广东专升本计算机C语言
因为char和short都是一家人,都是整型家族的。所以要整型提升,也就是没有到int的字节长度的,在CPU的时候都变成int字节。1)输入:在算法中可以又零个或者多个输入2)输出:在算法中至至少有一个输出3)有穷性:任意一个算法在执行又穷哥计算步骤后必须终止4)确定性:算法的每一个步骤都具有确定的含义,不会出现二义性5)可行性:算法的每一步都必须是可行的下面就是2行3列的结构int main()
目录
学校的老师很喜欢出一些奇葩的题,专升本也喜欢出这种题,比如:
4)赋值操作符: = 、+= 、 -= 、 *= 、 /= 、%= 、<<= 、>>= 、&= 、|= 、^=
5)单⽬操作符: !、++、--、&、*、+、-、~ 、sizeof、(类型)
6)关系操作符: > 、>= 、< 、<= 、 == 、 !=
2)printf用%s输出时,写的是str,而不是str[0],str[1]等等
1.返回类void时,可以提前return;结束,return后面什么都不接
putchar和getchar以及scanf和printf还有gets和puts区别
引言:
两万六字的广东专升本知识点,对于一些易错的我也专门拿出来提了下,希望能对大家有帮助。大家可以通过目录来查漏补缺。但是这些东西只能对于期末考试或者专升本,对于就业是完全不够的。
一、编译与链接
1.计算机语言
美国人说美国话,中国人说中国话,计算机说计算机话,就有了自己的语言。
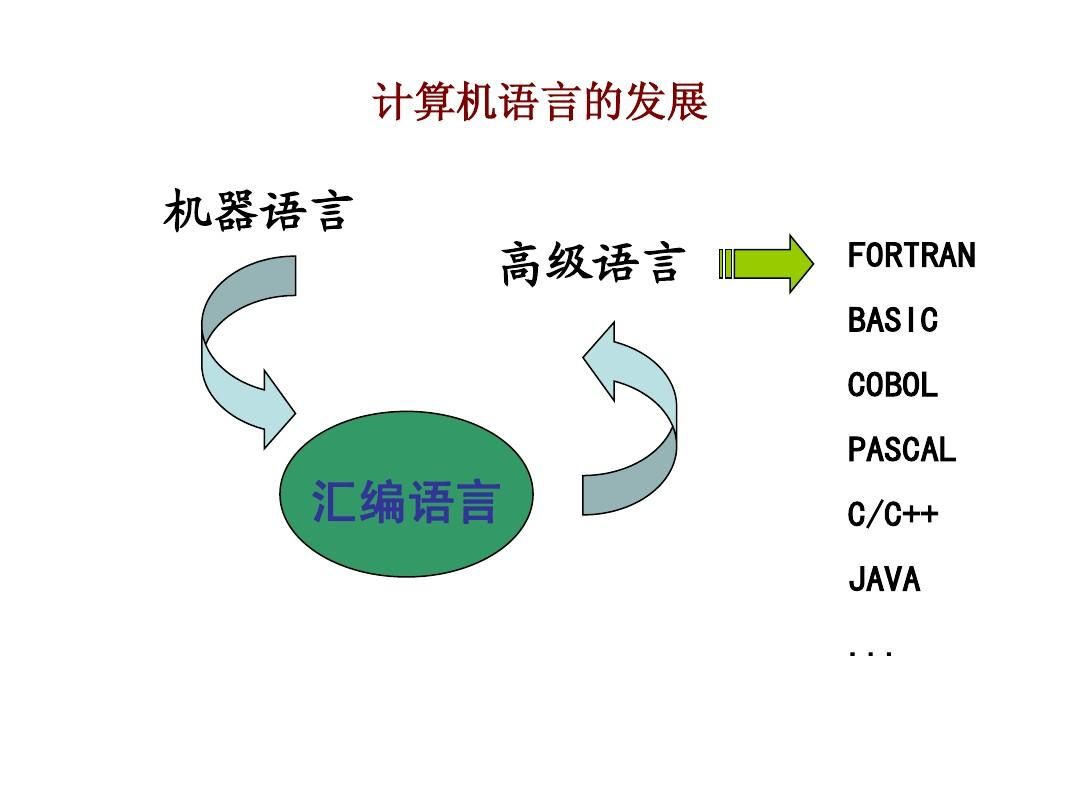
1)机器语言
计算机只会说机器语言,它是由0、1的二进制代码组成的。
字母“A”在ASCII编码中对应二进制“01000001”
2)汇编语言
机器语言不大方便读,就出现了汇编语言,让助记符代替这些指令与数据
3)高级语言
C语言、Java、python等就是高级语言,这种更加易读易修改,
类似于人类语言,但是不能被计算机直接执行,执行速度也慢一些。
2.翻译方式
C语言不能直接被计算机读取,而是要通过翻译变成目标代码才行。翻译有两种方式:
1)解释
一边翻译一边执行,不产生目标代码,比如说JS这种实时性的。
2)编译
全部翻译为用机器语言表示的目标代码,用的很广泛,C语言就是这种。
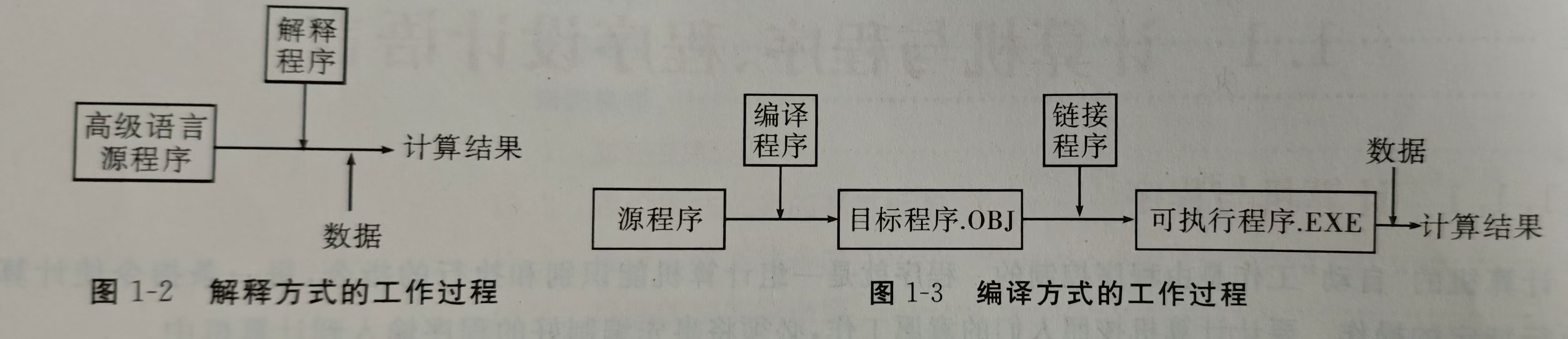
C语言的编译和链接过程:
通过编译变成目标文件(计算机看得懂的),然后通过链接变成exe文件(能在内存运行的)
二、进制
1)2进制
最简单,也是计算机看得懂的。只有0和1组成。满2(下一位)进1,一个0或者1就是1bit。
假设是一个字节(8个bit)存储5这个值的话,就是00000101,
因为101,如下图,也就是4+0+1=5

2)八进制
又0、1、2、3、4、5、6、7这八个数字组成,它不会和十进制或者16进制弄混,因为它会用开头为0提醒你,比如012,就是八进制的12
3)10进制
也是我们最熟悉的一个,但是十进制没有10,只有0123456789这十个数字。
4)16进制
由0123456789ABCDEF这16位组成,用的字符A代替10,后同。它和8进制一样,会有特殊字符提示,以0x开头,0xC指的就是十六进制的12
注意:这些都是通过ASCII值来让计算机识别的。DEC是十进制,而HEX是十六进制。如下图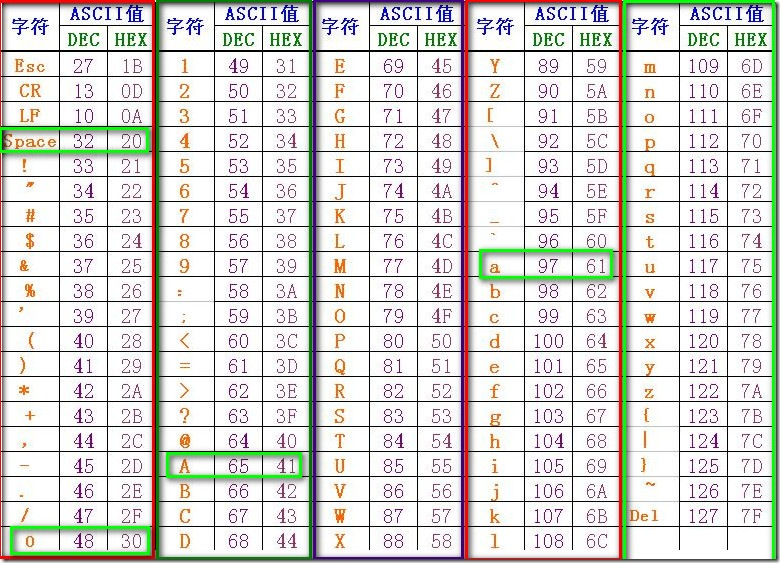
如果想要更加详细的,看下图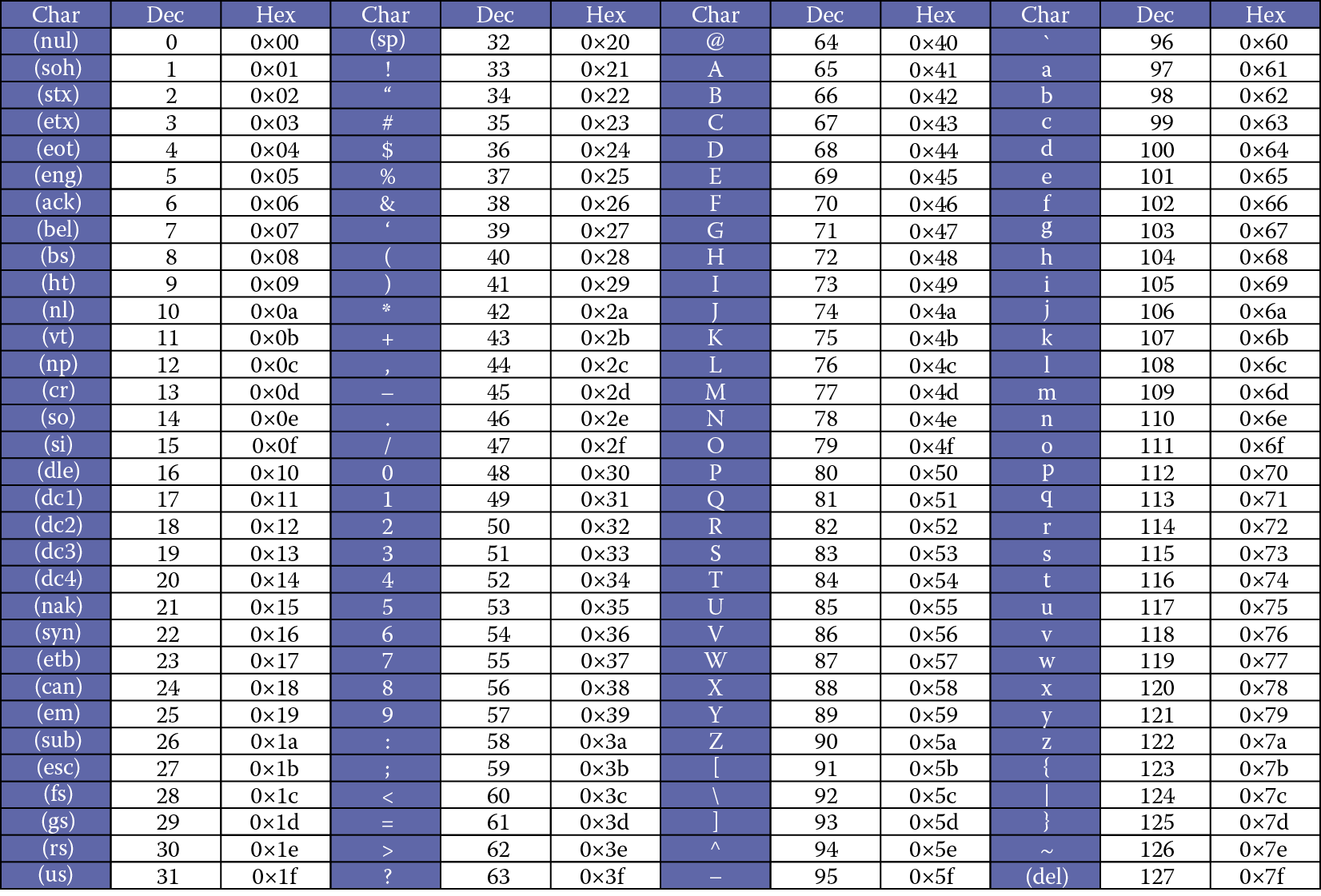
注意:有一些特殊的符号我们直接输入的,我们会考虑转义字符,用' '圈起来
八进制:\ddd
十六进制:\xhh
char A_char1 = '\x41'; // 十六进制41是十进制的65,是字符'A'
char A_char2 = '\101'; // 八进制101是十进制的65,是字符'A'进制转换
我们的8、10、16进制都需要转化为2进制供计算机识别,那么怎么转换呢,考试时,各种转换怎么转?
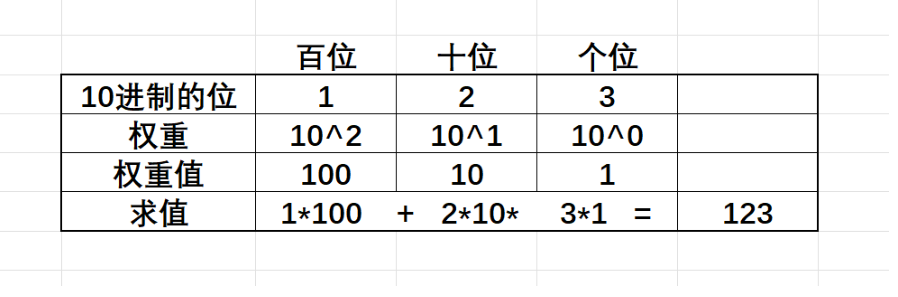
1)二进制转十进制
把每一位都用2^n表示,从右往前算
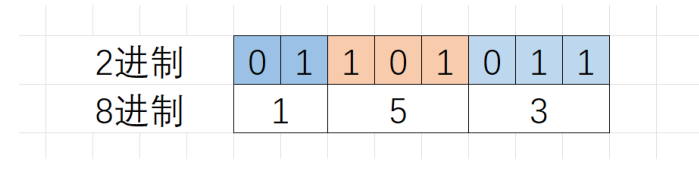
2)二进制转八进制(方法可互转)
因为3位二进制位就能表示所有八进制,比如八进制最多就是7,我直接用111就能表示了。
我们只需要把上面的图记住,就能直接配凑了,采用3-3-2的形式,如下:
二进制011 010 11的八进制为0153,前面 要加个0区分十进制
3)二进制转十六进制(方法可互转)
同样的,我们16位最高为F,只需要4位二进制位就能配凑出来了
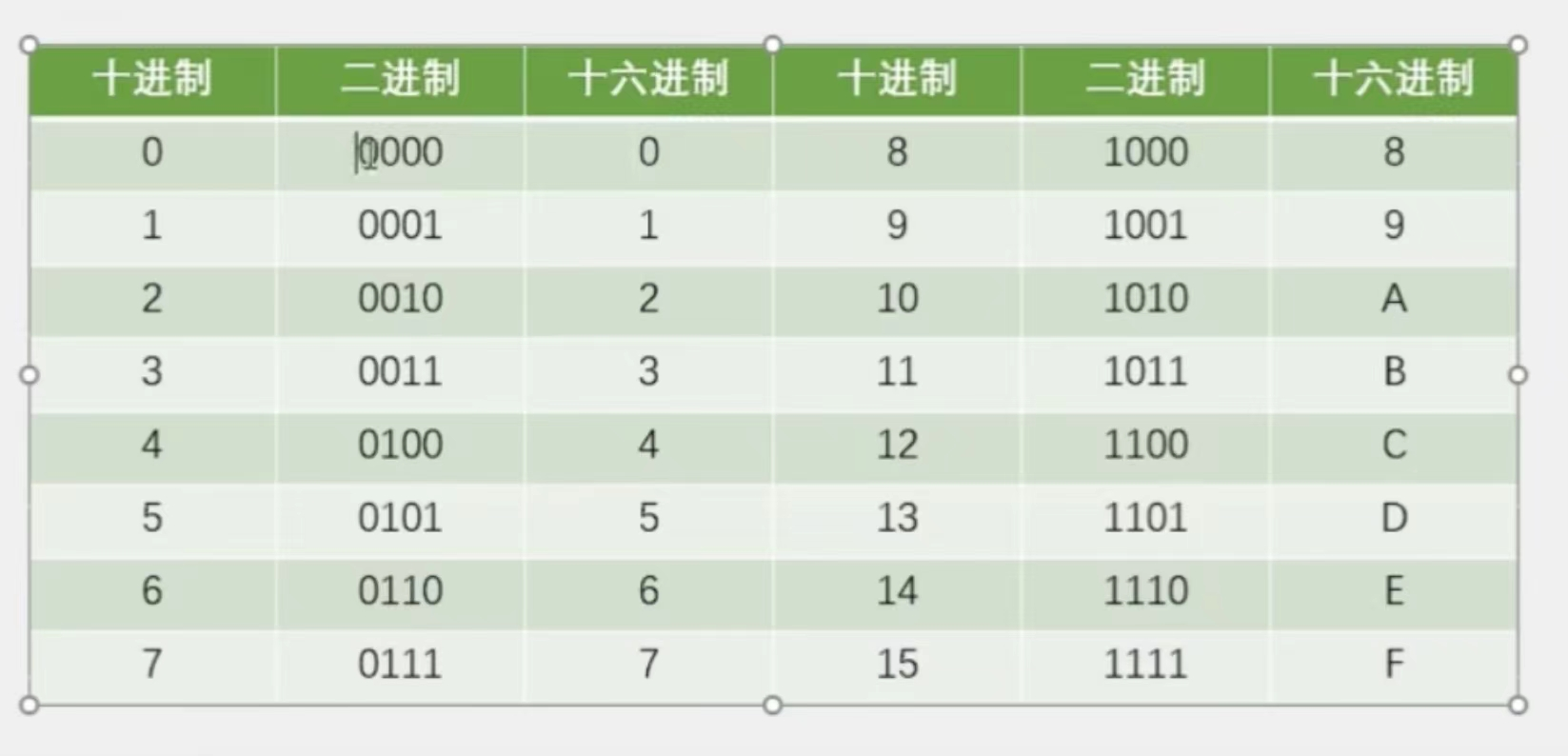
开始配凑,采用4-4,假设是0002 1110,则十六进制为0x2E(加0x区分十进制):

