Agentic AI TASK02 Reflection Design and Pattern
直接生成”是AI最基础、最直观的工作方式,也常被称为“零样本提示”(Zero-shot Prompting)。特点: 简单、快速、一步到位。它不提供任何中间反馈或修正的机会。术语解释: “零样本提示”中的“零样本”指的是在提示中没有提供任何输入-输出示例。这与“单样本提示”(One-shot)和“少样本提示”(Few-shot)形成对比。零样本 (Zero-shot): 写一个关于黑洞的文章(无示
反思如何改进任务输出
“反思模式”是经常使用且实现起来“出奇地简单”的一种方法。
将这一过程比作人类写作:我们写完初稿后,会回头阅读、发现问题(如模糊不清、拼写错误、遗漏署名),然后进行修改,最终得到一份更完善的文稿。
核心类比: 人类反思 → AI反思。这不仅是模仿,更是赋予AI一种自我优化的能力。
案例1:以写邮件为例:
人类反思流程:从初稿到定稿
人类反思流程:从初稿到定稿 Ng 自己写给 Tommy 的邮件为例,演示人类的反思过程:
- 初稿 (Email V1):
- 问题1:模糊性 - “next month” 不够具体,Tommy 无法确定是哪几天。
- 问题2:拼写错误 - “fre” 应为 “free”。
- 问题3:不完整 - 邮件没有署名。
- 反思与改进 (Email V2):
- 改进点: 明确了日期范围(5th-7th),修正了拼写错误,并添加了署名。
AI反思流程:硬编码的"提示-反思"工作流
- 第一阶段:生成初稿 (Write first draft)
- 向 LLM 发送一个初始提示(Prompt),例如:“Write an email…”。
- LLM 根据提示生成第一个版本的输出(Email V1)。
- 第二阶段:反思与改进 (Reflect and write improved second draft)
- 将第一版输出(Email V1)作为新的输入,再次发送给 LLM(可以是同一个模型,也可以是另一个专门用于推理的模型)。
- 这次的提示语会不同,例如:“请反思这份邮件草稿,并写出一个改进版。”
- LLM 基于对自身初稿的分析,生成最终的、质量更高的第二版输出(Email V2)。
