基于YOLO8和Streamlit的学生课堂行为检测系统【源码+数据集+训练教程+文章】
摘要 本文介绍了一个基于YOLOv8和Streamlit的学生课堂行为智能识别系统。系统采用YOLOv8目标检测算法,能够精准识别6种典型课堂行为(如举手、玩手机等),并通过Streamlit实现可视化交互。文章详细解析了YOLOv8的网络架构创新,包括C2f模块、优化Neck结构和解耦检测头等改进。系统使用包含5686张标注图像的真实课堂数据集,经测试mAP@50达87.4%。该系统实现了课堂教
文末附下载链接
开发目的
随着教育信息化的不断推进,课堂教学质量的科学评估与学生学习状态的实时监测日益成为教育管理中的关键议题。传统的课堂行为观察主要依赖教师人工巡查或事后视频回放分析,不仅耗时耗力,且难以实现全面、客观、实时的行为识别与反馈,尤其在大规模教学监管中暴露出覆盖不足、主观性强和响应滞后等问题。为应对这一挑战,亟需一种智能化、自动化、可视化的学生课堂行为检测手段,以提升教学管理的精细化与数据化水平。
基于此背景,本系统融合YOLOv8目标检测算法与Streamlit交互式Web框架,构建了一套高效、直观的学生课堂行为智能识别系统。YOLOv8作为当前最先进的端到端目标检测模型,在检测精度、推理速度及多尺度适应性方面表现卓越,能够精准识别学生在课堂中的多种典型行为,如低头、举手、站立、玩手机、交头接耳等,实现对异常行为的实时预警与行为分布统计。
同时,借助Streamlit强大的前端可视化能力,系统可将检测结果以动态视频流、行为热力图、时间序列分析等形式直观呈现,支持教师与管理者在线监控、回溯分析与教学干预决策,极大提升了课堂教学监管的智能化与便捷性。该系统的应用不仅有助于营造专注、有序的学习氛围,还能为教育研究提供客观的行为数据支撑,推动人工智能技术在智慧教育场景中的深度融合与落地,具有重要的实践价值与社会意义。
YOLO介绍
YOLOv8:架构解析与相较于YOLOv5、YOLOv7的创新升级
YOLOv8由Ultralytics于2023年发布,作为YOLO系列的最新迭代版本,它在保持实时检测性能的同时,进一步提升了检测精度和模型效率。YOLOv8延续了YOLO系列“一个网络完成端到端检测”的设计理念,但在网络结构设计上进行了多项关键优化。本文将从骨干网络(Backbone)、Neck结构和检测头(Head)三个方面深入解析YOLOv8,并对比其相较于YOLOv5和YOLOv7的主要改进与创新。
一、YOLOv8网络结构解析
- 骨干网络(Backbone):C2f模块取代C3模块
YOLOv8的骨干网络基于CSP(Cross Stage Partial)思想进行改进,但摒弃了YOLOv5和YOLOv7中广泛使用的C3模块,转而采用全新的C2f(Cross Stage Feature)模块。C2f模块通过更轻量的特征融合方式,在保证梯度流畅通的同时减少了参数量和计算量。其核心结构包含多个并行支路和跨阶段连接,能够更有效地提取和传播多尺度特征。此外,YOLOv8在Backbone中去除了SPP模块中的最大池化层冗余,改用SPPF(Spatial Pyramid Pooling Fast)结构,提升计算效率。
- Neck结构:PANet的进一步优化
YOLOv8的Neck部分延续了PANet(Path Aggregation Network)的双向特征融合机制,但对结构进行了简化与增强。它采用更高效的特征金字塔结构,通过上采样与下采样路径实现深层语义信息与浅层细节特征的充分融合。与YOLOv5和YOLOv7相比,YOLOv8的Neck减少了冗余卷积操作,提升了信息传递效率。同时,Neck中的卷积层普遍采用SiLU激活函数,增强了非线性表达能力。
