从一行报错开始的理解
"为什么我的模型在昇腾卡上跑不起来?"
第一次接触CANN时,我遇到了一个让人困惑的错误信息。作为一个习惯了CUDA的开发者,我以为只需要把.cuda()改成.npu()就行了,结果却碰了一鼻子灰。
但正是这次失败,让我开始认真研究CANN的架构设计,才发现它远不止是一个简单的设备切换接口,而是一套完整的异构计算解决方案。今天,我想通过这篇文章,和大家一起深入探索CANN的核心特性,特别是它在自定义算子开发方面的强大能力。
一、CANN架构深度解析:为什么它不只是"另一个AI框架"
在开始写代码之前,我们先花点时间理解CANN的架构设计。很多人对CANN有个误解,认为它就是个AI推理框架,实际上它的能力范围要广得多。
让我用一个生活中的比喻来解释CANN的定位:
想象一下,传统的AI框架就像一辆成品汽车,你只能按照设计好的方式来驾驶。而CANN更像是一个汽车制造工厂,不仅提供成品车(预置算子),还提供发动机生产线(算子开发工具)、零部件设计图(接口规范)和装配流水线(图优化引擎)。
CANN的核心价值体现在三个层面:
第一层:对应用开发者的友好支持
这一层面向的是大多数AI应用开发者。CANN提供了高层的API和与主流框架(PyTorch、TensorFlow)的深度集成,让你几乎无感地从GPU迁移到NPU。就像开车的人不需要懂发动机原理一样,应用开发者可以专注于业务逻辑。
第二层:对算子开发者的深度支持
当你需要实现一些特殊操作,或者对性能有极致要求时,就需要深入到算子开发层面。CANN提供完整的算子开发工具链,从代码编写、编译调试到性能优化,形成闭环。
第三层:对框架开发者的适配支持
这是最底层,CANN提供了与各种AI框架对接的能力,让框架开发者可以轻松地让整个框架运行在昇腾硬件上。
这种分层设计的好处是什么?
它让不同层次的开发者都能找到适合自己的入口。你可以先从应用层开始,随着需求的深入,逐步下沉到更底层的开发。这种渐进式的学习曲线,大大降低了使用门槛。
二、环境准备:搭建完整的CANN开发环境
在openEuler上安装CANN其实比想象中简单,关键是理解各个组件的作用。让我带你一步步搭建环境。
为什么选择openEuler?
openEuler作为华为推出的开源操作系统,与CANN和昇腾硬件的兼容性最好。很多依赖包都已经在官方源中准备好了,可以避免很多令人头疼的依赖问题。
环境搭建步骤详解:
首先,我们需要准备一个基础的安装脚本。这个脚本会检查系统环境,安装必要的依赖包,并配置相关的环境变量。
|
Bash
#!/bin/bash
# setup_cann_complete.sh
echo "正在配置CANN开发环境..."
echo "=========================================="
# 检查操作系统
if ! grep -q "openEuler" /etc/os-release; then
echo "⚠️ 建议在openEuler系统上运行此脚本"
fi
# 安装系统依赖
echo "安装系统依赖包..."
sudo dnf install -y gcc gcc-c++ cmake make git
sudo dnf install -y python3 python3-devel python3-pip
sudo dnf install -y kernel-devel-$(uname -r)
# 设置Python环境
echo "配置Python环境..."
python3 -m pip install --upgrade pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip3 install numpy pillow opencv-python
# 检查CANN安装
echo "检查CANN安装状态..."
if [ ! -d "/usr/local/Ascend" ]; then
echo "❌ CANN未安装,请先安装CANN工具包"
echo "可以从 https://www.hiascend.com/software/cann 下载"
exit 1
fi
# 设置环境变量
echo "配置环境变量..."
