day11常见的调参方式@浙大疏锦行
1.网格搜索2.随机搜索----基于采样的思想,大幅减少搜索的点3.贝叶斯优化-----基于代理模型的思想,用简单的模型(高斯回归、决策树、神经网络)来替代复杂且计算成本高的模型,实现形式多样(sklearn、贝叶斯优化库、optuna)4.time库的计时模块,方便后人查看代码运行时长6.如何给AI提问?
day11常见的调参方式@浙大疏锦行
超参数调整专题1
知识点回顾
1. 网格搜索
2. 随机搜索----基于采样的思想,大幅减少搜索的点
3. 贝叶斯优化-----基于代理模型的思想,用简单的模型(高斯回归、决策树、神经网络)来替代复杂且计算成本高的模型,实现形式多样(sklearn、贝叶斯优化库、optuna)
4. time库的计时模块,方便后人查看代码运行时长
5. 代理模型的思想
6. 如何给AI提问?----最小mvp法则
补充知识:
1. 贝叶斯优化的思想
引入一个平替的模型来替代计算成本过高的原模型,优先考虑可以可以拟合万能公式的模型(神经网络 高斯回归 决策树) ,这个平替的模型称之为代理模型
这里平替模型的思想可以理解为训练成本更低的模型,类比做实验的话,有的仪器运行一次成本很贵,可以找到一个更加简单的仪器或者干脆直接找到一个数学模型,在这个成本更低的模型上进行实验即可;而神经网络、高斯回归、决策树等方法就是这个成本更低的模型,当然了,这次学习用到的机器学习的模型本身就很简单
超参数搜索的过程可以理解为 g(超参数)=结果,让代理模型来学习到这个关系(课上我说的是学习原模型,口误说错了),这个模型g(超参数)其实是已知的,但是计算成本太高。
贝叶斯的关键步骤
1. 初始化n个点,得到n组(超参数,结果)
2. 代入这n组结果到代理模型中,开始连线
3. 利用采集函数(类似于蒙特卡洛算法)的思想来找到线型的概率分布
4. 对决定最不确定的线型的超参数进行带入原函数求解新的m组点
5. 迭代这个过程,不断让代理函数接近g(x),直到达到设置的最大迭代值
这些所谓的模型,我的理解就是一个映射,比如如今的chatgpt训练一次时间非常长,但理论上来说,就算参数再多也不存在遍历不完的情况,所以只要给定所有参数的输入,那么它的输出就是确定的;而模型训练就是利用现有的数据(并非包括了所有可能性)去学习这个输入->输出的规则,也就是一个映射规则。那么现存的优化方法,就可以再一次缩短模型训练的时间,例如可以利用一些成熟的数学模型来简化这个过程,上面提到的神经网络等我目前不太了解,但貌似也是干这个的。
基线模型
KNN
# --- 2. 特征缩放 (仅用于 KNN) ---
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("--- 数据集规模 ---")
print(f"训练集 (80%): {len(X_train)} 样本")
print(f"测试集 (20%): {len(X_test)} 样本")
print("--------------------")

print("\n--- KNN 基线模型 ---")
# 1. 创建 KNN 模型 (使用默认参数: n_neighbors=5, weights='uniform', p=2/欧氏距离)
knn_baseline = KNeighborsClassifier()
# 2. 训练模型 (使用缩放后的训练集)
knn_baseline.fit(X_train_scaled, y_train)
# 3. 在测试集上进行预测 (使用缩放后的测试集)
y_pred_knn = knn_baseline.predict(X_test_scaled)