- 检测头(Head):解耦头与Anchor-Free趋势
YOLOv8采用了与YOLOv5类似的Anchor-Based检测头,但在设计上更加简洁高效。其检测头为解耦结构(Decoupled Head),将分类与回归任务分离,分别使用独立的卷积分支,提升了任务专注度和检测精度。值得注意的是,YOLOv8在部分变体(如YOLOv8n)中已开始向Anchor-Free方向探索,通过直接预测边界框中心与偏移量,减少先验框设计带来的超参数依赖。此外,YOLOv8默认使用更高效的损失函数组合:分类损失采用BCE Loss,定位损失采用CIoU Loss,提升边界框回归精度。
二、YOLOv8 vs YOLOv5 & YOLOv7:核心改进与创新
- 模块设计更高效:C2f vs C3
YOLOv5和YOLOv7均采用C3模块作为核心构建单元,该模块基于Bottleneck结构堆叠,虽然有效但计算开销较大。YOLOv8引入的C2f模块通过更稀疏的连接方式,在保持梯度多样性的同时显著降低计算负担,尤其在小模型(如YOLOv8s以下)中表现更为突出。
- 更强的特征融合能力
相较于YOLOv5较为基础的PANet结构,YOLOv8在Neck中优化了特征融合路径,增强了低层细节与高层语义的交互能力。而YOLOv7虽然引入了E-ELAN等复杂结构以提升性能,但牺牲了部分推理速度。YOLOv8在精度与速度之间实现了更优平衡。
- 损失函数与训练策略升级
YOLOv8在训练策略上采用更先进的标签分配机制(如Task-Aligned Assigner),动态匹配正负样本,避免了YOLOv5中静态匹配可能带来的误匹配问题。同时,YOLOv8默认关闭了Mosaic增强在最后若干轮的使用,有助于模型收敛更稳定。
- 模型系列更统一与可扩展
YOLOv8推出了n、s、m、l、x五个标准尺寸模型,接口统一,配置清晰,便于部署与迁移。相比之下,YOLOv7虽然性能强劲,但结构复杂,变体众多,部署成本较高。YOLOv5虽结构简洁,但在精度上限上已被YOLOv8超越。
- 默认激活函数全面升级
YOLOv8全网络统一采用SiLU(Swish)激活函数,替代YOLOv5中的部分ReLU和Sigmoid,提升非线性建模能力。实验表明,SiLU有助于加快收敛并提升最终精度。
结语
YOLOv8在继承YOLO系列高效、实时优势的基础上,通过C2f模块、优化Neck结构、改进检测头设计以及更先进的训练策略,实现了在精度、速度和部署友好性上的全面升级。相较于YOLOv5,它在结构设计上更加现代化;相较于YOLOv7,它在复杂度与实用性之间取得了更好平衡。YOLOv8不仅是当前YOLO系列的集大成者,也为工业级目标检测提供了更优的默认选择。
系统设计
数据集
(1) 数据集基本情况
本项目所使用的数据集为专门针对学生课堂行为构建的目标检测数据集。数据集来源于真实的小学、中学、高中以及大学等多样化的课堂场景,涵盖了多种光照、角度和人群密度情况,具备较强的泛化能力。
数据集已按标准划分方式分为训练集和验证集:
- 训练集:共4518张图像
- 验证集:共1168张图像
- 总计:5686张标注图像
数据集共包含6类学生课堂行为类别,具体如下:
- 举手
- 阅读
- 写作
- 玩手机
- 低头
- 靠在桌子上
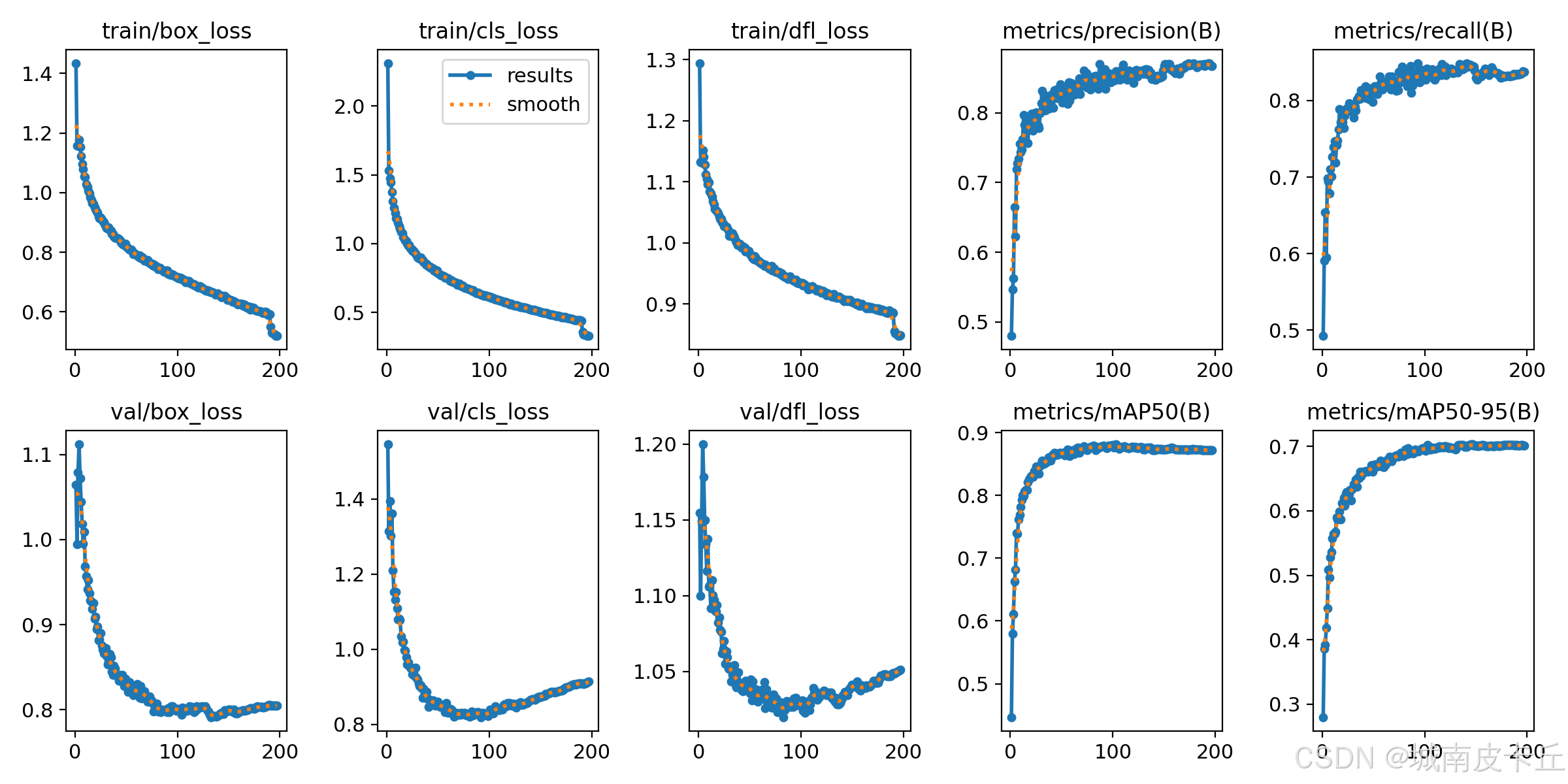
该数据集未使用任何数据增强技术,所有图片均为原始采集图像,确保了数据的真实性与可靠性。经过实测,在YOLOv8s模型上训练后,mAP@50指标达到87.4%,表明数据集质量高、标注准确,适合用于课堂行为识别任务的深度学习模型训练。

