基于 HAMi 实现亚马逊云科技 Trainium 与 Inferentia 核心级共享与策略性拓扑调度
HAMi 对亚马逊云科技 Neuron 的支持,在设计上体现了清晰的工程哲学:用策略代替扫描,用简约实现高效。其拓扑寻优算法,通过识别实例类型并将拓扑问题简化为寻找连续的设备索引,以极低的复杂度实现了与亚马逊云科技官方调度器行为一致的高性能调度。这种务实的设计,不仅确保了多设备任务能够充分利用 Neuron 硬件的底层高速互联优势,也为用户提供了灵活、易用的云原生 AI 算力调度体验。参考资料。
作为一个活跃的开源项目,HAMi 由来自 15+ 国家、350+ 贡献者共同维护,已被 200+ 企业与机构在实际生产环境中采纳,具备良好的可扩展性与支持保障。
亚马逊云科技自研的亚马逊云科技 Trainium 与 Inferentia 芯片,在构建更高效、成本可控的 AI 加速基础设施方面具有明显优势,目标不仅是算力提升,也强调功耗与成本效率。 Inferentia2 在性能/瓦特(perf/W)上做了显著优化, Trainium2 相较同类 GPU 实例可节省约 30–40% 成本,因此在大规模推理与训练任务中,其应用规模持续增长并展现出良好的性价比。
然而,随着企业部署的异构算力种类不断增加(如 GPU、NPU 等),不同类型芯片通常由各自的驱动与调度组件独立管理,难以在同一层实现统一调度与监控。这使得资源利用、任务编排和可观测体系出现割裂,增加了多芯片集群的管理复杂度。
HAMi 正是为了解决这些痛点而设计的。它是一个面向 Kubernetes 的异构设备管理中间件,支持包括 GPU、NPU、以及亚马逊云科技 Neuron 芯片在内的多类加速设备。通过 GPU 虚拟化、核心级共享、拓扑感知调度与统一可观测性 ,HAMi 能在同一集群中实现异构算力的资源池化与精细化调度,显著提升设备利用率并降低运维复杂度。对于需要同时管理多种加速卡的企业而言,HAMi 提供了一个统一、高效、可观测的算力底座。
在 HAMi v2.7.0 中,已完成对亚马逊云科技 Trainium 与 Inferentia 芯片的深度集成,实现了 核心级共享、策略性拓扑调度与统一可观测性 。这不仅保持了亚马逊云科技原生的性能优化策略,同时让企业在 Kubernetes 环境中获得一致的异构资源管理体验, 在保持性能稳定的同时显著降低调度与管理成本 。
本文将从代码实现层面出发,详细剖析 HAMi 在支持亚马逊云科技 Neuron 核心级共享、拓扑感知调度等核心功能时的具体设计与实现原理。
核心特性总览
- 双重粒度共享 :HAMi 同时支持 设备级 (
aws.amazon.com/neuron) 和 核心级 (aws.amazon.com/neuroncore) 两种资源分配粒度。用户既可以申请整个 Neuron 设备,也可以按需申请单个 NeuronCore,极大地提高了昂贵芯片的利用率。 - 策略性拓扑调度 :对于需要多个 Neuron 设备的多卡任务,HAMi 调度器能够基于 EC2 实例类型,采用一种高效的策略性调度算法,确保任务被分配到通信效率最高的设备组合上。
- 统一监控视图 :将 Neuron 设备无缝集成到 HAMi 的 vGPU 监控体系中。用户可以通过 Prometheus 等标准工具,直观地看到每个 Neuron 设备或核心的分配情况,实现了与 GPU 等异构硬件一致的监控体验。
核心原理:基于先验知识的策略性拓扑调度
