MLA2025-东南大学-Top Conference Review
所有顶会:VLDBoral 口头报告poster 张贴海报workshop:一般都是某些大牛觉得该领域有哪些方面是研究热点,就向会议chair申请开一个独立的研讨会,值得注意的是workshop是独立审稿的。AC 是 Area Chair 领域专家SAC 是 Senior ACMeta-review 是对多个评审专家意见的综合评审,desk reject:一些版面情况的 拒稿审稿过程:一般会快速看
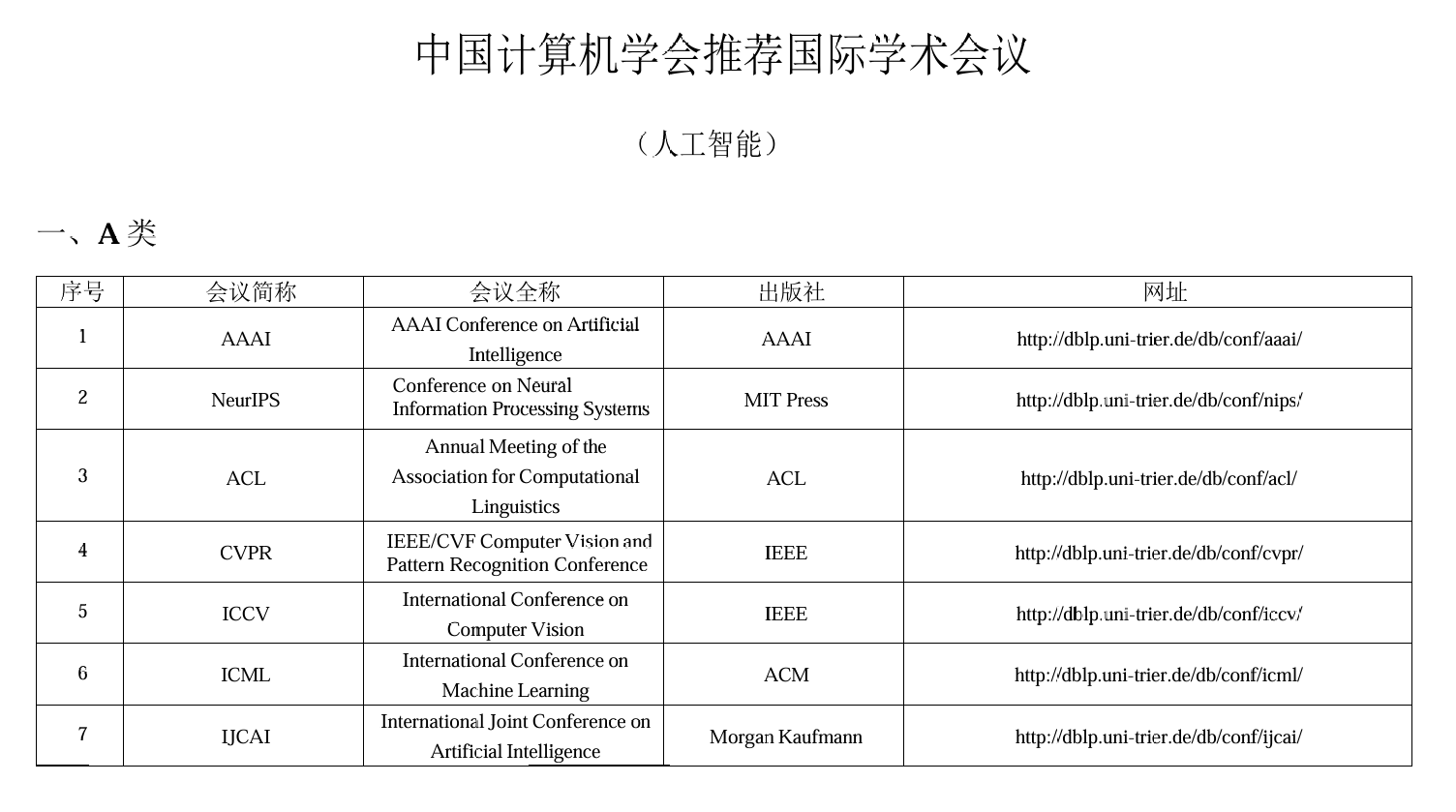
所有顶会:
ML(machine learning):
- ICML
- NeurIPS
- COLT
- ICLR
AI:
- IJCAI
- AAAI
DM:
- KDD
Applications:
- CVPR
- ICCV
- MM
- ACL
VLDB
论文投稿流程:
https://blog.csdn.net/qq_44722174/article/details/118440400
从评审专家的角度看,论文投稿之后会经历什么:
https://www.sohu.com/a/778110086_121119001
oral 口头报告
poster 张贴海报
workshop:一般都是某些大牛觉得该领域有哪些方面是研究热点,就向会议chair申请开一个独立的研讨会,值得注意的是workshop是独立审稿的。
AC 是 Area Chair 领域专家 SAC 是 Senior AC
Meta-review 是对多个评审专家意见的综合评审,
desk reject:一些版面情况的 拒稿
审稿过程:
一般会快速看一遍摘要和引言部分。看动机/故事是否合理;贡献总结得是否有价值。然后看后面的方法和实验,主要看贡献是否被足够地支撑了。部分文章会看下实验结果和 baseline 是否 solid。过程中会关注下 typo。看完之后,看看优点多还是缺点多,是中还是拒。
1.ICML:
国际机器学习会议 (International Conference on Machine Learning)
会议流程(年度周期)
ICML 的年度周期通常如下:
- 1月-2月:论文投稿截止。
- 3月-5月:审稿期(包括 rebuttal / 作者反馈阶段)。
- 5月底:论文录用结果通知。
- 7月-8月:会议正式举行(通常在北美洲或欧洲的夏季)。
会议进程:

词云:
- Language:329 语言
- Multi:212
- large:211
- Diffusion:208 扩散
- Efficient:193 效率
- Optimization:190 优化
- Time:176
- Graph:173
- Traing:143
- Reinforcement:141 强化学习
杰出论文:
Outstanding Papers
- CollabLLM: From Passive Responders to Active Collaborators
- Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions
- Conformal Prediction as Bayesian Quadrature
- Score Matching with Missing Data
- Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
- The Value of Prediction in Identifying the Worst-Off
- Position: The AI Conference Peer Review Crisis Demands Author Feedback and Reviewer Rewards
- Position: AI Safety should prioritize the Future of Work
Conference heightlight 会议亮点
position paper 观点论文 。对应的是Research Paper 研究论文
Profound insights 深刻的见解, controversial perspectives or future directions 有争议的观点或未来方向
是ICML第二年接受position paper 71/361 19.67% 中稿率
Position paper topics:
- Reflection and Optimization on AI Evaluation Systems
- 对人工智能评估系统的反思与优化
- Explainable AI
- 可解释人工智能 (XAI)
- AI Safety, Ethics, and Regulation
- 人工智能安全、伦理与监管
- Technical Limitations of LLMs
- 大型语言模型 (LLMs) 的技术限制
- Balancing AI and Its Societal Impacts
- 平衡人工智能及其社会影响
Hot / emerging topics
- Reinforcement Learning 强化学习
- Offline Reinforcement Learning
- 离线强化学习
- Safe Reinforcement Learning
- 安全强化学习
- Multi-agent Reinforcement Learning
- 多智能体强化学习
- Multi-objective Reinforcement Learning
- 多目标强化学习
- Inverse Reinforcement Learning
- 逆强化学习
- Offline Reinforcement Learning
NeurIPS
Conference on Neural Information Processing System 神经信息处理系统打会
投稿时间:2025年5月15日
反驳时间:2025年7月24日
通知时间:2025年9月18日
会议时间:2025年 11月30 日-12月7日
投稿论文:21575 录取:5290 录用率:24.52%
oral:77 Spotlight 688
除了主要的论文,还有 Datasets 和 Benchmarks Track(基准测试追踪)
- 一组标准化的测试任务 (A Set of Standardized Test Tasks): “Benchmarks” (基准测试) 指的是一系列被普遍接受的、用于衡量特定算法、模型或系统的性能的标准化任务或数据集。这些任务通常被设计来模拟真实世界中的应用场景,并且有明确的评估指标。
- 用于比较和评估 (For Comparison and Evaluation): 这些基准测试的目的是提供一个公平的平台,让不同的研究者或团队可以比较他们提出的新方法、算法或模型的表现。通过在相同的基准测试上进行测试,可以客观地评估哪个方法更优。
- 追踪进步 (Tracking Progress): “Track” (追踪) 强调的是持续的、系统的评估过程。一个 “Benchmarks Track” 可能意味着:
- 一个长期的项目: 持续收集和更新基准测试数据集。
- 一个评估流程: 规定了如何提交结果、如何进行评分、如何公布排行榜等。
- 一个研究方向: 专门关注如何设计更好的基准测试、如何改进评估方法。
也是新增加了 Position Paper Track
录用率 8%

