LangChain语言的基础学习
LangChain是一个开源框架,主要用于开发有大语言模型驱动的应用程序,主要是将大模型与外部数据和各种组件连接起来构建AI程序模型1.创建新项目在pycharm中创建一个新项目,项目名称位置的基本信息自己定,新项目的环境选择使用conda编辑器环境,如果有就直接选择原有的conda环境,没有就点击新创建一个(显示下载miniconda时直接下载就行会自动调用)
LangChain是一个开源框架,主要用于开发有大语言模型驱动的应用程序,主要是将大模型与外部数据和各种组件连接起来构建AI程序模型
官网地址:https://www.langchain.com/langchain
官网文档:https://python.langchain.com/docs/introduction/
API文档:https://python.langchain.com/api_reference/
github地址:https://github.com/langchain-ai/langchain
1.创建新项目
在pycharm中创建一个新项目,项目名称位置的基本信息自己定,新项目的环境选择使用conda编辑器环境,如果有就直接选择原有的conda环境,没有就点击新创建一个(显示下载miniconda时直接下载就行会自动调用)
1.RAG与Agent架构
何为RAG?:检索增强生成,检索——给到的问题在数据库中进行检索,增强——将检索到的数据给到提示词,生成——使用大语言模型将提示词的内容进行更准确的回复
RAG——主要用来提升大语言模型的准确性和时效性 因为生成的数据可以添加数据来源
RAG中的难点:文件解析,文件切割,知识检索,知识重排序(增加响应时长)
何为Agent(智能体)?:Agent=LLM+Memory+Tools+Planning+Action LLM——大模型
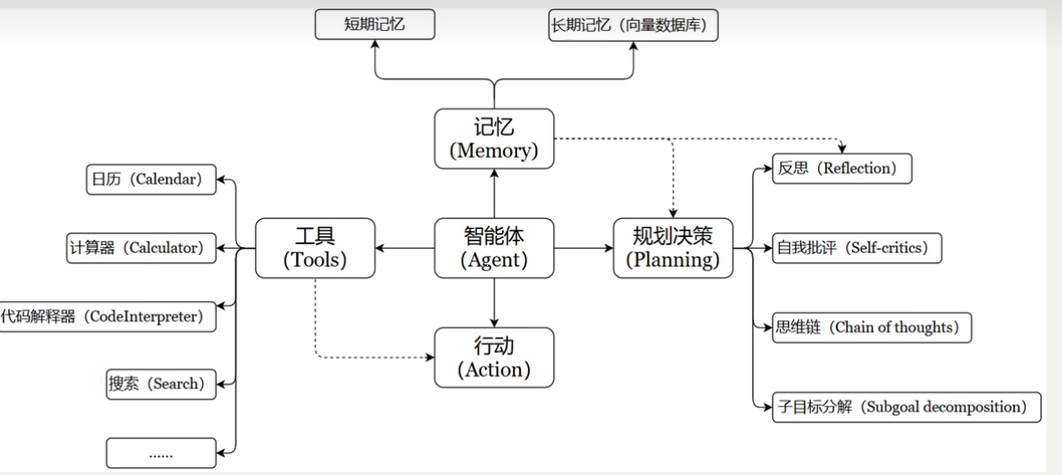
一个有记忆能够使用工具,做出规划并且行动的响应程序
大模型应用开发的四个场景:
1 纯Prompt
2 Agent+Function Calling
3 RAG
4 Fine-tuning(精调/微调)
2.Langchain的核心模块
官网文档:https://python.langchain.com/docs/introduction/
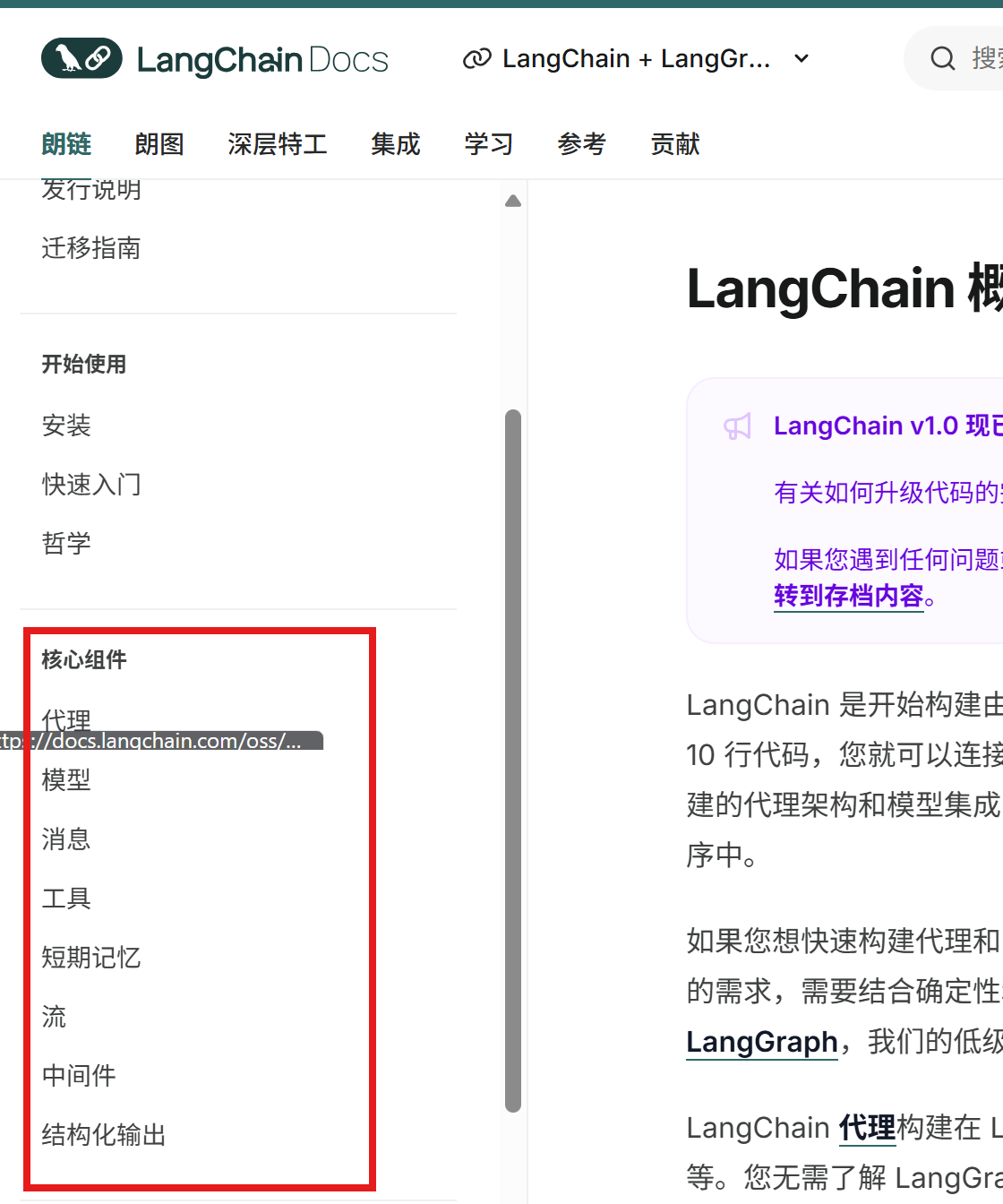
langchain中各个模块都能在官方文档里查看到,主要在0.1版本中
将pycharm社区版升级成professional版本后可以创建jupyter文件,jupyter文件可以单独运行某一行代码方便后对代码的修改。升级professional版本后有30天的免费试用期。后续收费了还可以在改回社区版
langchain的hello world(简单的使用一下langchain相当于编程里的hello world)
获取大模型,调用deepseek
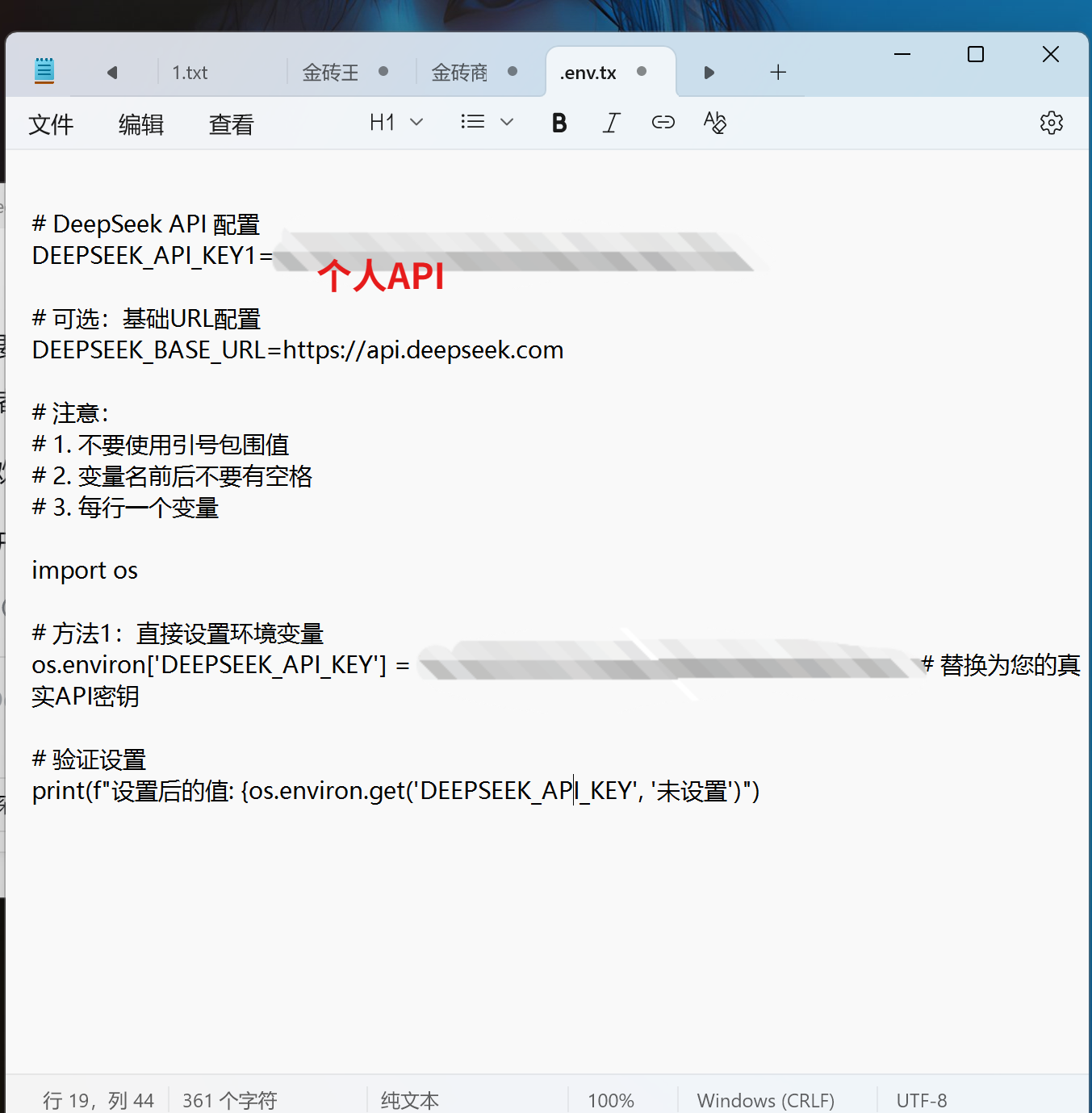
从deepseek官方的文档里获取个人API将API整理后放入桌面文件里命名为.env(可以创建一个文本文档在里面填写需要的内容但是文件命名只能是.env不能带有.txt后缀,本人因该文件名为.env.txt导致代码一直报错接口有问题找了半天原因)
在pycharm里新创建jupyter文件然后问ai要一个简单的创建大模型的代码
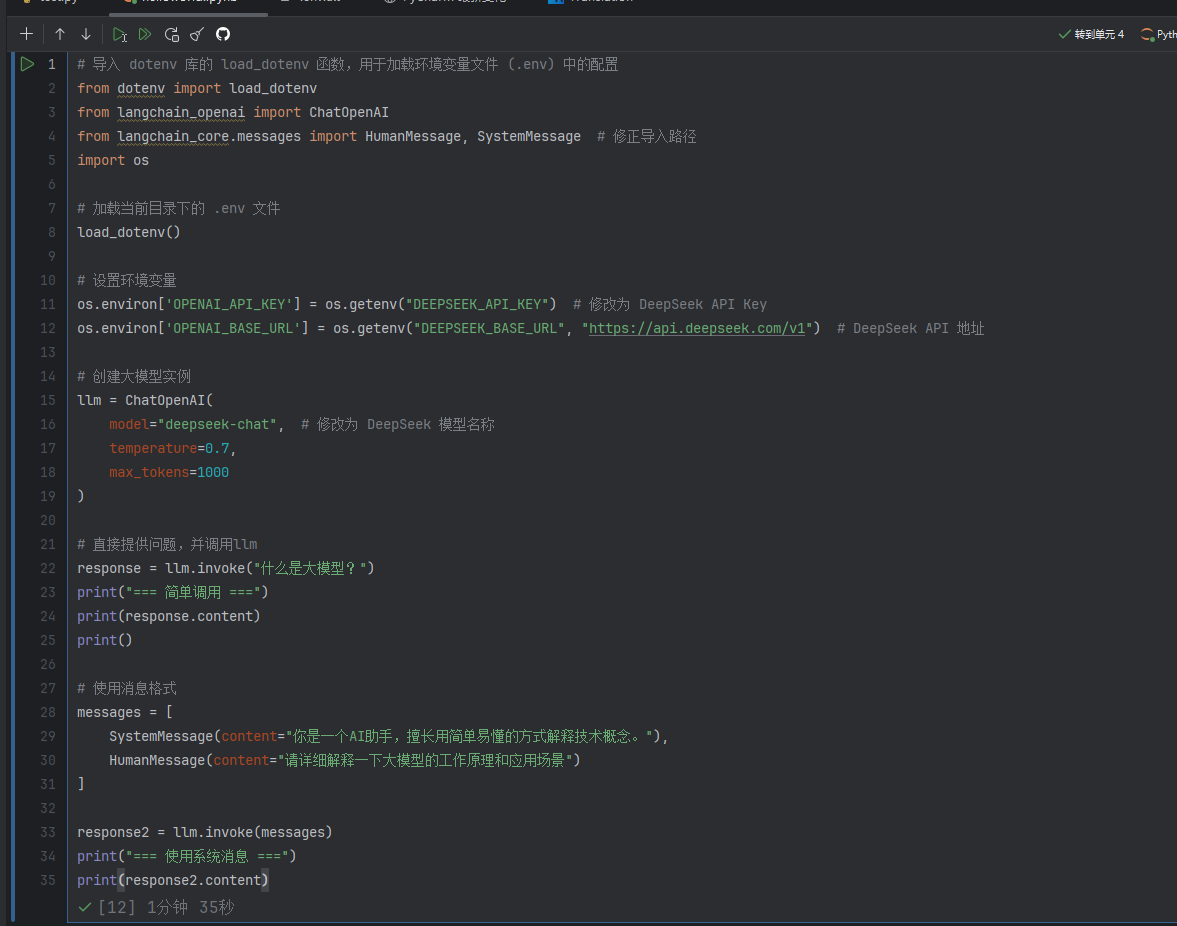
将桌面上的.env复制后粘贴到pycharm里面运行即可
3.LangChain使用之Model l/o

后面学习按照 调用模型---输入提示词---输出解析的顺序
3.1模型调用
LangChain只是一个工具,不提供LLMs,而是依赖第三方的集成的各种大模型
不同模型的
1.模型调用的分类
角度一:按照模型的功能不同
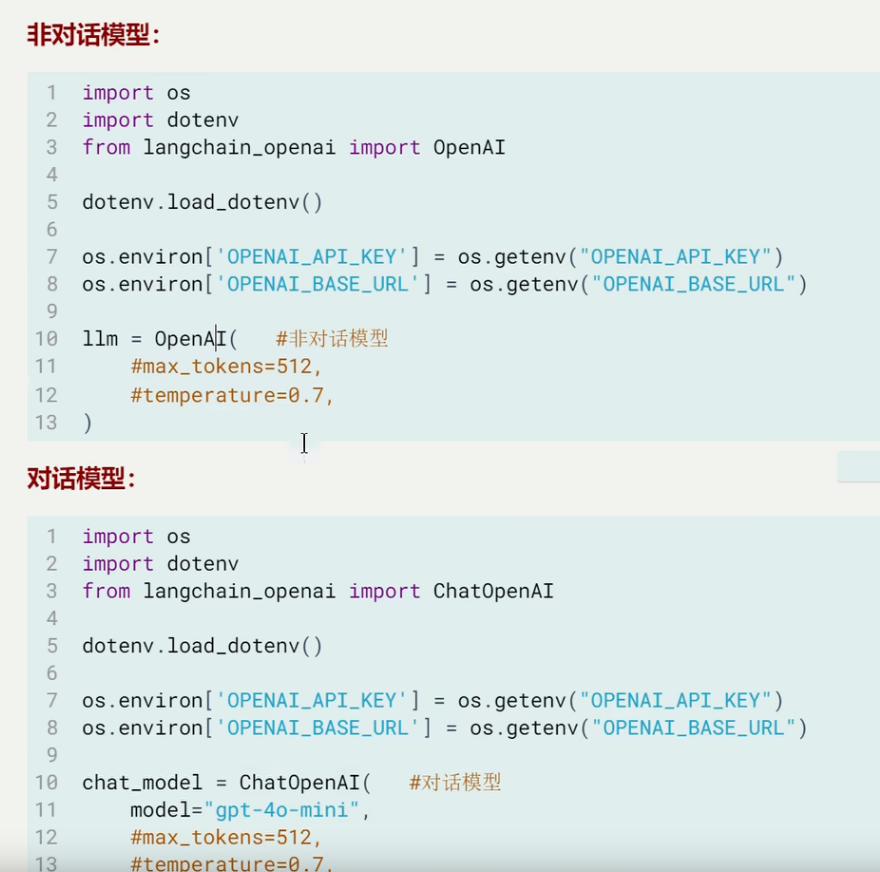
非对话模型:(LLms,Text Model) 多轮对话情景
对话行模型:(Chat Models) 单个任务情景
嵌入模型:(Embedding Models)
角度二:按照模型调用时,参数书写位置的不同(api-key,base_url,model-name)
硬编码的方式:将参数书写在代码中
使用环境变量的方式
使用配置文件的方式
角度三:具体API的调用
使用LangChain提供的API
使用OpenAI官方的API
使用其他平台提供的API
非对话模型的调用:
特点:不支持多轮对话的上下文,有局限性无法处理角色分工或复杂对话逻辑