与需要实时扫描硬件拓扑的复杂方案不同,HAMi 对亚马逊云科技 Neuron 的拓扑感知调度,其根本设计思想是 基于先验知识的策略性调度 。这种设计哲学与亚马逊云科技官方的 Neuron Scheduler Extension 保持一致,即通过识别实例类型来应用预设的、能够保证性能的拓扑分配规则,而非进行复杂的实时计算。它将对亚马逊云科技标准化硬件部署(EC2 实例)的深入理解,直接固化为了内部调度规则。
其实现原理可归纳为三点:
- 识别实例类型 :调度器首先读取节点的 EC2 实例类型(如 Trainium 系列的 trn1 与 Inferentia 系列的 inf1/inf2),以此作为判断硬件拓扑的 唯一依据 。
- 线性抽象 :它将节点上所有 Neuron 设备视为一个从
0开始的 连续编号列表 (如[0, 1, 2, ...]),而不是一个复杂的拓扑图。 - 强制连续分配 :这是最核心的规则。当任务请求
N个设备时,调度器必须在此编号列表中找到一个 长度为N的、完全空闲的、连续的设备块 。如果节点有足够数量的空闲设备但它们不相邻,调度依然会失败。
原理实现:代码深度解析
下面我们深入代码,探究上述原理是如何实现的。
1. 拓扑感知基石:识别实例类型
HAMi 并非直接扫描硬件,而是通过一种更简洁的间接方式来感知拓扑:
- 识别实例类型 :Device Plugin 启动时,会从节点的
label中读取node.kubernetes.io/instance-type,并将其存储在每个虚拟设备对象的CustomInfo[AWSNodeType]字段中。这是后续所有拓扑决策的数据源。 - 线性抽象 :代码为节点上的所有 Neuron 设备创建一个扁平化的、索引连续的列表
[]*device.DeviceInfo。这个索引号,就是后续“强制连续分配”算法的操作对象。 - 强制连续分配:这是最核心的规则。当任务请求
N个设备时,调度器必须在此编号列表中找到一个长度为N的、完全空闲的、连续的设备块。如果节点有足够数量的空闲设备但它们不相邻,调度依然会失败。
// File: pkg/device/awsneuron/device.go
func (dev *AWSNeuronDevices) GetNodeDevices(n corev1.Node) ([]*device.DeviceInfo, error) {
// ...
counts, ok := n.Status.Capacity.Name(corev1.ResourceName(dev.resourceCountName), resource.DecimalSI).AsInt64()
// ...
customInfo := map[string]any{}
// 1. 从节点标签中获取实例类型,作为拓扑判断的依据
customInfo[AWSNodeType] = n.Labels["node.kubernetes.io/instance-type"]
// 2. 创建一个线性的、连续编号的设备列表
for int64(i) < counts {
nodedevices = append(nodedevices, &device.DeviceInfo{
Index: uint(i), // 索引从 0 开始连续递增
ID: n.Name + "-" + AWSNeuronDevice + "-" + fmt.Sprint(i),
Type: AWSNeuronDevice,
Numa: 0, // Numa 信息被忽略,拓扑聚焦于设备邻接关系
Health: true,
CustomInfo: customInfo,
})
i++
}
return nodedevices, nil
