Rust:Trait 抽象类型
讲解Rust的抽象类型与多态,并验证虚表
Rust:Trait 抽象类型
Trait 是 Rust 最强大的特性之一,既是类型系统的支柱,也是泛型约束的核心机制。它大致有四大功能:抽象接口、泛型约束、抽象类型、标签。本博客聚焦于抽象类型。
抽象类型
Trait 对象
在很多其它语言中,都有多态的概念。其中最灵活的就是面向对象范式下,父类型可以接收子类型做参数,从而实现一个函数在不同场景下表现不同行为。
比如说,Duck可以游泳,Person可以游泳,Dog也可以游泳,它们都有swim方法。那么面向对象中可以让这三个类都去继承一个Swimmer类,在函数参数中接收Swimmer的指针,实际上你可以传入任意它的子类型。
那么Rust是否有这样的语法?Rust本身不支持面向对象,但是它同样提供了类似的机制,这个机制就是Trait对象。
Trait对象是将拥有相同行为的类型集合,抽象为一个新类型。
比如说Duck、Person和Dog,这三个类型都实现了Swimmer特征,此时你就可以用dyn Swimmer类型作为参数,它可以接收任意实现了Swimmer特征的类型。
此处的dyn Swimmer就是一个Trait对象。
在 Rust 中,如果你希望一个函数参数能够接受任意实现了某个 Trait 的类型,可以使用 Trait 对象。Trait 对象的语法是:
dyn TraitName
这个语法可以用于函数参数,函数返回值等位置。
现在尝试实现刚才的案例:
trait Swimmer {
fn swim(&self);
}
struct Duck;
struct Person;
struct Dog;
impl Swimmer for Duck {
fn swim(&self) {
println!("Duck paddles through the pond.");
}
}
impl Swimmer for Person {
fn swim(&self) {
println!("Person swims freestyle.");
}
}
impl Swimmer for Dog {
fn swim(&self) {
println!("Dog does the doggy paddle.");
}
}
首先定义Swimmer特征,以及三个类型,并为三个类型分别实现Swimmer。
随后定义一个函数,接收dyn Swimmer:
fn perform_swim(swimmer: &dyn Swimmer) {
swimmer.swim();
}
此处的swimmer参数就是一个Trait对象,尝试调用:
let duck = Duck;
let person = Person;
let dog = Dog;
perform_swim(&duck);
perform_swim(&person);
perform_swim(&dog);
以上代码可以成功运行,这就是Trait对象的最基本用法。
但是这里有一个小细节,我接受Trait对象的时候,使用了借用&dyn Swimmer,而不是直接接收,因为Trait对象必须基于借用、指针、智能指针来间接使用。如果你之前学的还不错,那应该想到了,这里和动态大小类型有关系。
对于一个Trait来说,往往可以被多种类型实现,而实现它的各种类型之间,大小可能是不同的。
比如说实现Swimmer的类型中,Person可能有age、name、height等等属性,而Duck有color之类的属性,这些属性就会导致Person和Duck两个类型占用的内存大小不同。
对于一个dyn Swimmer来说,它可能接收到的是任意实现它的类型,在运行前无法确定具体是哪一个,只能保证这个类型实现了Swimmer而已,因此dyn Swimmer可以视为一种动态大小类型。
动态大小类型不能直接在函数中使用,之前说过函数的栈帧大小在编译期就要确定,因此会通过一个指针来间接操作动态大小类型,比如借用、智能指针等等。
这是非常重要的知识点:
Trait对象必须基于指针间接使用
虚表
指向Trait对象的指针是一个胖指针,它包含两部分:data和v-ptr。

如图所示,这就是整个Trait对象的内存布局。在栈区存储的是一个借用指针,胖指针内包含data和v-ptr,这两个成员也是指针。data指向了堆区的Self,这是实现了这个Trait的具体类型,而v-ptr指向一个叫做v-table的表。
此处的v-table叫做虚表,v-ptr叫做虚表指针,这种叫法来源于C++。在虚表内,存储了关于Self的众多信息:
- 析构函数:回收内存时,可以调用这个函数回收
Self的资源,避免内存泄露,这个会在后续博客详细讲解。 size:Self占用内存字节数对齐:Self的对齐数,这涉及到内存的分配方法:Self实现的这个Trait的方法列表
举一个切实的例子:
trait Demo {
fn func1(&self);
fn func2(&self);
fn func3(&self);
}
struct Type1 {
x: u8,
y: u32,
z: [u8; 7],
}
#[repr(align(16))]
struct Type2 {
p: u64,
q: u8,
r: [u64; 2],
}
impl Demo for Type1 {
fn func1(&self) { println!("Type1::func1"); }
fn func2(&self) { println!("Type1::func2"); }
fn func3(&self) { println!("Type1::func3"); }