输入:只接受文本字符串或promptvalue
输出:总是返回文本字符串
参数位置不同举例:
OpenAI/ChatOpenAI 非对话类/对话类 模型
model.invoke(xxx) 执行调用,将用户输入发给模型
.content 提取模型返回的实际文本内容
调用大模型后三种输出方式的区别:
-
print(response):就像是查看包裹的运单。它告诉你关于包裹的基本信息(从哪里来、状态码、头部信息等),但不会告诉你里面的具体物品是什么。 -
print(response.content):就像是打开包裹,直接查看里面的原始物品(二进制零件)。 -
print(response.text):就像是打开包裹后,还附上了一本说明书,帮你把这些二进制零件组装成你能看懂的文字。
参数的类别:
1)必须设置的参数:
base_url:大模型的API服务的根地址
api_key:用于身份验证的密钥,由大模型服务商提供
model/model_name:指定要调用具体的大模型的名称
2)其他参数:
temperature:温度,控制生成文本的“随机性”,取值范围为0~1
中间值为0.8
值越低表示输出越稳定{适合事实回答}
值越高表示输出越多样有创意{适合创意回答}
max_tokens:限制生成文本的最大长度,防止输出过长
tokens为大模型中处理文本的最小单位相当于字节

3.1.1模型调用示例
1)硬编码的方式:将参数书写在代码中
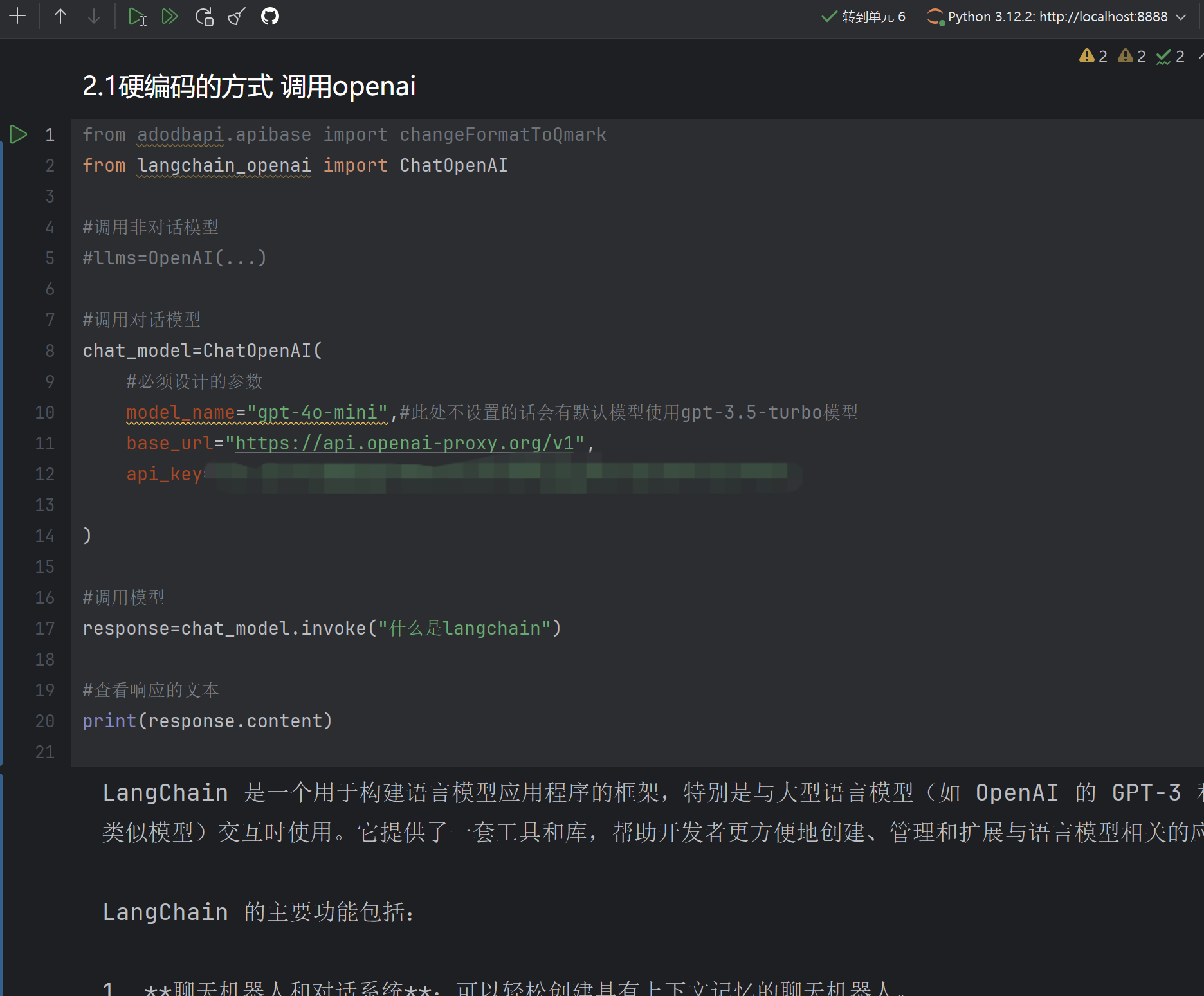
此案例运用的是Openai模型的gpt了,考虑到Openai官网访问受限这里可以使用
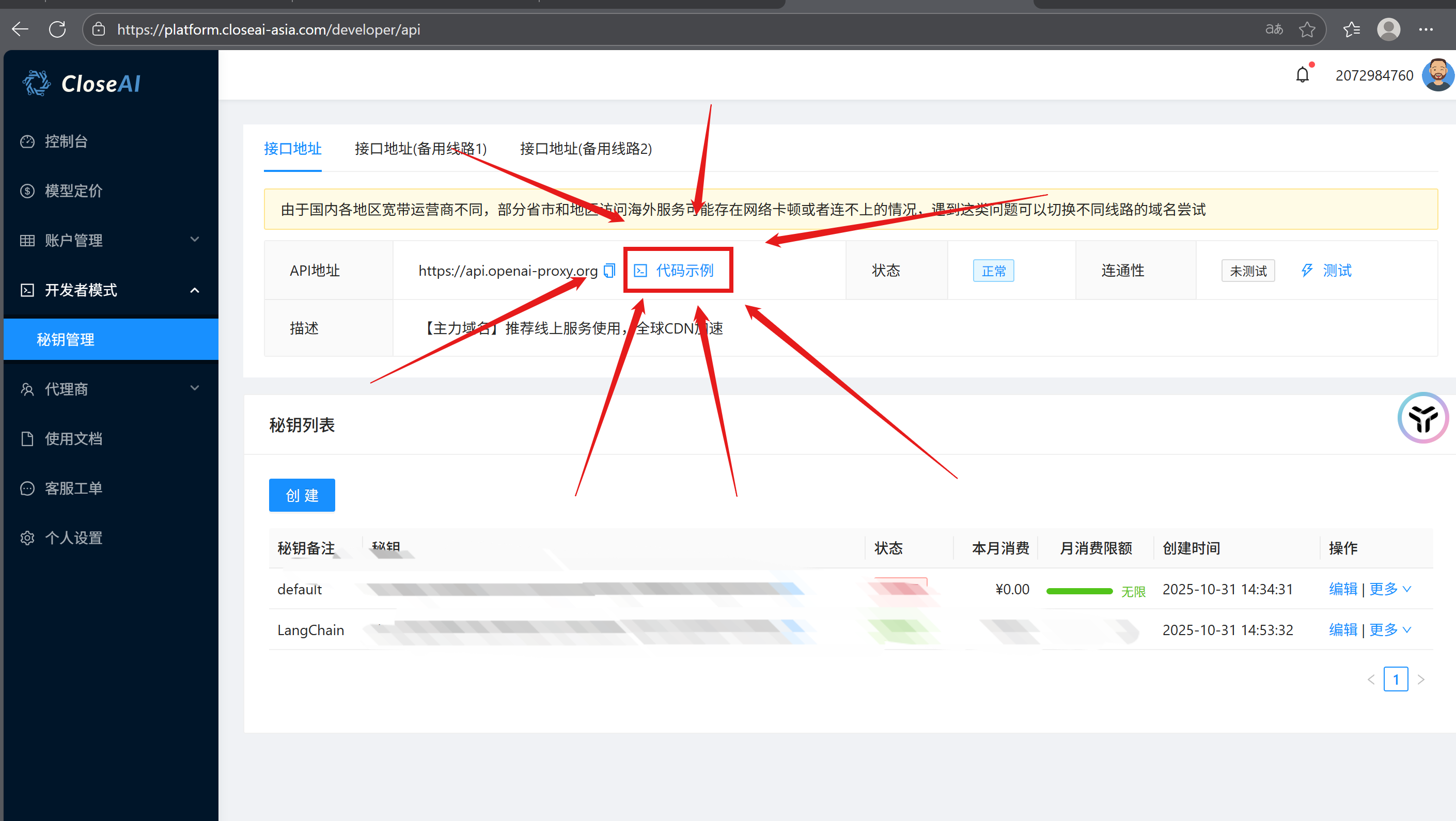
closeaihttps://platform.closeai-asia.com/dashboard也就是openai在国内的代理
进入closeai官网后创建个人帐号然后充值账户(调用大模型收费)在closeai官网中点击密钥管理即可创建个人API将创建的Api复制到代码中的api_key参数中即可,base_url的格式需要加入后缀具体内容在
注意。juptyer文件中如果需要用到的库前面已经用到了后面可以不写
2)使用环境变量的方式
使用环境变量的方式,在juptyer中执行不合适,需要在.py文件中执行
创建.py文件
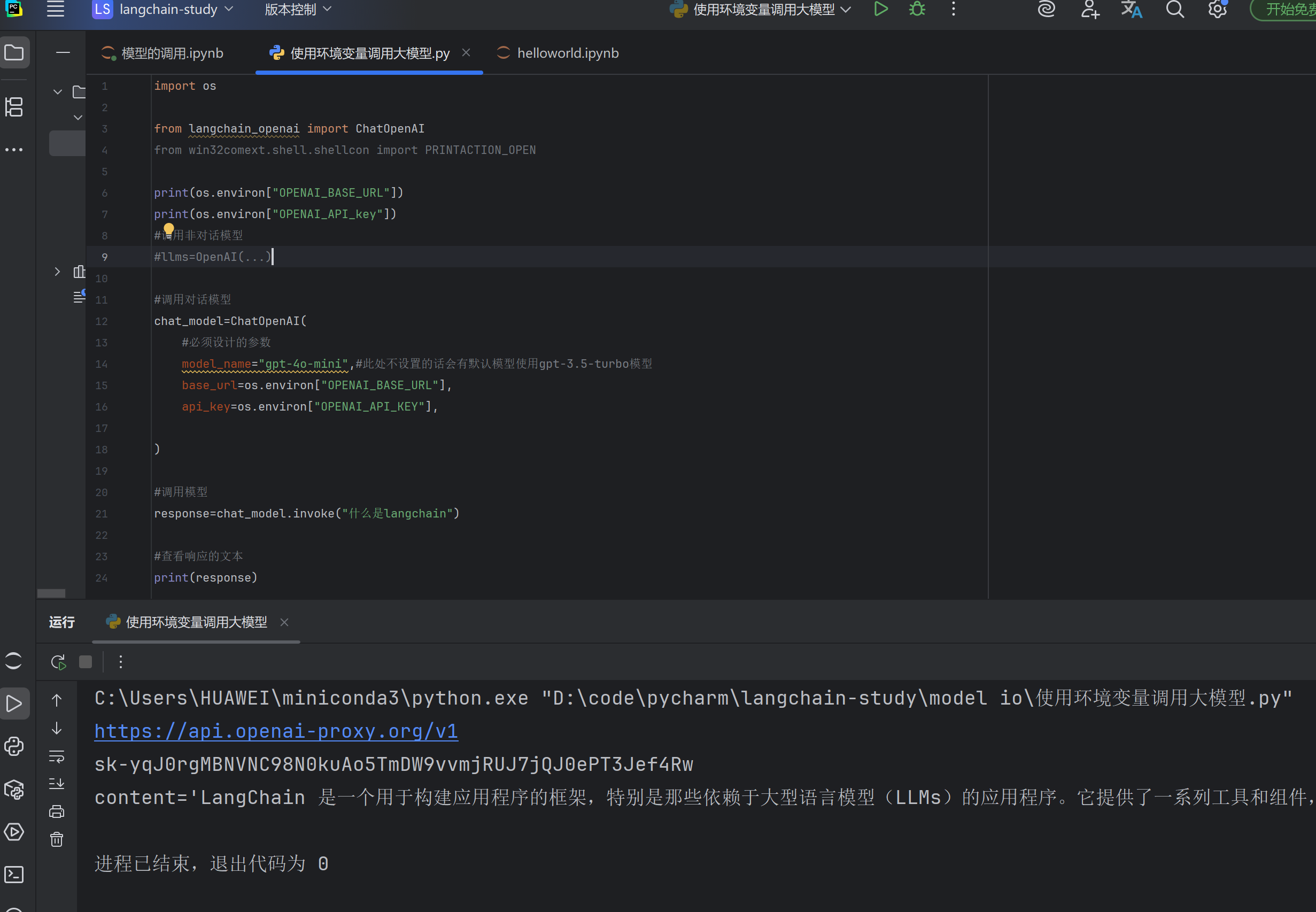
在.py文件里创建好了后不能直接运行
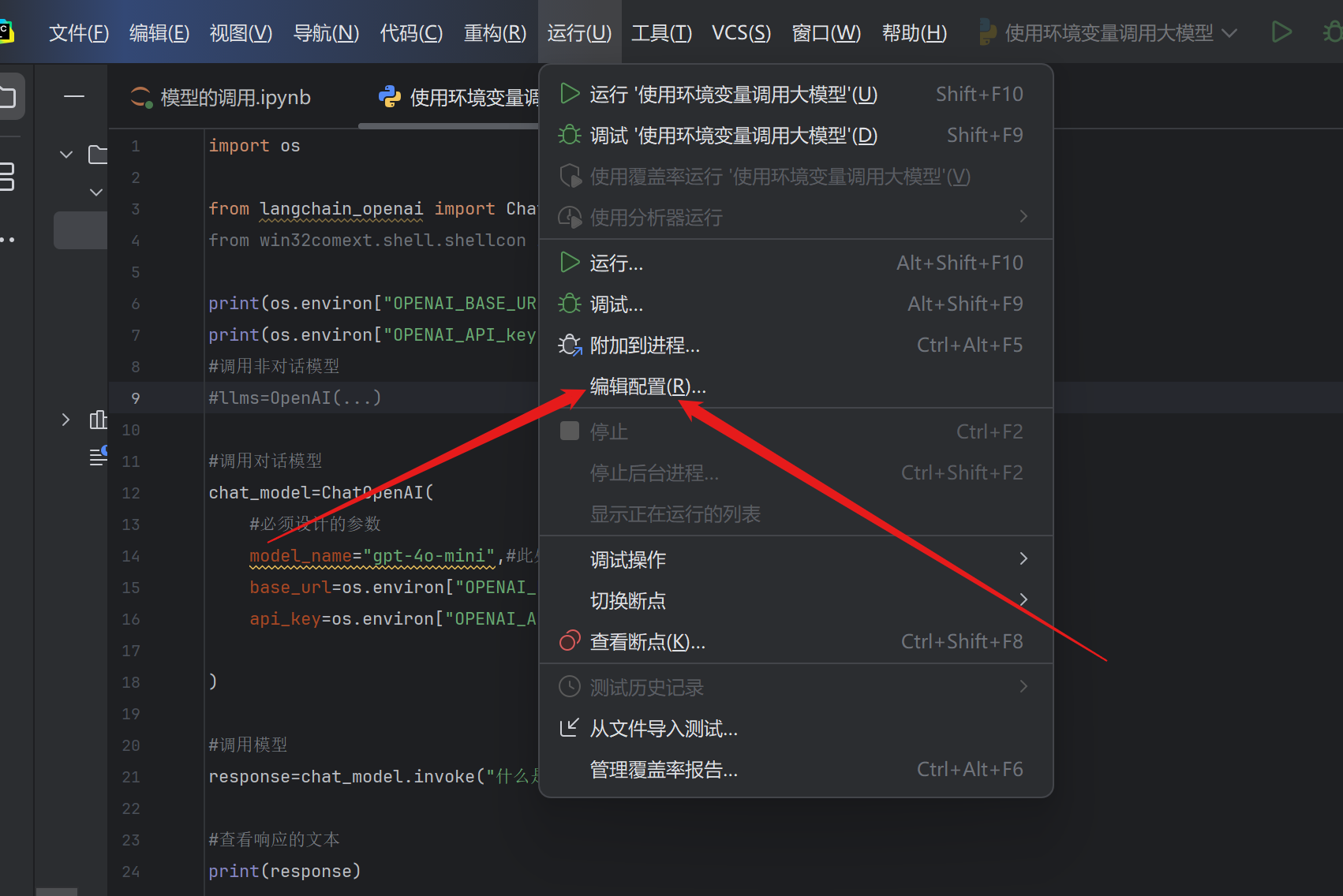
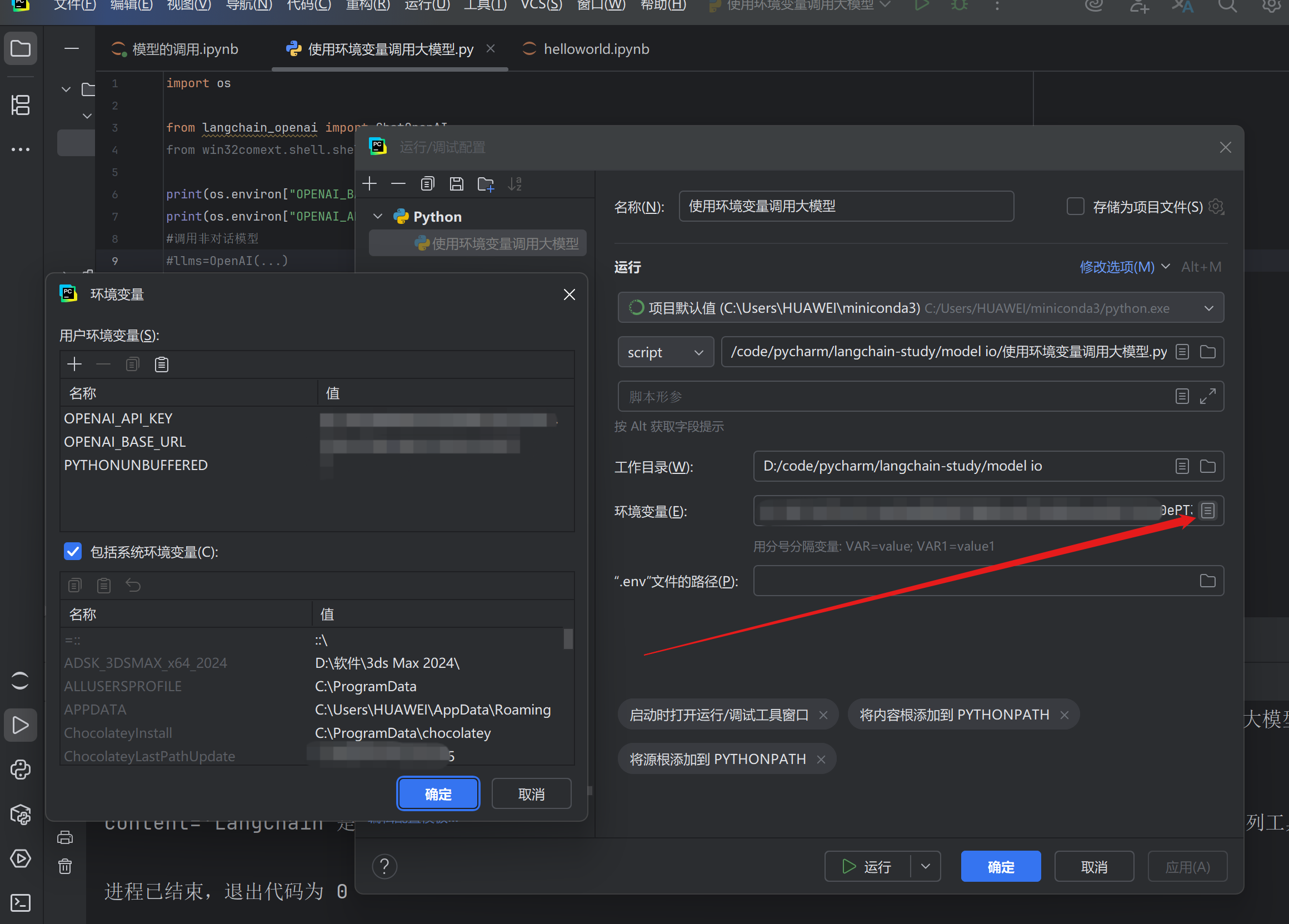
点击编辑配置进行新环境的配置,点击弹出的新的窗口里的+配置新环境,名称为OPENAI_KEY_API 值为个人API值
名称为OPENAI_BASE_URL 值为url值,要和上面一样添加后缀
3)使用配置文件的方式
和前面展示的helloworld一样需要导入
import os
import dotenv
然后将API和BASE_URL放入到.env文件里
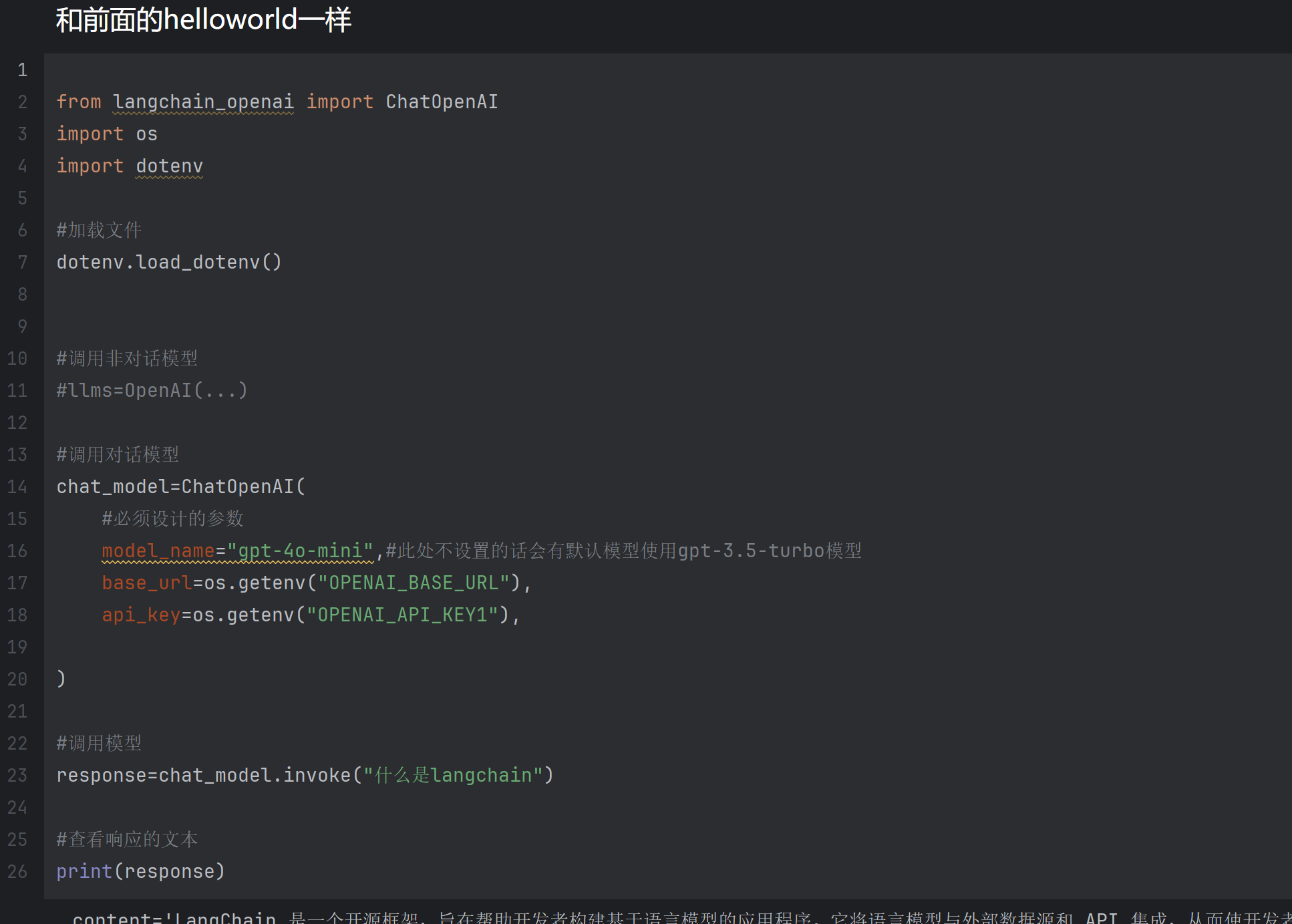
此种发方法最安全可靠API,五星推荐
获取大模型的标准方式
对话模型与非对话模型的区别从输出内容上:非对话模型是纯文本
| 输出结构 | 返回结构化 ChatMessage(如 role, content) |
返回纯文本补全(text: str) |
关于对话模型的Message(消息)
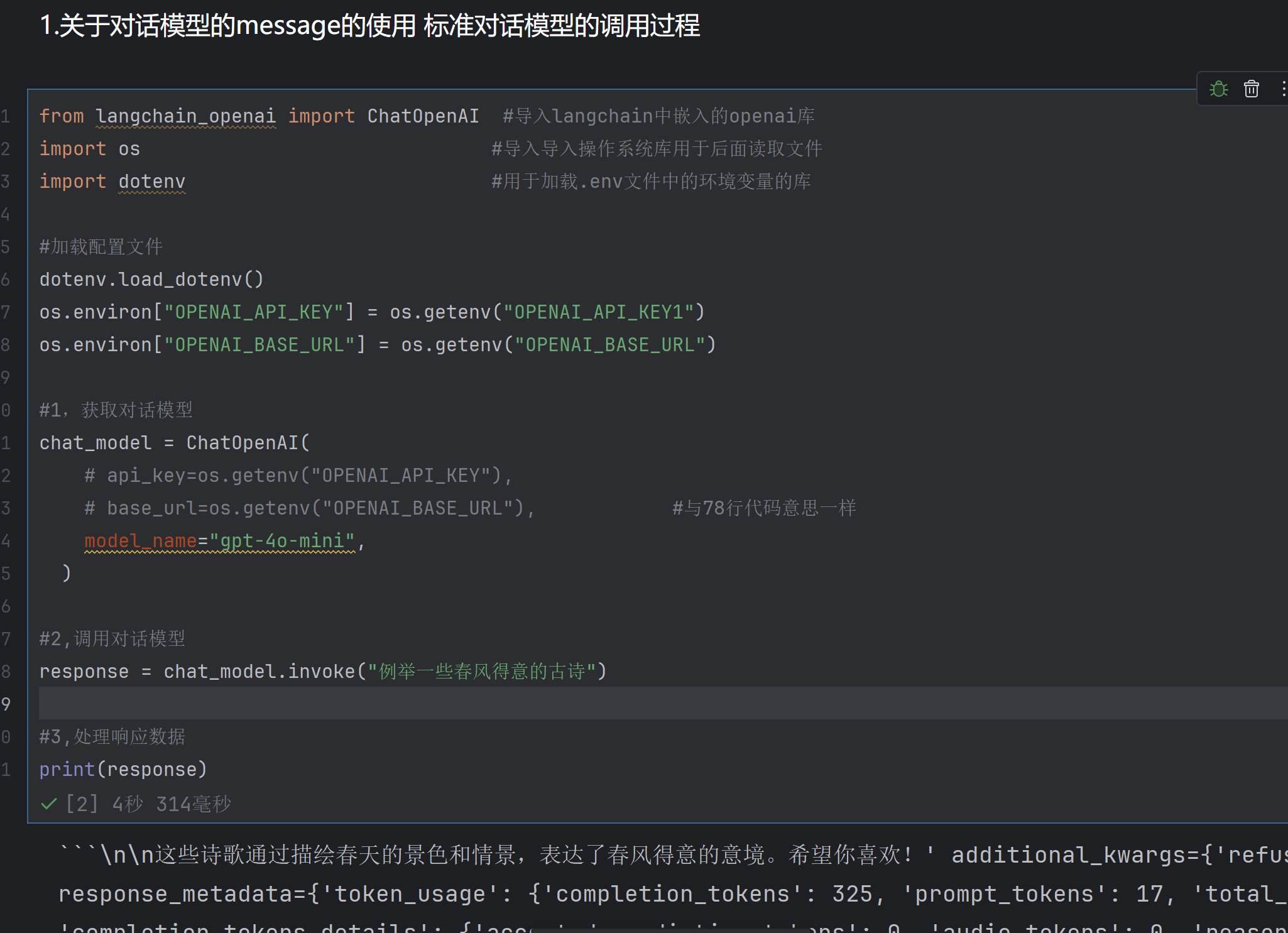
消息类型

![]()
举例子
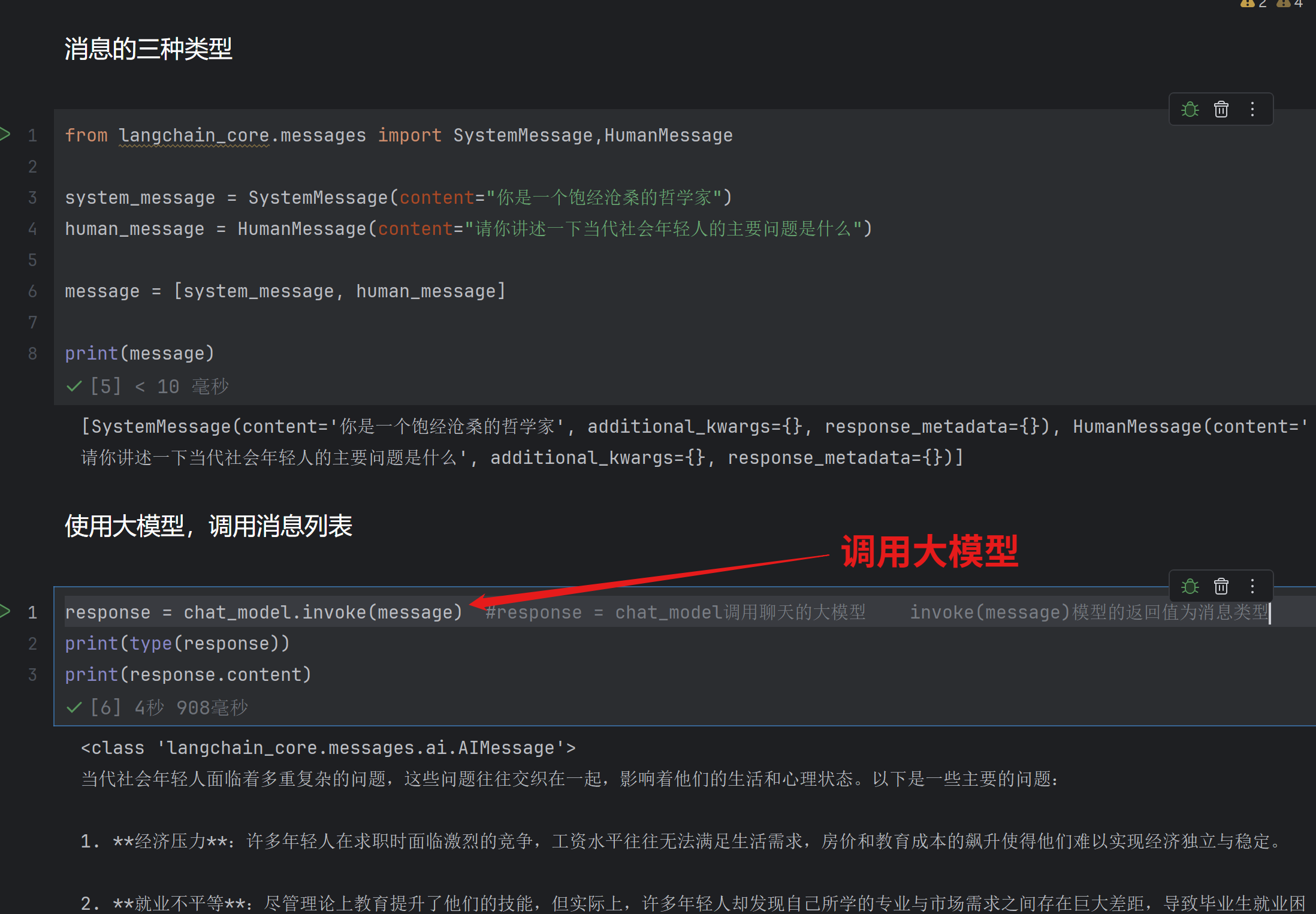
关于多轮对话与上下文记忆
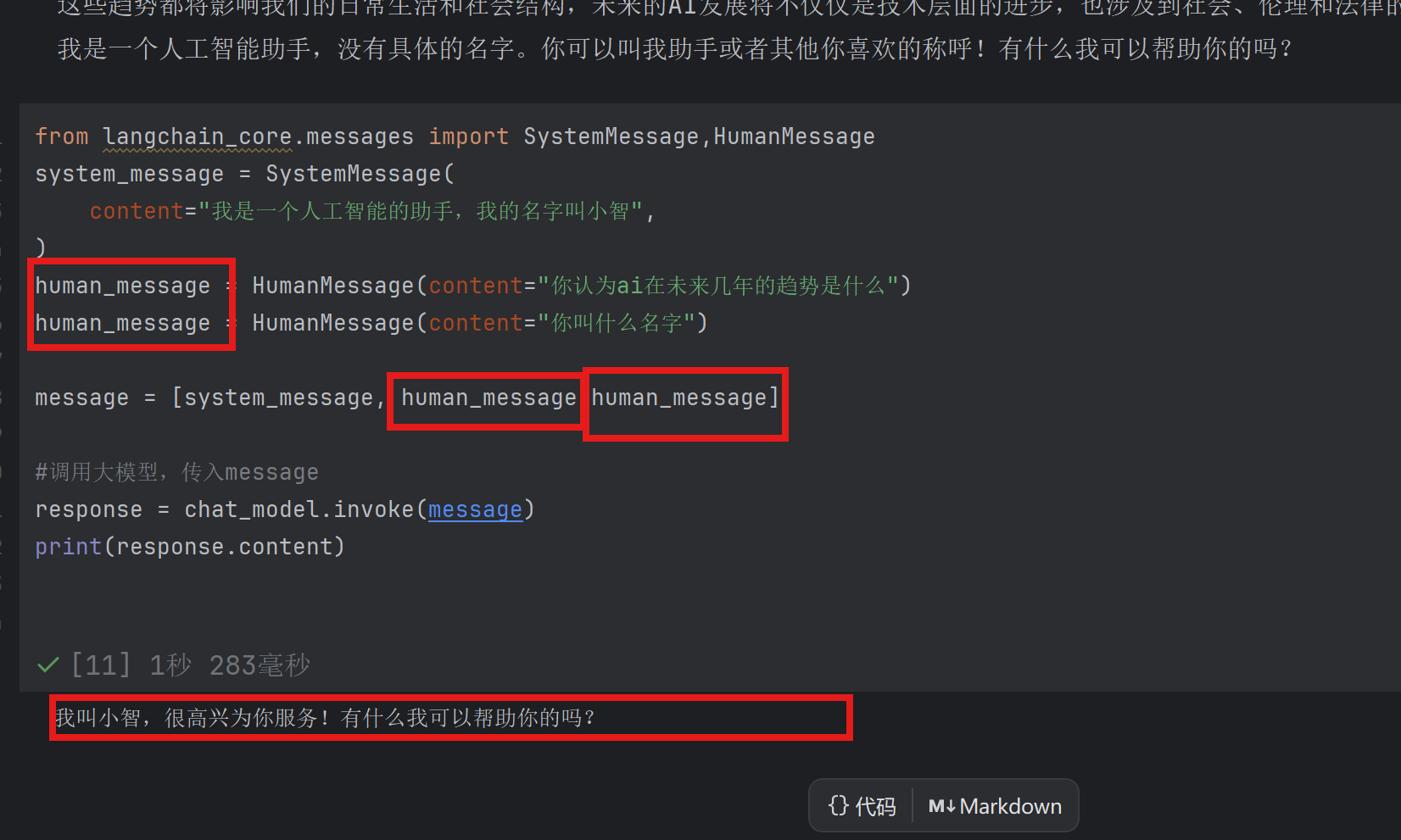
大模型本身是没有上下文记忆能力的
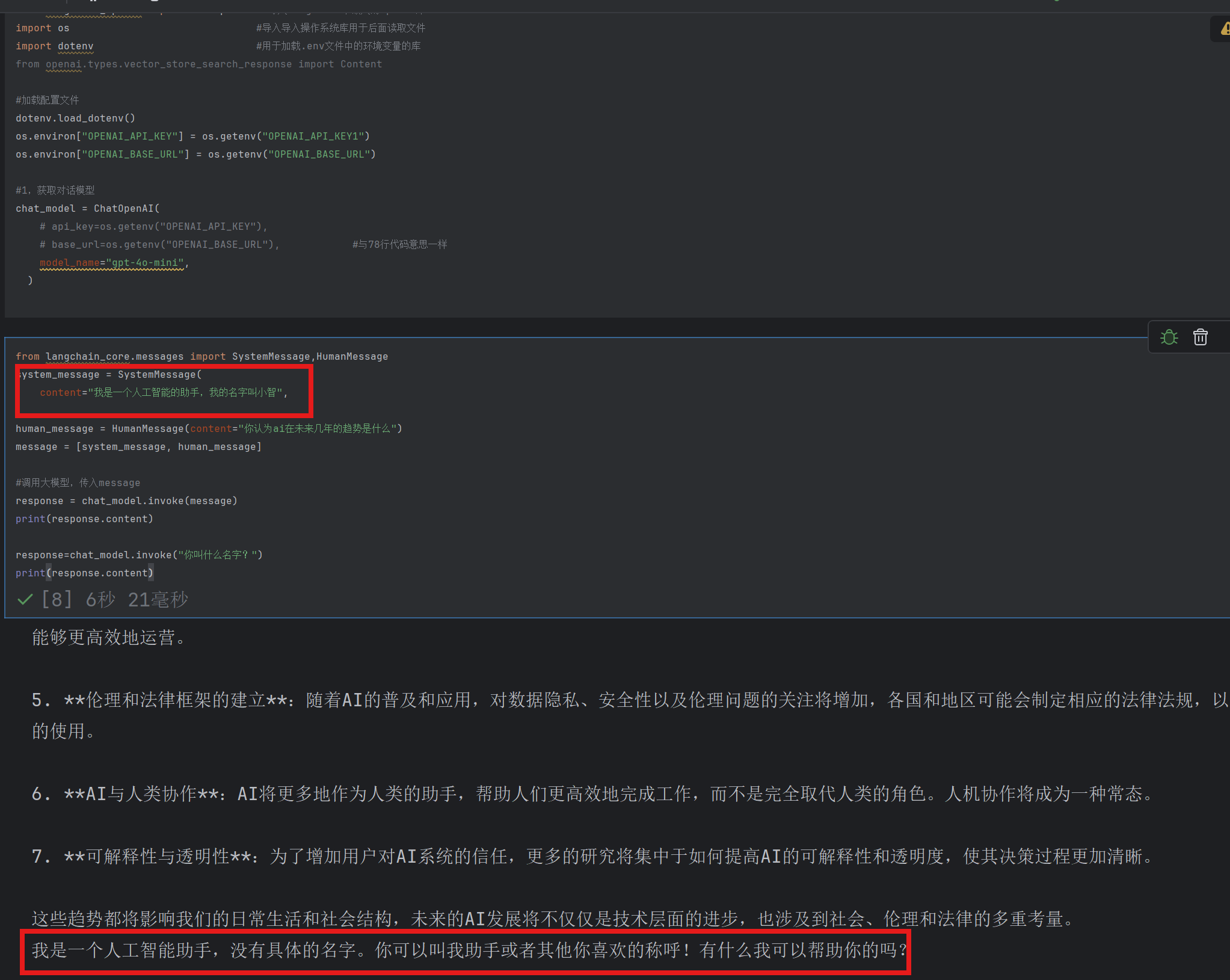
首先给定了大模型一个具体名字但是在下一轮对话之后该大模型就忘记了自己的名字
默认情况下大模型只会回答human_message中的最后一个参数
(同理system_message也是一样)
3.1.2关于模型调用的方法
1)流式与非流式调用
非流式:当用户发出请求后,系统在后台等待模型生成完整响应后一次性将全部结果全部返回
流式:用户发出请求后,模型逐个token地实时返回结果(一个字一个字的生成)
示例一,体会invoke阻塞式(非流式)的调用
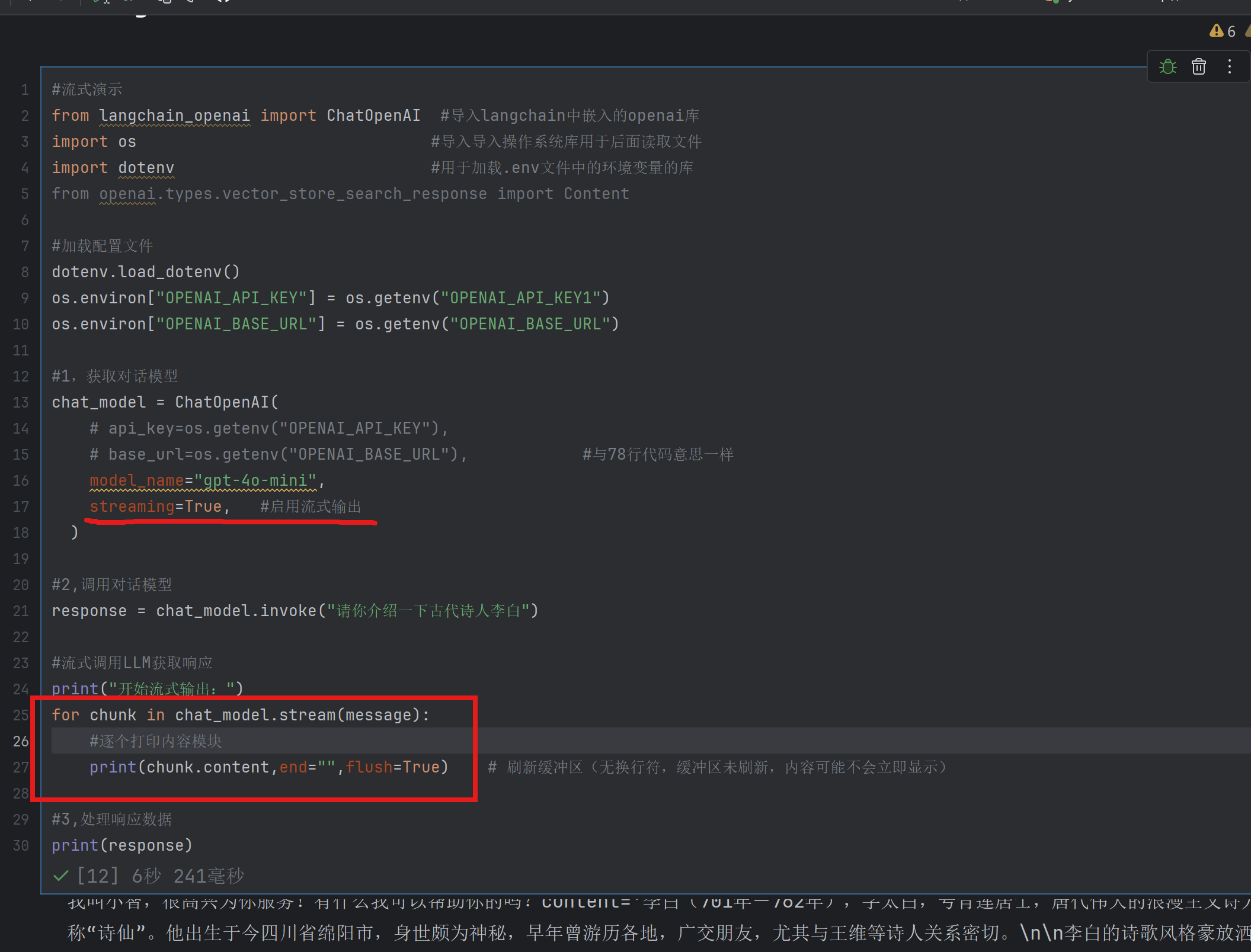