(2) 数据集处理
在完成图像采集后,我们采用 LabelMe 工具对图像进行手动标注。LabelMe 是一个开源的图像标注工具,支持多边形、矩形、点等多种标注方式,适用于目标检测、语义分割等任务。
对于目标检测任务,我们使用矩形框(bounding box)对每张图像中的学生行为进行标注。LabelMe 默认输出为 JSON 格式文件,每个 JSON 文件记录了图像中所有目标的位置信息及类别标签。
为了适配 YOLO 系列模型的训练需求,我们将 LabelMe 的 JSON 标注文件转换为 YOLO 目标检测所要求的标准格式——每图一个 .txt 文件,每行表示一个目标。
YOLO 目标检测数据集格式说明:
YOLO 格式的标注文件(.txt)遵循以下结构:
<class_id> <x_center> <y_center> <width> <height>
其中:
class_id:类别索引(从0开始)x_center,y_center:边界框中心点坐标(相对于图像宽高的归一化值,范围 [0,1])width,height:边界框的宽高(同样为归一化值)
例如:
0 0.456 0.321 0.123 0.234
3 0.789 0.654 0.100 0.150
该格式要求每个图像文件(如 image.jpg)对应一个同名的 .txt 文件(如 image.txt),并存放在 labels/ 目录下。
最终,整个数据集组织结构如下:
dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
└── data.yaml
data.yaml 文件定义了类别数量、类别名称和训练/验证集路径,是训练时的关键配置文件。
模型训练
安装 Ultralytics
YOLOv8 由 Ultralytics 公司开发,其官方提供了简洁高效的 ultralytics Python 包,支持模型训练、验证、推理与部署。
安装命令如下:
pip install ultralytics
支持 PyTorch 1.8 及以上版本,推荐使用 GPU 环境以加速训练过程。
训练代码编写
训练脚本通常通过 Python API 调用方式进行,以下是最基本的训练代码示例:
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8s.pt')
# 开始训练
results = model.train(
data='path/to/data.yaml',
epochs=100,
imgsz=640,
batch=16,
name='yolov8s_student_behavior'
)
该脚本会自动加载数据集、初始化模型并开始训练,同时保存最佳权重和训练日志。
训练参数设置(超参数详解)
Ultralytics 提供了丰富的可调超参数,合理设置有助于提升模型性能。以下是本次训练中关键超参数的取值及其含义说明:
| 超参数 | 取值 | 含义 |
|---|---|---|
epochs |
100 | 训练轮数,控制模型学习的迭代次数 |
batch |
16 | 每批次输入图像数量,影响内存占用和梯度稳定性 |
imgsz |
640 | 输入图像尺寸(H×W),越大细节越丰富但计算量增加 |
optimizer |
auto(AdamW) | 优化器选择,默认根据模型自动选择 |
lr0 |
0.01 | 初始学习率,控制参数更新步长 |
lrf |
0.01 | 最终学习率 = lr0 × lrf,用于学习率衰减 |