关键点: 这个流程是“硬编码”的,即工程师预先设计好整个步骤,而不是让模型自主决定何时反思。这是一种可靠且易于实现的工程化方法。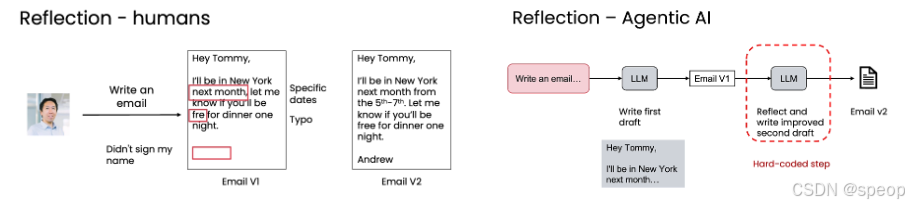
案例2:代码编写
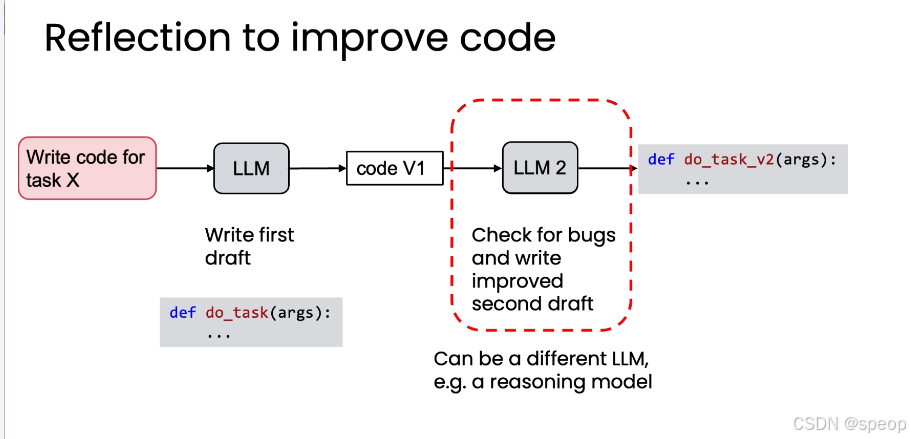
- 基础版:模型自省
- 步骤1: 提示 LLM 编写一段代码(code V1)。
- 步骤2: 将 code V1 再次输入给 LLM,提示其“检查代码中的错误并写出改进版”。
- 结果: 得到修复了潜在 bug 的 code V2。
- 进阶版:利用“思考模型” (Reasoning Models)去“检查代码中的错误并写出改进版”
- 不同的 LLM 有不同的专长。可以使用一个擅长快速生成的模型来写初稿,再用一个“思考模型”(Thinking Model)、更擅长逻辑推理和错误排查的模型来进行反思和改进。
- 这种组合能发挥各自的优势,达到“1+1>2”的效果。
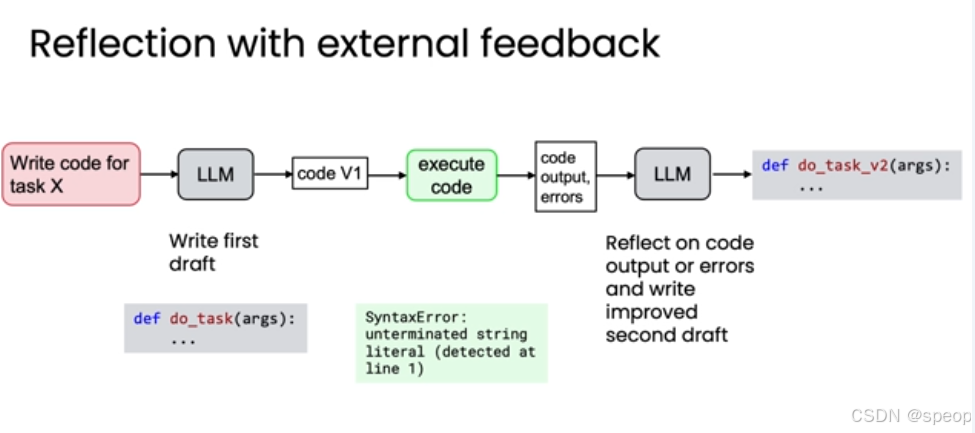
- 终极形态:结合外部反馈的反思
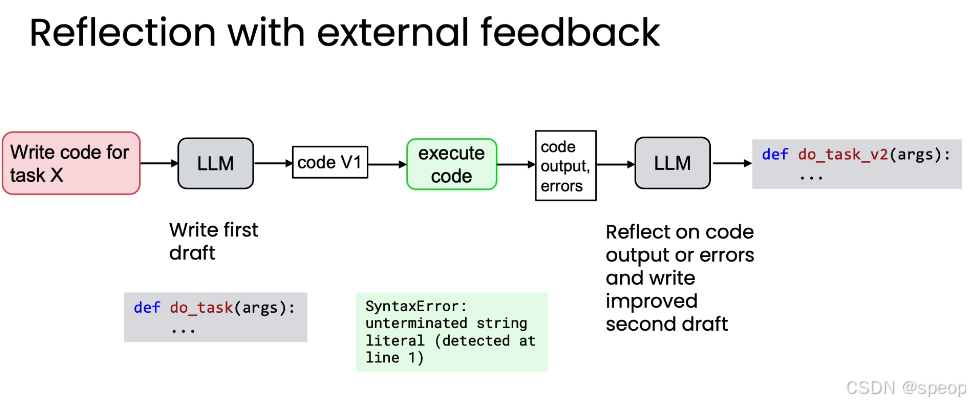
反思最强大的形式是结合外部反馈。仅仅让模型“内省”是有限的,而引入来自模型之外的新信息,则能带来质的飞跃。
以上面的代码为例做结合外部反馈的反思:
- 生成初稿: LLM 生成 code V1。
- 执行代码: 在安全的沙盒环境中运行 code V1。
- 获取外部反馈: 系统捕获代码的实际输出(Output)和任何错误信息(Errors),例如 SyntaxError: unterminated string literal。
- 反思与改进: **将 code V1、Output 和 Errors 一起作为输入,[这里可能需要的token比较多]**交给 LLM 进行反思,要求其根据这些具体的、客观的反馈来重写代码。
- 获得终稿: LLM 基于真实的执行结果,修正错误,生成功能正确的 code V2。
总结:
- 反思不是魔法,而是工程实践: 它不能保证模型每次都100%正确,但能带来“适度的性能提升”,是性价比极高的优化手段。
