音画同步视频生成重磅开源!Character AI和耶鲁大学推出Ovi,让音、画在一个大脑里思考
OpenAI的Sora 2,谷歌的Veo 3.1能音画同步生成视频,但都是闭源产品。开发者们苦苦等待的的源神阿里的wan 2.5,也没选择开源。这不,终于有人打破了寂静。Character AI和耶鲁大学的研究团队联手推出OVI(Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation)。它没有遵循先生成画面再配声音,或反之的
OpenAI的Sora 2,谷歌的Veo 3.1能音画同步生成视频,但都是闭源产品。
开发者们苦苦等待的的源神阿里的wan 2.5,也没选择开源。
这不,终于有人打破了寂静。
Character AI和耶鲁大学的研究团队联手推出OVI(Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation)。

它没有遵循先生成画面再配声音,或反之的传统路径,而是将音频和视频这两种模态,视为一个不可分割的整体,在同一个生成过程中同步诞生。
这套方法的核心,是一种被称为双骨干交叉模态融合的架构。
想象一下,OVI拥有两个并行且结构完全相同的大脑,一个负责视觉,一个负责听觉。它们并非各自为政,而是在思考的每一步都进行着深度交流。这种设计,从根本上消除了音画不同步的问题,不再需要复杂的多阶段流程或后期对齐。
过去,要让AI生成的视频音画同步,是一件极其棘手的事情。
开发者们尝试了各种方法,比如先固定声音,再根据声音生成视频画面(A2V),或者反过来(V2A)。
也有些方法是先各自生成,再用后期技术强行对齐,如同给电影配音,但效果往往差强人意。
还有一些方法依赖于特定的捷径,比如只关注人脸区域的口型同步,但这大大限制了模型的通用性,无法处理更广泛的场景。
这些多阶段的处理方式,不仅增加了系统的复杂性,也难以保证时间上的精确同步。
OVI为开源的音视频生成技术提供了一条全新的、可行的道路。
OVI让音画天生同步
OVI的架构设计精妙而对称。
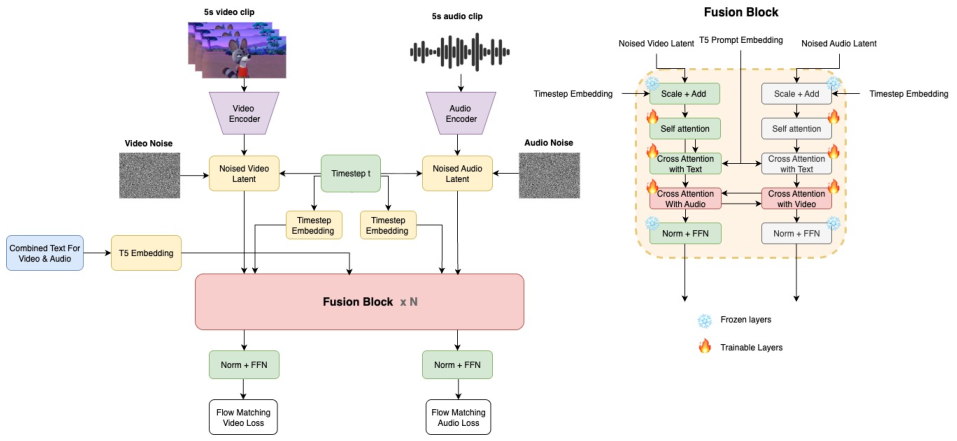
它拥有两个并行的分支,一个处理视频,一个处理音频,两者都构建在相同的扩散变换器(Diffusion Transformer, DiT)架构之上。
视频分支的能力,继承自一个强大的预训练视频模型Wan2.2 5B。
而音频分支,虽然是从零开始训练的,但其架构设计与视频分支完全一致,就像一对同卵双胞胎。
这种对称性是关键。
它保证了两种模态在模型内部具有相同的潜在维度、相同的transformer块数量、相同的注意力头数和头维度。
因为架构上的完全对称,音频和视频的语言得以互通,无需任何额外的翻译层。这不仅避免了不必要的参数和计算开销,也让信息交换变得更加直接高效。
在模型的每一个transformer处理块中,都含有一对交叉注意力层。
在这里,音频流会关注视频流,同时视频流也会关注音频流。
具体来说,音频信息会作为查询信号,去视频信息中寻找相关的键和值,这使得音频能够看到与之相关的视觉内容。
反之亦然,视频信息也会作为查询信号,去音频信息中寻找对应,这让视频能够听到匹配的声音。
这种双向的、实时的信息交互,贯穿了整个生成过程。
模型因此能够自主学习到音频和视频之间复杂的对应关系,比如嘴唇的微妙运动如何与特定的发音同步,或者一个物体的动作如何与它发出的声音精确匹配。
OVI用数学技巧对齐时间
音频和视频虽然共享架构,但它们的时间分辨率天生不同。
在OVI中,一段5秒的视频,其潜在变量会跨越31个时间帧。
而同样时长的音频,在采样和编码后,会形成157个时间token。
这是一个157对31的不等关系,如何让它们在时间上精确对齐?