# 4. 评估模型
accuracy_knn = accuracy_score(y_test, y_pred_knn)
print(f"KNN 默认参数 (K=5) 模型在测试集上的准确率: {accuracy_knn:.4f}")

LightGBM
# =================================================================
# --- 3. LightGBM 基线模型 (默认参数) ---
# =================================================================
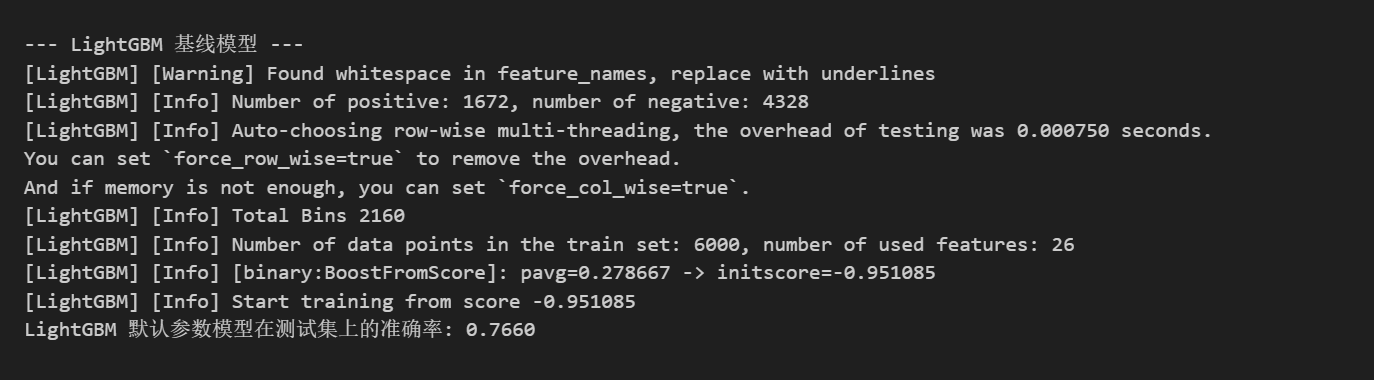
print("\n--- LightGBM 基线模型 ---")
RANDOM_STATE = 42
# 1. 创建 LightGBM 模型 (使用默认参数)
# 注意: LightGBMClassifier 默认参数通常很合理,例如 n_estimators=100, learning_rate=0.1
lgbm_baseline = lgb.LGBMClassifier(random_state=RANDOM_STATE)
# 2. 训练模型 (使用未缩放的训练集)
lgbm_baseline.fit(X_train, y_train)
# 3. 在测试集上进行预测
y_pred_lgbm = lgbm_baseline.predict(X_test)
# 4. 评估模型
accuracy_lgbm = accuracy_score(y_test, y_pred_lgbm)
print(f"LightGBM 默认参数模型在测试集上的准确率: {accuracy_lgbm:.4f}")
网格搜索
KNN
import time
import lightgbm as lgb
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
# =================================================================
# --- 4. KNN 网格搜索 (GridSearchCV) ---
# =================================================================
print("\n--- 4. KNN 网格搜索 ---")
# 定义 KNN 的参数网格
param_grid_knn = {
'n_neighbors': [1, 3, 5, 7, 9, 11], # 搜索 K 值
'weights': ['uniform', 'distance'], # 权重模式
'p': [1, 2] # 距离度量 (1: 曼哈顿距离, 2: 欧氏距离)
}
# 创建 GridSearchCV 对象
# 注意:KNN 模型不需要设置 random_state
grid_search_knn = GridSearchCV(
estimator=KNeighborsClassifier(),
param_grid=param_grid_knn,
cv=5,
scoring='accuracy',
n_jobs=-1
)
start_time = time.time()
# 在缩放后的训练集上进行网格搜索
grid_search_knn.fit(X_train_scaled, y_train)
end_time = time.time()
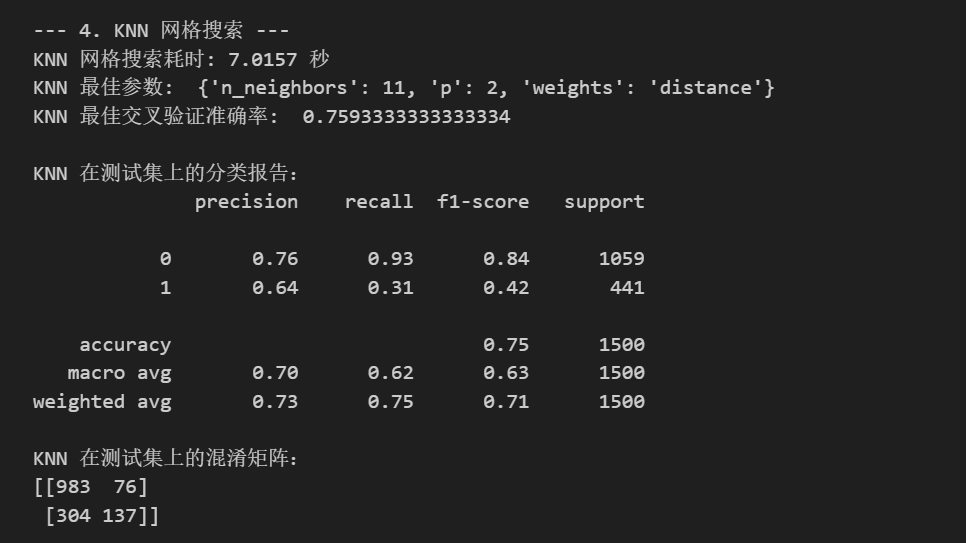
print(f"KNN 网格搜索耗时: {end_time - start_time:.4f} 秒")