momentum |
0.937 | SGD/Adam 动量因子,提升收敛速度 |
weight_decay |
0.0005 | L2 正则化系数,防止过拟合 |
warmup_epochs |
3.0 | 学习率预热阶段的 epoch 数 |
warmup_momentum |
0.8 | 预热阶段动量值 |
box |
7.5 | 边界框回归损失权重 |
cls |
0.5 | 分类损失权重 |
cls_pw |
1.0 | 分类正样本权重 |
obj |
1.0 | 对象性损失权重 |
iou_type |
ciou | IoU 损失类型(支持 ciou, giou, diou) |
anchor_free |
False | 是否启用无锚框机制 |
label_smoothing |
0.0 | 标签平滑系数,增强泛化能力 |
注:以上参数可通过
model.train(...)函数传入,部分高级参数需通过配置文件修改。
训练后评估
为什么需要模型评估?
训练完成后,必须对模型性能进行全面评估,以判断其是否具备实际应用价值。评估不仅可以反映模型在验证集上的表现,还能帮助我们发现模型的弱点(如漏检、误检),进而指导后续优化。
常用评价指标介绍
1. PR 曲线(Precision-Recall Curve)
PR 曲线是目标检测中最核心的评估工具之一,描绘了不同置信度阈值下**精确率(Precision)与召回率(Recall)**之间的关系。
-
精确率(Precision):预测为正类的样本中,真正为正类的比例。
Precision=TPTP+FP \text{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP -
召回率(Recall):真实为正类的样本中,被正确预测的比例。
Recall=TPTP+FN \text{Recall} = \frac{TP}{TP + FN} Recall=TP+FNTP
其中:
- TP:真正例(True Positive)
- FP:假正例(False Positive)
- FN:假反例(False Negative)
PR 曲线下面积(AUC)越大,说明模型整体性能越好。
2. mAP(mean Average Precision)
mAP 是目标检测领域的“黄金标准”,综合衡量模型在所有类别和 IoU 阈值下的平均精度。
- AP(Average Precision):对某一类别,计算其 PR 曲线下的面积。
- mAP@50:在 IoU 阈值为 0.5 时计算的各类别 AP 的平均值。
- mAP@50:95:在 IoU 从 0.5 到 0.95(步长 0.05)共 10 个阈值下 AP 的平均值,更严格。
公式表示为:
mAP=1N∑i=1NAPi \text{mAP} = \frac{1}{N} \sum_{i=1}^{N} \text{AP}_i mAP=N1i=1∑NAPi
其中 NNN 为类别总数。
本项目中,YOLOv8s 模型在验证集上达到了 mAP@50 = 87.4%,说明模型对六类学生行为具有良好的识别能力。
模型推理
图片推理代码
使用训练好的模型进行图片推理非常简单,只需调用 model.predict() 方法即可。
from ultralytics import YOLO
from PIL import Image
model = YOLO('runs/detect/yolov8s_student_behavior/weights/best.pt')
image = Image.open('test.jpg')