- 外部反馈是关键: 反思的力量在于能否获取并利用外部信息。如果能运行代码、查询数据库或调用API,将这些结果作为反馈输入,就能让模型进行更深层次的反思,从而产出更优的结果。
- 设计哲学:当你有机会获取额外信息时,请务必将其融入反思流程。这是提升系统鲁棒性和输出质量的核心策略。
为什么不一次直接生成
在“直接生成”(Direct Generation)与“反思工作流”(Reflection Workflow)之间,我们为何更倾向于要采用一个包含反思步骤的复杂工作流?这个问题直指AI应用的核心权衡:效率 vs. 质量。 虽然“直接生成”看似简单快捷,但“反思”能带来更优的结果,值得我们投入额外的计算成本。
核心观点: 反思不是为了增加复杂度,而是为了在质量上获得“质的飞跃”。
什么是“直接生成”(Direct Generation)?
“直接生成”是AI最基础、最直观的工作方式,也常被称为“零样本提示”(Zero-shot Prompting)。
特点: 简单、快速、一步到位。它不提供任何中间反馈或修正的机会。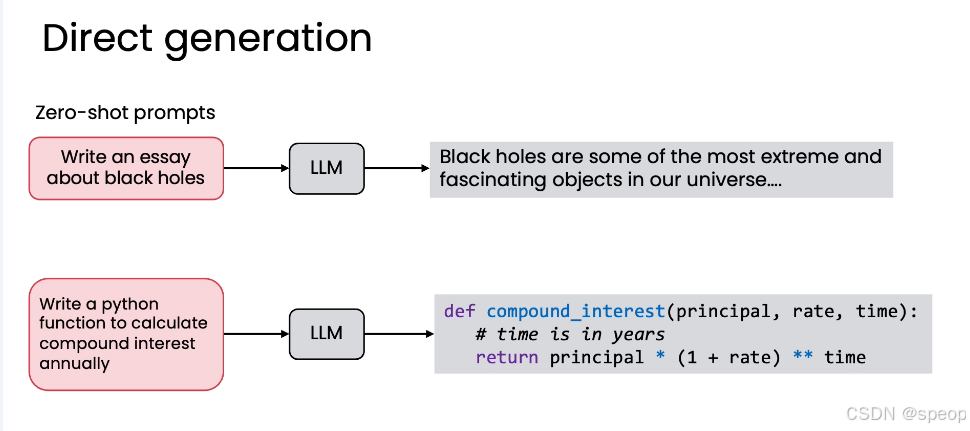
术语解释: “零样本提示”中的“零样本”指的是在提示中没有提供任何输入-输出示例。这与“单样本提示”(One-shot)和“少样本提示”(Few-shot)形成对比。
零样本 (Zero-shot): 写一个关于黑洞的文章(无示例)
单样本 (One-shot): 写一个关于黑洞的文章 + 示例1
少样本 (Few-shot): 写一个关于黑洞的文章 + 多个示例
反思在性能上全面碾压直接生成
论文《Self-refine: Iterative refinement with self-feedback》的关键图表
- 横轴 (X-axis): 7种不同的任务,包括情感反转、对话响应、代码优化、数学推理等。
- 纵轴 (Y-axis): 性能得分(Performance %)。
- 柱状图配对: 每个任务下有两组柱子:
- 浅色柱子 (Light bar): 代表“零样本提示”(即直接生成)下的性能。
- 深色柱子 (Dark bar): 代表“相同模型+反思过程”下的性能。 在所有7个任务、所 有4个被测试的模型(GPT-3.5, ChatGPT, GPT-4, Claude)中,加入反思步骤后的深色柱子,无一例外地高于对应的浅色柱子!
