MSTAgent-VAD: Multi-scale video anomaly detection using time agent mechanism for segments’ tempora
由于训练过程中缺乏帧级标注,视频异常检测(VAD)需要开发无需全面监督的学习方法。以往方法主要聚焦于建模时间依赖关系与学习判别性特征,但常面临异常检测不完整、视频片段分离能力弱等问题。为解决这些问题,本文提出一种基于时间代理机制的多尺度 VAD 方法,称为,在方法结构与特征学习方面实现了显著创新:首先,针对视频中异常事件在时间尺度上的多样性,我们设计了一种多尺度时间注意力模块,用于捕获不同长度异常

MSTAgent-VAD: Multi-scale video anomaly detection using time agent
mechanism for segments’ temporal context mining
Expert Systems With Applications(CCF-C/中科院1区)
https://www.sciencedirect.com/science/article/pii/S0957417425007766
摘要
由于训练过程中缺乏帧级标注,视频异常检测(VAD)需要开发无需全面监督的学习方法。以往方法主要聚焦于建模时间依赖关系与学习判别性特征,但常面临异常检测不完整、视频片段分离能力弱等问题。为解决这些问题,本文提出一种基于时间代理机制的多尺度 VAD 方法,称为 MSTAgent-VAD,在方法结构与特征学习方面实现了显著创新:
首先,针对视频中异常事件在时间尺度上的多样性,我们设计了一种多尺度时间注意力模块,用于捕获不同长度异常片段的时间特征,从而增强时间一致性,并克服传统方法在检测持续时间各异的异常时的局限性;
其次,通过可变形卷积生成时间代理令牌(temporal agent tokens),该时间代理机制可在特征空间中强化正常与异常片段之间的区分度,提升二者分离能力——尤其在处理不完整异常或边界模糊情形时,显著增强了模型判别力;
最后,基于多示例学习(MIL),我们采用一种改进的鲁棒时间特征幅值学习(RTFM),用于检测多个离散的异常片段,解决了传统方法在复杂场景中难以识别多样异常的挑战,保障了对多种异常事件检测的准确性。
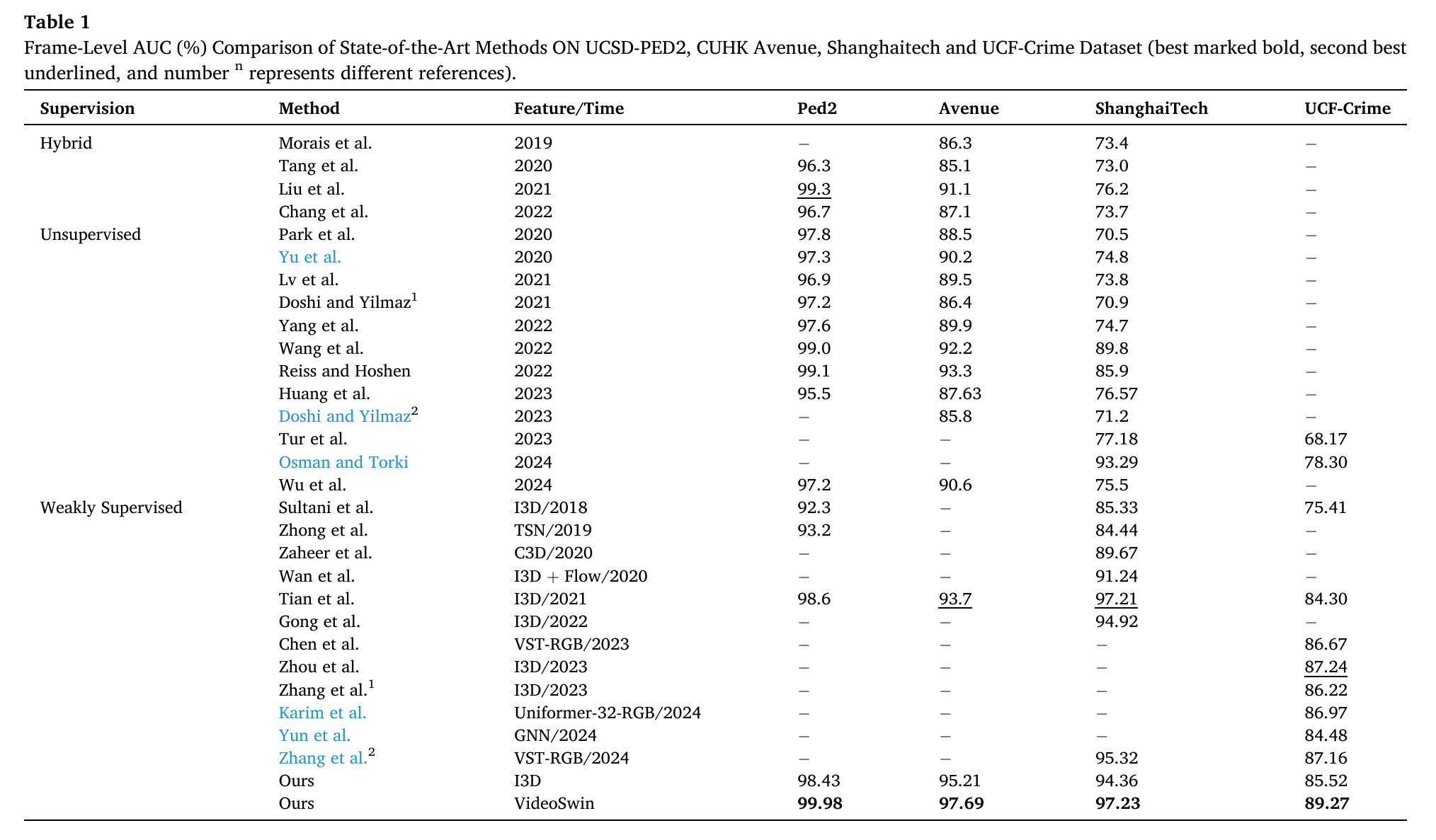
实验结果显示,本方法在 UCSD-Ped2、CUHK Avenue、ShanghaiTech 和 UCF-Crime 四个数据集上均达到当前最优(state-of-the-art),能准确识别多种异常事件,展现出优异的泛化能力。本研究为监控场景下的 VAD 应用提供了创新性解决方案,有效提升了真实场景中的检测性能。
1. Introduction
近年来,社会的快速发展导致日常生活中各类安全威胁与突发事件频发,凸显了视频异常检测(Video Anomaly Detection, VAD)的重要性。VAD 是指在预期为正常的视频数据中,识别出与正常模式显著偏离的异常数据,从而自动检测并定位不符合预期行为的事件(Bai et al., 2021)。作为计算机视觉应用中的关键领域之一,VAD 因其在自主监控系统中的巨大应用潜力,已受到学术界与工业界的广泛关注(Sultani et al., 2018; Wu et al., 2021; Yang et al., 2023)。然而,复杂背景、高维数据以及异常定义模糊等挑战,使得对未见过异常的建模尤为困难,从而令 VAD 成为一项极具挑战性的任务(Wang et al., 2022)。