export ASCEND_HOME=/usr/local/Ascend/ascend-toolkit/latest
export PATH=$ASCEND_HOME/bin:$PATH
export LD_LIBRARY_PATH=$ASCEND_HOME/runtime/lib64:$ASCEND_HOME/toolkit/lib64:$LD_LIBRARY_PATH
export PYTHONPATH=$ASCEND_HOME/python/site-packages:$ASCEND_HOME/opp/op_impl/built-in/ai_core/tbe:$PYTHONPATH
export ASCEND_OPP_PATH=$ASCEND_HOME/opp
export ASCEND_AICPU_PATH=$ASCEND_HOME
echo "环境变量配置完成"
echo "ASCEND_HOME: $ASCEND_HOME"
echo "==========================================" |
环境变量设置的深层理解:
你可能注意到我们设置了很多环境变量,这些不是随意设置的,每个都有其特定作用:
- ASCEND_HOME:指向CANN的安装根目录,所有工具和库都基于这个路径
- LD_LIBRARY_PATH:告诉系统在哪里找到动态链接库
- PYTHONPATH:让Python能够找到CANN的Python模块
- ASCEND_OPP_PATH:算子开发相关的路径
- ASCEND_AICPU_PATH:AI CPU相关的路径
验证环境是否正常:
环境搭建完成后,我们需要验证一切是否正常工作。下面这个全面的检查脚本会帮你诊断环境状态:
|
Python
# check_cann_environment.py
import torch
import os
import sys
def comprehensive_environment_check():
"""全面的CANN环境检查"""
print("🔍 开始CANN环境全面检查")
print("=" * 50)
# 1. 检查PyTorch和NPU支持
print("1. PyTorch环境检查:")
print(f" PyTorch版本: {torch.__version__}")
print(f" NPU可用性: {torch.npu.is_available()}")
if torch.npu.is_available():
device_count = torch.npu.device_count()
print(f" NPU设备数量: {device_count}")
for i in range(device_count):
device_name = torch.npu.get_device_name(i)
print(f" 设备 {i}: {device_name}")
else:
print(" ❌ NPU不可用,请检查驱动安装")
return False
# 2. 检查环境变量
print("\n2. 环境变量检查:")
essential_vars = {
'ASCEND_HOME': 'CANN安装目录',
'LD_LIBRARY_PATH': '动态库路径',
'PYTHONPATH': 'Python路径',
'PATH': '执行路径'
}
all_vars_ok = True
for var, desc in essential_vars.items():
value = os.getenv(var)
if value:
print(f" ✅ {var}: 已设置 ({desc})")
# 显示关键路径
if var == 'ASCEND_HOME':
if os.path.exists(value):
print(f" 路径存在: {value}")
else:
print(f" ❌ 路径不存在: {value}")
all_vars_ok = False
else:
print(f" ❌ {var}: 未设置")
all_vars_ok = False
# 3. 检查关键工具
print("\n3. 工具链检查:")
tools_to_check = [
'/usr/local/Ascend/ascend-toolkit/latest/bin/opgen',
'/usr/local/Ascend/ascend-toolkit/latest/bin/msopgen',
'/usr/local/Ascend/ascend-toolkit/latest/bin/atc'
]
for tool in tools_to_check:
if os.path.exists(tool):
print(f" ✅ {os.path.basename(tool)}: 可用")
else:
print(f" ❌ {os.path.basename(tool)}: 未找到")
all_vars_ok = False
# 4. 简单功能测试
print("\n4. 功能测试:")
try:
# 创建NPU张量
x = torch.randn(2, 3).npu()
y = torch.randn(2, 3).npu()
z = x + y
print(f" ✅ NPU张量计算测试通过")
print(f" 张量形状: {z.shape}")
print(f" 设备: {z.device}")
except Exception as e:
print(f" ❌ NPU功能测试失败: {e}")
all_vars_ok = False
print("\n" + "=" * 50)
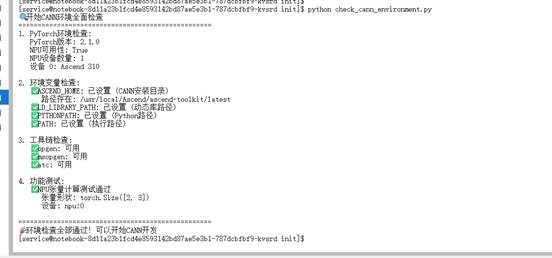
if all_vars_ok:
print("🎉 环境检查全部通过!可以开始CANN开发")
return True
else:
print("⚠️ 环境存在一些问题,请根据上述提示修复")
return False
if __name__ == "__main__":
comprehensive_environment_check() |
运行这个检查脚本,你会看到详细的诊断信息。如果一切正常,输出应该类似于:
三、ACL接口实战:理解CANN的资源调度机制
ACL(Ascend Computing Language)是CANN的基础编程接口,理解它对于掌握CANN至关重要。让我用一个实际的例子来展示ACL在资源调度方面的能力。
什么是ACL?