4)十进制转换二进制
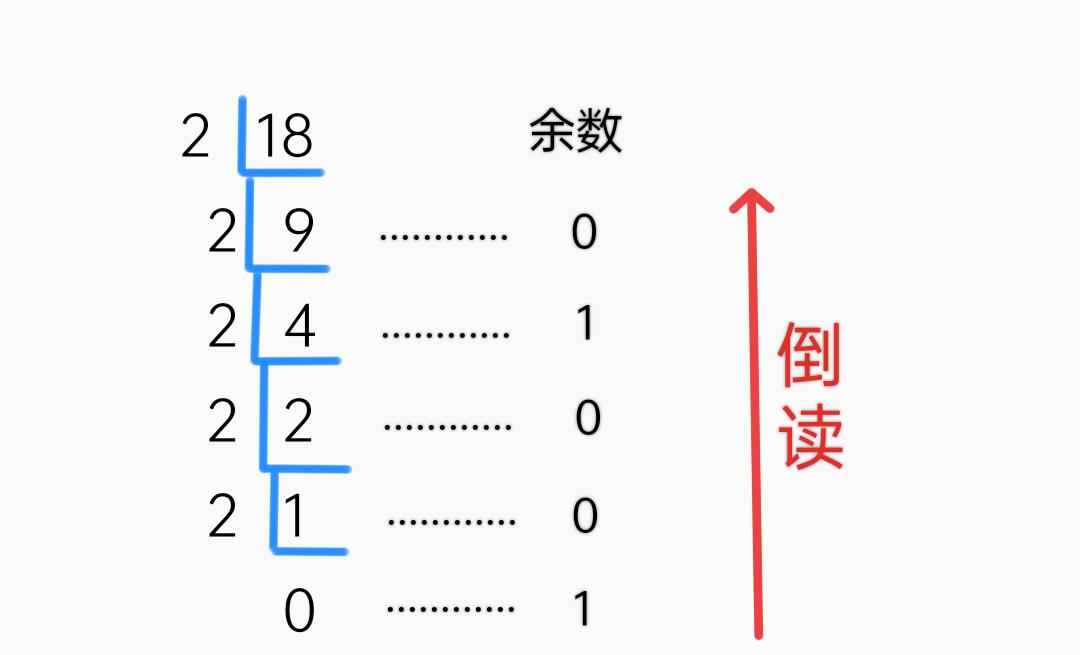
5)八进制、十六进制转十进制

6)十进制转八进制、十六进制
十六进制也如下,除16取模就好了

7)十六进制转八进制(方法一样):
先转成二进制,再转成八进制(十六进制)
三、原码、反码、补码
正数的原码反码补码,都一样的。负数的如下:
1)源码
比如说在一个字节中,
我们的数字-5(说的都是人类的十进制)就是二进制的10000101(第一位为符号位),
这个数就是原码,原原本本的没有加任何添加剂的.
2)反码
在原码的基础上,按位取反(符号位不变),反码为11111010
3)补码
反码+1,补码为11111011
为啥用补码计算?
计算机中只能进行加法计算,如果用原码计算的话:负数的计算1+(-1)就会出现问题,得出的答案为2而不是0
补码怎么推原码?
原码:补码取反+1
三、类型与变量
内置类型:就是我能直接用的,
自定义类型:就是我需要根据语法自己构建出来,
类型如下:
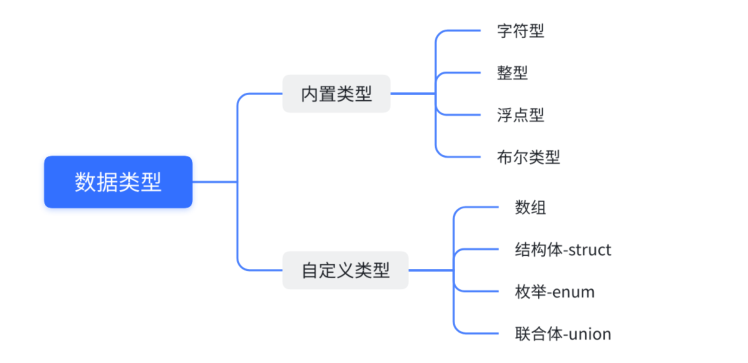
而类型分为有符号(signed)和无符号(unsigned),signed包括±,unsigned不包括±。
1)字符型
char (=signed char)
unsigned char一个字符类型1个字节,用''单引号,如:char ch='A';
2)整型
//短整型
short(=signed short)
unsigned short
//整型
int(=signed int)
unsigned int
//长整型
long(=signed long)
unsigned long
//更长的整型 c99引入
long long(=signed long long)
unsigned long long在VS2022 x64上,short为2字节,int为4字节,long为4字节,long long为8字节。int n=1;
为啥long为4字节
每个编译器的厂商制定的标准不一样,可能A厂就为4,B厂就为8。
在C语言语法中,long>=int的长度,在考试中,有争议性的题目是基本上不会出的。
3)浮点型
浮点就是小数,3.1415这种的
//单精度浮点型
float
//双精度浮点型
double
//更高精度的双精度浮点型
long doublefloat为4字节,double为8字节,long double为8字节,
语法中long double>=double,不同厂商规定的也不同。
float f=3.14,double d=3.3123
4)布尔型
bool
bool flag = true;
if (flag)
printf("hello");bool为1字节,值有false和true。
sizeof()
检测类型的长度,从上到下答案为4448,默认小数为double类型
int main()
{
int a = 10;
printf("%zd\n", sizeof(a));
printf("%zd\n", sizeof a);//a是变量的名字,可以省略掉sizeof后边的()
printf("%zd\n", sizeof(int));
printf("%zd\n", sizeof(3 + 3.5));
return 0;
}signed和unsigned类型的值范围
因为0也包括在正整数里,所以正数部分会-1
1)char
char占1个字节,也就是8个比特位,一个比特位有2个数(0和1)可以选择。
signed范围:-2^7 ~ 2^7-1 -> -128~127
unsigned范围:0 ~ 2^8-1 -> 0~255
2)short
short占2个字节,16个比特位
signed:-2^15 ~ 2^15-1 -> -32,768~32,767
unsigned:0 ~ 2^16-1 -> 0~65,535
3)int
int占4个字节,32个比特位
signed:-2^31 ~ 2^31-1 -> -2,147,483,648~2,147,483,647
unsigned:0 ~ 2^32-1 -> 0~4,294,967,295
其他的类推就行了。

强制类型转换:
我想打游戏,对象一定要让我逛街。强扭的瓜不甜就是强制类型转换。
int main()
{
//意思是将3.14强制类型转换为int类型,这种强制类型转换只取整数部分
int a = (int)3.14;
return 0;
}这玩意儿容易丢数据,慎用。
类型之间计算(CPU底层)
整型提升
定义
因为char和short都是一家人,都是整型家族的。
所以要整型提升,也就是没有到int的字节长度的,在CPU的时候都变成int字节。

如何整型提升+符号扩充
//负数的整形提升
char c1 = -1;
变量c1的⼆进制位(补码)中只有8个⽐特位:
1111111
因为 char 为有符号的 char
所以整形提升的时候,⾼位补充符号位,即为1
提升之后的结果是:
11111111111111111111111111111111
//正数的整形提升
char c2 = 1;
变量c2的⼆进制位(补码)中只有8个⽐特位:
00000001
因为 char 为有符号的 char
所以整形提升的时候,⾼位补充符号位,即为0
提升之后的结果是:
00000000000000000000000000000001
//⽆符号整形提升,⾼位补0如上面的代码,最后的结果还得再截断成11111111和00000001这两个就是c1和c2的结果。
如果要%d打印的话,还得继续放在内存上再一次整型提升。
算术转换
简单说,就是类型小的±类型大的,的时候怕出事,要都变成类型大的。
(char和short都变成int了)如下图,从下到上,进行算术转换。
long double
double
float
unsigned long int
long int
unsigned int
int!!!类型计算的练习题
1)同类型,比如char与char
CPU里面是补码:char有1个字节,
ch1为-1的话,就是11111111,整型提升11111111111111111111111111111111,
ch2为1的话,就是00000001,整型提升0000000000000000000000000001,
相加的话0000000000000000000000000000(第一位进一丢失数据),
把他装进char ch3,计算结果截断变成char长度:00000000(补码)->00000000(原码),
原码为0装进去ch3。
2)不同类型,比如char和int
char ch=1,int n=1。
那么ch为00000001,整型提升0000000000000000000000000001。
n为0000000000000000000000000001(不需要整型提升),
不用算术转换char(已经整型提升为int,不需要转了,如果是double和int就需要算术转换成double,为了不丢数据),
然后相加变成0000000000000000000000000010,也就是2。存char就截断,存int就不变。
3)同类型,有无符号的计算
unsigned int n1=1,signed int n2=-1,都是int或以上不用整型提升,
然后开始算术转换成unsigned int因为他的等级更高。
n1就变成00000000000000000000000000000001。
n2最开始补码是111111111111111111111111111111111111(signed),
如果变成unsigned的话就是4,294,967,295,符号位也算上值,
相加为00000000000000000000000000000000(补码),原码就为0,所以n3=n1+n2=0。
学校的老师很喜欢出一些奇葩的题,专升本也喜欢出这种题,比如:
int a=2;
printf("%d",a+'E'-'A');1)整型提升:'E'和'A'就变成了69和65(int)
2)计算:2+69-65=6
变量
计算机为了描述会经常改变的量,就创建了变量。
比如说,我们今年20岁,明年就多一岁了。还有温度,今天40度,明天广东下个大暴雨就30度了。这都都可以称为变量。
创建变量如下:
int age; //整型变量
char ch; //字符变量
double weight; //浮点型变量初始化:创建变量就给值
int age=20;
char ch='A';全局变量和局部变量
int b = 3;//全局变量
int main()
{
int a = 2;//局部变量
return 0;
}全局和局部名字相冲,优先局部
int b = 3;
int main()
{
int b = 2;
printf("b的值为:%d", b);//输出2
return 0;
}这些在内存存在哪里?
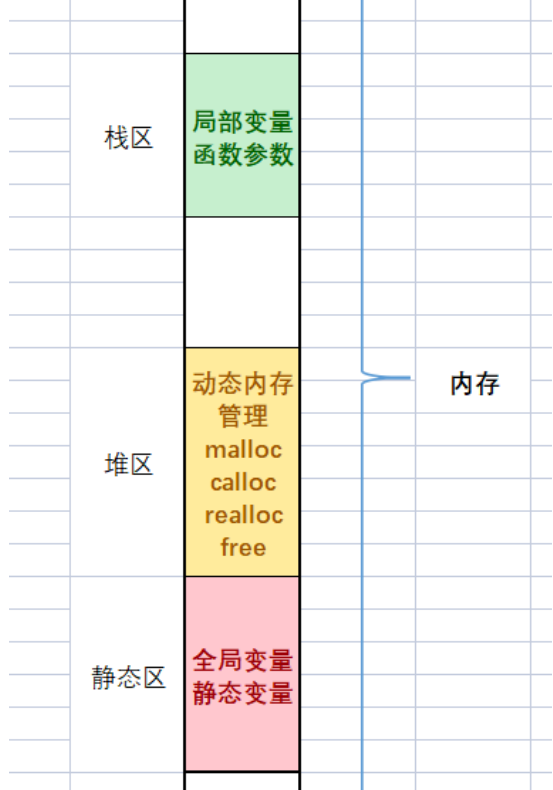
操作符
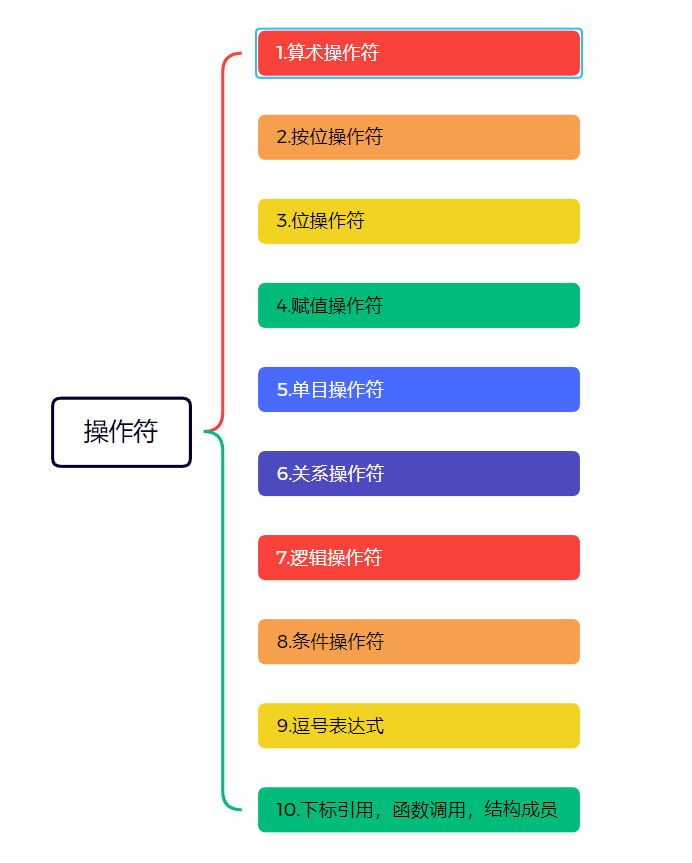
1)算术操作符: + 、- 、* 、/ 、%
+-*/上过小学的都知道,我们直接看代码:
int main()
{
int a = 2;
int b = 2;
printf("%d", a + b);//4
printf("%d", a - b);//0
printf("%d", a * b);//4
printf("%d", a / b);//1
}我们只需要知道,计算机就是为了算数学的计算,所以跟数学差不多。
我们讲点有区别的:
1)/ ,类型截断
int main()
{
int a = 13;
int b = 2;
double n = a / b;
printf("%d\n", a/b);//6
printf("%f\n", n);//6.000000
return 0;
}为啥不是6.5,有人说这不是用%d输出嘛,所以就是整数。
那后面我用double存起来,不也是6.000000嘛。为啥呢?
因为a/b先计算,两个int整数计算就为int答案,多出来的小数就截断。就是是先存到double的n也是会被截断的。如果要输出6.5,先变成double类型,这样就会算术转换,
如下:
double n = (double)a / b;2)/ ,输出格式和类型不匹配
int main()
{
int a = 13;
int b = 2;
printf("%f", a / b);//0.000000
return 0;
}大家就在想为什么不是6.000000,而是0.000000这个是大家都想不到的。
因为计算机是没有脑子的,它只是一个机器,执行你的指令。
你给的指令就是a/b压入栈为6(int类型只能得int),然后进行%f打印压入栈。
你要打印的时候是8个字节,然后你的值只有4字节,计算机就开始凑字数,往后面拿4个字节给你。
你也不知道这四个字节是啥数据。凑8个数据给你,输出0.000000是你运气好,差点的就是烫烫烫烫烫烫烫烫了。
3)/ ,负数
int main()
{
int n1 = -12;
int n2 = -2;
int n3 = 12;
int n4 = 2;
printf("%d\n", n1 / n2);//6
printf("%d\n", n1 / n4);//-6
printf("%d\n", n3 / n2);//-6
printf("%d\n", n3 / n4);//6
}4)%取模,不能为小数,可以为负数
int main()
{
int n1 = -13;
int n2 = -2;
int n3 = 13;
int n4 = 2;
printf("%d\n", n1 % n2);//-1
printf("%d\n", n1 % n4);//-1
printf("%d\n", n3 % n2);//1
printf("%d\n", n3 % n4);//1
}注意:负数取模时,只需要看被模数是不是负数,如果是就变成负数,不是就整数。
2)移位操作符: << >>
左移<<

