StreamingT2V:从文本生成一致、动态和可扩展的长视频
StreamingT2V提出了一种突破性的文本到长视频生成方法,通过条件注意力模块(CAM)实现平滑片段过渡,外观保持模块(APM)维持长期场景一致性,以及随机混合策略消除增强过程中的拼接痕迹。该方法能够生成长达2分钟的高质量视频,在运动丰富性和一致性方面显著优于现有技术,定量指标MAWE降低28%。这种模块化设计结合了短/长期记忆机制,为AI视频创作开辟了新可能,可应用于广告、教育、娱乐等多个领
论文题目:StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text(从文本生成一致、动态和可扩展的长视频)
会议:CVPR2025
摘要:文本到视频传播模型支持生成遵循文本说明的高质量视频,简化了制作多样化和个性化内容的过程。目前的方法在生成短视频(高达16s)方面表现出色,但当天真地扩展到长视频合成时,会产生困难。为了克服这些限制,我们提出了StreamingT2V,这是一种自回归方法,可以生成长达2分钟或更长的视频,并进行无缝转换。关键组件是:(I)被称为条件注意模块(CAM)的短期记忆块,其通过注意机制对从先前块中提取的特征来调节当前代,从而导致一致的块转换;(Ii)被称为外观保持模块(APM)的长期记忆块,其从第一视频块中提取高级场景和对象特征以防止模型忘记初始场景;以及(Iii)随机混合方法,其允许在不确定长度的视频上自动回归地应用视频增强器,以确保块之间的一致性。