道生一,图生智: LGM如何打破 RAG 对长上下文大模型的依赖
本文介绍了一种基于道家哲学思想的新型检索增强生成(RAG)方法——Language Graph Model(LGM)。作者从"道生万物"的理念出发,提出通过"概念+元关系"的图结构来重构知识检索,而非依赖传统的超长上下文窗口。LGM采用三类元关系(继承、组成、别名)构建语法关系图(SRG)和概念关系图(CRG),通过概念迭代检索机制实现多跳推理。实验表明,L
—— 一篇来自第一作者的技术与哲思记录
arXiv:https://arxiv.org/abs/2511.03214
GitHub:https://github.com/Philisense/language-graph-model
大家好,我是 雷文昌。
这篇博客想系统地聊三件事:
- 我为什么会从道家哲学出发去思考 RAG 的问题;
- 我在论文 《LGM: Enhancing Large Language Models with Conceptual Meta-Relations and Iterative Retrieval》 里到底做了什么;
- 这套 Language Graph Model(LGM) 是如何打破当前 RAG 领域对“超长上下文大模型”的路径依赖的。
一、从“道生一,一生二,二生三,三生万物”说起
如果你做过一段时间的大模型应用,应该对这套 RAG 流程已经很熟悉了:
- 文档切块(chunking)
- 向量化(embedding)
- 相似度检索
- 把若干块文本塞进上下文,让大模型回答
这套东西非常实用,但也有公认的痛点:
- 一旦问题需要 多跳推理(跨多段、多文档),就很容易漏证据;
- 知识里充满 别名、缩写、上下位概念,向量召回说不上“真正理解”;
- 知识库越来越大,只能不断 堆长上下文窗口,算力和费用压力非常明显。
有段时间我在想:
有没有可能,不靠“无限拉长上下文窗口”,也能让模型处理任意大的文本?
我很自然地想到了老子那句:
“道生一,一生二,二生三,三生万物。”
如果把这句话翻译成“知识工程语言”,大致可以理解为:
- 世界不是一堆离散的事实;
- 世界是从一些抽象的结构 / 关系不断“生长”出来的网络。
于是,在 LGM 这篇工作里,我刻意做了一件事:
从道家“道生万物”的视角出发,把文本世界重写成“概念 + 元关系”的图结构,
让检索沿着“关系”走,而不是一味堆长上下文。
换句话说:
不再迷信“更长的上下文”,而是相信“更好的结构”。
二、现有 RAG 的根本问题:它“看不到关系”
在我看来,传统 RAG 有两个根本问题:
- 检索单位是文本块,而不是概念。
它不知道“苹果”和“水果”、“CPU”和“计算机”、“内部代号”和“正式名称”之间的关系,它只知道“这些字符串在向量空间里比较接近”。 - 扩展能力完全依赖长上下文窗口。
当知识库变大,只能不断增加:- 更长的上下文窗口,
- 更大、更贵的基础模型。
结果是:RAG 和长上下文大模型形成了强耦合,
仿佛“不堆上下文,就做不好复杂问答”。
在 LGM 中,我做的第一件事,就是把这个耦合拆开。
三、用三类“元关系”把文本变成语言图
受“道生万物”的启发,我在 LGM 里刻意只用三类元关系(Meta-Relations) 来组织知识:
- 继承(Inheritance)
- “苹果是水果的一种”
- “Llama 是大语言模型的一种”
→ 这类关系回答“它属于谁”。
- 组成(Composition)
- “计算机由 CPU、内存、硬盘组成”
- “系统由多个模块组成”
→ 这类关系回答“它由什么构成”。
- 别名(Alias)
- “DNA / 脱氧核糖核酸”
- “kg / 千克”
- 产品内部代号 / 外部商品名
→ 这类关系回答“它还有哪些叫法”。
在这个设定下,一个概念的“含义”不是一个孤立的词典定义,而是:
- 自身的描述;
- 父类的共性(继承);
- 子类的特性;
- 组成部分带来的能力;
- 以及所有别名下汇聚的证据。
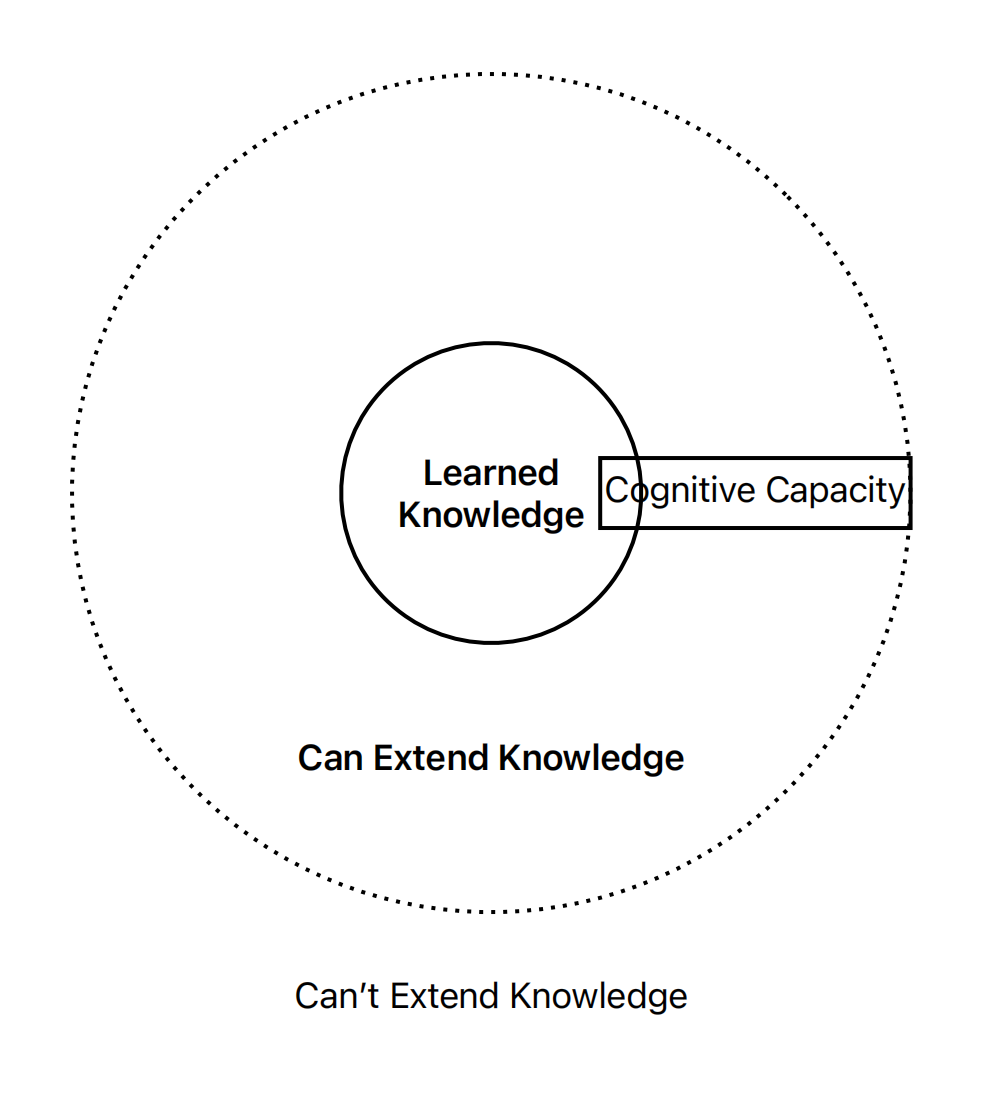
图1:从人类认知到 Language Graph 的整体视角
这其实就是把“道生万物”里的“道”,具象成了一张可计算的语言图:
关系先于文本、结构优于长度。
四、两张图:SRG + CRG,把语言拆成“说法”和“道理”
在实现上,LGM 是由两张图共同构成的:SRG(语法关系图) 和 CRG(概念关系图)。
4.1 SRG:Syntactic Relation Graph —— 聚焦“说法”
SRG 主要解决一个问题:原文是怎么说的?