视频异常检测(VAD)的目标是定位异常事件发生的时间窗口。传统的检测方法依赖人工对视频进行异常判读,然而随着监控视频数量激增,人工检测不仅耗费大量人力,还易出现漏检(omission)或误检(error detection)问题。
随着计算机技术的发展,一些基于手工特征(manual features)的经典异常检测方法被提出(Cong et al., 2011;Wang & Miao, 2010)。这类方法通过对视频数据的动作特征(action features)与外观特征(appearance features)建模,进而识别异常行为。然而,其普遍存在以下缺陷:
- 无法有效捕获异常的判别性信息(discriminative information);
- 特征工程过于复杂,难以在实际中大规模部署。
近年来,深度学习方法已主导 VAD 领域(Chang et al., 2020;Gong et al., 2022;Reiss & Hoshen, 2022;Wan et al., 2020;Wang et al., 2022;Wu et al., 2023),其主流范式可分为两类:
- 无监督异常检测方法(unsupervised VAD)
仅使用正常视频数据,通过学习其概率分布建模正常行为模式,并训练无监督分类器进行异常判别(Doshi & Yilmaz, 2021;Huang et al., 2023;Lv et al., 2021 等)。
❗ 然而,现实场景中异常事件种类繁多,且远少于正常事件;仅依赖正常数据训练导致模型缺乏对异常的感知能力,限制了检测性能。 - 弱监督异常检测方法(weakly supervised VAD)
采用视频级标签(video-level labels)进行训练——即仅标注整段视频是否包含异常(如“正常”或“异常”),无需逐帧标注(Gong et al., 2022;Sultani et al., 2018;Tian et al., 2021 等)。相比无监督方法,其在标注成本较低的前提下,实现了更高的异常分类精度。 主流框架基于多示例学习(MIL, Multi-Instance Learning):训练集中每个视频(即一个“bag”)仅提供视频级别标签,而未提供异常发生的具体位置;测试阶段,模型需对每一帧输出一个异常得分 $ s_i \in [0,1] $,从而实现帧级定位。
综上,弱监督 MIL 框架在实用性和性能之间取得了良好平衡,已成为当前 VAD 的主流研究方向。
多示例学习(MIL)通过平衡异常片段与正常片段的数量来实现视频异常检测(VAD)。然而,大多数基于 MIL 的方法存在以下局限性:
(1)等长分段方式忽略了异常事件的持续时间差异,导致对异常事件的表征不完整;
(2)时序关联建模不足,难以有效区分正常与异常片段;
(3)倾向于仅检测最显著的异常片段,而忽略其余异常片段。
部分方法(Deshpande 等,2022;Le & Kim,2023;Sun & Gong,2024;Zhang 等,2023)通过引入注意力机制或多尺度建模策略,更好地适应异常事件在时间维度上的变化,从而克服静态分段的局限性,并缓解等长分段导致的异常持续时间被忽略的问题。然而,当面对异常持续时间差异较大、异常行为长度不一致的复杂场景时,这些方法仍可能丢失关键信息。
为应对时序关联不足的问题,一些研究(Chen 等,2023;Zhang 等,2024;Zhong 等,2022)采用时空编码器或图卷积网络,以捕捉视频片段间的时空依赖关系,从而有效提升正常与异常片段的可分性。但这些方法在处理长时间跨度或复杂时序依赖时,可能因过度依赖局部信息而忽视全局时序结构。
