每日AIGC最新进展(93):字节开源720p视频生成自回归模型、字节开源多模态图片编辑模型DreamOmni2、上交提出细粒度PixCLIP
字节开源720p视频生成自回归模型、字节开源多模态图片编辑模型DreamOmni2、上交提出细粒度PixCLIP
目录
(1)多模态指令驱动的图像生成(Multimodal Instruction-based Generation)
(2)多模态指令驱动的图像编辑(Multimodal Instruction-based Editing)
InfinityStar
当前视觉生成领域面临三大核心矛盾:
-
扩散模型的“慢”与“僵”:依赖数十至数百次迭代去噪,推理延迟高,易产生抖动,难以扩展至长序列、交互式或运动外推任务。
-
传统自回归模型的“低质”与“低效”:逐token生成(数万步)导致延迟极高,视觉细节模糊、动态失真;且图像与视频模型无法共享参数,训练成本高。
-
任务割裂的“冗余”:T2I、T2V、I2V长期依赖独立模型,知识无法迁移,系统臃肿。
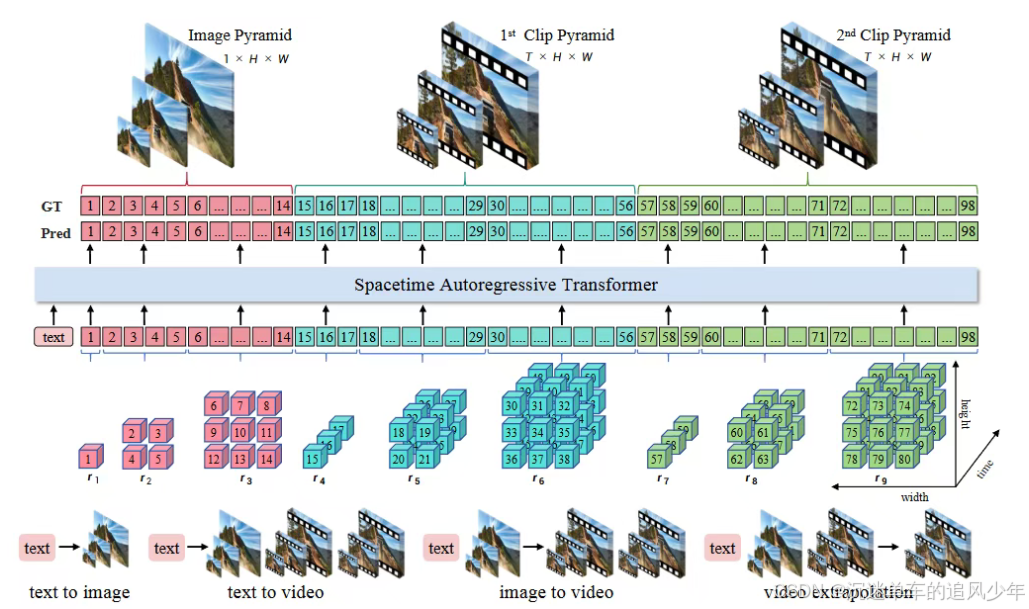
InfinityStar 的目标是构建一个:高保真、高效率、长序列、多任务通用的统一生成引擎。
本文的解决方案是构建时空金字塔自回归建模框架(Spacetime Pyramid Modeling),其核心思想是显式解耦空间结构与时间动态。
-
将任意视频视为一个首帧图像金字塔(T=1,编码静态外观) + 多个时间片段金字塔(T>1,编码后续运动)的组合。
-
每一金字塔结构沿空间尺度(h×w)递增,而时间维度对每个片段保持固定,仅在片段间递进。
-
模型分两阶段自回归生成:
-
帧内生成:在单一片段内,按尺度顺序出生(从粗到细)预测残差 token,构建视觉细节;
-