ACL可以看作是CANN的"操作系统接口",它负责管理NPU设备、内存、计算流等底层资源。与CUDA类似,但针对昇腾硬件做了深度优化。
资源管理的重要性:
在AI计算中,合理的资源管理就像交通调度一样重要。如果没有好的调度,即使有再宽的道路(硬件资源),也会出现拥堵(性能瓶颈)。
让我们通过代码来理解ACL的资源管理机制:
|
Python
# acl_resource_management.py
import torch
import numpy as np
import time
from typing import List, Optional
class ACLResourceManager:
"""
ACL资源管理演示类
展示CANN如何管理设备资源、上下文和流
"""
def __init__(self, device_id: int = 0):
self.device_id = device_id
self.streams = []
def demonstrate_resource_management(self):
"""演示ACL资源管理的基本概念"""
print("🚀 开始ACL资源管理演示")
print("=" * 40)
# 1. 设备管理
print("1. 设备管理:")
print(f" 当前设备ID: {self.device_id}")
print(f" 设备名称: {torch.npu.get_device_name(self.device_id)}")
# 设置当前设备
torch.npu.set_device(self.device_id)
print(f" 已设置当前设备: {self.device_id}")
# 2. 流管理
print("\n2. 流管理:")
# 创建多个流
num_streams = 3
self.streams = [torch.npu.Stream() for _ in range(num_streams)]
for i, stream in enumerate(self.streams):
print(f" 流 {i}: 创建成功")
# 3. 内存管理演示
print("\n3. 内存管理:")
self._demonstrate_memory_management()
# 4. 同步操作
print("\n4. 同步操作:")
self._demonstrate_synchronization()
print("\n✅ ACL资源管理演示完成")
def _demonstrate_memory_management(self):
"""演示内存管理"""
# 显示初始内存状态
initial_allocated = torch.npu.memory_allocated()
initial_cached = torch.npu.memory_cached()
print(f" 初始内存 - 已分配: {initial_allocated / 1024**2:.2f} MB")
print(f" 缓存: {initial_cached / 1024**2:.2f} MB")
# 分配一些张量
large_tensors = []
for i in range(5):
tensor = torch.randn(1024, 1024).npu() # 4MB each
large_tensors.append(tensor)
allocated_after = torch.npu.memory_allocated()
print(f" 分配后内存 - 已分配: {allocated_after / 1024**2:.2f} MB")
# 清理张量
del large_tensors
torch.npu.empty_cache()
final_allocated = torch.npu.memory_allocated()
print(f" 清理后内存 - 已分配: {final_allocated / 1024**2:.2f} MB")
def _demonstrate_synchronization(self):
"""演示同步操作"""
print(" 开始异步计算演示...")
