5. BV11-密钥切换与模切换-《Efficient Fully Homomorphic Encryption from (Standard) LWE》
前言
借鉴致远的文章学习同态加密,本文主要记录密钥切换与模切换流程,参考文献为Zvika Brakerski 和Vinod Vaikuntanathan的《Efficient Fully Homomorphic Encryption from (Standard) LWE》,这篇文章的针对性问题如下:
| 😄 | 现有方法的问题 | 改进方法 / 文章贡献 |
|---|---|---|
| 1 | 现有的全同态加密算法复杂度被量子规约到 worst-case 理想格难题上,但是当时对理想格的研究较少,未经过充分验证 | 容错学习问题(Learning with error problem):基于容错学习问题,算法复杂度可以标准规约到任意格的worst-case 难题上 |
| 2 | 现有的全同态加密算法在进行同态乘法时,密文维度从 n + 1 n+1 n+1扩展到将近 n 2 / 2 n^2/2 n2/2。因此,随着乘法深度增加,计算开销上升。 | 重线性化(re-relinearization):进行密钥切换,将平方级密钥维度收缩为线性大小 |
| 3 | 为将部分同态算法提升至全同态,现有方法基于稀疏子集和假设(sparse subset-sum assumption),引入压缩(Squashing step)技术 | 维度-模数约减(dimension-modulus reduction):进行模数和密钥维度的切换,避免使用压缩技术,从而去除稀疏子集和这个强假设 |
半同态加密(Partially Homomorphic Encryption,PHE):仅支持一种同态运算,但是支持无限次运算。
部分同态加密(Somewhat Homomorphic Encryption,SWHE):支持多种同态运算,但是运算次数有限。
全同态加密(Fully Homomorphic Encryption,FHE):支持无限次多种同态运算。
文章目录
一、预备知识
1. 基础定义
| 知识点 | 个人理解 | 形式化定义 |
|---|---|---|
| B-bound distribution | 分布多数样本的范数小于 B B B。换句话说,样本落在以原点为圆心, B B B为半径的圆外的概率很小。 | 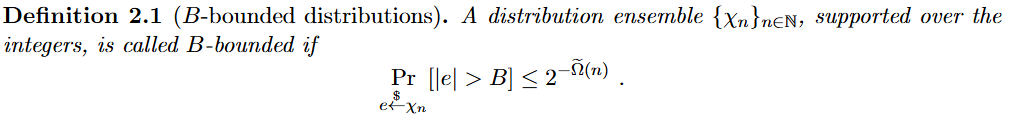 |
| Matrix-vector leftover hash lemma | 剩余哈希引理揭示了LWE样本接近均匀分布。 | 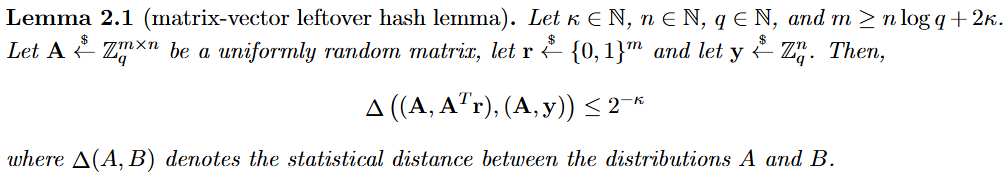 |
| Correctness | 对称加密算法是正确的,意味着对于任何明文和密钥,解密失败的概率非常小。 |  |
| IND-CPA secure | 攻击者无法在有限时间内区分真实明文对应的密文和比特0对应的密文 | 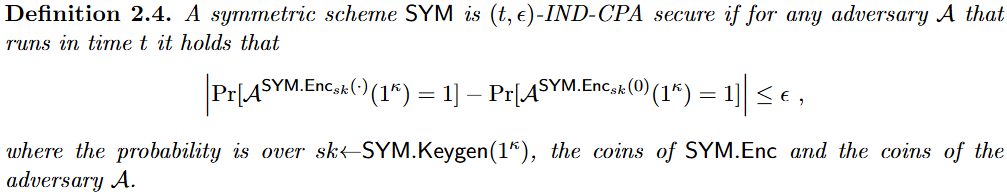 |
| C \mathcal{C} C-Homomorphism | 同态性是指,对于函数集合中某类函数的实例,解密同态计算后的密文 = 明文运算结果 | 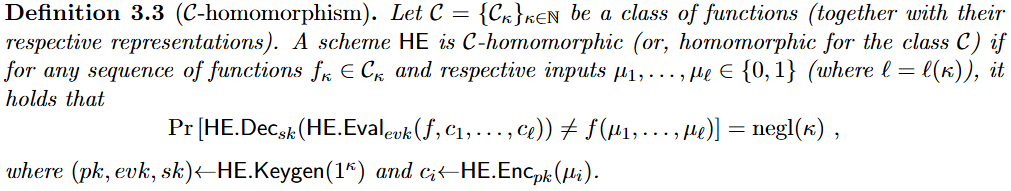 |
| Compactness | 紧凑性要求,无论有几个输入,同态计算的密文输出长度最多为多项式级别的。 | 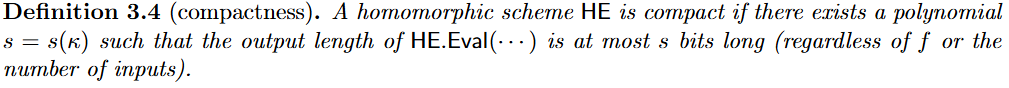 |
| Bootstrappable encryption scheme | 同时包含异或运算和与运算的同态方案。这是因为XOR和AND可以组合出任意布尔电路,包括解密电路。 |  |
| Weak circular security | 弱循环安全是指,攻击者拥有按比特加密的私钥,但公钥加密算法仍是IND-CPA安全的。 |  |
2. IND-CPA secure
IND-CPA安全是指攻击者即使能够自由加密任何他选中的明文,也无法区分两个特定明文的加密结果。下面介绍同态加密方案的CPA安全性:
| 知识点 | 个人理解 | 形式化定义 |
|---|---|---|
| CPA security | 攻击者已知公钥、同态计算的评估密钥、密文,但在多项式时间内无法区分同一明文对应的两条不同密文。同一密文可以加密成两条不同的密文,这是因为同态加密算法是一种随机算法 | 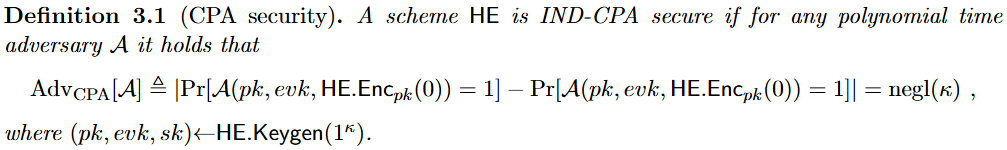 |
| ( t , ϵ ) (t,\epsilon) (t,ϵ)-CPA security | 攻击者已知公钥 p k pk pk、同态计算的评估密钥 e v k evk evk、密文,但在时间 t t t(超多项式级别)内区分同一明文对应的两条不同密文的概率很小,小于次多项式级别。 | 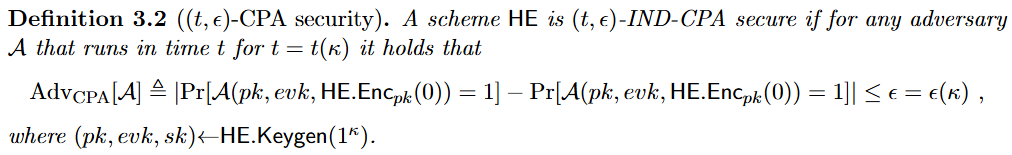 |
在证明CPA安全时,需要通过一个挑战者(Challenger)和攻击者(Adversary)之间的安全游戏来定义:
- 初始化:挑战者运行密钥生成算法 K e y G e n ( 1 κ ) KeyGen(1^κ) KeyGen(1κ),产生一对公钥 p k pk pk 和私钥 s k sk sk。挑战者将公钥 p k pk pk 发送给攻击者。私钥 s k sk sk 被安全保存。
- 查询阶段 1:攻击者可以自适应地选择任意明文 m m m,并发送给挑战者。挑战者返回对应的密文 E n c ( p k , m ) Enc(pk, m) Enc(pk,m)。攻击者可以根据之前收到的密文,不断调整并选择新的明文进行查询。这个阶段可以重复多项式次。
- 挑战阶段:攻击者选择两个等长的明文 m 0 m₀ m0 和 m 1 m₁ m1,并发送给挑战者。挑战者随机地抛一枚硬币,选择一个比特 b ∈ { 0 , 1 } b ∈ \{0, 1\} b∈{0,1}。挑战者计算挑战密文 c ∗ = E n c ( p k , m b ) c^* = Enc(pk, m_b) c∗=Enc(pk,mb),并将 c ∗ c^* c∗ 发送给攻击者。
- 查询阶段 2:攻击者可以像阶段1一样继续请求加密其他明文,但不能请求解密挑战密文 c ∗ c^* c∗。
- 猜测阶段:攻击者输出一个猜测比特 b ′ b' b′。攻击者的优势是指以超过 50 % 50\% 50%的概率猜对的可能性,定义为: A d v C P A [ A ] = ∣ P r [ b ′ = b ] − 1 / 2 ∣ Adv_{CPA}[\mathcal{A}] = | Pr[b' = b] - 1/2 | AdvCPA[A]=∣Pr[b′=b]−1/2∣
- 定义:如果对于所有多项式时间的攻击者 A \mathcal{A} A,其优势 A d v C P A [ A ] Adv_{CPA}[\mathcal{A}] AdvCPA[A] 都是可忽略的,那么这个加密方案就是 IND-CPA 安全的。
3. 全同态加密方案的扩展
Gentry提出了自举(Bootstrapping)技术,有研究者在此基础上得出以下结论:
- 理论3.1:利用基于自举的同态加密方案,可以构造层次全同态加密方案。
- 理论3.2:利用一个满足弱循环安全的基于自举的同态加密方案,可以构造全同态加密方案。
- 引理3.3:若一个(层次)全同态加密方案是由自举技术构造的,那么同态计算后的密文长度与新密文一样长。
二、核心算法
本文的同态计算函数由伽罗瓦域 G F ( 2 ) GF(2) GF(2)上的电路表示。下面介绍BV11的核心算法:
1. 密钥切换:Re-linearization
重线性化是为了解决同态乘法中密文维度指数级增长的问题,主要新增了重线性化密钥,并改动了同态乘法的计算方法。
- 参数设置
| 参数 | 解释 |
|---|---|
| κ \kappa κ | 安全参数 |
| n = p o l y ( κ ) n=poly(\kappa) n=poly(κ) | 密文维度 |
| m = p o l y ( n ) ≥ n log q + 2 κ m=poly(n) \geq n \log q+2\kappa m=poly(n)≥nlogq+2κ | LWE样本个数 |
| q ∈ [ 2 n ϵ , 2 ⋅ 2 n ϵ ) q\in [2^{n^\epsilon},2\cdot 2^{n^\epsilon}) q∈[2nϵ,2⋅2nϵ) | 模数,取奇数,其中 ϵ ∈ ( 0 , 1 ) \epsilon \in(0,1) ϵ∈(0,1),保证 q q q是 n n n次指数级别 |
| L ≈ ϵ log n L\approx \epsilon \log n L≈ϵlogn | 乘法深度,即允许计算的乘法次数 |
| χ \chi χ | 噪声分布,取小噪声,噪声范数最多为 n n n |
- 生成密钥
| 参数 | 解释 |
|---|---|
| s 0 , ⋯ , s L s_0,\cdots,s_L s0,⋯,sL | 私钥链:包括 L + 1 L+1 L+1个私钥,其中 s i ← Z q n s_i\leftarrow \Z^n_q si←Zqn前 L L L个私钥的第0位为1,即 s l − 1 [ 0 ] = 1 s_{l-1}[0]=1 sl−1[0]=1 |
| ( A , b ) (A,b) (A,b) | 公钥:首先均匀采样矩阵 A ∈ Z q m × n A\in \Z_q^{m\times n} A∈Zqm×n和噪声 e ∈ χ m e\in \chi^m e∈χm,然后计算 b = A s 0 + 2 e b=As_0+2e b=As0+2e |
| Φ = { ϕ l , i , j , τ } \Phi=\{\phi_{l,i,j,\tau}\} Φ={ϕl,i,j,τ} | 重线性化密钥:用于加密同态乘法后的密文二次项 2 τ ⋅ s l [ i ] ⋅ s l [ j ] 2^\tau\cdot s_l[i]\cdot s_l[j] 2τ⋅sl[i]⋅sl[j]。对于每一层 l ∈ [ L ] l\in [L] l∈[L],乘法索引对 0 ≤ i ≤ j ≤ n 0\leq i\leq j \leq n 0≤i≤j≤n,和每个比特位 τ ∈ { 1 , ⋯ , log q ⌋ } \tau\in\{1,\cdots, \log q \rfloor\} τ∈{1,⋯,logq⌋},从LWE分布中采样密钥 ϕ l , i , j , τ = ( a l , i , j , τ , b l , i , j , τ ) \phi_{l,i,j,\tau}=(a_{l,i,j,\tau},b_{l,i,j,\tau}) ϕl,i,j,τ=(al,i,j,τ,bl,i,j,τ) 其中,向量 a l , i , j , τ ∈ Z q n a_{l,i,j,\tau}\in\Z_q^n al,i,j,τ∈Zqn和小噪声 e l , i , j , τ ∈ Z q n e_{l,i,j,\tau}\in\Z_q^n el,i,j,τ∈Zqn通过随机采样得到,则 b l , i , j , τ = < a l , i , j , τ , s l > + 2 ⋅ e l , i , j , τ + 2 τ ⋅ s l − 1 [ i ] ⋅ s l − 1 [ j ] ∈ Z q b_{l,i,j,\tau} = \left<a_{l,i,j,\tau},s_l \right>+2\cdot e_{l,i,j,\tau} + 2^\tau\cdot s_{l-1}[i]\cdot s_{l-1}[j] \in \Z_q bl,i,j,τ=⟨al,i,j,τ,sl⟩+2⋅el,i,j,τ+2τ⋅sl−1[i]⋅sl−1[j]∈Zq |
- 加密
给定明文 μ ∈ G F ( 2 ) \mu\in GF(2) μ∈GF(2),随机选取一个向量 r ∈ { 0 , 1 } m r\in \{0,1\}^m r∈{0,1}m,则密文为 c = ( ( v , w ) , 0 ) c=((v,w),0) c=((v,w),0)。其中,0 表示初始化乘法深度, v = A T r v=A^Tr v=ATr, w = b T r + μ w=b^Tr+\mu w=bTr+μ - 解密
对于乘法深度为 l l l的密文 c = ( ( v , w ) , l ) c=((v,w),l) c=((v,w),l),解密结果如下: ( w − < v , s l > m o d q ) m o d 2 (w-\left< v,s_l\right> \mod q)\mod 2 (w−⟨v,sl⟩modq)mod2一般只解密同态计算后的结果,即对最后一层 l = L l=L l=L 密文解密。 - 同态加法
同态加法可以有多个输入 c 1 , ⋯ , c t c_1,\cdots,c_t c1,⋯,ct,但必须在同一层,其中 c i = ( ( v i , w i ) , l ) c_i=((v_i,w_i),l) ci=((vi,wi),l),则加法运算后的密文 c a d d = ( ( v a d d , w a d d ) , l ) c_{\mathrm{add}}=((v_{\mathrm{add}},w_{\mathrm{add}}),l) cadd=((vadd,wadd),l)有 v a d d = ∑ i v i v_{\mathrm{add}}=\sum_i v_i vadd=i∑vi w a d d = ∑ i w i w_{\mathrm{add}} = \sum_i w_i wadd=i∑wi - 同态乘法
同态乘法只可以输入同一层的两个密文 c = ( ( v , w ) , l ) c=((v,w),l) c=((v,w),l) 和 c ′ = ( ( v ′ , w ′ ) , l ) c'=((v',w'),l) c′=((v′,w′),l)。令 h i , j h_{i,j} hi,j为函数 ϕ ( s l ) \phi(s_l) ϕ(sl)的系数,即:
ϕ ( s l ) = ( w − < v , s l > ) ⋅ ( w ′ − < v ′ , s l > ) ( m o d q ) = ∑ 0 ≤ i ≤ j ≤ n h i , j ⋅ s l [ i ] ⋅ s l [ i ] \begin{aligned} \phi(s_l) &=(w-\left< v,s_l\right>)\cdot (w'-\left< v',s_l\right>) \pmod q \\ &=\sum_{0\leq i\leq j \leq n}h_{i,j}\cdot s_l[i] \cdot s_l[i] \end{aligned} ϕ(sl)=(w−⟨v,sl⟩)⋅(w′−⟨v′,sl⟩)(modq)=0≤i≤j≤n∑hi,j⋅sl[i]⋅sl[i]具体而言有:
h i , j = { w ⋅ w ′ , if i = 0 , j = 0 − w ⋅ v ′ [ j ] − w ′ ⋅ v [ j ] , if i = 0 , j ≥ 1 v ′ [ i ] ⋅ v [ i ] , if i = j ≥ 1 v [ i ] ⋅ v ′ [ j ] + v ′ [ i ] ⋅ v [ j ] , if j > i ≥ 1 h_{i,j}=\begin{cases} w\cdot w', & \text{if }& i=0,j=0\\ -w\cdot v'[j] - w'\cdot v[j], & \text{if }& i=0,j\geq 1 \\ v'[i]\cdot v[i], & \text{if}& i=j\geq 1\\ v[i]\cdot v'[j] + v'[i]\cdot v[j], & \text{if }& j> i\geq 1 \\ \end{cases} hi,j=⎩ ⎨ ⎧w⋅w′,−w⋅v′[j]−w′⋅v[j],v′[i]⋅v[i],v[i]⋅v′[j]+v′[i]⋅v[j],if if ifif i=0,j=0i=0,j≥1i=j≥1j>i≥1将 h i , j h_{i,j} hi,j转为二进制后有: h i , j = ∑ τ = 0 ⌊ log q ⌋ h i , j , τ ⋅ 2 τ h_{i,j}=\sum_{\tau=0}^{\lfloor \log q\rfloor}h_{i,j,\tau}\cdot 2^\tau hi,j=τ=0∑⌊logq⌋hi,j,τ⋅2τ则乘法运算后的密文 c m u l t = ( ( v m u l t , w m u l t ) , l + 1 ) c_{\mathrm{mult}}=((v_{\mathrm{mult}},w_{\mathrm{mult}}),l+1) cmult=((vmult,wmult),l+1)有 v m u l t = ∑ i , j , τ h i , j , τ ⋅ a l + 1 , i , j , τ m o d q v_{\mathrm{mult}}=\sum_{i,j,\tau}h_{i,j,\tau}\cdot a_{l+1,i,j,\tau} \mod q vmult=i,j,τ∑hi,j,τ⋅al+1,i,j,τmodq w m u l t = ∑ i , j , τ h i , j , τ ⋅ b l + 1 , i , j , τ m o d q w_{\mathrm{mult}} = \sum_{i,j,\tau} h_{i,j,\tau}\cdot b_{l+1,i,j,\tau}\mod q wmult=i,j,τ∑hi,j,τ⋅bl+1,i,j,τmodq其中, 0 ≤ i ≤ j ≤ n 0\leq i\leq j \leq n 0≤i≤j≤n, τ ∈ { 0 , ⋯ , ⌊ log q ⌋ } \tau\in \{0,\cdots,\lfloor \log q\rfloor\} τ∈{0,⋯,⌊logq⌋}。
2. 模切换、密钥维度切换:Dimension-modulus Reduction
维度-模数约减是在 L L L层同态乘法结束后,为了减小自举(解密)的计算开销而设计的,在重线性化的基础上,将原本的密文维度 n n n和模数 q q q 切换为更小的参数 ( k , p ) (k,p) (k,p),新增了约减密钥,并设计了在新参数下的同态计算。下面只介绍改进步骤,其余都与上文一致:
- 参数设置
| 参数 | 解释 |
|---|---|
| k = κ k=\kappa k=κ | 新的密文维度 |
| n = κ 4 n=\kappa^4 n=κ4 | 旧的密文维度 |
| q ≈ 2 n q\approx 2^{\sqrt n} q≈2n | 旧的模数 |
| p = ( n 2 log q ) ⋅ p o l y ( k ) = p o l y ( k ) p=(n^2\log q)\cdot poly(k) =poly(k) p=(n2logq)⋅poly(k)=poly(k) | 旧的模数 |
| m = O ( n log q ) m=O(n\log q) m=O(nlogq) | LWE样本个数 |
| L = 1 / 3 log n = 4 / 3 log k L=1/3\log n=4/3\log k L=1/3logn=4/3logk | 乘法深度 |
| χ \chi χ | 旧的噪声分布,噪声范数最多为 n n n |
| χ ^ \hat\chi χ^ | 新的噪声分布,噪声范数最多为 k k k |
- 生成密钥
| 参数 | 解释 |
|---|---|
| s L ∈ Z q n s_L\in \Z^n_q sL∈Zqn | 旧的私钥,有 n n n维 |
| s ^ ∈ Z p k \hat s\in \Z^k_p s^∈Zpk | 新的私钥,只有 k k k维 |
| ( A , b ) (A,b) (A,b) | 公钥, A ∈ Z q m × n A\in \Z_q^{m\times n} A∈Zqm×n, e ∈ χ m e\in \chi^m e∈χm, b ∈ Z q b\in \Z_q b∈Zq |
| Φ = { ϕ l , i , j , τ } \Phi=\{\phi_{l,i,j,\tau}\} Φ={ϕl,i,j,τ} | 重线性化密钥, l ∈ [ L ] l\in [L] l∈[L], 0 ≤ i ≤ j ≤ n 0\leq i\leq j \leq n 0≤i≤j≤n, τ ∈ { 1 , ⋯ , log q ⌋ } \tau\in\{1,\cdots, \log q \rfloor\} τ∈{1,⋯,logq⌋} |
| Φ ^ = { ϕ ^ i , τ } \hat \Phi=\{\hat \phi_{i,\tau}\} Φ^={ϕ^i,τ} | 约减密钥。对于 i ∈ [ n ] i\in[n] i∈[n],和每个比特位 τ ∈ { 1 , ⋯ , log q ⌋ } \tau\in\{1,\cdots, \log q \rfloor\} τ∈{1,⋯,logq⌋},从LWE分布中采样密钥 ϕ i , τ = ( a ^ i , τ , b ^ i , τ ) \phi_{i,\tau}=(\hat a_{i,\tau},\hat b_{i,\tau}) ϕi,τ=(a^i,τ,b^i,τ) 其中,向量 a ^ i , τ ∈ Z p k \hat a_{i,\tau}\in\Z_p^k a^i,τ∈Zpk和小噪声 e ^ i , τ ∈ χ ^ \hat e_{i,\tau}\in\hat\chi e^i,τ∈χ^通过随机采样得到,则 b ^ i , τ = < a ^ i , τ , s ^ > + e ^ i , τ + ⌊ p q ⋅ ( 2 τ ⋅ s L [ i ] ) ⌉ m o d p \hat b_{i,\tau}=\left<\hat a_{i,\tau},\hat s\right> + \hat e_{i,\tau} + \lfloor \frac{p}{q}\cdot(2^\tau\cdot s_L[i]) \rceil \mod p b^i,τ=⟨a^i,τ,s^⟩+e^i,τ+⌊qp⋅(2τ⋅sL[i])⌉modp |