若改成非流式只需要将streaming=False和response = chat_model.invoke(message)替换一下图中标记的就行
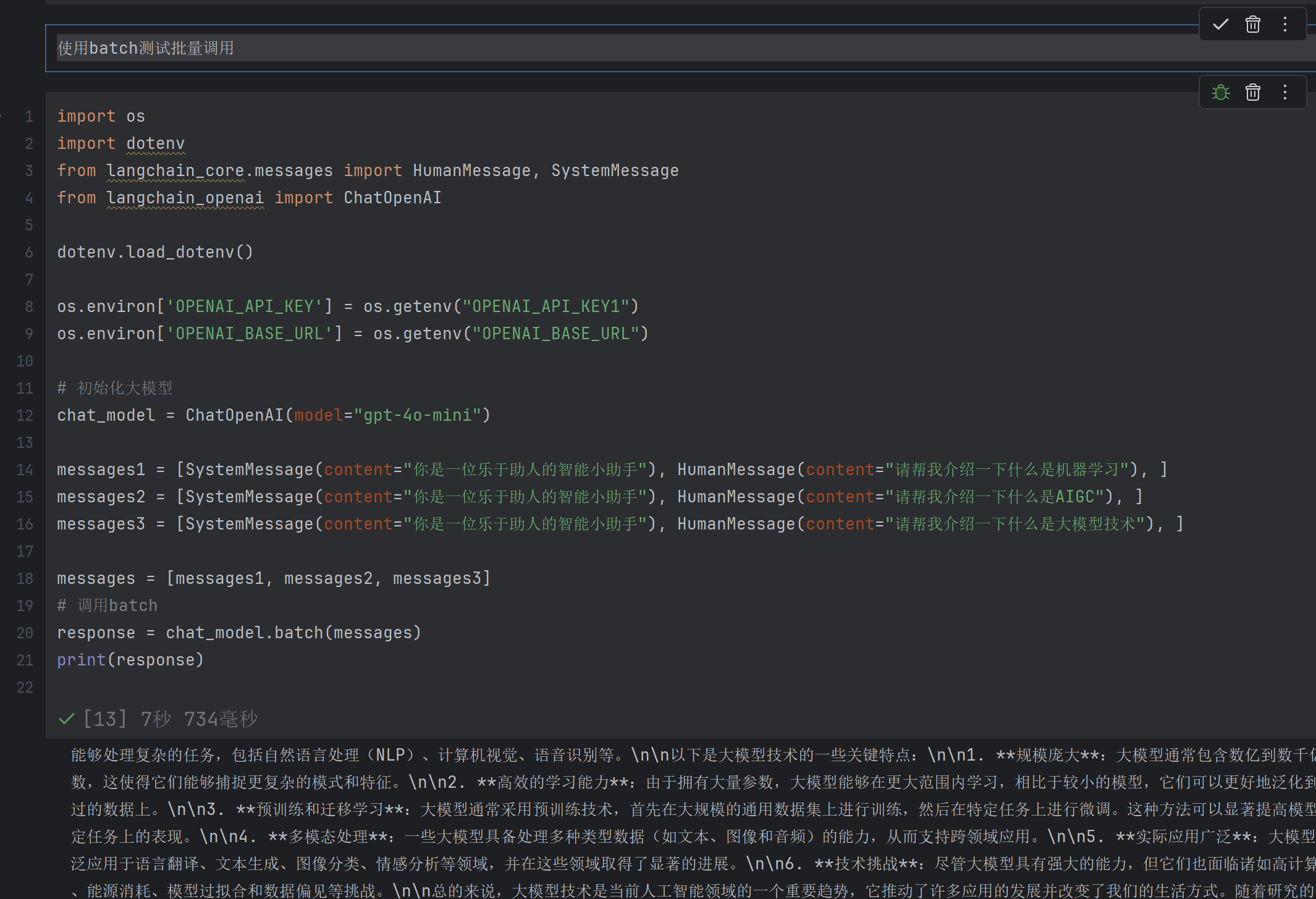
2)批量调用
3)同步和异步方法的调用
同步调用:几种操做同时进行
使用time库用于time.sleep()模拟任务耗时
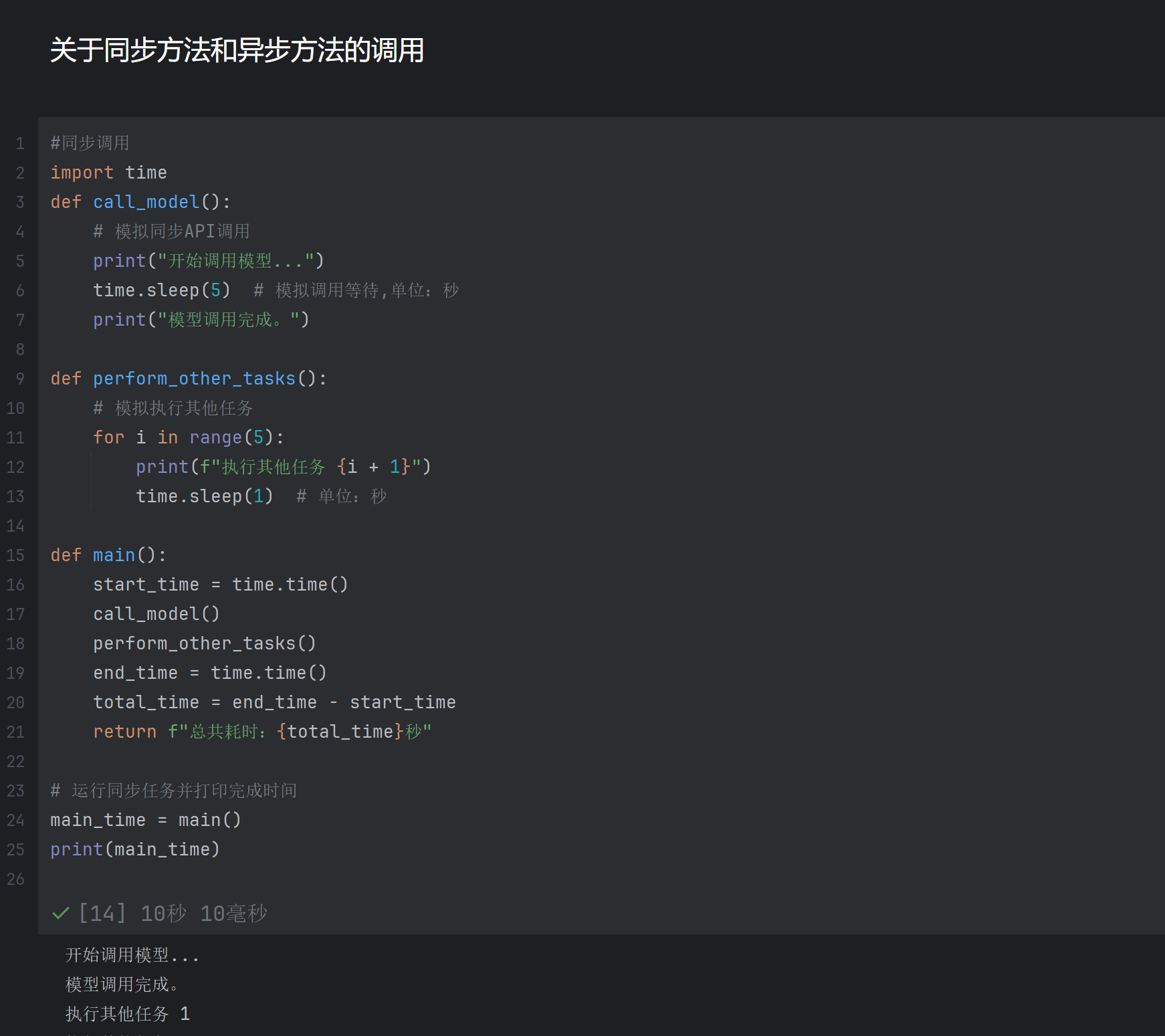
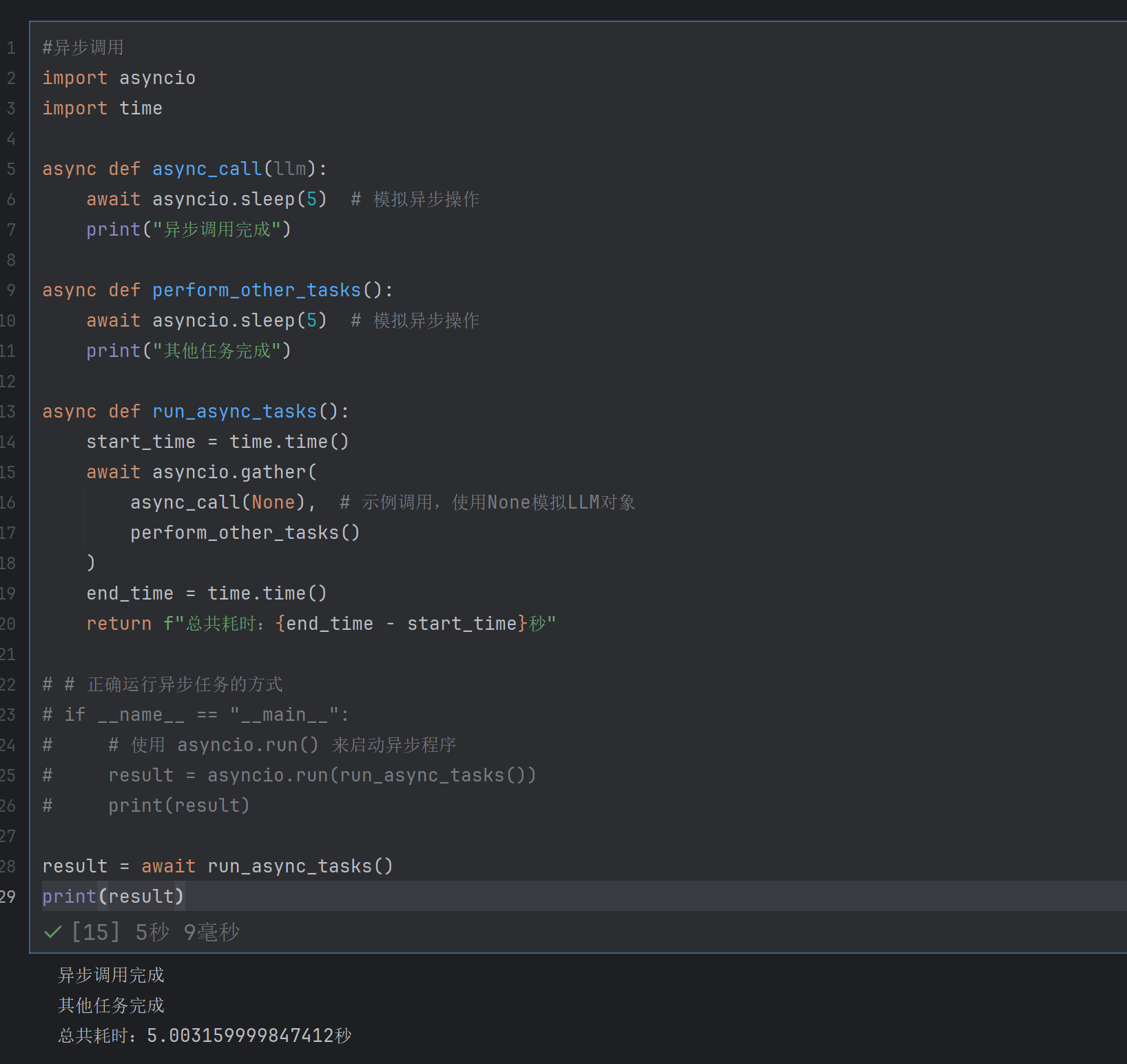
异步调用:按照先后顺序进行
使用time库和asyncio库(异步并发核心库,提供事件循环)
4.Model i/o之Prompt Template(提示词模板)
提示词可以理解为发给大模型的隐藏文本,当我们询问大模型时提示词和用户输入的信息一起发给大模型
提示词模板的类型

prompttemplate的使用
1.prompttemplate如何获取
2.两种特殊结构的使用(部分提示词模板的使用,组合提示词的使用)
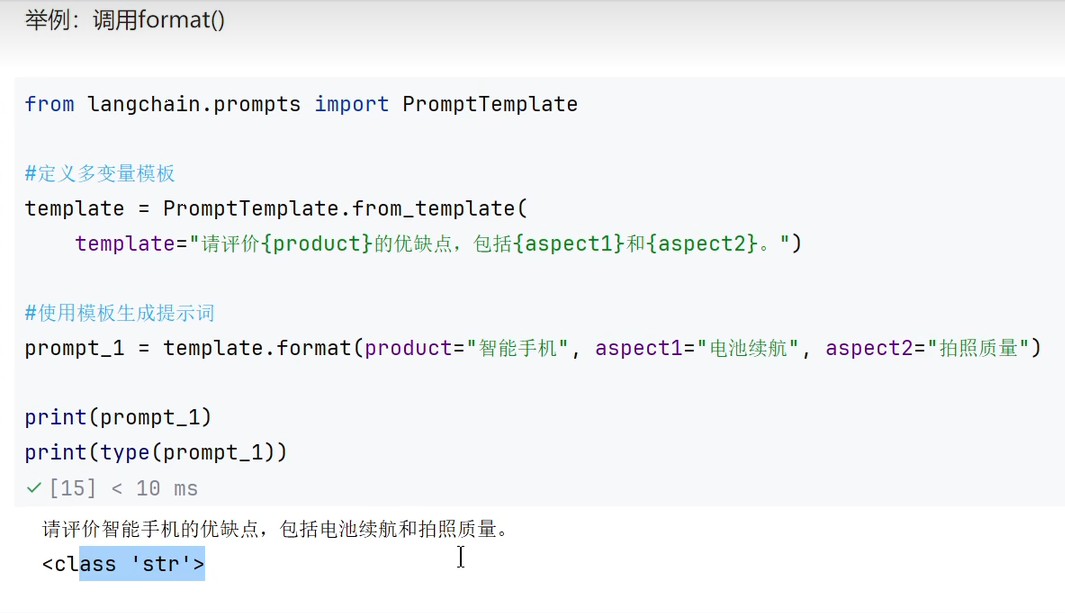
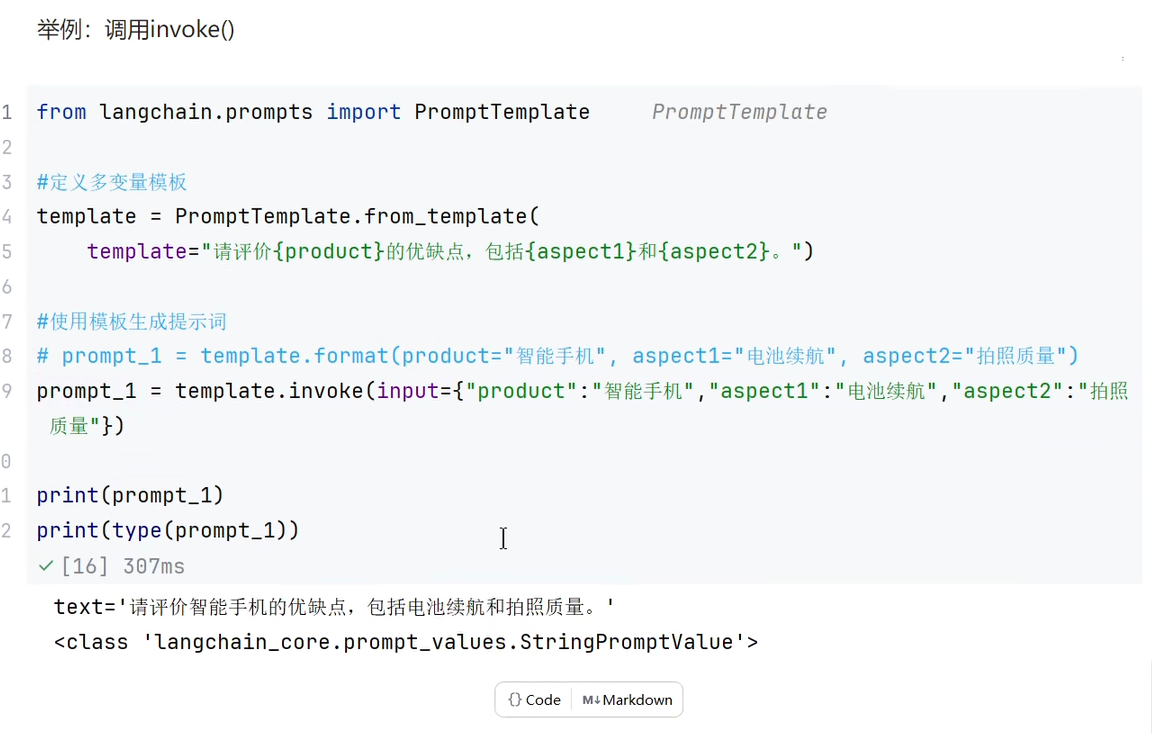
3.给变量赋值的两种方式:format()/invoke()
4.结合大模型的使用
1.prompttemplate如何获取
1.1方法一使用构造方法获取
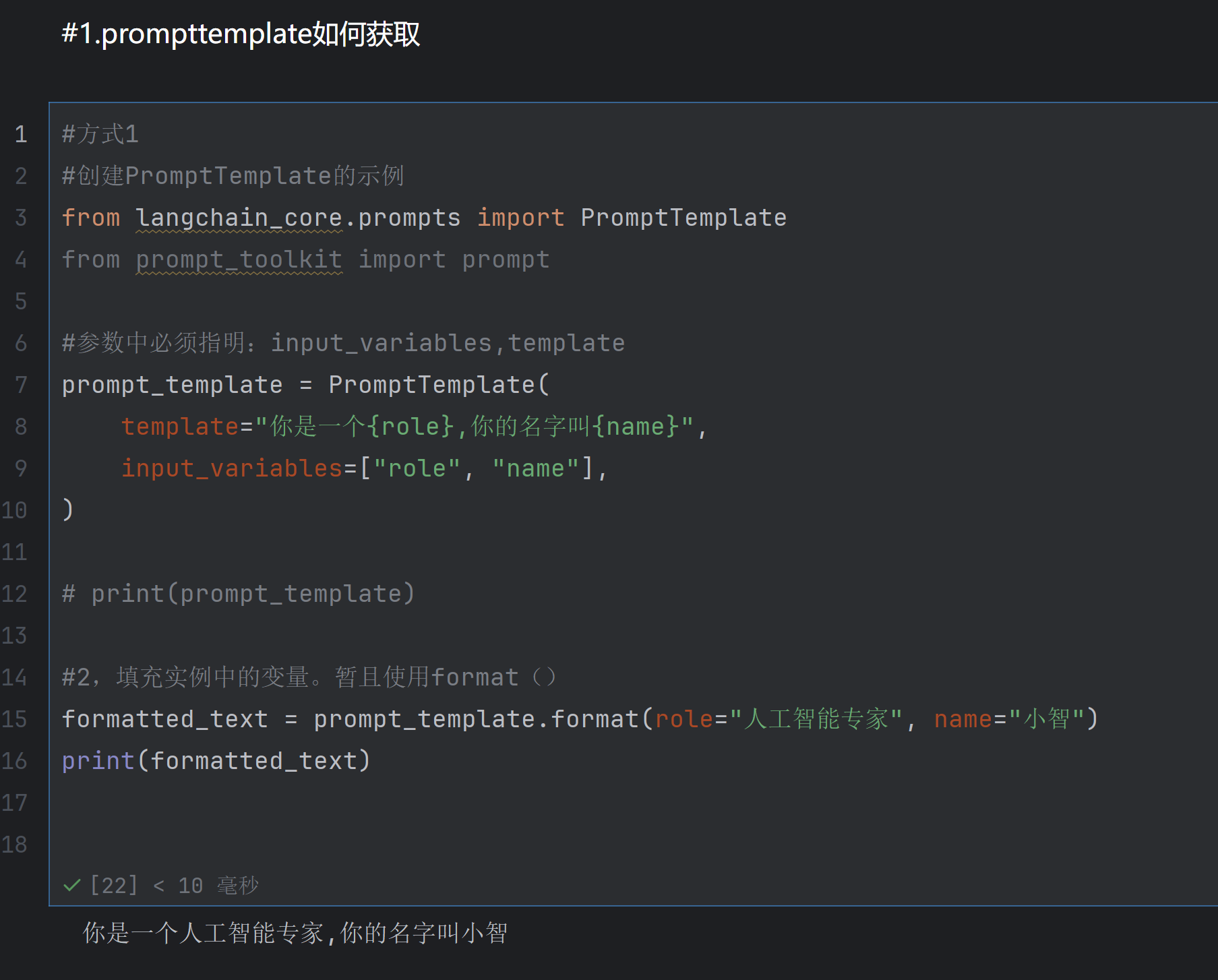
1.2方法二form_template() 此种方法很简单推荐使用
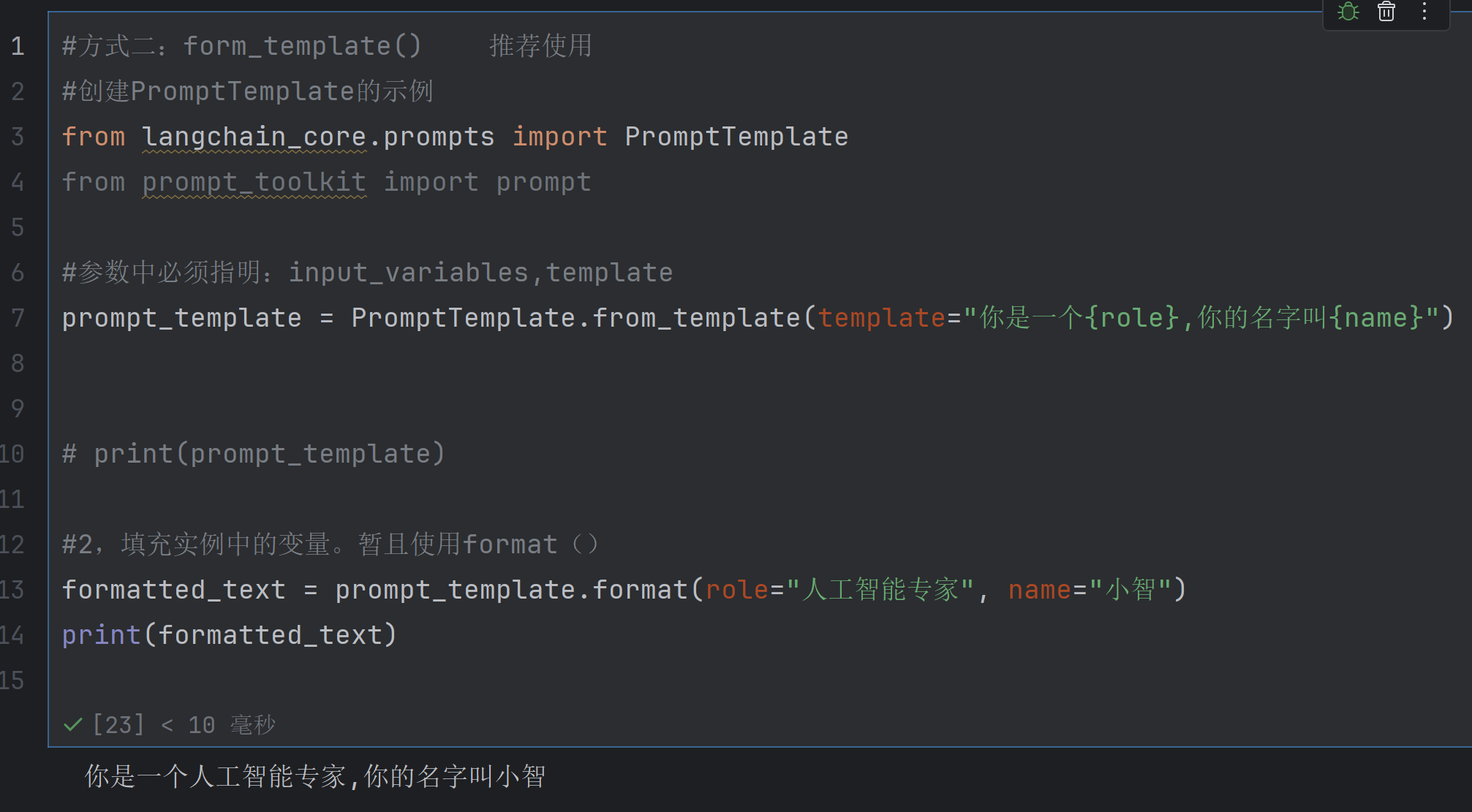
2.部分提示词模板的使用
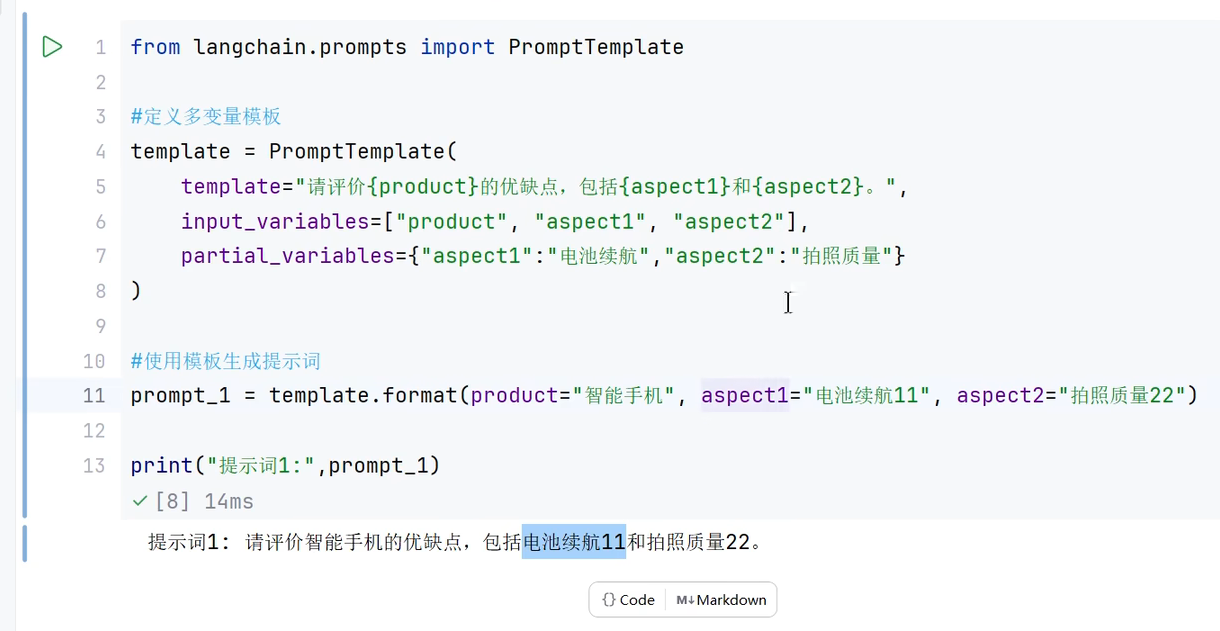
2.1在from_template()方法内或者prompttemplate的构造方法 使用partical_variables设置
在from_template()方法内
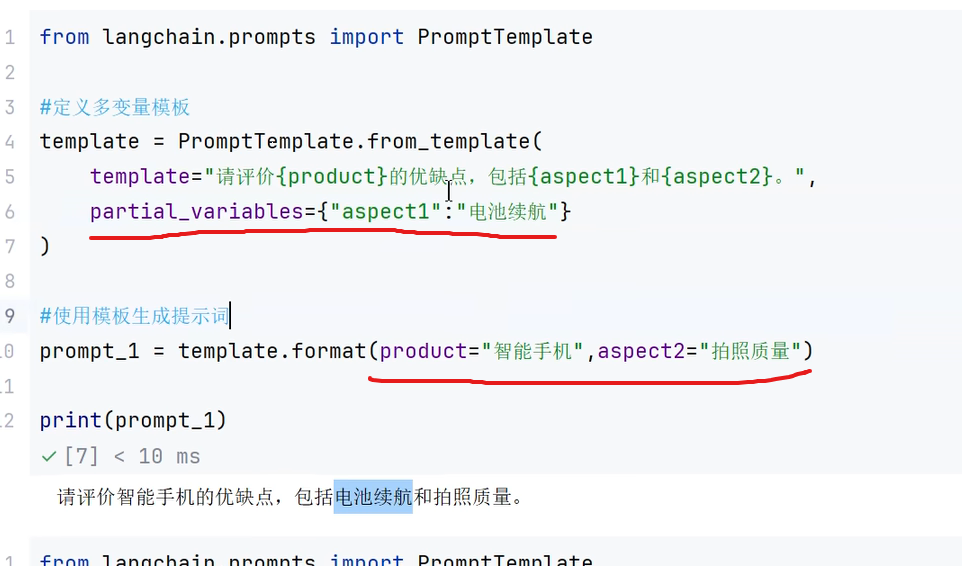
prompttemplate的构造方法
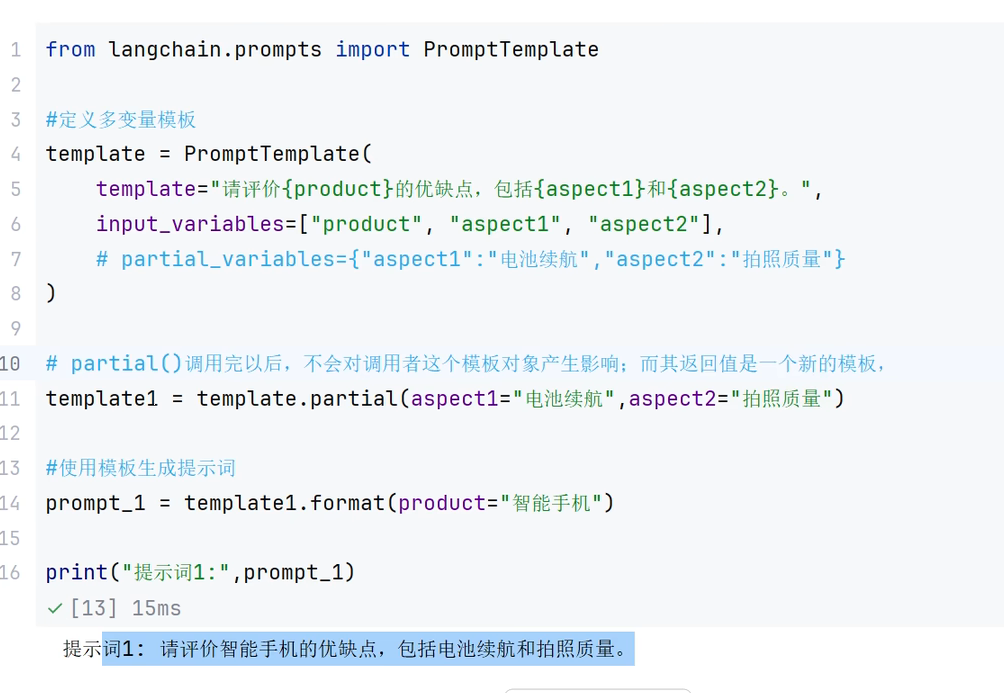
2.2调用方法partical()
3.给变量赋值的两种方式
foramt()和invoke()
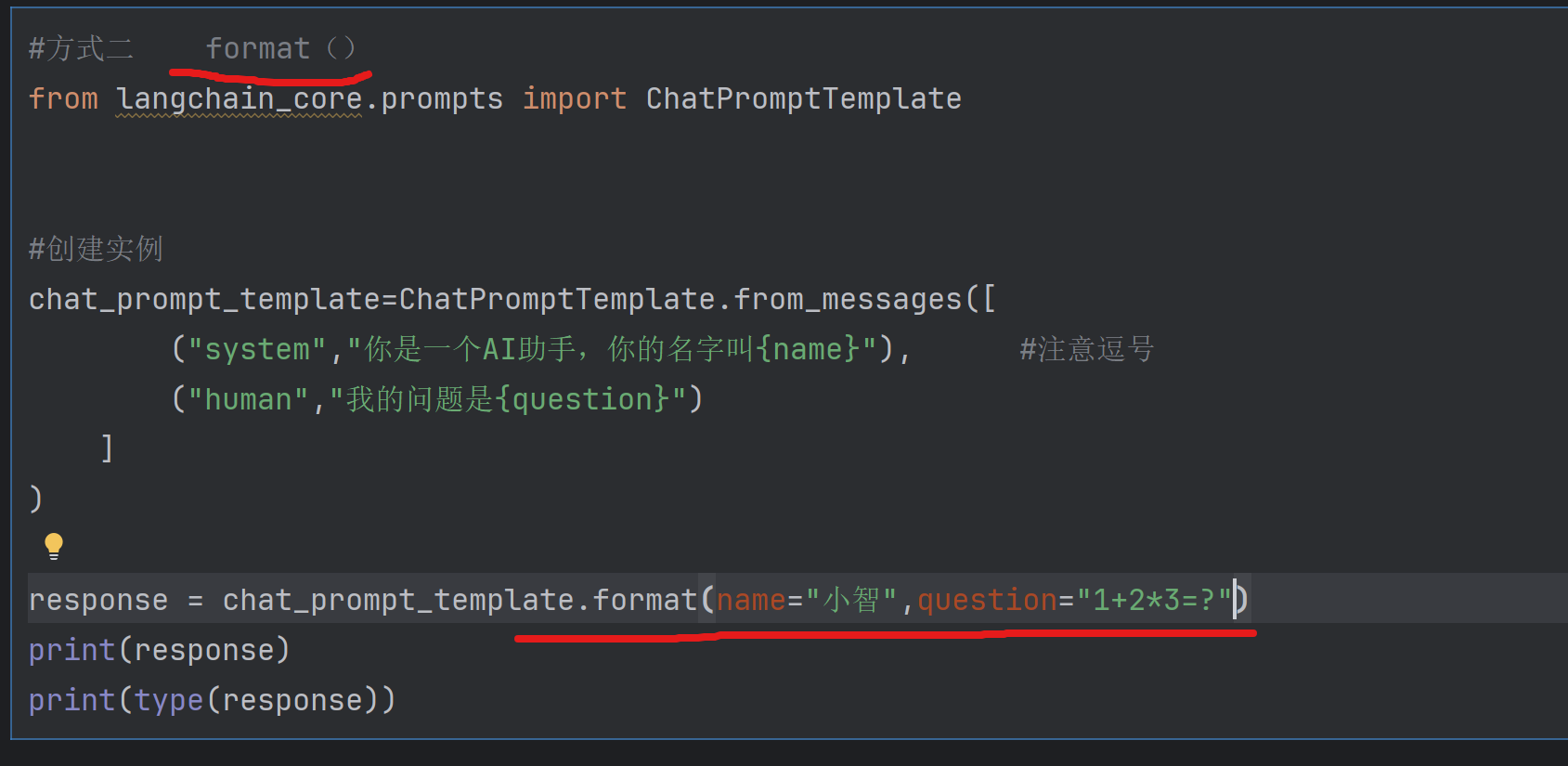
format(): 参数部分:给变量赋值 返回值:str类型
invoke(): 参数部分: 使用的是字典 返回值:PromoptValue类型
4.具体使用Chatprompttemplate

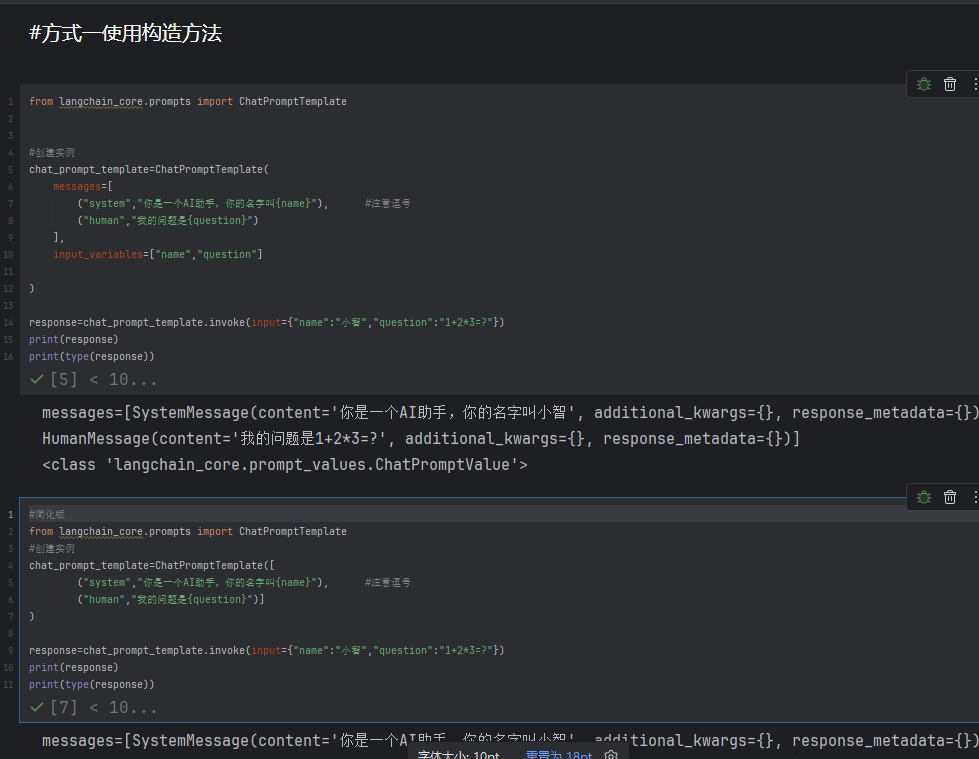
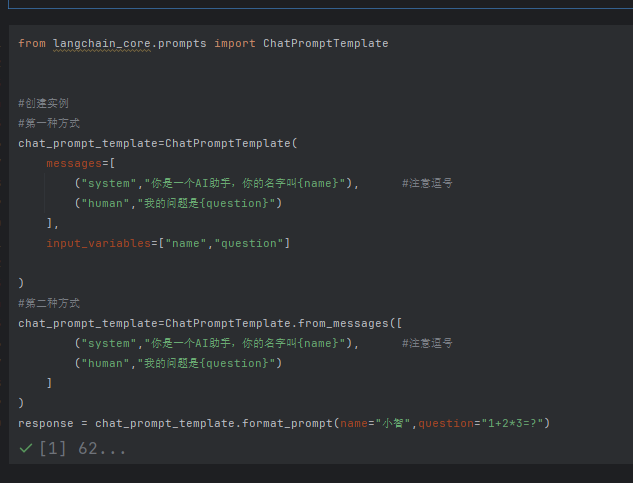
4.1实例化的方式
方式一使用构造方法
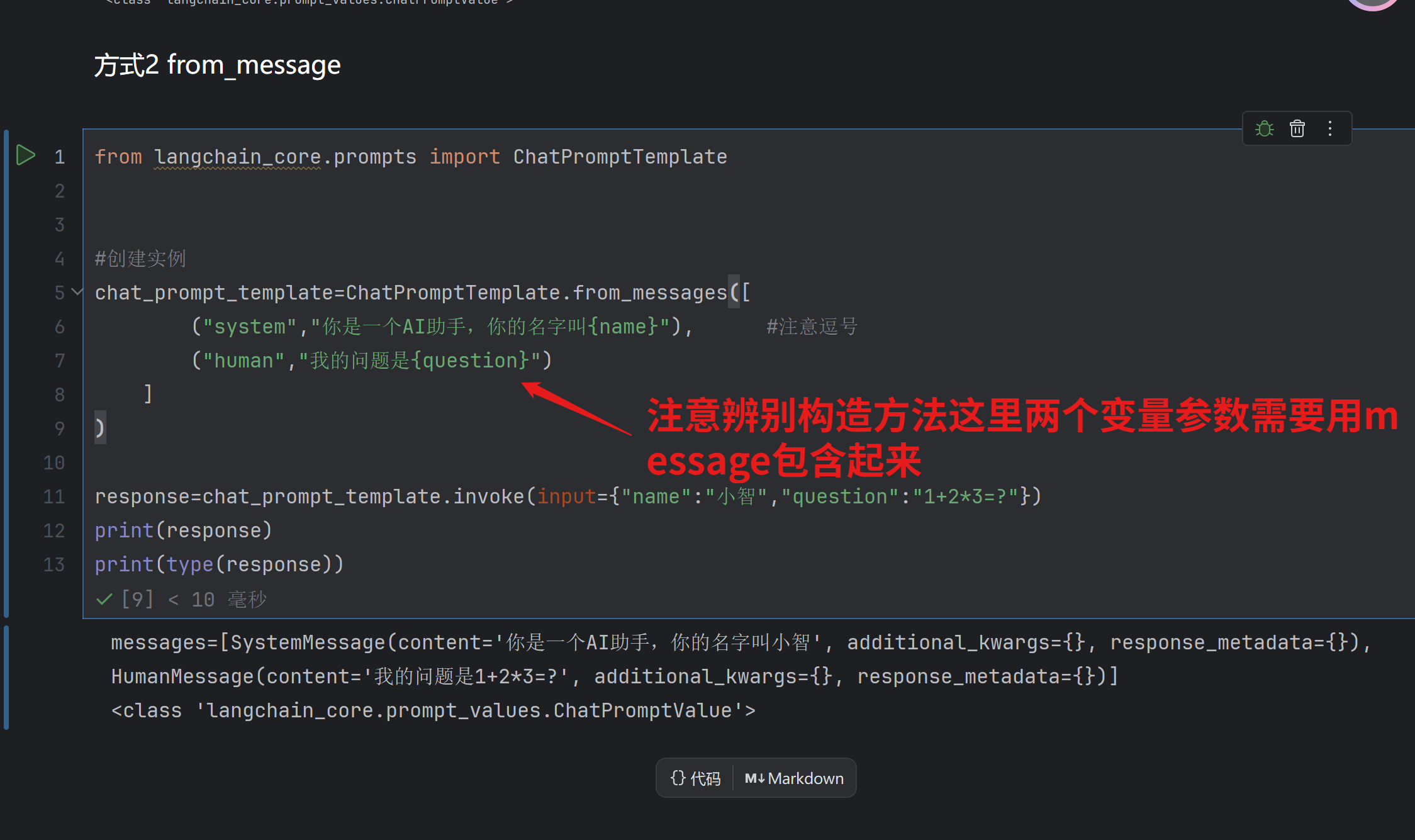
方式2 from_message 把方法一中的message提到括号外面了
4.2调用提示词模板的几种方法
方式一 invoke():传入字典,返回ChatPrpmptValue
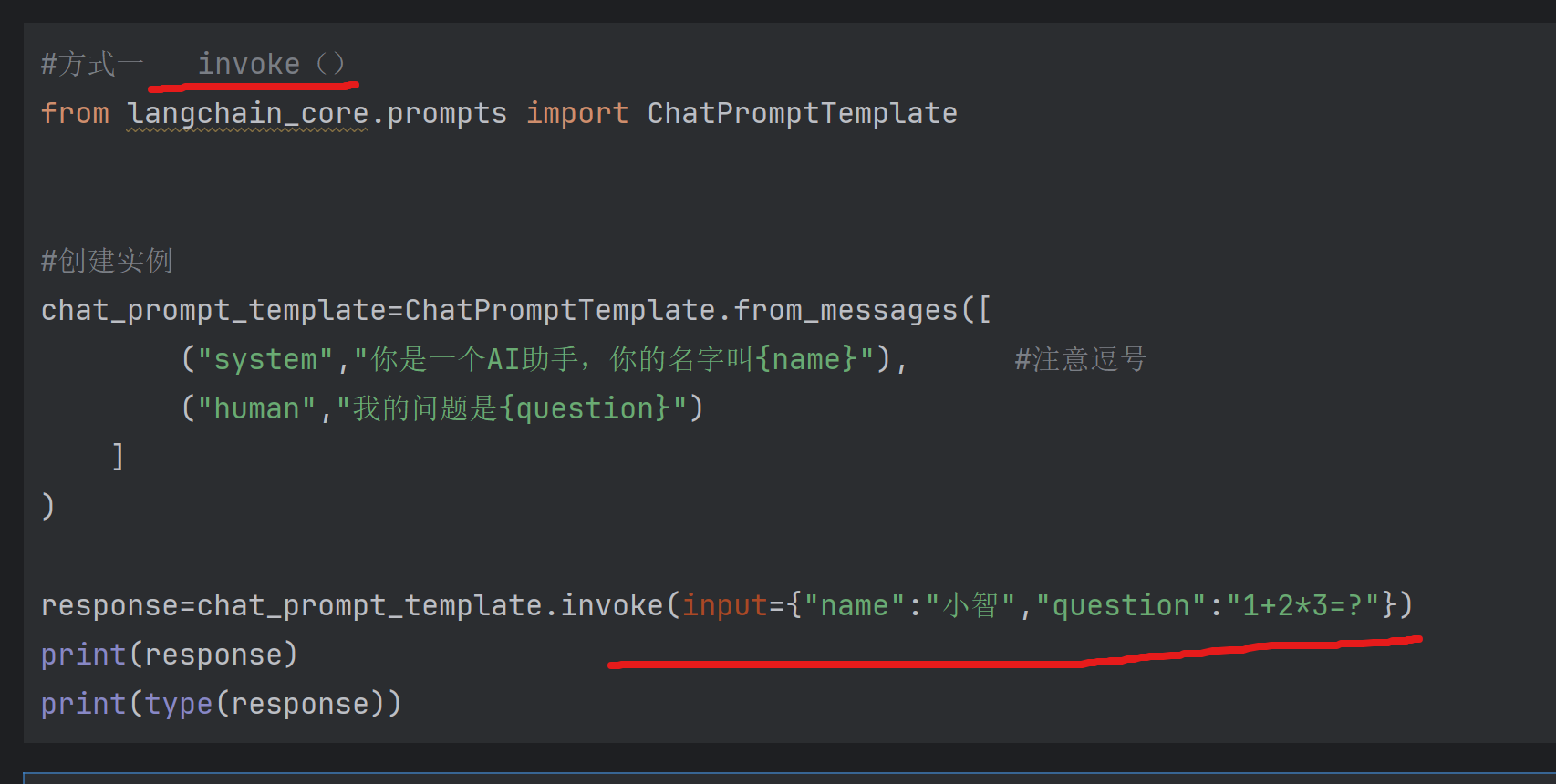
方式二 format() 传入变量值,返回str
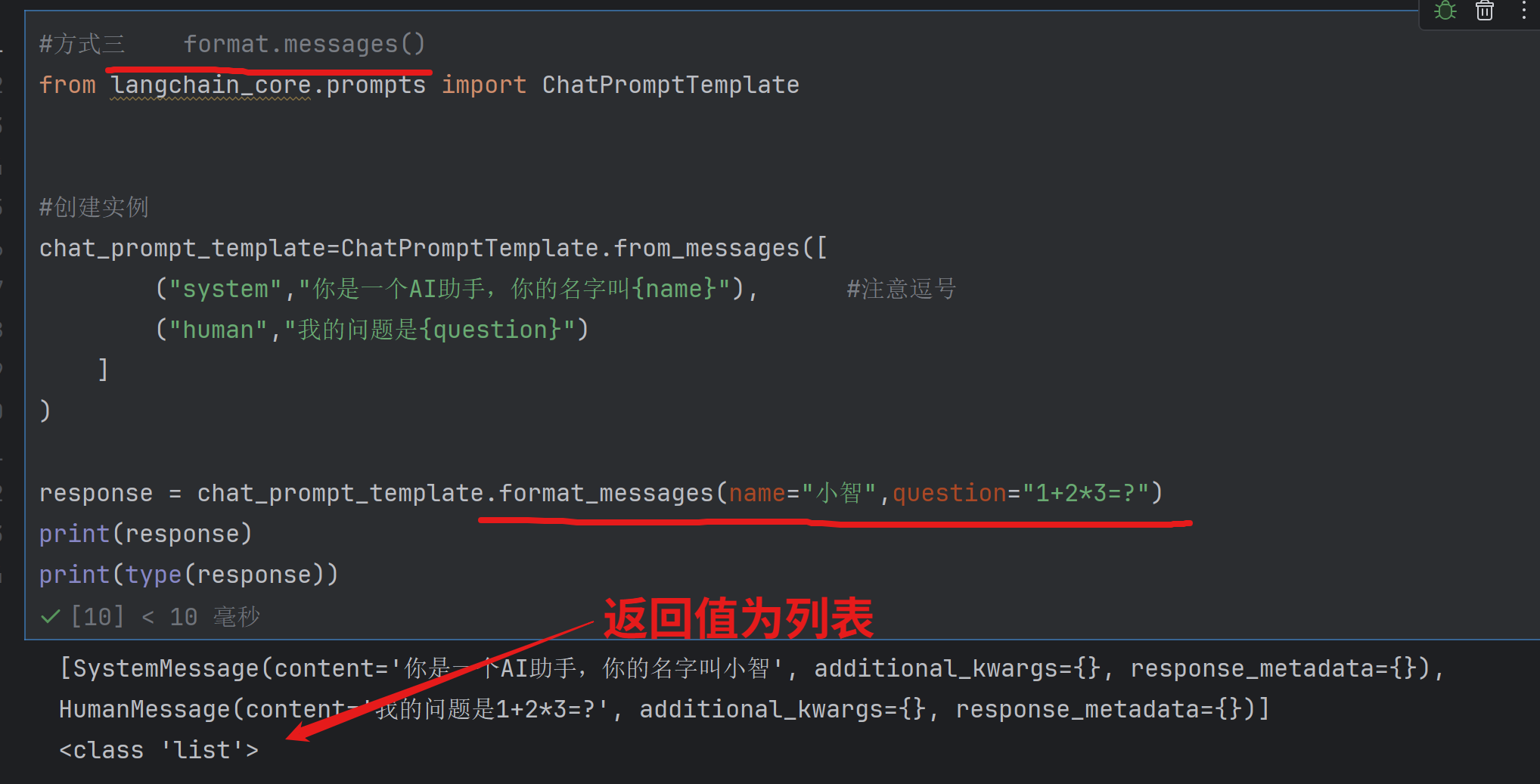
方式三 format_message()传入变量值,返回消息构成的list
方式四 format_prompt() 传入变量值,返回ChatPrpmptValue
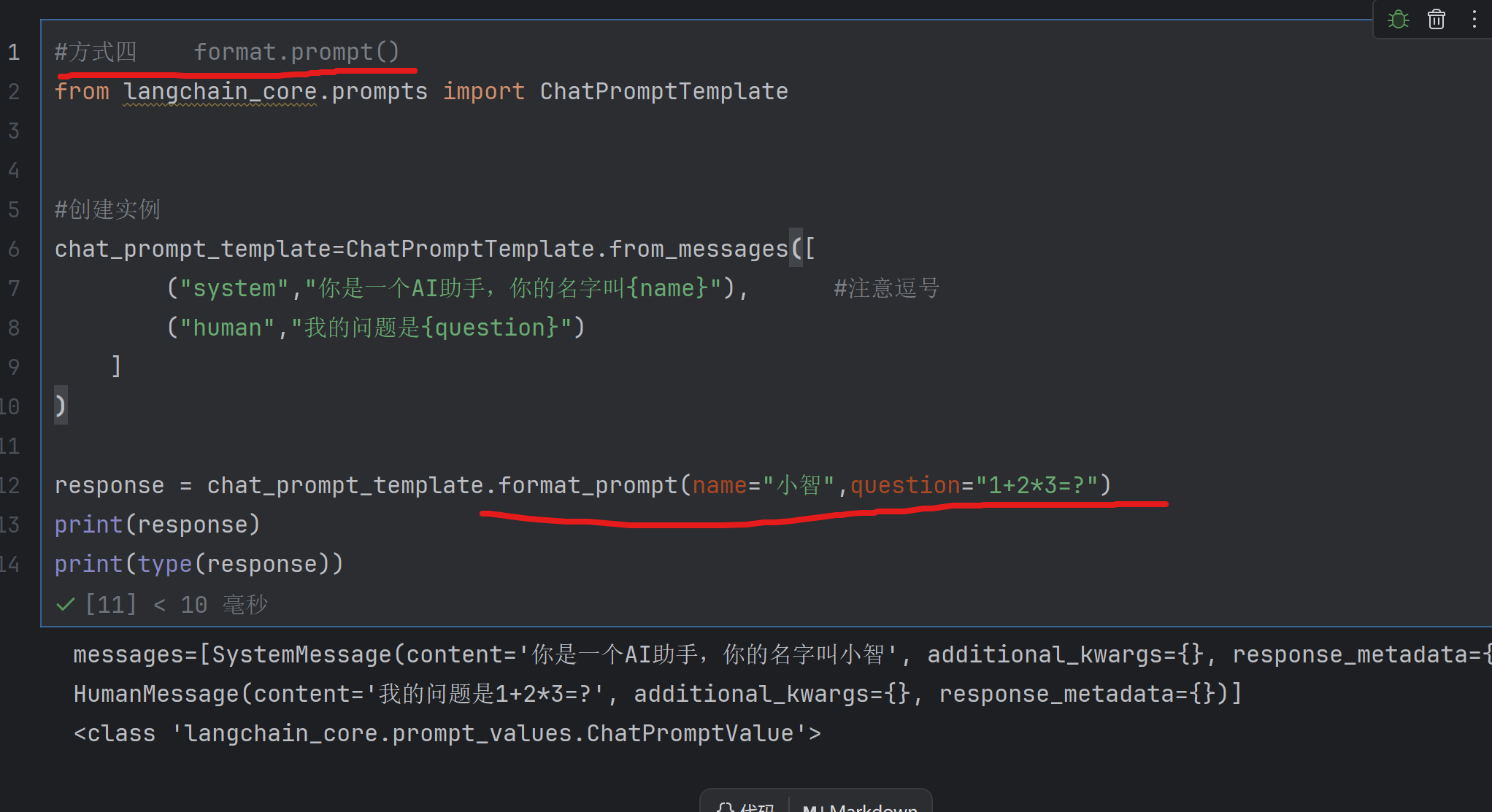
可以使用
response_messages = response.to_messages()对ChatPrpmptValue转换为list
response_to_string = response.to_string()对ChatPrpmptValue转换为str
4.3更丰富的实体化参数类型
实体化参数就是 图中框选部分需要填入的值
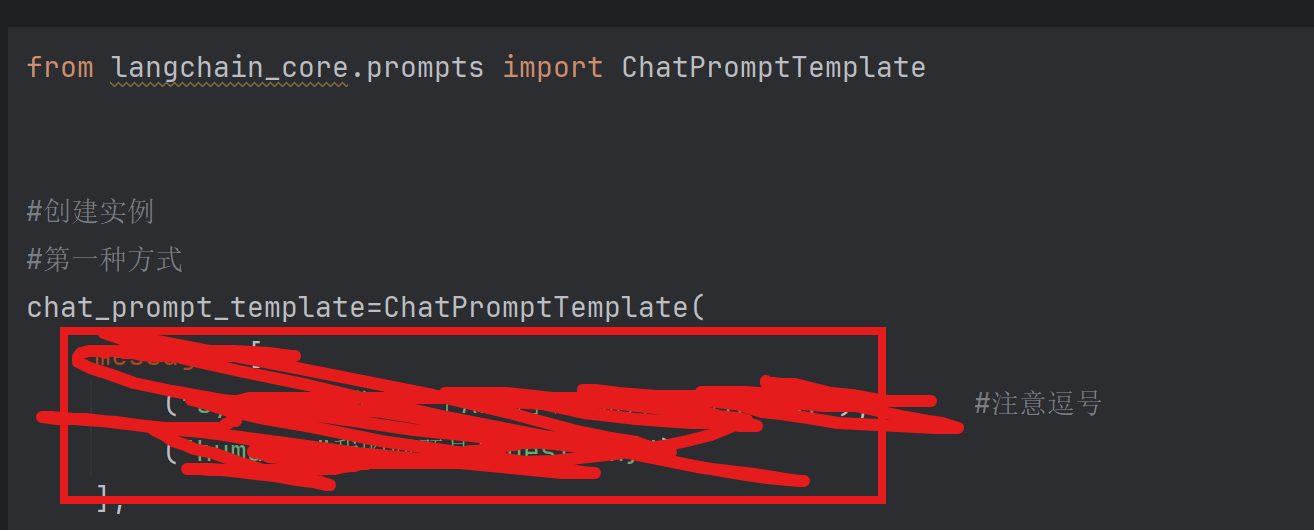
对与4.1本质:不管使用构造方法、还是使用from_message()来创建ChatPromptTemplate的实例,本质上来讲
传入的都是消息构成的列表。
从调用上来讲,我们看到,不管使用构造方法,还是使用from_message(),message参数的类型都是列表,但列表的元素的类型是多样的。可以是:
字符串类型、字典类型、消息类型、元组构成的列表、提示词模板类型、消息提示词模板类型
举例1 元组构成的列表
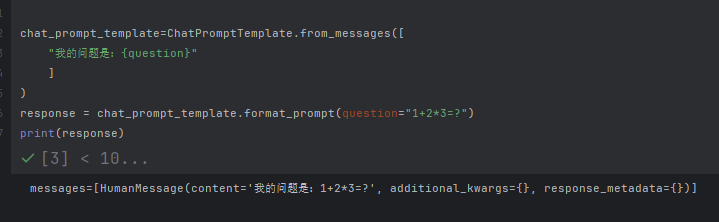
举例2 字符串类型
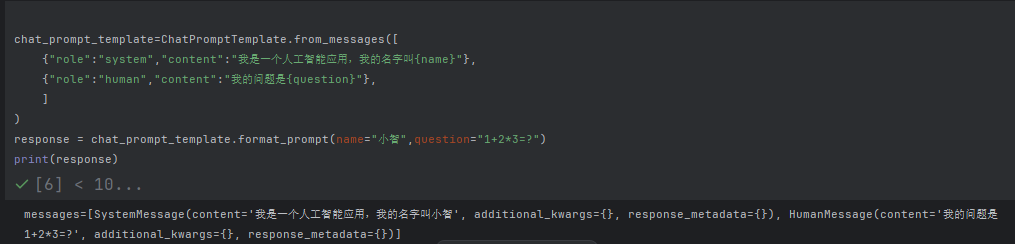
举例3 字典类型
举例4 消息类型
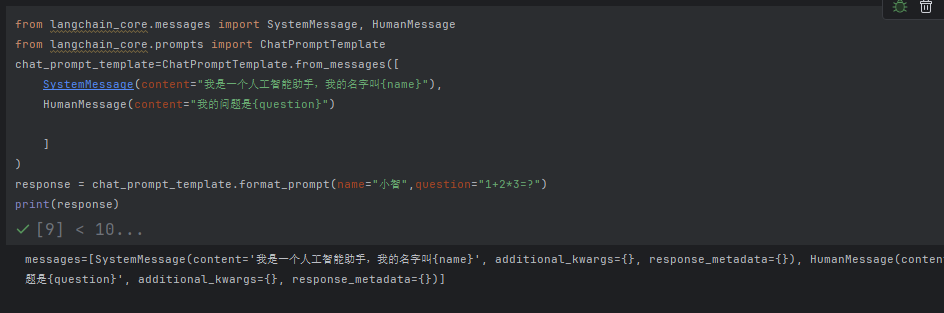 举例5 Chat提示词模板类型
举例5 Chat提示词模板类型
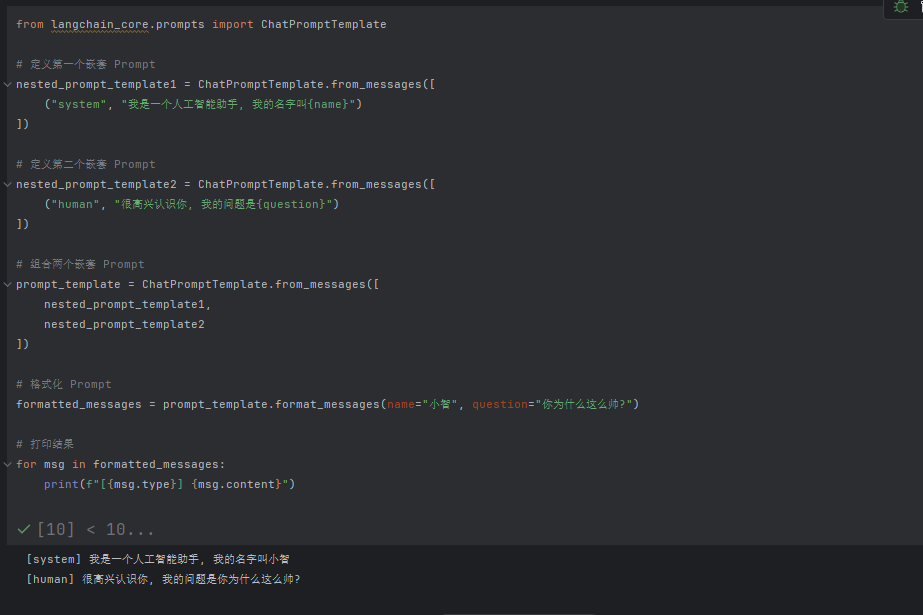
4.4调用大模型MessagePlaceholder
当ChatPromptTemplate模板中的消息类型和个数不确定时,我们就可以使用MessagePlaceholder
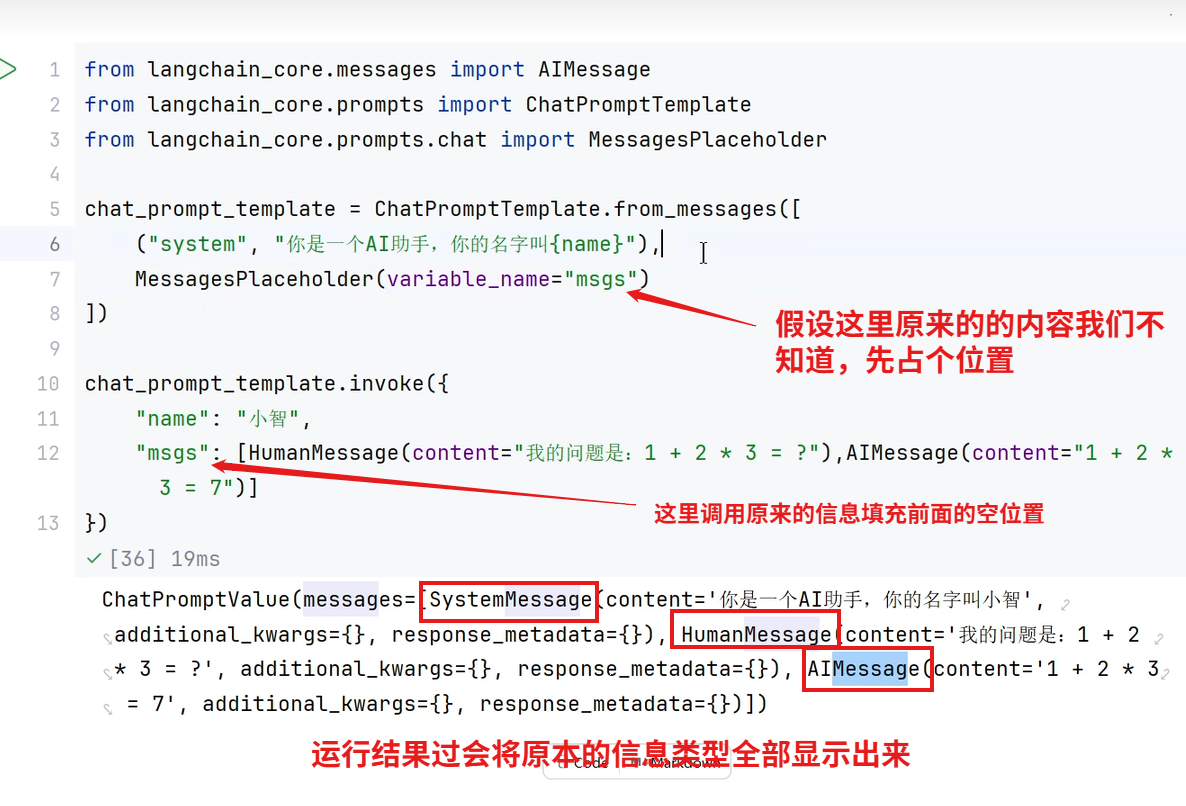
MessagePlaceholder 是 LangChain 中用于 动态插入聊天消息 的占位工具,通常用在 ChatPromptTemplate 中。它的核心作用是 预先留空,后续再填充具体的消息内容,类似于 Python 字符串格式化中的 {} 占位符,但专门针对多轮对话场景设计。
填充的大多都是历史对话信息
注意:
- 传入
MessagesPlaceholder的数据必须是 消息对象的列表(如HumanMessage、AIMessage)。 - 如果不需要动态消息,直接用
("role", "content")元组更简单。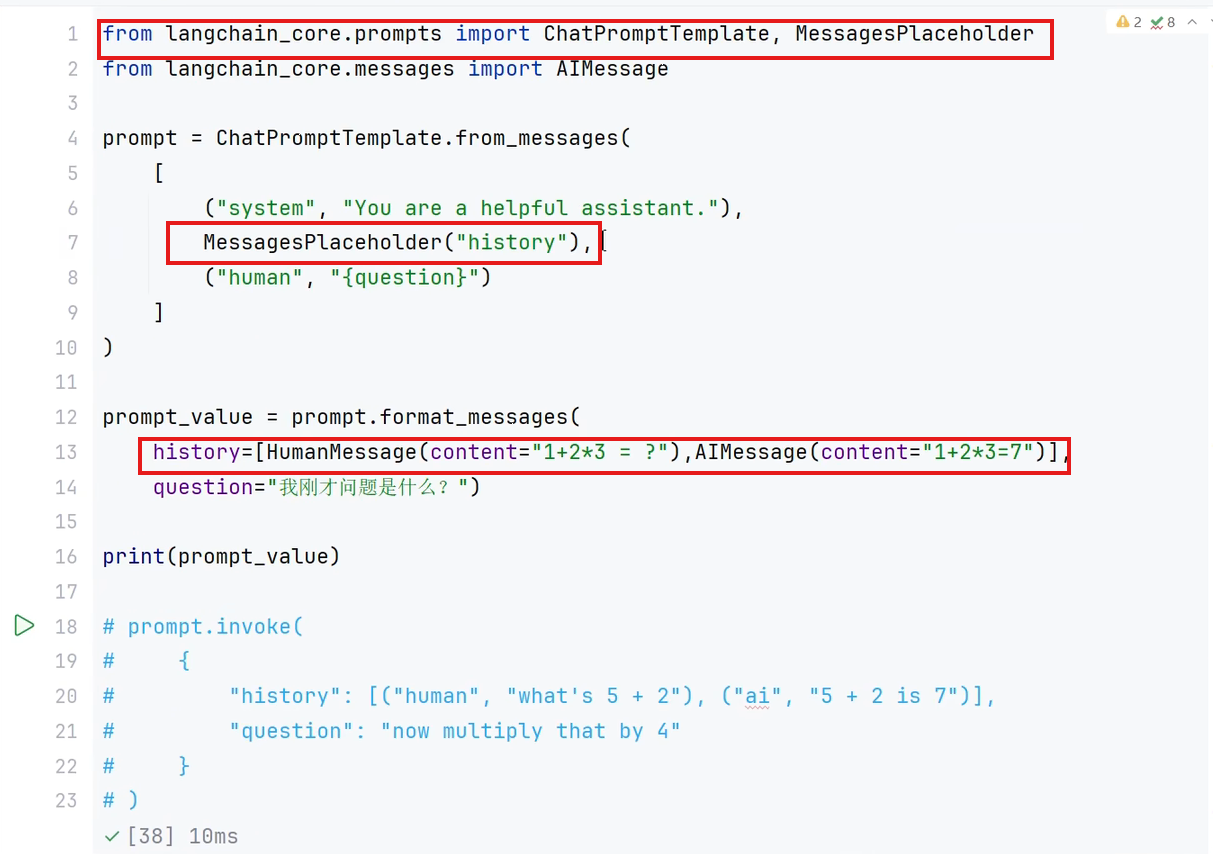
由图可以看出调用调用大模型MessagePlaceholder就相当于在前面占了个位置后面再把内容塞到位置里
5.FewShotPromptTemplate
少量样本提示词模板,给出少量的案例让大模型去学习然后解决类似的问题
- FewShot教法:先举几个例子:
- 例子1(狗):问“这是什么?”,答“这是狗,它会汪汪叫”。
- 例子2(猫):问“这是什么?”,答“这是猫,它会喵喵叫”。
—— 然后 再问孩子:“那鸭子呢?”(让孩子通过之前的例子自己推理)。
FewShotPromptTemplate 就是干这个的:通过给大模型看几个例子(few-shot),让它学会你的任务套路,再回答新问题。
示例
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
# 1. **例子列表**(教模型的"例题集")
examples = [
{"问题": "2+2等于几?", "答案": "4"},
{"问题": "3的平方是多少?", "答案": "9"},
]
# 2. **单个例子的模板**(怎样格式化每个例子?)
example_template = PromptTemplate.from_template(
"问题:{问题}\n答案:{答案}"
)
# 3. **最终提示词模板**(例子+新问题如何组合?)
prompt_template = FewShotPromptTemplate(
examples=examples, # 例题集
example_prompt=example_template, # 单个例子的格式
prefix="请根据以下例子回答问题", # 开头说明
suffix="问题:{输入}", # 最后接用户的新问题
input_variables=["输入"], # 用户问题的变量名
)
# 4. **使用**(问一个新问题)
result = prompt_template.format(输入="5+5等于几?")
print(result)
1.FewShotPromptTemplate:与PromptTemplate一起使用
2.FewShotChatMessagePromptTemplate:与ChatPromptTemplate一起使用
3.example selectors(示例选择器)
注意:1和2是将全部的案例喂给大模型让他去学习,3是选择部分案例给大模型
1.FewShotPromptTemplate
实例
第一步引用FewShotPromptTemplate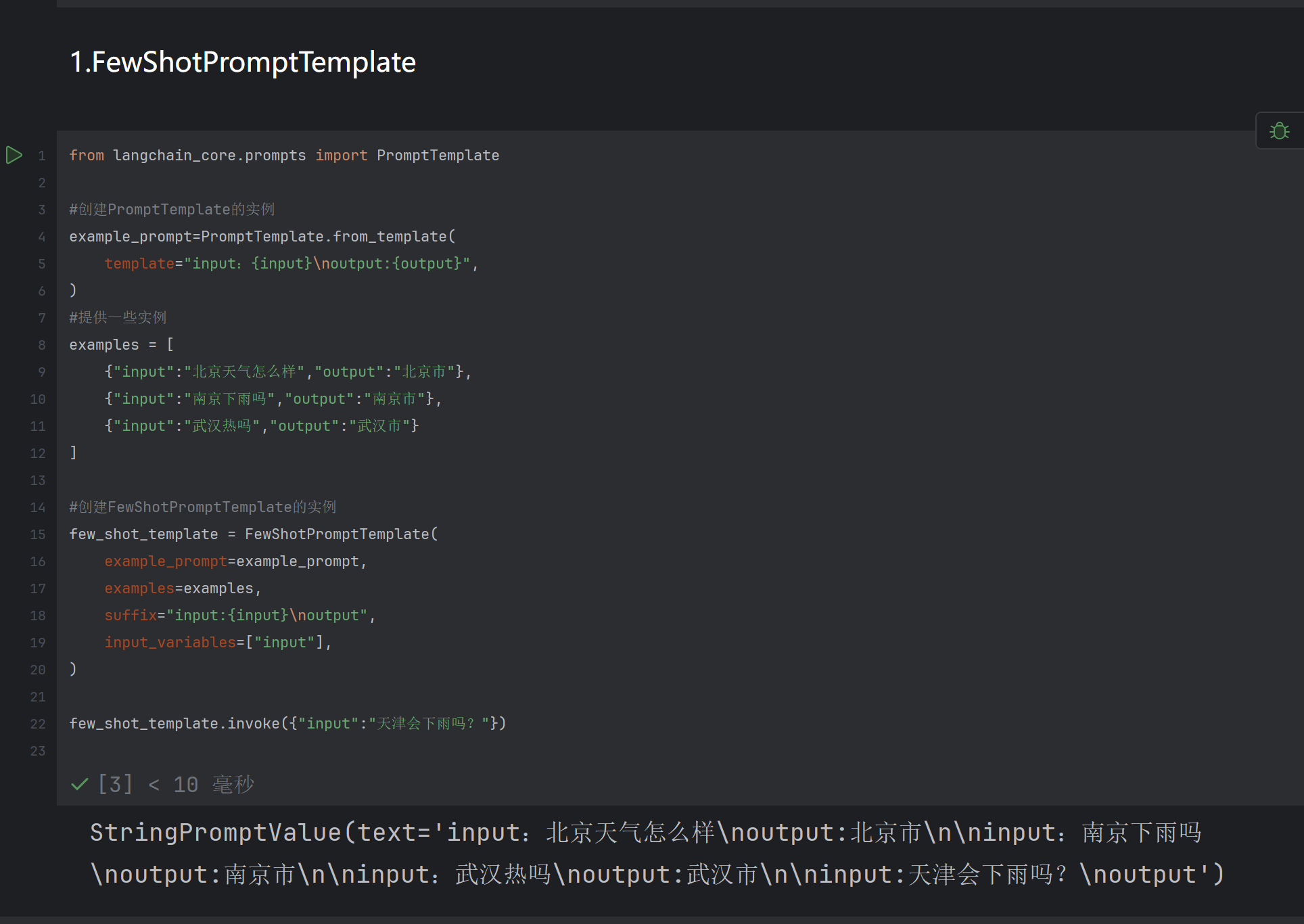
第二步调用大模型然后用大模型加载前面引用的FewShotPromptTemplate变量
2.FewShotChatMessagePromptTemplate
from langchain_core.prompts import (
ChatPromptTemplate,
FewShotChatMessagePromptTemplate,