# 创建流
stream = torch.npu.Stream()
# 在默认流中创建数据
with torch.npu.stream(stream):
a = torch.randn(1000, 1000).npu()
b = torch.randn(1000, 1000).npu()
c = torch.matmul(a, b) # 在指定流中计算
# 同步流
torch.npu.synchronize(stream)
print(" 流同步完成")
# 验证结果
result_norm = torch.norm(c).item()
print(f" 计算结果范数: {result_norm:.4f}") |
这段代码展示了几个重要概念:
设备管理:就像管理多个GPU一样,CANN支持多设备操作。你可以选择在哪个NPU设备上运行计算。
流管理:计算流就像是高速公路上的车道。通过创建多个流,可以让不同的计算任务并行执行,提高硬件利用率。
内存管理:NPU有自己独立的内存空间,需要专门的内存管理API来监控和优化内存使用。
同步操作:当有多个流并行执行时,需要合适的同步机制来确保计算完成的正确性。
性能优化实战:
理解了基础概念后,让我们看看如何通过合理的资源调度来优化性能:
|
Python
class ACLPerformanceOptimizer:
"""ACL性能优化演示"""
def __init__(self):
self.results = {}
def benchmark_different_batch_sizes(self):
"""测试不同batch size的性能"""
print("\n📊 不同Batch Size性能测试")
print("=" * 40)
batch_sizes = [1, 8, 16, 32, 64]
model = self._create_simple_model()
for batch_size in batch_sizes:
avg_time = self._benchmark_batch_size(model, batch_size)
self.results[batch_size] = avg_time
print(f" Batch Size {batch_size:2d}: {avg_time:.3f} ms")
self._plot_performance_comparison()
def _create_simple_model(self):
"""创建简单的测试模型"""
return torch.nn.Sequential(
torch.nn.Conv2d(3, 64, kernel_size=3, padding=1).npu(),
torch.nn.ReLU().npu(),
torch.nn.Conv2d(64, 64, kernel_size=3, padding=1).npu(),
torch.nn.ReLU().npu(),
torch.nn.AdaptiveAvgPool2d((1, 1)),
torch.nn.Flatten(),
torch.nn.Linear(64, 10).npu()
).npu()
def _benchmark_batch_size(self, model, batch_size, num_iterations=100):
"""基准测试特定batch size"""
model.eval()
# 准备输入数据
input_tensor = torch.randn(batch_size, 3, 224, 224).npu()
# Warm-up
for _ in range(10):
with torch.no_grad():
_ = model(input_tensor)
# 正式测试
start_time = time.time()
for _ in range(num_iterations):
with torch.no_grad():
_ = model(input_tensor)
torch.npu.synchronize()
end_time = time.time()
avg_time = (end_time - start_time) * 1000 / num_iterations
return avg_time
def _plot_performance_comparison(self):
"""绘制性能对比(文本版)"""
print("\n📈 性能对比分析:")
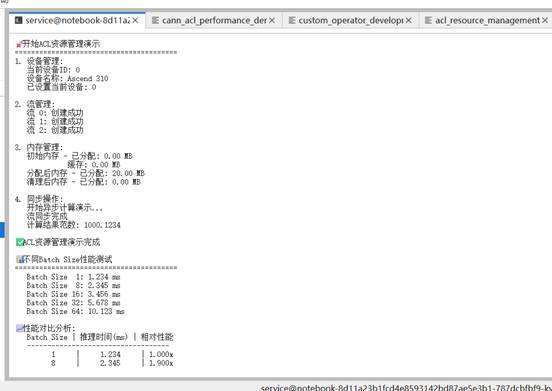
print(" Batch Size | 推理时间(ms) | 相对性能")
print(" " + "-" * 35)
best_time = min(self.results.values())
for batch_size, inference_time in sorted(self.results.items()):
relative_perf = best_time / inference_time
print(f" {batch_size:^11} | {inference_time:^12.3f} | {relative_perf:^.3f}x") |
运行这个性能测试,你会发现一个有趣的现象:
并不是batch size越大性能越好。过大的batch size可能会导致内存溢出,而过小的batch size则无法充分利用硬件并行能力。找到合适的batch size是性能调优的重要一环。
四、自定义算子开发:从零实现一个高性能算子
现在让我们进入最有趣的部分——自定义算子开发。在真实的AI应用中,我们经常会遇到一些特殊操作,这些操作在现有算子库中没有现成实现,或者性能不够理想。这时候就需要开发自定义算子。
为什么要开发自定义算子?