OVI采用了一种名为旋转位置嵌入(Rotary Positional Embedding, RoPE)的技术,并对其进行了巧妙的缩放。
RoPE是一种为模型输入信息标注时间顺序的方法。OVI将音频分支的RoPE频率,乘以一个缩放因子31/157,约等于0.197。
这个简单的数学操作,相当于给节奏更快的音频带上了一个节拍器,使其时间步点与视频的较粗糙的帧率完美匹配。
对齐前后的效果差异是显著的。
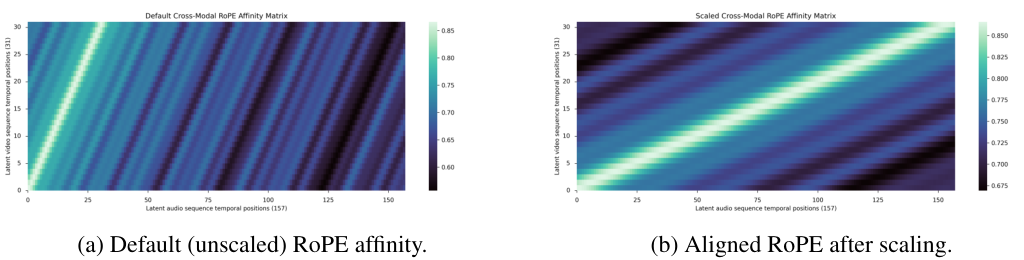
在没有进行RoPE缩放时,音频和视频的交叉关注矩阵在对角线上是错位的,信息无法有效同步。
而经过缩放后,对角线变得清晰而锐利,表明音频和视频的token在时间上实现了精准的一对一关注,为同步生成打下了坚实基础。
处理用户输入的提示词时,OVI也采取了统一的策略。
它使用一个冻结的T5编码器来理解一个组合后的提示。
这个提示词会将描述视觉事件的文本,与描述可听语音的文本连接在一起。
例如,一段提示可能是:一个男人坐在公园长椅上,<S>‘今天天气真好’<E>,周围有鸟叫声<AUDCAP>男人声音低沉,鸟鸣清脆</AUDCAP>。
其中<S>和<E>标记了语音的起止,而<AUDCAP>和</AUDCAP>则标记了对所有声音的描述。
这个统一的文本嵌入,会同时被用于指导音频和视频的生成。
这样做的好处是直观的。
视觉场景的细节(公园长椅),可以提升音频的特异性和多样性(鸟叫声)。
而声音的细节描述(男人声音低沉),则可以反过来指导视频中人物的面部表情和动作。
单一的语义上下文,不仅简化了训练和推理过程,也极大地改善了跨模态的对齐效果。
OVI的训练食谱极为考究
要训练一个统一的音视频生成器,一个高质量、大规模、多样化且音画同步的多模态数据集是成功的基石。
OVI的团队为此设计了一套复杂而严谨的多阶段数据处理流程。
他们精心策划了两个互补的数据语料库。
一个是由成对的音频和视频组成的语料库,用于教会模型理解两种模态之间的对应关系。
另一个是纯音频语料库,用于音频模型的预训练和微调,以建立强大的声音生成能力。
这个纯音频库又被分为两个子集:一个包含较长音频(最长12秒),用于初始预训练;另一个则包含较短音频,用于后续的微调。
这种两阶段的训练方法,让模型先在长音频中学习声音的普遍规律,再在短音频上进行精细调整,以更好地适应最终生成任务的需求。
对于成对的音视频数据,处理流程分为四个步骤:分割与过滤、同步检测、字幕描述和打包。
第一步,使用场景检测算法,从海量视频中切分出符合标准的121帧(约5秒,24fps)的视频片段。
团队设定了严格的筛选标准:视频分辨率必须大于720x720像素;使用光流模型过滤掉静态或几乎没有运动的视频;同时,利用美学预测器剔除低质量的内容。
为了让模型具备更广泛的生成能力,数据集中还特意混合了单人、多人以及无人物的视频,避免模型过度拟合于某一特定场景。
第二步,同步检测是重中之重。
团队使用了广泛应用的SyncNet模型,它通过学习声音和嘴部图像之间的联合嵌入,来判断语音和口型是否同步。
为了处理数百万规模的视频数据,团队对SyncNet进行了优化。只有同步偏移在3帧以内,且置信度得分高于1.5的视频片段才会被保留。
实验表明,即使是少量不同步的数据,也会严重损害模型的唇语同步能力,因此必须采用如此严格的标准。