右移>>
有两种方法,不同编译器不一样,更多的是算术右移
1)逻辑右移:左边⽤0填充,右边丢弃

2)算术右移:左边⽤原该值的符号位填充,右边丢弃

不要写一些bug,比如移动负数:
int num = 10;
num>>-1;//error3)位操作符: & | ^ ~
1.1)按位与&
二进制数字中,两个都为1才是1,不然的话为0
int main()
{
char ch1 = -1;
//原码:10000001
//反码:11111110
//补码:11111111
char ch2 = 2;
//原码:00000010
//反码:00000010
//补码:00000010
char ch3 = ch1 & ch2;
//ch1:11111111
//ch2:00000010
//ch1 & ch2(补码):00000010
//原码:00000010
printf("%d", ch3);//2
return 0;
}按位或|
二进制数字中,有一个是1的话就为1,两个为0才为0
int main()
{
char ch1 = -1;
//原码:10000001
//反码:11111110
//补码:11111111
char ch2 = 2;
//原码:00000010
//反码:00000010
//补码:00000010
char ch3 = ch1 | ch2;
//ch1:11111111
//ch2:00000010
//ch1 | ch2(补码):11111111
//原码:10000001
printf("%d", ch3);//-1
return 0;
}按位异或^
二进制位上数值相同为0,不同为1
int main()
{
char ch1 = -1;
//原码:10000001
//反码:11111110
//补码:11111111
char ch2 = 2;
//原码:00000010
//反码:00000010
//补码:00000010
char ch3 = ch1 ^ ch2;
//ch1:11111111
//ch2:00000010
//ch1 ^ ch2(补码):11111101
//原码:10000011
printf("%d", ch3);//-3
return 0;
}按位取反~
如果是0变为1,是1变为0,符号位也要取反
int main()
{
char ch2 = 2;
//原码:00000010
//反码:00000010
//补码:00000010
char ch3 =~ ch2;
//ch1:11111111
//ch2:00000010
//~ch2(补码):11111101
//原码:10000011
printf("%d", ch3);//-3
return 0;
}4)赋值操作符: = 、+= 、 -= 、 *= 、 /= 、%= 、<<= 、>>= 、&= 、|= 、^=
剩下的都差不多,自己改一下符号就行了。
int main()
{
int a = 1;//1
a = 2;//2
a += 2;//4 ->a=a+2
a -= 1;//3 ->a=a-1
int b=0;
a=b=3//连续赋值,c语言是支持的(3赋值给b,b赋值给a)
return 0;
}5)单⽬操作符: !、++、--、&、*、+、-、~ 、sizeof、(类型)
+正值,-负值,&取地址,*指针,sizeof(可以看前面的内容)
!非
int main()
{
if (!0) {
printf("hello");
}
return 0;
}前置++和前置--
int a=1;
//先++,再赋值
int b=++a;//a=2后b=2
//先--,再赋值
b=++a;//a=1后b=1后置++和后置--
int a=1;
//先赋值,再++
int b=a++;//b=1后a=2
//先赋值,再--
b=a--;//b=2后a=16)关系操作符: > 、>= 、< 、<= 、 == 、 !=
比较两个数字的关系:>=和<=(≥和≤),==就是(3=3),(3!=4)和数学是差不多的
7)逻辑操作符: && 、||
两个一起是&&,只需要一个就行||
int main()
{
if (3==4||3==2) {
printf("hello");//不打印
}
return 0;
}8)条件操作符: ? :
三目表达式,如果?前面成立,输出第二个表达式,不成立输出第三个表达式
int main()
{
int a = 9;
if (a > 0 ? a : 0) {
printf("a大于0");
}
return 0;
}9)逗号表达式: ,
从左往右依次执行,但是只会结果为最后一个逗号后面的表达式
int main()
{
int a, b;
printf("%d", (a = 1, b = 2, a + b));
return 0;
}10)下标引⽤[]、函数调⽤ ()、结构成员
下标索引:操作数组
int main()
{
int arr[3] = { 1,2,3 };
arr[0] = 2;
printf("%d",arr[0]);
return 0;
}函数调用,比如int main()
结构成员:后面讲
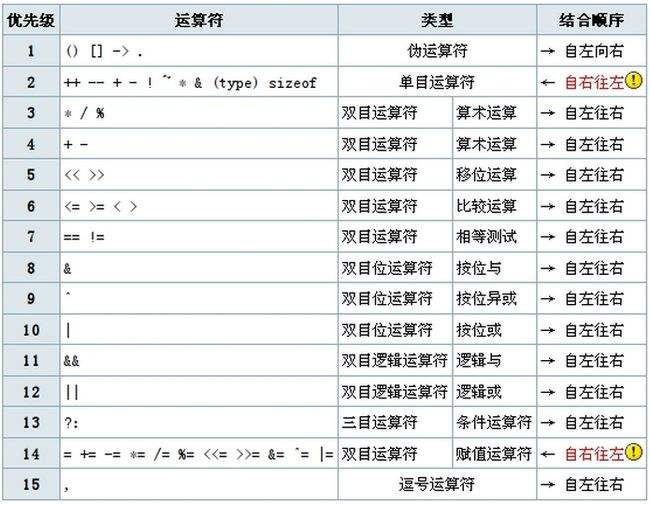
操作符的优先级和结合性
优先级:根据级别,看看谁先算,下面就是4 *5先算,优先级高,跟数学差不多吧
int n = 3 + 4 * 5;结合性:级别相同时,从左到右算,先5*6再/2
int n = 5 * 6 / 2;优先级排行榜:
scanf和printf
都是格式化的输入输出
这两种属于别人写好的,我们可以直接用的函数,使用的话得说明是哪里来的,需要在代码前这样写,standard input output(标准输入输出流)
#include <stdio.h>printf
用法
#include <stdio.h>
int main()
{
printf("hello world");
return 0;
}如上图,光标会停在d后面这里。如果你想要停在下一行就可以加\n,或者换行都能用\n
占位符
下面输出的内容都是一样的:我今年10岁。
int main()
{
//printf("hello world");
printf("我今年10岁\n");
printf("我今年%d岁\n",10);
int a = 10;
printf("我今年%d岁\n", a);
return 0;
}相当于你在排队,去丢了个垃圾,让你兄弟帮你占位,你回来还是那个位置,就你兄弟就是占位符。
多个占位符
printf("%s今年%d岁了", "zhangsan", 12);常见的占位符
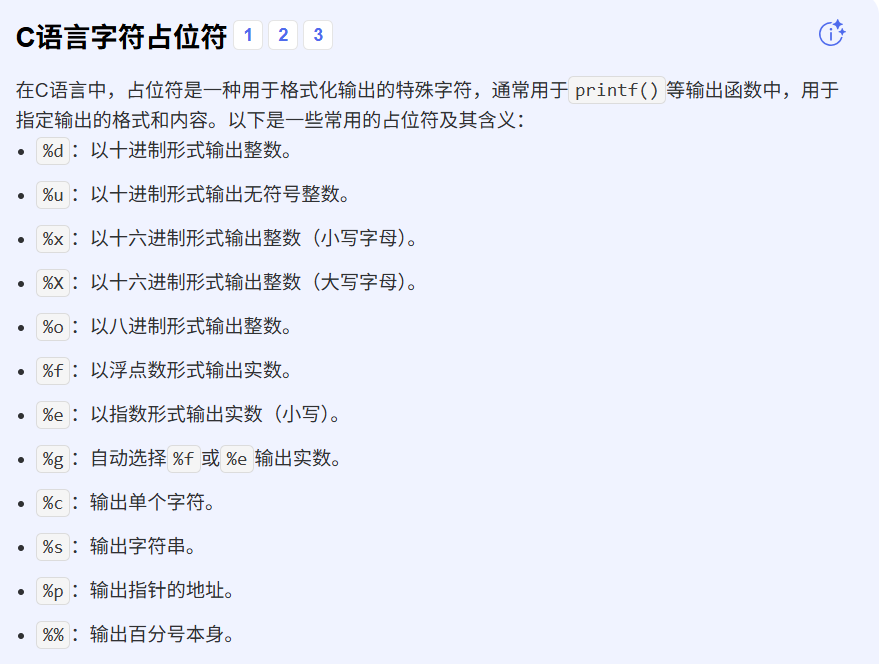
常见的如上,日常使用基本够了,不够的话再上官网查就行了。
输出格式
最小宽度:允许占位符的最小宽度。

上面的其实123的前面有2个空,加123就是5个,默认右对齐。
若希望左对齐,加个-号

保留几位小数

小数后面默认显示6位,小数点算一位,所以前面还有2个空格
显示正负号
printf("%+d\n", 12); // 输出 +12
printf("%+d\n", -12); // 输出 -12只针对小数点位(加.)

scanf
用法
占位符+&取地址(scanf传递的不是值,而是地址,将变量 age 的地址指向⽤⼾输⼊的值)
int main()
{
int age = 0;
scanf("%d", &age);
printf("age为%d", age);
return 0;
}对scanf的一些理解
1)必须加
#include <stdio.h>2)开头过滤空白字符
scanf("%d%d%f%f", &i, &j, &x, &y);不管开头是空格、tab键、换行等等,都不影响数据

如果是已经输入一个数据之后,你必须用“空白字符”来隔开不同的数据
注意:除了 %c 以外,都会⾃动忽略起⾸的空⽩字符。空白字符也是字符。
3)格式匹配
错误示范

你scanf要什么格式,你就得用什么格式

4)返回值
就是成功输入的多少个数据,用 int 接收
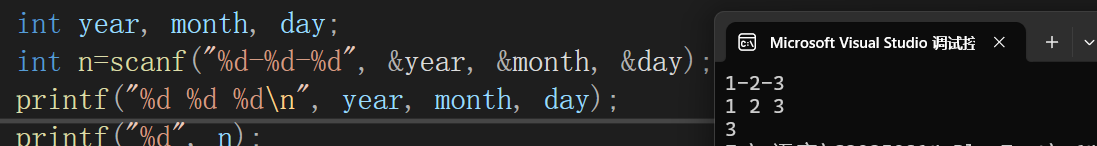
如果一个都不输入,将为-1