}2. 调度算法 核心:双策略拓扑寻优
当一个请求多个 Neuron 设备的 Pod 到达时,调度器的 Fit 函数会调用 graphSelect 来执行核心的拓扑匹配。该函数会读取之前存储的实例类型,并根据类型应用两种不同的调度策略,来确保分配的设备组具有最低的通信延迟。
策略一:Inferentia 实例的环形拓扑
Inf1 和 Inf2 实例上的 Neuron 设备通过 环形拓扑 连接。在这种拓扑结构中,物理上相邻的设备通信效率最高。因此,为了保证性能,调度器 必须 为任务分配一组 连续的 设备。
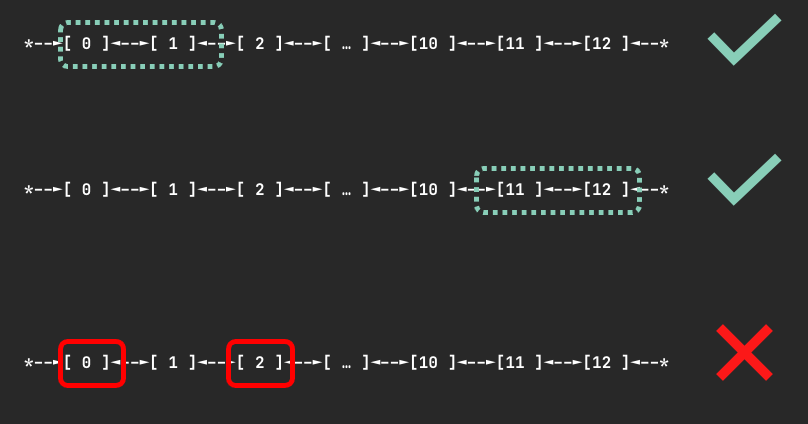
HAMi 的调度算法精确地实现了这一规则。当 graphSelect 函数识别到实例类型为 inf 时,它会不设数量限制地调用 continuousDeviceAvailable 函数,在节点的设备列表(如 [0, 1, ..., 11] )中寻找一个长度与请求数量相匹配的、完全空闲的连续索引段。
如下方图示,对于一个请求 2 个设备的 Pod, [0, 1] 或 [11, 12] 这样的连续分配是有效的;而 [0, 2] 这样的非连续分配则是无效的,调度器绝不会生成这样的分配方案。这正是通过 continuousDeviceAvailable 函数的循环检查机制来保证的。
策略二:Trainium 实例的 2D 环面拓扑
在 Trn1 实例上,设备通过更复杂的 2D 环面拓扑 连接。为了适配这种拓扑并确保最佳性能,亚马逊云科技规定容器只能请求 1,4,8,或 16 个设备。
HAMi 严格遵守了此核心约束。 graphSelect 函数通过一个 switch 语句,只对这四种特定数量的请求进行处理。任何其他数量的请求(如 2 或 7 个设备)都会被直接拒绝,Pod 将无法被调度。
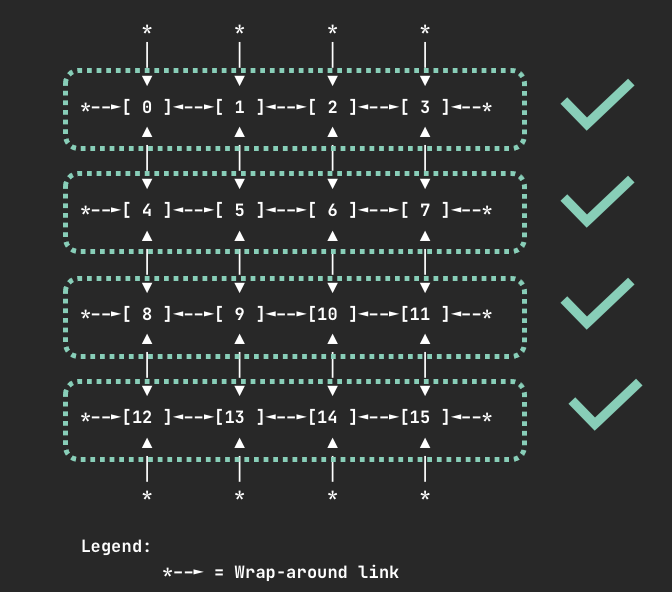
对于有效的请求数量,HAMi 同样采用 continuousDeviceAvailable 函数来寻找连续的设备块。这种看似简单的线性查找,实际上恰好能匹配 Trn1 实例上预定义的有效设备组。例如,在 16 个设备的节点上,请求 4 个设备时, continuousDeviceAvailable 会找到 [0,1,2,3] , [4,5,6,7] , [8,9,10,11] 或 [12,13,14,15] 这样的组合。
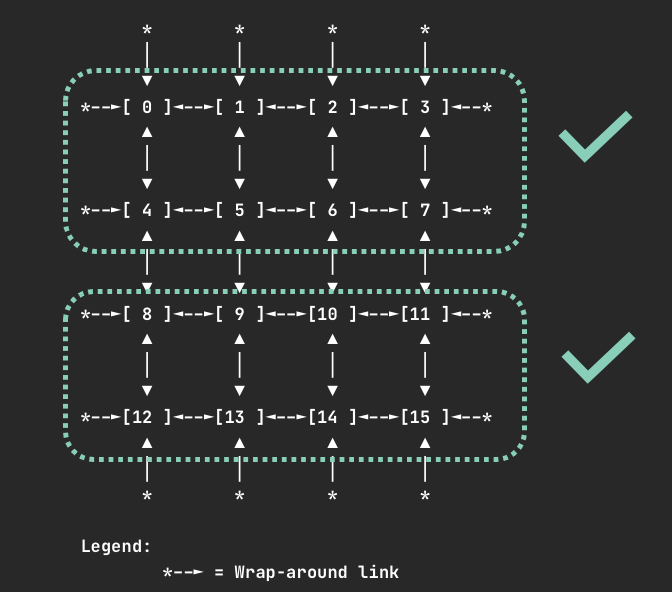
同样,当请求 8 个设备时,会找到 [0,1,2,3,4,5,6,7] 或 [8,9,10,11,12,13,14,15] 这样的组合。这些分配方案确保了任务使用的设备都处于同一个高速互联域中
代码实现
// File: pkg/device/awsneuron/device.go
func graphSelect(devices []*device.DeviceUsage, count int) []int {
// ...
// 1. 从设备信息中获取之前存储的实例类型
if nodeType, ok := devices[0].CustomInfo[AWSNodeType].(string); ok {
AWSNodetype = nodeType
}
// 2. 策略一:如果是 Inferentia 实例,直接寻找任意长度的连续设备块
if strings.Contains(AWSNodetype, "inf") || strings.Contains(AWSNodetype, "Inf") {
// ...