PromptTemplate,
)
from langchain_openai import ChatOpenAI
import os
import dotenv
# --- 1. 定义示例和消息模板 ---
examples = [
{"input": "2+2", "output": "4", "description": "加法"},
{"input": "5-2", "output": "3", "description": "减法"},
]
# 定义 **每条示例** 的格式(Human-AI 对话式)
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "算式:{input}"),
("ai", "答案为 {output}(这是{description}运算)"),
]
)
# --- 2. 构建 Few-Shot Chat Prompt ---
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
# --- 3. 组合成最终 Prompt(加上指引) ---
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一位数学专家,请根据以下示例回答问题。"),
few_shot_prompt,
("human", "请计算:{input}"),
]
)
# --- 4. 调用模型(保持原逻辑,只给 input,让模型计算 output) ---
dotenv.load_dotenv()
chat_model = ChatOpenAI(model_name="gpt-3.5-turbo")
# 测试新问题
question = "2*5"
prompt_messages = final_prompt.format_messages(input=question)
# 打印生成的 Prompt(方便调试)
print("\n===== 生成的提示词 =====\n")
for msg in prompt_messages:
print(f"{msg.type}: {msg.content}")
# 调用模型
response = chat_model.invoke(prompt_messages)
print(f"\n模型答案:{response.content}")
3.example selectors(示例选择器)

主要就是构建提示词模板的不同,第二种方式的生成结果是以对话的形式呈现的
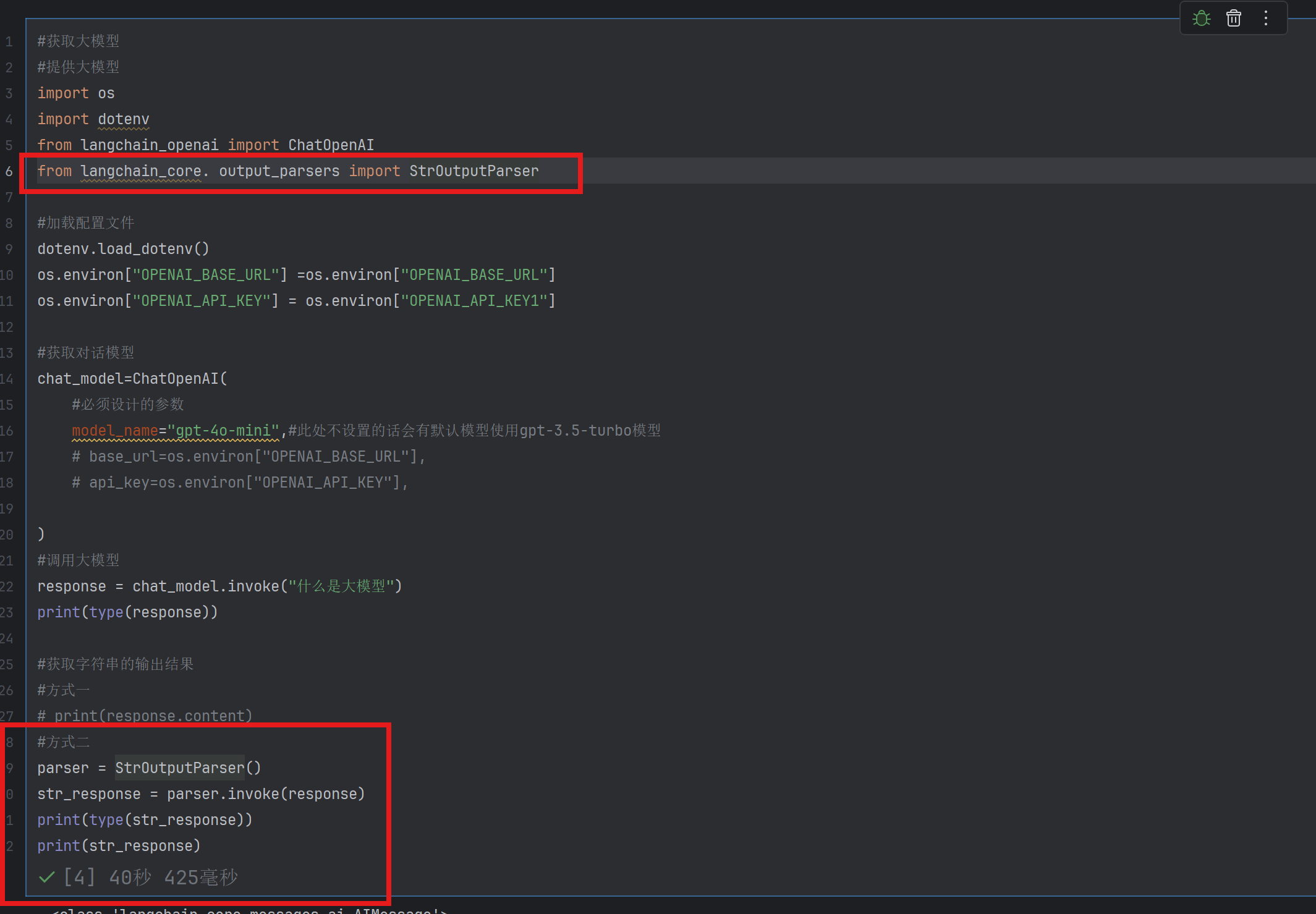
6.输出解析器
将大模型输出的str转换成其他格式

1)字符串解析器
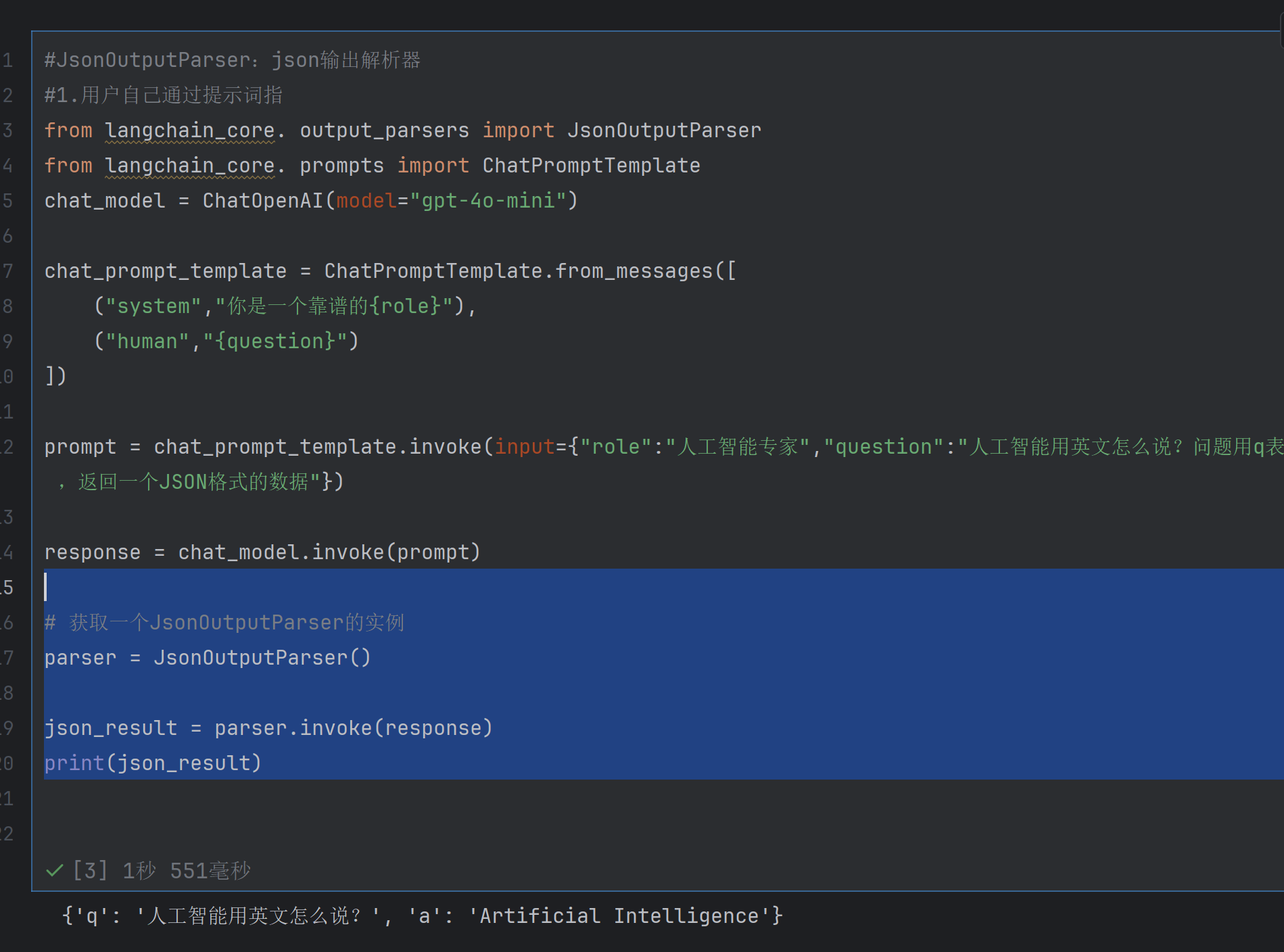
2)json解释器
最后三行
-
parser = JsonOutputParser():创建一个JsonOutputParser类的实例(解析器对象),用于将文本形式的 JSON 字符串转换为 Python 可处理的字典对象。 -
json_result = parser.invoke(response):调用解析器的invoke方法,传入模型的响应结果response(其中包含文本形式的 JSON 内容),解析器会将其转换为 Python 字典。 -
print(json_result):打印解析后的字典对象,方便查看最终的结构化数据(包含 "q" 和 "a" 键值对)。
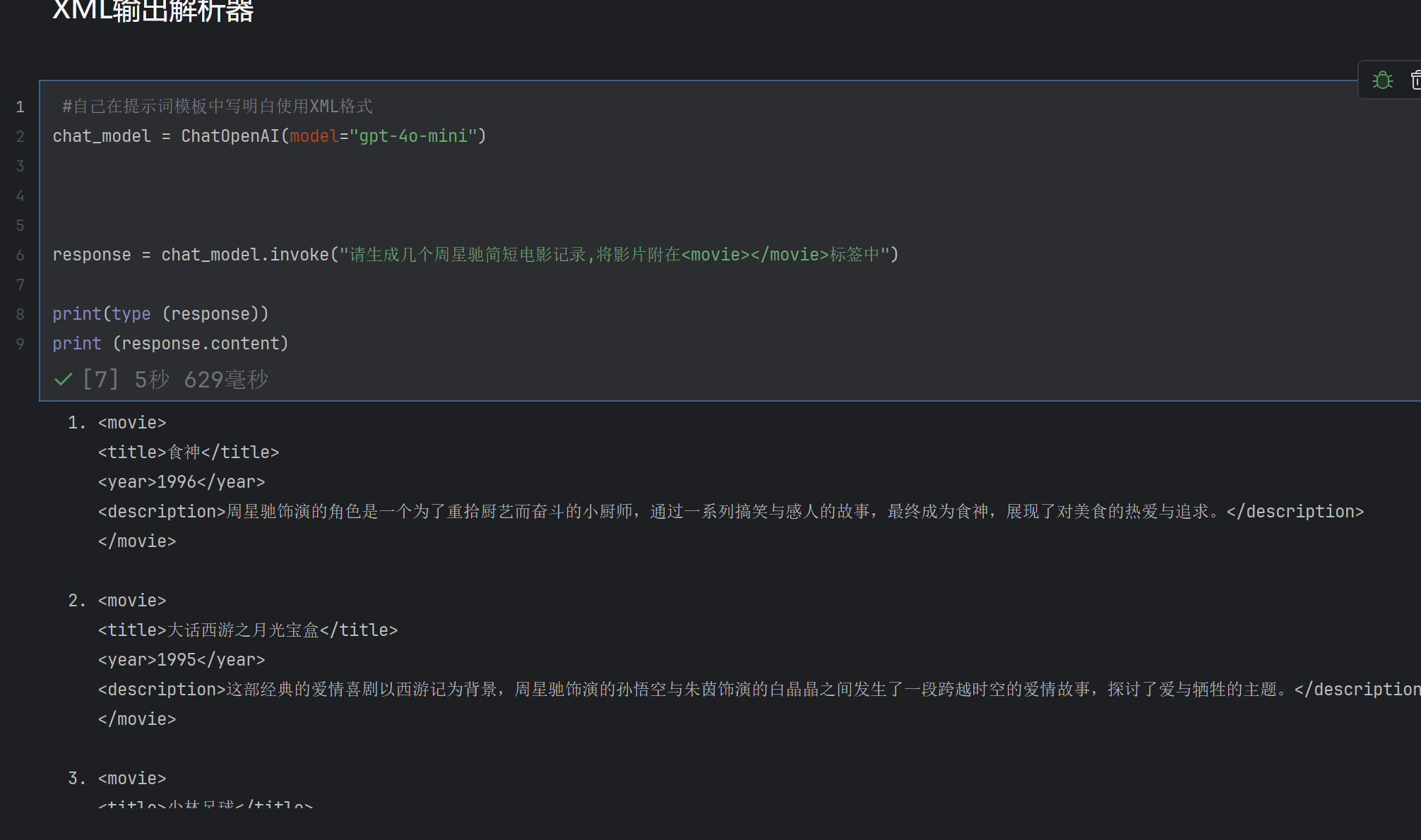
3)XML解析器
xml的典型特点有< >两个符号
方式一:
1.用户自己通过提示词指
7.langchain调用本地大模型
部署本地Ollama大模型框架,Ollama是一个大模型容器
8.langchain之使用chain
chain的理解
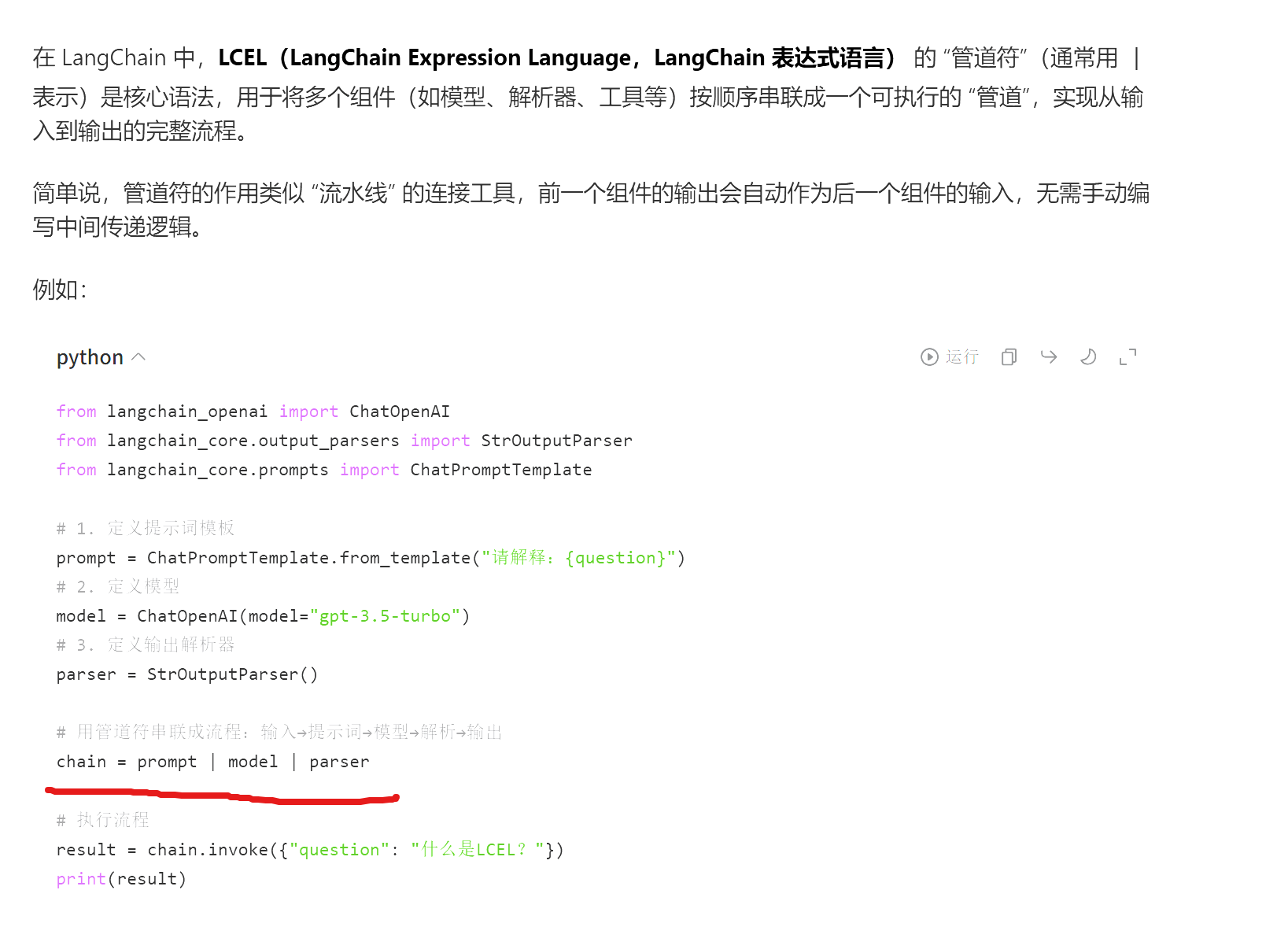
8.1LangChain表达式(LCEL)
LLMChain是最基础的chain这个链需要包括一个提示词模板一个语言模型
特点:适合单次应答,默认没有记忆
1. Runnable
是一种 统一的抽象接口,用来描述“可以被执行、产生输出的对象”。它把 模型调用、数据处理、链路组合 等操作抽象成 可复用、可组合 的组件,从而让构建复杂工作流变得像搭积木一样简单。在顺序连接中( | )每一个节点都是一个runnable。Runnable就是一个可以调用的模块,每一个模块进行runnable接入后都可以调用
2. 组合链:
串型:
r1 = 组件(函数/模块)1
r2 = 组件(模块/函数)2