算法
定义:就是要计算机做的事情的代码步骤
特征:
1)输入:在算法中可以又零个或者多个输入
2)输出:在算法中至至少有一个输出
3)有穷性:任意一个算法在执行又穷哥计算步骤后必须终止
4)确定性:算法的每一个步骤都具有确定的含义,不会出现二义性
5)可行性:算法的每一步都必须是可行的
表示:
1)流程图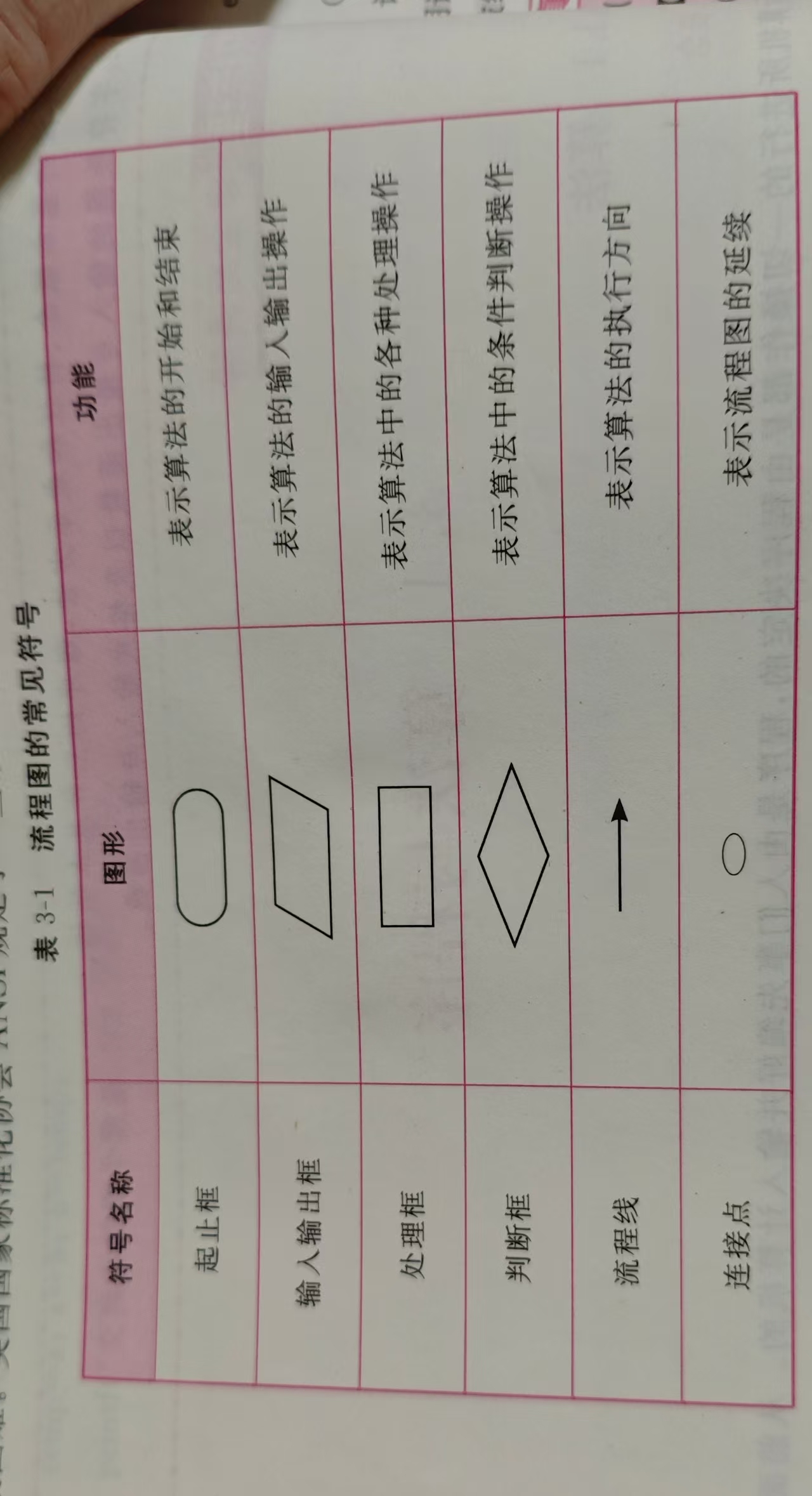
2)N-S图
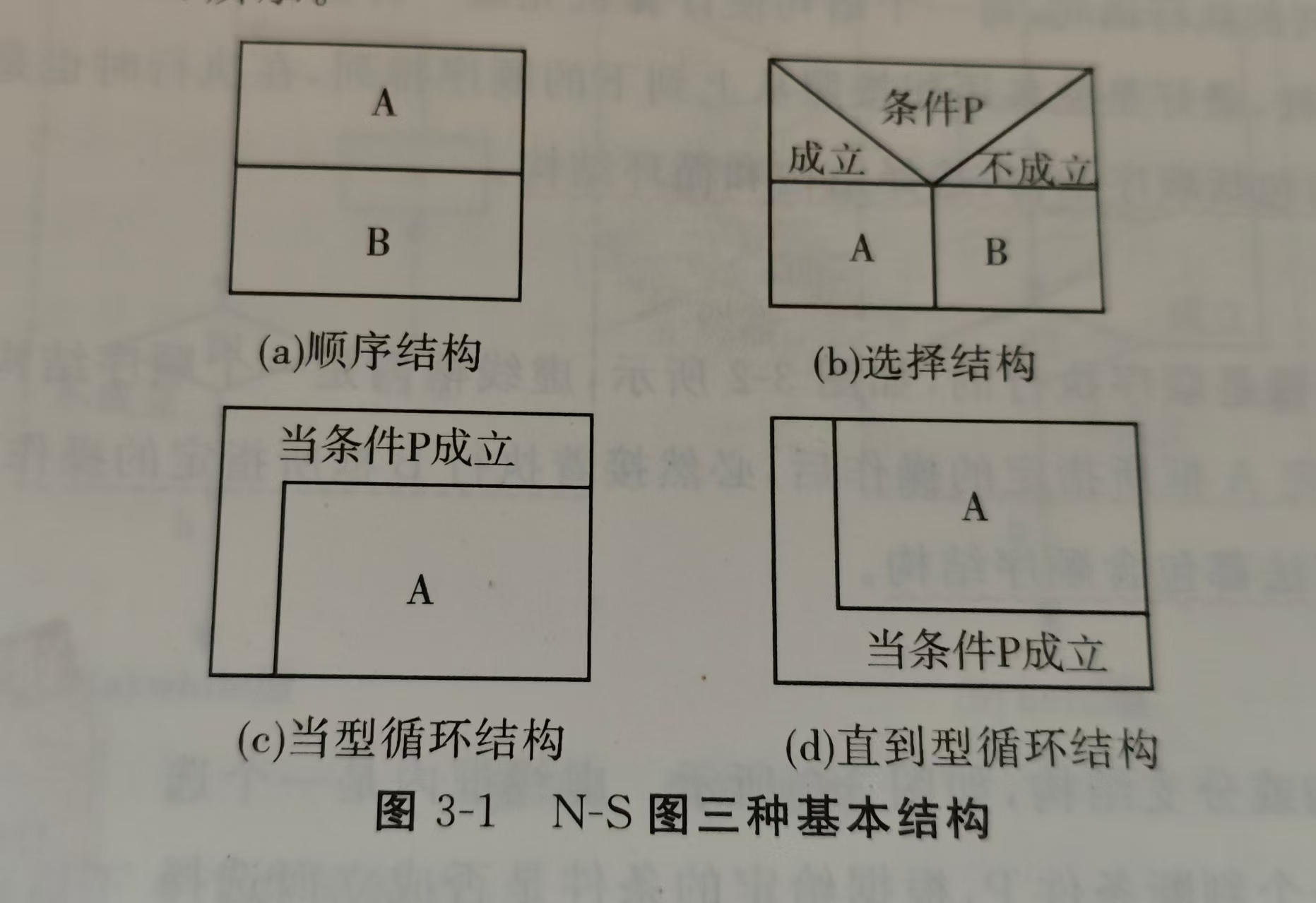
3)伪代码
4)计算机语言
就是我们现在写的C语言的代码等等
算法+数据结构=程序
这么理解:数据结构提供底层基础,算法就是建设,也就是上层结构
IO流,输入输出
putchar和getchar
用于字符的输入输出
int main()
{
//getchar从键盘输入一个char送给a
char a = getchar();
//将char a输出
putchar(a);
return 0;
}当你敲下字符时,并非敲一个字符就直接送给计算机,
而是先存进缓存区,等着按下enter的时候,才送到内存中供计算机享用,这对于scanf也适用。
程序结构
1)顺序结构
没啥好讲的,也是最简单的。一行一行执行就是顺序结构,比如说写100行printf就是顺序结构
#include <stdio.h>
int main()
{
printf("hello world");
return 0;
}2)分支(选择)结构
if语句
真就执行,假就不执行。
if (12 % 2 == 0)
printf("我可以被2整模");注意:在C语⾔中,0为假,⾮0表⽰真
在N-S图如下: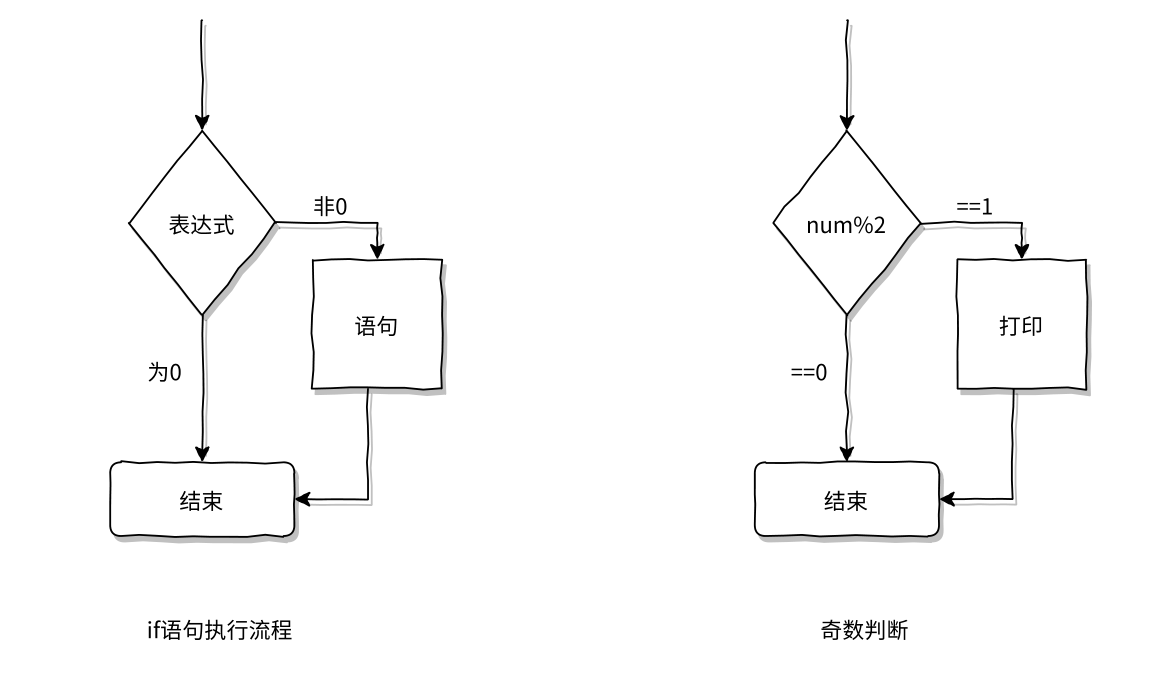
其他情况else
if (12 % 2 == 0)
printf("我可以被2整模");
else
printf("我不能被2整模");else只能与最近的if进行匹配
if和else有多条语句
这时候需要用大括号阔起来,美观又漂亮
int age = 16;
if (age >= 18) {
printf("成年了");
printf("可以考驾照");
}
else {
printf("没有成年");
printf("不能考驾照");
}如果不用括号括起来呢?(它判定可以考驾照和下一条if同级别)
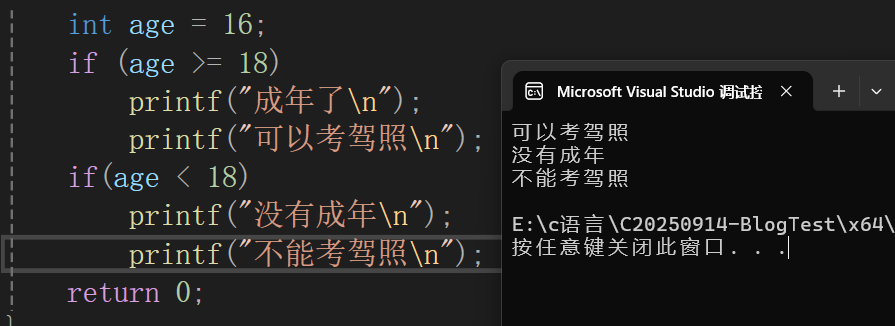
如果是else将会报错,因为没有if跟他关联,它已经断开了。

嵌套if
if里面还有if,像俄罗斯套娃
int main()
{
if (1 != 2) {
if (2 != 3) {
//...
}
}
return 0;
}switch
也是分支的一种写法,对于某些场合是if的升级版本。
里面switch()里面只能是数值和字符,绝对不能是小数。case也是如此。
int main()
{
int day;
scanf("%d", &day);
switch (day)
{
case 1:
printf("周一");
break;
case 2:
printf("周二");
break;
case 3:
printf("周三");
break;
case 4:
printf("周四");
break;
case 5:
printf("周五");
break;
case 6:
printf("周六");
break;
case 7:
printf("周日");
break;
}
return 0;
}注意事项:记得写break,不然的话:
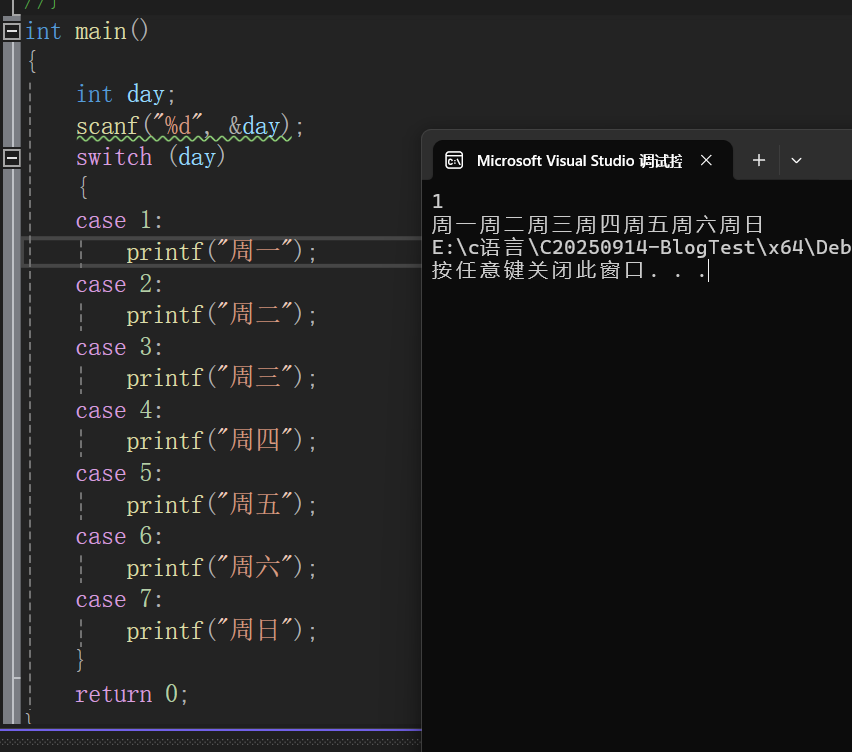
上面现象叫case穿透,
没有break它就会继续执行。
也可以应用在一些多个都需要统一输出的时候:
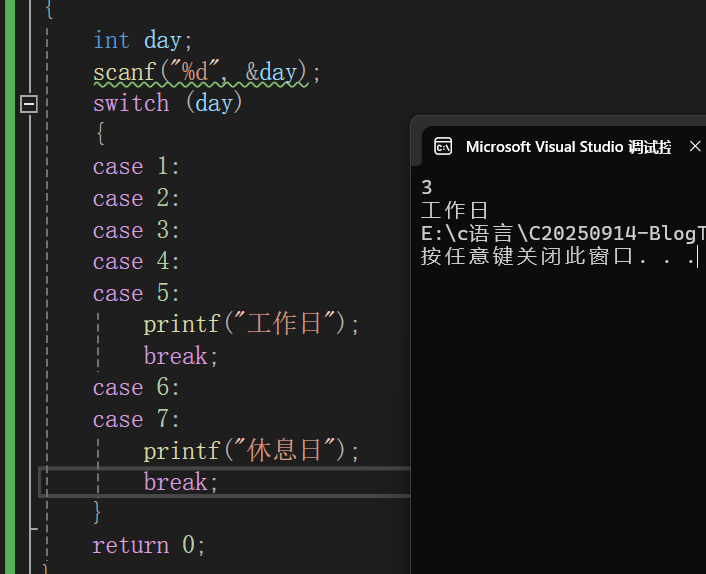
default
如果输入不符合规定的输入,比如18,没有周18,这个是错误的。我们可以default来规范。
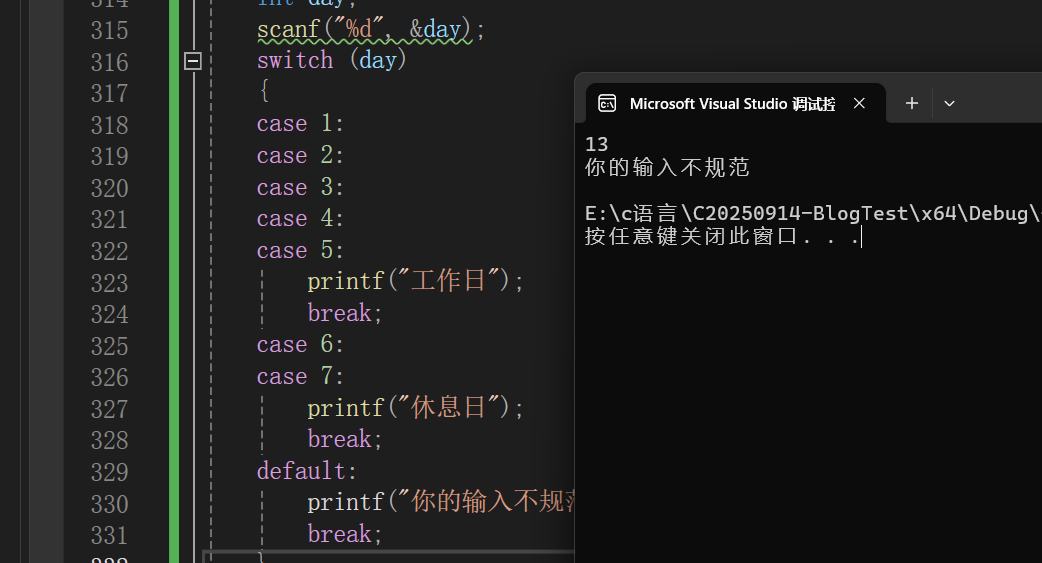
case和default颠倒顺序也是可以的,没有硬性要求。
但是为了美观还是建议把case放前面,default放后面。
循环结构
while
最简单的一种循环,while里面为真就循环,为假就退出循环
int main()
{
int i = 1;
while (i < 10)
{
printf("%d ", i);//1 2 3 4 5 6 7 8 9
i++;
}
return 0;
}break和continue
break终止循环
int main()
{
int i = 1;
while (i < 10)
{
if (i == 2) {
break;
}
printf("%d ", i);//1
i++;
}
return 0;
}continue跳出这次循环,开始下次循环
int main()
{
int i = 1;
while (i < 10)
{
if (i == 2) {
continue;
}
printf("%d ", i);//1 死循环
i++;
}
return 0;
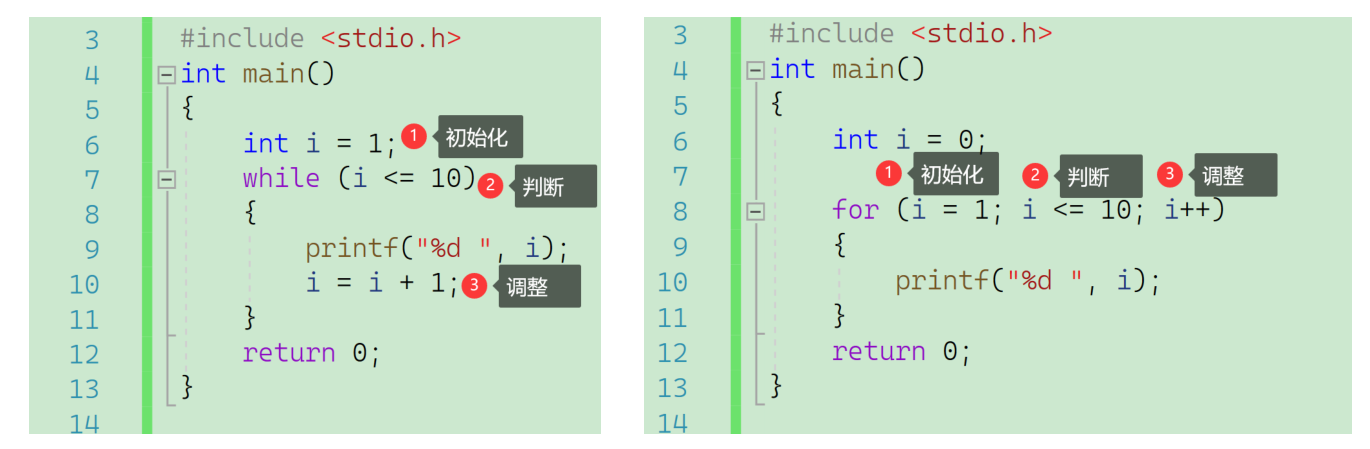
}for循环
while循环的pro版本,使用更方便,频率高
for里面有两个表达式,第一个是初始条件,第二个是要遵守的条件,第三个是变化的条件
int main()
{
for (int i = 1; i < 10; i++) {
printf("%d ", i);//1 2 3 4 5 6 7 8 9
}
return 0;
}注意哦:i=1的时候要先执行一次,执行完再回来for的时候,执行i++,看看i<10不,为真才能进来。
同样的,break和continue也适用,跟while是差不多的
int main()
{
for (int i = 1; i < 10; i++) {
if (i == 4) {
continue;
}
printf("%d ", i);//1 2 3 5 6 7 8 9(少个4)
}
return 0;
}为啥跟while那个答案不一样?
因为这个先i++,while那个是i==4之后继续循环,还等于4,一直执行不到i++。
while与for的区别:
do...while
先执行一次的while,先do一次再判断(没有开车~~)
举例场景:假设我需要判断我输入的数是几位数,比如1234是4位,2是一位。code如下:
int main()
{
int a,count=0;
scanf("%d", &a);
do
{
count++;
a /= 10;
} while (a);
printf("%d", count);
return 0;
}为啥要用do...while,因为while的话假设我输入0,就跳出循环了。
如果是dowhile的话,就算是0也会先do一次count++一次,为1。
continue和break也适用,具体的大家可以根据实际场景来书写。
循环嵌套
找出1-100的素数
素数:大于1,只能被自己和1整除,其他都除不了,比如7
int main()
{
for (int i = 2; i <= 100; i++)
{
int flag = 1;
for (int j = 2; j < i; j++)
{
if (i % j == 0)
{
flag = 0;
break;
}
}
if (flag == 1)
{
// 2 3 5 7 11 13 17 19 23 29 31 37 41
// 43 47 53 59 61 67 71 73 79 83 89 97
printf("%d ", i);
}
}
}为什么是模,而不是除。因为除的话,2/3的话就是0了
数组
我们需要一个变量就是int a,char ch等等。如果我需要十个,那么我要定义a1,a2....a10等等太麻烦了,这时候数组就出现了。
数组就是把相同类型的变量都放在一起,用法如下:
int arr[10];
char chs[10];
double d[10];
定义的长度必须是整型,不能是3.14这些,也不能是变量。
虽然c99中可以用变量,但是很多编译器都不允许用,并且如果考试考到的话,也是选不可以用变量的。
初始化
在定义的时候就给值,就叫初始化
//完全初始化
int arr1[5] = { 1,2,3,4,5 };
int arr[]={1,2,3,4,5};//直接给定值,可以不用长度
//不完全初始化
int arr2[5] = { 1 };当第二种初始化时,只有一个元素有值,其他自动都填充为0。
如果不初始化,里面的值是随机的,也就是垃圾值(可能上个程序留下的等等,但如果你打断点的话一般都是-858993460,int数组的话)
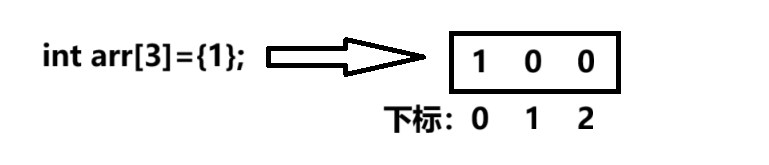
怎么操作数组
我们使用的是下标,用下标来找到各个数据的位置