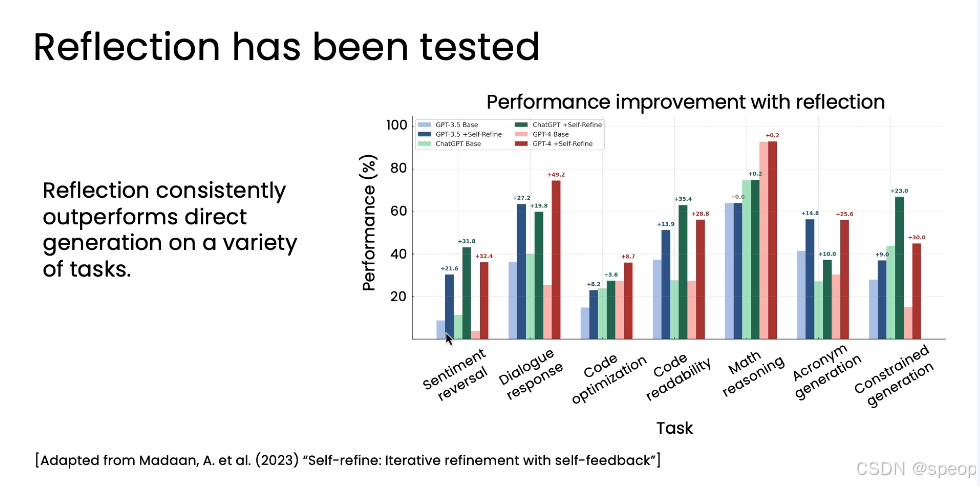
结论:反思模式在各种任务上都能稳定地提升性能。即使是最强大的GPT-4,在加入反思后,其表现也能得到进一步增强。这说明反思是一个普适且有效的优化策略。
反思模式更适用的任务场景
反思模式在以下类型的复杂任务中尤其有效: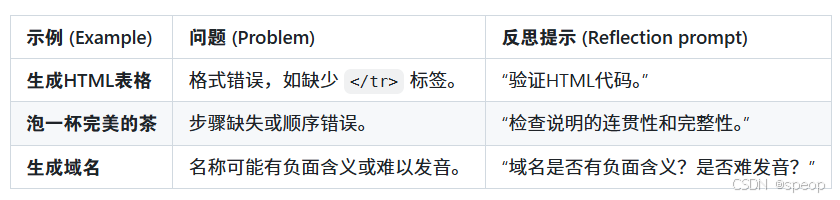

如何编写高效的反思提示语
编写反思提示的两大黄金法则:
- 明确指示反思动作 (Clearly indicate the reflection action):
- 不要含糊地说“请改进”,而要说“请审查”、“请检查”、“请验证”。
- 明确告诉模型你要它做什么,例如“审核电子邮件初稿”或“验证HTML代码”。
- 具体指定检查标准 (Specify criteria to check):
- 不要只说“让它更好”,而要列出具体的评判标准。
- 例如,在域名任务中,标准是“易发音”和“无负面含义”;在邮件任务中,标准是“语气专业”和“事实准确”。
- 这样做能引导模型围绕你最关心的维度进行深入思考和改进。

图表生成流程
如何利用“反思设计模式”结合多模态AI,将一份粗糙的图表初稿,迭代优化为清晰、美观、专业的可视化作品。 通过一个咖啡销售数据的实战案例,生动展示了AI如何像人类专家一样“审视”和“改进”自己的工作成果。

直接生成
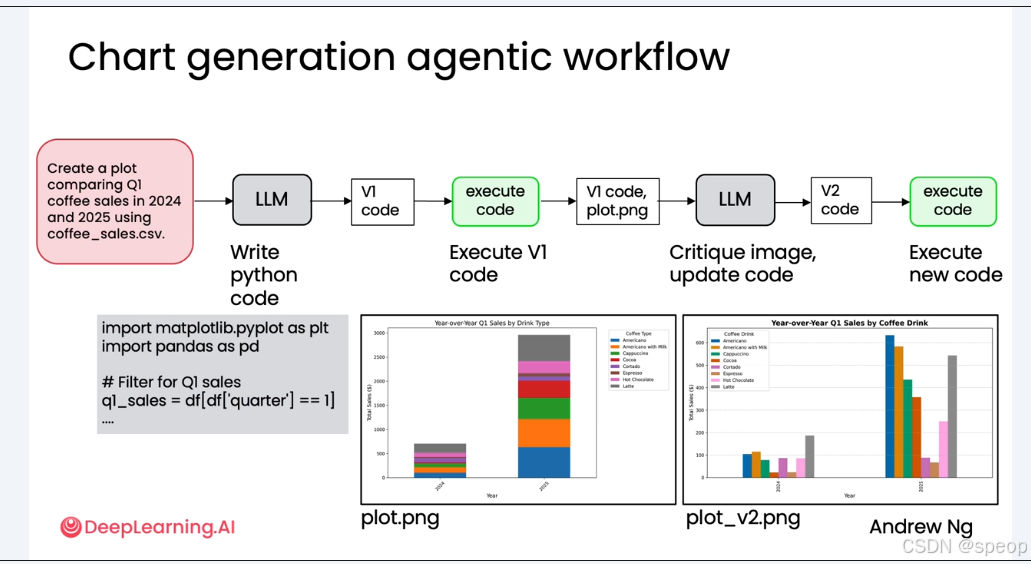
- 向 LLM 发送提示:“Create a plot comparing Q1 coffee sales in 2024 and 2025 using coffee_sales.csv.”
- LLM 生成第一版 Python 代码(V1 code),用于读取CSV文件并绘制图表。
- 执行与结果:运行 V1 代码,生成了一张名为 plot.png 的图表。
- 问题显现: 这是一张堆叠柱状图(Stacked Bar Plot)。虽然它完成了数据展示的基本功能,但存在两大缺陷:
- 堆叠柱状图对于比较不同年份同一饮品的销量不够直观。
- 图表整体观感不佳,缺乏专业性。
