【datawhale】Agentic AI学习笔记
本文探讨了Agentic AI的概念及其与AI Agent的区别。Agentic AI是由多个专业Agent协同工作的系统,能动态交互并实现高层次目标,而AI Agent是执行单一任务的个体。文章介绍了Agentic AI的组成要素,包括反思、工具使用、规划和多智能体协作等功能,并提出了两种评估方法:端到端评估和组件级评估。通过对比图例说明了两类系统在自主性和协作能力上的差异,为理解新一代AI系统
文章目录
基于datawhale的Agentic-AI共学以及吴恩达老师在 DeepLearning.AI 推出的 Agentic AI 系列课程
Introduction
定义definition
本质是AI,可以说是可以通过调用不同的agent来实现任务的AI
辨析:AI Agent 和 Agentic AI 区别
AI Agent本质是Agent,是可以利用AI的agent。FYI:Agent更多是强化学习中的概念,即与环境进行交互,执行action,得到rewards
如图(Sapkota et al.),AI Agent接收用户设定的温度值,并自主控制加热或冷却系统以维持目标温度。虽然它能够表现出一定的自主性,比如学习用户的作息时间或在无人时减少能耗,但它仅在孤立状态下运行,执行单一且明确的任务,而不涉及更广泛的环境协调或目标推断。
Agentic AI 系统——多个专业化 Agent 协同互动,管理诸如天气预测、日常安排、能源定价优化、安全监控以及备用电源激活等多种功能。它们不仅仅是响应式模块,还可以动态通信、共享记忆状态,并协同实现高层次系统目标。

“非智能体”&“智能体”工作流
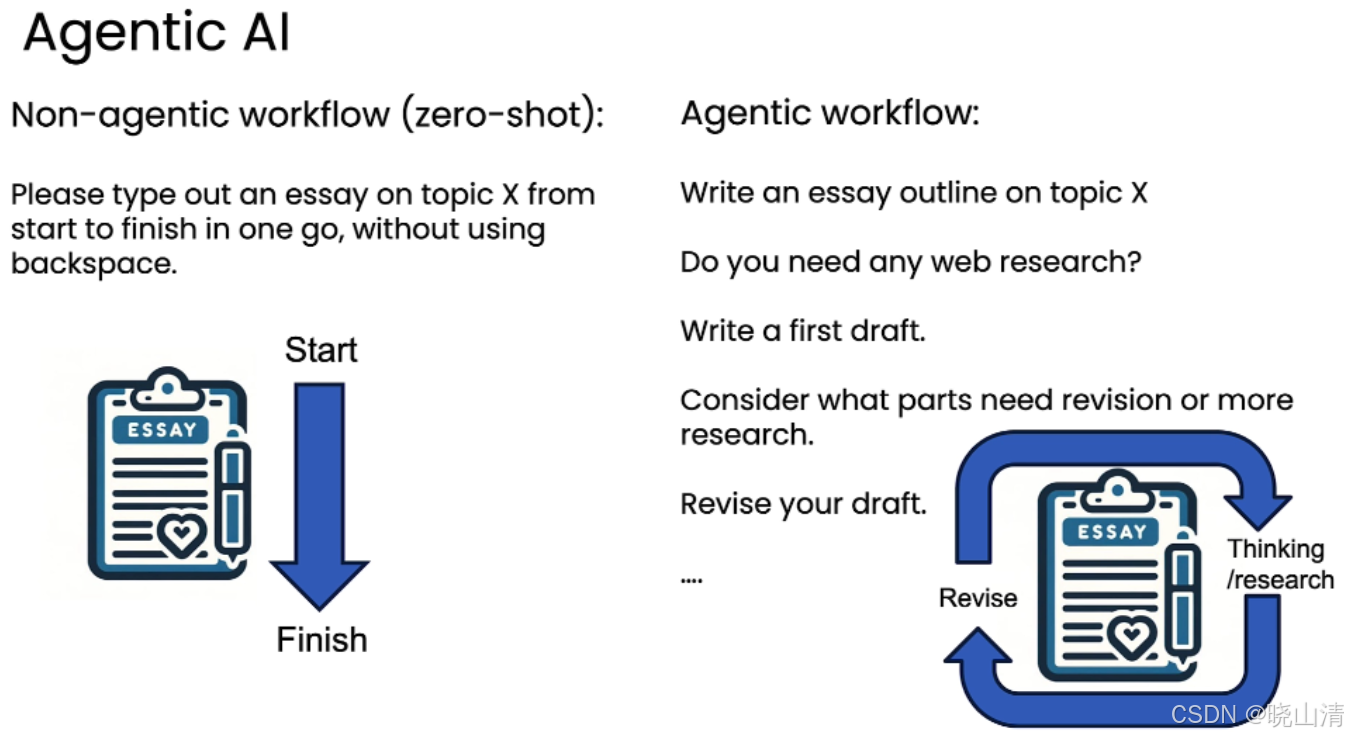
四种设计模式:
- 反思 (Reflection)
- 执行 - 工具使用 (Tool Use)
- 规划 (Planning)
- 多智能体协作 (Multi-agent collaboration)
R. Sapkota, K. I. Roumeliotis, and M. Karkee, “AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and Challenges,” Information Fusion, vol. 126, p. 103599, Feb. 2026, doi: 10.1016/j.inffus.2025.103599.
