IntaLink:让数据的“关系”成为智能时代的底层算力
IntaLink创新性地提出将"表间关系"作为智能计算底座,通过五大核心能力解决数据治理痛点:智能发现表间关系、构建关系语义图谱、多源异构融合、指标口径统一及开放生态嵌入。该引擎显著提升了智能问数准确率(38%)、SQL可执行率(45%),实现跨部门指标100%一致性,并降低AI错误理解率70%。
一、为什么智能化时代需要“关系引擎”
过去十年,企业的数字化建设从数据仓库、数据中台一路发展到智能问数、AI Copilot、知识图谱等新形态。
然而,无论形式如何变化,核心痛点始终未解:
-
表越来越多,表间关系越来越模糊;
-
系统越来越复杂,跨源融合越来越脆弱;
-
模型越来越强大,但上下文依赖仍靠人脑维护。
结果就是:
数据在企业内部被“看似打通”,但实际上仍然碎片化、不可迁移、不可解释。
这就是 IntaLink 诞生的背景 ——
它不是又一个数据平台,而是一个让“表间关系”成为智能时代计算底座的引擎。
二、IntaLink 的核心能力:让“关系”成为第一公民
1. 🔗 表间关系智能发现
IntaLink 自动识别不同表、不同库之间的结构与语义关联:
-
主外键与候选键识别
-
编码映射与实体对齐
-
同义字段与别名识别
-
时序锚点识别(如账期、业务日期)
✅ 没有 IntaLink 时:
人工维护表关系文档,靠 ETL 工程师“记忆”映射规则,迁移即崩溃。💡 有了 IntaLink:
系统可自动绘制关系网络,Join 逻辑、实体映射、字段上下文实时可见,且可导出/复用到 BI、RAG、AI 模块。
2. 🧠 关系语义图谱(Relation Graph)
IntaLink 把结构化关系映射为图谱节点与链路,使 AI 能理解“字段与业务”的内在语义。
-
每条关系带有置信度、打分权重
-
支持多层关系链路(直接、间接、衍生)
-
可被上层问数、分析、AI Agent 调用
✅ 没有 IntaLink 时:
大模型 NL2SQL 在模糊语境中“猜”Join,误连、漏连、重复计算频发。💡 有了 IntaLink:
AriLink 等智能问数应用可直接调用关系图谱,自动确定最优 Join 路径、验证一致性,实现稳定、可信的 SQL 生成。
3. 🧩 多源异构融合
IntaLink 支持多种数据库与数据湖引擎:MySQL、PostgreSQL、达梦、金仓、openGauss、Hive、Iceberg、Trino……
-
自动抽取各源的元数据与统计信息
-
对齐不同数据源的主数据实体
-
标准化方言与类型映射
-
提供统一查询接口与跨源 Join 引擎
✅ 没有 IntaLink 时:
跨库分析要靠中台统一抽数,数据延迟高、ETL 成本大。💡 有了 IntaLink:
直接在“逻辑层”拼接多源表,联邦查询可解释、可追溯、可复用。
4. 📈 关系资产化与指标口径统一
IntaLink 把“关系”变成可复用的企业级资产:
-
指标注册表:每个业务指标与其关系链绑定
-
口径资产:时间窗、维度层级、过滤逻辑统一管理
-
版本追踪:任意口径变化可回溯、对比
✅ 没有 IntaLink 时:
同一指标在不同系统间不一致,财务与运营数据经常“打架”。💡 有了 IntaLink:
所有上层应用都共用一套“可验证”的口径关系链,数据标准一体化。
5. ⚙️ 开放接口与生态嵌入
IntaLink 提供完整的 API、SDK 与插件生态,可嵌入至:
-
智能问数平台(AriLink、ChatBI)
-
报表系统(FineReport、QuickBI、Power BI)
-
AI Agent 市场(MCP Market)
-
元数据治理平台与数据目录
💡 这样,IntaLink 不仅是一个底层引擎,更是一个关系智能基础设施,为上层生态持续供能。
三、典型应用场景与对比
🌟 场景一:智能问数(AriLink)
任务:用户提问“最近一个月退款率上升最快的品类?”