引入反思 —— 多模态模型的视觉推理
将生成的图像作为输入,交由一个多模态语言模型(Multi-modal LLM)进行反思。
- 输入准备: 将 V1 版本的代码 (V1 code) 和它生成的图表 (plot.png) 一同打包,作为新的输入。
- 反思指令: 提示多模态 LLM 扮演“专家数据分析师”的角色,对图表进行批判性评估。
- 视觉推理: 多模态模型能够“真正地看”这张图,分析其可读性、清晰度和完整性,并提出具体的改进建议。
- 生成新代码: 根据反思反馈,模型更新代码,生成第二版(V2 code)。
最终成果: 运行 V2 代码,生成了 plot_v2.png。
使用不同的模型进行分工协作
- LLM (初始生成): 负责根据用户提示生成第一版代码。例如,可以使用 GPT-4 或 GPT-5 等强大的通用模型。
- LLM 2 (反思阶段): 负责接收第一版代码、生成的图表以及对话历史,扮演“专家分析师”的角色,提供建设性反馈并指导代码改进。这个角色可能更适合由具备强大推理能力的“思考模型”(Reasoning Model)来担任。

反思提示语示例:
您是一位专业的数据分析师,能够为可视化提供建设性反馈。 {V1 代码} {plot.png} {对话历史记录}
步骤 1:评估所附图表的可读性、清晰度和完整性。
步骤 2:编写新代码来实现您的改进。
总结:
反思机制并非万能,其效果因应用场景而异。在某些任务上提升显著,在另一些任务上则可能微乎其微。
因此,了解反思机制对你特定应用的影响至关重要。它能为你提供优化方向,无论是调整初始生成提示,还是优化反思提示,都能帮助你获得更好的性能
Evaluating the impact of reflection
反思(Reflection)作为一种设计模式,能有效提升agent性能,但其代价是会略微拖慢agent速度。因此,关键在于如何科学地评估反思带来的实际收益,从而在“性能提升”与“效率损耗”之间做出明智取舍。
一、客观评估——数据查询任务
反思工作流
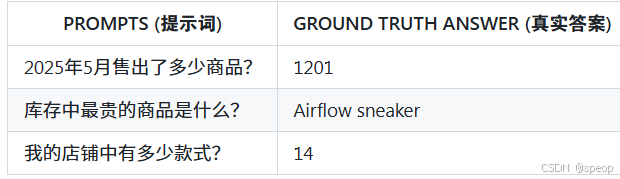
问题:“哪种颜色的产品总销量最高?”
