强化学习学习笔记chapter1
本文介绍了强化学习的基本概念及算法实现。主要内容包括:1)强化学习的五大核心要素(agent、state、action、env、reward)及Gym工具包的使用方法,通过Taxi游戏示例展示了Q-learning算法的实现过程;2)马尔可夫决策过程的数学建模,重点阐述了策略转换和环境状态转换的随机性特征;3)值函数的核心作用,包括状态价值函数和动作价值函数的定义及其贝尔曼方程表达;4)三种经典迭
(一)强化学习基本概念及工具包
(1)通过对强化学习数学原理的学习我们大致了解了强化学习五大元素:agent,state ,action,env,reward,以及一些基本概念(trajectory,state value,action value...)。本篇文章主要记录了强化学习算法在代码实现层面的学习经历。(使用gym包进行模拟游戏环境)
gym包含三个类,但我们只会用到env类来模拟环境,agent类:单智能体,algorithm:算法:
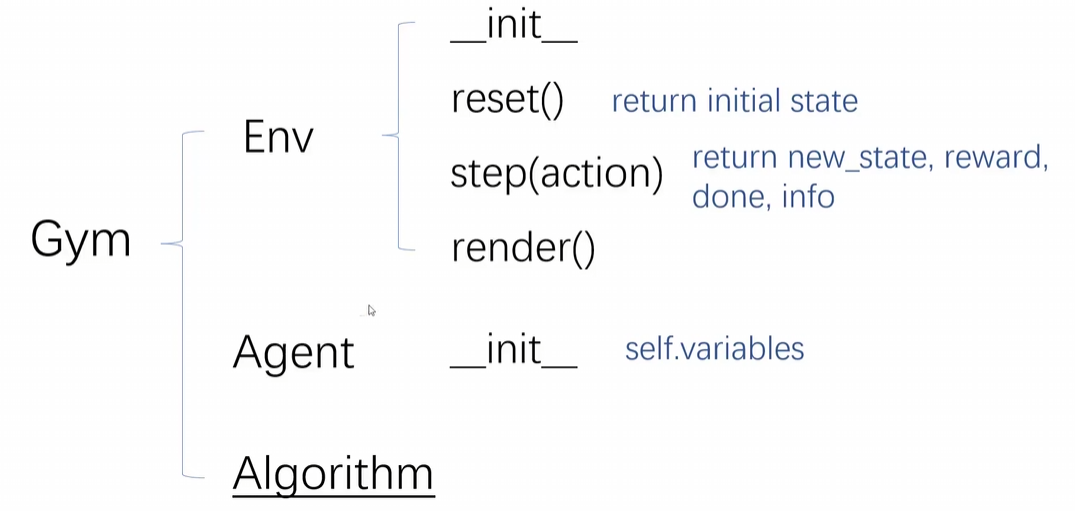
来一个例子吧,step会返回四个值info我们一般是不用的,done表示游戏是否结束:
import gymnasium as gym
env = gym.make('Cliffe-v0')#网格世界
env.action_space= list(range(4))#定义动作空间
env.reset()
new_state,reward,done,info=env.step(env.action_space.sample())#随机执行一个动作
env.render()#把这一帧游戏画面展示再来简单看一下一个完整的代码,目前仅作了解:
import numpy as np
import gym
import random
def main():
env = gym.make('Taxi-v3')
state_size = env.observation_space.n
action_size = env.action_space.n
qtable = np.zeros((state_size, action_size))#创建一个q表
#一些超参数的定义
learning_rate = 0.9
discount_rate = 0.8#gamma
epsilon = 1.0
decay_rate = 0.005
num_episodes = 1000#这一千条轨迹用来生成数据
max_steps = 100
#开始玩游戏,train一下
for episode in range(num_episodes):
state = env.reset()
done = False
#每一局游戏最大只能玩一百步
for s in range(max_steps):
if random.uniform(0,1)<epsilon:
action = env.action_space.sample()#增加随机性,有可能会随机选择一个action
else:
action = np.argmax(qtable[state,:])#不随机的情况下直接拿对应状态中reward最大的一个action
#每一步都可以得到新的一些参数:
new_state, reward, done, _ = env.step(action)#这里不关心info因为不会用
#qlearning