针对“仅检测最显著异常而忽略其他类型异常”的问题,已有工作(Georgescu 等,2021;Sun & Gong,2023;Tian 等,2022;Wang 等,2020)通过对比学习或多任务学习框架,提升了模型对细微或边缘异常的敏感性。尽管如此,这些方法在处理多类异常事件时仍存在局限,部分异常片段仍可能被遗漏或误判。
为解决上述问题,本文提出一种基于时间代理机制的多尺度视频异常检测方法,称为 MSTAgent-VAD。具体而言:
-
针对等长分段导致的异常表征不完整问题,我们设计了一个多尺度时间注意力模块,可灵活适配不同时间尺度的上下文表征。该模块从不同长度的视频片段中提取丰富的上下文与细节信息,使模型能更准确地捕捉异常事件的持续性与时序特征细节,从而提升异常片段的特征学习能力,避免传统等长分段造成的异常表征缺失问题。
-
为应对时序关联建模不足的挑战,我们提出一种时间代理机制(Time Agent Mechanism):通过可变形卷积生成时间代理令牌(temporal agent tokens),动态捕获片段间的时序依赖关系;这些令牌随后输入代理 Transformer 的自注意力机制中进行处理,使模型有效建模长程时序依赖,增强特征空间中正常与异常片段的可分性,进而提升模型对时序信息的敏感度。
-
为进一步提升模型在含多个离散异常片段视频中的性能(传统 MIL 方法常忽略较小异常),我们采用基于多示例学习(MIL)的鲁棒时间特征幅值学习(RTFM)方法。RTFM 可有效处理视频中的多段异常。为增强模型对正常与异常片段间细微差异的感知能力,我们引入类别对比损失(category contrast loss),优化 RTFM 的异常评分策略,最大化异常与正常视频间的表征差异。此外,我们进一步融合了时序平滑约束与稀疏性约束,使模型能更可靠地捕捉视频中多个异常片段,显著提升对复杂离散异常的检测精度、鲁棒性与可靠性。
本文的主要贡献如下:
- 多尺度时间注意力模块:提出一种能灵活捕获多时间尺度片段特征的模块,通过引入更丰富的时序上下文信息,增强模型对各类异常事件的表征与检测能力;
- 时间代理机制:利用可变形卷积生成代理令牌,自适应优化正常与异常片段的特征分布,形成更清晰的类别边界,从而强化时序关联建模能力,提升对多样化异常片段的检测准确性;
- RTFM 改进策略:通过融合对比学习、时序平滑与稀疏性约束,推动特征幅值的稳健学习,实现在多种数据集上对复杂异构异常事件的精准检测。
在 UCSD-Ped2、CUHK Avenue、ShanghaiTech 和 UCF-Crime 四个主流数据集上的实验表明,本方法性能显著优于多种当前最先进的方法。
3. Methodology
3.1. Video anomaly detection problem description
给定一组训练视频,记为 $ B $ 个包(即 $ B $ 段视频){V1,V2,…,VB}\{V_1, V_2, \dots, V_B\}{V1,V2,…,VB},每段视频 $ V_i $ 对应一个视频级标签 $ Y_i \in {0,1} $,其中
Yi={1,若视频 Vi 中至少包含一个异常实例;0,否则(即 Vi 全为正常内容). Y_i = \begin{cases} 1, & \text{若视频 } V_i \text{ 中至少包含一个异常实例};\\ 0, & \text{否则(即 } V_i \text{ 全为正常内容)}. \end{cases} Yi={1,0,若视频 Vi 中至少包含一个异常实例;否则(即 Vi 全为正常内容).