为什么下标从0开始?
因为指的是内存中的偏移量,第一个数据就是arr的地址,所以偏移量为0
如下:
int arr[5] = { 1,2,3,4,5 };
printf("%d", arr[1]);//打印2打印数组
int arr[10] = { 1,2,3,4,5,6,7,8,9,10};
int i;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}输入与打印
int arr[10];
int i;
for (i = 0; i < 10; i++)
{
scanf("%d", &arr[i]);
}
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}数组在内存中

可以看到,在内存中的地址是连续的,也就是数组其实是申请了一块连续的空间。
int main()
{
int arr[10] = {0};
printf("%d\n", sizeof(arr));//40
return 0;
}输出40,以字节的单位。也就是说arr的类型大小:类型*个数
下面就是计算数组个数的方法
int main()
{
int arr[10] = {0};
int sz = sizeof(arr)/sizeof(arr[0]);
printf("%d\n", sz);//10
return 0;
}二维数组
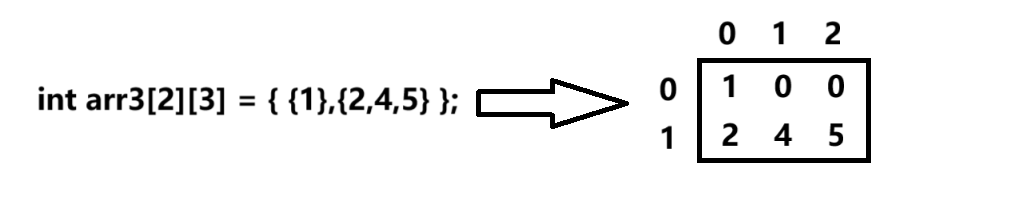
类似于矩阵,我们的买的商品房,一楼二楼,101,102,201,202这样的,如下图。

定义:
下面就是2行3列的结构
int arr[2][3];
char chs[2][3];初始化
int arr1[2][3] = {1,2,3,4,5,6};
int arr2[][3] = {1,2,3,4,5,6};//可以不给行,根据列就能算出行
int arr3[2][3] = { {1},{2,4,5} };//给特定行赋特定值能省略行,不能省略列,因为可以根据列来推出行,有4个值,分2列,那只能是2行。
如果初始化一个值,剩下没有初始化的都是0,如果一个值都没初始化,那就是随机值,可能烫烫烫
操控二维数组
int main()
{
int arr[3][5] = { 1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7 };
printf("%d\n", arr[2][4]);//7
return 0;
}打印二维数组
int main()
{
int arr[3][5] = { 1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7 };
int i, j;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}二维数组的存储
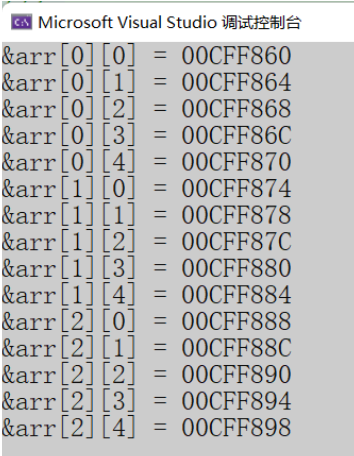
虽然我们看的是分行的,但是实际上,他们是连续的,就算是二维数组也是连续的。因为都是int类型的四字节,间隔都是四字节。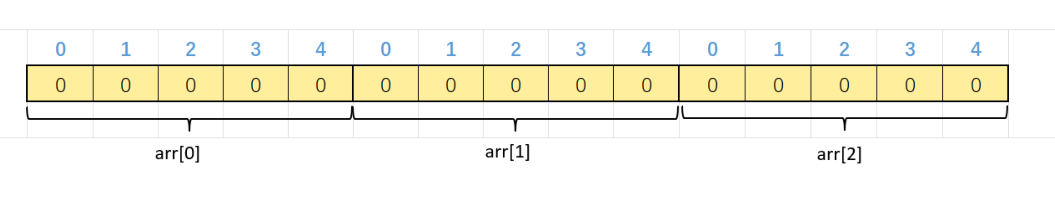
字符类型与字符串
其实就是一维数组里面放字符
int main()
{
char chs[5] = { 'h','e','l','l','o' };
int i;
for (i = 0; i < 5; i++)
{
printf("%c", chs[i]);//hello
}
return 0;
}二维字符数组
打印三角形
int main()
{
int i, j;
char chs[2][3] = { {' ','*'},{'*',' ','*'} };
for (i = 0; i < 2; i++)
{
for (j = 0; j < 3; j++)
{
printf("%c", chs[i][j]);
}
printf("\n");
}
return 0;
}运行如下:

字符串
在c语言中其实没有专门的字符串的类型,像Java、python那些就有。
在c语言中我们用的是字符数组,char chs[]这样的
定义:
int main()
{
char str1[10] = { "hello!" };
char str2[10] = "hello!";
char str3[] = "hello!";//常见,书写方便
return 0;
}注意:在字符串中最后一个字符是\0,表示我就在这截断了,这个字符啥也不表示。
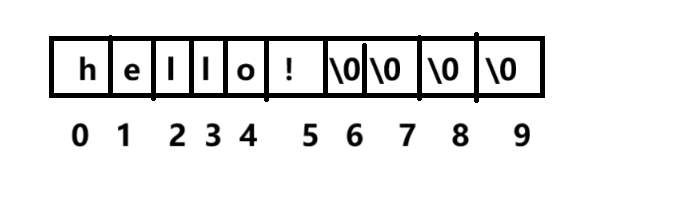
如果是helloworld呢,已经是10个了,没有\0的位置呢?
int main()
{
char str[10] = { "helloworld" };
printf("%s", str);//运气好正常输出
printf("%d", strlen(str));//异常输出:烫烫烫烫
return 0;
}为什么str能正常输出?因为运气好,在别处可能就不行了。
为什么strlen是乱码?因为strlen是看\0之前的,它找不到\0就一直找,就会找到别人那里就会报错。
我们知道这个之后,也可以根据自己需要放\0在字符数组:

注意事项:
1)输出不包括\0
2)printf用%s输出时,写的是str,而不是str[0],str[1]等等
3)碰到\0就结束,无论数组多长
4)可以用scanf对str赋值,但是不能直接对str修改
char a[10];
a = "aaa"; // 错误!
char a[10];
scanf("%s", a); // 正确!因为a是自定义的类型,数组名代表的是地址,地址就算0x100这种的,是常量不能修改的。但是如果scanf的话,就是对a这个地址里面的东西进行修改,这个是可行的。
5)scanf输入多个str,用空格隔开
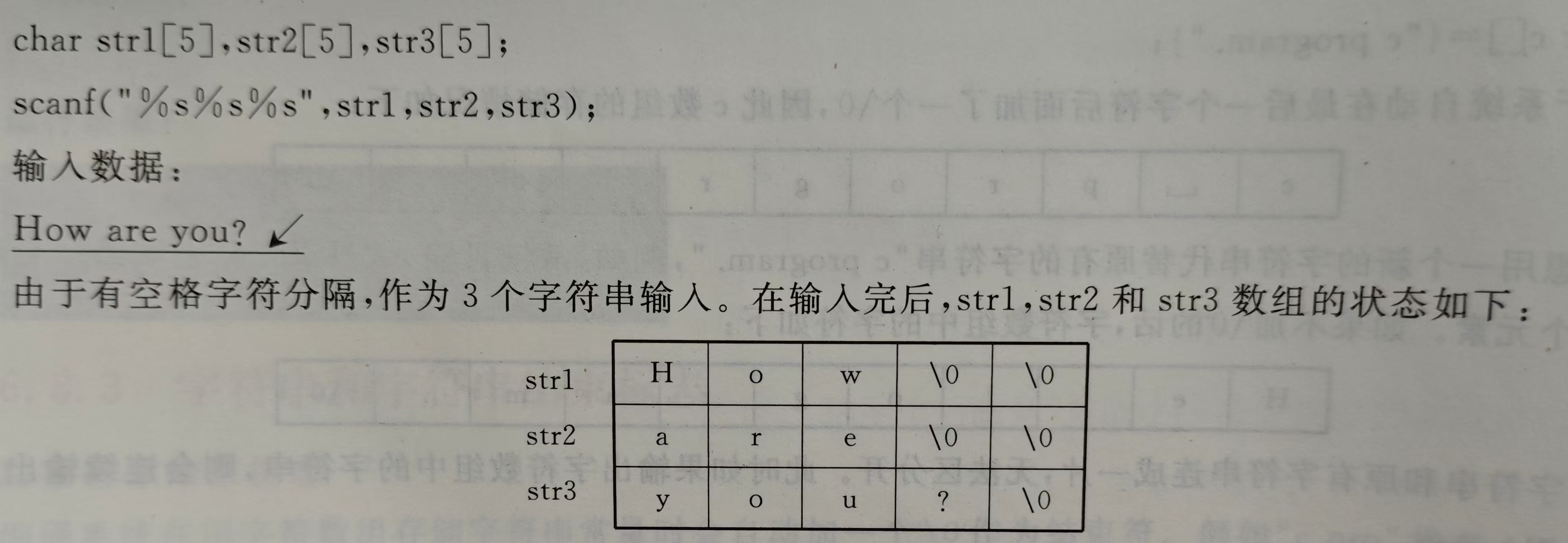
如果是只输入给一个str,那么就是how\0\0\0\0\0。。。(输出完剩下所有空位的\0)
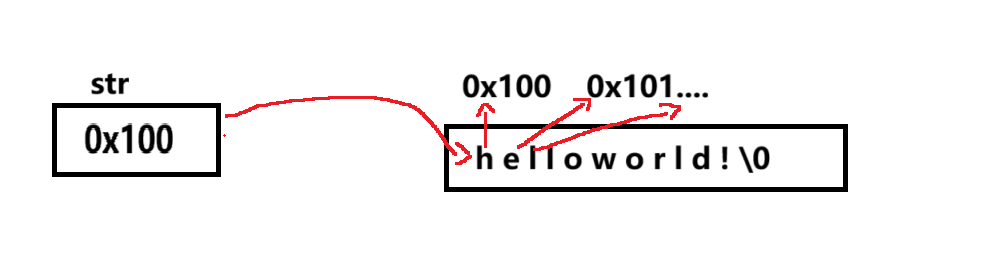
6)注意!scanf中,不能用&符号
scanf("%s",str);因为这种自定义类型本来名字就表示地址,str表示0x100这样的,里面的值才是,如图:
字符串函数
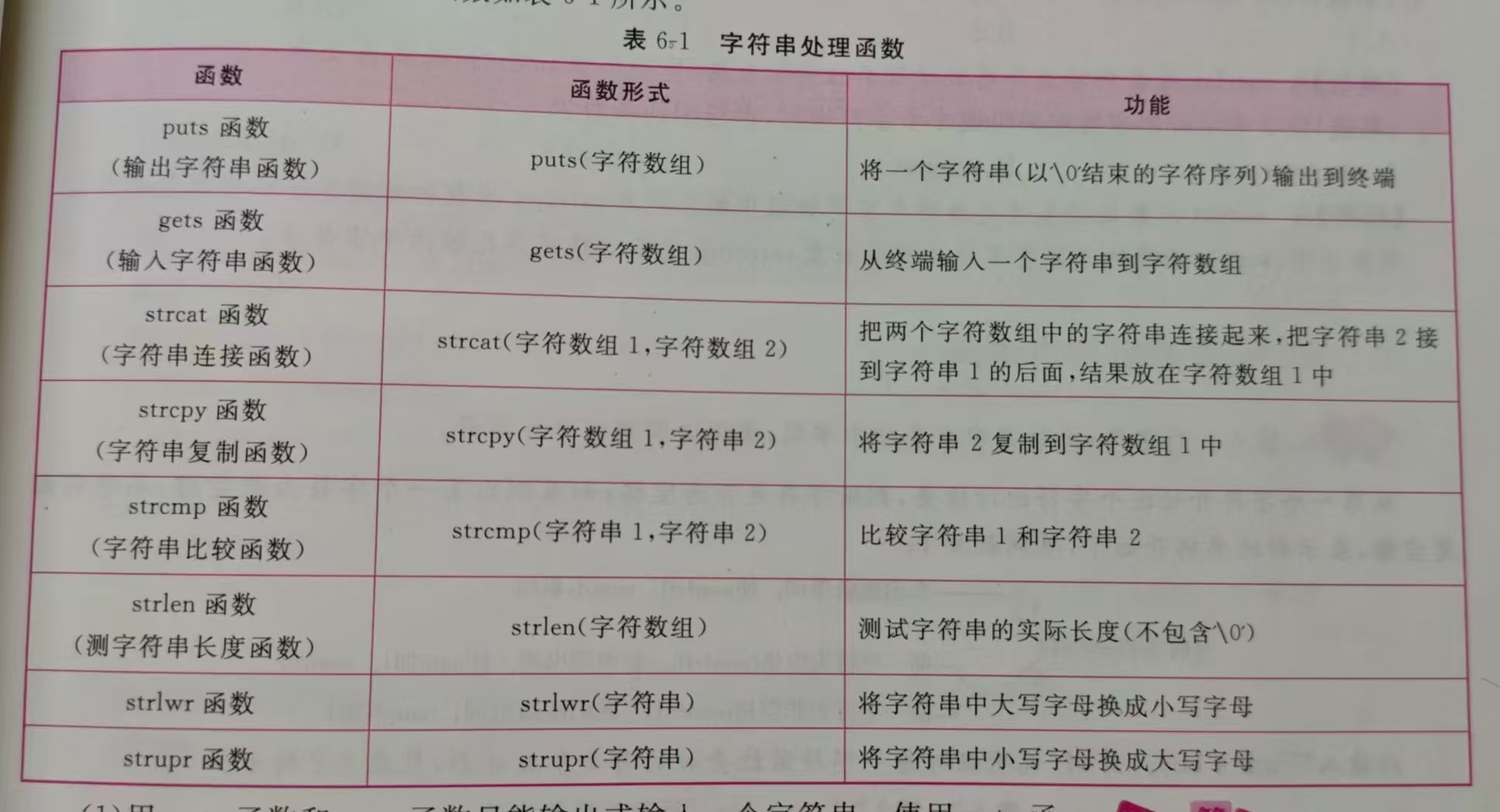
gets和puts
int main()
{
char str[10];
gets(str);//输入hello
puts(str);//输出hello
return 0;
}不仅可以用scanf,还可以用gets
strcat
int main()
{
char str1[11] = "hello";
char str2[11] = "world";
strcat(str1, str2);
printf("str1:%s,str2:%s", str1, str2);
//str1:helloworld,str2:world 也就是追加到str1
return 0;
}注意str1得放得下,不然会栈溢出
strcpy
int main()
{
char str1[11] = "hello";
char str2[11] = "world";
strcpy(str1, str2);
printf("str1:%s,str2:%s\n", str1, str2);
//str1:world,str2:world 也就是把后一个覆盖到前一个
char str3[11] = "cxxxxxxx";
char str4[11] = "111";
strcpy(str3, str4);
printf("str3:%s,str4:%s", str3, str4);
//str3:111,str4:111 因为字符串\0结尾,直接给带过去,输出111\0结束
return 0;
}strcmp
int main()
{
char str1[5] = "abc";
char str2[5] = "abb";
char str3[5] = "abc";
int num1 = strcmp(str1, str2);
int num2 = strcmp(str1, str3);
printf("%d,%d", num1,num2);//1,0
//主要看ascii值,第一个值比较然后第二个值比较,直到不相等,或者结束
//1表示大于,0表示等于,-1表示小于
return 0;
}strlen
int main()
{
int n=strlen("你好");//单位为字节,你好表示4个字节
int n2 = strlen("hello");
printf("%d\n", n);
printf("%d", n2);//\0前面有几位数,结果为5
return 0;
}strlwp和strupr
int main()
{
char str[20] = { "asdADasdDFFAsd" };
strlwr(str);
printf("%s\n", str);//asdadasddffasd
strupr(str);
printf("%s", str);//ASDADASDDFFASD
return 0;
}函数
函数就是为了实现某一类功能的抽离出来的一段代码
比如我想要相加a+b,但是我每次相加都要自己写a+b,
这时候用add方法,要相加的时候,直接调用add方法就能帮我们自动相加了。
库函数
库函数:就是厂商给我们做好的,我们可以直接用的。
vs就是微软的厂商,每个厂商设计的可能不一样,但是都是大差不差的。
其实我们很早就用过库函数了,比如printf和scanf
库函数
#include<stdio.h>
#include<math.h>
int main()
{
printf("你好呀\n");
float f=sqrt(64);
printf("%f", f);
return 0;
}用法很简单:引入头文件,就能直接用了。
比如printf函数是在stdio.h这个头文件,开根号sqrt是在math.h这个头文件。
我们直接#include<>就能直接导入了。就能直接用了。
自定义函数
库函数没什么含金量,都是别人做的,考试考的多的都是自己做的,也就是自定义函数。
我们根据自己的需求,自己做一个函数。比如我想要两个数相加,2+3这样的。
代码如下:
int add(int a, int b)
{
return a + b;
}
int main()
{
int sum1 = add(2, 3);
int x = 1, y = 2;
int sum2 = add(x, y);
printf("sum1=%d,sum2=%d\n", sum1, sum2);
return 0;
}
我们只需要在main函数上方写自定义函数就行了,如上面的,add是个名字,你下次调用就是用这个名字。int是返回类型,int a和int b是形式参数。{}里面的都是函数体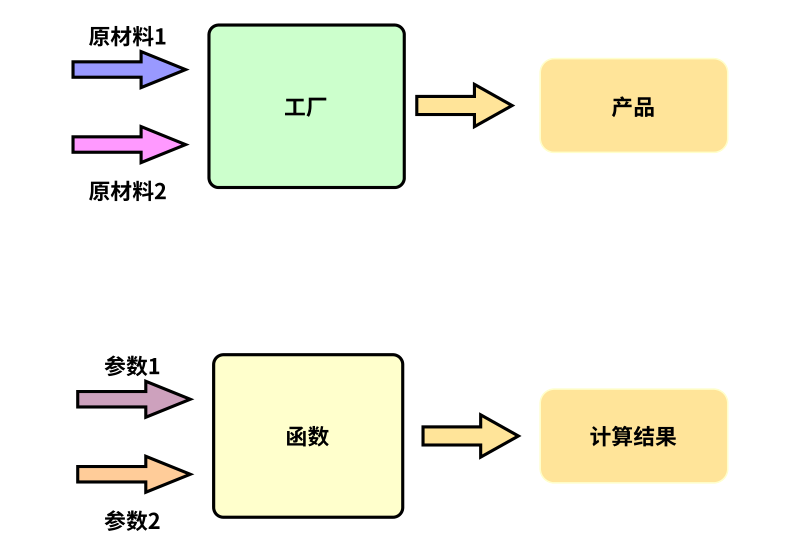
意思就是说,我需要两个数,一个是a,一个是b。
你需要给我这两个数,然后我会给你加工,计算出来,用int类型的值return给你。
你要做的就是在main中用这个函数,也就是:名字(参数)。
add(2,3)。其中也可以用变量去传参.
我们再来一个,打印菜单
我好像不需要返回值,直接printf好像就行了。
void print()
{
printf("------菜单------\n");
printf("------程序------\n");
printf("------选择------\n");
printf("------设置------\n");
}
int main()
{
print();
return 0;
}
如果我不需要返回值,就直接用void就行了。然后直接在main中调用就好了
定义与声明
如果一个函数在main函数下面,就需要声明,不然会报错,因为代码是从上往下看的,计算机都不知道你有没有这个函数,它就直接说不知道这个函数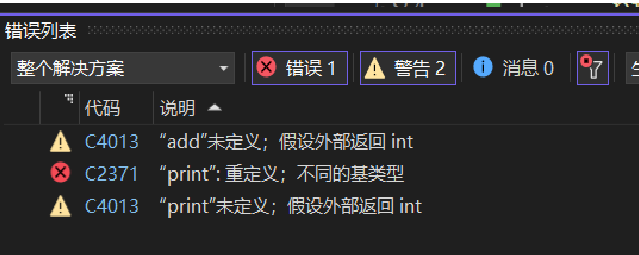
如下:
//函数的声明
int add(int a, int b);
void print();
int main()
{
//声明放在这也是可以的
//...
int sum1 = add(2, 3);
int x = 1, y = 2;
int sum2 = add(x, y);
printf("sum1=%d,sum2=%d\n", sum1, sum2);
print();
return 0;
}
int add(int a, int b)
{
return a + b;
}
void print()
{
printf("------菜单------\n");
printf("------程序------\n");
printf("------选择------\n");
printf("------设置------\n");
}
就相当于我有个函数是有的,我先告诉你有这个东西。
形参和实参
函数int add(int a,int b)中,a和b就是形参,形式参数。
在main中,直接调用add方法,如add(2,3);中的2和3就是实参,实际参数。
形参自己是没有内存空间的,问就是省内存。
它只有在被调用的时候才会开辟一个空间给形参。否则是没有空间的,然后函数调用完之后就关掉。
实参在main函数中,他是有自己的内存空间的。
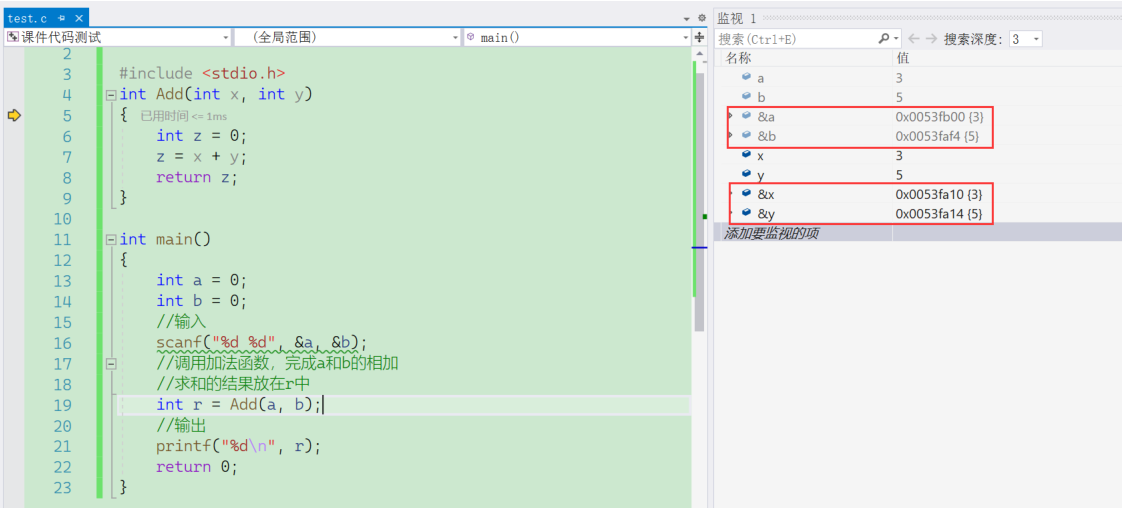
形参是实参的⼀份临时拷⻉
return语句
1.返回类void时,可以提前return;结束,return后面什么都不接
2.返回类型与返回值类型不同,以返回类型为主
3.return结束就相当于函数结束
4.有if分支时,return要覆盖所有可能的情况
5.return后面可以是表达式,也可以是单纯的值
数组传参
数组传参传的不是值,而是地址
arr->首元素地址
&arr[0]->首元素地址
&arr->整一个数组的地址
void set_arr(int arr[10], int sz)
{
for (int i = 0; i < sz; i++)
{
arr[i] = -1;
}
}
//传参也可以不写arr的个数
void print_arr(int arr[], int sz)
{
for (int i = 0; i<sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
//void set_arr(int arr[], int sz);
//void print_arr(int arr[], int sz);
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
set_arr(arr, sz);
print_arr(arr, sz);
return 0;
}传参arr,相当于把arr的首元素的地址传过去,
但是形参不开辟内存,直接通过地址,对本身进行修改。
形参int arr[]在程序中会被解析成int *arr这个指针变量,存放的就是首元素的地址。
不是说数组传参不开辟内存嘛,int*arr不就是一块空间嘛?
是一块空间,注意的是,这里说的空间是对原数组的,不需要重新开辟一块数组存。
嵌套调用和链式调用
嵌套调用:
指的是一个函数的调用会调用其他的函数。
#include<stdio.h>
int main()
{
printf("你好呀\n");
return 0;
}上面就是main函数嵌套printf函数,main函数的调用是系统调用的,其他都没资格。
链式调用
把一个函数的结果给另一个函数做形参
#include <stdio.h>
int main()
{
printf("%d\n", strlen("abcdef"));//链式访问
return 0;
}static和extern
static修饰局部变量,效果可以累加,也就是保留值。
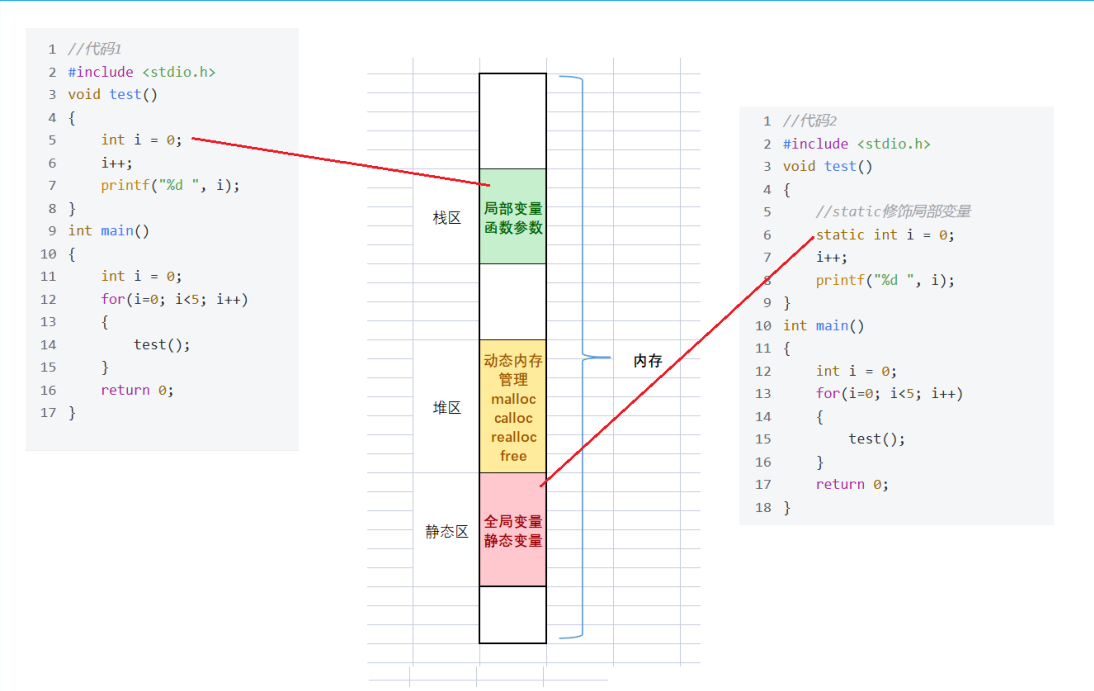
static修饰全局变量不被用,且extern采用外部变量