}
impl Demo for Type2 {
fn func1(&self) { println!("Type2::func1"); }
fn func2(&self) { println!("Type2::func2"); }
fn func3(&self) { println!("Type2::func3"); }
}
现有一个Demo特征,Type1和Type2两个类型,并且type2强制对齐数为16,随后分别为两个类型实现了Demo。
两个Trait对象的内存布局如下:

左侧的Type1的作为Trait对象的布局,右侧是Type2的。
首先data指针指向了各自堆区上的Self,这很好理解,基于这个指针可以访问到结构体内部的成员。
而v-ptr指向了v-table后,从上往下是析构函数的地址,大小,对齐数,以及方法列表。
Type1的大小是12 byte,对齐数是4,Type2的大小是32,对齐数是16,这个可以自行验证,都被放在了v-table中。
最后是Demo中的三个方法func1、func2、func3。不同类型的方法实现不同,那么它们的函数地址就不同,因此左右两个列表中,对应位置的函数地址就是不同的。
在本博客的最后,我会带着大家尝试验证这个布局是否正确,这有不小的难度,以及部分超纲知识。
有了v-ptr和data,Trait对象在调用方法的时候,就很容易的可以进行调用和传参。
例如:
fn process_func(demo: &dyn Demo) {
demo.func1();
demo.func2();
demo.func3();
}
这个函数分别调用了demo的三个方法,问题是我编译期无法确定运行时demo具体是谁啊?我怎么知道调用哪一个类型的函数?此时v-ptr就发挥作用了。
以func2为例,回看刚才的布局图,你会发现不论v-ptr指向谁,在v-table中函数的布局顺序是固定的。此处的v-table是一个数组,而func2就在数组的第五个元素。不论谁实现了Demo这个Trait,最后func2一定是v-ptr[4]这个元素。
注:此处v-ptr[4]的语法,其实类似于C语言中的数组,数组名的本质是一个指针,arr[4]等效*(arr + 4),这是一个指针先偏移,后解引用的过程。如果你没有这方面的基础,直接认为 v-ptr[4] 就是通过指针拿到数组的第五个元素即可。
那么demo.func2()会在编译期转化为以下等效的伪代码:
let (data, vptr) = demo; // 拆胖指针
let f = vptr[4]; // 偏移量 4 是 func2 的槽位
f(data); // 调用
首先从demo这个胖指针中拿出v-ptr,随后通过v-ptr[4]拿到func2的函数地址,最后data作为self传进函数中,并完成函数调用。
也就是说这个函数调用的过程,本质是不同类型传入的v-ptr不同,但是虚表的结构是相同的。因此不论v-ptr是哪一个类型的,都去拿表中指定偏移量位置的值,取出来做函数调用。
这个过程发生在运行时,也就是在运行时才能确定要调用的函数地址。这个过程需要查表传参,因此运行时效率会有所降低,对应的灵活性会提高。
这个运行时基于虚表和偏移量查找函数并调用的过程,称为动态分发。而动态的英文是dynamic,因此Trait对象使用了dyn这个关键字。在早期的Rust中没有dyn这个关键字,比如& Swimmer直接就是一个Trait对象,现在必须使用dyn来声明了。
最后,同一个类型的所有实例共用一张v-table,因为虚表内部的信息是完全固定的,整个程序运行期间都不会发生变化。
Trait 对象约束
在Trait对象中,也可以对这个对象进行约束。
语法:
dyn Trait_A + Trait_B + Trait_C ...
在dyn后面,用+连接多个Trait。
这代表:这是一个Trait_A 的Trait对象,并要求改对象的具体类型同时实现了Trait_B和Trait_C。
要注意的是,"这是一个Trait_A 的Trait对象"这句话。这意味着只有第一个Trait的方法会进入虚表,而后续的Trait只用于约束类型。
例如:
trait Foo {
fn foo(&self);
}
struct S;
impl Foo for S {
fn foo(&self) { println!("Foo::foo()!"); }
}
fn call_foo(x: &dyn Foo + Debug) { x.foo(); }
此处的call_foo中,x参数类型为 &dyn Foo + Debug,这代表它是一个Foo的对象,但是必须实现Debug这个Trait。
但如果你想要让某个Trait对象,虚表中同时拥有多个Trait的方法,那就不适合这种约束,而是要用一个Trait去继承所有Trait
dyn-compatible
并不是所有的Trait都可以作为Trait对象使用,只有符合要求的才行。
具体要求参考官方文档:Traits - The Rust Reference。
Trait对象必须符合以下要求:
- 所有的
Super Trait也必须是dyn-compatibleTrait的Self类型参数不能被限定为Sized(不能继承Sized)- 不能有任何关联常量
- 所有函数必须要么是可动态分发的函数,要么显式标记为不可调用
- 不能有带泛型的关联类型
如果符合以上要求,就称为 dyn-compatible,就可以被作为 Trait对象使用。
接下来分点解释。
Sized
Trait的Self类型参数不能被限定为Sized
