时仅依赖历史信息。
- 优势:
- 训练目标统一(预测下一个词),易于扩展。
- 结构简单,适合生成任务(如对话、写作)。
关键原理:
- Decoder-Only架构将语言模型简化为序列生成问题,与智能体的生成式任务高度契合。
学习提示(坑):
- 掩码机制是Decoder-Only的核心,需理解其如何保证生成逻辑连贯。
3.2 与大语言模型交互
3.2.1 提示工程
基础概念:
- 提示(Prompt):引导模型生成期望输出的指令或示例。
- 采样参数:
- Temperature:控制输出随机性(低温度更确定,高温度更创意)。
- Top-k/Top-p:限制候选词范围,平衡多样性与一致性。
- 提示类型:
- 零样本(Zero-shot):无示例,直接指令。
- 单样本(One-shot):提供1个示例。
- 少样本(Few-shot):提供多个示例,提升任务理解。
- 指令调优:通过微调使模型更好遵循指令(如ChatGPT)。
- 高级技巧:
- 角色扮演:限定模型身份,调整输出风格。
- 思维链(Chain-of-Thought, CoT):引导模型分步推理,提升复杂问题解决能力。
关键原理:
- 提示工程是智能体与模型沟通的桥梁,设计质量直接影响输出效果。
学习提示(坑):
- Temperature=0时退化为贪心搜索,可能输出重复内容。
- 少样本提示的示例需覆盖任务多样性,避免偏见。
3.2.2 文本分词
基础概念:
- 分词(Tokenization):将文本转换为数字序列的过程。
- 子词分词:平衡词表大小和语义表达,主流算法包括:
- BPE(Byte-Pair Encoding):迭代合并高频词对构建词表。
- WordPiece:基于概率提升合并(如BERT)。
- SentencePiece:将空格视为普通字符,支持多语言。
- 对开发者的意义:
- 上下文窗口以Token数计算,影响长文本处理。
- API成本按Token计费,需优化输入长度。
关键原理:
- 分词算法影响模型对未见词的处理能力(如“DatawhaleAgent”切分为子词)。
学习提示(坑):
- 中英文分词效率不同,中文Token数通常更多,需注意上下文限制。
- 特殊格式(如无空格“2+2”)可能导致分词错误,影响模型理解。
3.2.3 调用开源大语言模型
基础概念:
- 使用Hugging Face Transformers库本地部署模型(如Qwen)。
- 步骤:加载分词器→编码输入→生成输出→解码结果。
实践提示:
- 代码示例中,
apply_chat_template用于格式化对话输入。 - 生成时控制
max_new_tokens避免无限输出。
3.2.4 模型的选择
基础概念:
- 选型因素:性能、成本、速度、上下文窗口、部署方式、生态工具链、可微调性、安全性。
- 闭源模型:
- OpenAI GPT系列:多模态领先,适合复杂任务。
- Google Gemini:原生多模态,长上下文优势。
- Anthropic Claude:安全可靠,适合企业级应用。
- 开源模型:
- Meta Llama系列:生态丰富,性能均衡。
- Mistral AI:小尺寸高性能,适合资源受限场景。
- 国内模型(如Qwen、ChatGLM):中文优化好。
关键原理:
- 闭源模型“开箱即用”,开源模型灵活可控,需权衡需求。
学习提示(坑):
- 企业级应用需考虑数据隐私和合规性,开源模型更安全。
3.3 大语言模型的缩放法则与局限性
3.3.1 缩放法则
基础概念:
- 缩放法则(Scaling Laws):模型性能与参数量、数据量、计算量呈幂律关系。
- Chinchilla定律:最优性能需平衡模型大小与训练数据量(小模型+更多数据可能更优)。
- 能力涌现:模型规模达阈值后,突现新能力(如推理、代码生成)。
关键原理:
- 缩放法则指导模型设计,但数据效率同样关键。
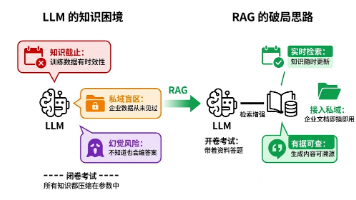
3.3.2 模型幻觉
基础概念:
- 幻觉(Hallucination):模型生成不实或矛盾内容。
- 类型:事实性、忠实性、内在幻觉。
- 原因:训练数据噪声、自回归生成机制、推理错误。
- 缓解方法:
- 检索增强生成(RAG):从外部知识库检索信息,增强事实性。
- 多步推理与验证:引导模型自我检查。
- 外部工具调用:使用搜索引擎、计算器等辅助。
关键原理:
- 幻觉是LLM固有局限,智能体需设计验证机制(如RAG)保障可靠性。
学习提示(坑):
- 高创意任务可容忍幻觉,但事实性任务(如客服)需严格规避。
实践
D:\Users\WDF\miniconda3\envs\my-hello-agents\lib\site-packages\huggingface_hub\file_download.py:143: UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them in C:\Users\WDF\.cache\huggingface\hub\models--Qwen--Qwen1.5-0.5B-Chat. Caching files will still work but in a degraded version that might require more space on your disk. This warning can be disabled by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable. For more details, see https://huggingface.co/docs/huggingface_hub/how-to-cache#limitations.
To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator. In order to activate developer mode, see this article: https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development
warnings.warn(message)
Xet Storage is enabled for this repo, but the 'hf_xet' package is not installed. Falling back to regular HTTP download. For better performance, install the package with: `pip install huggingface_hub[hf_xet]` or `pip install hf_xet`
不影响下载模型
推荐安装hf_xet
设置环境变量换源
HF_ENDPOINT=https://hf-mirror.com
本章小结
- 核心知识:语言模型演进→Transformer革命→交互技巧(提示工程、分词)→模型生态→缩放法则与幻觉。
- 与智能体关联:提示工程引导智能体决策,模型选型影响性能,幻觉缓解提升可靠性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)