- 自举(解密)
对于 L L L层同态乘法后的密文 c f = ( ( v , w ) , L ) c_f=((v,w),L) cf=((v,w),L)。令 h ^ i \hat h_{i} h^i为函数 ϕ ^ ( s L ) \hat\phi(s_L) ϕ^(sL)的系数,即:
ϕ ^ ( s L ) = p q ⋅ ( q + 1 2 ⋅ ( w − < v , s L > ) ) ( m o d p ) = ∑ i ∈ [ n ] h i ⋅ ( p q ⋅ s L [ i ] ) \begin{aligned} \hat\phi(s_L) &=\frac{p}{q}\cdot(\frac{q+1}{2}\cdot(w-\left< v,s_L\right>)) \pmod p\\ &=\sum_{i\in[n]}h_{i}\cdot(\frac{p}{q}\cdot s_L[i]) \end{aligned} ϕ^(sL)=qp⋅(2q+1⋅(w−⟨v,sL⟩))(modp)=i∈[n]∑hi⋅(qp⋅sL[i])具体而言有:
h ^ i = { q + 1 2 ⋅ w , if i = 0 − q + 1 2 ⋅ v [ i ] , if i ≥ 1 \hat h_{i}=\begin{cases} \frac{q+1}{2} \cdot w, & \text{if }& i=0\\ -\frac{q+1}{2} \cdot v[i], & \text{if }& i\geq 1 \\ \end{cases} h^i={2q+1⋅w,−2q+1⋅v[i],if if i=0i≥1将 h ^ i \hat h_{i} h^i转为二进制后有: h ^ i = ∑ τ = 0 ⌊ log q ⌋ h ^ i , τ ⋅ 2 τ \hat h_{i}=\sum_{\tau=0}^{\lfloor \log q\rfloor}\hat h_{i,\tau}\cdot 2^\tau h^i=τ=0∑⌊logq⌋h^i,τ⋅2τ则自举后的密文 c ^ = ( ( v ^ , w ^ ) , 0 ) \hat c = ((\hat v,\hat w),0) c^=((v^,w^),0)有 v ^ = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ a ^ i , τ m o d p \hat v = 2\cdot\sum_{i,\tau} \hat h_{i,\tau}\cdot \hat a_{i,\tau} \mod p v^=2⋅i,τ∑h^i,τ⋅a^i,τmodp w ^ = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ b ^ i , τ m o d p \hat w=2\cdot\sum_{i,\tau} \hat h_{i,\tau}\cdot \hat b_{i,\tau} \mod p w^=2⋅i,τ∑h^i,τ⋅b^i,τmodp其中, i ∈ [ n ] i\in [n] i∈[n], τ ∈ { 0 , ⋯ , ⌊ log q ⌋ } \tau\in \{0,\cdots,\lfloor \log q\rfloor\} τ∈{0,⋯,⌊logq⌋}。
三、算法分析
1. 正确性
1.1 Re-linearization 的正确性
- 解密的正确性
w − < v , s l > = ( b T r + μ ) − < A T r , s l > = b T r + μ − < r , A ⋅ s l > = b T r + μ − r T ⋅ A ⋅ s l = μ + r T ⋅ ( b − A s l ) = μ + r T ⋅ 2 e t o t a l \begin{aligned} w-\left< v,s_l\right>&=(b^Tr+\mu)-\left< A^Tr,s_l\right> \\ &=b^Tr+\mu-\left<r, A\cdot s_l\right> \\ &=b^Tr+\mu-r^T\cdot A\cdot s_l \\ &=\mu+r^T\cdot (b -As_l )\\ &=\mu+r^T\cdot 2e_{total}\\ \end{aligned} w−⟨v,sl⟩=(bTr+μ)−⟨ATr,sl⟩=bTr+μ−⟨r,A⋅sl⟩=bTr+μ−rT⋅A⋅sl=μ+rT⋅(b−Asl)=μ+rT⋅2etotal在模 q q q和模 2 2 2后为 μ \mu μ。 - 同态加法的正确性
w a d d − < v a d d , s l > = ∑ i w i − < ∑ i v i , s l > = ∑ i ( w i − < v i , s l > ) = ∑ i ( μ i + r i T ⋅ 2 e i t o t a l ) = ∑ i μ i + 2 ⋅ ∑ i r i T ⋅ e i t o t a l \begin{aligned} w_{\mathrm{add}} - \left< v_{\mathrm{add}},s_l \right> &= \sum_i w_i - \left< \sum_i v_i,s_l \right>\\ &= \sum_i ( w_i - \left< v_i,s_l \right>)\\ &= \sum_i (\mu_i+r_i^T\cdot 2e_i^{total})\\ &= \sum_i \mu_i+2\cdot \sum_i r_i^T\cdot e_i^{total}\\ \end{aligned} wadd−⟨vadd,sl⟩=i∑wi−⟨i∑vi,sl⟩=i∑(wi−⟨vi,sl⟩)=i∑(μi+riT⋅2eitotal)=i∑μi+2⋅i∑riT⋅eitotal在模 q q q和模 2 2 2后为 ∑ i μ i \sum_i \mu_i ∑iμi。 - 同态乘法的正确性
