[LLM-RAG] Task01:初识RAG(理论与简单实践)
·
目录
一、理论
1. 概念
RAG(Retrieval-Augmented Generation)检索增强生成。顾名思义,在大型语言模型(LLM)生成文本前,先通过检索机制从外部知识库中动态获取相关信息,并将检索结果融入生成过程,从而提升输出的准确性和时效性。
| 问题 | RAG的解决方案 |
|---|---|
| 静态知识局限 | 实时检索外部知识库,支持动态更新 |
| 幻觉(Hallucination) | 基于检索内容生成,错误率降低 |
| 领域专业性不足 | 引入领域特定知识库(如医疗/法律) |
| 数据隐私风险 | 本地化部署知识库,避免敏感数据泄露 |
关键优势
- 准确性提升
- 基础知识增强,尤其是预训练没有的专业领域知识
- 减轻幻觉现象,避免无中生有
- 可溯源引用,增强输出的可信度
- 实时性保障
- 支持动态更新外部知识库
- 减轻模型的时滞性,预训练数据截止日期带来的问题
- 成本效益
- 替代反复微调,知识库可以独立更新
- 特定专业领域模型可以用小模型+知识库的组合替代更大的模型
- 减少存储完整知识使用的模型权重
- 可扩展性
- 模块化,可以独立优化各模块
- 支持多源集成,从不同来源和格式构建同一知识库
2. 技术原理
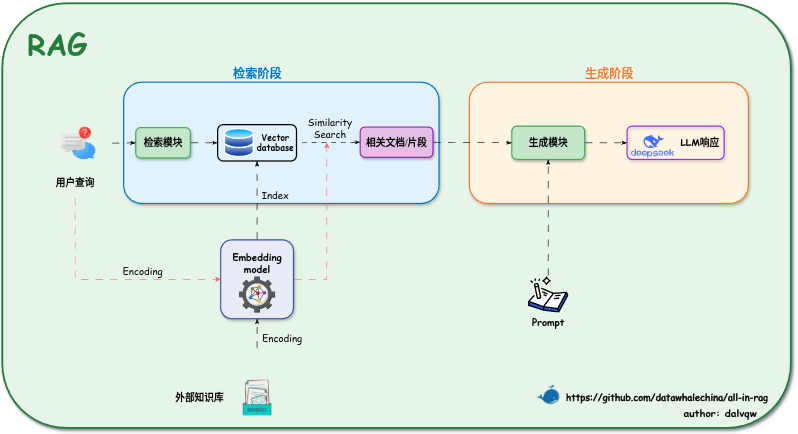
- 将外部知识库分割为片段,通过嵌入模型转换为向量数据库。
- 检索模块利用相似度匹配查找与用户查询匹配的相关内容(向量)。
- 相关文档和片段交给生成模块生成更准确的相应。
3. 演变
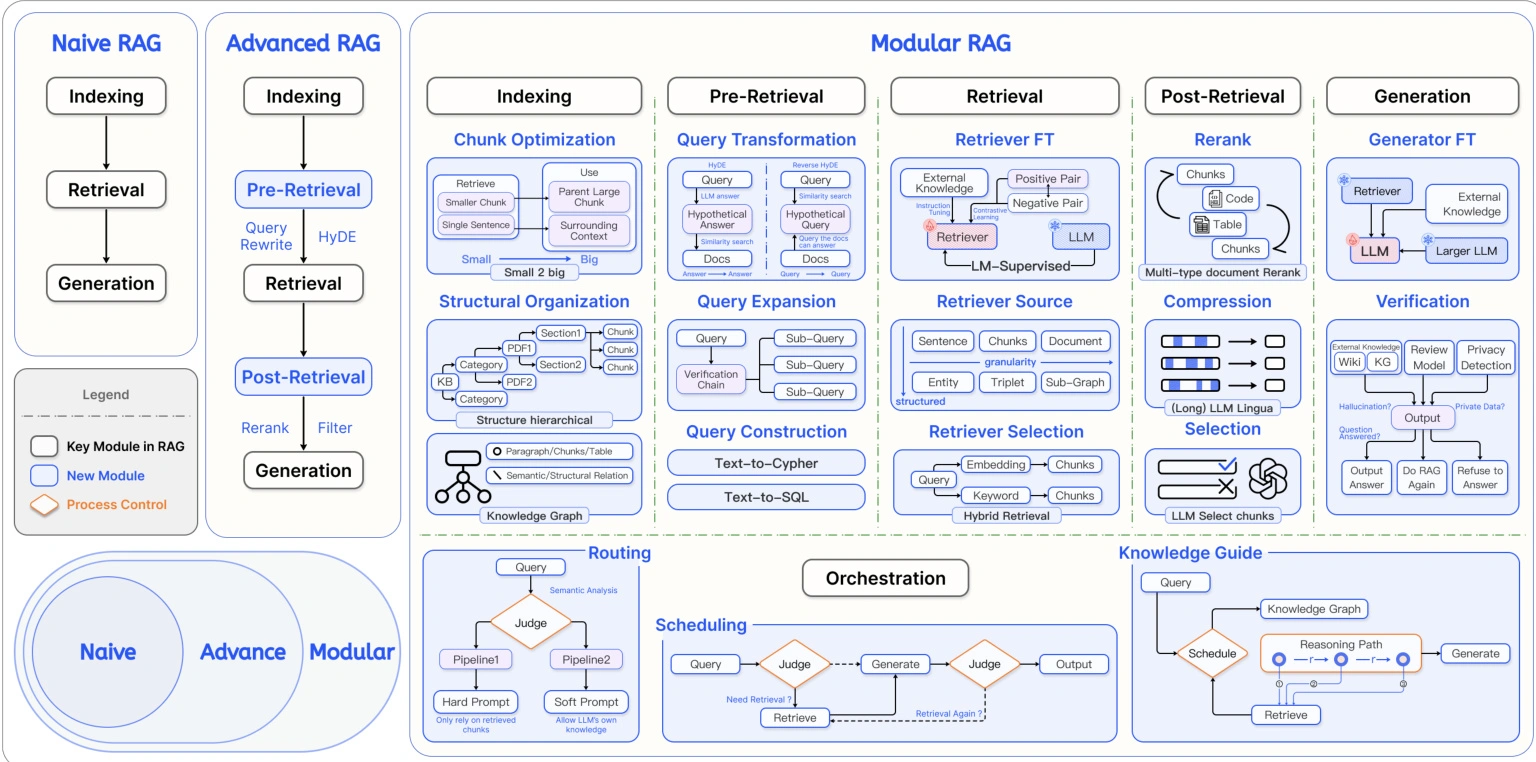
主要是在“索引-检索-生成”的流程上,不断增强检索的细节(数据清洗等),逐步走向模块化:灵活集成搜索引擎、强化学习优化、知识图谱增强等。
4. 基础工具链
开发框架:
- LangChain:提供预置RAG链(如rag_chain),支持快速集成LLM与向量库
- LlamaIndex:专为知识库索引优化,简化文档分块与嵌入流程
向量数据库:
- Milvus:开源高性能向量数据库
- FAISS:轻量级向量搜索库
- Pinecone:云服务向量数据库
5. 实践步骤
-
数据准备
- 格式支持:PDF、Word、网页文本等
- 分块策略:按语义(如段落)或固定长度切分,避免信息碎片化
-
索引构建