results = model.predict(source=image, conf=0.25, iou=0.45)
annotated_img = results[0].plot()
annotated_img.show()
视频推理代码
对于视频或摄像头流,可逐帧进行推理:
import cv2
from ultralytics import YOLO
model = YOLO('best.pt')
cap = cv2.VideoCapture('input.mp4')
while cap.isOpened():
success, frame = cap.read()
if not success:
break
results = model.predict(source=frame, conf=0.25)
annotated_frame = results[0].plot()
cv2.imshow('Detection', annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
上述代码也可用于本地摄像头(将 'input.mp4' 替换为 0)。
系统UI设计
Streamlit 框架优点
本系统采用 Streamlit 作为前端可视化框架,主要原因包括:
- 开发效率高:纯 Python 编写,无需 HTML/CSS/JS 即可构建交互式 Web 应用。
- 语法简洁:API 设计直观,几行代码即可创建按钮、滑块、文件上传等功能。
- 实时热重载:代码修改后页面自动刷新,便于调试。
- 组件丰富:支持图像显示、视频播放、表格、图表等多媒体展示。
- 易于部署:支持一键部署到 Streamlit Community Cloud、Heroku 等平台。
UI 源码解析(基于提供的 app.py)
以下是系统 UI 的核心实现逻辑分析:
st.set_page_config(page_title="code learn corner", page_icon="🤖", layout="wide")
设置页面标题、图标和布局为宽屏模式。
hide_streamlit_style = """<style> MainMenu {visibility: hidden;} footer {visibility: hidden;} </style>"""
st.markdown(hide_streamlit_style, unsafe_allow_html=True)
隐藏默认的 Streamlit 菜单和页脚,使界面更干净专业。
st.markdown("<h1 style='text-align: center;'>基于YOLOv8的学生课堂行为分析系统</h1>", unsafe_allow_html=True)
居中显示主标题,使用 HTML 样式增强视觉效果。
confidence = float(st.sidebar.slider("调整置信度", 10, 100, 25)) / 100
iou=float(st.sidebar.slider("调整iou", 10, 100, 45)) / 100
在侧边栏添加滑块控件,允许用户动态调节置信度和 IoU 阈值。
source = ("图片检测", "视频检测",'本地摄像头检测')
select_radio=st.sidebar.radio('检测类型',source)
提供三种检测模式选择:图片、视频、摄像头。
图片检测流程:
- 使用