代码2编译失败,代码1编译成功,如果不想全局变量被用,用static修饰
static修饰函数

和全局变量一样,就是不被用。1编译成功,2失败。
指针
这个是c语言中最难理解的一部分,给我一些时间,我会让你对指针有不一样的认识。
类比:
你去别的学校找你同学,但是这个学校很大,你不知道去哪找。
你就问他,他说在a栋605。也就是说它在这个宿舍,你去这里就能找到他。
指针和内存
在计算机中,一个程序的运行离不开内存,它是在内存中运行起来的,它有很多数据需要拿取,计算机需要知道每个数据放哪里,这时候就有了地址的概念,就类似于很多学生在很多个宿舍,可以一一对应。
注意哦,本身程序是没有地址的,运行在内存中,内存才有地址的概念,c语言管这个地址,叫做指针!这就是指针的概念。
1byte = 8bit
1KB = 1024byte
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
1PB = 1024TB内存中一个单位的是一字节,1byte,1字节相当于8个比特位(0或者1),也就是一个宿舍八个人,单位转换如上。
它是怎么拿取数据的?
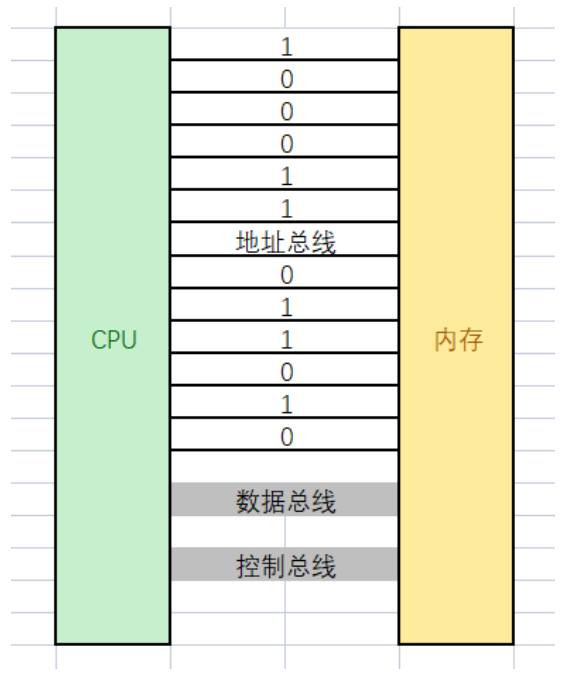
底层如上图,当然会更复杂一点,这也是冯·诺依曼架构中CPU与内存的交互过程(cpu是计算的,内存是暂时放数据的)。我这里只是简单说说。
原理如下:
CPU会拿内存里的数据(通过控制总线说我要拿数据),
计算好再通过地址总线(0100011这种的地址,有的是32个有的是64个)找到对应的地址里的数据,
再通过数据总线拿回来这个数据,开始计算 。算完之后用控制总线(说我要放数据),通过地址总线找到对应的位置,然后用数据总线放进去数据。
指针在c语言中是怎么样的
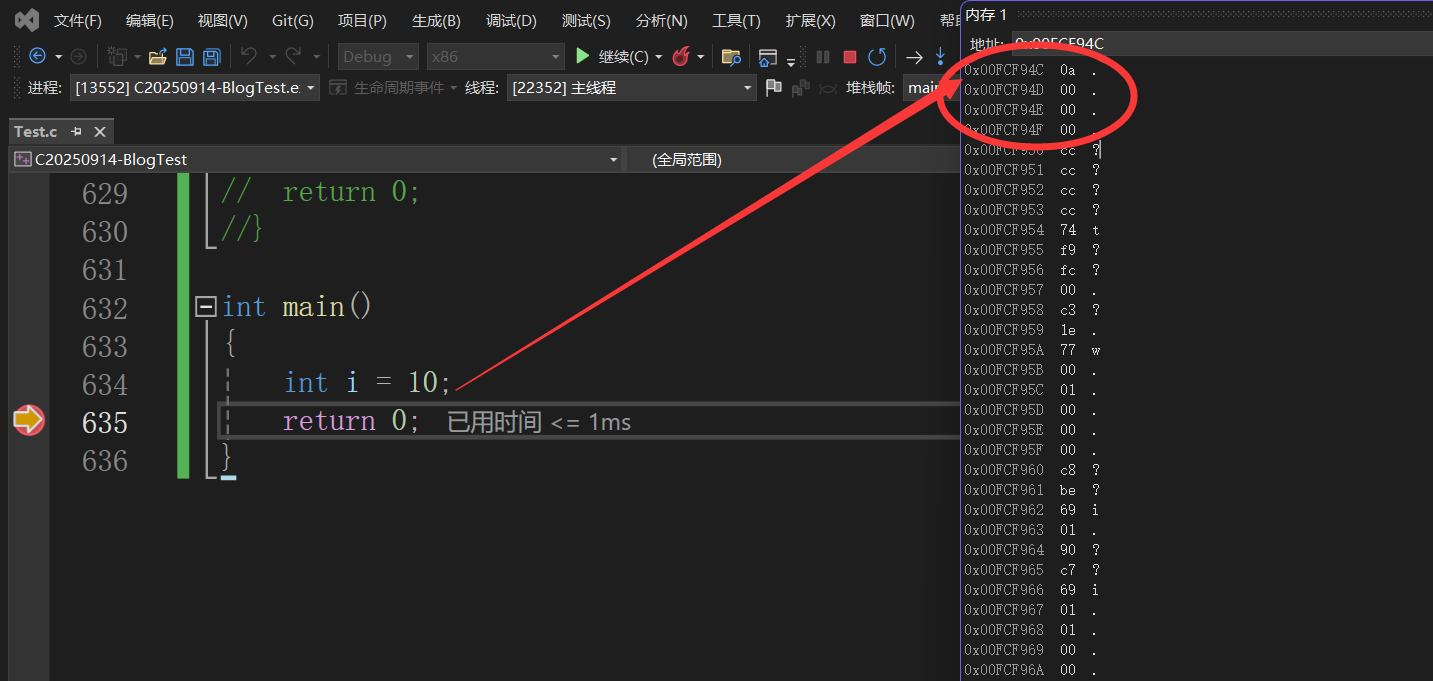
如上图,int i=10;也就是在内存中开辟了四个字节的空间存放10,第一个地址是x00FCF94C,
剩下三个其实说不说都无所谓,因为只要知道第一个,剩下的地址+1就能找到了。
怎么拿到i的地址?
用&取地址符号,%p打印地址信息(每一次运行地址都不一样,基本上不会一样)
指针变量
c语言说的指针,其实是口语化,说的就是指针变量。指针是地址,指针变量存的是地址的变量
int main()
{
int i = 10;
int* p = &i;
return 0;
}int *p就是创建指针。这里的p是指针的名字,*说明它是一个指针,int是 他的基类型,也就是p指向的是int类型的变量的地址。如下图: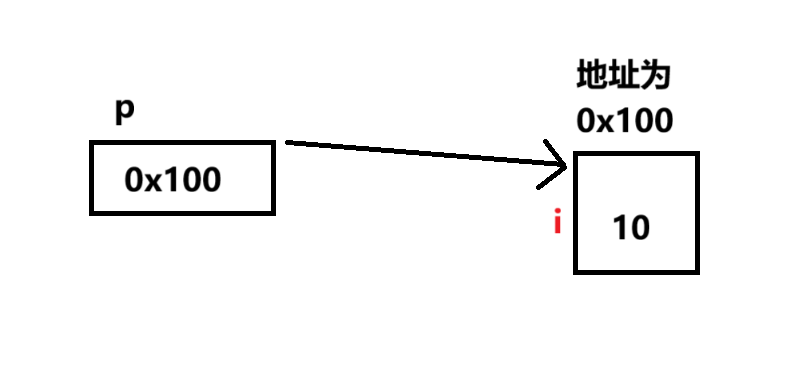
指针变量实际上是一种变量,它里面存的就是地址,p里面存的是i的地址(0x100),就是可以通过p找到i,我们形象的称为“p指向i”
解引用操作*
如果我们需要拿到i的值,不仅可以通过i本身拿,还能通过p指针拿。
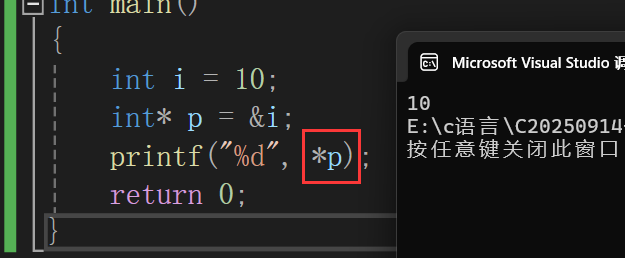
我们通过*p来操作i,*p的意思 就是,我拿到p指向的对象的值,也就是10
我们不仅可以拿到值,我们甚至可以通过*p来修改值
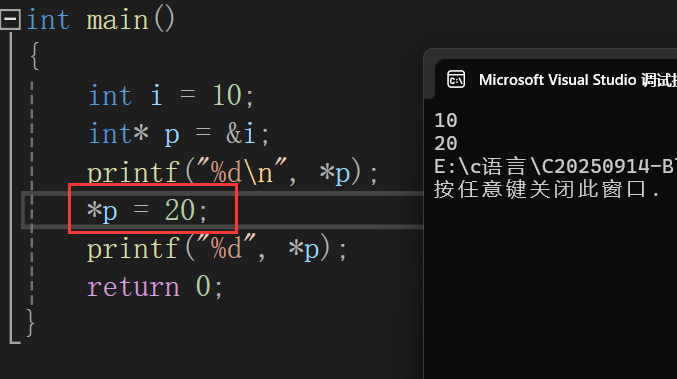
*p就相当于一个代理人,只要高启强说一句,老莫我想吃鱼了。老莫就会帮强哥把人干掉。
还有一些比较有意思的题
int main()
{
int* a, * b, * c;
a = (int*)malloc(sizeof(int));
b = c = a;
*a = 3;
*b = 4;
*c = 5; printf("%d,%d,%d\n", *a, *b, *c);
return 0;
}答案输出5,5,5。为什么呢?我们画个图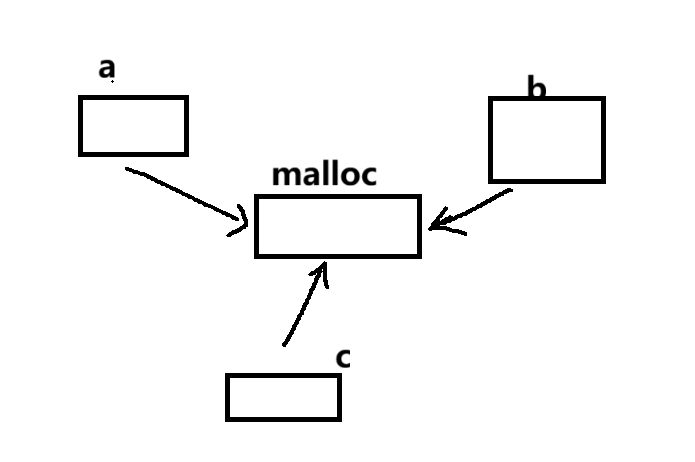
在
b = c = a中:也就是从右往左赋值,都是0x1000
a存储的是malloc返回的地址(比如 0x1000)
c = a意思是:把a的值(0x1000)赋给c
b = c意思是:把c的值(0x1000)赋给b所有指针存储的都是同一个地址值,没有"指向指针"的关系。
所以打印的时候,就是打印malloc区域的值,也就是5。
指针变量的大小
我们之前说地址总线有些是32位,有些是64位,这个就是看环境了,
在vs中,如果是x86环境,就是32位地址总线,如果是x64的就是64位地址总线。
1位就是一比特位(1bit),8bit=1字节,32bit=4个字节。所以在x86环境下,一个指针变量就是4个字节。下面都是4哈,跟基类型是int还是char无关。
int main()
{
printf("%zd\n", sizeof(char *));//4
printf("%zd\n", sizeof(short *));//4
printf("%zd\n", sizeof(int *));//4
printf("%zd\n", sizeof(double *));//4
return 0;
}既然都是4个字节,为什么还需要基类型?对指针同个操作结果是不同的。
指针基类型的意义
当我打印他们的地址时,pc和pi与&i是一样的。但是pc+1和pi+1就不一样呢。