- 嵌入模型:选取开源模型(如text-embedding-ada-002)或微调领域专用模型
- 向量化:将文本分块转换为向量存入数据库
-
检索优化
- 混合检索:结合关键词(BM25)与语义搜索(向量相似度)提升召回率
- 重排序(Rerank):用小模型筛选Top-K相关片段(如Cohere Reranker)
-
生成集成
- 提示工程:设计模板引导LLM融合检索内容
- LLM选型:GPT、Claude、Ollama等(按成本/性能权衡)
二、简单实践
1. 环境准备
见教程第二节、准备工作
codespace老是报空间不足,最后还是在本地跑了
2. 构建RAG
按照:数据准备-索引构建-查询与检索-生成集成的流程完成代码,其中教程默认的deepseek调用需要充值,这里提供一个免费解决方案,使用Qwen3-8B:
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.prompts import ChatPromptTemplate
# from langchain_deepseek import ChatDeepSeek
from langchain_openai import ChatOpenAI
load_dotenv()
markdown_path = "../../data/C1/markdown/easy-rl-chapter1.md"
loader = UnstructuredMarkdownLoader(markdown_path)
docs = loader.load()
print(f"已加载 {len(docs)} 个文档。")
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
prompt = ChatPromptTemplate.from_template("""请根据下面提供的上下文信息来回答问题。
上下文:
{context}
问题: {question}
回答:"""
)
llm = ChatOpenAI(
model="Qwen/Qwen3-8B",
base_url="https://api.siliconflow.cn/v1",
temperature=0.7,
max_tokens=2048,
api_key=os.getenv("SILICONFLOW_API_KEY")
)
question = "文中举了哪些例子?"