Sized是一个原生的Trait,它表示一个类型的大小是固定的。与之对应的是Unsize,表示动态大小类型。
绝大部分Trait默认就是?Sized,它表示不限制Self的大小,既可以是Sized也可以是Unsize。
你可以显式的指定:
trait Demo: Sized {}
这个Demo继承了Sized,那么它就无法成为一个Trait对象。
为什么不能继承Sized?在Rust官方文档有这样一句话:
Trait objects implement the base trait, its auto traits, and any supertraits of the base trait
译:特征对象会实现它的基Trait、它的auto trait,以及所有的Super Trait
这句话来自:Trait object types - The Rust Reference
简单来说,特征对象会实现它自己对应的Trait继承的所有Trait。
例如:
trait Demo: Display + Debug {
fn func();
}
这是一个Trait,它继承了Display、Debug,这两个算作Super trait。它还隐式的继承了?Sized,这属于auto trait。
那么对应的特征对象dyn Demo作为一个类型,它也会自动实现Display、Debug、?Sized这Trait,以及它自己Demo。
你有没有想过一个问题,动态分发的时候,为什么Trait对象可以随意的调用Trait内部的方法:
fn process_func(demo: &dyn Demo) {
demo.func();
}
dyn Demo自己就是一个类型,它想要调用Demo这个Trait内部的func方法,它自己就必须实现Demo这个Trait,并满足所有Self的约束,因为此时dyn Demo本身就是Self。而这个过程,已经由Rust编译期自动帮你实现了。
假设Demo受到Size约束:
trait Demo: Sized {}
也就是Self收到Sized约束,如果需要Trait 对象,那么dyn Demo就要受到Sized约束。问题在于,dyn Demo是一个动态大小类型,它根本不可能有确定的大小,根本不可能受到Sized约束。
因此当一个Trait收到Sized约束,它不能使用Trait对象。
关联常量
不能有任何关联常量
不同实现者可以给同一个关联常量不同的值。
trait Foo {
const A: i32;
}
impl Foo for u8 { const A: i32 = 1; }
impl Foo for u16 { const A: i32 = 2; }
如果你有一个 Box<dyn Foo>,那么问题来了: dyn Foo::A 应该是 1 还是 2?
在方法调用时,编译器可以通过 v-table 动态分发到正确的函数指针,但常量不是函数调用,无法通过v-table动态查找一个常量的值。所以编译器无法在运行时决定该取哪个值。
所以Trait对象要禁止关联常量,它无法进行动态分发。
可动态分发的函数
所有函数必须要么是可动态分发的函数,要么显式标记为不可调用
这里对于 “可动态分发的函数” 的定义又是一个非常复杂的条例,我们已经知道Trait对象会维护一张虚表,内部会存放元信息和众多方法地址。但并不是Trait内部所有的方法都会进入虚表,只有可通过Trait对象动态分发的方法才会进入虚表。
可动态分发的函数必须满足:
- 不能有泛型参数
- 必须使用
Self或者可解引用为Self的类型作为第一个参数 - 函数签名中,不能在第一个参数以外的位置使用
Self - 返回值不能是不透明类型
如果不能满足以上条件,必须显式标记为不可调用。
分点一个一个讲解:
- 不能有泛型参数
当一个函数带有泛型参数,那么经过单态化后,它就可能派生出无数种具体实现。我们先前说过,动态分发的基础是v-ptr以及指定的偏移量,而这个又建立在同一个Trait所有类型的v-table格式是一模一样的基础上。
当使用泛型参数后,首先无法预知会单态化出多少个版本的函数,那么无论v-table有多大,都装不下这么多函数地址。其次,不同类型单态化出的版本不同,那么每个v-table格式就不一样了,这会撼动整个动态分发体系的根基。
- 必须使用
Self或者可解引用为Self的类型作为第一个参数
动态分发过程中,从虚表拿到函数地址后,会把data作为第一个参数传入,如果函数第一个参数不是Self或者Self的指针,此时参数传递就会出错,直接错误。因此可动态分发的函数必须有Self作为第一个参数。
- 函数签名中,不能在第一个参数以外的位置使用
Self
此处的第一个参数外,包括从第二个参数往后的所有参数,以及函数返回值都不能用Self。
这个点同样从两个方面来理解。
假设有一个违背以上条件的方法,函数签名是func(&self, other: Self) -> Self。
Trait对象本身就是一个实现了自己的Base Trait的类型,那么这个方法也会被Trait对象自己所实现。对于第一个参数,Trait对象会做特殊处理,最后传入一个data表示具体类型。请问第二个参数Self怎么办?它不会被特殊处理,此时Self就是Trait对象自己,是一个动态大小类型。怎么可以把一个动态大小类型放到函数的栈区?因此这条路走不通,Trait对象根本无法实现自己的Base Trait
另一个方面,假设某个函数使用动态分发调用了这个方法:
fn process_func(d: &dyn Trait) {
let arg; // ?
let ret = d.func(arg); // ?