实验表明,StreamingT2V产生了更多的运动,而竞争的方法如果以自回归的方式幼稚地应用,则会受到视频停滞的影响。因此,我们提出了StreamingT2V的高质量无缝文本到长视频生成器,在一致性和动作方面都超过了竞争对手。
项目地址:Https://github.com/Picsart-AI-Research/StreamingT2V.StreamingT2V

StreamingT2V:突破长视频生成的技术瓶颈
引言
想象一下,你只需输入一段文字描述,AI就能为你生成一段2分钟的高质量视频,画面流畅、动作自然、前后一致。这听起来像科幻小说吗?来自Picsart AI Research、UT Austin和Georgia Tech的研究团队在CVPR 2025上发表的StreamingT2V论文,让这个梦想变成了现实。
现有技术的困境
短视频的"紧箍咒"
当前的文本到视频(Text-to-Video, T2V)生成模型虽然能产生令人惊叹的效果,但都有一个共同的"阿喀琉斯之踵"——只能生成短视频。大多数模型生成的视频长度仅为16-24帧(不到1秒),即使最先进的模型也只能生成384帧。这对于广告制作、电影叙事等实际应用来说远远不够。
自回归方法的"三大难题"
研究人员尝试通过自回归方式扩展视频长度——即基于前一个视频片段的最后几帧生成下一个片段。但这种方法面临三个致命问题:
-