自主性degree of autonomy
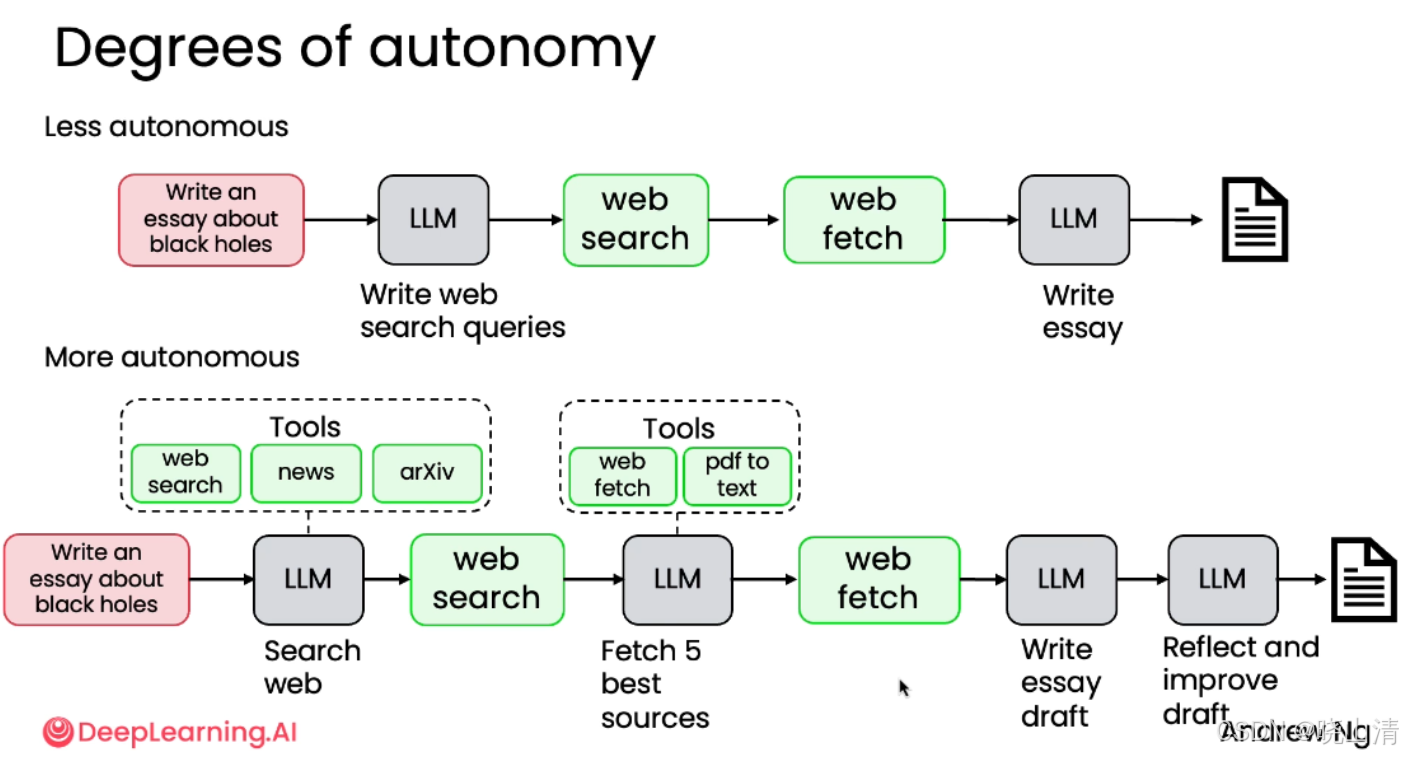
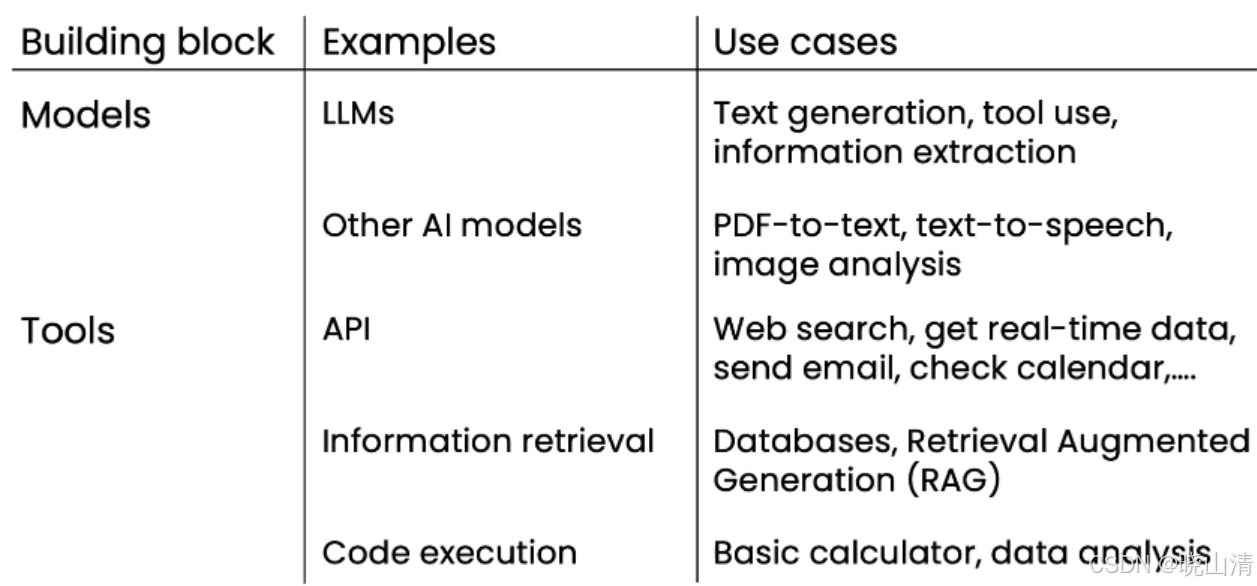
组成composition
评估evaluation
1、端到端评估 (End-to-end evals):衡量整个智能体最终输出的整体质量。
例如:评估一篇完整论文的最终得分。
2、组件级评估 (Component-level evals):衡量智能体工作流中单个步骤或组件的输出质量。
方法:
- 构建评估指标(量化指标便于统计,但要考虑到不可量化的因素)
- LLM as judge
反思(Reflection Design Pattern)
Reflection 是一种提示策略(prompt stategy)
工作流workflow
生成初稿 (Write first draft) → \rightarrow →反思与改进 (Reflect and write improved second draft)
例如,写邮件:
初始prompt是“Write an email…”,此时获得Email V1将第一版输出(Email V1)
再将prompt是Email V1+“review this email and improve it”发送给 LLM(可以是同一个模型,也可以是另一个专门用于推理的模型)
注:除了self-Reflection 外还可以结合外部反馈,比如说将 code V1、Output 和 Errors 一起作为prompt输入
编写反思提示的两大黄金法则:
- 明确指示反思动作 (Clearly indicate the reflection action):
- 不要含糊地说“请改进”,而要说“请审查”、“请检查”、“请验证”。
- 明确告诉模型你要它做什么,例如“审核电子邮件初稿”或“验证HTML代码”。
- 具体指定检查标准 (Specify criteria to check):
- 不要只说“让它更好”,而要列出具体的评判标准。