chain =r1 | r2 #将r1的结果给r2,两个串起来
并行:
chain = RunnableParallel(r1=r1,r2=r2)
print(chain.invoke(input,config={'max_concurrency': }))
#input代表r1中输入的数量,config代表同时最大运行量
同理也可以把两个chain串起来
print((chain | chain2).invoke(2))
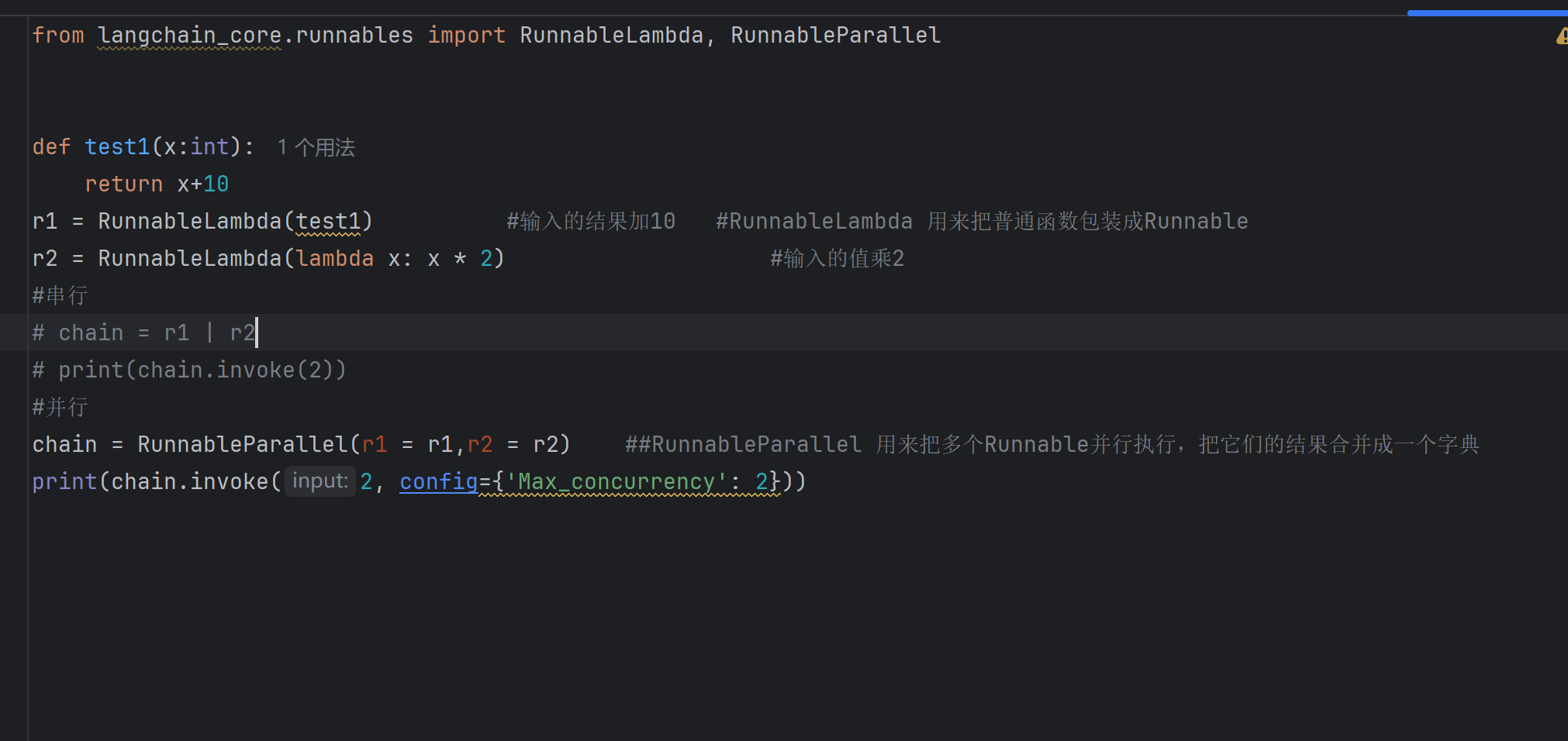
3.合并输入,并处理中间数据
#RunnableLambda 用来把普通函数包装成Runnable
#RunnableParallel 用来把多个Runnable并行执行,把它们的结果合并成一个字典
#RunnablePassthrough 把 前面的值 原封不动地传递 给后面的节点,相当于一个占位符
runnablepassthorugh可以在后面添加新的节点或者删除旧的节点,
4.后备选项
:在紧急请情况下使用到替代方案

优先执行r1,如果报错就执行r2,r2属于r1后备选项
5.根据条件,动态的构建链
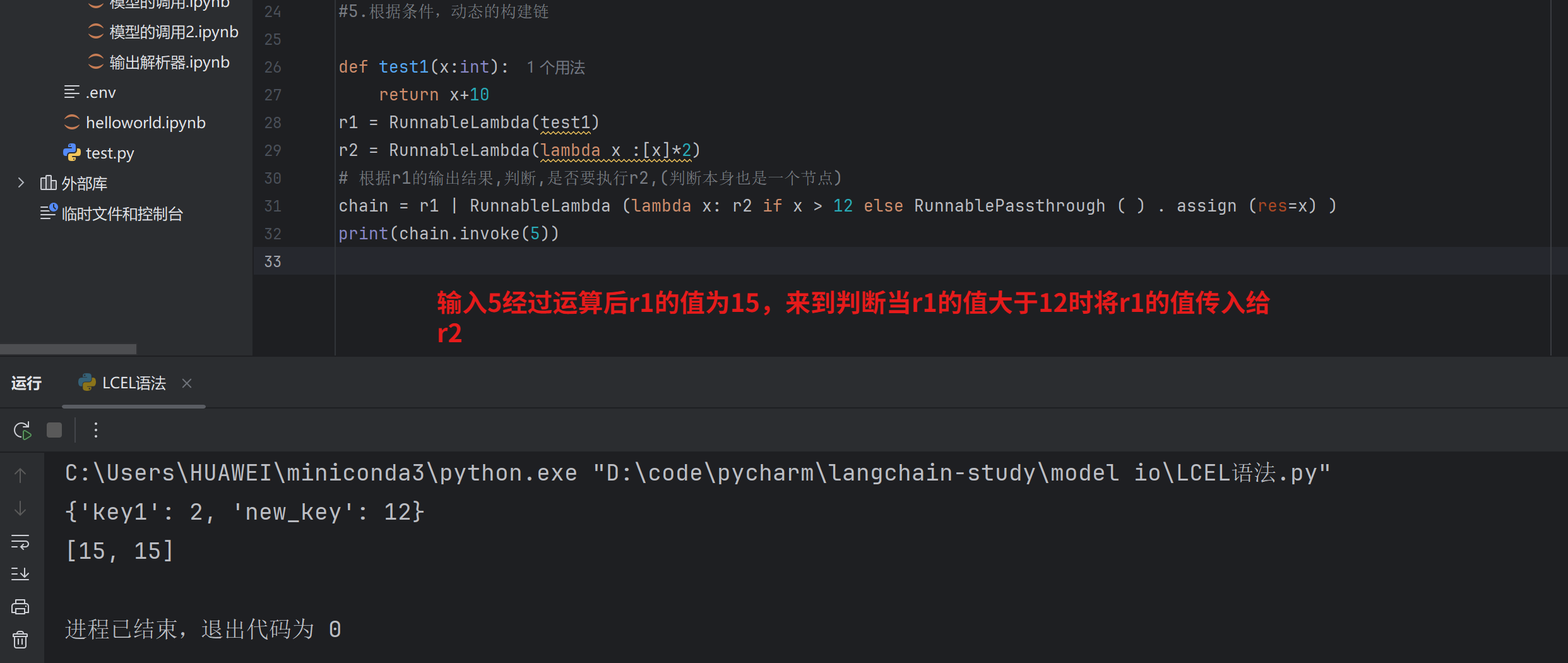
LCEL动态案例
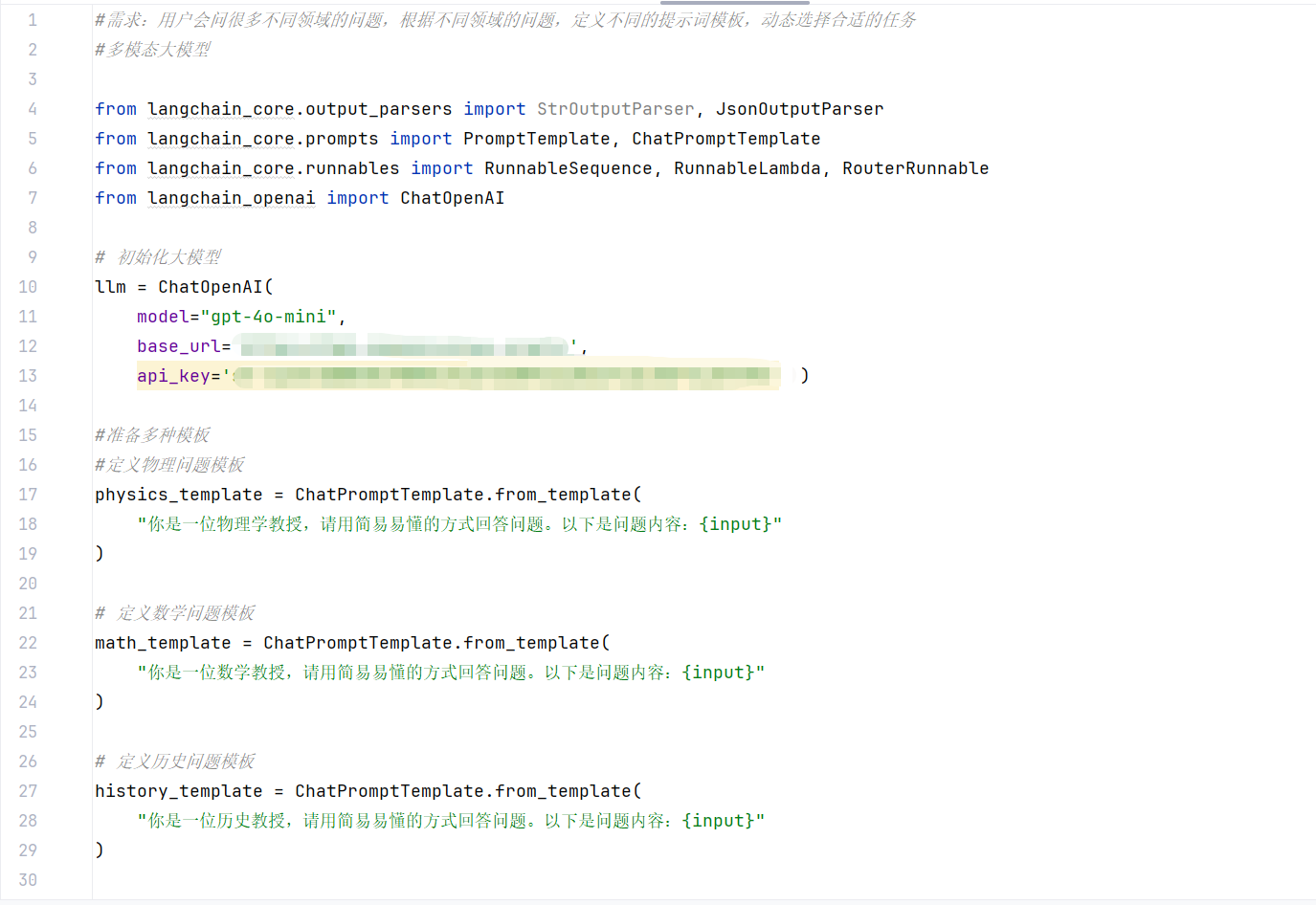

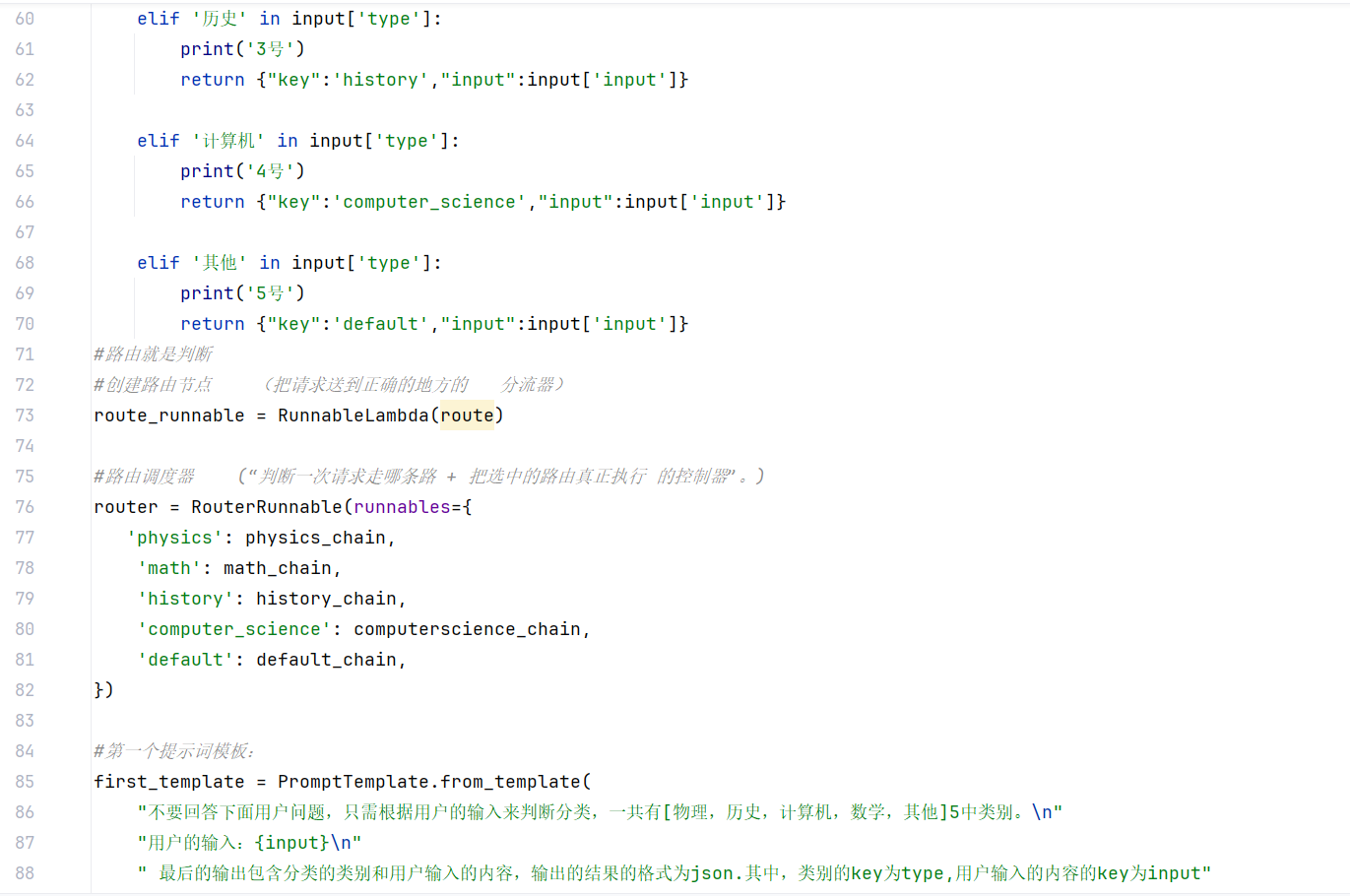
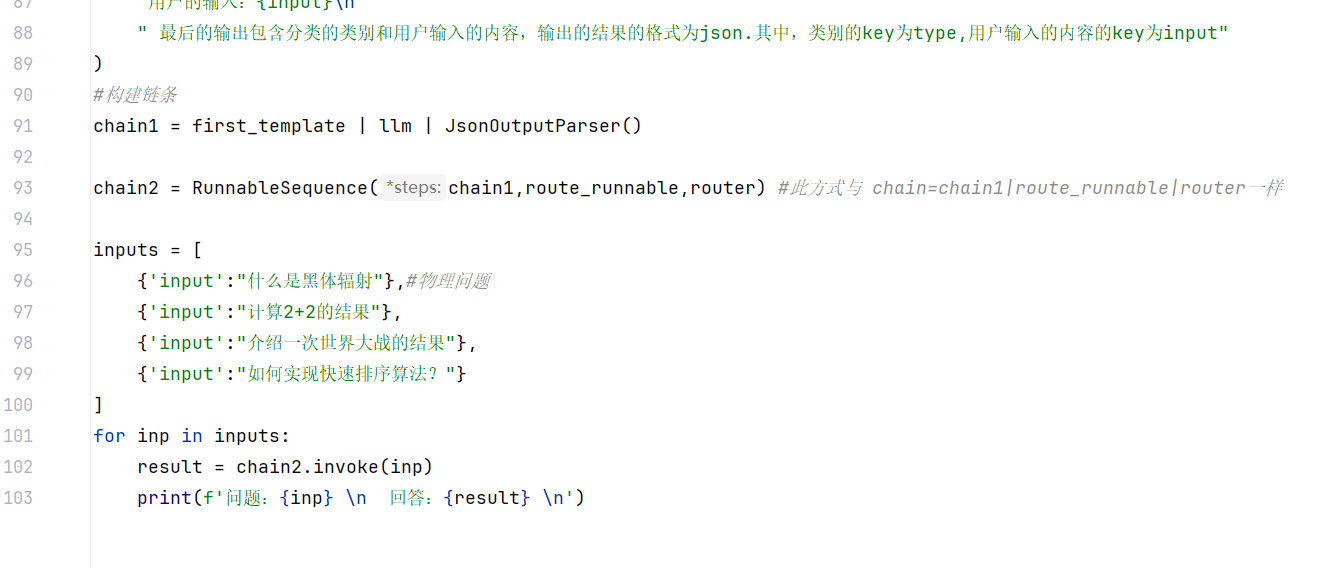
此案例将判断用户输入的问题 ,根据不同领域的问题,定义不同的提示词模板,动态选择合适的任务
需要用到路由,路由简单来说就是判断
创建路由节点==>把请求送到正确的地方 相当于一个分流器
路由调度器==>判断一次请求走哪条路+把选中的路去执行 相当于一个控制器
9.Memory
大模型的记忆模块,(大模型本身没有记忆)简单来说就是在下一次请求时将前面的历史信息自动传给大模型,让大模型带着新的问题和历史信息重新输出结果
倘若不用Memory模块想要实现记忆功能则需要创建一个循环,不断地将用户信息和大模型输出结果放到提示词模板中
Memory模块的设计思路
方式一 保留一个消息列表,及不使用Memory记忆模块
方式二 只返回最近交互的K条消息
方式三 返回过去k条消息的简洁摘要
方式四 从储存的消息中提取实体,并且进返回有关当前运行中引用的实体的信息
储存记忆的几种库
1.ChatMessageHistory(inmemroychatmessage)
导入库from langchain.memory import ChatMessageHistory
只存储消息不涉及消息的格式化
用history.add_user_message("你好")
用history.add_ai_message("很高兴认识你")
两种格式手动添加用户和大模型的的历史对话信息
2.ConversationBufferMemory
基础的对话记忆组件,用于按照原始顺序储存完整的对话历史,使用对话轮次少的场景
由于版本和兼容问题conversationbuffermemory包导入不进去这里用创建自定义conversationbuffermemory
实例
第一步自定义conversationbuffermemory
# 完全不依赖 LangChain 的导入,自己实现记忆功能
class MyConversationBufferMemory:
"""自定义的对话记忆实现"""
def __init__(self, memory_key="history", return_messages=False):
self.memory_key = memory_key
self.return_messages = return_messages
self.chat_history = []
def save_context(self, inputs, outputs):
"""保存对话上下文"""
user_input = inputs.get("input", "")
assistant_output = outputs.get("text", outputs.get("output", ""))
if user_input:
self.chat_history.append(f"User: {user_input}")
if assistant_output:
self.chat_history.append(f"Assistant: {assistant_output}")
def load_memory_variables(self, inputs):