片段间生成:在片段之间,以先前片段和文本为条件,按顺序延拓时间,实现无限长视频。
-
-
基于此结构,相同的Transformer架构,可直接应用于T2I(仅一帧)、T2V(多片段)、I2V(以输入图像为首帧)等所有任务,实现参数与能力的统一。
该设计首次在离散自回归框架中,实现了生成行为与任务类型之间的无缝切换。
将空间维度的“下一尺度预测”扩展至视频,关键挑战在于如何有效建模时间维度。直接让时间与空间同步增长(即从 到 )会导致卡顿;若固定时间尺度(伪时空金字塔)则会耦合外观与运动,使 T2V 学习无法共享 T2I 知识。
本文提出时空金字塔建模框架:每一视频被分解为一组序列片段 。首帧 被设为 T=1,构建图像金字塔,用于编码静态内容;其余片段共享固定时长 T>1,分别构建片段金字塔。每个片段内,空间尺度从 增至 ,存在 K 个残差 token 块 。所有尺度仅在空间维度扩展,时间维度保持恒定。
视频分词器训练面临两大挑战:计算成本高(压缩数十帧)、信息分布严重不均衡(末层聚集大部分信息)。
知识继承:本文不从零训练,而是继承预训练连续视频 VAE 的编码器与解码器结构,在其间插入无参数二元球形量化器。此操作不引入额外参数(如VQ-VAE的码本),直接复现 VAE 的结构与语义表征。如图2所示,即使无微调,重建质量已显著优于从零训练或继承图像VAE的方案。微调时,将原始VAE的KL损失替换为“承诺损失+熵惩罚”,联合优化图像与视频数据,显著加速收敛。
为适应时空维度,提升质量与效率,本文对VAR Transformer进行三项改进。
语义尺度重复(SSR):观察到早期尺度(如前 个)承载了场景布局、主体身份等高语义信息。为此,将这 个尺度在生成序列中重复预测 次,实现结构精细化。由于其token占比极低,额外开销可忽略,但显著提升细节与动态真实感。