视频"冻结"现象:多个方法生成的长视频中,背景像被施了定身咒,相机纹丝不动,对象几乎没有任何运动
-
时间"断层":视频片段之间出现明显的不连续跳跃,就像电影中的硬切换,严重破坏观看体验
-
质量"雪崩":随着生成时间推移,视频质量不断下降,出现颜色失真、物体变形等问题
StreamingT2V的创新解决方案
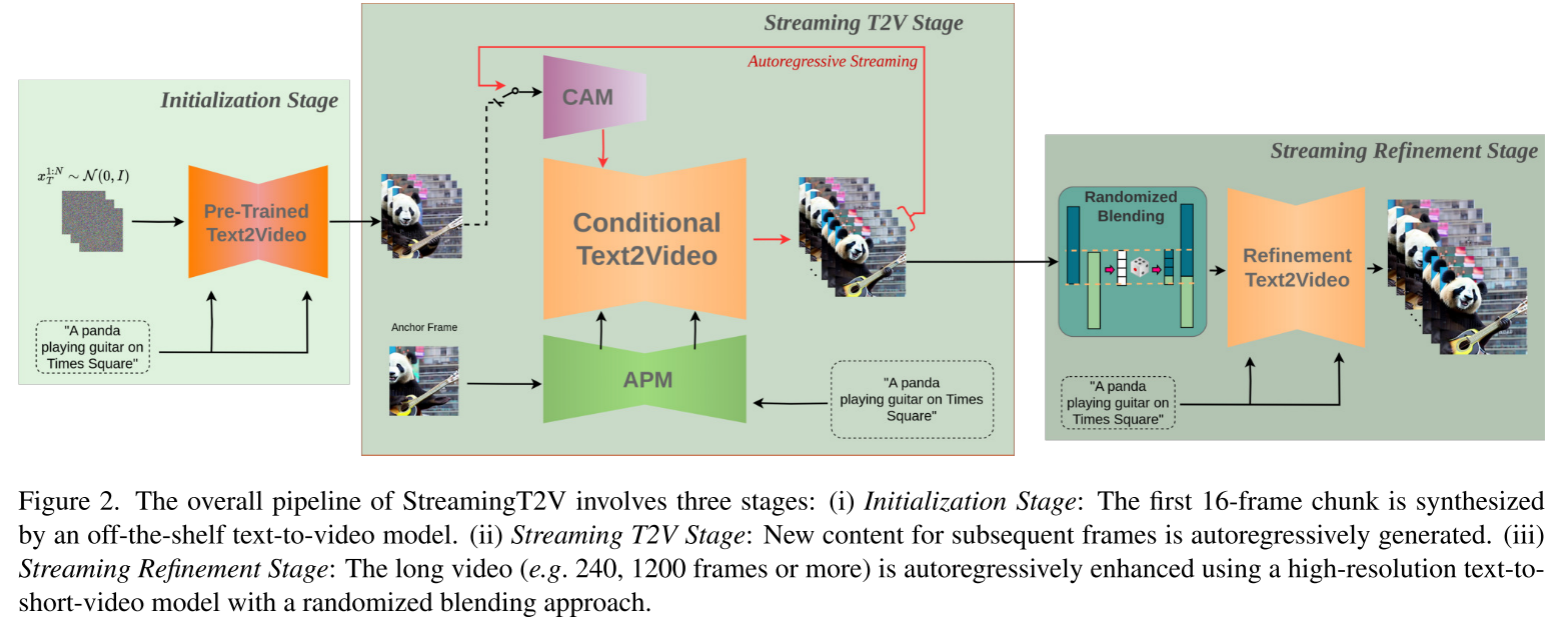
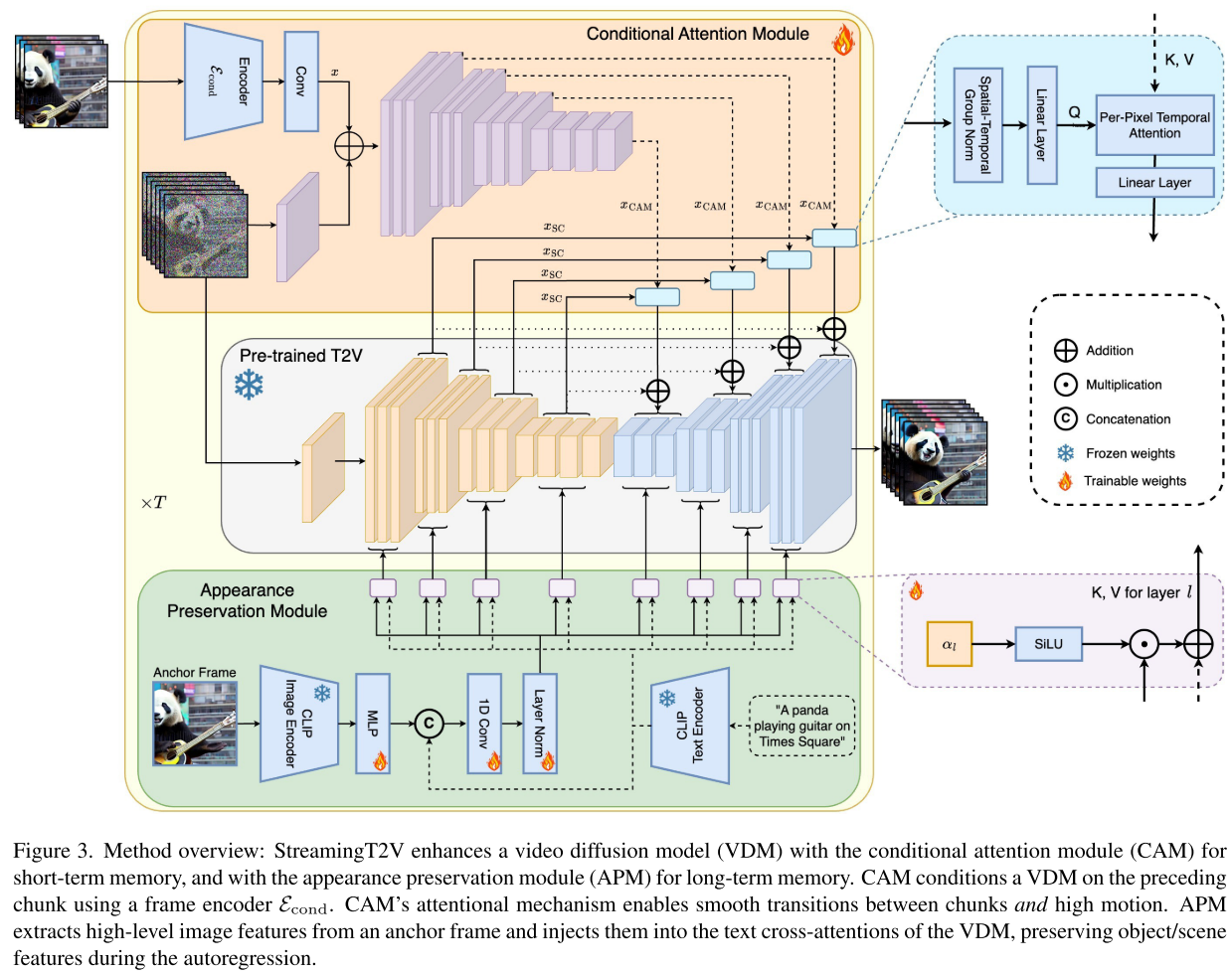
StreamingT2V提出了一个优雅的三模块架构,分别解决短期一致性、长期记忆和质量增强问题。
创新一:条件注意力模块(CAM)——短期记忆的艺术
问题本质:如何让视频片段之间平滑过渡?
传统方法简单地将前一个片段的最后几帧"拼接"到新生成的帧上,这就像用胶水粘照片——接缝明显。
StreamingT2V的方案:使用注意力机制而非简单拼接。
想象你在画一幅连续的画卷。CAM就像一位经验丰富的画家,在绘制新部分时:
- 会"参考"前面已画好的内容(通过注意力机制提取关键信息)
- 但不会被前面的笔触"束缚"(保持运动的自由度)
- 自然地延续风格和内容(实现平滑过渡)
技术亮点:
- CAM可以让当前的16帧"关注"前一个片段的最后8帧
- 通过交叉注意力机制注入特征,而非强制对齐结构
- 零初始化确保训练初期的稳定性
创新二:外观保持模块(APM)——长期记忆的守护者
问题本质:如何防止长视频中角色和场景"失忆"?
