21.模型微调——LLM的PEFT微调方法
PEFT(参数高效微调)方法通过仅微调少量额外参数,显著降低了大模型在下游任务中的计算和存储成本。主要包括三类方法:1)Prefix-Tuning通过在输入前添加可训练前缀向量;2)Adapter-Tuning在模型层间插入小型适配器模块;3)LoRA采用低秩分解矩阵近似参数更新。其中LoRA冻结原始权重,注入可训练的低秩矩阵,是目前效果最优的通用方法。HuggingFace的PEFT库实现了这些
PEFT(大模型参数高效微调)
参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)也称为轻量化微调 ,仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本 。
该方法可以使 PLM 高效适应各种下游应用任务,而无需微调预训练模型的所有参数,且让大模型在消费级硬件上进行全量微调(Full Fine-Tuning)变得可行。
目前应用较多的PEFT方法主要分为三大类:
- Prefix/Prompt-Tuning :在模型的输入或隐层添加 k个额外可训练的前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练这些前缀参数;
- Adapter-Tuning :将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为 adapter(适配器),下游任务微调时也只训练这些适配器参数;
- LoRA :通过学习小参数的低秩矩阵来近似模型权重矩阵 W的参数更新,训练时只优化低秩矩阵参数;
此外Huggface 开源的一个高效微调大模型的库PEFT,该算法库支持上述三类方法,可以直接调用。
1. Prefix Tuning
Prefix-Tuning 在模型输入前添加一个连续的且任务特定的向量序列(continuous task-specific vectors),称之为前缀(prefix)。前缀被视为一系列“虚拟 tokens”,但是它由不对应于真实 tokens 的自由参数组成。与更新所有 PLM 参数的全量微调不同,Prefix-Tuning 固定 PLM 的所有参数,只更新优化特定任务的 prefix。因此,在生产部署时,只需要存储一个大型 PLM 的副本和一个学习到的特定任务的 prefix,每个下游任务只产生非常小的额外的计算和存储开销。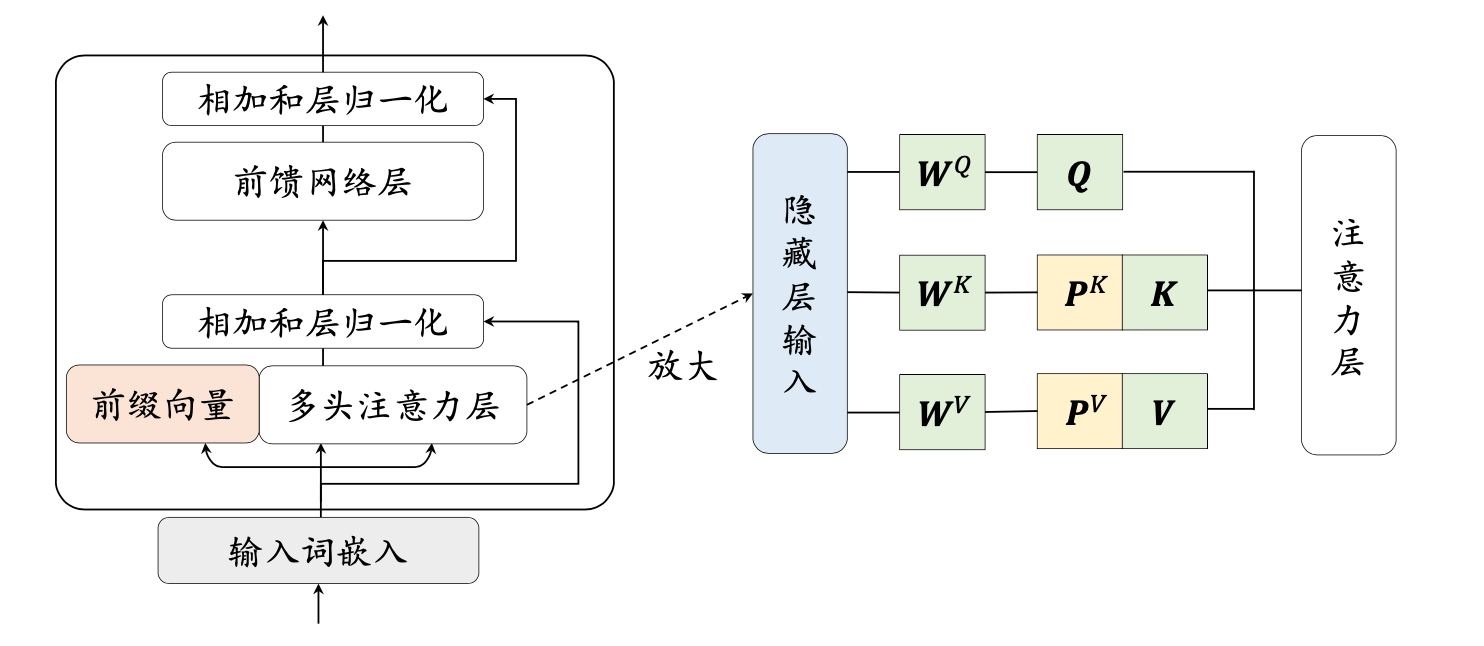