时空稀疏注意力(SSA):为解决长序列计算爆炸,本文设计一种稀疏注意力模式:每个片段仅关注前一片段的最后一层 Token(及其对应尺度位置)。如图4所示,该方法将注意力跨度压缩至仅“当前与前一帧最后层”,有效降低自注意力复杂度,避免OOM,在192p-161帧下实现 1.5× 速度提升,并在480p下可运行(全注意内存溢出)。
DreamOmni2
DreamOmni2是一个基于多模态指令驱动的图像编辑、生成模型,它支持同时使用文本和图像指令,能够处理具体物体和抽象属性的编辑与生成任务。用户可以通过简单的指令,实现图像中物体的替换、风格迁移、光照调整等复杂操作。
DreamOmni2的创新之处在于数据创建管道和多图像输入处理方式,能够避免像素混乱,提高编辑与生成的准确性与一致性。


(1)多模态指令驱动的图像生成(Multimodal Instruction-based Generation)
- 支持多图+文本联合输入:可指定多个参考图像,并通过自然语言指令融合其内容。
- 保留身份与姿态一致性:在主体驱动生成(subject-driven generation)中表现最佳(尤其对具体对象,如人脸、角色)。
- 理解抽象属性:能从参考图中提取并迁移 材质、纹理、妆容、发型、姿势、设计风格、艺术风格 等难以用文字精确描述的特征。
- 优于商业模型:在抽象属性迁移任务上,性能超过部分闭源商业系统。
示例:用两张人物图 + 指令 “在飞船内景中握手”,生成一张新图,融合两人身份、姿势与场景。
(2)多模态指令驱动的图像编辑(Multimodal Instruction-based Editing)
- 突破纯文本编辑限制:允许用户上传“源图 + 参考图 + 指令”进行编辑。
- 保留非编辑区域严格一致:编辑任务强调对原图未修改区域的高保真保留(与生成任务本质区别)。