qtable[state,action] = qtable[state,action]+learning_rate*(reward + discount_rate * np.max(qtable[new_state,:]))
state = new_state
if done==True:
break
epsilon = np.exp(-decay_rate*episode)
#游戏玩完了 ,但前面只是在训练数据,下面我们来测试一下
state = env.reset()
rewards = 0
done = False
#test一下
for s in range(max_steps):
action = np.argmax(qtable[state,:])#策略已经有了,直接选q值最大的action
new_state, reward, done, _ = env.step(action)
env.render()
rewards += reward
state = new_state
if done:
break
env.close()#全部结束
if __name__ == '__main__':
main()(2)直观上来讲强化学习的过程是这样的:智能体(下文统称 agent)初始处于环境(env)的某一特定状态(state),而环境中存在多个可切换的状态选项。agent 通过执行特定动作(action)与环境交互,进而触发状态转移 —— 即从当前状态切换至另一状态。每次状态转移都会伴随即时奖励(reward),该奖励用于直接评判动作的优劣;实际场景中,我们通常以即时奖励(reward)或累积回报(return,某一交互轨迹上所有奖励的总和)为核心依据,制定并优化 agent 的行为策略。
(二)强化学习基本算法:一堆数学公式的轰炸
1.马尔可夫决策过程(所有强化学习算法的基础)
数学模型: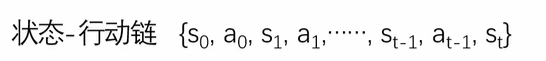
即一个状态会执行一个动作,这个动作会触发状态变化;在新状态下,又会执行新的动作并转换为下一个状态,这一过程持续循环,直到状态St达到目标状态(target state)。
我们需要知道一些东西:在这个循环链中,存在两类核心转换:
-
策略转换:聚焦 “状态到动作” 的映射(
S→A),策略相对更具确定性; -
环境的状态转换:聚焦 “状态 + 动作到新状态” 的映射(
S,A→S'),本质是环境的随机响应,随机性更强。
其中,策略(本质是条件概率相关的映射规则)分为两种:
-
概率型策略
Π(a|s):给定状态s时,选择动作a的概率分布,是S×A的映射关系 —— 每个动作都有对应的发生概率,并非唯一确定。 -
确定性策略
Π(s)=a:给定状态s时,直接输出唯一对应的动作a,是S→A的确定映射 —— 无需概率分配,动作由状态直接决定。
而环境对 “状态s+ 动作a” 的响应,就是状态转换,其数学表达为 P(s'|s,a):在当前状态s和执行动作a均确定的前提下,转移到新状态s'的概率。
这里需遵循马尔可夫性:下一时刻的状态转换仅与当前时刻的状态s相关,与当前时刻之前的历史状态无关。后续的所有求解都会以这样一种性质来简化考虑。
那么知道了上面这些东西有什么用呢,我们来看一下:在强化学习中,奖励(reward)是核心元素之一,整个学习过程的目标是最大化累积奖励。若直接以各时刻奖励的总和表示累积奖励,即:∑t=0∞r**t则该式可能因状态循环导致奖励无限累积,从而不具备可计算性(无法收敛)。结合前文的核心概念,可通过两点改进解决这一问题:
-
引入折扣系数解决收敛问题在每时刻的奖励 r**t 前乘以折扣系数 γ**t(其中 γ∈[0,1) ),将累积奖励修正为:∑t=0∞γtr**t随着时间步 t 增大,γ**t 逐渐趋近于 0,后期奖励的权重被不断削弱,确保累积奖励能够收敛。
-
利用马尔可夫性简化计算由于未来状态仅依赖当前状态(马尔可夫性),无需从初始时刻开始计算累积奖励,只需关注 “从当前时刻状态 s**t 出发的未来累积奖励”,即:∑k=0∞γkr**t+k这一简化大幅降低了计算复杂度,且完全符合状态转换的特性。
这样的改进既保证了累积奖励的可计算性,又充分利用了马尔可夫决策过程的结构特性。
2.策略迭代
但这样修正后的累积奖励,仍存在一个关键问题:实际场景中,我们无法预知未来每一步的状态转换与奖励(状态转换由环境概率P(s'|s,a)决定,动作选择由策略Π(a|s)决定,均存在不确定性)。
因此,最合理的方式是引入期望(用概率加权平均),通过期望估计 “当前状态 / 状态 - 动作对” 对应的长期累积奖励 —— 这种基于期望的累积奖励,就是值函数**(Value Function)。
值函数主要分为两类,它们都是最初版本的改进,都是对回报的估计,我们希望越大越好:
1. 状态价值函数 (V^Π(s))
-
定义:在当前状态 s 下,遵循策略 (Π) 所能获得的期望累积奖励。
-
数学表达:
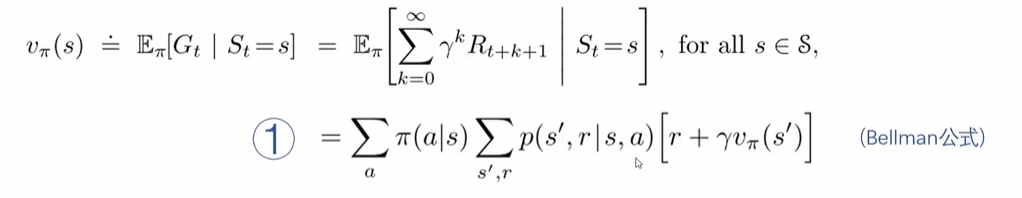
-
解释:在当前state下策略Π下会有概率产生多种action,而每一个action我们都可以求得
当前及后续的累积回报,再将每一个action得到的回报加权平均,就是当前s下遵循Π策略得到的期望累积奖励
2. 动作价值函数 (q^Π(s,a))
-
定义:在当前状态 s 下,执行动作 a 后再遵循策略 (Π),所能获得的期望累积奖励。
-
数学表达:我们同样把qΠ(S)写成贝尔曼公式的形式
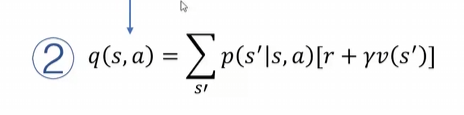
-
解释:我们看到这个式子,它好像与VΠ(S)产生了某种联系,我们会先得到V再求出q。
这个函数是对s^进行了加权平均,意思是在当前s下采取了a动作会得到一个到达s^的概率,
用v(s^)得到的是下一个状态的价值,再加上当前状态的immediate reward就可以求到当前状态下做这个动作的价值,在qΠ(s,a)里面将v(s^)作为了计算后续回报的一种手段。
这两类值函数并不需要我们推导,我们只需要理解公式在干什么就好
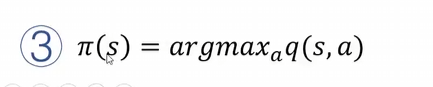
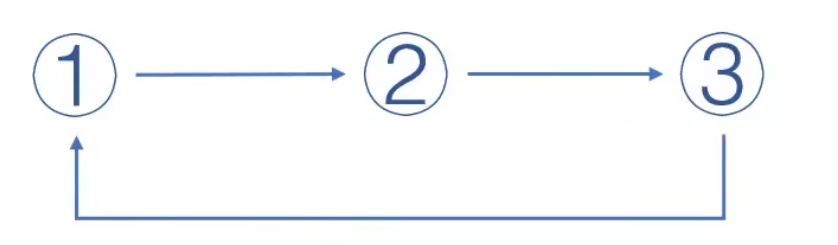 而这样一个模型就是策略迭代。
而这样一个模型就是策略迭代。
3.价值迭代
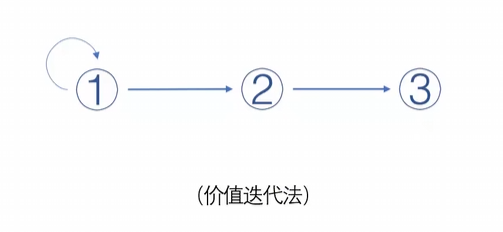
先让V(s)迭代到最优,不要让三个一起来迭代浪费时间和资源。因为前面我们铺垫了这么多,所有这里理解起来十分简单。
4.泛化迭代 = 价值迭代+策略迭代,先让值函数接近最优,再用值函数进行策略改进
其实三种迭代方法本质目标完全一致 都是通过持续迭代,找到每个状态(或状态 - 动作对)下 “能带来最大动作价值” 的最优动作,最终让整个轨迹的累积回报(期望)达到最大。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)