数据分布:订单库、退款库、商品库(跨三个数据源)
-
自动识别订单-退款-商品三表关系链
-
基于路径置信度选择最佳 Join
-
提供“路径决策书”解释 SQL 逻辑
-
权限策略提前校验
-
最终 SQL 一次生成、零重试
-
传统方式:LLM 生成 NL2SQL 语句,凭字段名“猜” Join,误连率 >30%。
-
IntaLink 支撑:
✅ 结果:准确率提升 38%,SQL 可执行率提升 45%,解释覆盖率 100%。
🌟 场景二:指标口径统一
任务:不同部门在 BI 报表中定义的“活跃客户数”不一致。
传统方式:各自维护计算逻辑、Excel 补口径、反复协调。
IntaLink 支撑:
-
识别各报表中涉及的关系链
-
对齐客户实体主键
-
将统一口径注册为指标资产
-
所有系统自动复用一致计算逻辑
✅ 结果:口径一致率 100%,跨部门对齐时间从 2 周缩短到 1 天。
🌟 场景三:AI Copilot 数据理解
任务:企业构建自己的 AI Copilot,需要理解业务指标、报表字段与模型输出。
传统方式:AI 模型只能“背诵”文档知识,无法理解指标间逻辑关系。
IntaLink 支撑:
-
向 Copilot 提供关系图谱 API 与指标注册表
-
Copilot 能解释“指标如何计算”“字段如何关联”
-
输出“基于关系链”的自然语言解释
✅ 结果:AI 问答解释性增强 3 倍,错误理解率下降 70%。
四、从“人维持的关系”到“系统自演化的关系”
IntaLink 的价值不止是“节省时间”,而是让企业的数据资产自我进化。
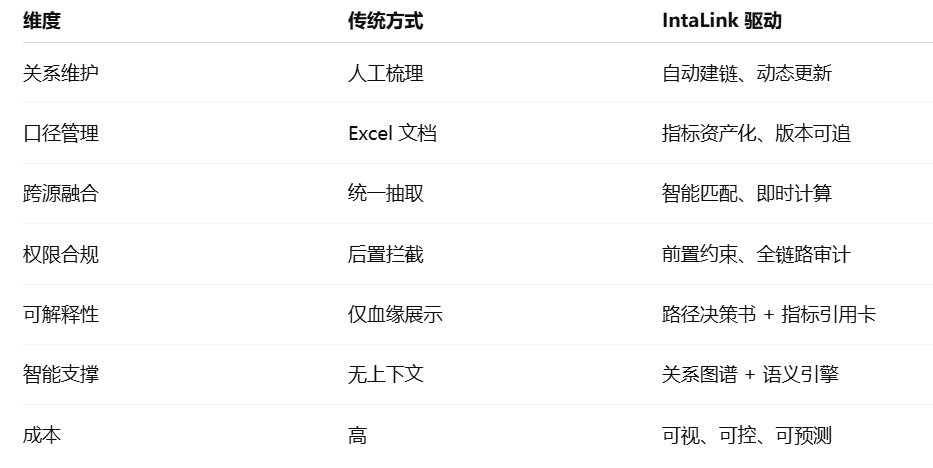
五、IntaLink 的战略意义:让数据关系成为智能时代的新算力
数据的本质,不是表,不是字段,而是关系。
AI 时代的每一个上层应用——智能问数、Copilot、指标治理、知识图谱、RAG 检索——都依赖于底层的关系准确性、稳定性与可解释性。
而 IntaLink,正是这套关系智能的计算引擎。
它让企业拥有的不再是一堆表,而是一张可以理解、计算、演化的数据关系网。
🔹 有了 IntaLink
-
数据分析从“重人力”变为“重智能”
-
数据问答从“能用”变成“可信”
-
数据资产从“静态结构”变为“动态关系”
🔹 IntaLink 不是一个产品,而是一种底座能力
它将成为企业智能化的“关系神经系统”,
让上层所有 AI 应用,都能问得准、连得通、解释清、信得过。
👉 如果你正在建设智能问数、AI Copilot 或数据中台,
请先问一句:我的关系底座,是否已准备好?
IntaLink —— 数据表间的 Google Map。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)