print("KNN 最佳参数: ", grid_search_knn.best_params_)
print("KNN 最佳交叉验证准确率: ", grid_search_knn.best_score_ if grid_search_knn.best_score_ is not None else "N/A")
# 使用最佳参数的模型进行最终预测和评估
best_model_knn = grid_search_knn.best_estimator_
best_pred_knn = best_model_knn.predict(X_test_scaled)
print("\nKNN 在测试集上的分类报告:")
print(classification_report(y_test, best_pred_knn))
print("KNN 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred_knn))
LightGBM网格搜索
# =================================================================
# --- 3. LightGBM 网格搜索 (GridSearchCV) ---
# =================================================================
print("\n--- 3. LightGBM 网格搜索 ---")
# 定义 LightGBM 的参数网格 (相对较小的范围以节省时间)
param_grid_lgbm = {
'n_estimators': [100, 200, 300],
'learning_rate': [0.05, 0.1, 0.2],
'num_leaves': [15, 31, 45]
}
# 创建 GridSearchCV 对象
grid_search_lgbm = GridSearchCV(
estimator=lgb.LGBMClassifier(random_state=RANDOM_STATE, verbose=-1, n_jobs=-1),
param_grid=param_grid_lgbm,
cv=5, # 5折交叉验证
scoring='accuracy',
n_jobs=-1 # 使用所有核心进行并行计算
)
start_time = time.time()
# 在训练集上进行网格搜索
grid_search_lgbm.fit(X_train, y_train)
end_time = time.time()
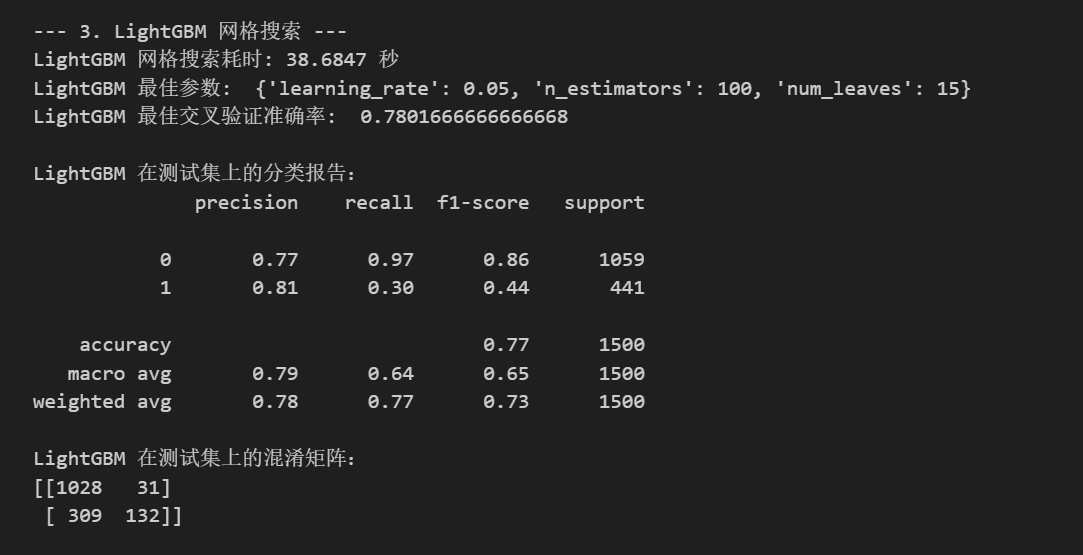
print(f"LightGBM 网格搜索耗时: {end_time - start_time:.4f} 秒")
print("LightGBM 最佳参数: ", grid_search_lgbm.best_params_)
print("LightGBM 最佳交叉验证准确率: ", grid_search_lgbm.best_score_ if grid_search_lgbm.best_score_ is not None else "N/A")
# 使用最佳参数的模型进行最终预测和评估
best_model_lgbm = grid_search_lgbm.best_estimator_
best_pred_lgbm = best_model_lgbm.predict(X_test)
print("\nLightGBM 在测试集上的分类报告:")