Fine-tuning 更新所有 PLM 参数,并且需要为每个任务存储完整的模型副本。Prefix-tuning 冻结了 PLM 参数并且只优化了 prefix。因此,只需要为每个任务存储特定 prefix,使 Prefix-tuning 模块化且节省存储空间。
2. Adapter Tuning
与 Prefix Tuning 和 Prompt Tuning 这类在输入前可训练添加 prompt embedding 参数来以少量参数适配下游任务,Adapter Tuning 则是在预训练模型内部的网络层之间添加新的网络层或模块来适配下游任务 。
假设预训练模型函数表示为Ø_w(x),对于 Adapter Tuning ,添加适配器之后模型函数更新为Ø_{w,w_0}(x), w是预训练模型的参数, w_0是新添加的适配器的参数,在训练过程中, w被固定,只有 w_0被更新。|w_0|<<|w| ,这使得不同下游任务只需要添加少量可训练的参数即可,节省计算和存储开销,同时共享大规模预训练模型。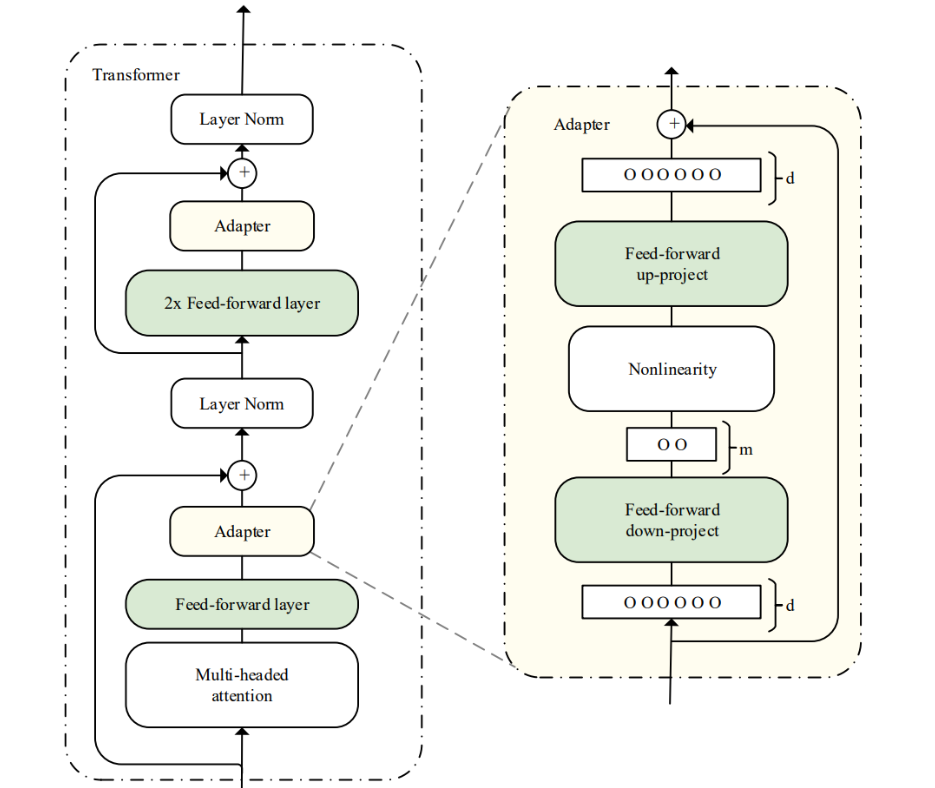
Series Adapter的适配器结构和与 Transformer 的集成如上图所示。适配器模块被添加到每个 Transformer 层两次:多头注意力映射之后和两层前馈神经网络之后。适配器是一个 bottleneck(瓶颈)结构的模块,由一个两层的前馈神经网络(由向下投影矩阵、非线性函数和向上投影矩阵构成)和一个输出输出之间的残差连接组成。
3. LoRA 微调
大语言模型中包含大量的线性变换层,其中参数矩阵的维度通常很高。研究人员发现模型在针对特定任务进行适配时,参数矩阵往往是过参数化(Over-parametrized)的,其存在一个较低的内在秩。为了解决这一问题,LoRA (Low-Rank Adaptation)提出在预训练模型的参数矩阵上添加低秩分解矩阵来近似每层的参数更新,从而减少适配下游任务所需要训练的参数。