# 测试不同配置(练习2)
test_cases = [
(500, 50), # 小块
(1000, 100), # 中块
(2000, 200), # 大块
]
for chunk_size, chunk_overlap in test_cases:
print(f"\n{'='*80}")
print(f"测试: chunk_size={chunk_size}, chunk_overlap={chunk_overlap}")
print(f"{'='*80}")
# 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
chunks = text_splitter.split_documents(docs)
print(f"分成 {len(chunks)} 个文本块")
# 构建向量存储
vectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(chunks)
# 检索
retrieved_docs = vectorstore.similarity_search(question, k=3)
print(f"检索到 {len(retrieved_docs)} 个相关文档")
# 显示检索内容的长度
for i, doc in enumerate(retrieved_docs, 1):
print(f" 文档{i}: {len(doc.page_content)} 字符")
# 生成答案
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print(f"\n回答: {answer.content}") # 取content部分内容(练习1)
print(f"{'='*80}\n")输出样式如下:
已加载 1 个文档。
================================================================================
测试: chunk_size=500, chunk_overlap=50
================================================================================
分成 61 个文本块
检索到 3 个相关文档
文档1: 455 字符
文档2: 423 字符
文档3: 491 字符
回答:
文中举了以下例子:
1. **强化学习的例子**
- DeepMind研发的走路智能体:学习在曲折道路上行走,通过举手保持平衡以提高速度,并能适应环境扰动。
- 机械臂抓取:通过多个机械臂训练,学习统一的抓取策略以适应不同形状的物体,替代传统需逐个建模的方法。
2. **探索与利用的例子**
- 选择餐馆:利用是前往最喜欢的餐馆(已知美味),探索是搜索并尝试新餐馆(可能风险但可能发现更好选择)。
- 做广告:利用是采用最优广告策略,探索是尝试新策略以评估效果提升。
- 挖油:利用是挖掘已知地点(确保发现油田),探索是尝试新地点(可能无果,但可能发现大油田)。
- 玩游戏(如《街头霸王》):利用是固定策略(如蹲角落出脚),探索是尝试新招式(如“大招”)。
3. **奖励的例子**
- 象棋选手:赢棋获得正奖励,输棋获得负奖励。
这些例子涵盖了强化学习在不同场景中的应用,以及探索与利用的核心概念。
================================================================================
================================================================================
测试: chunk_size=1000, chunk_overlap=100
================================================================================
分成 26 个文本块
检索到 3 个相关文档
文档1: 967 字符
文档2: 985 字符
文档3: 861 字符
回答:
文中举了以下例子:
1. **DeepMind研发的走路的智能体**:学习在曲折道路上行走,通过奖励机制调整动作,如举手保持平衡以加快移动速度。
2. **机械臂抓取**:利用强化学习训练机械臂抓取不同形状的物体,避免传统方法需要为每个物体单独建模的繁琐性。