w m u l t − < v m u l t , s l + 1 > = ∑ i , j , τ h i , j , τ ⋅ b l + 1 , i , j , τ − < ∑ i , j , τ h i , j , τ ⋅ a l + 1 , i , j , τ , s l + 1 > = ∑ i , j , τ h i , j , τ ⋅ ( b l + 1 , i , j , τ − < a l + 1 , i , j , τ , s l + 1 > ) = ∑ i , j , τ h i , j , τ ⋅ ( 2 ⋅ e l + 1 , i , j , τ + 2 τ ⋅ s l [ i ] ⋅ s l [ j ] ) = ∑ i , j , τ h i , j , τ ⋅ 2 ⋅ e l + 1 , i , j , τ + ∑ i , j , τ ( h i , j , τ ⋅ 2 τ ) ⋅ s l [ i ] ⋅ s l [ j ] = ∑ i , j , τ h i , j , τ ⋅ 2 ⋅ e l + 1 , i , j + ∑ i , j h i , j ⋅ s l [ i ] ⋅ s l [ j ] = ∑ i , j , τ h i , j , τ ⋅ 2 ⋅ e l + 1 , i , j + ϕ ( s l ) = ∑ i , j , τ h i , j , τ ⋅ 2 ⋅ e l + 1 , i , j + ( w − < v , s l > ) ⋅ ( w ′ − < v ′ , s l > ) = ∑ i , j , τ h i , j , τ ⋅ 2 ⋅ e l + 1 , i , j + ( μ + r T ⋅ 2 e t o t a l ) ⋅ [ μ ′ + ( r ′ ) T ⋅ 2 e t o t a l ′ ] = μ μ ′ + 2 ⋅ [ μ ⋅ ( r ′ ) T ⋅ e t o t a l ′ + μ ′ ⋅ r T ⋅ e t o t a l + 2 ⋅ ( r ′ ) T ⋅ e t o t a l ′ ⋅ r T ⋅ e t o t a l + ∑ i , j , τ h i , j , τ ⋅ e l + 1 , i , j ] \begin{aligned} w_{\mathrm{mult}} - \left< v_{\mathrm{mult}},s_{l+1} \right> &= \sum_{i,j,\tau} h_{i,j,\tau}\cdot b_{l+1,i,j,\tau} - \left< \sum_{i,j,\tau}h_{i,j,\tau}\cdot a_{l+1,i,j,\tau},s_{l+1} \right> \\ &= \sum_{i,j,\tau} h_{i,j,\tau}\cdot (b_{l+1,i,j,\tau} - \left< a_{l+1,i,j,\tau},s_{l+1} \right>) \\ &= \sum_{i,j,\tau} h_{i,j,\tau}\cdot (2\cdot e_{l+1,i,j,\tau} + 2^\tau\cdot s_{l}[i]\cdot s_{l}[j]) \\ &= \sum_{i,j,\tau} h_{i,j,\tau}\cdot 2\cdot e_{l+1,i,j,\tau} + \sum_{i,j,\tau}(h_{i,j,\tau}\cdot 2^\tau)\cdot s_{l}[i]\cdot s_{l}[j] \\ &= \sum_{i,j,\tau} h_{i,j,\tau}\cdot 2\cdot e_{l+1,i,j} + \sum_{i,j}h_{i,j}\cdot s_{l}[i]\cdot s_{l}[j] \\ &= \sum_{i,j,\tau} h_{i,j,\tau}\cdot 2\cdot e_{l+1,i,j} +\phi(s_{l}) \\ &= \sum_{i,j,\tau} h_{i,j,\tau}\cdot 2\cdot e_{l+1,i,j} +(w-\left< v,s_l\right>)\cdot (w'-\left< v',s_l\right>) \\ &= \sum_{i,j,\tau} h_{i,j,\tau}\cdot 2\cdot e_{l+1,i,j} +(\mu+r^T\cdot 2e_{total})\cdot [\mu'+(r')^T\cdot 2e'_{total}] \\ &=\mu\mu'+2\cdot[\mu\cdot (r')^T\cdot e'_{total}+\mu'\cdot r^T\cdot e_{total}+2\cdot (r')^T\cdot e'_{total}\cdot r^T\cdot e_{total}+\sum_{i,j,\tau} h_{i,j,\tau}\cdot e_{l+1,i,j}] \end{aligned} wmult−⟨vmult,sl+1⟩=i,j,τ∑hi,j,τ⋅bl+1,i,j,τ−⟨i,j,τ∑hi,j,τ⋅al+1,i,j,τ,sl+1⟩=i,j,τ∑hi,j,τ⋅(bl+1,i,j,τ−⟨al+1,i,j,τ,sl+1⟩)=i,j,τ∑hi,j,τ⋅(2⋅el+1,i,j,τ+2τ⋅sl[i]⋅sl[j])=i,j,τ∑hi,j,τ⋅2⋅el+1,i,j,τ+i,j,τ∑(hi,j,τ⋅2τ)⋅sl[i]⋅sl[j]=i,j,τ∑hi,j,τ⋅2⋅el+1,i,j+i,j∑hi,j⋅sl[i]⋅sl[j]=i,j,τ∑hi,j,τ⋅2⋅el+1,i,j+ϕ(sl)=i,j,τ∑hi,j,τ⋅2⋅el+1,i,j+(w−⟨v,sl⟩)⋅(w′−⟨v′,sl⟩)=i,j,τ∑hi,j,τ⋅2⋅el+1,i,j+(μ+rT⋅2etotal)⋅[μ′+(r′)T⋅2etotal′]=μμ′+2⋅[μ⋅(r′)T⋅etotal′+μ′⋅rT⋅etotal+2⋅(r′)T⋅etotal′⋅rT⋅etotal+i,j,τ∑hi,j,τ⋅el+1,i,j]在模 q q q和模 2 2 2后为 μ μ ′ \mu\mu' μμ′。
1.2 Dimension-modulus Reduction的正确性
w ^ − < v ^ , s ^ > = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ b ^ i , τ − < 2 ⋅ ∑ i , τ h ^ i , τ ⋅ a ^ i , τ , s ^ > ( m o d p ) = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ ( b ^ i , τ − < a ^ i , τ , s ^ > ) = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ ( e ^ i , τ + ⌊ p q ⋅ ( 2 τ ⋅ s L [ i ] ) ⌉ ) = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ e ^ i , τ + 2 ⋅ ∑ i h ^ i ⋅ ⌊ p q ⋅ s L [ i ] ⌉ = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ e ^ i , τ + 2 ⋅ ϕ ^ ( s L ) = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ e ^ i , τ + p ⋅ ( q + 1 ) q ( w − < v , s L > ) = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ e ^ i , τ + p ⋅ ( q + 1 ) q ( 2 ⋅ e t o t a l + μ + k q ) ( where k ∈ Z ) = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ e ^ i , τ + 2 p ⋅ ( q + 1 ) q ⋅ e t o t a l + p ⋅ ( q + 1 ) q μ + k p ⋅ ( q + 1 ) = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ e ^ i , τ + ( 2 p ⋅ e t o t a l + 2 p q ⋅ e t o t a l ) + ( p + 1 + p q − 1 ) ⋅ μ = 2 ⋅ ∑ i , τ h ^ i , τ ⋅ e ^ i , τ + 2 p q ⋅ e t o t a l + p μ + μ + ( p q − 1 ) ⋅ μ = μ + 2 ⋅ ( ∑ i , τ h ^ i , τ ⋅ e ^ i , τ + p q ⋅ e t o t a l + p − q 2 q ⋅ μ ) \begin{aligned} \hat w - \left< \hat v,\hat s \right> &= 2\cdot\sum_{i,\tau} \hat h_{i,\tau}\cdot \hat b_{i,\tau} - \left< 2\cdot\sum_{i,\tau} \hat h_{i,\tau}\cdot \hat a_{i,\tau},\hat s \right> \pmod p\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot ( \hat b_{i,\tau} - \left< \hat a_{i,\tau},\hat s \right>)\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot \bigg(\hat e_{i,\tau} + \lfloor \frac{p}{q}\cdot(2^\tau\cdot s_L[i]) \rceil\bigg)\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot \hat e_{i,\tau} +2\cdot \sum_{i}\hat h_{i}\cdot \lfloor \frac{p}{q}\cdot s_L[i] \rceil\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot \hat e_{i,\tau} +2\cdot \hat\phi(s_L)\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot \hat e_{i,\tau} +\frac{p\cdot(q+1)}{q}(w-\left< v,s_L \right>)\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot \hat e_{i,\tau} +\frac{p\cdot(q+1)}{q}(2\cdot e_{total}+\mu+kq) & (\text{where }k\in\Z)\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot \hat e_{i,\tau} +\frac{2p\cdot(q+1)}{q}\cdot e_{total}+\frac{p\cdot(q+1)}{q}\mu+kp\cdot(q+1)\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot \hat e_{i,\tau} +\bigg(2p\cdot e_{total}+ \frac{2p}{q}\cdot e_{total}\bigg)+\bigg(p+1 + \frac{p}{q}-1\bigg)\cdot \mu\\ &=2\cdot \sum_{i,\tau}\hat h_{i,\tau}\cdot \hat e_{i,\tau} + \frac{2p}{q}\cdot e_{total}+p \mu+ \mu +\bigg( \frac{p}{q}-1\bigg)\cdot \mu\\ &= \mu +2\cdot \bigg(\sum_{i,\tau}\hat h_{i,\tau}\cdot \hat e_{i,\tau} + \frac{p}{q}\cdot e_{total}+\frac{p-q}{2q}\cdot \mu\bigg)\\ \end{aligned} w^−⟨v^,s^⟩=2⋅i,τ∑h^i,τ⋅b^i,τ−⟨2⋅i,τ∑h^i,τ⋅a^i,τ,s^⟩(modp)=2⋅i,τ∑h^i,τ⋅(b^i,τ−⟨a^i,τ,s^⟩)=2⋅i,τ∑h^i,τ⋅(e^i,τ+⌊qp⋅(2τ⋅sL[i])⌉)=2⋅i,τ∑h^i,τ⋅e^i,τ+2⋅i∑h^i⋅⌊qp⋅sL[i]⌉=2⋅i,τ∑h^i,τ⋅e^i,τ+2⋅ϕ^(sL)=2⋅i,τ∑h^i,τ⋅e^i,τ+qp⋅(q+1)(w−⟨v,sL⟩)=2⋅i,τ∑h^i,τ⋅e^i,τ+qp⋅(q+1)(2⋅etotal+μ+kq)=2⋅i,τ∑h^i,τ⋅e^i,τ+q2p⋅(q+1)⋅etotal+qp⋅(q+1)μ+kp⋅(q+1)=2⋅i,τ∑h^i,τ⋅e^i,τ+(2p⋅etotal+q2p⋅etotal)+(p+1+qp−1)⋅μ=2⋅i,τ∑h^i,τ⋅e^i,τ+q2p⋅etotal+pμ+μ+(qp−1)⋅μ=μ+2⋅(i,τ∑h^i,τ⋅e^i,τ+qp⋅etotal+2qp−q⋅μ)(where k∈Z)在模 p p p和模 2 2 2后为 μ \mu μ。
2. 安全性
DLWE n , m , q , χ \text{DLWE}_{n,m,q,\chi} DLWEn,m,q,χ:判断 m m m个样本来自LWE分布还是均匀分布。
DLWE n , q , χ \text{DLWE}_{n,q,\chi} DLWEn,q,χ:判断任意数量的样本来自LWE分布还是均匀分布。
如果 DLWE n , m , q , χ \text{DLWE}_{n,m,q,\chi} DLWEn,m,q,χ问题和 DLWE n , q , χ \text{DLWE}_{n,q,\chi} DLWEn,q,χ问题都是 ( t , ϵ ) (t, \epsilon) (t,ϵ)-困难的,那么BV11方案是 ( t − poly ( κ ) , 2 ( L + 1 ) ⋅ ( 2 − κ + ϵ ) ) (t-\text{poly}(\kappa), 2(L+1)\cdot(2^{-\kappa}+\epsilon)) (t−poly(κ),2(L+1)⋅(2−κ+ϵ))-CPA安全的。原文的结论如下:

假定有一个IND-CPA攻击者 A \mathcal{A} A。下面利用混合论证,证明该方案的安全性:
- 定义攻击者的优势
首先,思考攻击者 A \mathcal{A} A攻击成功的概率,即猜测值 b ′ b' b′ 和真实值 b b b 一样的概率,如下:
P ( b ′ = b ) = P ( b = 0 ) ⋅ P ( b ′ = 0 ∣ b = 0 ) + P ( b = 1 ) ⋅ P ( b ′ = 1 ∣ b = 1 ) = 1 2 ⋅ [ 1 − P ( b ′ = 1 ∣ b = 0 ) ] + 1 2 ⋅ P ( b ′ = 1 ∣ b = 1 ) = 1 2 + 1 2 ⋅ [ P ( b ′ = 1 ∣ b = 0 ) − P ( b ′ = 1 ∣ b = 1 ) ] \begin{aligned} P(b'=b) &=P(b=0)\cdot P(b'=0|b=0)+P(b=1)\cdot P(b'=1|b=1)\\ &=\frac{1}{2}\cdot [1-P(b'=1|b=0)]+\frac{1}{2}\cdot P(b'=1|b=1)\\ &=\frac{1}{2}+\frac{1}{2}\cdot [P(b'=1|b=0)- P(b'=1|b=1)]\\ \end{aligned} P(b′=b)=P(b=0)⋅P(b′=0∣b=0)+P(b=1)⋅P(b′=1∣b=1)=21⋅[1−P(b′=1∣b=0)]+21⋅P(b′=1∣b=1)=21+21⋅[P(b′=1∣b=0)−P(b′=1∣b=1)]其中, A \mathcal{A} A在游戏 H H H中获胜的优势 Adv H \text{Adv}_{H} AdvH被定义为概率公式里中括号那部分,即:
Adv H [ A ] = P ( b ′ = 1 ∣ b = 0 ) − P ( b ′ = 1 ∣ b = 1 ) \text{Adv}_{H}[\mathcal{A}]=P(b'=1|b=0)- P(b'=1|b=1) AdvH[A]=P(b′=1∣b=0)−P(b′=1∣b=1)此时, Adv H \text{Adv}_{H} AdvH越大,攻击成功率越高,则优势越大。 - 定义攻击者的知识:攻击者有一个LWE Oracle,该Oracle可能生成LWE样本,也可能生成均匀样本;攻击者已知密文,以及加密所用的公钥、重线性化密钥、约减密钥。
- 定义混合游戏
| 混合 游戏 |
描述 |
|---|---|
| H ^ L + 1 \hat H_{L+1} H^L+1 | 攻击者 A \mathcal{A} A根据真实密文和密钥(公钥、重线性化密钥、约减密钥)所生成的密文猜测真实明文 |
| H L + 1 H_{L+1} HL+1 | 攻击者 B ^ \mathcal{\widehat{\mathcal{B}}} B 仅将约减密钥替换为随机数。具体而言,攻击者 B ^ \widehat{\mathcal{B}} B 向LWE Oracle申请一个样本,并用该样本替换约减密钥。然后,攻击者 B ^ \widehat{\mathcal{B}} B 用替换后的密钥加密一个随机比特,并交给攻击者 A \mathcal{A} A猜测。如果猜对了,攻击者 B ^ \widehat{\mathcal{B}} B 认为密文来自LWE分布,否则为均匀样本。 |
| H l ∈ [ L ] H_{l\in [L]} Hl∈[L] | 攻击者 B ^ l \widehat{\mathcal{B}}_l B l将约减密钥、前第 l l l层所有重线性化密钥 { ϕ λ , i , j , τ } λ ≤ l , i , j , τ \{\phi_{\lambda,i,j,\tau}\}_{\lambda\leq l,i,j,\tau} {ϕλ,i,j,τ}λ≤l,i,j,τ替换为随机数。攻击者 B ^ l \widehat{\mathcal{B}}_l B l向LWE Oracle申请一个样本,并用该样本替换重线性化密钥链中第 l + 1 l+1 l+1层密钥。攻击者 B ^ l \widehat{\mathcal{B}}_l B l用替换后的密钥加密一个随机比特,并交给攻击者 A \mathcal{A} A猜测。如果猜对了,攻击者 B ^ l \widehat{\mathcal{B}}_l B l认为密文来自LWE分布,否则为均匀样本。 |
| H 0 H_0 H0 | 攻击者将约减密钥、所有重线性化密钥、公钥替换为随机数,并根据替换后的密钥生成的密文猜测真实明文 |
| H rand H_\text{rand} Hrand | 攻击者将约减密钥、所有重线性化密钥、公钥、密文替换为随机数,并猜测真实明文 |
- 计算每个游戏下的优势
对于游戏 H ^ L + 1 \hat H_{L+1} H^L+1:根据优势的定义,我们假设 Adv H ^ L + 1 [ A ] = δ \text{Adv}_{\hat H_{L+1}}[\mathcal{A}]= \delta AdvH^L+1[A]=δ。
对于游戏 H l H_{l} Hl:如果Oracle生成均匀样本, H l H_{l} Hl 分布与 H l + 1 H_{l+1} Hl+1 相同,此时攻击成功的概率为
P ( H l ∈ A s , χ ∣ H l ∈ U ) = 1 2 + 1 2 ⋅ [ P l + 1 ( b ′ = 1 ∣ b = 0 ) − P l + 1 ( b ′ = 1 ∣ b = 1 ) ] = 1 2 + 1 2 ⋅ Adv H l + 1 [ A ] \begin{aligned}P(H_{l}\in A_{s,\chi}|H_{l}\in U)&=\frac{1}{2}+\frac{1}{2}\cdot [P_{l+1}(b'=1|b=0)- P_{l+1}(b'=1|b=1)]\\&=\frac{1}{2}+\frac{1}{2}\cdot \text{Adv}_{ H_{l+1}}[\mathcal{A}]\end{aligned} P(Hl∈As,χ∣Hl∈U)=21+21⋅[Pl+1(b′=1∣b=0)−Pl+1(b′=1∣b=1)]=21+21⋅AdvHl+1[A]如果生成LWE样本,分布仍为 H l H_{l} Hl,此时攻击成功的概率为
P ( H l ∈ A s , χ ∣ H l ∈ A s , χ ) = 1 2 + 1 2 ⋅ [ P l ( b ′ = 1 ∣ b = 0 ) − P l ( b ′ = 1 ∣ b = 1 ) ] = 1 2 + 1 2 ⋅ Adv H l [ A ] \begin{aligned}P(H_{l}\in A_{s,\chi}|H_{l}\in A_{s,\chi})&=\frac{1}{2}+\frac{1}{2}\cdot [P_{l}(b'=1|b=0)- P_{l}(b'=1|b=1)]\\&=\frac{1}{2}+\frac{1}{2}\cdot \text{Adv}_{ H_{l}}[\mathcal{A}]\end{aligned} P(Hl∈As,χ∣Hl∈As,χ)=21+21⋅[Pl(b′=1∣b=0)−Pl(b′=1∣b=1)]=21+21⋅AdvHl[A] 此时该游戏的区分优势为