- 支持任意对象或属性引用:例如“把第二张图中的发型应用到第一张图的人物上”。
- 性能对标商业模型:在复杂编辑任务中达到接近或等同于商业系统的质量。
注意:源图像必须作为第一个输入图像(因训练数据格式要求)。
(3)统一的生成与编辑架构(Unified Model)
- 一个模型,两种模式:通过任务类型(生成/编辑)切换,共享底层多模态理解与生成能力。
- 任务解耦设计:尽管指令可能相似(如“让这个人穿西装”),但生成允许重绘全图,编辑则仅改动局部。因此系统明确区分两者,便于用户精准控制。
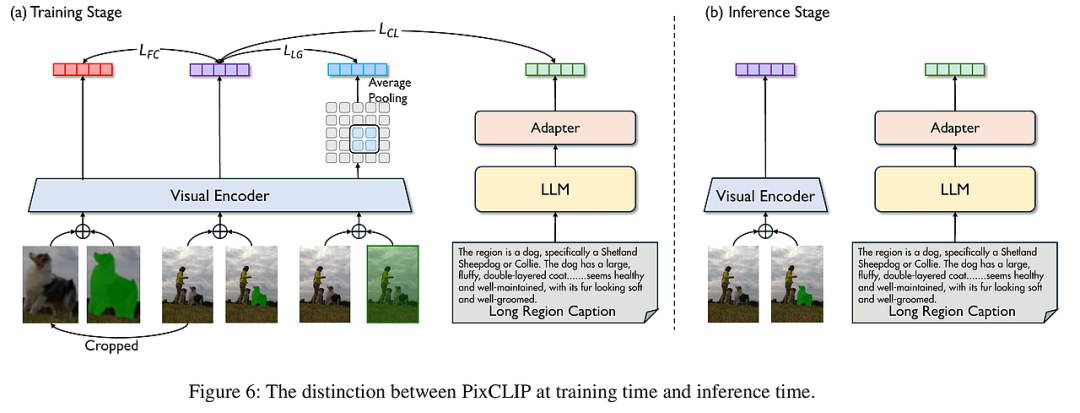
PixCLIP: Achieving Fine-grained Visual Language Understanding via Any-granularity Pixel-Text Alignment Learning
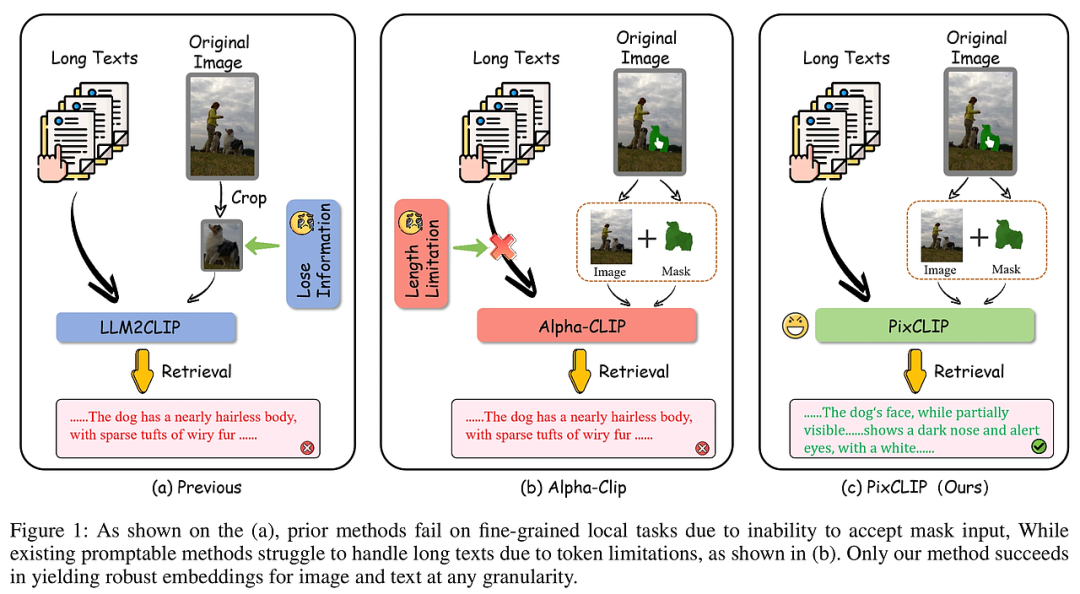
PixCLIP旨在解决现有CLIP模型在细粒度视觉语言理解上的局限,尤其是对局部区域的像素级文本对齐能力不足和处理长文本的能力受限。该模型创新性地支持任意粒度的图像局部区域(通过掩码输入)与复杂的长文本描述之间的对齐,突破了传统方法只能处理整体图像或简短文本的限制。为提升模型性能,研究团队构建了LongGRIT数据集,包含约150万条高质量、自动生成并由多模态大语言模型验证的细粒度掩码-文本对。这不仅增强了模型的区域级视觉理解能力,也保持了全局图像语义的兼容性,使PixCLIP成为一个更细致、更通用的视觉语言基础模型,适用于从像素级检索到开放世界识别的多样化任务。
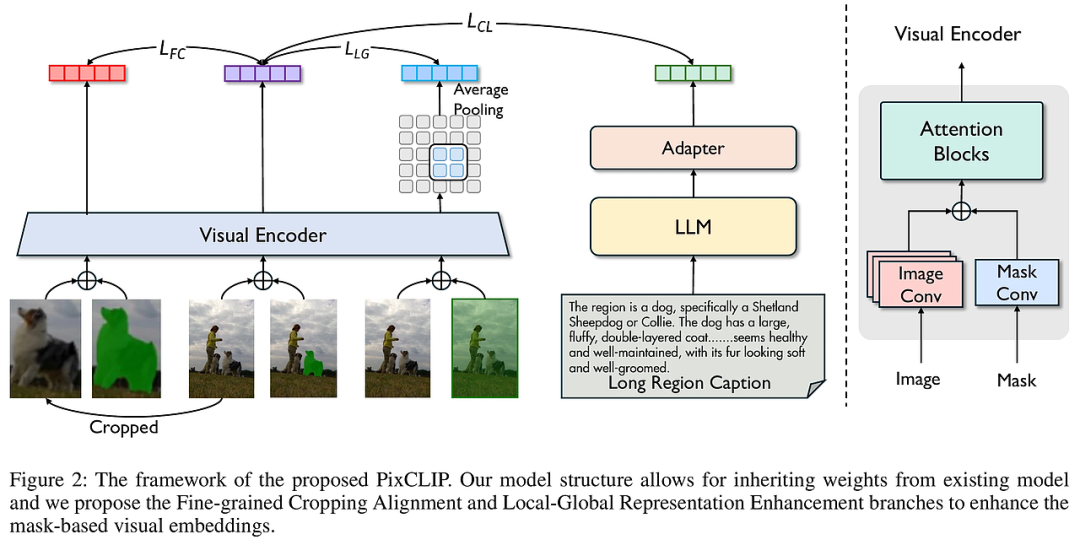
PixCLIP采用三大核心技术策略:
-
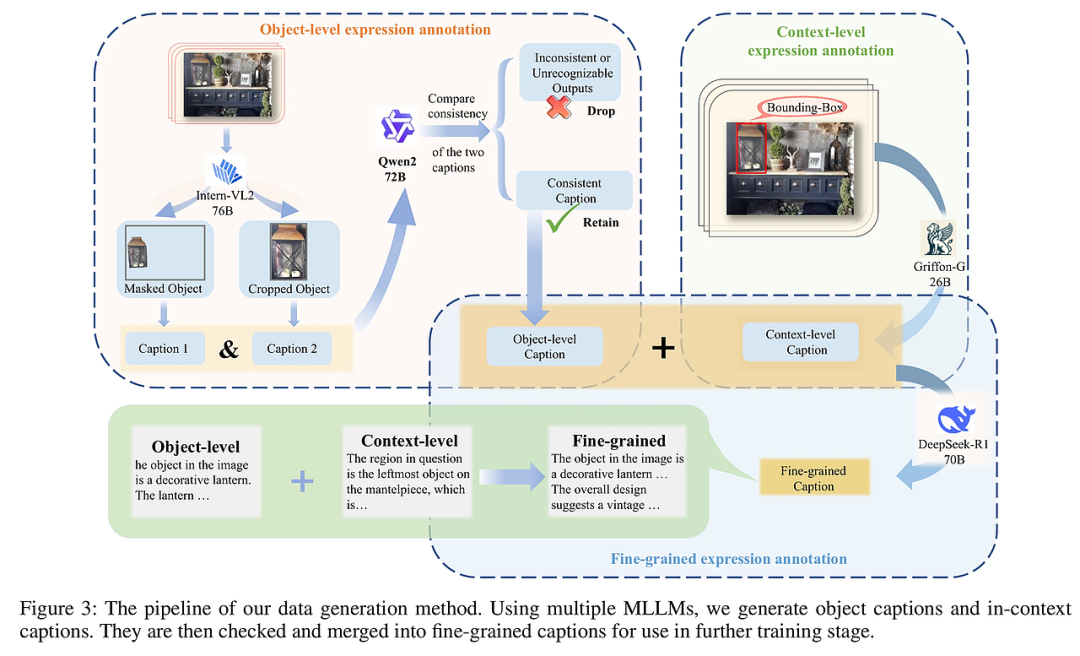