给定参数 W 采用低秩分解W=W0+ΔW=W0+A⋅BT其中 A∈RH×R,B∈RR×H,R≪H .在实际使用中,引入了合并因子 αW=W0+ΔW=W0+αRA⋅BT矩阵 AB的参数是可训练的,总的参数量由原来的H2变为 2HR,参数大幅降低了。
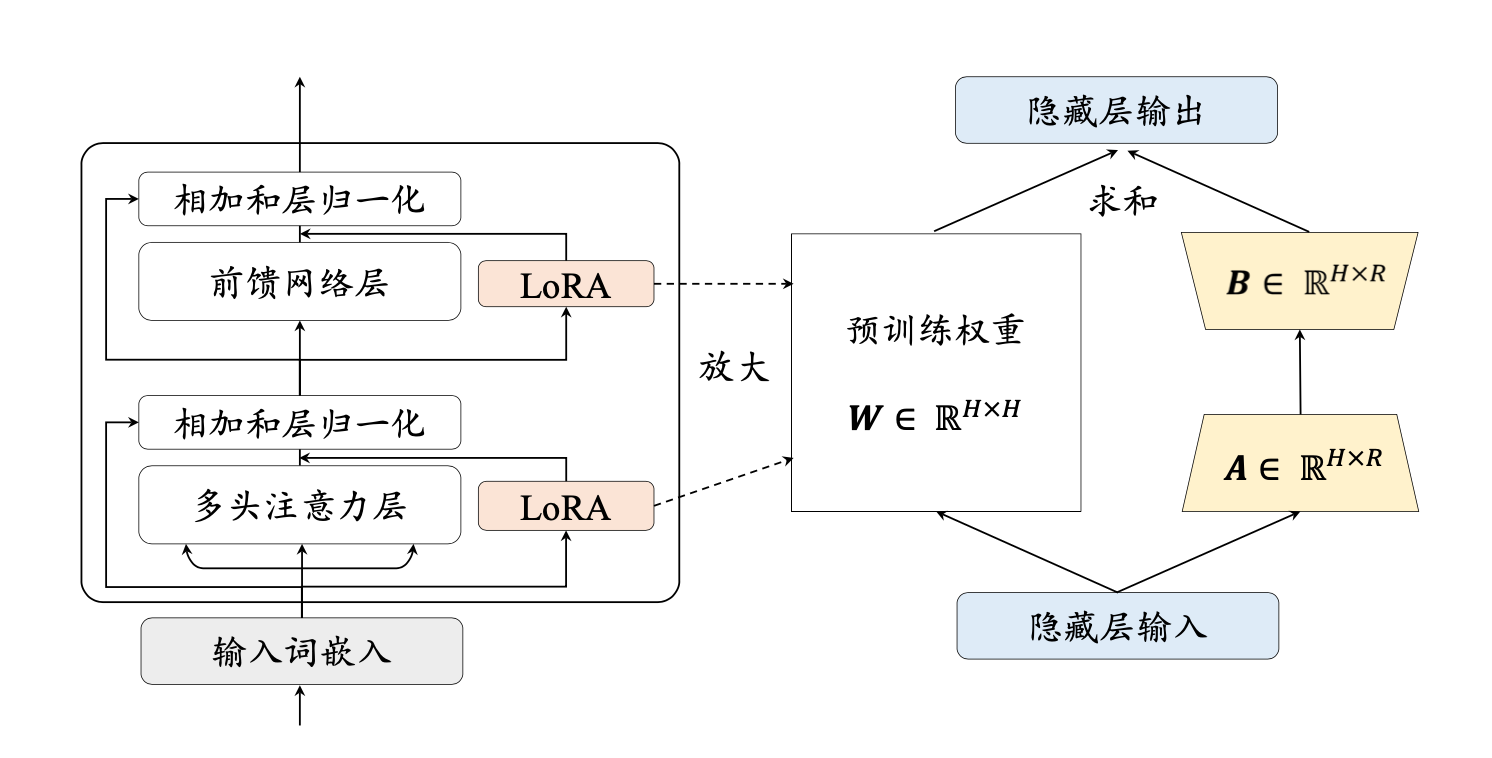
基本原理:LoRA技术冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵),即在模型的Linear层的旁边增加一个“旁支”A和B。其中,A将数据从d维降到r维,这个r是LoRA的秩,是一个重要的超参数;B将数据从r维升到d维,B部分的参数初始为0。模型训练结束后,需要将A+B部分的参数与原大模型的参数合并在一起使用。
python伪代码
input_dim = 768 # 例如,预训练模型的隐藏大小
output_dim = 768 # 例如,层的输出大小
rank = 8 # 低秩适应的等级'r'
W = ... # 来自预训练网络的权重,形状为 input_dim x output_dim
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA权重A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA权重B初始化LoRA权重
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)
def regular_forward_matmul(x, W):
h = x @ W
return h
def lora_forward_matmul(x, W, W_A, W_B):
h = x @ W # 常规矩阵乘法
h += x @ (W_A @ W_B) * alpha # 使用缩放的LoRA权重,alpha缩放因子
return h
LoRA方法是目前最通用、同时也是效果最好的微调方法之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)