DLWE Adv [ B ^ ] = ∣ P ( H l ∈ A s , χ ∣ H l ∈ U ) − P ( H l ∈ A s , χ ∣ H l ∈ A s , χ ) ∣ = 1 2 ⋅ ∣ Adv H l [ A ] − Adv H l + 1 [ A ] ∣ \begin{aligned} \text{DLWE Adv}[\widehat{\mathcal{B}}] &= |P(H_{l}\in A_{s,\chi}|H_{l}\in U)- P(H_{l}\in A_{s,\chi}|H_{l}\in A_{s,\chi})| \\ &=\frac{1}{2}\cdot |\text{Adv}_{ H_{l}}[\mathcal{A}] -\text{Adv}_{H_{l+1}}[\mathcal{A}]|\\ \end{aligned} DLWE Adv[B ]=∣P(Hl∈As,χ∣Hl∈U)−P(Hl∈As,χ∣Hl∈As,χ)∣=21⋅∣AdvHl[A]−AdvHl+1[A]∣
对于游戏 H rand H_\text{rand} Hrand:所有元素都是均匀随机,与消息无关,因此优势为0。
先解释一下文章中在定义不同混合游戏的优势时,所用到的符号表示: μ \mu μ表示真实明文; SH.Enc p k ( μ ) \text{SH.Enc}_{pk}(\mu) SH.Encpk(μ) 是按规矩一步一步生成的真实密文; A ( ⋅ ) \mathcal{A}(\cdot) A(⋅)表示攻击者 A \mathcal{A} A在已知一定知识的情况下猜测对应明文,攻击知识即输入 ( ⋅ ) (\cdot) (⋅),例如 A ( p k , SH.Enc p k ( μ ) ) \mathcal{A}(pk,\text{SH.Enc}_{pk}(\mu)) A(pk,SH.Encpk(μ))表示攻击者 A \mathcal{A} A在已知公钥和真实密文的情况下猜测对应明文。
| 混合游戏 | 优势 |
|---|---|
| H ^ L + 1 \hat H_{L+1} H^L+1 | Pr [ A ( p k , SH.Enc p k ( μ 0 ) ) = 1 ] − Pr [ A ( p k , SH.Enc p k ( μ 1 ) ) = 1 ] ∣ = δ \Pr[\mathcal{A}(pk, \text{SH.Enc}_{pk}(\mu_0)) = 1] - \Pr[\mathcal{A}(pk, \text{SH.Enc}_{pk}(\mu_1)) = 1] | = \delta Pr[A(pk,SH.Encpk(μ0))=1]−Pr[A(pk,SH.Encpk(μ1))=1]∣=δ |
| H L + 1 H_{L+1} HL+1 | DLWE k , p , χ ^ Adv [ B ^ ] ≥ 1 2 ⋅ ∣ Adv H ^ l + 1 [ A ] − Adv H l + 1 [ A ] ∣ \text{DLWE}_{k,p,\hat\chi}\text{Adv}[\widehat{\mathcal{B}}] \geq \frac{1}{2} \cdot | \text{Adv}_{\hat H_{l+1}}[\mathcal{A}] - \text{Adv}_{H_{l+1}}[\mathcal{A}] | DLWEk,p,χ^Adv[B ]≥21⋅∣AdvH^l+1[A]−AdvHl+1[A]∣ |
| H l ∈ [ L ] H_{l\in [L]} Hl∈[L] | DLWE n , q , χ Adv [ B ^ l ] = 1 2 ⋅ ∣ Adv H l [ A ] − Adv H l + 1 [ A ] ∣ \text{DLWE}_{n,q,\chi}\text{Adv}[\widehat{\mathcal{B}}_l] = \frac{1}{2} \cdot | \text{Adv}_{H_{l}}{[A]} - \text{Adv}_{H_{l+1}}{[A]} | DLWEn,q,χAdv[B l]=21⋅∣AdvHl[A]−AdvHl+1[A]∣ |
| H 0 H_0 H0 | DLWE n , q , χ Adv [ B ^ l ] = 1 2 ⋅ ∣ Adv H 1 [ A ] − Adv H 0 [ A ] ∣ \text{DLWE}_{n,q,\chi}\text{Adv}[\widehat{\mathcal{B}}_l] = \frac{1}{2} \cdot | \text{Adv}_{H_{1}}{[A]} - \text{Adv}_{H_{0}}{[A]} | DLWEn,q,χAdv[B l]=21⋅∣AdvH1[A]−AdvH0[A]∣ |
| H rand H_\text{rand} Hrand | Adv H rand [ A ] = 0 \text{Adv}_{H_\text{rand}}[\mathcal{A}]=0 AdvHrand[A]=0 |
- 计算总优势
根据 Leftover hash lemma,样本与均匀随机统计接近:
∣ Adv H 0 [ A ] − Adv H rand [ A ] ∣ ≤ 2 − κ |\text{Adv}_{H_0}[\mathcal{A}]-\text{Adv}_{H_\text{rand}}[\mathcal{A}]| \leq 2^{-\kappa} ∣AdvH0[A]−AdvHrand[A]∣≤2−κ
则将所有游戏中的优势关系相加有:
Adv CPA [ A ] = Adv H ^ L + 1 [ A ] − Adv H rand [ A ] ≤ 2 − κ + 2 ⋅ ( DLWE k , p , χ ^ Adv [ B ^ ] + ∑ l ∈ [ L ] DLWE n , q , χ Adv [ B ^ l ] ) \begin{aligned} \text{Adv}_{\text{CPA}}[\mathcal{A}]&=\text{Adv}_{\hat H_{L+1}}[\mathcal{A}]-\text{Adv}_{H_\text{rand}}[\mathcal{A}] \\ &\leq 2^{-\kappa} + 2\cdot(\text{DLWE}_{k,p,\hat\chi}\text{Adv}[\widehat{\mathcal{B}}]+\sum_{l\in[L]}\text{DLWE}_{n,q,\chi}\text{Adv}[\widehat{\mathcal{B}}_l]) \end{aligned} AdvCPA[A]=AdvH^L+1[A]−AdvHrand[A]≤2−κ+2⋅(DLWEk,p,χ^Adv[B ]+l∈[L]∑DLWEn,q,χAdv[B l])
3. 同态性
😛这章部分证明看懂了,但懒得打字了,要是以后用到了再填坑
4. 全同态性
😐这章部分证明还有没打通的地方,就不详解了
通过Gentry的自举定理,BV11可以转为全同态方案。文章中首先证明了BV11的解密电路足够浅,可以由深度为 O ( log k + log log p ) O(\log k + \log \log p) O(logk+loglogp)的算术电路实现;其次证明了方案可自举,即存在常数 C C C,当设置 n = k C / ϵ n = k^{C/\epsilon} n=kC/ϵ 时,BV11可以同态计算自己的增强解密电路;最后,利用Gentry自举定理,可以获得层次全同态加密,若方案满足弱循环安全性,则获得真正的完全同态加密。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)