它记录:
- 章节 / 段落 / 句子 / 词元;
- 句子的从属关系、依存结构;
- 指代关系(把“它/他/他们”还原到真实实体)。
SRG 保证:
- 当我们在概念层面做完一轮推理之后,
一定可以回到 人类可读的原句证据,这是可解释性的基础。
4.2 CRG:Concept Relation Graph —— 聚焦“道理”
CRG 则是对“道理”的抽象:
- 节点:词形还原后的概念;
- 边:继承 / 组成 / 别名三类元关系;
- 有一个抽象的根节点 Thing 作为“万物之源”。
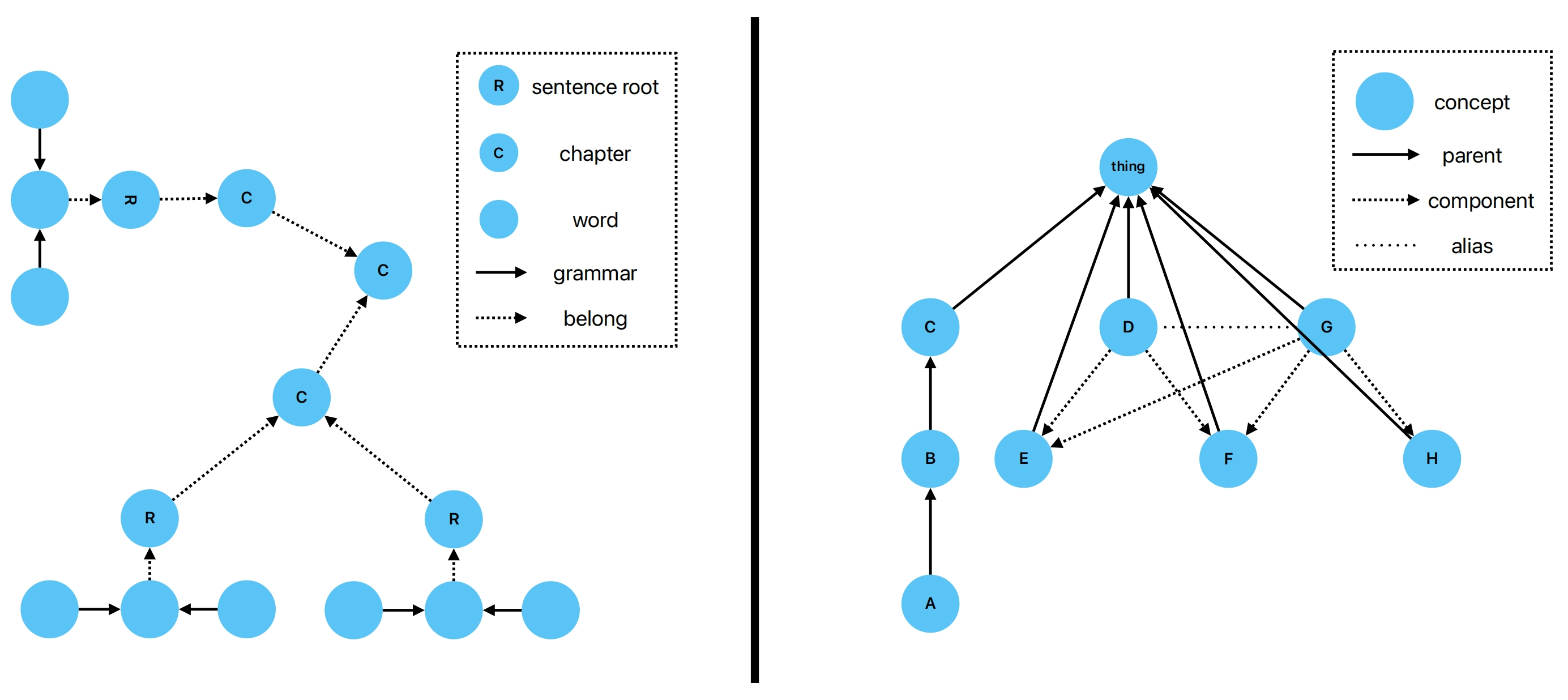
图2:SRG 与 CRG 的结构示意
如果说:
- SRG 像是“语言长什么样”;
- 那 CRG 更像是“世界是怎么组织的”。
LGM 的核心,就是在这两张图之间来回跳转:
在 CRG 上扩展概念,在 SRG 中抽取证据。
五、LGM 的两大阶段:学习语言图 + 概念迭代检索
LGM 的工作流可以分成两个阶段:
- Learning 阶段:从文档学习语言图
- 概念迭代检索:在图上做推理 + 控制上下文
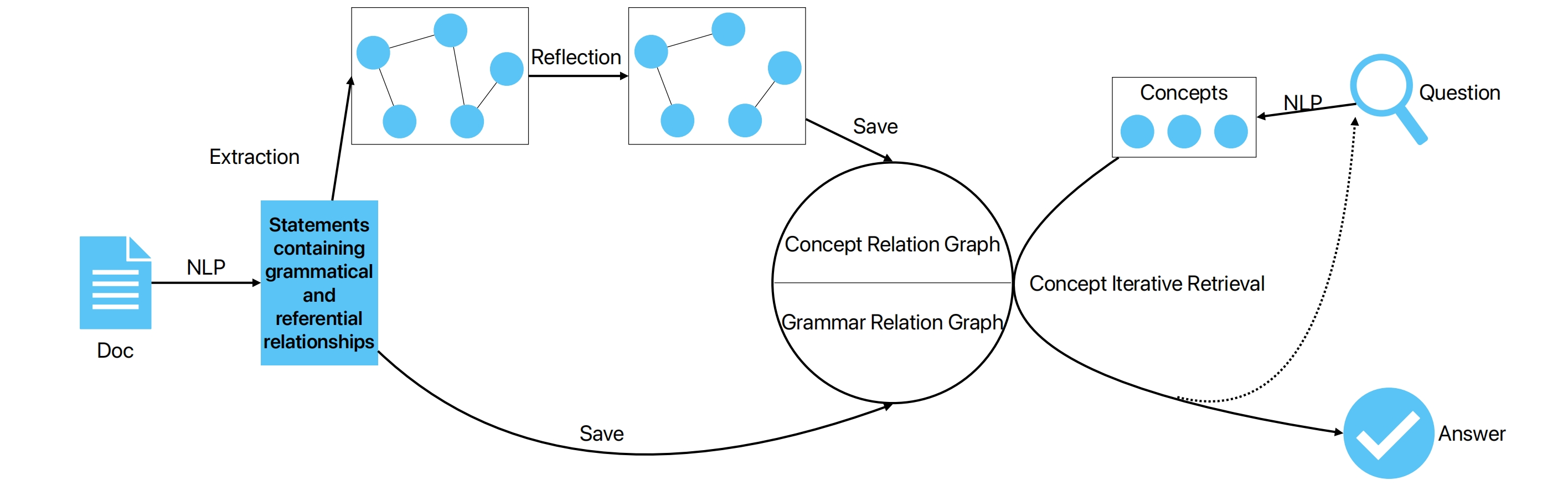
图3:LGM 整体工作流
5.1 Learning 阶段:把文档“吃进图里”
在这个阶段,我们做几件关键的事:
- NLP 预处理
- 分句、分词、依存分析、指代消解、词形还原;
- 构建 SRG,让文本的语言结构完整被记录下来。