print(classification_report(y_test, best_pred_lgbm))
print("LightGBM 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred_lgbm))
随机搜索
KNN
import time
import lightgbm as lgb
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
from scipy.stats import randint, uniform, loguniform
import numpy as np
# =================================================================
# --- 4. KNN 随机搜索 (RandomizedSearchCV) ---
# =================================================================
print("\n--- 4. KNN 随机搜索 ---")
# 定义 KNN 的参数分布空间
param_dist_knn = {
'n_neighbors': randint(low=1, high=20), # 1到20之间随机整数
'weights': ['uniform', 'distance'], # 离散值
'p': [1, 2] # 离散值 (1: 曼哈顿距离, 2: 欧氏距离)
}
# 创建 RandomizedSearchCV 对象
random_search_knn = RandomizedSearchCV(
estimator=KNeighborsClassifier(),
param_distributions=param_dist_knn,
n_iter=15, # KNN参数较少,减少迭代次数
cv=5,
scoring='accuracy',
random_state=RANDOM_STATE,
n_jobs=-1
)
start_time = time.time()
# 在缩放后的训练集上进行随机搜索
random_search_knn.fit(X_train_scaled, y_train)
end_time = time.time()
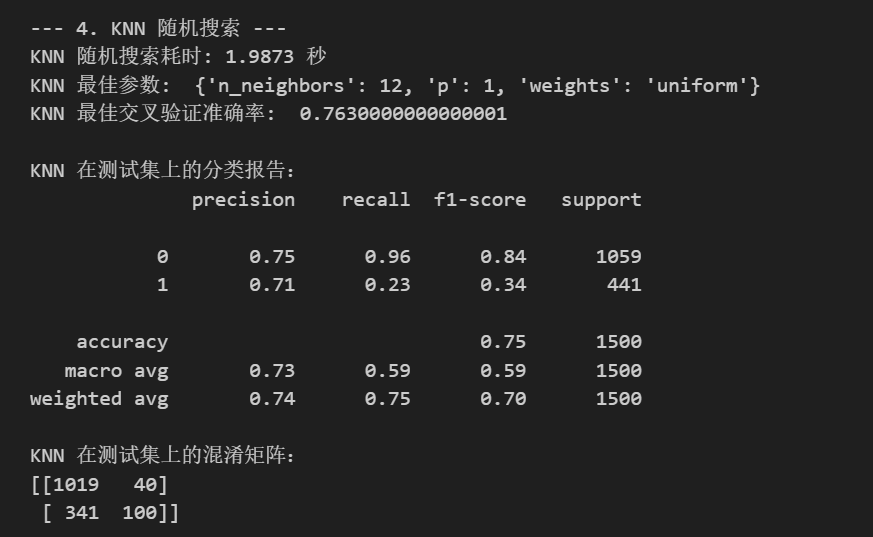
print(f"KNN 随机搜索耗时: {end_time - start_time:.4f} 秒")
print("KNN 最佳参数: ", random_search_knn.best_params_)
print("KNN 最佳交叉验证准确率: ", random_search_knn.best_score_ if random_search_knn.best_score_ is not None else "N/A")
# 使用最佳参数的模型进行最终预测和评估
best_model_knn = random_search_knn.best_estimator_
best_pred_knn = best_model_knn.predict(X_test_scaled)
print("\nKNN 在测试集上的分类报告:")
print(classification_report(y_test, best_pred_knn))
print("KNN 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred_knn))
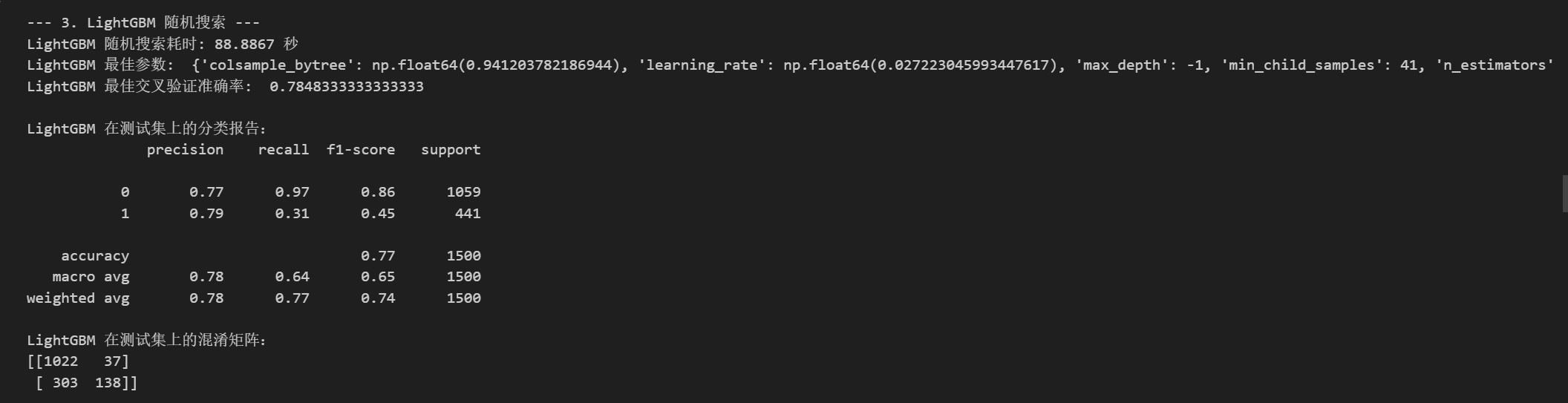