- 基础流程:
- LLM 根据问题生成 SQL 查询语句(V1)。
- 执行 V1 查询,获取结果。
- LLM 根据结果回答问题。
- 反思增强流程:
- LLM 生成初始 SQL 查询(V1)。
- 新增反思步骤:另一个 LLM 对 V1 查询进行审视,并生成改进版的 SQL 查询(V2)。
- 执行 V2 查询,获取结果。
- LLM 根据结果回答问题。
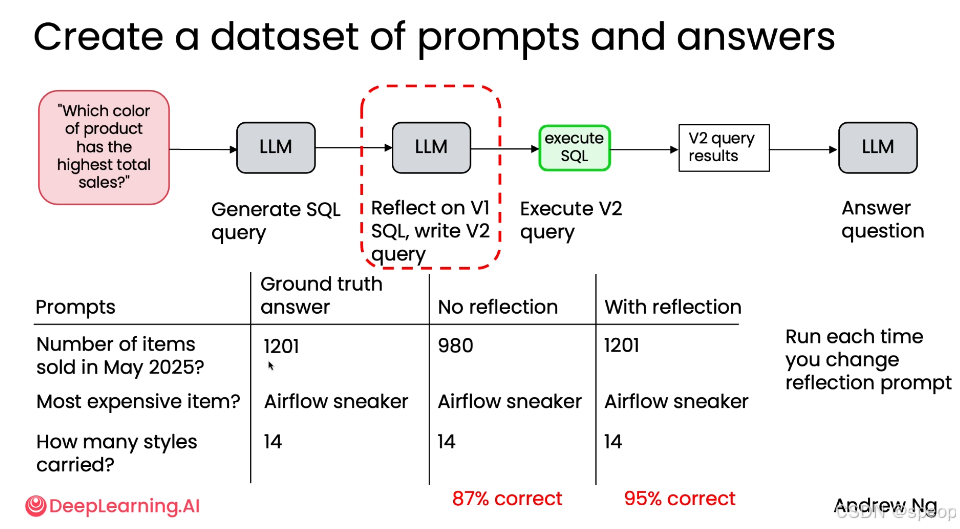
构建评估数据集
为了评估反思的效果,需要创建一个包含“提示词”和“真实答案”的数据集。
通过运行两个版本的工作流并比较结果,可以得出客观的性能指标。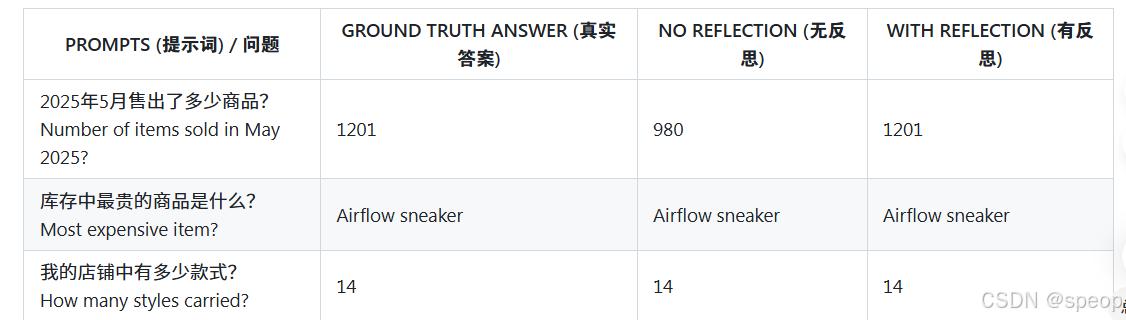
结论:反思显著提升了数据库查询的质量和最终答案的准确率。虽然增加了计算开销,但其带来的性能提升(+8%)是“有意义的”(meaningfully improving),值得保留。
迭代优化:调整提示词
一旦建立了评估机制,开发者就可以快速迭代:
- 修改“反思提示词”,例如要求模型让查询“更快”或“更清晰”。
- 或者修改“初始生成提示词”。
- 每次修改后重新运行评估,测量正确率的变化,从而选择最适合应用的提示词。
二、主观评估——可视化图表任务
- 任务:根据 coffee_sales.csv 数据生成 Q1 咖啡销售对比图。
- 问题:如何判断“反思后”的图表比“反思前”的图表更好?