}
此处我打了两个问号,d.func(arg)这个动态分发调用,接收一个Self参数,返回一个Self参数,在process_func内,Self = dyn Trait,这又是一个动态大小类型被直接放到了栈区。
- 返回值不能是不透明类型
这个会在一会讲解impl Trait时讲到。
只要满足以上四点,就是一个可动态分发的函数,它的地址就会进入虚表,从而实现动态分发。
如果说某个函数违背了以上要求,那么你必须显式标记为不可调用,最常见的手法是在方法中限制Self: Sized,这样这个函数就不会进入虚表。
但是如果某个函数违背了四条规则之一,并且还没有显式标注不可调用,那么整个Trait都将无法动态分发了。
例如:
trait Demo {
fn demo(&self);
fn func(&self, other: Self) -> Self;
}
struct Type1;
impl Demo for Type1 {
fn demo(&self) {
println!("Type1 demo");
}
fn func(&self, other: Type1) -> Type1 {
println!("Type1 func");
other
}
}
fn process_demo(d: &dyn Demo) {
d.demo();
}
在Demo中,它的demo函数是一个可动态分发的函数,满足所有要求。而func函数在其他位置出现了Self,它不可动态分发,还没有显式标注不可调用。那么整个Demo都无法作为Trait对象使用,process_demo中就算没有调用func方法,d: &dyn Demo这个语法也会报错。
想要解决,只需要在func中对Self进行限制:
trait Demo {
fn demo(&self);
fn func(&self, other: Self) -> Self
where Self: Sized; // 添加 Trait 约束
}
struct Type1;
impl Demo for Type1 {
fn demo(&self) {
println!("Type1 demo");
}
fn func(&self, other: Type1) -> Type1
where Self: Sized { // 添加 Trait 约束
println!("Type1 func");
other
}
}
fn process_demo(d: &dyn Demo) {
d.demo();
}
在以上代码中的两处位置,添加了Sized约束,此时这个func函数就不会进入虚表,最后demo也就可以正常调用了。
泛型关联类型
不能有带泛型的关联类型
在理解完刚才的一点后,其实这个就很好理解了。关联类型往往会在对应的方法中进行使用,用户每指定一个泛型作为关联类型,就会单态化出一个新版的函数,最后导致v-table大小不确定,格式不一致,和之前不能有泛型参数是一个逻辑
总结
看到这里你估计已经头昏眼花了,我写的也快头昏眼花了。我把每个要点都拆出来理清了内部的逻辑,最后总结一下所有规则。
dyn-compatible的要求有:
- 所有的
Super Trait也必须是dyn-compatible Trait的Self类型参数不能被限定为Sized(不能继承Sized)- 不能有任何关联常量
- 所有函数必须要么是可动态分发的函数,要么显式标记为不可调用。可动态分发的函数必须满足:
- 不能有泛型参数
- 必须使用
Self或者可解引用为Self的类型作为第一个参数 - 函数签名中,不能在第一个参数以外的位置使用
Self - 返回值不能是不透明类型
- 不能有带泛型的关联类型
impl Trait
在Rust 2018,又引入了一个新特性impl Trait。它也属于抽象类型,并且是静态分发的。它和Trait对象属于相反的特性。
在Trait对象中,基于指针把类型放到堆上管理,称为装箱。而impl Trait则会把值放到栈区,称为拆箱。前者是运行时动态分发,后者是编译期静态分发。
impl Trait也用于描述实现了某个Trait的类型,它可以放在函数参数和返回值中。但是不能用作 let 绑定、结构体字段类型或类型别名等位置。
函数参数
语法:
fn func(arg: impl Trait_1 + Trait_2);
此处的arg参数,就是一个受到约束的类型,它必须是实现了Trait_1和Trait_2的类型。
其实它等效与以下代码:
fn func<T: Trait_1 + Trait_2>(arg: T);
也就是之前的泛型约束,它们两个几乎是完全等价的。只是impl Trait语法下,不用显式写出泛型,更简洁。
它们也有相同的编译期单态化机制,当func函数传入多少种参数,最后就会单态化出多少实例。
但不同的是,泛型可以由用户自己指定,而impl Trait只能通过编译器自行推导。
返回值
语法:
fn func() -> impl Trait_1 + Trait_2;
此时func函数限制了返回的类型必须是同时实现了Trait_1和Trait_2的类型。
与泛型不同的是,泛型由调用方决定具体类型,而impl Trait是在函数内部自己决定返回类型的。
例如:
fn make_number() -> impl std::fmt::Display {
42
}
最终返回的是一个i32类型,它实现了std::fmt::Display。
但是这不代表可以在一个函数中返回不同类型。例如:
fn make_number(num: i32) -> impl std::fmt::Display {
if num > 0 {
10
} else {
"hello"
}
}
这个代码是错误的,你不能让一个函数返回多种类型。
那有人就有疑问了,既然如此为什么不直接把返回值写死,还要搞个impl Trait语法?