- 元关系抽取
- 借助大模型 + Prompt,从句子中抽取继承 / 组成 / 别名关系;
- 得到大量候选三元组。
- Reflection 反思机制过滤错误关系
- 把直接提到该关系的句子暂时拿掉;
- 只让大模型根据其他证据判断该关系“是否真的合理”;
- 无效的关系被剔除,“不确定”的先留着。
这一整套,是在用“关系质量”而不是“关系数量”来定图的可靠性。
5.2 概念迭代检索:不用长上下文,也能做复杂推理
真正回答问题时,LGM 采用的是 Concept Iterative Retrieval(概念迭代检索):
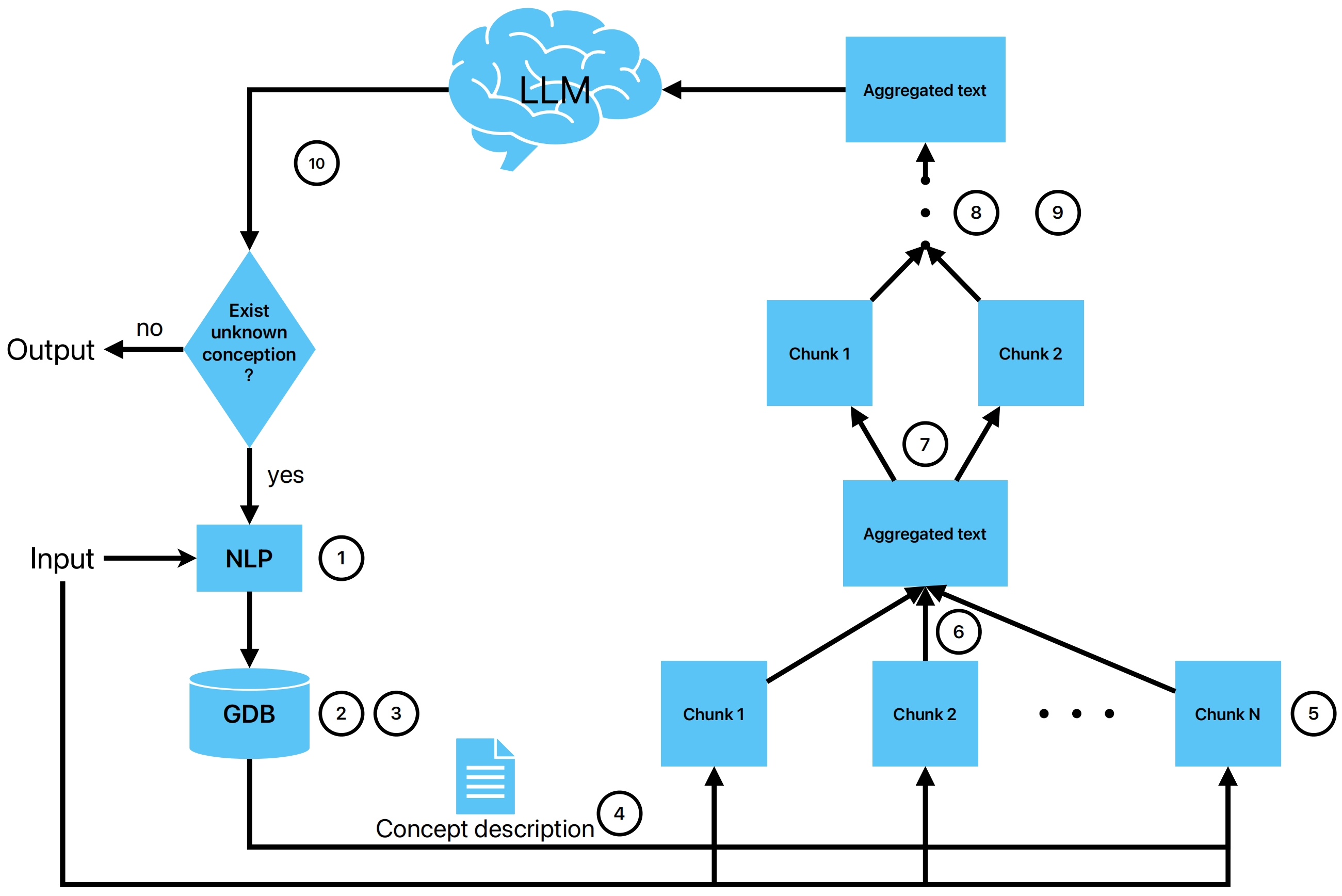
图4:概念迭代检索流程
简化来说,它分为七步:
- 从问题中抽取关键概念;
- 在 CRG 上按继承 / 组成 / 别名扩展概念闭包;
- 回到 SRG,抓取所有相关的原句证据;
- 把证据句切块,交给大模型并行标记“支持该问题”的句子;
- 合并这些支持句,如过长就逐步总结、压缩;
- 长度仍超限时,用 ROUGE 选出与问题最相关的部分;
- 让大模型在这些证据上生成答案,如果发现某些概念缺证据,就再回到 CRG 做下一轮扩展。
关键在于:
整个过程中,大模型看到的上下文始终是“小而精”的证据集合,
而不是“粗暴堆上来的一大坨长文本”。
这就是 LGM 可以摆脱对超长上下文依赖的根本原因:
我们在结构层面先做了一轮“瘦身”。
六、实验结果:不用堆上下文,照样打得过一众 RAG