"""加载记忆变量"""
if self.return_messages:
return {self.memory_key: self.chat_history}
else:
# 保留最近6条消息(3轮对话)
recent_history = self.chat_history[-6:] if len(self.chat_history) > 6 else self.chat_history
return {self.memory_key: "\n".join(recent_history)}
def clear(self):
"""清空记忆"""
self.chat_history = []
# 使用自定义实现
ConversationBufferMemory = MyConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
print("✅ 自定义 ConversationBufferMemory 创建成功!")第二步使用自定义conversationbuffermemory结合其他模块一起使用
# 1. 使用自定义的 ConversationBufferMemory(你已经成功的部分)
class MyConversationBufferMemory:
"""自定义的对话记忆实现"""
def __init__(self, memory_key="history", return_messages=False):
self.memory_key = memory_key
self.return_messages = return_messages
self.chat_history = []
def save_context(self, inputs, outputs):
"""保存对话上下文"""
user_input = inputs.get("input", "")
assistant_output = outputs.get("text", outputs.get("output", ""))
if user_input:
self.chat_history.append(f"User: {user_input}")
if assistant_output:
self.chat_history.append(f"Assistant: {assistant_output}")
def load_memory_variables(self, inputs):
"""加载记忆变量"""
if self.return_messages:
return {self.memory_key: self.chat_history}
else:
# 保留最近6条消息(3轮对话)
recent_history = self.chat_history[-6:] if len(self.chat_history) > 6 else self.chat_history
return {self.memory_key: "\n".join(recent_history)}
def clear(self):
"""清空记忆"""
self.chat_history = []
# 使用自定义实现
ConversationBufferMemory = MyConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
print("✅ 自定义 ConversationBufferMemory 创建成功!")
# 2. 导入其他必要的组件
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
print("✅ 其他组件导入成功")
# 3. 创建 LLM 实例(需要设置 API Key)
import os
# 如果你有 OpenAI API Key,取消注释下面这行:
# os.environ["OPENAI_API_KEY"] = "你的-api-key-here"
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.7)
# 4. 创建 Prompt 模板
prompt = PromptTemplate(
input_variables=["chat_history", "input"],
template="""对话历史:
{chat_history}
用户:{input}
助手:"""
)
print("✅ Prompt 模板创建成功")
# 5. 创建对话链(使用我们的自定义记忆)
chain = LLMChain(
llm=llm,
prompt=prompt,