在返回值中impl Trait与其说是一个约束,不如说是一种承诺,承诺我的返回值一定是实现了某些Trait的类型。
当外部调用这个函数,拿到一个类型后。用户不必关心类型的具体值,只要知道它实现了某些Trait,并且可以使用这个Trait就好。
你可以尝试运行以下代码:
fn make_number() -> impl std::fmt::Display {
42
}
let mut num = make_number();
println!("{}", num);
num += 10;
这行代码会报错,因为实现了Display的类型不一定可以使用+=。即便num真的是一个i32类型,但是在外层调用时,编译器认为num相当于一个impl Display的类型,你只能使用在Display范围内的方法。
甚至编译器不允许你去指定类型:
let mut num: impl Display = make_number();
let mut num: i32 = make_number();
这两个写法都是错误的,你既不能直接判断这是一个i32,甚至你不能说它是一个impl Display,只能让编译器自己去推出它是一个impl Display。
这种类型就是刚才说的不透明类型,你只知道这个类型具有某些特征,但不会让你知道这个类型具体是什么,从而实现封装。
在后续学习中,比如闭包这一块内容,你很难去写出一个类型,有一些类型是编译器生成的匿名类型,非常复杂。但是你只要知道这个类型实现了某些Trait,然后用impl Trait语法来使用它,到时候才能感受到这个语法的实际作用。
现在的主要作用,可以理解为部分场景下可以简化泛型,提高代码可读性。
多态
如果你有其它语言的学习经验,可能常常听说多态,而多态分为静态多态和动态多态。这可以说是计算机界的元老级别八股文了,面试常考。
但是作为多范式语言,我希望基于Rust带大家理解更加广泛的多态体系,而不是以简单的动静区分。
在类型系统里,多态性通常分为三类:
- 参数多态(
Parametric Polymorphism):属于静态多态,函数或类型对任意类型参数都能工作,不依赖具体实现。Rust的泛型,impl traitC++的模板
- 特设多态(
Ad-hoc Polymorphism):属于静态多态,同一个函数名在不同类型上有不同实现。Rust的TraitHaskell的typeclassC++函数重载
- 子类型多态(
Subtype Polymorphism):属于动态多态,面向对象语言里常见,子类可以替代父类使用。Rust的Trait对象C++的虚函数Java的继承
参数多态
通过 泛型 或 impl Trait 实现,编译期静态分发。
例如:
// 泛型写法
fn swap<T>(a: &mut T, b: &mut T) {
std::mem::swap(a, b);
}
// impl Trait 写法
fn print_debug(x: impl std::fmt::Debug) {
println!("{:?}", x);
}
这种多态在编译期可以传入多种类型,并且每种类型最后的实现都是相同的,根据调用来进行单态化,从而产生符合各个类型的函数版本。
特设多态
通过 trait 为不同类型提供不同实现,本质就是函数重载。
trait Hello {
fn hello(&self);
}
impl Hello for i32 {
fn hello(&self) {
println!("i32 says hello: {}", self);
}
}
impl Hello for String {
fn hello(&self) {
println!("String says hello: {}", self);
}
}
虽然Rust没有提供直接的函数重载,但是Trait可以看成一种函数重载。
比如String和i32都能调用hello这个函数,可以理解为在hello这个同名函数中,你可以给第一个参数传入不同的self,从而调用到不同版本的函数。函数名相同,而根据不同参数来选择版本,这其实就是函数重载。
子类型多态
通过 trait object 实现,运行时动态分发。
trait Shape {
fn area(&self) -> f64;
}
struct Circle { r: f64 }
struct Square { a: f64 }
impl Shape for Circle {
fn area(&self) -> f64 { 3.14 * self.r * self.r }
}
impl Shape for Square {
fn area(&self) -> f64 { self.a * self.a }
}
fn print_area(s: &dyn Shape) {
println!("area = {}", s.area());
}
Rust是一个混合范式语言,而不是一个面向对象语言,但是Rust汲取了面向对象的核心思想,把他们最重要的一些理论抽出来,做符合Rust的表达。
在Rust中,几乎没有别的位置有对象这样的OOP风格表述。唯独dyn Trait这里使用了特征对象的表述,就是因为这里融合了非常类似于面向对象的多态思想。并且是以C++风格为主的多态思想。
你也许困惑为什么要叫虚表,为什么叫虚指针,为什么叫析构函数。对Rust来说,其实就是从C++中借鉴后,做出了一定的机制修改。
这里可以理解为Trait Object是一种父类型,而所有实现了Trait的类型都是子类型。父类型的引用或者指针,可以接收子类型的实例作为参数,然后运行时动态调用方法。因此 dyn Trait 从思想上就是一个子类型多态。
面向对象三大思想继承、多态、封装。
首先Rust舍弃了继承,采用组合优先的思想。但是也有Trait继承这样的语法,以及刚才说的 dyn Trait 融合了继承的思想在里面。