// The core logic is to call continuousDeviceAvailable
res := continuousDeviceAvailable(devices, start, count)
if len(res) > 0 { return res }
// ...
}
// 3. 策略二:如果是 Trainium 实例,只接受特定数量的请求
switch count {
case 1, 4, 8, 16:
{
// ...
// The core logic is also to call continuousDeviceAvailable
res := continuousDeviceAvailable(devices, start, count)
if len(res) > 0 { return res }
// ...
}
}
return []int{} // For Trainium, requests with other counts will fail here
}
// continuousDeviceAvailable 检查从 start 开始的 count 个设备是否都可用
func continuousDeviceAvailable(devices []*device.DeviceUsage, start int, count int) []int {
// ...
for iterator < start+count {
// 核心检查:设备是否已被占用
if devices[iterator].Used > 0 {
return []int{}
}
// ...
}
return res
}3. 核心级共享:资源请求的转换
HAMi 能同时支持设备级和 核心级共享,关键在于 其内部的资源请求 转换逻辑。该逻辑将用户在 YAML 中定义的 不同资源 ( /neuron 或 /neuroncore) “翻译”成调度器可以理解的统一格式。
- 对于设备级请求 (
aws.amazon.com/neuron): 转换是直接的。请求N个设备,就会生成一个需要N个完整物理设备的内部调度请求。 - 对于核心级请求 (
aws.amazon.com/neuroncore): 转换策略的核心是 聚合打包 。为了将零散的核心请求高效地映射到物理设备上,HAMi 采用了一种基于“2 核/设备”模型的捆绑策略,其具体转换规则如下:- 请求 1 个核心 : 转换为寻找 1 个能提供 1 个空闲核心的物理设备。
- 请求 2 个核心 : 转换为寻找 1 个能提供 2 个空闲核心的物理设备。
- 请求 N > 2 个核心 : 转换为寻找
N/2个物理设备,并要求 每个 设备都能提供 2 个空闲核心。
这种策略的本质,是尝试将核心请求打包到尽可能少的物理设备上。但需要注意:对于大于 2 的奇数请求 (如 3 或 5), N/2 的整数除法会导致请求被 向下取整 ,例如请求 3 个核心,最终会被转换为寻找 1 个能提供 2 个核心的设备。
这种设计将复杂的资源换算工作在调度前完成,既为用户提供了灵活的核心级共享,又简化了后续的调度决策过程。
使用方式
示例 1:申请 4 个 Neuron 设备 (触发拓扑感知)
apiVersion: v1
kind: Pod
metadata:
name: neuron-device-demo
spec:
restartPolicy: Never
containers:
- name: nuropod
command: ["sleep","infinity"]
image: public.ecr.aws/neuron/pytorch-inference-neuron:1.13.1-neuron-py310-sdk2.20.2-ubuntu20.04
resources:
limits:
cpu: "4"
memory: 4Gi
# 请求4个Neuron设备,将触发 graphSelect 拓扑寻优逻辑
aws.amazon.com/neuron: 4 示例 2:申请 1 个 NeuronCore (核心级共享)
apiVersion: v1
kind: Pod
metadata:
name: neuron-core-demo
spec:
restartPolicy: Never
containers:
- name: nuropod
command: ["sleep","infinity"]
image: public.ecr.aws/neuron/pytorch-inference-neuron:1.13.1-neuron-py310-sdk2.20.2-ubuntu20.04
resources:
limits:
cpu: "4"
memory: 4Gi
# 请求1个NeuronCore,实现细粒度共享
aws.amazon.com/neuroncore: 1总结
HAMi 对亚马逊云科技 Neuron 的支持,在设计上体现了清晰的工程哲学: 用策略代替扫描,用简约实现高效 。其拓扑寻优算法,通过识别实例类型并将拓扑问题简化为寻找连续的设备索引,以极低的复杂度实现了与亚马逊云科技官方调度器行为一致的高性能调度。这种务实的设计,不仅确保了多设备任务能够充分利用 Neuron 硬件的底层高速互联优势,也为用户提供了灵活、易用的云原生 AI 算力调度体验。
参考资料
- 使用文档:AWS Neuron 示例与操作指南 ( https://project-hami.io/docs/userguide/AWSNeuron-device/enable-awsneuron-managing )
- 相关 PRs: https://github.com/Project-HAMi/HAMi/pull/1238

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)