LightGBM随机搜索
# =================================================================
# --- 3. LightGBM 随机搜索 (RandomizedSearchCV) ---
# =================================================================
print("\n--- 3. LightGBM 随机搜索 ---")
# 定义 LightGBM 的参数分布空间
param_dist_lgbm = {
'n_estimators': randint(low=100, high=500), # 100到500之间随机整数
'learning_rate': loguniform(0.01, 0.3), # 0.01到0.3之间的对数均匀分布
'num_leaves': randint(low=10, high=50), # 10到50之间的随机整数
'max_depth': [-1, 5, 10, 20], # 离散值,-1代表无限制
'min_child_samples': randint(low=10, high=50),
'subsample': uniform(0.6, 0.4), # 0.6到1.0之间的均匀分布 (0.6 + 0.4)
'colsample_bytree': uniform(0.6, 0.4) # 0.6到1.0之间的均匀分布
}
# 创建 RandomizedSearchCV 对象
random_search_lgbm = RandomizedSearchCV(
estimator=lgb.LGBMClassifier(random_state=RANDOM_STATE, verbose=-1, n_jobs=-1),
param_distributions=param_dist_lgbm,
n_iter=50, # 随机采样的组合数量,可以根据时间和资源调整
cv=5, # 5折交叉验证 (内部验证)
scoring='accuracy',
random_state=RANDOM_STATE,
n_jobs=-1 # 使用所有核心进行并行计算
)
start_time = time.time()
# 在训练集上进行随机搜索
random_search_lgbm.fit(X_train, y_train)
end_time = time.time()
print(f"LightGBM 随机搜索耗时: {end_time - start_time:.4f} 秒")
print("LightGBM 最佳参数: ", random_search_lgbm.best_params_)
print("LightGBM 最佳交叉验证准确率: ", random_search_lgbm.best_score_ if random_search_lgbm.best_score_ is not None else "N/A")
# 使用最佳参数的模型进行最终预测和评估
best_model_lgbm = random_search_lgbm.best_estimator_
best_pred_lgbm = best_model_lgbm.predict(X_test)
print("\nLightGBM 在测试集上的分类报告:")
print(classification_report(y_test, best_pred_lgbm))
print("LightGBM 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred_lgbm))