3. **OpenAI的机械臂翻魔方**:通过虚拟环境训练机械臂的手指灵活性,最终将其应用于真实机械臂,实现玩魔方的功能。
4. **穿衣服的智能体**:学习执行精细的穿衣动作,能够抵抗扰动并适应失败情况。
5. **小车上山(MountainCar-v0)**:作为与Gym库交互的示例,展示观测空间、动作空间及奖励机制的实现。
6. **雅达利游戏中的Pong**:说明奖励延迟的问题,智能体需通过长期动作影响才能获得奖励。
7. **象棋选手的奖励机制**:赢棋得正奖励,输棋得负奖励。
8. **股票管理的奖励**:由股票收益与损失决定。
这些例子涵盖了强化学习在不同场景(如机器人控制、游戏、物理环境等)中的应用,以及奖励信号在序列决策中的作用。
================================================================================
================================================================================
测试: chunk_size=2000, chunk_overlap=200
================================================================================
分成 13 个文本块
检索到 3 个相关文档
文档1: 1920 字符
文档2: 1725 字符
文档3: 1897 字符
回答:
文中举了以下例子:
1. **探索与利用的例子**
- 选择餐馆:利用是指直接去最喜欢的餐馆(已知可口),探索是指尝试新餐馆(可能浪费钱)。
- 做广告:利用是直接采用最优广告策略,探索是尝试更换策略以评估效果。
- 挖油:利用是直接在已知地点挖油,探索是在新地点挖油(可能发现大油田或失败)。
- 玩游戏(如《街头霸王》):利用是固定某种策略(如蹲角落出脚),探索是尝试新招式(如释放“大招”)。
2. **强化学习实验的例子**
- **Gym中的环境**:雅达利环境(如Pong游戏)、MuJoCo环境(连续控制场景)。
- **Gym Retro扩展**:包含更多游戏。
- **机械臂翻魔方**:OpenAI设计的机械臂通过强化学习训练后翻动魔方。
- **穿衣服的智能体**:训练智能体完成穿衣动作,并抵抗扰动。
3. **奖励的例子**
- 象棋选手:赢棋得正奖励,输棋得负奖励。
- 股票管理:奖励由收益与损失决定。
- 雅达利游戏Breakout:奖励为游戏分数的增减,稀疏性影响难度。
4. **序列决策与状态/观测关系的例子**
- **Pong游戏**:智能体通过动作(移动木板)影响后续状态,但奖励延迟至游戏结束。
- **状态与观测**:状态是对历史的函数,观测是状态的部分描述(如RGB像素矩阵或关节角度速度)。
**总结**:文中涉及的例子里,探索与利用相关的是餐馆、广告、挖油、游戏;强化学习实验相关的是Gym环境、机械臂翻魔方、穿衣服智能体;奖励相关的是象棋、股票、Breakout游戏;序列决策相关的是Pong游戏及状态与观测的定义。
================================================================================三、总结
RAG的核心概念是给输入加上切分好的对应文档,构成类似few-shot的输入,从而为LLM提供更多的信息输入。
其中“提供对应的文本块”这个步骤是RAG相对于传统大模型多的一个步骤,这个步骤主要通过相似度匹配等手段检索所有参考材料选出最合适的部分,并不涉及使用大模型的处理。
总体感受,RAG概念上是prompt工程或者context工程的一种分支演进。
在实践中我们主要的两种手段是Langchain和LlamaIndex,前者更加工程化后者封装更友好。
主要的流程包括四个步骤:
- 数据准备:准备我们的知识库文档,并选取合适的文本块大小和重叠,进行切分。
- 索引构建:将文本块利用嵌入模型转换为向量(用于检索)
- 查询与检索:找到匹配的文本向量,合并为统一的字符串作为prompt中提供的上下文。
- 生成集成:利用大模型生成回应
参考
1. Datawhale开源项目《all-in-rag》第一章节:all-in-rag
2. 群友优秀笔记:siliconflow替代方案与环境配置

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)