在多态中,Rust有丰富全面的多态体系,你可以舍弃性能换取灵活性,你也可以舍弃灵活性以获取最高的性能,这一切都基于强大的Trait体系,它的知识点最庞杂。
对于封装来说,Rust有合理的函数封装体系,pub控制可见性,这一块知识点也会在后续讲解。
可见的是,Rust虽然不支持面向对象,但是其最核心,最精华的思想都已被Rust收入囊中。
验证虚表 与 模拟动态分发
博客的最后,如果你有兴趣,可以一起往下用代码验证虚表的存在。
使用的案例是之前的Demo:
trait Demo {
fn func1(&self);
fn func2(&self);
fn func3(&self);
}
struct Type1 {
x: u8,
y: u32,
z: [u8; 7],
}
#[repr(align(16))]
struct Type2 {
p: u64,
q: u8,
r: [u64; 2],
}
impl Demo for Type1 {
fn func1(&self) { println!("Type1::func1 调用完毕"); }
fn func2(&self) { println!("Type1::func2 调用完毕"); }
fn func3(&self) { println!("Type1::func3 调用完毕"); }
}
impl Demo for Type2 {
fn func1(&self) { println!("Type2::func1 调用完毕"); }
fn func2(&self) { println!("Type2::func2 调用完毕"); }
fn func3(&self) { println!("Type2::func3 调用完毕"); }
}
- 输出真实信息:
// 打印真实元信息
fn print_real_info<T: Demo>() {
let f1: fn(&T) = T::func1;
let f2: fn(&T) = T::func2;
let f3: fn(&T) = T::func3;
println!("=== 真实信息 ===");
println!("size: {} align: {}", size_of::<T>(), align_of::<T>());
println!("func1: {:p}", f1 as *const ());
println!("func2: {:p}", f2 as *const ());
println!("func3: {:p}", f3 as *const ());
}
这是第一个函数,用于输出某个类型的真实信息,包括size,对齐数,以及三个函数的地址。其中fn (&T)是一个函数指针类型,会在后续博客深入讲解。使用{:p}就可以输出这个指针指向的具体地址,也就是函数的地址。
- 输出虚表信息:
unsafe fn print_vtable_info<T: Demo>(obj: &dyn Demo) {
// 拆解胖指针
let raw = obj as *const dyn Demo;
let (data, vptr): (*const (), *const ()) = transmute(raw);
let data: &T = transmute(data);
let vt = vptr as *const *const ();
// ...
}
首先定义一个 print_vtable_info 函数,它被unsafe修饰,表示内部会进行一些不安全操作。接收一个&dym Demo,这是一个胖指针,函数开头先把胖指针中的data和vtable拆解出来。
let raw = obj as *const dyn Demo;
这行代码的意思是把obj转化为一个原生指针,*const是一种原生指针,会在后续博客讲解,基于这种指针可以进行一些类似C语言的不安全操作。*const后面接着的是它具体指向的类型,*const dyn Demo就是一个指向Demo特征对象的指针。
let (data, vptr): (*const (), *const ()) = transmute(raw);
这里用到了一个transmute方法,它类似于强制类型转化,强行把raw内部的信息解释为(*const (), *const ())这个类型。而*const ()是指向一个单元类型的原生指针,可以理解为C语言中的void*。也就是说这里我不在乎它具体指向什么类型,我只是要把两个指针拿出来而已。
let data: &T = transmute(data);
这里也是基于 transmute,把data转化为&T这个类型,也就是&self,后续才能正常传参。
let vt = vptr as *const *const ();
这行代码是通过v-ptr拿到虚函数表,而*const *const ()可以看作一个二级指针,它指向的是*const ()的指针。
为什么这里要用二级指针?可以看以下布局:
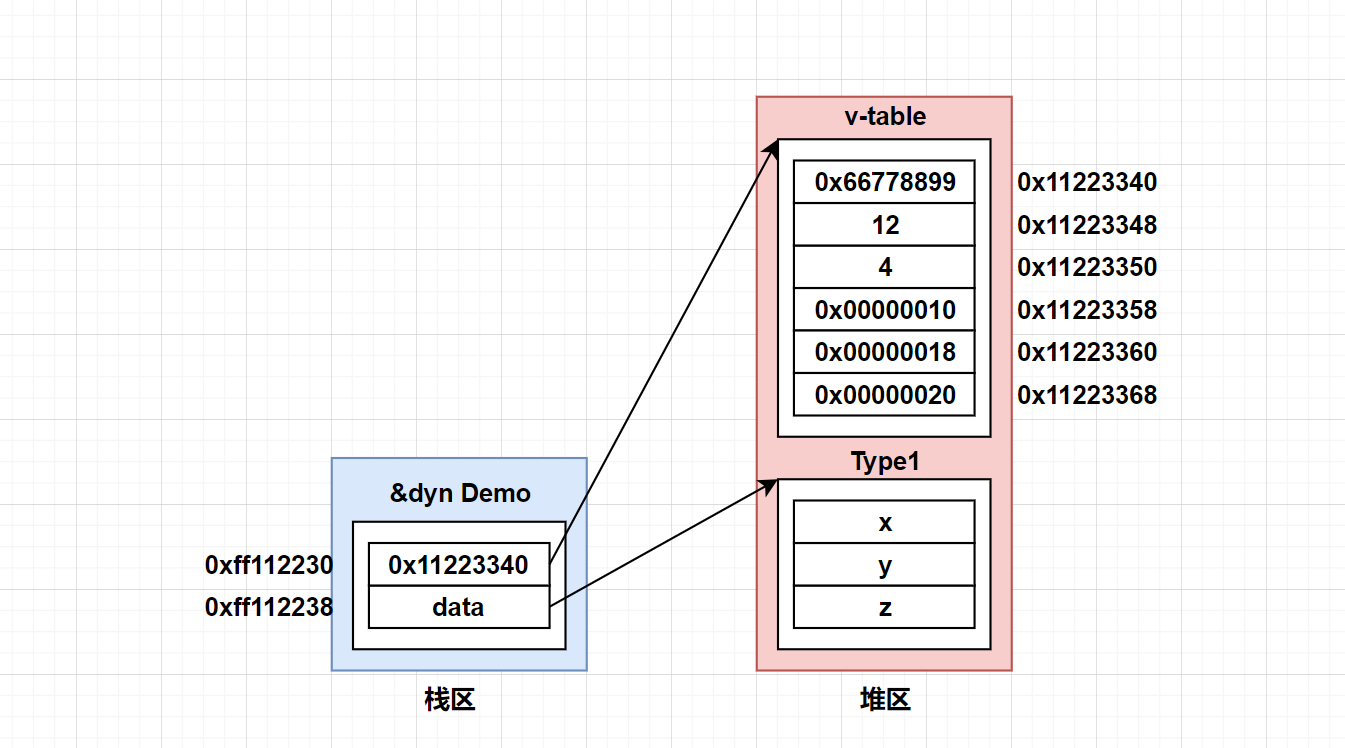
我把所有变量名都变为了具体的数值,0x开头的是十六进制的地址。
一开始我们从胖指针中拆出了v-ptr,它的值就是整个v-table的起始地址0x11223340。对它直接解引用,拿到的就是0x66778899这个地址,也就是析构函数的地址。但是目前它是*const ()类型,解引用拿到的是一个单元类型,而我们期望解引用之后还是一个指针。因此把他转为*const *const ()类型。此时对其解引用,拿到的就是*const ()类型,还是一个指针,那么0x66778899这个地址就会被解释为一个指针,方便我们进行后续操作了。(这地方真挺绕的,有C/C++指针经验的同学会更好理解)。
这个过程我们只是修改它的类型,从而保证解引用后拿到的值会被解析为一个指针。
拆完胖指针,接下来基于vt提取出重要信息:
unsafe fn print_vtable_info<T: Demo>(obj: &dyn Demo) {