在自回归生成过程中,模型只"记得"最近的几帧,就像患了短期记忆丧失症。这导致视频开头的蓝色衬衫到后面可能变成红色,原本的海滩场景可能变成森林。
StreamingT2V的方案:引入"锚点帧"机制。
APM就像一位导演,手里始终拿着第一个镜头的剧照:
- 从第一个视频片段中提取场景和对象的核心特征
- 在每次生成新内容时都参考这个"剧照"
- 确保整个视频保持角色和场景的一致性
技术巧思:
- 结合CLIP图像编码和文本编码
- 为每个注意力层引入可学习权重,动态平衡锚点引导和文本指令
- 防止错误累积,保持长期一致性
创新三:随机混合方法——画质提升的魔法
生成长视频后,还需要提升分辨率和质量。但直接对每个片段独立增强会导致片段边界出现"接缝"。
StreamingT2V的方案:聪明的随机混合策略。
想象你在拼接两块拼图:
- 共享噪声:重叠区域使用相同的"底纹"
- 随机切换点:在重叠区域随机选择拼接位置
- 概率混合:重叠区域的每一帧都有一定概率来自左侧或右侧
这种方法的精妙之处在于,通过随机性消除了确定性带来的视觉"接缝",就像用羽化工具处理照片边缘。
实验结果:碾压式的性能优势
定量对比
StreamingT2V在三个核心指标上都取得了最佳或接近最佳的成绩:
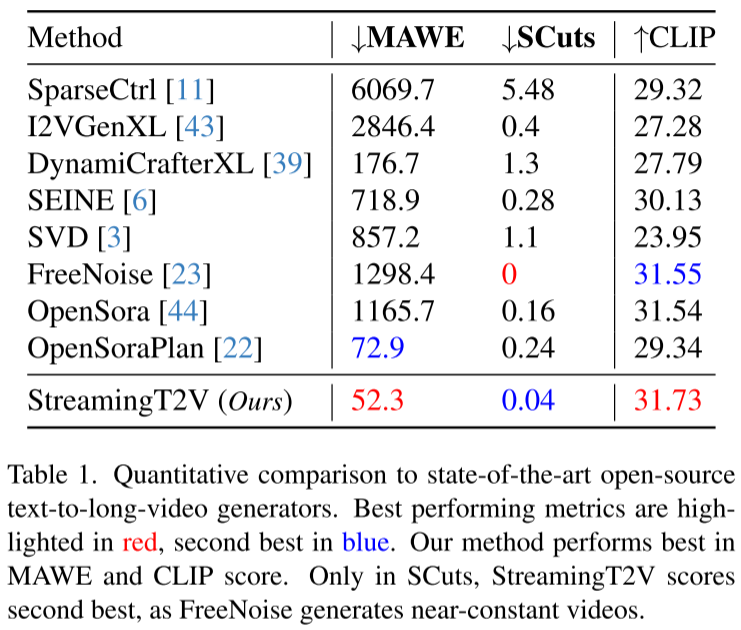
| 评估指标 | StreamingT2V | 竞争方法最佳 | 优势 |
|---|---|---|---|
| MAWE (运动&一致性) | 52.3 | 72.9 | 降低28% |
| CLIP (文本对齐) | 31.73 | 31.55 | 最高 |
| SCuts (场景切换) | 0.04 | 0.16 | 显著更低 |
特别值得注意的是:
- MAWE指标同时衡量运动量和一致性,StreamingT2V比第二名低28%,说明既有丰富运动又保持一致
- 唯一在SCuts不是最低的原因:FreeNoise虽然SCuts为0(完美),但那是因为它生成的是几乎静止的视频!
定性对比
论文展示了与9种先进方法的视觉对比:
竞争方法的问题:
- I2VGen-XL, SVD:随时间严重质量退化,颜色错误明显
- SparseCtrl:场景切换次数是StreamingT2V的100倍!