- 难点:评估标准是主观的(如美观度、清晰度),而非黑白分明的客观标准。
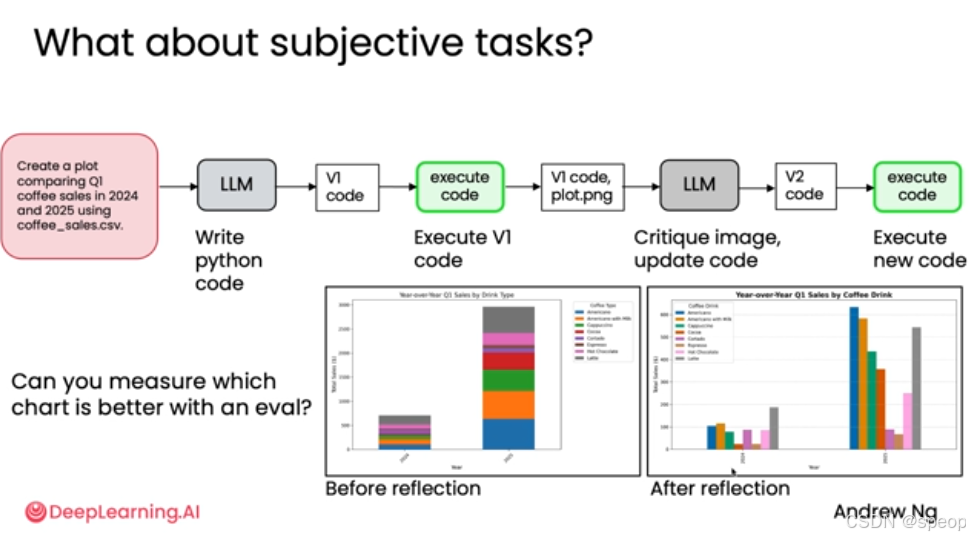
直接让LLM做裁判的弊端
直观的想法是让 LLM 直接比较两张图并给出“哪个更好”。 已知问题:
- 答案不可靠:LLM 的评判结果往往不稳定。
- 位置偏见(Position bias):许多模型倾向于选择第一个输入的选项(A),无论其质量如何。

使用评分表(更好的方法)
更好的方法是为 LLM 提供一套结构化的评分标准(Rubric),让它对每个维度进行打分,而不是直接比较。
- 示例评分量表:
- 是否有清晰的标题?
- 坐标轴是否有标签?
- 图表类型是否合适?
- 坐标轴的数值范围是否恰当? 同样,可以构建一个包含多个用户查询的数据集,对“有反思”和“无反思”生成的图表分别打分。

三、评估反思的核心方法论
客观评估:
- 构建带“真实答案”的数据集,用代码自动计算正确率。
- 简单、易管理、结果客观。适用于有明确答案的任务(如数据库查询)。
主观评估:
- 使用 LLM 作为裁判,但需提供详细的评分量表(Rubric)。
- 需要更多调优,但能处理复杂的主观标准(如图表美观度)。
总结:
反思的价值:它是一种强大的工具,能显著提升输出质量,但需付出一定的性能代价。
评估是关键:不能凭感觉决定是否保留反思步骤,必须通过客观或结构化的主观评估来衡量其收益。
客观任务:用“真实答案”数据集 + 代码自动化评估。
主观任务:用“评分量表”引导 LLM 进行结构化打分,避免直接比较。
迭代优化:建立评估体系后,可以快速尝试不同的提示词,找到最优解。
未来方向:结合外部信息,是进一步提升反思效果的下一个前沿。
Using external feedback
在构建AI代理工作流时,单纯的**“自我反思**”存在性能瓶颈。真正的突破在于引入外部反馈(External Feedback)。这不仅能打破性能天花板,还能让系统获得全新的、更强大的信息源,从而实现质的飞跃。
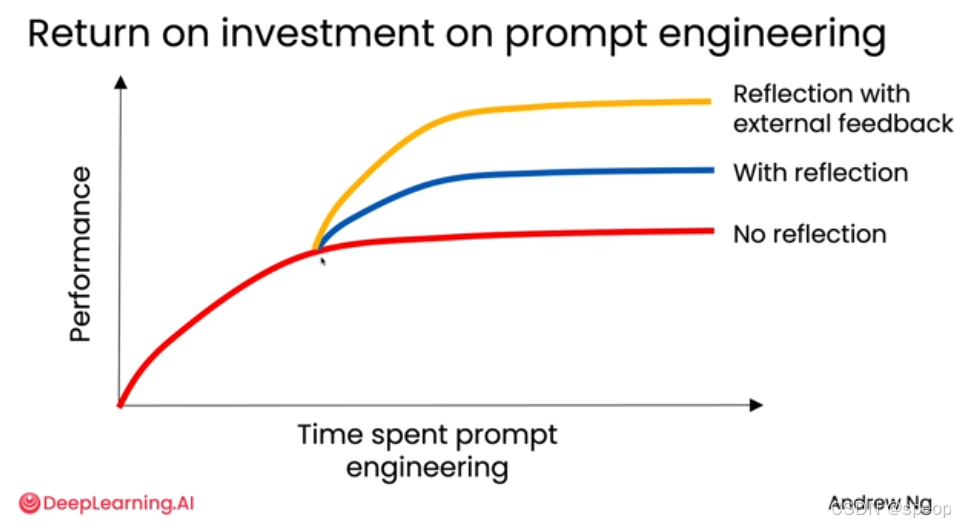
提示词工程的收益递减规律
- 横轴:投入在提示词工程上的时间。
- 纵轴:系统性能。
- 红色曲线(无反思):