论文中,我在两个典型多跳问答数据集上评估了 LGM:
- HotpotQA
- Musique
并选用两种基础大模型,与 GraphRAG、LightRAG、FastRAG、Dify 等多种方案进行了对比。
6.1 F1 对比(Table 3):LGM 站在第一梯队
我们在论文里给出了如下表格(Table 3):
|
Method |
HotpotQA (DeepSeek) |
HotpotQA (Llama) |
HotpotQA AVG |
Musique (DeepSeek) |
Musique (Llama) |
Musique AVG |
|
Language Graph Model |
89.46% |
87.06% |
88.26% |
68.13% |
63.07% |
65.60% |
|
GraphRAG 1 |
88.55% |
82.59% |
85.57% |
64.98% |
63.16% |
64.07% |
|
GraphRAG 2 |
86.90% |
69.21% |
78.06% |
48.98% |
48.61% |
48.79% |
|
LightRAG 2 |
87.94% |
76.34% |
82.14% |
65.36% |
50.33% |
57.84% |
|
FastRAG 3 |
72.66% |
72.26% |
72.46% |
39.91% |
36.51% |
38.21% |
|
Dify |
68.53% |
43.64% |
56.09% |
52.32% |
18.27% |
35.29% |
可以看到:
- 在 HotpotQA 和 Musique 上,LGM 的平均 F1 都是最高,超越了微软的GraphRAG,因特的FastRAG等;
- LGM 在同样的基础模型和相似的资源预算下,整体优于一众现有 RAG 方案。
6.2 关键点:性能对上下文窗口“不敏感”
更重要的是,我还专门做了一个实验:
让最大输入长度从 120k 一路压到 30k,观察性能变化。
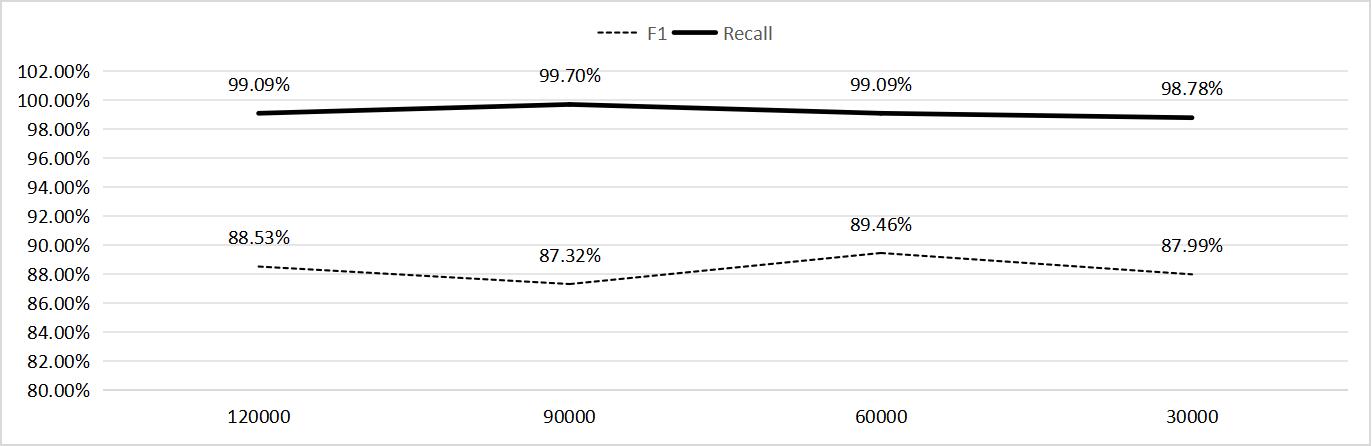
图5:不同上下文窗口大小对 LGM 性能的影响
结果表明:F1 和 Recall 变化非常平滑,
没有出现那种一缩窗口就“性能断崖式下跌”的情况。
这就印证了一个核心结论:
LGM 的性能来自结构化检索和概念推理,
而不是对“更长上下文、更大模型”的依赖。
换个说法:
哪怕只用中等上下文窗口 + 相对便宜的基础模型,
只要结构建得好,一样能处理任意长文本和多跳推理。
七、这对 RAG 方向意味着什么?
站在研究者和工程师的双重视角,我觉得 LGM 至少说明了两点:
- 长上下文不是唯一出路。
我们完全可以通过更好的结构、更聪明的检索,
来降低对“巨无霸上下文窗口”的依赖。 - 东方式哲学可以给 AI 带来新的视角。
“道生一,一生二,二生三,三生万物”这句话,