第三步,为视频添加详细的字幕描述。
团队使用了一个强大的多模态大语言模型(MLLM)来完成这项任务。
这个模型会接收视频中的七个关键帧和完整的音轨,然后生成一段交织着视觉事件和语音内容的详细描述。
语音内容会被<S>和<E>标签包裹,而对整体音频环境的描述则被<AUDCAP>和</AUDCAP>包裹。
对于包含语音的片段,音频描述会强调说话者的声学特征,如年龄、性别、口音、音高、情感和语速。
对于没有语音的片段,描述则会详述存在的音效、背景声或音乐元素。
第四步,打包数据。
在将数据送入模型前,所有视频帧都会被调整到720x720的固定分辨率,音频则被转换为原始的波形字节流,确保模型接收到的输入格式是统一的。
对于纯音频数据,预处理流程相对简化。
音频被提取为两种不同长度:用于预训练的数据最长为12秒,用于微调的数据则精确到5.04秒,以匹配视频片段的时长。
同样地,MLLM也被用来为这些音频生成转录和详细的声学描述。
OVI的训练策略分步进行
为了提升效率,OVI的音频塔在一个紧凑的潜在空间中进行操作,而不是直接处理原始的音频波形。
它使用了MMAudio的预训练1D VAE(变分自编码器)来完成音频的编码和解码。
在训练时,OVI的音频塔(OVI-AUD)被分为两个子阶段。
首先是预训练阶段,音频骨干在数十万小时的、主要是语音的长音频数据上从零开始学习。
这使得模型能够广泛接触到各种自然的声学变化,如音高、情感等,从而学会生成具有一致说话者特征的音频。
接下来是微调阶段,团队使用填充到5.04秒的短音频,对预训练好的模型进行微调。
这一步是为了让音频骨干的输出与未来要生成的视频在时长上完全匹配。同时,此阶段还引入了大量的音效数据,使OVI-AUD不仅仅是一个语音模型,更是一个能够处理复杂声音场景的通用音频生成器。
当音频和视频两个骨干都准备就绪后,就进入了最终的融合训练阶段。
团队将预训练好的音频和视频骨干结合在一起,并从零开始初始化它们之间的交叉模态注意力模块。
为了减少计算资源的消耗,训练过程中冻结了所有的前馈网络(FFN)层,使得110亿总参数中只有57亿是可训练的。
通过只微调单模态的自注意力和所有的交叉注意力模块,团队成功地对齐了音频和视频,同时保留了它们在预训练阶段学到的强大表示能力。
在推理生成时,音频和视频两个分支共享相同的时间表,并通过一个求解器联合生成,确保了最终输出的同步性。
OVI的生成效果令人信服
为了直观地展示OVI的学习效果,研究团队可视化了音频到视频(A2V)的交叉模态注意力图。
这张图可以告诉我们,当模型在生成某种声音时,它的注意力集中在画面的哪个区域。

当音频内容是语音时,模型的注意力会高度集中在说话者的嘴部区域。
当音频是鼓声时,注意力则聚焦在鼓上。
当音频是动物的叫声时,注意力会与发出声音的动物身体部位对齐。
这有力地证明了OVI的融合模型能够有效地将音频线索与相关的视觉内容同步起来。
为了量化评估OVI的性能,团队进行了多项对比实验。
首先,他们独立评估了音频塔(OVI-AUD)的音频生成能力,将其与业界顶尖的文本到音频(T2A)和文本到语音(TTS)模型进行了比较。
然后,他们评估了OVI完整的联合音视频生成(JAVG)能力,并与JavisDiT和UniVerse-1这两个开源模型进行了对比。
评估的核心是一项由50名真人参与者进行的盲对偏好研究。