// 拆胖指针
// 提取信息
let drop_fn: unsafe fn(*mut ()) = transmute(*vt.add(0));
let size = *vt.add(1) as usize;
let align = *vt.add(2) as usize;
let f1: fn (&T) = transmute(*vt.add(3));
let f2: fn (&T) = transmute(*vt.add(4));
let f3: fn (&T) = transmute(*vt.add(5));
// ...
}
这部分将函数地址和元信息都从虚表中提取了出来。
let drop_fn: unsafe fn(*mut ()) = transmute(*vt.add(0));
这里提取出析构函数的地址。*vt.add(0)中,vt本身已经指向第一个元素,add(0)不修改指针大小,随后对指针解引用,拿到了一个*const ()的指针。基于 transmute 函数,强行把这个指针的类型转化为 unsafe fn(*mut ()),这是一个函数指针,这里不讲解为什么是这样的格式,你只要知道drop_fn现在是一个指向析构函数的指针就好了。
let size = *vt.add(1) as usize;
let align = *vt.add(2) as usize;
这里提取出虚表中的size字段,也就是第二个元素。*vt.add(1),先把vt的指针往后偏移一个元素的位置,此时它指向第二个元素,再对其解引用,就拿到了第二个元素的值。但是类型是*const (),于是使用as usize强行把它转换为一个数字,这样就拿到了size。
下一行的align同理。
let f1: fn (&T) = transmute(*vt.add(3));
let f2: fn (&T) = transmute(*vt.add(4));
let f3: fn (&T) = transmute(*vt.add(5));
这里是拆出三个指针,实际上是三个函数指针,类型是 fn (&T)。通过*vt.add(偏移量)拿到对应偏移量的值,并通过 transmute 强制转化为函数指针类型。
到此为止所有有难度的内容都完成了,最后输出这些信息:
unsafe fn print_vtable_info<T: Demo>(obj: &dyn Demo) {
// 拆胖指针
// 提取信息
println!("\n== 基于虚表调用函数 ==");
f1(data);
f2(data);
f3(data);
println!("\n== 虚表信息 ==");
println!("data: {:p}", data);
println!("vptr: {:p}", vptr);
println!(" [元信息]");
println!(" drop fn: {:p}", drop_fn as *const ());
println!(" size: {}", size);
println!(" align: {}", align);
println!(" [函数表]");
println!(" func1: {:p}", f1);
println!(" func2: {:p}", f2);
println!(" func3: {:p}", f3);
}
首先直接拿f1、f2、f3去调用函数:
println!("\n== 基于虚表调用函数 ==");
f1(data);
f2(data);
f3(data);
这个过程已经是在模拟动态分发了,我们通过v-ptr、data、偏移量,终于凑齐了调用这个函数的所有必要条件,此时可以直接进行函数调用。
后续就是输出各种之前存储的信息,比如元数据,函数表地址等等。
在main函数中调用:
fn main() {
let obj1: Box<dyn Demo> = Box::new(Type1 { x: 1, y: 2, z: [0; 7] });
let obj2: Box<dyn Demo> = Box::new(Type2 { p: 2, q: 1, r: [0; 2] });
// Type1
println!("验证 Type1: ");
print_real_info::<Type1>();
unsafe { print_vtable_info::<Type1>(&*obj1); }
// Type2
println!("验证 Type2: ");
print_real_info::<Type2>();
unsafe { print_vtable_info::<Type2>(&*obj2); }
}
首先定义了两个Trait对象,随后调用print_real_info输出真实信息,再调用 print_vtable_info 输出虚表中的信息。
输出结果:
验证 Type1:
=== 真实信息 ===
size: 12 align: 4
func1: 0x7ff7ad013b40
func2: 0x7ff7ad013b70
func3: 0x7ff7ad013ba0
== 基于虚表调用函数 ==
Type1::func1 调用完毕
Type1::func2 调用完毕
Type1::func3 调用完毕
== 虚表信息 ==
data: 0x20aabc43130
vptr: 0x7ff7ad02bce0
[元信息]
drop fn: 0x0
size: 12
align: 4
[函数表]
func1: 0x7ff7ad013b40
func2: 0x7ff7ad013b70
func3: 0x7ff7ad013ba0
验证 Type2:
=== 真实信息 ===
size: 32 align: 16
func1: 0x7ff7ad013bd0
func2: 0x7ff7ad013c00
func3: 0x7ff7ad013c30