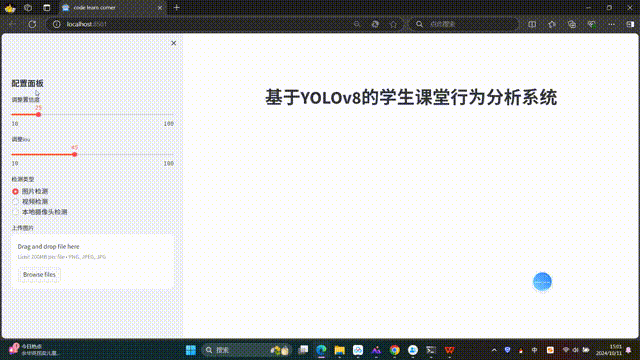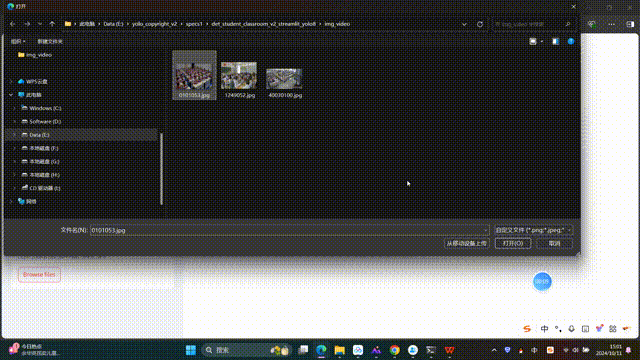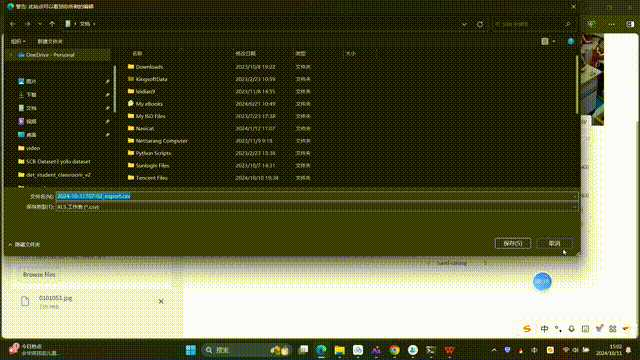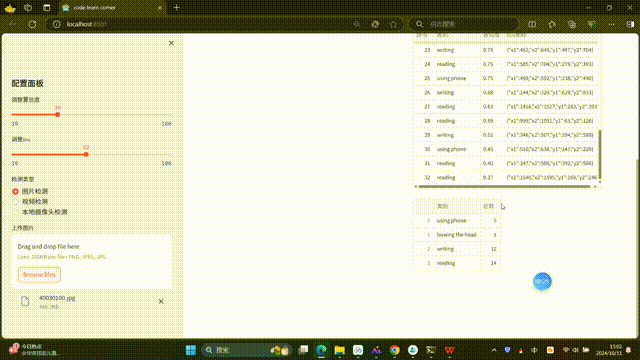
file_uploader上传图片 - 显示原始图像和检测结果
- 输出检测结果表格(序号、类别、置信度、坐标)
- 统计各类行为总数
视频检测流程:
- 上传视频文件
- 使用
tempfile临时保存 - 用 OpenCV 读取帧并逐帧推理
- 使用
st.empty().image()实时更新检测画面
摄像头检测流程:
- 点击“终止执行”按钮前持续运行
- 调用
cv2.VideoCapture(0)打开本地摄像头 - 实时显示带标注的视频流
整个 UI 设计清晰、交互友好,充分体现了 Streamlit 在快速构建 AI 应用方面的优势。
系统功能
根据提供的源代码,该系统具备以下主要功能:
-
多模态输入支持:
- 支持上传本地图片进行检测
- 支持上传视频文件进行逐帧分析
- 支持调用本地摄像头实现实时行为监控
-
可调节推理参数:
- 用户可通过滑块自定义置信度阈值(Confidence)
- 可调节 IoU 阈值,控制非极大值抑制(NMS)强度
-
可视化检测结果:
- 原始图像/视频与检测结果并列展示
- 检测框带有类别标签和置信度
- 使用不同颜色区分不同行为类别
-
结构化结果输出:
- 表格形式展示每个检测目标的详细信息(序号、类别、置信度、坐标)
- 统计各类行为出现的总次数,便于数据分析
-
高性能实时推理:
- 基于 YOLOv8 的高效架构,满足实时检测需求
- 视频和摄像头模式下流畅播放,延迟低
-
易用性与可扩展性:
- 界面简洁直观,适合教育场景使用
- 模块化设计,便于后续集成更多功能(如导出报告、行为趋势分析等)
综上所述,本系统成功实现了基于 YOLOv8 和 Streamlit 的学生课堂行为智能检测,具备高精度、强交互性和良好实用性,可广泛应用于智慧教室、教学行为分析、课堂管理等领域。
总结
本文围绕“基于YOLOv8和Streamlit的学生课堂行为检测系统”展开,系统性地阐述了项目的开发背景、核心技术选型、数据集构建、模型训练与评估流程,以及系统的整体架构与功能实现。通过融合当前最先进的目标检测算法YOLOv8与高效易用的Web交互框架Streamlit,成功构建了一套集智能化、可视化、实时化于一体的课堂行为分析平台。
在技术层面,YOLOv8凭借其C2f模块、优化的Neck结构、解耦检测头以及先进的训练策略,在精度与速度之间实现了优异平衡,确保了对学生多种课堂行为(如举手、低头、玩手机等)的高准确率识别。实测mAP@50达到87.4%,验证了模型在真实课堂场景下的强大泛化能力。而在系统层面,Streamlit的引入极大降低了前端开发门槛,使得复杂的AI模型推理过程得以通过简洁直观的Web界面呈现,支持图片、视频及本地摄像头三种输入模式,并提供可调节的置信度与IoU参数、结构化结果输出与行为统计功能,显著提升了系统的实用性与用户体验。
本系统的成功实践不仅为课堂教学质量评估提供了客观、高效的技术手段,减轻了教师管理负担,也为教育大数据的采集与分析奠定了基础。未来可进一步拓展方向包括:引入行为时序分析以识别长期学习状态变化、结合注意力机制提升遮挡场景下的检测性能、支持多教室并发监控与云端部署等。总体而言,该系统是人工智能技术赋能智慧教育的一次有力探索,展现了AI在教育领域广阔的应用前景与深远的社会价值。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)