- DynamiCrafter-XL:块之间频繁出现不一致
- SEINE:对象外观特征改变
- FreeNoise:生成近乎静态的视频,像幻灯片而非视频
- OpenSora/OpenSoraPlan:运动受限,仍有停滞问题
StreamingT2V的表现:

- ✅ 丰富的运动动态(游动的鱼、奔跑的马、行走的小狗)
- ✅ 平滑的片段过渡(无明显切换点)
- ✅ 持续的高质量(不随时间退化)
- ✅ 完美的文本对齐(精确匹配描述)
技术细节:可复现的成功
训练策略
- 基础模型:Modelscope T2V模型(256×256, 16帧)
- 训练数据:WebVid-10M数据集
- 训练效率:在8张NVIDIA A100 GPU上训练7天
- 参数量:CAM和APM模块轻量化设计,训练高效
三阶段流程
- 初始化阶段:使用预训练T2V模型生成首个16帧片段
- 流式生成阶段:通过CAM和APM自回归生成长视频(240-1200帧)
- 流式增强阶段:使用高分辨率模型(如MS-Vid2Vid-XL)提升至720×720
推理性能
- 可生成1200帧(2分钟)视频,理论上可无限扩展
- 增强阶段无需额外训练,成本效益高
- 支持不同架构(UNet和DiT)
消融实验:验证每个模块的价值
CAM的重要性
| 变体 | MAWE ↓ | SCuts ↓ |
|---|---|---|
| 无CAM | 147.3 | 0.72 |
| 有CAM | 52.3 | 0.04 |
移除CAM后,场景切换增加18倍,MAWE恶化近3倍!
APM的贡献
通过对比有无APM的结果:
- 无APM:对象颜色和特征随时间漂移
- 有APM:保持初始外观,场景一致
随机混合的效果
视觉对比(X-T切片图)清晰显示:
- 简单拼接:块边界有明显线条
- 共享噪声:略有改善但仍可见边界
- 随机混合:完全平滑的过渡
局限性与未来方向
当前局限
- 计算成本:生成长视频仍需较高算力
- 运动复杂性:极其复杂的动作序列仍有挑战
- 分辨率:当前最高720p,未达到4K标准
未来展望
论文展示了StreamingT2V在DiT架构(OpenSora)上的初步应用,证明了方法的可扩展性。未来可以:
- 更高分辨率:适配更强的基础模型实现4K生成
- 更长时长:优化内存管理,支持10分钟以上视频
- 交互控制:增加用户对特定帧或对象的控制能力
- 多模态融合:结合音频、3D等多模态信息
实际应用前景
StreamingT2V的突破为多个领域打开了新的可能:
1. 内容创作
- 广告制作:快速生成产品宣传视频
- 短视频创作:自动化生成社交媒体内容
- 游戏CG:游戏过场动画的自动生成
2. 教育培训
- 教学视频:根据教案自动生成演示视频
- 虚拟实验:创建科学实验的可视化过程
3. 娱乐产业
- 故事板可视化:将剧本转化为视频草稿
- 概念预览:快速验证创意想法
4. 虚拟现实
- VR内容生成:为虚拟世界创建动态场景
- 数字人:生成虚拟角色的行为动作
技术启示:设计原则的智慧
StreamingT2V的成功提供了几个重要启示:
1. 注意力机制 > 简单拼接
在处理序列数据时,注意力机制能更好地捕捉上下文关系,而简单的拼接往往导致不自然的过渡。
2. 长短期记忆的结合
CAM处理短期一致性,APM维护长期特征,这种双记忆机制值得在其他序列生成任务中借鉴。
3. 随机性的妙用
随机混合方法展示了如何用随机性消除确定性算法的缺陷,这是一个反直觉但有效的策略。
4. 模块化设计的优势
三个独立模块可以单独训练和优化,增强了系统的灵活性和可维护性。
结语
StreamingT2V代表了文本到长视频生成领域的重大突破。通过巧妙的CAM、APM和随机混合设计,它成功解决了长期困扰该领域的视频停滞、时间不一致和质量退化问题。
这项工作不仅在技术上具有创新性,更重要的是,它让高质量长视频生成从实验室走向实用,为AI辅助内容创作开辟了新的可能性。随着基础模型的不断改进,我们有理由期待StreamingT2V能够生成更长、更高质量、更具创造性的视频内容。
从某种意义上说,StreamingT2V不仅是一个算法的进步,更是向"AI导演"时代迈出的坚实一步。未来,也许每个人都能成为自己故事的导演,只需要一段文字描述和一个AI助手。
希望这篇详细的介绍和博客能帮助您全面理解StreamingT2V论文!如果您需要针对特定部分进行更深入的讨论,或者想了解如何实现某个具体模块,请随时告诉我。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)