贝叶斯优化
KNN
import numpy as np
import time
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
# --- 导入贝叶斯优化和模型库 ---
from skopt import BayesSearchCV
# Real 用于连续参数, Integer 用于离散范围
from skopt.space import Real, Integer
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
import lightgbm as lgb
# =================================================================
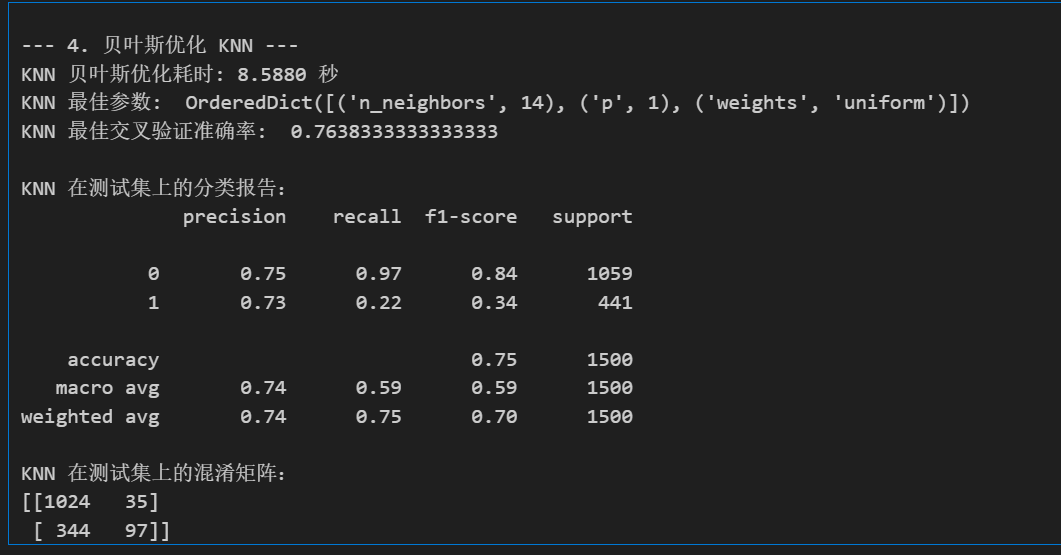
# --- 4. 贝叶斯优化 KNN (KNeighborsClassifier) ---
# =================================================================
print("\n--- 4. 贝叶斯优化 KNN ---")
# 定义 KNN 的参数空间
search_space_knn = {
'n_neighbors': Integer(1, 15), # 搜索 K 值
'weights': ['uniform', 'distance'], # 权重模式 (均匀或距离加权)
'p': Integer(1, 2) # 距离度量 (p=1: 曼哈顿距离, p=2: 欧氏距离)
}
# 创建贝叶斯优化搜索对象
# 注意:KNN 必须使用缩放后的数据 X_train_scaled, X_test_scaled
bayes_search_knn = BayesSearchCV(
estimator=KNeighborsClassifier(),
search_spaces=search_space_knn,
n_iter=16, # KNN参数较少,减少迭代次数
cv=5,
n_jobs=-1,
scoring='accuracy',
random_state=RANDOM_STATE
)
start_time = time.time()
# 在缩放后的训练集上进行贝叶斯优化搜索
bayes_search_knn.fit(X_train_scaled, y_train)
end_time = time.time()
print(f"KNN 贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("KNN 最佳参数: ", bayes_search_knn.best_params_)
print("KNN 最佳交叉验证准确率: ", bayes_search_knn.best_score_ if bayes_search_knn.best_score_ is not None else "N/A")
# 使用最佳参数的模型进行预测和评估
best_model_knn = bayes_search_knn.best_estimator_
best_pred_knn = best_model_knn.predict(X_test_scaled)
print("\nKNN 在测试集上的分类报告:")
print(classification_report(y_test, best_pred_knn))
print("KNN 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred_knn))