memory=memory,
verbose=True # 显示详细日志
)
print("✅ 对话链创建成功")
# 6. 测试多轮对话
print("\n" + "="*50)
print(">>> 第一轮对话:打招呼")
try:
result1 = chain.invoke({"input": "你好!"})
print("助手:", result1["text"])
# 手动保存上下文到我们的自定义记忆
memory.save_context({"input": "你好!"}, {"text": result1["text"]})
except Exception as e:
print("❌ 对话失败(可能是API Key未设置):", e)
# 使用模拟响应继续测试记忆功能
mock_response = "你好!我是AI助手。"
print("助手(模拟):", mock_response)
memory.save_context({"input": "你好!"}, {"text": mock_response})
print("\n>>> 第二轮对话:自我介绍")
try:
result2 = chain.invoke({"input": "请介绍一下你自己"})
print("助手:", result2["text"])
memory.save_context({"input": "请介绍一下你自己"}, {"text": result2["text"]})
except Exception as e:
mock_response = "我是AI助手,可以帮你回答问题。"
print("助手(模拟):", mock_response)
memory.save_context({"input": "请介绍一下你自己"}, {"text": mock_response})
print("\n>>> 第三轮对话:测试记忆功能")
try:
result3 = chain.invoke({"input": "我们刚才聊了什么?"})
print("助手:", result3["text"])
except Exception as e:
# 即使API调用失败,我们也可以查看记忆内容
mock_response = "让我看看我们的对话历史..."
print("助手(模拟):", mock_response)
# 7. 查看记忆内容(验证记忆是否工作)
print("\n" + "="*50)
print("=== 当前对话记忆内容 ===")
memory_vars = memory.load_memory_variables({})
print(memory_vars["chat_history"])
print("\n🎉 记忆功能测试完成!")结合chain使用,配置大模型和提示词模板
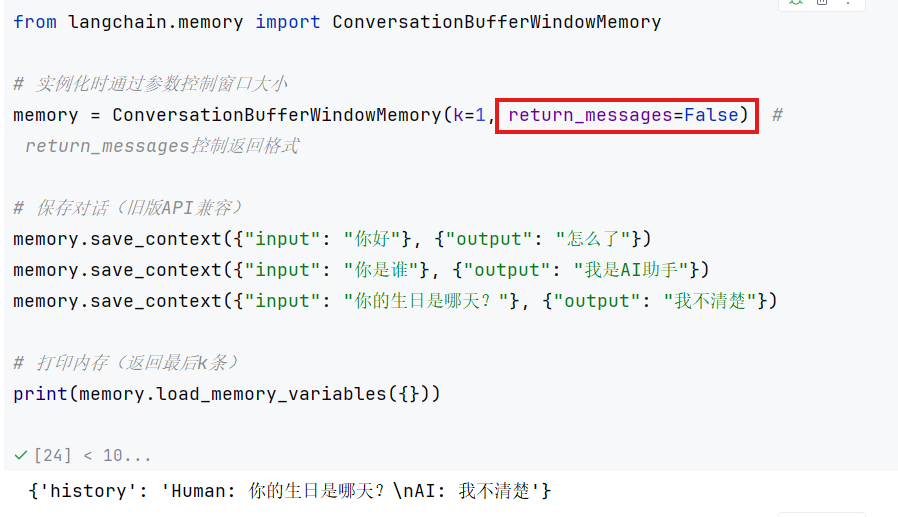
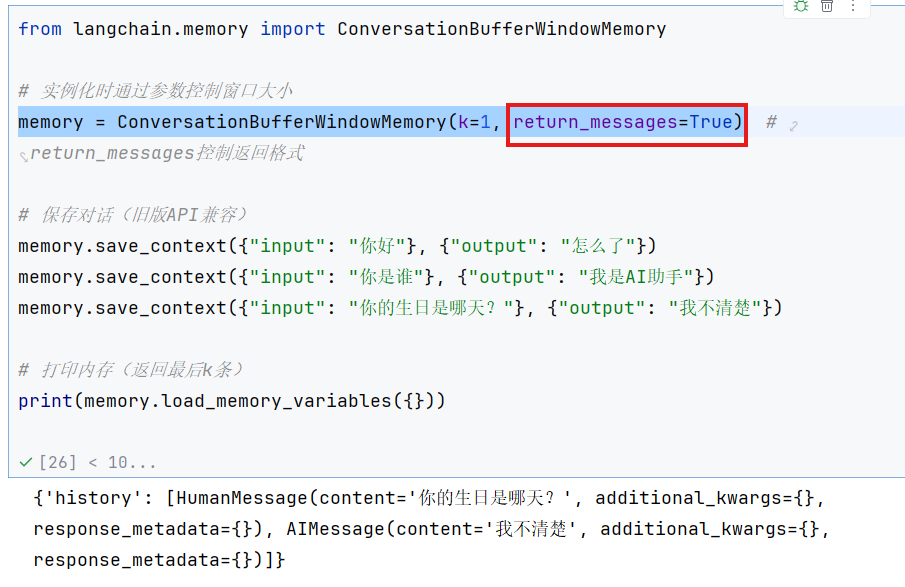
3.ConversationBufferWindowMemory

导入库:
from langchain.memory import ConversationBufferWindowMemory
调用包:
memory = ConversationBufferWindowMemory(k=1, return_messages=True)
return_message=Flase/True这里为Flase时输出结果为纯文本字符串,True时输出结果为消息对象列表
10.tools和agent
1.tools
可以根据tools来判断大模型和智能体,能调用tool的是智能体,不能调用的是大模型。
智能体包含大模型且能够调用tools

自定义工具的两种方式:
第一种:使用@tool装饰器(简单方法)

属性中最重要的就是名称和描述,大模型根据描述信息来选择工具
第二种:使用StructuredTool.from_function 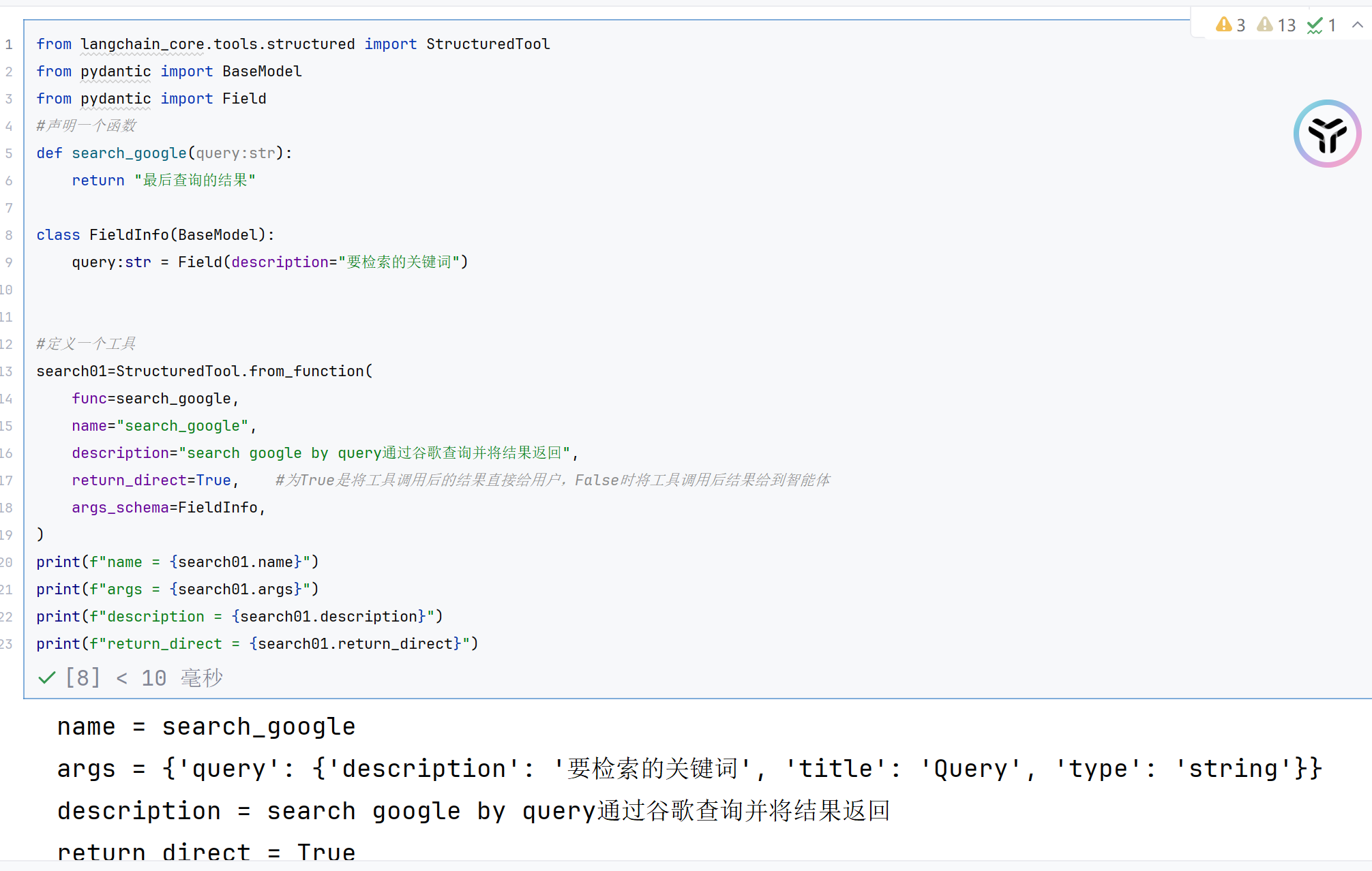
两种方式主要就是对工具进行定义的方式
举例:大模型分析调用工具以及对工具的运用
1.大模型与智能体的区别在于:是否涉及到工具的调用
2.针对大模型:仅仅能够分析出要调用的工具,但是此工具(或函数)不能够真正的执行
针对智能体:除了分析出要调用的工具之外,还可以执行具体的工具(或函数)
2.agent
Agent = LLM + Memory + Tools (思考决策+记忆+执行)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)