参与者会看到由不同模型生成的两段带音频的视频,并选择他们更偏好哪一个。
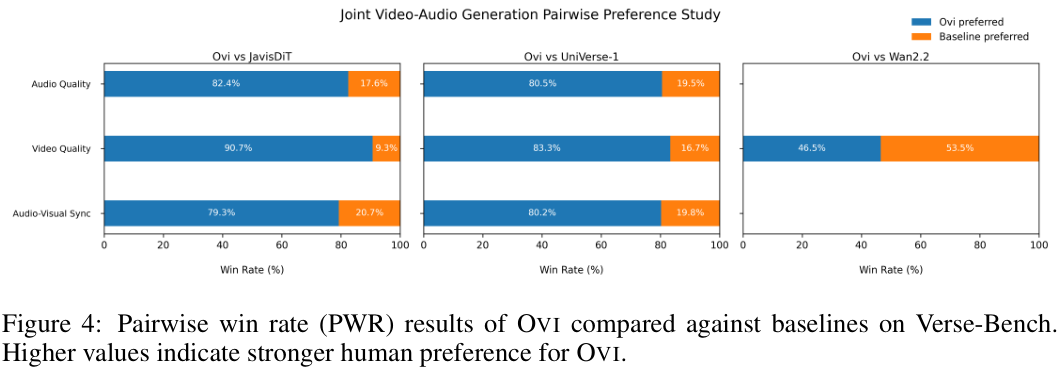
在Verse-Bench数据集上,无论是在音频质量、视频质量还是音画同步这三个维度上,参与者都压倒性地偏爱OVI的生成结果。
这表明OVI的统一设计和训练框架,不仅保持了强大的性能,而且显著推动了开源社区在联合音视频生成领域的发展,使其能力更接近像Veo 3这样的前沿闭源模型。
团队也注意到,与作为其基础的纯视频模型Wan2.2相比,OVI生成视频的质量有轻微下降。
这是可以预见的,因为联合训练使用的数据集,在规模上小于Wan2.2预训练时所用的海量视频语料库。
但重要的是,这种权衡是微小的,并不会削弱OVI在联合音视频生成任务中的整体优越性。
在纯音频生成的评估中,OVI-AUD的表现同样出色。
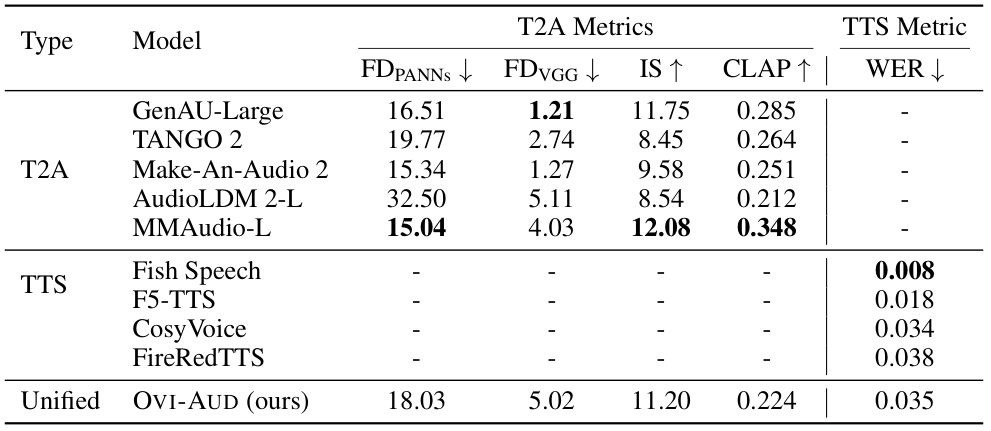
作为一个能够同时处理文本到音频(T2A)和文本到语音(TTS)的统一模型,OVI-AUD在各自的指标上,都实现了与那些专门为此任务设计的顶尖模型相当的性能。
这证明了OVI-AUD作为一个坚实的基础,完全有能力支撑起更复杂的音视频融合任务。
真实世界的视频往往同时包含复杂的音效和连贯的语音,这是那些专用的、只能处理单一任务的模型所无法支持的。
一项有趣的消融研究揭示了OVI设计决策的智慧。
最初,团队曾尝试为音频塔设计两个独立的文本编码器:一个CLAP编码器处理音效描述,一个T5编码器处理语音转录。
他们本以为这样可以避免两种任务互相干扰。
但实践发现,这种分离的设计反而限制了模型的发挥。模型可以很好地单独处理音效或语音,却难以将它们融合成一个统一连贯的音频流。
于是,团队改用了前文提到的组合文本提示方法,将语音转录和音效描述融合到单个T5文本嵌入中。

这一修改在保持了语音正确性(WER指标相当)的同时,显著提升了音频的保真度和对齐度指标。
更重要的是,统一的文本嵌入也让联合音视频生成变得更加简单和高效,因为音频和视频塔现在可以基于完全相同的文本指令进行创作,增强了多模态的连贯性。
OVI第一版生成5秒长的720p分辨率短视频,这限制了它在创作长篇叙事、处理镜头转换等方面的应用。
但刚刚升级的Ovi 1.1,将最初的5秒视频+音频生成时间扩展到10秒,从而实现了更丰富的故事讲述、更长的对话和更具表现力的角色。
OVI的开源贡献是开创性的。
它提出了一个统一的音视频生成框架,通过架构对称性和块级双向融合,让时间和语义在线索被联合学习,而非顺序处理。
它的基础音频塔能够同时处理语音和多样的音效,支持了通用的同步生成,无需任何额外的辅助模块。
这为后来的开发者们提供了非常难得的基础和借鉴。
免费试玩:
https://huggingface.co/spaces/akhaliq/Ovi
参考资料:
https://aaxwaz.github.io/Ovi/
https://arxiv.org/abs/2510.01284
https://github.com/character-ai/Ovi
https://huggingface.co/chetwinlow1/Ovi
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)