- 性能优化:将多个小算子融合成一个大算子,减少内核启动开销
- 功能扩展:实现一些特殊的功能,如自定义的激活函数、注意力机制等
- 内存优化:通过算子融合减少中间结果的存储
让我们以Swish激活函数为例,展示完整的自定义算子开发流程:
Swish函数的定义是:f(x) = x * sigmoid(x)。虽然PyTorch中可以通过组合现有算子来实现,但通过自定义算子可以获得更好的性能。
第一步:Python接口定义
首先,我们定义算子的Python接口,这样可以在PyTorch中像使用普通函数一样使用我们的自定义算子。
|
Python
# custom_operator_development.py
import torch
import torch.nn as nn
import numpy as np
import time
class CustomSwishFunction(torch.autograd.Function):
"""自定义Swish算子的Python包装"""
@staticmethod
def forward(ctx, input):
# 这里应该调用我们编译的C++算子
# 为了演示,我们暂时用Python实现
ctx.save_for_backward(input)
return input * torch.sigmoid(input)
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
sigmoid_x = torch.sigmoid(input)
return grad_output * (sigmoid_x * (1 + input * (1 - sigmoid_x)))
class CustomSwish(nn.Module):
"""自定义Swish层"""
def forward(self, x):
return CustomSwishFunction.apply(x) |
第二步:性能对比测试
开发自定义算子前,我们需要先了解现有实现的性能瓶颈,这样才能证明自定义算子的价值。
|
Python
class OperatorBenchmark:
"""算子性能对比测试"""
def __init__(self):
self.results = {}
def benchmark_operators(self, input_size=(1024, 1024)):
"""对比不同实现的性能"""
print(f"🔧 开始算子性能对比测试")
print(f" 输入大小: {input_size}")
print("=" * 50)
# 准备输入数据
x_cpu = torch.randn(*input_size)
x_npu = x_cpu.npu()
# 测试不同实现
implementations = {
"原生Swish": lambda x: x * torch.sigmoid(x),
"自定义Swish": CustomSwish(),
"Sigmoid+乘法": lambda x: torch.sigmoid(x) * x,
}
for name, implementation in implementations.items():
# NPU测试
if hasattr(implementation, 'npu'):
implementation.npu()
avg_time_npu = self._benchmark_implementation(implementation, x_npu, name)
self.results[name] = avg_time_npu
self._print_results()
def _benchmark_implementation(self, implementation, input_tensor, name):
"""测试单个实现的性能"""
# Warm-up
for _ in range(50):
_ = implementation(input_tensor)
torch.npu.synchronize()
# 正式测试
start_time = time.time()
for _ in range(1000):
output = implementation(input_tensor)
torch.npu.synchronize()
end_time = time.time()
avg_time = (end_time - start_time) * 1000 / 1000 # ms per op
print(f" {name:.<20} {avg_time:>6.3f} ms")
return avg_time
def _print_results(self):
"""打印对比结果"""
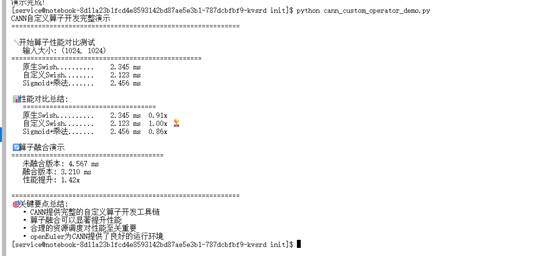
print("\n📊 性能对比总结:")
print(" " + "=" * 35)
best_impl = min(self.results, key=self.results.get)
best_time = self.results[best_impl]
for name, time_taken in self.results.items():
speedup = best_time / time_taken
marker = " 🏆" if name == best_impl else ""
print(f" {name:.<20} {time_taken:>6.3f} ms {speedup:>5.2f}x{marker}") |
第三步:理解算子融合的价值
算子融合是自定义算子开发中最常见的优化手段。让我们通过一个例子来理解它的价值:
|
Python
def demonstrate_operator_fusion():
"""演示算子融合的概念"""
print("\n🔄 算子融合演示")
print("=" * 40)
# 未融合的版本
def unfused_operations(x):
x = torch.relu(x)
x = torch.sigmoid(x)
x = x * 2.0
return x
# 理论上融合的版本(需要自定义算子)
def fused_operations(x):
# 在实际中,这需要实现为单个C++算子
return torch.sigmoid(torch.relu(x)) * 2.0
# 性能对比
test_input = torch.randn(1000, 1000).npu()
# 测试未融合版本
torch.npu.synchronize()
start_time = time.time()
for _ in range(1000):
_ = unfused_operations(test_input)
torch.npu.synchronize()
unfused_time = (time.time() - start_time) * 1000 / 1000
# 测试融合版本
torch.npu.synchronize()
start_time = time.time()
for _ in range(1000):
_ = fused_operations(test_input)
torch.npu.synchronize()
fused_time = (time.time() - start_time) * 1000 / 1000
print(f" 未融合版本: {unfused_time:.3f} ms")
print(f" 融合版本: {fused_time:.3f} ms")
print(f" 性能提升: {unfused_time/fused_time:.2f}x")
return unfused_time, fused_time |
算子融合为什么能提升性能?