- 初期,通过调整提示词,性能会快速提升。
- 但很快,性能增长会放缓并趋于平缓,进入“平台期”。此时,即使再花费大量时间微调提示词,也很难获得显著的性能提升。
- 蓝色曲线(有反思):
- 在某个时间点加入反思机制后,性能曲线会再次上扬,达到一个比“无反思”更高的平台。
- 这表明,反思能为系统带来一次“性能跃迁”,突破原有的瓶颈。
- 黄色曲线(有反思 + 外部反馈):
- 在引入反思的基础上,如果能接入外部反馈,性能将再次跃升,达到一个远超前两者的更高平台。
- 外部反馈为系统注入了“新信息”,使其不再局限于模型自身的知识库和推理能力。
外部反馈的案例
1、避免提及竞争对手:模型有时会在文案中不必要地提及竞争对手的名字(如 “Our company’s shoes are better than RivalCo”)。
-
外部反馈工具:编写一个代码工具,使用正则表达式对模型的输出进行模式匹配,自动检测是否包含竞争对手名称。
-
反思流程:
- 模型生成初稿。
- 工具扫描文本,发现“RivalCo”。
- 将“检测到竞争对手名称”的反馈信息传回给模型。
- 模型基于此反馈,重新撰写一份不提及竞争对手的新版本。
2、事实核查:模型生成的历史内容可能存在不准确之处(如 “The Taj Mahal was built in 1648”)。
-
外部反馈工具:调用网络搜索API,查询关于泰姬陵建造时间的权威资料。
-
反思流程:
- 模型生成初稿。
- 工具发起网络搜索,返回结果:“泰姬陵于1631年下令建造,1648年完工”。
将搜索结果作为额外输入,提供给反思模型。 - 模型基于更精确的历史事实,重写文本,使其更准确。
3、遵守字数限制:模型生成的博客文章或摘要常常超出预设的字数上限。
-
外部反馈工具:开发一个简单的字数统计工具。
-
反思流程:
- 模型生成初稿。
- 工具统计字数,发现“超过字数限制”。
- 将“当前字数”和“字数限制”等信息作为反馈,传回给模型。
- 模型基于此反馈,压缩或精简内容,重新生成符合字数要求的版本。

表格展示了三种常见的挑战及对应的工具化反馈来源:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)