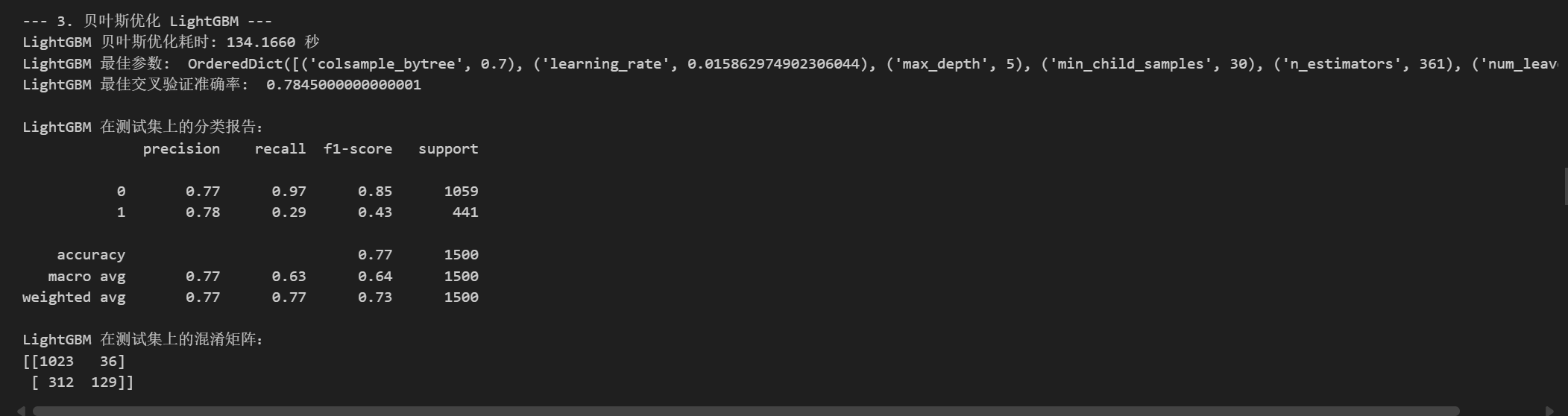
LightGBM
# =================================================================
# --- 3. 贝叶斯优化 LightGBM (LGBMClassifier) ---
# =================================================================
print("\n--- 3. 贝叶斯优化 LightGBM ---")
# 定义 LightGBM 的参数空间
search_space_lgbm = {
'n_estimators': Integer(100, 500), # 树的数量
'learning_rate': Real(0.01, 0.3, prior='log-uniform'), # 学习率(对数均匀分布)
'num_leaves': Integer(20, 40), # 每棵树的最大叶子数
'max_depth': Integer(5, 15), # 树的最大深度
'min_child_samples': Integer(10, 30), # 叶子节点最小数据量
'colsample_bytree': Real(0.7, 1.0, prior='uniform') # 特征采样率 (0.7到1.0均匀分布)
}
# 创建贝叶斯优化搜索对象
bayes_search_lgbm = BayesSearchCV(
estimator=lgb.LGBMClassifier(objective='multiclass',
num_class=3,
random_state=RANDOM_STATE,
n_jobs=-1,
verbose=-1 # 关闭冗余输出
),
search_spaces=search_space_lgbm,
n_iter=32,
cv=5,
n_jobs=-1,
scoring='accuracy',
random_state=RANDOM_STATE
)
start_time = time.time()
# 在训练集上进行贝叶斯优化搜索
bayes_search_lgbm.fit(X_train, y_train)
end_time = time.time()
print(f"LightGBM 贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("LightGBM 最佳参数: ", bayes_search_lgbm.best_params_)
print("LightGBM 最佳交叉验证准确率: ", bayes_search_lgbm.best_score_ if bayes_search_lgbm.best_score_ is not None else "N/A")
# 使用最佳参数的模型进行预测和评估
best_model_lgbm = bayes_search_lgbm.best_estimator_
best_pred_lgbm = best_model_lgbm.predict(X_test)
print("\nLightGBM 在测试集上的分类报告:")
print(classification_report(y_test, best_pred_lgbm))
print("LightGBM 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred_lgbm))

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)