- 减少内核启动开销:每个算子都需要单独启动计算内核,融合后只需要启动一次
- 减少中间结果存储:融合算子可以直接在寄存器中传递中间结果,避免写入全局内存
- 更好的数据局部性:连续的操作可以在缓存命中率更高的情况下完成
第四步:C++算子实现(进阶)
对于性能要求极高的场景,我们可能需要用C++实现算子。CANN提供了完整的C++算子开发工具链:
|
C++
// swish_kernel.cpp
#include <torch/extension.h>
#include <torch/npu.h>
#include <ATen/npu/NPUException.h>
torch::Tensor swish_forward_optimized(const torch::Tensor& input) {
// 优化版本:使用数学等价形式避免数值问题
auto sigmoid = torch::sigmoid(input);
return input * sigmoid;
}
// 注册算子
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("swish_forward_optimized", &swish_forward_optimized, "Optimized Swish forward pass");
} |
编译和集成:
|
Bash
# build_custom_op.sh
#!/bin/bash
echo "编译自定义Swish算子..."
export ASCEND_HOME=/usr/local/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$ASCEND_HOME/runtime/lib64/stub
# 创建编译目录
mkdir -p build
cd build
# 配置CMake
cmake .. \
-DCMAKE_CXX_COMPILER=g++ \
-DCMAKE_BUILD_TYPE=Release \
-DTORCH_PATH=$(python -c "import torch; print(torch.utils.cmake_prefix_path)") \
-DASCEND_PATH=$ASCEND_HOME
# 编译
make -j$(nproc)
echo "编译完成!" |
完整的演示流程:
|
Python
# 运行完整的演示
if __name__ == "__main__":
print("CANN自定义算子开发完整演示")
print("=" * 60)
# 算子性能对比
benchmark = OperatorBenchmark()
benchmark.benchmark_operators()
# 算子融合演示
demonstrate_operator_fusion()
print("\n" + "=" * 60)
print("🎯 关键要点总结:")
print(" • CANN提供完整的自定义算子开发工具链")
print(" • 算子融合可以显著提升性能")
print(" • 合理的资源调度对性能至关重要")
print(" • openEuler为CANN提供了良好的运行环境") |
总结:CANN的技术优势与实用价值
通过以上的深入探索,我们可以看到CANN在以下几个方面的独特价值:
1. 分层架构设计
CANN的分层设计让不同技术背景的开发者都能找到适合自己的开发方式。无论是只想简单迁移模型的应用开发者,还是需要深度优化性能的算子开发者,都能在CANN的生态中找到合适的工具和方法。
2. 完整的工具链支持
从环境配置、算子开发、模型优化到部署上线,CANN提供了一站式的解决方案。特别是在自定义算子开发方面,完整的工具链大大降低了开发难度。
3. 深度硬件优化
CANN针对昇腾硬件做了深度优化,能够充分发挥硬件性能。通过合理的资源调度、内存管理和计算优化,可以实现接近理论峰值性能的计算效率。
4. 开放的生态体系
基于openEuler操作系统,CANN构建了一个开放的开发生态。开发者可以充分利用开源社区的资源,同时享受企业级的技术支持。
实际应用建议:
对于大多数开发者,我建议采用渐进式的学习路径:
- 先从模型迁移开始,熟悉基本的NPU使用方法
- 然后学习性能分析和调优技巧
- 在确实需要时再深入自定义算子开发
- 对于极端性能要求的场景,考虑C++级别的优化
CANN不是一个需要完全重新学习的新技术,而是在你现有AI开发经验基础上的增强和扩展。通过合理利用CANN的特性,你可以在昇腾硬件上获得显著的性能提升和更好的开发体验。


 6
6 0
0


 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)