发现了一个 AI 评审论文的网站:https://review.cspaper.org
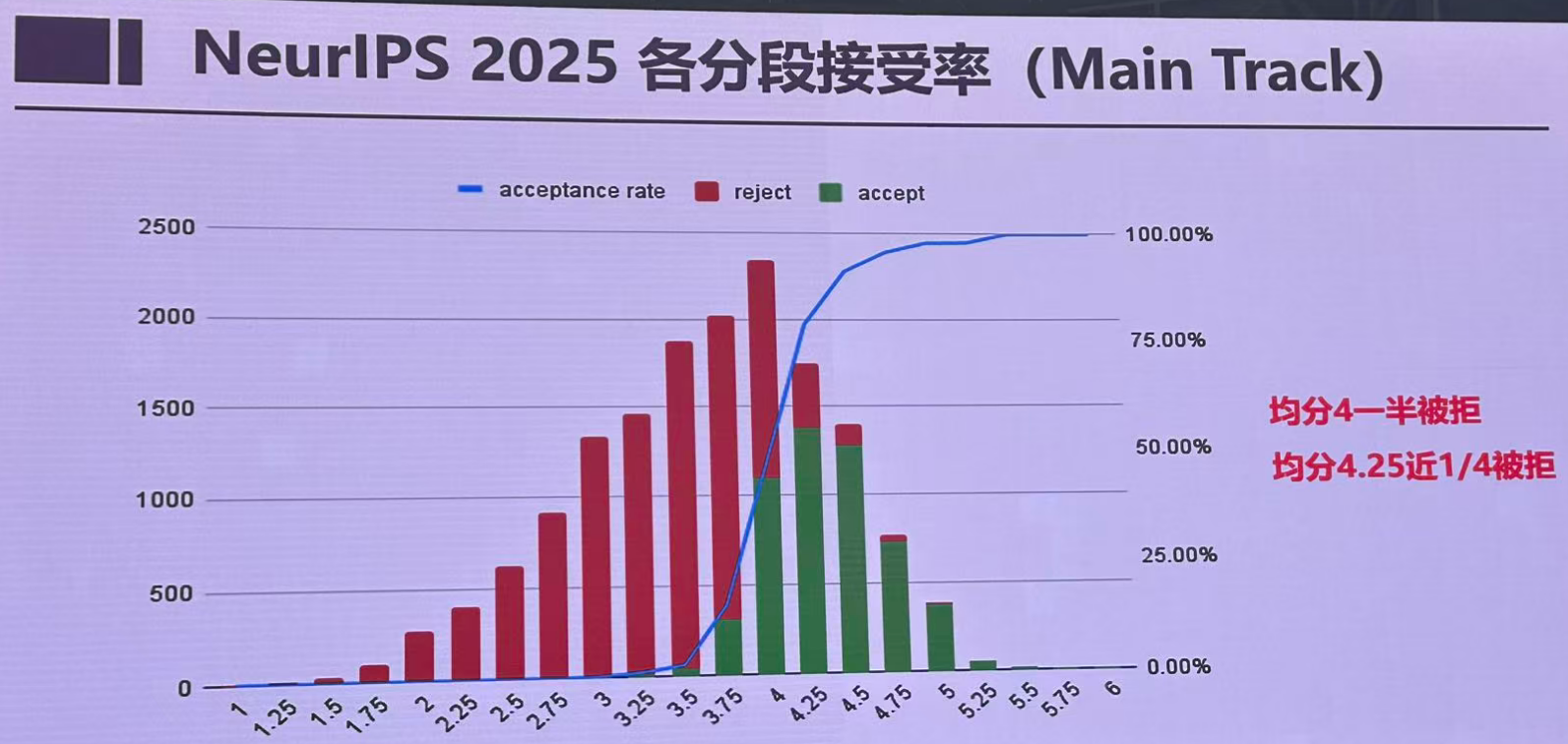
1. 评分机制
- 6分制评分标准:审稿人对论文采用1-6分制,评分含义如下:
- 6分:强接受(Strong Accept)
- 5分:弱接受(Weak Accept)
- 4分:边界接受(Borderline Accept)
- 3分:边界拒绝(Borderline Reject)
- 2分:弱拒绝(Weak Reject)
- 1分:强拒绝(Strong Reject)
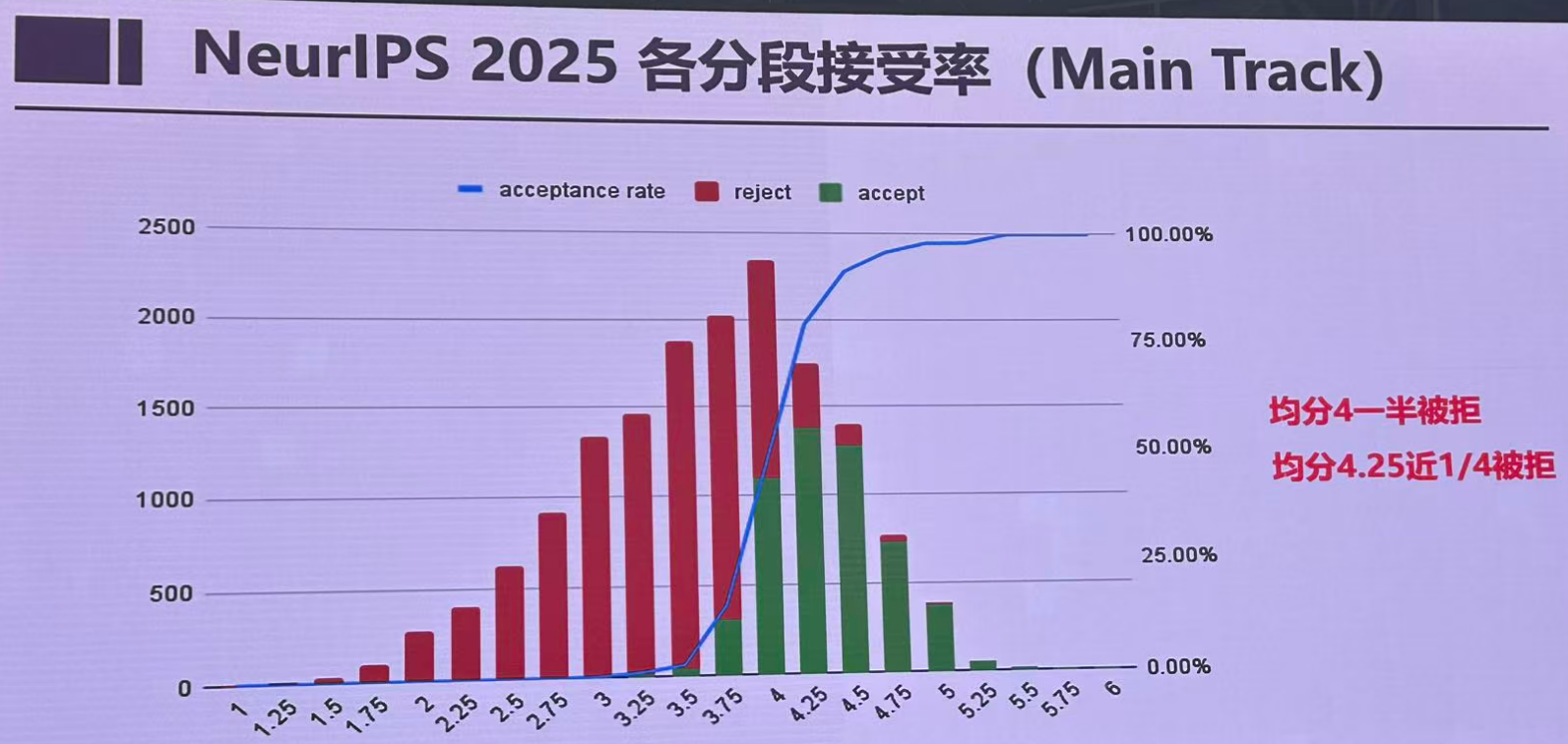
词云:

反驳阶段:

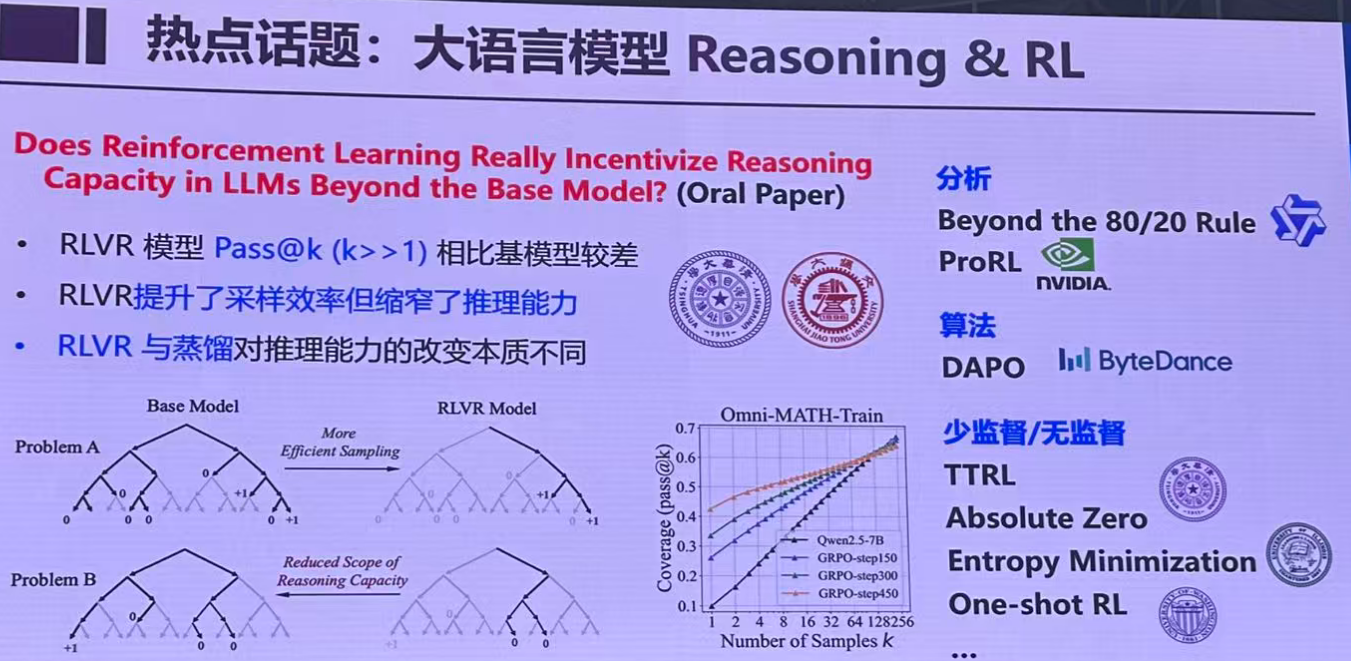
热点话题:
- 大语言模型 Reasoning and RL(推理)
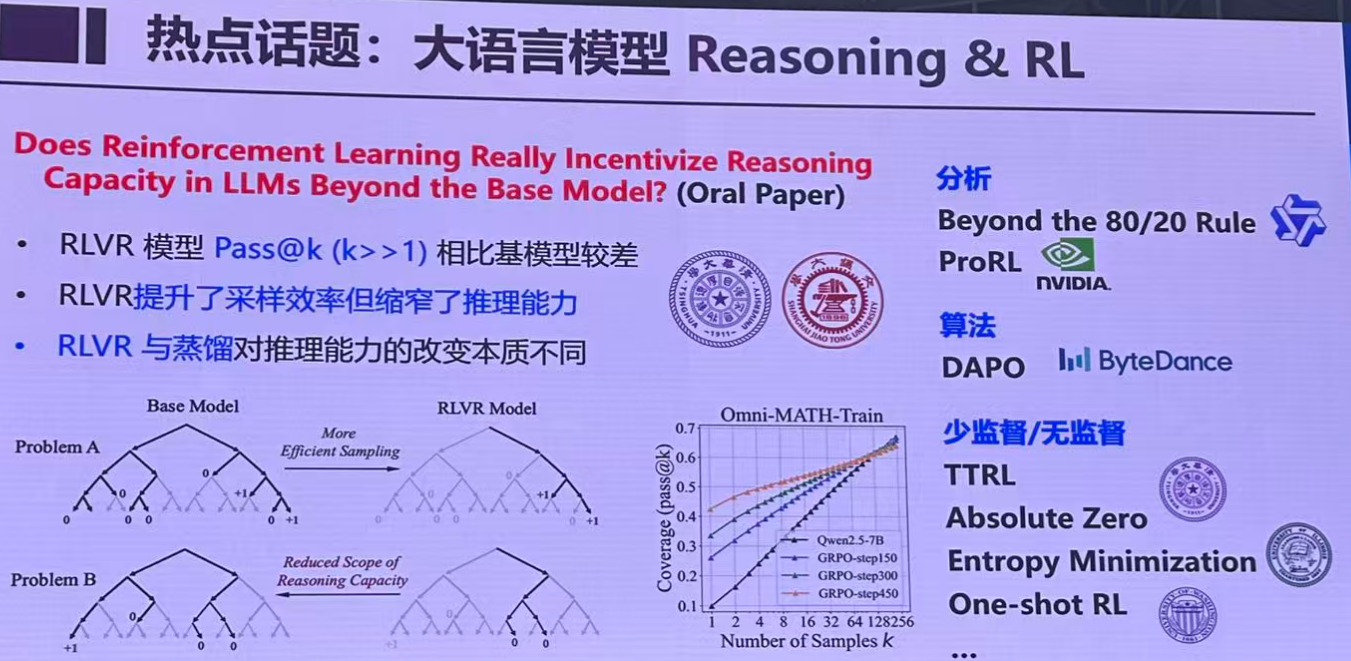
- 扩散模型