== 基于虚表调用函数 ==
Type2::func1 调用完毕
Type2::func2 调用完毕
Type2::func3 调用完毕
== 虚表信息 ==
data: 0x20aabc44200
vptr: 0x7ff7ad02bd10
[元信息]
drop fn: 0x0
size: 32
align: 16
[函数表]
func1: 0x7ff7ad013bd0
func2: 0x7ff7ad013c00
func3: 0x7ff7ad013c30
可以看到,真实信息和虚表中提取出来的信息是完全一致的。并且我们手动实现的动态分发也完成了最终的函数调用。
总代码:
use std::mem::{align_of, size_of, transmute};
trait Demo {
fn func1(&self);
fn func2(&self);
fn func3(&self);
}
struct Type1 {
x: u8,
y: u32,
z: [u8; 7],
}
#[repr(align(16))]
struct Type2 {
p: u64,
q: u8,
r: [u64; 2],
}
impl Demo for Type1 {
fn func1(&self) { println!("Type1::func1 调用完毕"); }
fn func2(&self) { println!("Type1::func2 调用完毕"); }
fn func3(&self) { println!("Type1::func3 调用完毕"); }
}
impl Demo for Type2 {
fn func1(&self) { println!("Type2::func1 调用完毕"); }
fn func2(&self) { println!("Type2::func2 调用完毕"); }
fn func3(&self) { println!("Type2::func3 调用完毕"); }
}
// 打印真实元信息
fn print_real_info<T: Demo>() {
let f1: fn(&T) = T::func1;
let f2: fn(&T) = T::func2;
let f3: fn(&T) = T::func3;
println!("=== 真实信息 ===");
println!("size: {} align: {}", size_of::<T>(), align_of::<T>());
println!("func1: {:p}", f1 as *const ());
println!("func2: {:p}", f2 as *const ());
println!("func3: {:p}", f3 as *const ());
}
// 打印虚表信息(drop/size/align + vtable 方法地址)
unsafe fn print_vtable_info<T: Demo>(obj: &dyn Demo) {
// 拆胖指针
let raw = obj as *const dyn Demo;
let (data, vptr): (*const (), *const ()) = transmute(raw);
let data: &T = transmute(data);
let vt = vptr as *const *const ();
// 提取信息
let drop_fn: unsafe fn(*mut ()) = transmute(*vt.add(0));
let size = *vt.add(1) as usize;
let align = *vt.add(2) as usize;
let f1: fn (&T) = transmute(*vt.add(3));
let f2: fn (&T) = transmute(*vt.add(4));
let f3: fn (&T) = transmute(*vt.add(5));
println!("\n== 基于虚表调用函数 ==");
f1(data);
f2(data);
f3(data);
println!("\n== 虚表信息 ==");
println!("data: {:p}", data);
println!("vptr: {:p}", vptr);
println!(" [元信息]");
println!(" drop fn: {:p}", drop_fn as *const ());
println!(" size: {}", size);
println!(" align: {}", align);
println!(" [函数表]");
println!(" func1: {:p}", f1);
println!(" func2: {:p}", f2);
println!(" func3: {:p}", f3);
}
fn main() {
let obj1: Box<dyn Demo> = Box::new(Type1 { x: 1, y: 2, z: [0; 7] });
let obj2: Box<dyn Demo> = Box::new(Type2 { p: 2, q: 1, r: [0; 2] });
// Type1
println!("验证 Type1: ");
print_real_info::<Type1>();
unsafe { print_vtable_info::<Type1>(&*obj1); }
// Type2
println!("验证 Type2: ");
print_real_info::<Type2>();
unsafe { print_vtable_info::<Type2>(&*obj2); }
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)