如果用工程方式重新理解,就会变成: 用少量元关系组织起概念世界,再让大模型在其上做推理。
这也是我在这篇工作中最想实践的一点:
敢不敢不跟随“堆大堆长”的潮流,
而是回到“关系”本身,从结构上重写 RAG?
八、如果你也在做 RAG / 知识库 / 多跳推理
如果你现在在做:
- 企业知识问答 / 内部知识库检索;
- 客服、工单、缺陷定位;
- 合规、风控、审计场景;
- 或者学术上的多跳问答、长文理解;
那么我真心建议你可以:
- 尝试在系统里显式构建一些 继承、组成、别名 这种简单关系;
- 试着围绕“概念 + 证据原句”来设计检索与推理流程;
- 把对“长上下文大模型”的依赖,看作可以被削弱甚至部分替代的东西。
九、结语:从道家一句话,到 RAG 的另一种可能
最后,再回到那句老话:
“道生一,一生二,二生三,三生万物。”
在 LGM 这篇工作里,我只是做了一件很小的事情:
- 把“道”理解成一种抽象关系结构;
- 把“万物”理解为文本世界里无数概念和句子;
- 然后试图用一张语言图,把这两者连了起来。
如果这篇论文、这套 LGM 的实践,
能让你在做 RAG 的时候,暂时停下来想一想:
“我真的需要更长的上下文吗?
还是说,我可以先把关系理清楚?”
那这篇受道家启发的小小工作,就已经实现了我最初的初心。
如果你有兴趣深入交流实现细节、实验设置或落地经验,
欢迎在评论区留言,或者私信我一起聊聊。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)