- 例如,在域名任务中,标准是“易发音”和“无负面含义”;在邮件任务中,标准是“语气专业”和“事实准确”。
- 这样做能引导模型围绕你最关心的维度进行深入思考和改进。
Notes:
- 反思机制并非万能,其效果因应用场景而异。在某些任务上提升显著,在另一些任务上则可能微乎其微。
- 在“性能提升”与“效率损耗”之间trade-off
执行-工具使用(Tool Use)
工具是什么(definition of tool)
工具即(预先写好的)函数,给模型自主决策使用。e.g.模型会选择需要使用某个工具,于是将需要的参数给这个函数,然后拿到函数的执行结果。
让模型自己写代码
与其让工程师逐个实现功能,不如让系统自己编写并执行代码来解决问题
-
设计系统提示词 (System Prompt):
- 指令模型:“编写代码来解决用户的问题”。
- 要求模型将答案以 Python 代码形式返回,并用
<execute_python>和</execute_python>标签包裹。
-
模型输出:
-
对于查询 “What’s the square root of 2?”,模型可能输出:
<execute_python> import math print(math.sqrt(2)) </execute_python>
-
-
提取与执行:
- 使用正则表达式等模式匹配技术,从模型输出中提取被标签包裹的代码。
- 在安全的沙盒环境中执行提取出的代码。
- 获取执行结果(例如
1.4142135623730951)。
-
反馈与格式化:
- 将数值结果传回给 LLM。
- LLM 根据原始问题,生成一个格式良好的最终答案(例如:“The square root of 2 is approximately 1.4142.”)。
Note:
- 在安全沙盒环境执行代码
- MCP协议
规划(Planning)
TBD
协作(Multi-agent collaboration)
TBD

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)