- 视觉生成模型

- 多模态

- AI4S
COLT 2025
Annual Conference on Learning Theory 国际学习理论大会
第38届 COLT是机器学习理论领域的顶级国际会议,由计算学习协会(ACL)主办,始于1988年,聚焦于学习理论与算法分析的交叉研究,强调数学严谨性与理论创新
在CCF (人工智能) 为B类
中搞情况:
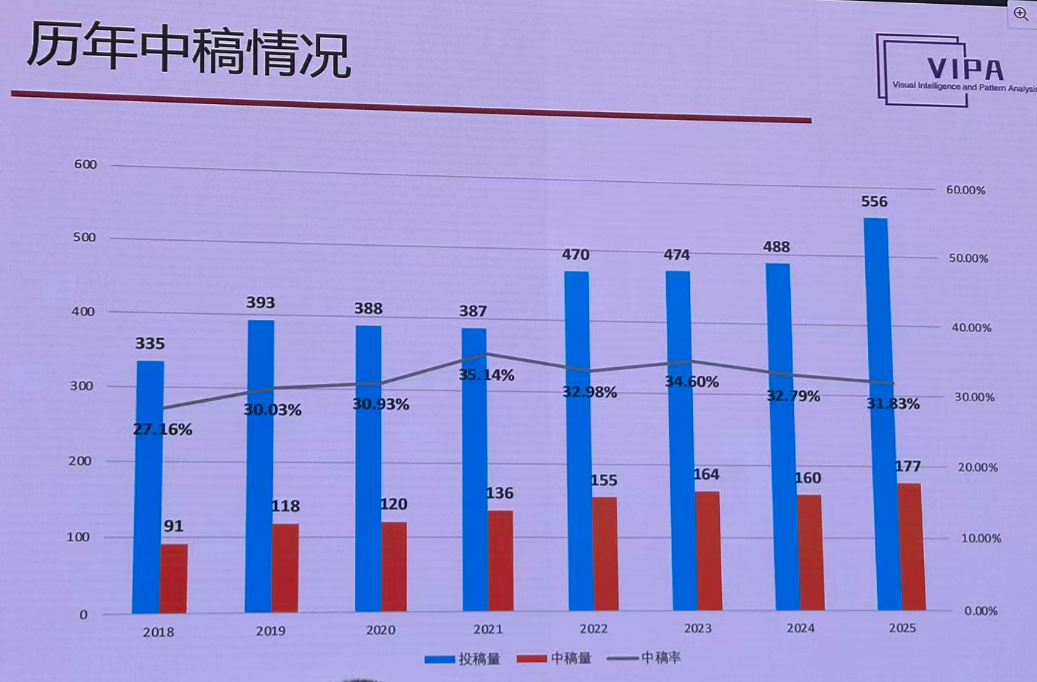
做理论的中稿率还是高一点,可能是投稿人对自己的要求会比较高。
ICLR
International Conference on Learning Representations (国际表征学习大会)
表征学习,也称为特征学习,其核心思想是:让机器自动地从原始数据(如图像的像素、文本的单词、音频的声波)中发现和提取出对后续任务(如分类、检测)更有用的表示形式或特征。
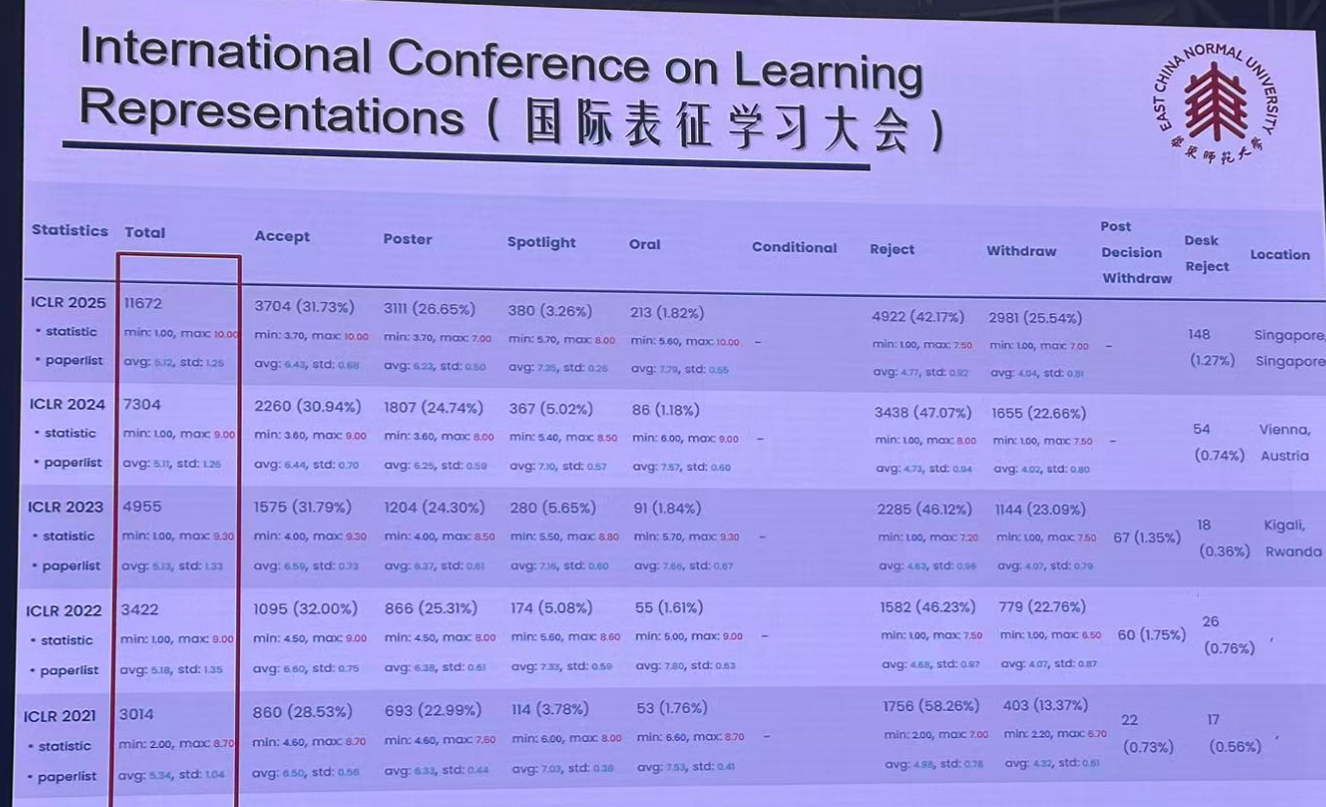
投稿,中稿情况:
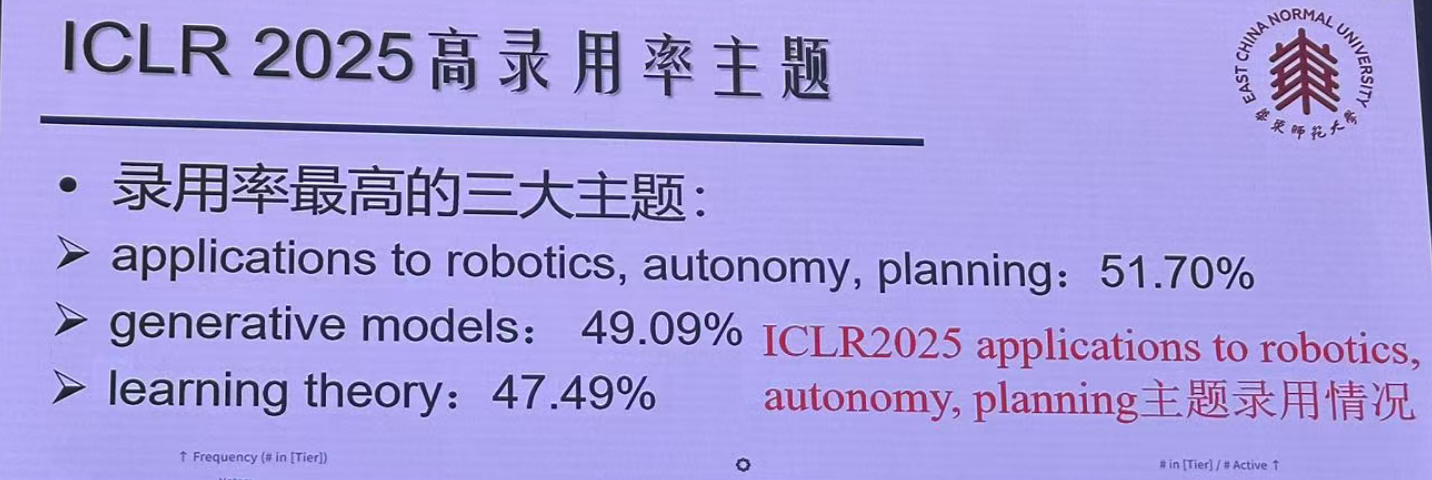
高录用主题:
ICLR 2025 — 热点、趋势、建议
- 安全与对齐
- 模型可编辑性与知识更新
- 理解与优化微调过程
- 数据质量与评估
- 多模态能力提升
- 高效计算(推理)
- 多智能体系统与协作
重视discussions and limitations, 重视rebuttal
IJCAI 2025
投稿截止时间 2025年1月24日
International Joint Conference on Artificial Intelligence 国际人工智能联合会议
投稿5404 录用 1042
录用率 19.3% 机器学习领域 17.7%
AAAI 2025
Association for the Advancement of Artificial Intelligence
截止日期:2024 年 8 月中旬
会议日期: 2025年2月25日 - 3月4日
吴恩达发表了讲话
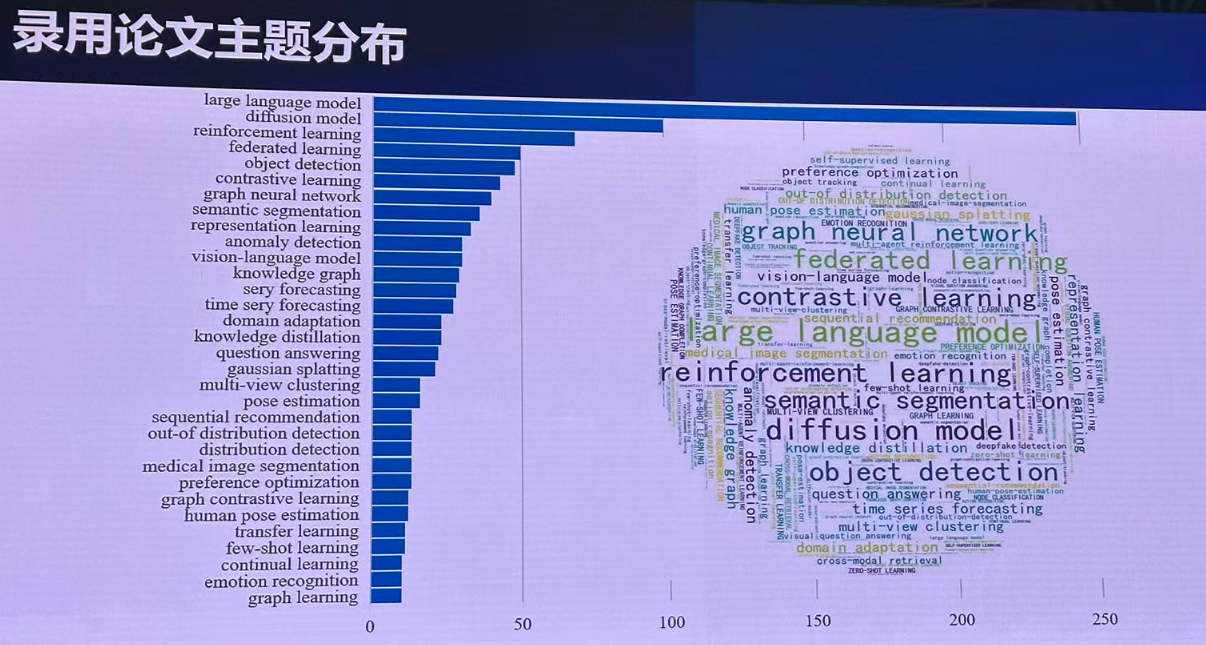
录用主题分布:
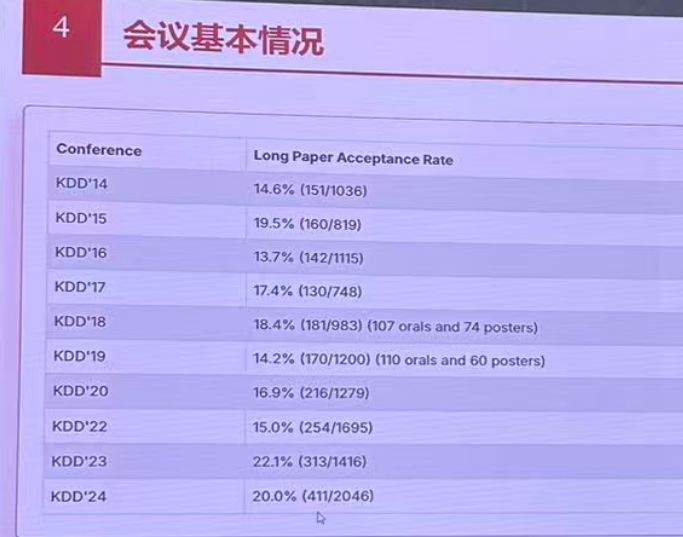
KDD 2025
Knowledge Discovery and Data Mining
在CCF (数据库/数据挖掘/内容检索) 为A类会议
数据挖掘会议
投稿机制:首次采用双轮次投稿机制(8月轮 + 2月轮)

投稿情况:
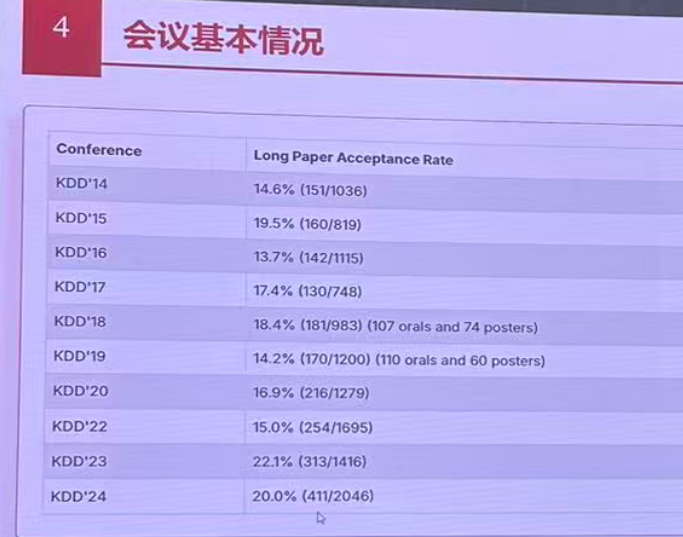
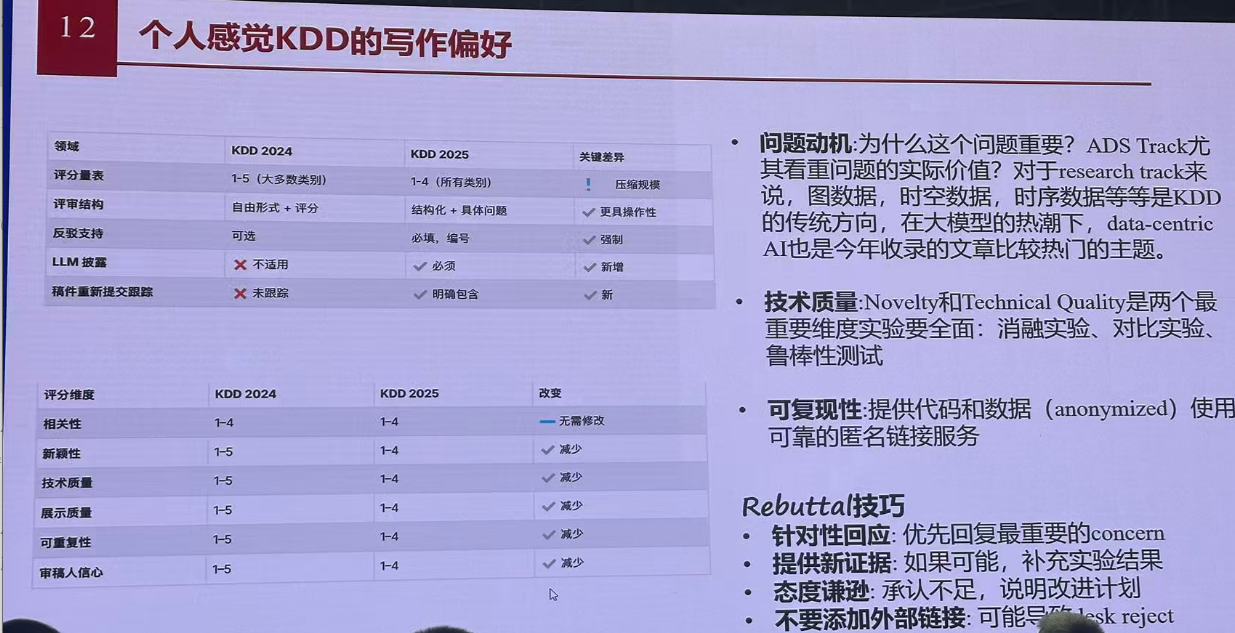
研究热点:

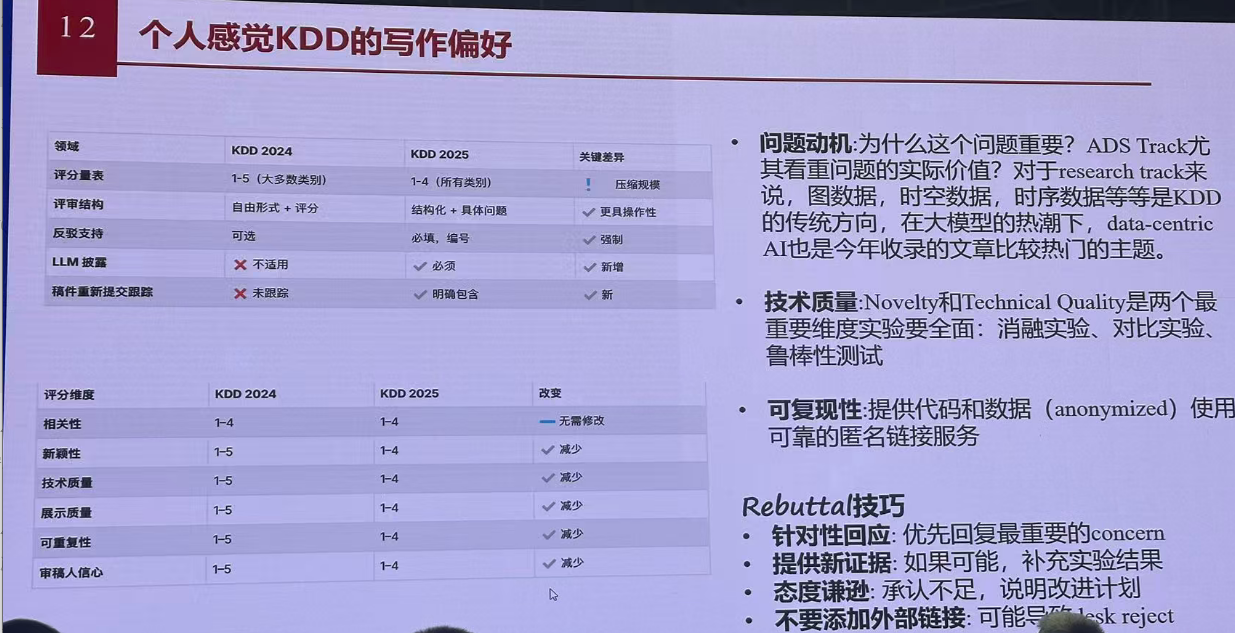
写作偏好:
CVPR
Computer Vision and Pattern Recognition Conference 计算机视觉与模式识别会议
会议时间/地点:2025年6月11日至15日,美国,纳什维尔
截稿时间:2024年11月14日
录用通知时间:2025年4月31日
HOT Topics:

ICCV
International Conference on Computer Vision 计算机视觉国际大会
截稿时间:2025年3月7日
录用通知时间:2025年6月20日
每两年举办一次
HOT Topic:
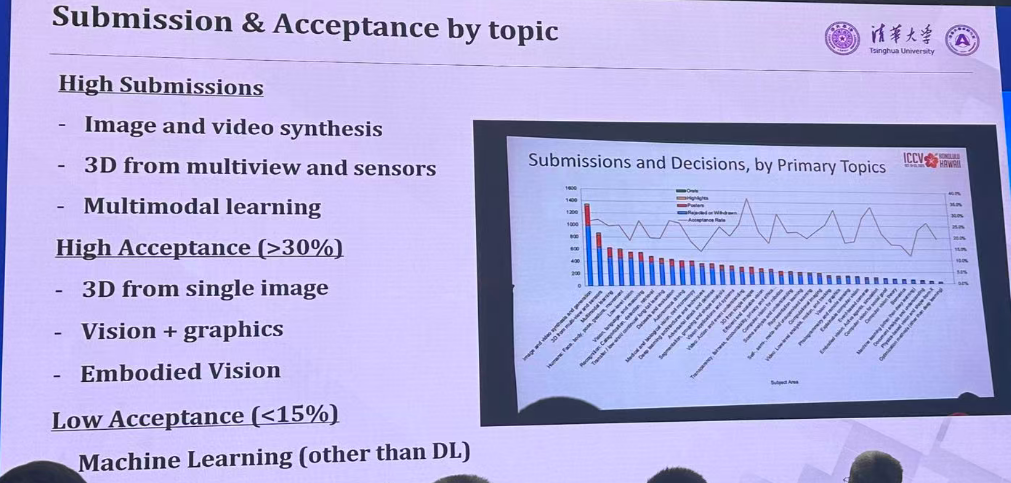
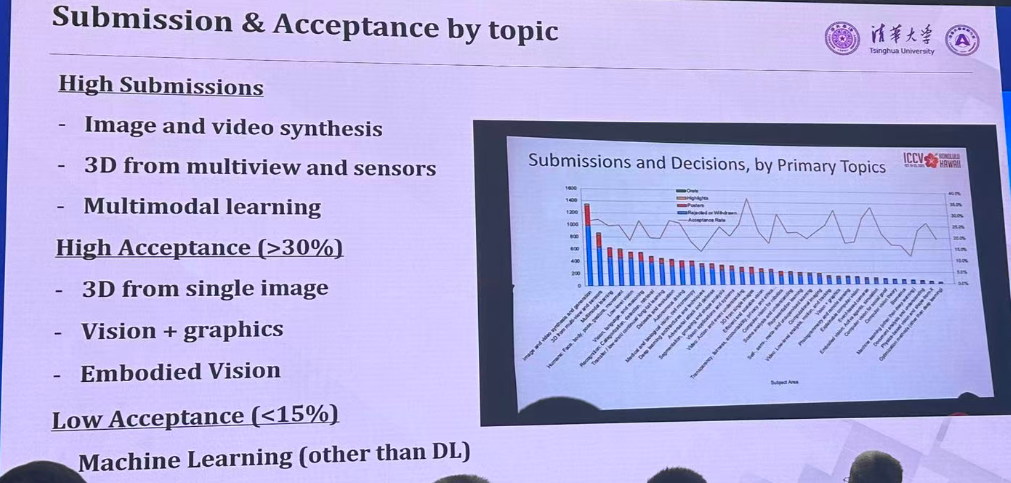
Top 5 Topics
- Image and video synthesis and generation
- 3D from multi-view and sensors
- Multimodal Learning
- Humans: Face, body, pose, gesture, movement
- Low-level vision
1. 图像与视频合成与生成
- 核心内容:这是当前AI领域最火热的方向之一,主要指利用生成模型(如扩散模型和生成对抗网络)创建全新的、逼真的图像和视频。
- 研究热点:
-
- 文生图/视频:根据文本描述生成图像或视频(例如 OpenAI 的 DALL-E、Stable Diffusion、Sora模型)。
- 图像/视频编辑:根据指令对现有图像或视频进行修改(如改变风格、替换内容、修复画质)。
- 虚拟内容创作:为游戏、电影、广告等行业生成虚拟场景和角色。
2. 基于多视图与传感器的3D重建
- 核心内容:研究如何通过多个角度的图像(多视图)或各类传感器(如深度相机、激光雷达)数据,来重建和理解现实世界的三维结构。
- 研究热点:
-
- 神经辐射场:一种革命性的技术,能够从稀疏的2D图片中合成出任意角度的、逼真的3D视图。
- 三维建模与数字化:用于文物修复、建筑测绘、自动驾驶的高精地图构建等。
- SLAM(同步定位与地图构建):机器人、无人机和AR/VR设备在未知环境中实时定位并构建地图的关键技术。
3. 多模态学习
- 核心内容:研究如何让AI模型同时理解和处理多种不同类型的信息(模态),如文本、图像、声音、视频等,并建立它们之间的关联。
- 研究热点:
-
- 跨模态检索:用一种模态的信息(如文字)去检索另一种模态的信息(如图片)。
- 多模态理解:让模型理解图文结合的复杂内容(例如,看懂表情包、理解视频的剧情)。
- 多模态生成:根据一种模态的信息生成另一种模态的信息(例如,根据图像生成描述文字,或根据文字生成语音)。
4. 人体相关研究:面部、身体、姿态、手势、运动
- 核心内容:专注于对“人”本身的视觉信息进行识别、分析和生成。
- 研究热点:
-
- 人脸识别与分析:身份识别、表情识别、年龄估计等。
- 人体姿态估计与动作识别:从图像或视频中精准定位人体的关键点,并识别其行为动作(应用于人机交互、体育分析、安防监控)。
- 手势识别:用于VR/AR交互、智能家居控制。
- 人体运动生成与重定向:在动画和游戏中生成逼真的人体运动。
5. 底层视觉
- 核心内容:与“高层视觉”(如图像识别、理解)相对,底层视觉关注的是图像本身的基本属性和质量的处理。
- 研究热点:
-
- 图像超分辨率:将低分辨率图像恢复成高分辨率图像。
- 图像去噪、去模糊、增强:提升图像质量。
- 图像/视频修复:填充图像中缺失或损坏的部分。
New Hot Topics
- Vision, language and reasoning
- Visual & action tokenization
- Unified Multimodal Understanding and Generation Models
- Vision-Language-Action Models
- World Models
1. 视觉、语言与推理
- 核心内容:这不仅仅是简单的“看图说话”(识别和描述),而是要求模型能够基于视觉和语言信息进行逻辑推理、因果推断和常识判断。
- 研究示例:
-
- 视觉问答:回答需要推理的问题,例如“为什么图片中的这个人看起来很惊讶?”(需要结合场景和人的表情进行推理)。
- 视觉常识推理:理解图像中隐含的、未被直接描绘的常识(例如,看到“平底锅和鸡蛋”,能推断出“可能正在做饭”)。
2. 视觉与动作的标记化
- 核心内容:这是将连续的、高维的视觉信息(像素)和动作指令,转换成离散的、低维的符号序列(Token) 的过程。这是为了统一不同模态的数据表示。
- 为何重要:
-
- 它借鉴了自然语言处理中“词标记”的成功经验。
- 一旦视觉和动作都被“标记化”,它们就可以像文字一样,被同一个模型(如Transformer)统一处理和生成。这是实现后续“统一模型”和“世界模型”的技术基石。
3. 统一的多模态理解与生成
- 核心内容:目标是构建一个单一的、强大的模型,能够同时处理多种任务(如视觉问答、图像描述、文生图、图生文等),而不是为每个任务训练一个专用模型。
- 研究热点:
-
- “任意模态到任意模态”的生成:例如,输入文本和图像,输出视频和语音。
- 通用多模态大模型:如GPT-4V、Gemini等,它们在一个模型中融合了理解和生成的能力,是这一方向的典型代表。
4. 视觉-语言-动作模型
- 核心内容:这是将VLAs模型的能力与物理世界的动作控制直接连接起来。它是实现具身智能 的关键技术。
- 应用场景:
-
- 机器人:给机器人下达指令“请把桌子上的那个红色杯子拿给我”,机器人需要:1)理解指令(语言),2)识别“桌子”、“红色杯子”(视觉),3)规划并执行拿起杯子的动作。
- 自动驾驶:感知环境(视觉),理解交通规则和导航指令(语言),然后执行转向、刹车等动作。
5. 世界模型
- 核心内容:这是人工智能领域一个宏伟而根本的目标。世界模型指的是一个能够模拟和理解真实世界如何运作的内部模型。它能够预测未来(“接下来会发生什么?”)并进行反事实推理(“如果我做了A,会发生什么?”)。
- 研究意义:
-
- 一个拥有世界模型的AI,不需要通过无数次试错来学习,它可以在“脑海”(模型内部)中模拟各种行动的结果,从而做出更安全、更高效的决策。
- 它是实现强人工智能 道路上至关重要的一环。
Research Trends & Directions
- Visual and action tokenizers (for UMM and VLAs)
- Unified Multimodal Understanding and Generation
- Visual Reasoning (unlocking and observing new capabilities)
- Vision-language-action models
- World Models (video/4D/interleave/others based)
- 3D + X (VLMs, Video Gen, VLAs)
1. 视觉与动作标记化器
- 核心解读:这是实现后续所有复杂模型的基础架构工作。它的目标是将连续的视觉信息(像素、视频帧)和物理动作,转换成离散的、类似语言的“符号”(Token)。
- 为何是趋势:只有完成了有效的标记化,才能将视觉、语言、动作置于同一个序列建模框架(如Transformer)下进行处理,这是实现“统一”模型的前提条件。
2. 统一的多模态理解与生成
- 核心解读:这是当前大模型时代的核心范式。旨在构建单一模型,无需特定任务头,就能处理跨模态的任意输入和输出任务(如文生图、图生文、视频问答等)。
- 为何是趋势:这种统一架构减少了模型冗余,更易于激发和涌现出未知的跨模态能力,是通向通用多模态AI的必经之路。
3. 视觉推理
- 核心解读:研究重点从“识别是什么”升级到“理解为什么”和“推断会怎样”。它关注模型如何从视觉场景中进行逻辑推理、因果推断和常识判断。
- 为何是趋势:括号内的“解锁与观察新能力”是关键。这表明研究者不仅在设计推理任务,更在探索大模型中自发涌现的、超出设计预期的推理能力,这是衡量模型智能程度的重要标尺。
4. 视觉-语言-动作模型
- 核心解读:这是具身智能 的核心技术。它将视觉感知、语言指令与物理世界的动作控制闭环打通,使AI智能体能够真正地“行动”起来。
- 为何是趋势:这是AI从虚拟世界走向物理世界的关键一步,在机器人、自动驾驶等领域有极其明确和重大的应用前景。
5. 世界模型
- 核心解读:这是通往强人工智能 的皇冠上的明珠。世界模型是智能体对环境运作规律的一种内部模拟,使其能够预测未来、进行反事实推理和规划。
- 为何是趋势:括号内注明了实现路径的多样性(基于视频、4D数据、交错数据等),表明这仍是一个开放且活跃的探索领域,是长期研究的根本方向。
6. 3D + X
- 核心解读:这是一个高度概括的研究范式。其核心思想是:以3D结构理解为基石,去增强和赋能其他(X)AI任务。
-
- 3D + 视觉语言模型:让VLM不仅能理解2D图片,还能理解物体的3D结构和物理属性。
- 3D + 视频生成:基于3D场景生成符合物理规律的、更逼真连贯的视频。
- 3D + VLA模型:让机器人能在三维空间中更好地进行导航和操作。
- 为何是趋势:3D信息提供了对世界更本质的描述。将3D先验引入各种任务,被认为是突破当前2D模型瓶颈、实现下一次性能飞跃的关键。
ACM MM
ACM International Conference on Multimedia 多媒体
在CCF (计算机图形学与多媒体) 为A
投稿时间 2025年4月11日
主题:


ACL 2025
Association for Computational Linguistics 自然语言的回忆
新增主题



趋势一:大语言模型的全面主导与深化
- 数据支撑:标题/摘要中含LLM的论文占比高达67%,这无可争议地表明,LLM已成为NLP研究的新范式和新基础。
- 生态多样化:除了常见的GPT、LLaMA系列,DeepSeek、Gemini/Gemma等模型也占据一席之地,形成了多元化的模型生态。同时,传统模型如BERT仍有其特定价值。
趋势二:从“对齐”到“精细化塑造”:强化学习与偏好建模的演进
- 能力增强:RL不仅用于让模型“说人话”,更被用于增强其核心推理能力(如通过改进的思维链技术)。
- 维度提升:偏好建模正从简单的“好/坏”判断,走向更高维度、更复杂的考量,如个性化偏好、具体情境下的权衡等。这标志着AI对齐研究进入了更精细、更实用的阶段。
趋势三:跨模态系统的融合与安全挑战
- 能力边界拓展:NLP模型正积极融合视觉、视频等多模态信息,致力于解决多模态推理、复杂视频理解等更富挑战性的任务。
- 新风险浮现:多模态能力也带来了新的安全漏洞,例如通过多模态联动的“越狱”攻击。因此,多模态安全检测已成为一个紧迫且重要的子方向。
趋势四:知识整合与结构化推理
- 突破模型局限:研究者们意识到纯文本训练的LLM在知识和逻辑上的局限,因此致力于将外部的结构化知识(如知识图谱、事件链条、表格、代码)与LLM相结合。
- 实现路径:通过RAG、知识解耦、工具调用等技术,让模型能够像专家一样,访问、理解和运用结构化的知识进行深度推理。
趋势五:普惠与包容:低资源语言与跨文化适应
- 技术民主化:研究视野正从英语中心主义扩展到哈萨克语、波斯语、白俄罗斯语、乌尔都语等低资源语言,推动AI技术的全球普惠。
- 价值对齐的深层挑战:认识到AI的价值观不能建立在单一文化之上。研究开始深入探讨跨文化的道德推理,并评估LLM在心理评估等敏感任务中的有效性与文化适应性,这是AI社会化的关键一步。
在CCF (数据库/数据挖掘/内容检索) 为A
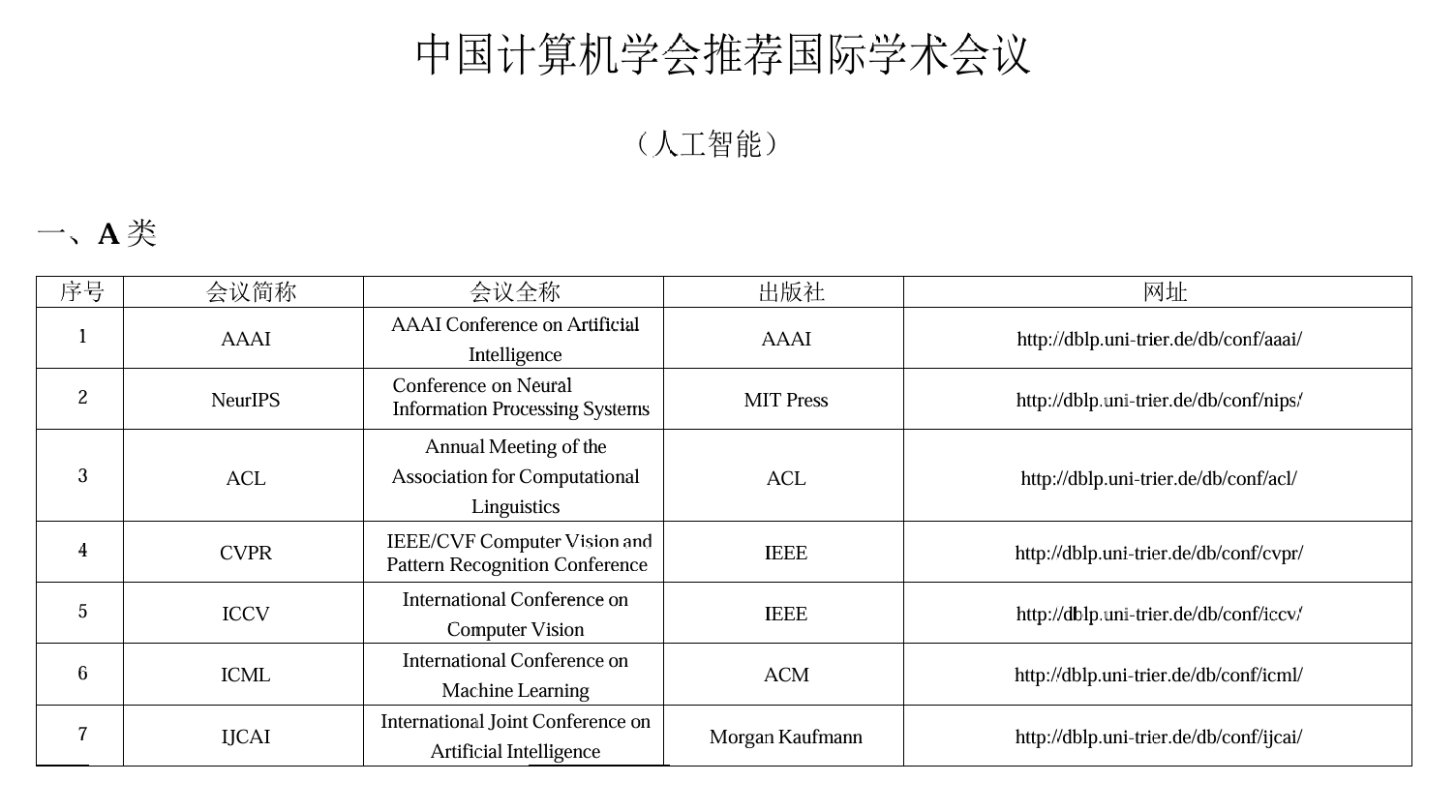
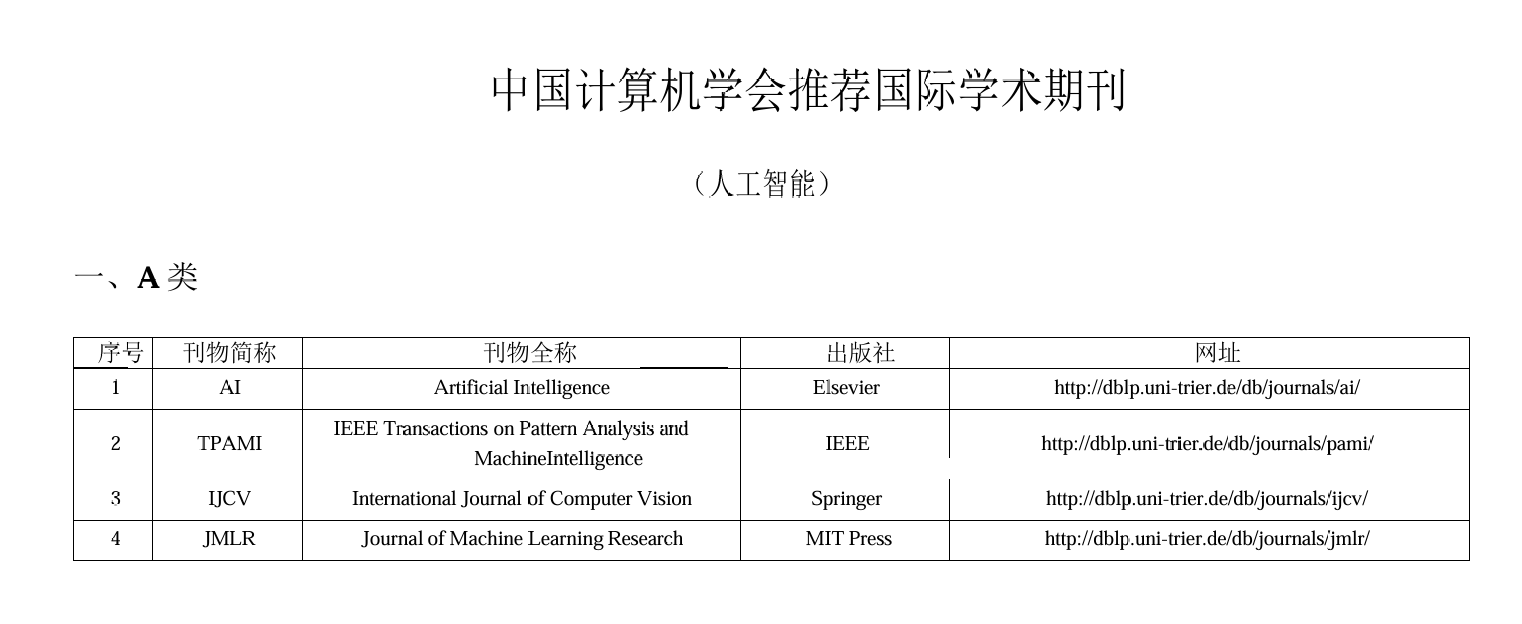
[中国计算机学会推荐顶会分析:
所有顶会:
ML(machine learning):
- ICML
- NeurIPS
- COLT
- ICLR
AI:
- IJCAI
- AAAI
DM:
- KDD
Applications:
- CVPR
- ICCV
- MM
- ACL
VLDB
论文投稿流程:
https://blog.csdn.net/qq_44722174/article/details/118440400
从评审专家的角度看,论文投稿之后会经历什么:
https://www.sohu.com/a/778110086_121119001
oral 口头报告
poster 张贴海报
workshop:一般都是某些大牛觉得该领域有哪些方面是研究热点,就向会议chair申请开一个独立的研讨会,值得注意的是workshop是独立审稿的。
AC 是 Area Chair 领域专家 SAC 是 Senior AC
Meta-review 是对多个评审专家意见的综合评审,
desk reject:一些版面情况的 拒稿
审稿过程:
一般会快速看一遍摘要和引言部分。看动机/故事是否合理;贡献总结得是否有价值。然后看后面的方法和实验,主要看贡献是否被足够地支撑了。部分文章会看下实验结果和 baseline 是否 solid。过程中会关注下 typo。看完之后,看看优点多还是缺点多,是中还是拒。
1.ICML:
国际机器学习会议 (International Conference on Machine Learning)
会议流程(年度周期)
ICML 的年度周期通常如下:
- 1月-2月:论文投稿截止。
- 3月-5月:审稿期(包括 rebuttal / 作者反馈阶段)。
- 5月底:论文录用结果通知。
- 7月-8月:会议正式举行(通常在北美洲或欧洲的夏季)。
会议进程:

词云:
- Language:329 语言
- Multi:212
- large:211
- Diffusion:208 扩散
- Efficient:193 效率
- Optimization:190 优化
- Time:176
- Graph:173
- Traing:143
- Reinforcement:141 强化学习
杰出论文:
Outstanding Papers
- CollabLLM: From Passive Responders to Active Collaborators
- Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions
- Conformal Prediction as Bayesian Quadrature
- Score Matching with Missing Data
- Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
- The Value of Prediction in Identifying the Worst-Off
- Position: The AI Conference Peer Review Crisis Demands Author Feedback and Reviewer Rewards
- Position: AI Safety should prioritize the Future of Work
Conference heightlight 会议亮点
position paper 观点论文 。对应的是Research Paper 研究论文
Profound insights 深刻的见解, controversial perspectives or future directions 有争议的观点或未来方向
是ICML第二年接受position paper 71/361 19.67% 中稿率
Position paper topics:
- Reflection and Optimization on AI Evaluation Systems
- 对人工智能评估系统的反思与优化
- Explainable AI
- 可解释人工智能 (XAI)
- AI Safety, Ethics, and Regulation
- 人工智能安全、伦理与监管
- Technical Limitations of LLMs
- 大型语言模型 (LLMs) 的技术限制
- Balancing AI and Its Societal Impacts
- 平衡人工智能及其社会影响
Hot / emerging topics
- Reinforcement Learning 强化学习
- Offline Reinforcement Learning
- 离线强化学习
- Safe Reinforcement Learning
- 安全强化学习
- Multi-agent Reinforcement Learning
- 多智能体强化学习
- Multi-objective Reinforcement Learning
- 多目标强化学习
- Inverse Reinforcement Learning
- 逆强化学习
- Offline Reinforcement Learning
NeurIPS
Conference on Neural Information Processing System 神经信息处理系统打会
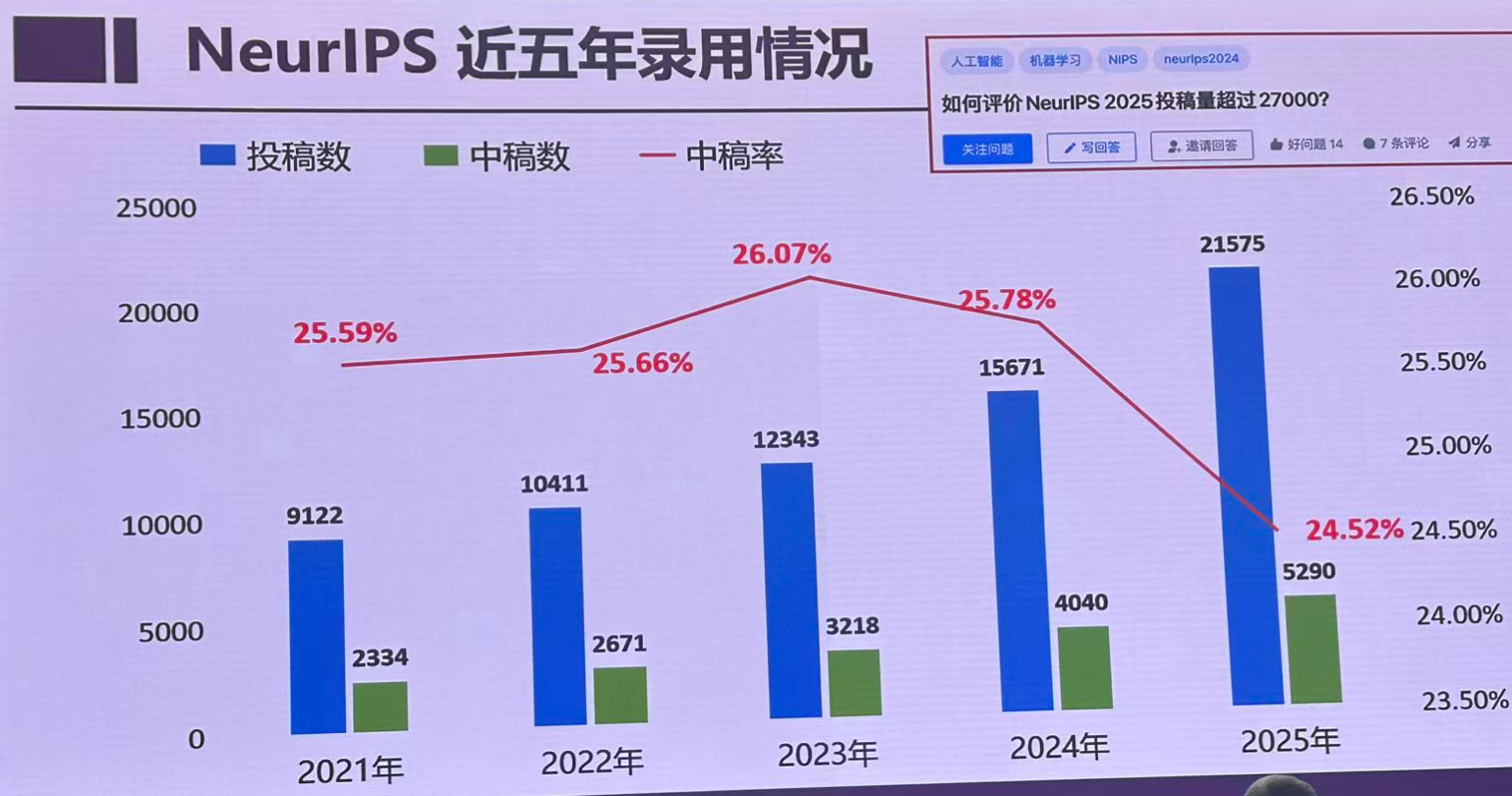
投稿时间:2025年5月15日
反驳时间:2025年7月24日
通知时间:2025年9月18日
会议时间:2025年 11月30 日-12月7日
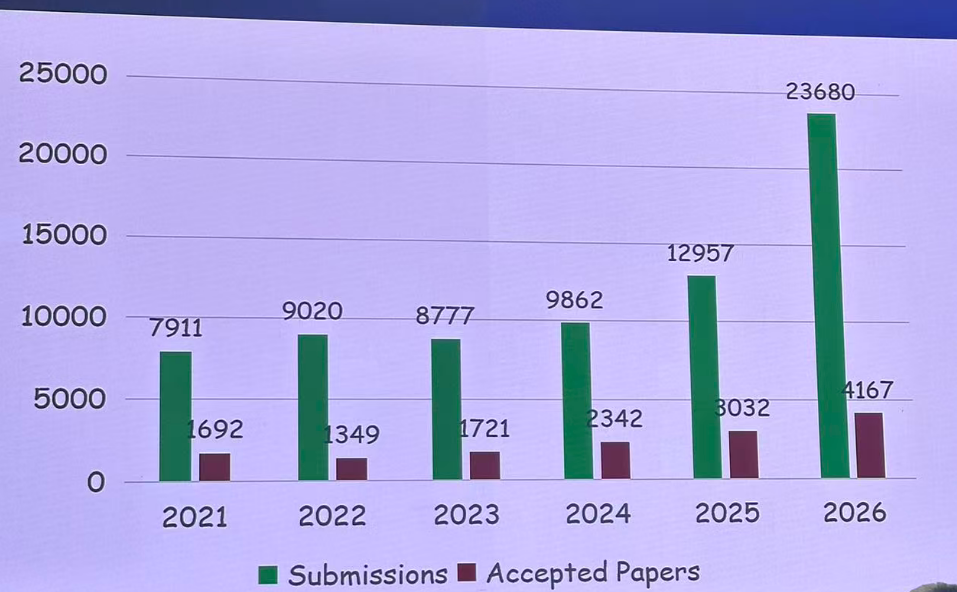
投稿论文:21575 录取:5290 录用率:24.52%
oral:77 Spotlight 688
除了主要的论文,还有 Datasets 和 Benchmarks Track(基准测试追踪)
- 一组标准化的测试任务 (A Set of Standardized Test Tasks): “Benchmarks” (基准测试) 指的是一系列被普遍接受的、用于衡量特定算法、模型或系统的性能的标准化任务或数据集。这些任务通常被设计来模拟真实世界中的应用场景,并且有明确的评估指标。
- 用于比较和评估 (For Comparison and Evaluation): 这些基准测试的目的是提供一个公平的平台,让不同的研究者或团队可以比较他们提出的新方法、算法或模型的表现。通过在相同的基准测试上进行测试,可以客观地评估哪个方法更优。
- 追踪进步 (Tracking Progress): “Track” (追踪) 强调的是持续的、系统的评估过程。一个 “Benchmarks Track” 可能意味着:
- 一个长期的项目: 持续收集和更新基准测试数据集。
- 一个评估流程: 规定了如何提交结果、如何进行评分、如何公布排行榜等。
- 一个研究方向: 专门关注如何设计更好的基准测试、如何改进评估方法。
也是新增加了 Position Paper Track
录用率 8%
发现了一个 AI 评审论文的网站:https://review.cspaper.org
1. 评分机制
- 6分制评分标准:审稿人对论文采用1-6分制,评分含义如下:
- 6分:强接受(Strong Accept)
- 5分:弱接受(Weak Accept)
- 4分:边界接受(Borderline Accept)
- 3分:边界拒绝(Borderline Reject)
- 2分:弱拒绝(Weak Reject)
- 1分:强拒绝(Strong Reject)
词云:

反驳阶段:
热点话题:
- 大语言模型 Reasoning and RL(推理)
- 扩散模型

- 视觉生成模型

- 多模态

- AI4S
COLT 2025
Annual Conference on Learning Theory 国际学习理论大会
第38届 COLT是机器学习理论领域的顶级国际会议,由计算学习协会(ACL)主办,始于1988年,聚焦于学习理论与算法分析的交叉研究,强调数学严谨性与理论创新
在CCF (人工智能) 为B类
中搞情况:
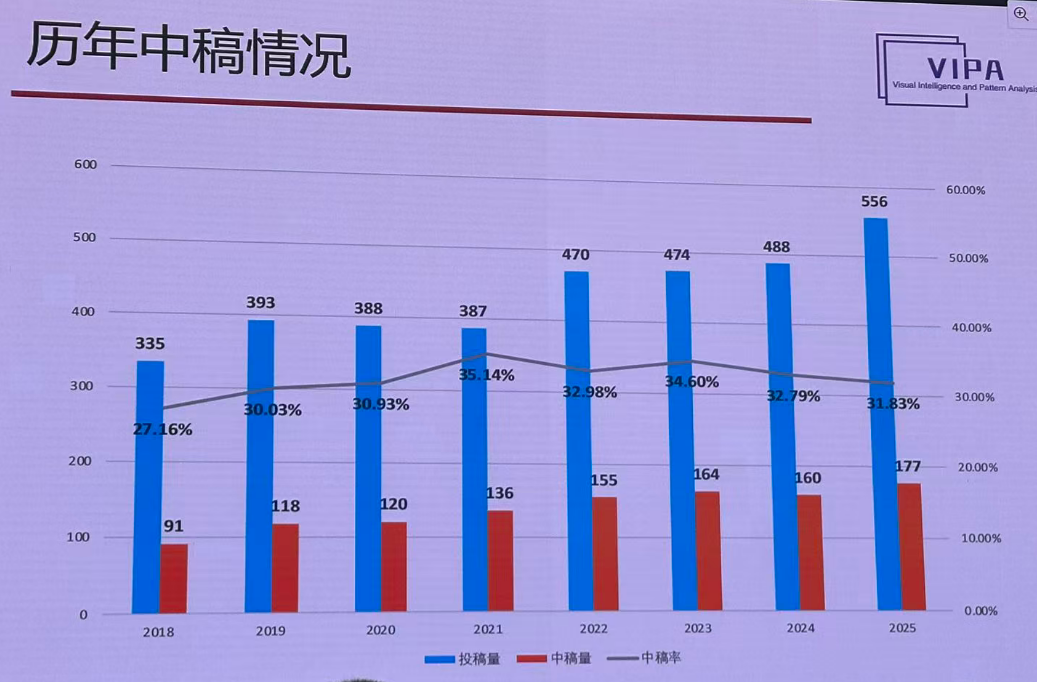
做理论的中稿率还是高一点,可能是投稿人对自己的要求会比较高。
ICLR
International Conference on Learning Representations (国际表征学习大会)
表征学习,也称为特征学习,其核心思想是:让机器自动地从原始数据(如图像的像素、文本的单词、音频的声波)中发现和提取出对后续任务(如分类、检测)更有用的表示形式或特征。
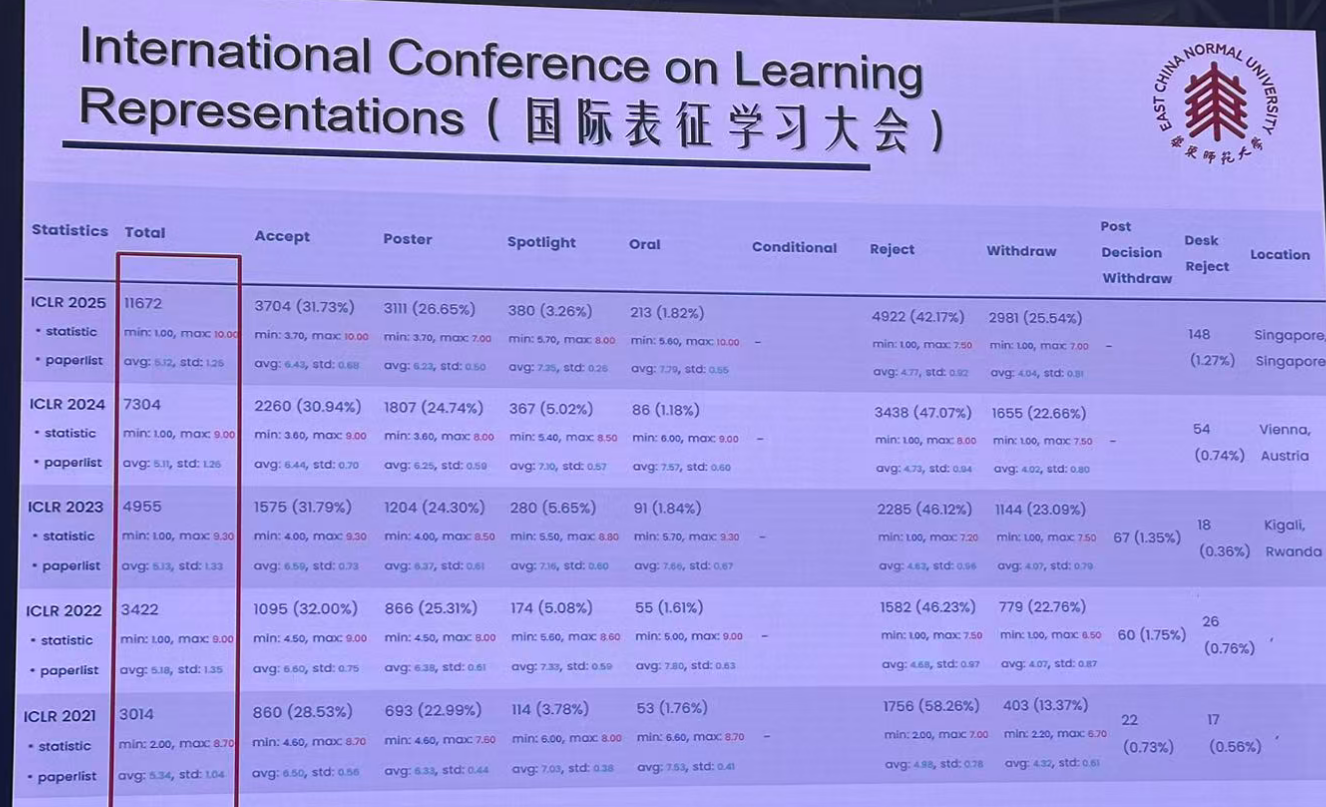
投稿,中稿情况:
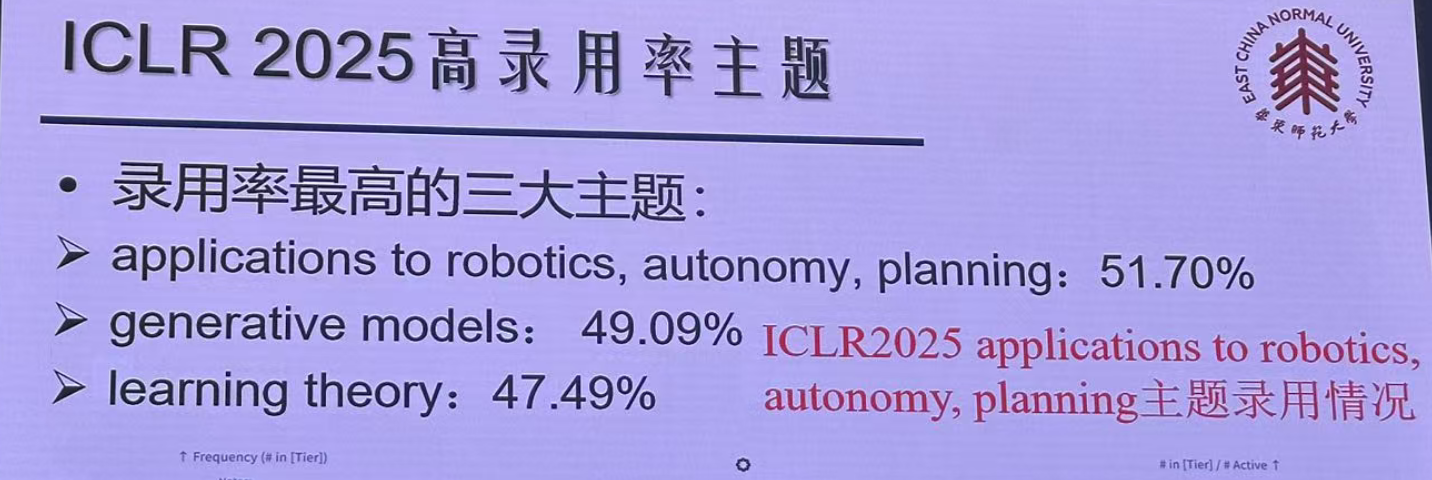
高录用主题:
ICLR 2025 — 热点、趋势、建议
- 安全与对齐
- 模型可编辑性与知识更新
- 理解与优化微调过程
- 数据质量与评估
- 多模态能力提升
- 高效计算(推理)
- 多智能体系统与协作
重视discussions and limitations, 重视rebuttal
IJCAI 2025
投稿截止时间 2025年1月24日
International Joint Conference on Artificial Intelligence 国际人工智能联合会议
投稿5404 录用 1042
录用率 19.3% 机器学习领域 17.7%
AAAI 2025
Association for the Advancement of Artificial Intelligence
截止日期:2024 年 8 月中旬
会议日期: 2025年2月25日 - 3月4日
吴恩达发表了讲话
录用主题分布:
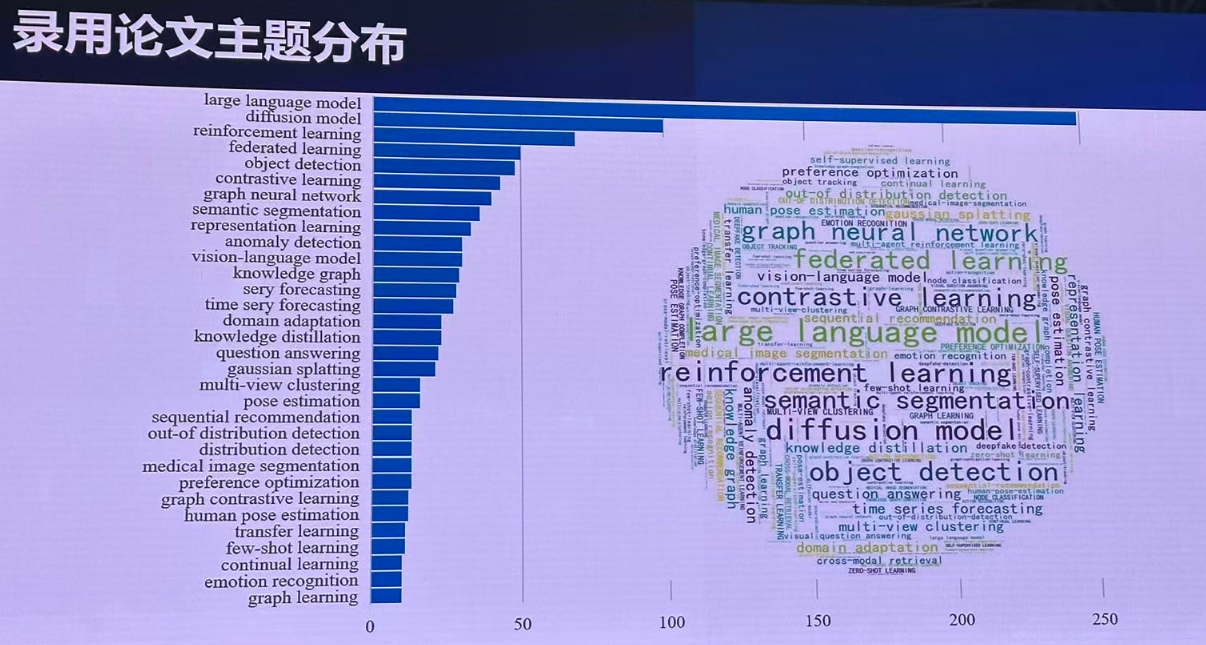
KDD 2025
Knowledge Discovery and Data Mining
在CCF (数据库/数据挖掘/内容检索) 为A类会议
数据挖掘会议
投稿机制:首次采用双轮次投稿机制(8月轮 + 2月轮)

投稿情况:
研究热点:

写作偏好:
CVPR
Computer Vision and Pattern Recognition Conference 计算机视觉与模式识别会议
会议时间/地点:2025年6月11日至15日,美国,纳什维尔
截稿时间:2024年11月14日
录用通知时间:2025年4月31日
HOT Topics:

ICCV
International Conference on Computer Vision 计算机视觉国际大会
截稿时间:2025年3月7日
录用通知时间:2025年6月20日
每两年举办一次
HOT Topic:
Top 5 Topics
- Image and video synthesis and generation
- 3D from multi-view and sensors
- Multimodal Learning
- Humans: Face, body, pose, gesture, movement
- Low-level vision
1. 图像与视频合成与生成
- 核心内容:这是当前AI领域最火热的方向之一,主要指利用生成模型(如扩散模型和生成对抗网络)创建全新的、逼真的图像和视频。
- 研究热点:
-
- 文生图/视频:根据文本描述生成图像或视频(例如 OpenAI 的 DALL-E、Stable Diffusion、Sora模型)。
- 图像/视频编辑:根据指令对现有图像或视频进行修改(如改变风格、替换内容、修复画质)。
- 虚拟内容创作:为游戏、电影、广告等行业生成虚拟场景和角色。
2. 基于多视图与传感器的3D重建
- 核心内容:研究如何通过多个角度的图像(多视图)或各类传感器(如深度相机、激光雷达)数据,来重建和理解现实世界的三维结构。
- 研究热点:
-
- 神经辐射场:一种革命性的技术,能够从稀疏的2D图片中合成出任意角度的、逼真的3D视图。
- 三维建模与数字化:用于文物修复、建筑测绘、自动驾驶的高精地图构建等。
- SLAM(同步定位与地图构建):机器人、无人机和AR/VR设备在未知环境中实时定位并构建地图的关键技术。
3. 多模态学习
- 核心内容:研究如何让AI模型同时理解和处理多种不同类型的信息(模态),如文本、图像、声音、视频等,并建立它们之间的关联。
- 研究热点:
-
- 跨模态检索:用一种模态的信息(如文字)去检索另一种模态的信息(如图片)。
- 多模态理解:让模型理解图文结合的复杂内容(例如,看懂表情包、理解视频的剧情)。
- 多模态生成:根据一种模态的信息生成另一种模态的信息(例如,根据图像生成描述文字,或根据文字生成语音)。
4. 人体相关研究:面部、身体、姿态、手势、运动
- 核心内容:专注于对“人”本身的视觉信息进行识别、分析和生成。
- 研究热点:
-
- 人脸识别与分析:身份识别、表情识别、年龄估计等。
- 人体姿态估计与动作识别:从图像或视频中精准定位人体的关键点,并识别其行为动作(应用于人机交互、体育分析、安防监控)。
- 手势识别:用于VR/AR交互、智能家居控制。
- 人体运动生成与重定向:在动画和游戏中生成逼真的人体运动。
5. 底层视觉
- 核心内容:与“高层视觉”(如图像识别、理解)相对,底层视觉关注的是图像本身的基本属性和质量的处理。
- 研究热点:
-
- 图像超分辨率:将低分辨率图像恢复成高分辨率图像。
- 图像去噪、去模糊、增强:提升图像质量。
- 图像/视频修复:填充图像中缺失或损坏的部分。
New Hot Topics
- Vision, language and reasoning
- Visual & action tokenization
- Unified Multimodal Understanding and Generation Models
- Vision-Language-Action Models
- World Models
1. 视觉、语言与推理
- 核心内容:这不仅仅是简单的“看图说话”(识别和描述),而是要求模型能够基于视觉和语言信息进行逻辑推理、因果推断和常识判断。
- 研究示例:
-
- 视觉问答:回答需要推理的问题,例如“为什么图片中的这个人看起来很惊讶?”(需要结合场景和人的表情进行推理)。
- 视觉常识推理:理解图像中隐含的、未被直接描绘的常识(例如,看到“平底锅和鸡蛋”,能推断出“可能正在做饭”)。
2. 视觉与动作的标记化
- 核心内容:这是将连续的、高维的视觉信息(像素)和动作指令,转换成离散的、低维的符号序列(Token) 的过程。这是为了统一不同模态的数据表示。
- 为何重要:
-
- 它借鉴了自然语言处理中“词标记”的成功经验。
- 一旦视觉和动作都被“标记化”,它们就可以像文字一样,被同一个模型(如Transformer)统一处理和生成。这是实现后续“统一模型”和“世界模型”的技术基石。
3. 统一的多模态理解与生成
- 核心内容:目标是构建一个单一的、强大的模型,能够同时处理多种任务(如视觉问答、图像描述、文生图、图生文等),而不是为每个任务训练一个专用模型。
- 研究热点:
-
- “任意模态到任意模态”的生成:例如,输入文本和图像,输出视频和语音。
- 通用多模态大模型:如GPT-4V、Gemini等,它们在一个模型中融合了理解和生成的能力,是这一方向的典型代表。
4. 视觉-语言-动作模型
- 核心内容:这是将VLAs模型的能力与物理世界的动作控制直接连接起来。它是实现具身智能 的关键技术。
- 应用场景:
-
- 机器人:给机器人下达指令“请把桌子上的那个红色杯子拿给我”,机器人需要:1)理解指令(语言),2)识别“桌子”、“红色杯子”(视觉),3)规划并执行拿起杯子的动作。
- 自动驾驶:感知环境(视觉),理解交通规则和导航指令(语言),然后执行转向、刹车等动作。
5. 世界模型
- 核心内容:这是人工智能领域一个宏伟而根本的目标。世界模型指的是一个能够模拟和理解真实世界如何运作的内部模型。它能够预测未来(“接下来会发生什么?”)并进行反事实推理(“如果我做了A,会发生什么?”)。
- 研究意义:
-
- 一个拥有世界模型的AI,不需要通过无数次试错来学习,它可以在“脑海”(模型内部)中模拟各种行动的结果,从而做出更安全、更高效的决策。
- 它是实现强人工智能 道路上至关重要的一环。
Research Trends & Directions
- Visual and action tokenizers (for UMM and VLAs)
- Unified Multimodal Understanding and Generation
- Visual Reasoning (unlocking and observing new capabilities)
- Vision-language-action models
- World Models (video/4D/interleave/others based)
- 3D + X (VLMs, Video Gen, VLAs)
1. 视觉与动作标记化器
- 核心解读:这是实现后续所有复杂模型的基础架构工作。它的目标是将连续的视觉信息(像素、视频帧)和物理动作,转换成离散的、类似语言的“符号”(Token)。
- 为何是趋势:只有完成了有效的标记化,才能将视觉、语言、动作置于同一个序列建模框架(如Transformer)下进行处理,这是实现“统一”模型的前提条件。
2. 统一的多模态理解与生成
- 核心解读:这是当前大模型时代的核心范式。旨在构建单一模型,无需特定任务头,就能处理跨模态的任意输入和输出任务(如文生图、图生文、视频问答等)。
- 为何是趋势:这种统一架构减少了模型冗余,更易于激发和涌现出未知的跨模态能力,是通向通用多模态AI的必经之路。
3. 视觉推理
- 核心解读:研究重点从“识别是什么”升级到“理解为什么”和“推断会怎样”。它关注模型如何从视觉场景中进行逻辑推理、因果推断和常识判断。
- 为何是趋势:括号内的“解锁与观察新能力”是关键。这表明研究者不仅在设计推理任务,更在探索大模型中自发涌现的、超出设计预期的推理能力,这是衡量模型智能程度的重要标尺。
4. 视觉-语言-动作模型
- 核心解读:这是具身智能 的核心技术。它将视觉感知、语言指令与物理世界的动作控制闭环打通,使AI智能体能够真正地“行动”起来。
- 为何是趋势:这是AI从虚拟世界走向物理世界的关键一步,在机器人、自动驾驶等领域有极其明确和重大的应用前景。
5. 世界模型
- 核心解读:这是通往强人工智能 的皇冠上的明珠。世界模型是智能体对环境运作规律的一种内部模拟,使其能够预测未来、进行反事实推理和规划。
- 为何是趋势:括号内注明了实现路径的多样性(基于视频、4D数据、交错数据等),表明这仍是一个开放且活跃的探索领域,是长期研究的根本方向。
6. 3D + X
- 核心解读:这是一个高度概括的研究范式。其核心思想是:以3D结构理解为基石,去增强和赋能其他(X)AI任务。
-
- 3D + 视觉语言模型:让VLM不仅能理解2D图片,还能理解物体的3D结构和物理属性。
- 3D + 视频生成:基于3D场景生成符合物理规律的、更逼真连贯的视频。
- 3D + VLA模型:让机器人能在三维空间中更好地进行导航和操作。
- 为何是趋势:3D信息提供了对世界更本质的描述。将3D先验引入各种任务,被认为是突破当前2D模型瓶颈、实现下一次性能飞跃的关键。
ACM MM
ACM International Conference on Multimedia 多媒体
在CCF (计算机图形学与多媒体) 为A
投稿时间 2025年4月11日
主题:


ACL 2025
Association for Computational Linguistics 自然语言的回忆
新增主题



趋势一:大语言模型的全面主导与深化
- 数据支撑:标题/摘要中含LLM的论文占比高达67%,这无可争议地表明,LLM已成为NLP研究的新范式和新基础。
- 生态多样化:除了常见的GPT、LLaMA系列,DeepSeek、Gemini/Gemma等模型也占据一席之地,形成了多元化的模型生态。同时,传统模型如BERT仍有其特定价值。
趋势二:从“对齐”到“精细化塑造”:强化学习与偏好建模的演进
- 能力增强:RL不仅用于让模型“说人话”,更被用于增强其核心推理能力(如通过改进的思维链技术)。
- 维度提升:偏好建模正从简单的“好/坏”判断,走向更高维度、更复杂的考量,如个性化偏好、具体情境下的权衡等。这标志着AI对齐研究进入了更精细、更实用的阶段。
趋势三:跨模态系统的融合与安全挑战
- 能力边界拓展:NLP模型正积极融合视觉、视频等多模态信息,致力于解决多模态推理、复杂视频理解等更富挑战性的任务。
- 新风险浮现:多模态能力也带来了新的安全漏洞,例如通过多模态联动的“越狱”攻击。因此,多模态安全检测已成为一个紧迫且重要的子方向。
趋势四:知识整合与结构化推理
- 突破模型局限:研究者们意识到纯文本训练的LLM在知识和逻辑上的局限,因此致力于将外部的结构化知识(如知识图谱、事件链条、表格、代码)与LLM相结合。
- 实现路径:通过RAG、知识解耦、工具调用等技术,让模型能够像专家一样,访问、理解和运用结构化的知识进行深度推理。
趋势五:普惠与包容:低资源语言与跨文化适应
- 技术民主化:研究视野正从英语中心主义扩展到哈萨克语、波斯语、白俄罗斯语、乌尔都语等低资源语言,推动AI技术的全球普惠。
- 价值对齐的深层挑战:认识到AI的价值观不能建立在单一文化之上。研究开始深入探讨跨文化的道德推理,并评估LLM在心理评估等敏感任务中的有效性与文化适应性,这是AI社会化的关键一步。
在CCF (数据库/数据挖掘/内容检索) 为A
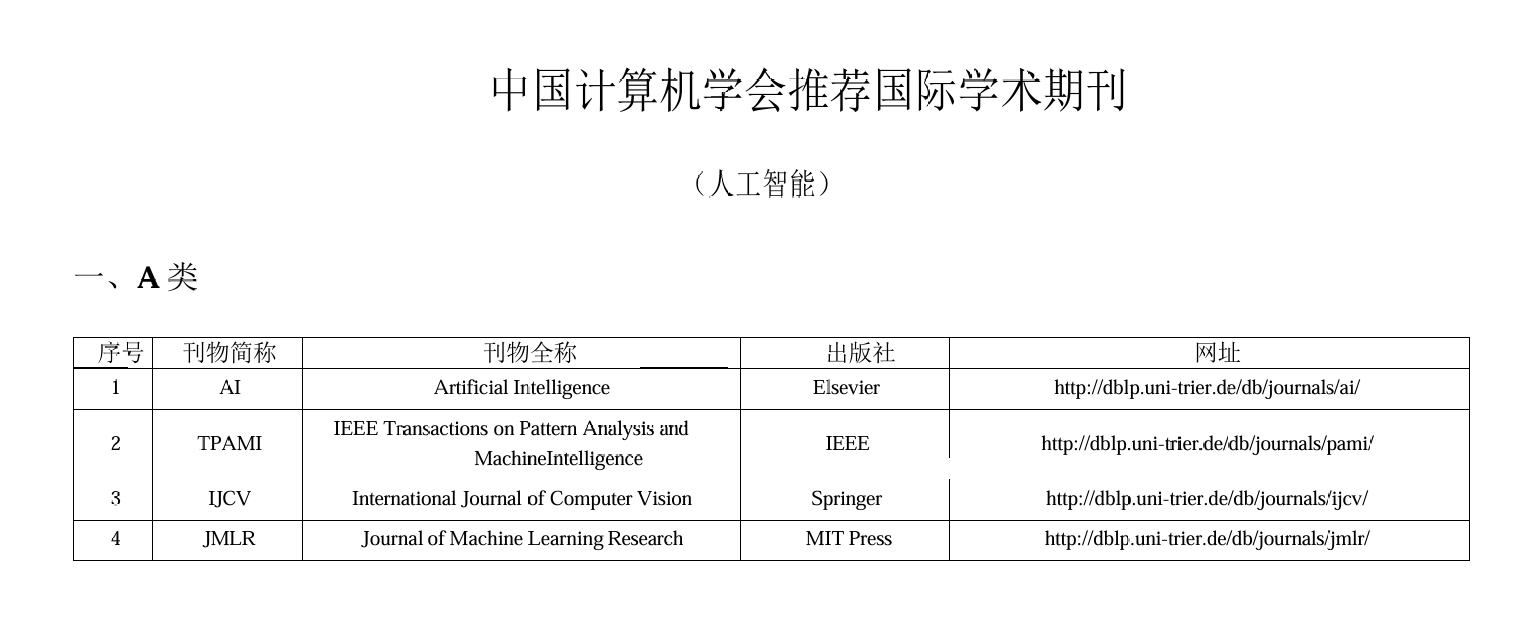
国际学术会议和期刊目录-2022.pdf](https://www.yuque.com/attachments/yuque/0/2025/pdf/39085148/1762848935447-4b27f552-d516-40ac-ace3-ba1fc26a8983.pdf)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)