为什么会不一样呢?因为计算机自动认为基类型就是你指向的那个东西的类型。
int*就是一次性跳四个字节,char*一次性跳一个字节,其他同理。
指针的类型决定了指针向前或者向后⾛⼀步有多⼤(单位)。
还有一个是void*,它可以来接收指针的地址,也是四个字节,但是它不能用来进行指针的加减。
指针的计算
指针+-整数
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = &arr[0];
for (int i = 0; i < sz; i++)
{
printf("%d ", *(p + i));//指针+整数
}
return 0;
}先让p,也就是p的值(也就是地址,假设是0x100)让他+i,也就是加i个单位(基类型为int,四个字节),
第一个i=0,所以就是0x100,*p就是打开0x100的值(首元素地址),也就是1。
其次p+1,加一个单位变成0x104。
*p,也就是取0x104取它的值,也就是2,打印。同理下面也是如此。
指针-指针(不能相加)
//指针-指针
int my_strlen(char* start)
{
char* p = start;
while (*p != '\0')
{
p++;
}
return p - start;
}
int main()
{
printf("%d", my_strlen("abcd"));
return 0;
}自己实现一个strlen函数,其实很简单。
我们用指针接收字符串,然后用一个新的指针,来遍历字符串,让指针p++(注意不是*p,但是*p++,相当于*(p++),对于这个程序来说,结果是一样的,但是意义可能有点出错),
如果=\0就算是没有值的,跳出循环。然后用p-start,也就是指针-指针。ptr2 - ptr1 = (地址差) / sizeof(类型)
我们可以把指针理解为日期,整数理解为天数。
指针+-整数=指针 -> 日期+-天数=日期
指针-指针=整数 -> 日期-日期=天数
指针相加无意义,可能值也可能无值。就像2024年某一天+2025年某一天,你也不知道是哪一天,甚至不知道发生什么,也不一定有人类了。
传值和传址
下面就是传值,函数开始,开辟临时空间,函数关闭,关闭临时空间。
所以就像武侠小说,知道真相的人调查完了,但是突然被暗杀了,也没有人知道真相了。
传值
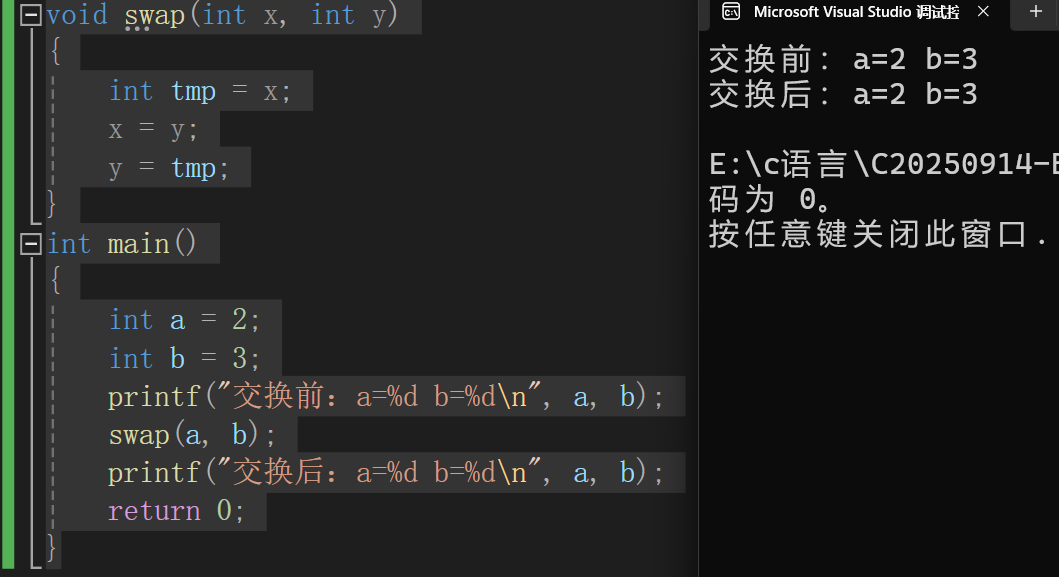
传址
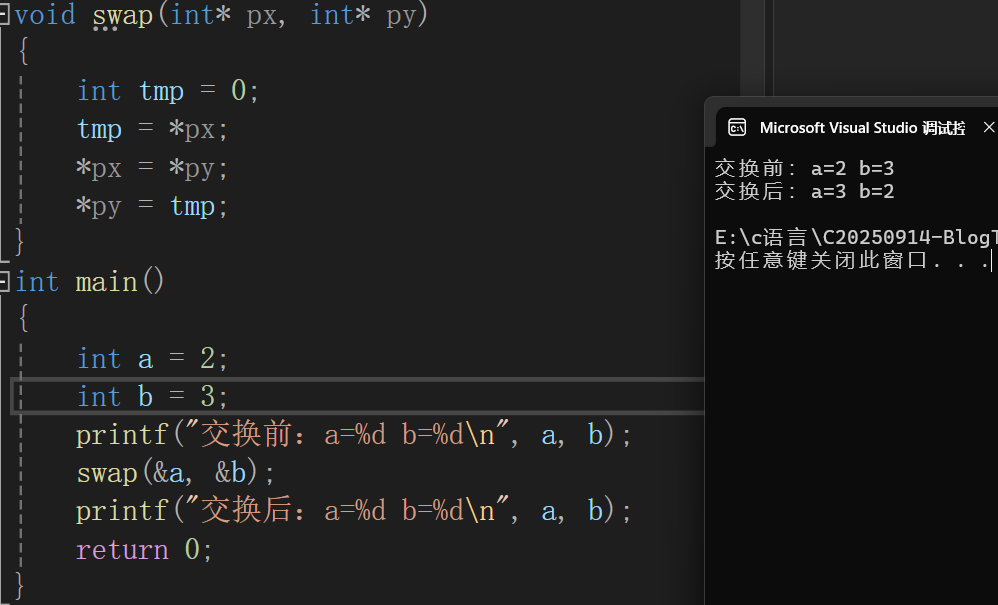
这种相当于借刀杀人,*px和*py就是直接对 地址映射 的值 进行修改。
就像身份证号对应的只有你,我不一定直接说我要找张三,我可以说我要找4415.....(张三的身份证号码),也可以找到张三。
数组传参的本质
形参int arr[]相当于int* arr,编译的时候会自动把int arr[]变成int*arr。
因为实参arr传进去,其实传的是一个地址,是arr首元素的地址,也就是&arr[0]。
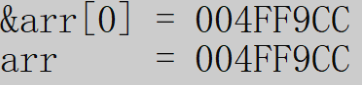
&arr和arr和arr[0]有什么区别呢?
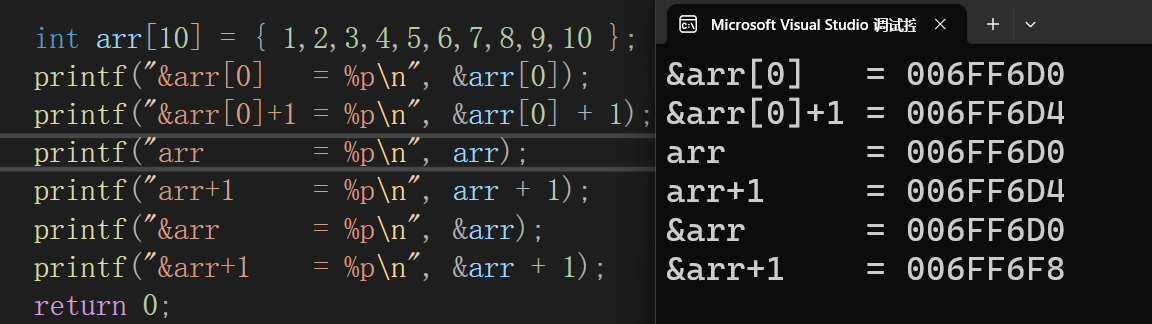
用来计算时,加加减减的单位会有所不同
int main()
{
int arr[10] = { 0 };
int* p=arr;
printf("%d ", p[1]);//相当于arr[1]
printf("%d ", *(p+1));//相当于*(arr+1)
//且arr[1]相当于*(arr+1)
return 0;
}二级指针
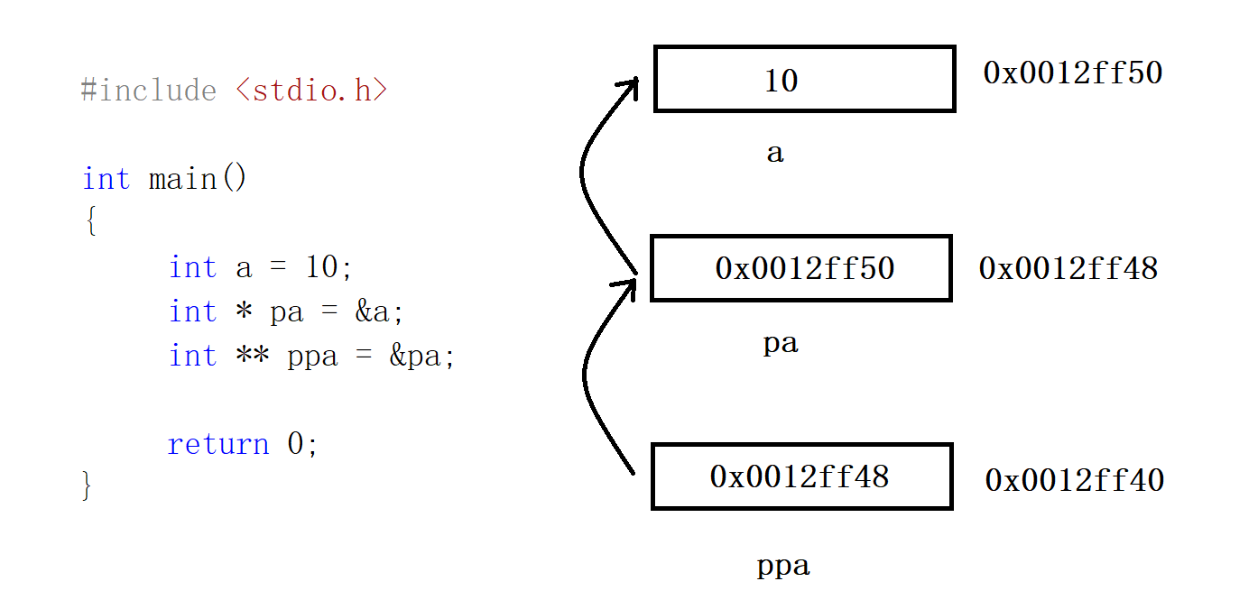
与一级指针类似
指针数组和数组指针
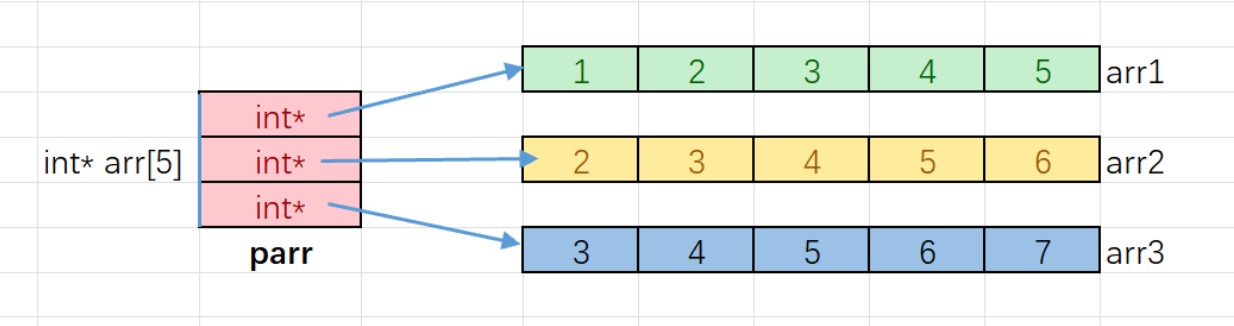
指针数组:
是数组,存的是n个指针
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
//数组名是数组⾸元素的地址,类型是int*的,就可以存放在parr数组中
int* parr[3] = { arr1, arr2, arr3 };
int i = 0;
int j = 0;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
}
数组指针
是指针存的是数组,用的很少,有特定的场景
int (*p)[10]=&arr;它和指针数组很像,他加了括号,不加括号的话,p会跟[10]结合,变成指针数组。
如果加了括号,就是p和*结合,是个指针,指向的是10单位这个数组。
void test(int(*p)[5], int r, int c)
{
int i = 0;
int j = 0;
for (i = 0; i < r; i++)
{
for (j = 0; j < c; j++)
{
printf("%d ", *(*(p + i) + j));
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5}, {2,3,4,5,6},{3,4,5,6,7} };
test(arr, 3, 5);
return 0;
}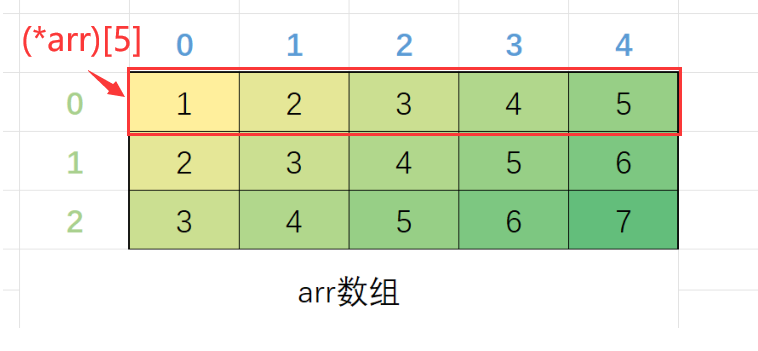
数组指针那不是跟指针数组一样嘛?
不一样的,虽然看着很像,但是指针数组把数组每一行都指了一遍,但是数组指针只指向第一行。需要的时候数组指针++就变成第二行了。
数组指针其实很少用到,一般用于二维数组。
结构体
像数组,我们装的都是一样类型的,但是如果是不一样类型的该怎么放一起呢?用结构体。
声明如下:struct stu{}; 注意要有分号
struct stu
{
char name[10];
int age;
};咋用呢?
第一种,声明之后,定义结构体变量并且初始化
//第一种用法
struct stu
{
char name[10];
int age;
};
int main()
{
struct stu s = { "zhangsan",18 };
printf("name:%s,age:%d\n", s.name, s.age);
return 0;
}第二种,声明的时候直接定义变量并且初始化
//第二种用法
struct stu
{
char name[10];
int age;
}s = { "zhangsan",18 };
int main()
{
printf("name:%s,age:%d\n", s.name, s.age);
return 0;
}第三种,先声明结构体,然后顺带整个结构体变量,之后你再赋值
//第三种用法
#include<string.h>
struct stu
{
char name[10];
int age;
}s;
int main()
{
s.age = 18;
strcpy(s.name, "zhangsan");
printf("name:%s,age:%d\n", s.name, s.age);
return 0;
}注意,如果不是再定义的时候就初始化的话,那么你在赋值的时候,简单类型可以直接:变量名. 来赋值。如果是字符串的话,就需要用到strcpy函数赋值,记得引头文件string.h。
结构体数组
struct stu
{
char name[10];
int age;
}a[2],arr[3] = { "lisi",2,"wangwu",4,"zhaoliu",8 };
int main()
{
struct stu brr[3] = { "lisi",2,"wangwu",4,"zhaoliu",8 };
printf("name:%s,age:%d\n", arr[0].name, arr[0].age);
printf("name:%s,age:%d\n", arr[1].name, arr[1].age);
return 0;
}结构体指针
struct stu
{
int num;
char name[20];
char sex;
int age;
};
struct stu s[3] = { {1,"zhangsan",'M',18},{2,"lisi",'w',19}, {3,"wangwu",'M',20} };
int main()
{
struct stu* p;
printf(" No. Name sex age\n");
for (p = s; p < s + 3;p++)
{
printf(" %d %-10s %2c %4d\n", p->num, p->name, p->sex, p->age);
}
return 0;
}如果指针指向的是结构体,用指针引用成员变量,可以用->,如上。
大致如下,改了点数据
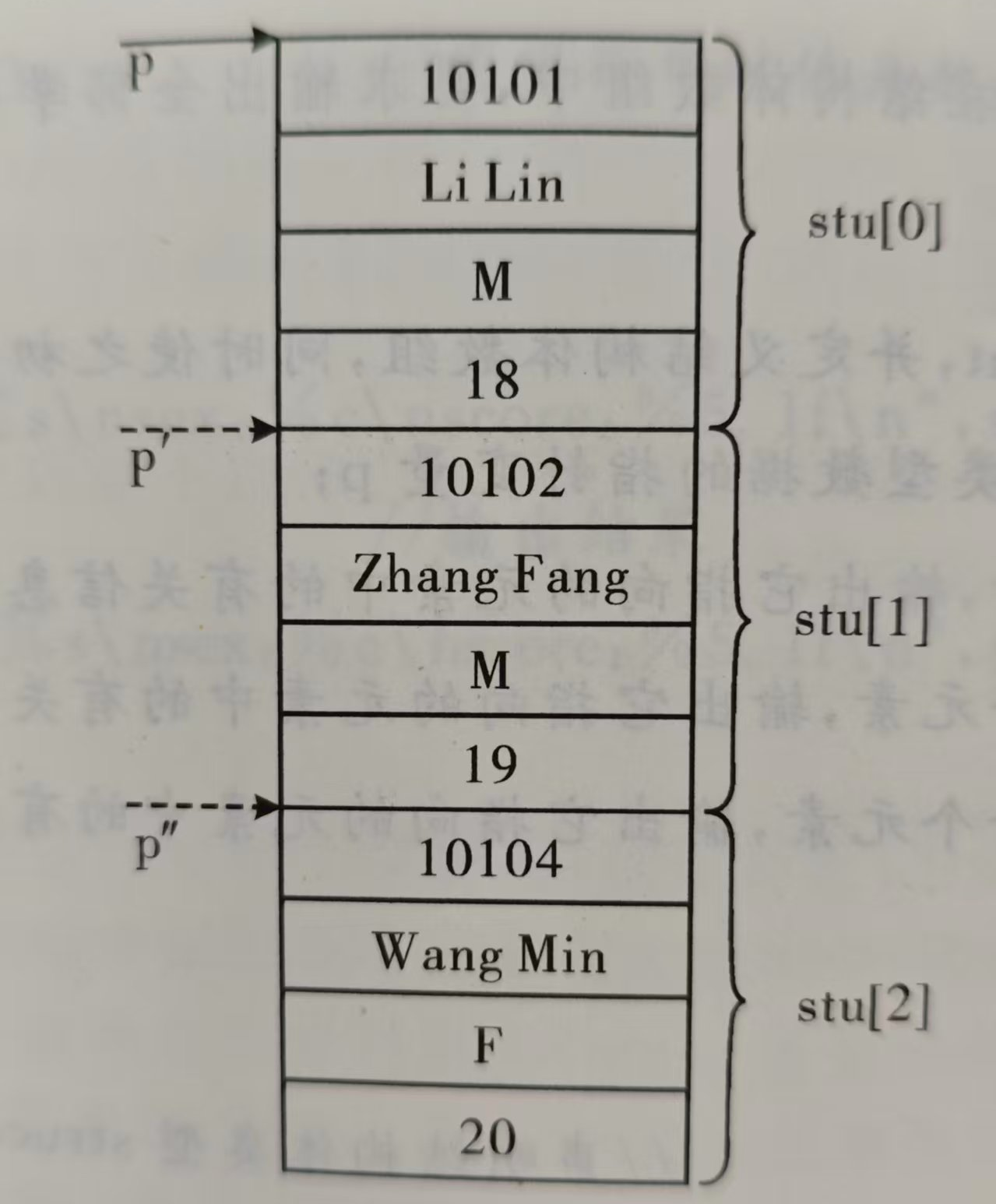
结构体传参
结构体传参传的是值,
也就是说name和age都是商品房,创建好给你的,你不要了就销毁了,类似于多次传简单类型吧。
struct Student {
int id;
char name[20];
float score[3];
};
void change(struct Student stu) {
stu.score[0] = 100;
strcpy(stu.name, "Jerry");
}
int main() {
struct Student stu;
stu.id = 12345;
strcpy(stu.name, "Tom");
stu.score[0] = 67.5;
stu.score[1] = 89;
stu.score[2] = 78.6;
change(stu);
// 此处stu的内容不会改变,因为change函数操作的是副本
return 0;
}结构体指针传参,会改变内容
struct Student {
int id;
char name[20];
float score[3];
};
void change(struct Student* p) {
p->score[0] = 100;
strcpy(p->name, "Jerry");
}
int main() {
struct Student stu;
stu.id = 12345;
strcpy(stu.name, "Tom");
stu.score[0] = 67.5;
stu.score[1] = 89;
stu.score[2] = 78.6;
change(&stu);
// 此处stu的内容会改变,因为change函数操作的是原始结构体
return 0;
}结构体内存
在专升本中,其实并没有考的很复杂,比如
struct stu
{
char a;
int b;
};它在专升本中,其实就是把变量都加起来,上面的代码就是char+int,1+4=5个字节。但是事实上它还要涉及到内存对齐,会浪费几块内存,专升本不考,只考简单的相加就行了,内存对齐有兴趣可以去翻阅其他博客。
还有就是,它在声明的时候并不会开辟空间给结构体,它只有定义了变量才会开辟空间给成员结构,而结构体本身没有空间,只有成员变量有空间。
共用体和枚举类型
这两个很简单,考的也是简单,可以说是考结构体顺带考一下的。搞清楚语法就行了。
共用体
union u
{
int a;
char b;
};a和b共用一个地址,他们两的起始地址一样。共用体变量的内存长度是最长的成员的长度。
结构体和共用体区别
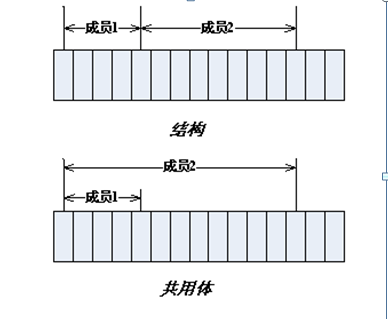
枚举
enum sex
{
MALE,//0
FAMALE//1
};
int main()
{
printf("%d", MALE);//打印0
return 0;
}枚举类型中,第一个成员变量值为0,依次递增。如果把MALE赋值为4,FAMALE为5。
文件操作
文件函数
有大佬写了更好的文章,这里我直接引用:
putchar和getchar以及scanf和printf还有gets和puts区别
此外,我这里想要补充的就是:
putchar和getchar以及scanf和printf还有gets和puts区别(这个在专升本中还是很经常用到)
这里有大佬的文章,写的比我好多了,请看:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)