细粒度数据生成:基于GRIT-20M数据集,利用多模态大语言模型(MLLM)自动生成并验证细粒度的掩码区域文本描述,融合对象属性、空间上下文及细节描述,形成高质量长文本标注。
-
三分支像素-文本对齐框架:
-
掩码-文本对比学习:将输入的图像和掩码分别编码,通过对比学习使局部视觉特征与对应长文本对齐。
-
细粒度裁剪对齐:从图像中裁剪掩码区域,专注提取该局部的视觉特征,强化局部细节捕捉能力。
-
局部-全局表示增强:结合全图与局部掩码特征,相互补充,提升模型对上下文和局部细节的综合理解。
-
-
长文本处理与视觉提示融合:替换原CLIP文本编码器为强大的LLM(如LLAMA3-8B),支持处理复杂长文本,且通过并行掩码嵌入层实现视觉提示的无缝融合,兼顾全局与局部信息,提升对任意粒度图文对齐的适应性。
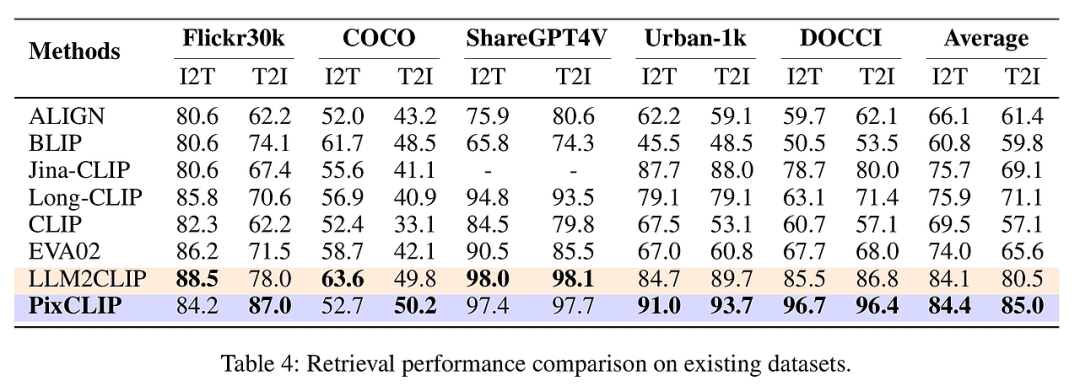
团队在多种细粒度区域识别与检索任务上评估PixCLIP性能,涵盖RefCOCO系列、Instance-COCO、ImageNet-S等像素级分类和检索任务。结果显示,PixCLIP在零样本区域分类准确率、掩码-文本检索准确率以及传统图文检索任务中均显著优于现有SOTA模型,如Alpha-CLIP和LLM2CLIP。尤其在处理长文本和复杂局部掩码时,PixCLIP表现出更强的细节捕捉能力和语义理解力。消融实验进一步验证了三分支训练框架中各个分支对性能提升的贡献,细粒度裁剪对齐和局部-全局增强显著提升了模型对局部区域的区分能力,同时不损失全局图像的理解能力。整体上,PixCLIP实现了细粒度与全局视觉语言任务的兼顾,展示了其作为统一视觉语言基础模型的潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)