每个包(即每段视频)ViV_iVi 被划分为 ttt 个视频片段:
Vi={vi,1,vi,2,…,vi,j,…,vi,t},i∈{1,2,…,B}, j∈{1,2,…,t}. V_i = \{v_{i,1}, v_{i,2}, \dots, v_{i,j}, \dots, v_{i,t}\}, \quad i \in \{1, 2, \dots, B\},\; j \in \{1, 2, \dots, t\}. Vi={vi,1,vi,2,…,vi,j,…,vi,t},i∈{1,2,…,B},j∈{1,2,…,t}.
视频异常检测(VAD)的目标是构建一个模型,使其对每段测试视频中的每个片段 $ v_{i,j} $ 输出一个帧级(或片段级)异常得分,即得到得分序列:
Si={si,1,si,2,…,si,j,…,si,t},其中 si,j∈[0,1]. S_i = \{s_{i,1}, s_{i,2}, \dots, s_{i,j}, \dots, s_{i,t}\}, \quad \text{其中 } s_{i,j} \in [0,1]. Si={si,1,si,2,…,si,j,…,si,t},其中 si,j∈[0,1].
得分越高,表示该片段越可能为异常;最终可通过设定阈值(如 si,j>τs_{i,j} > \tausi,j>τ)判断当前视频片段是否异常。
3.2. Method description
本文提出了一种基于视频级标签的弱监督异常检测方法,整体流程分为三个主要阶段(如图1所示),并设计了多个模块以提升异常事件检测的准确性与鲁棒性。
为统一处理不同长度的视频,每段视频被划分为固定数量的片段(segments),确保每个片段包含相同帧数。该方法基于以下假设:
- 异常视频划分出的片段中至少包含一个异常片段;
- 正常视频划分出的所有片段均为正常片段。
各阶段具体如下:
第一阶段:视频特征提取与多尺度特征建模
每个视频片段通过预训练的视频特征提取模型(本文采用 VideoSwin Transformer)提取丰富的空间与语义特征。这些特征作为基础输入,送入多尺度时间注意力模块。该模块结合空洞卷积(dilated convolution)与成对自注意力机制(paired self-attention),从不同时间尺度捕获短时与长时依赖特征,从而有效融合局部细节与全局上下文信息,显著提升模型对不同持续时长异常事件的感知能力。
第二阶段:基于时间代理机制的时序特征建模
时间代理机制在特征空间层面运作:利用可变形卷积(deformable convolution)从多尺度上下文特征中生成时间代理令牌(temporal agent tokens),以增强片段间的时序依赖建模。这些代理令牌可自适应聚焦于异常片段中的关键时序信息,并通过自注意力机制提升对边界模糊或不完整异常片段的建模能力,从而强化异常与正常片段在特征空间中的判别性表征。
第三阶段:异常检测与优化
在最终阶段,采用改进的 RTFM(Robust Temporal Feature Magnitude)模型对提取的片段特征进行异常评分。为进一步优化性能,引入以下三项损失机制:
- 对比损失(contrastive loss):拉近同类样本距离,推开异类样本,增强类别可分性;
- 时序平滑约束(temporal smoothing loss):使相邻片段的异常得分变化平缓,提升时序一致性;
- 稀疏性约束(sparsity loss):符合异常事件稀疏性先验,抑制无关片段响应。
这些改进共同保障了异常检测结果在时间维度上的稳定性,降低了对无关特征的敏感性,显著提升了模型整体的鲁棒性与可靠性。
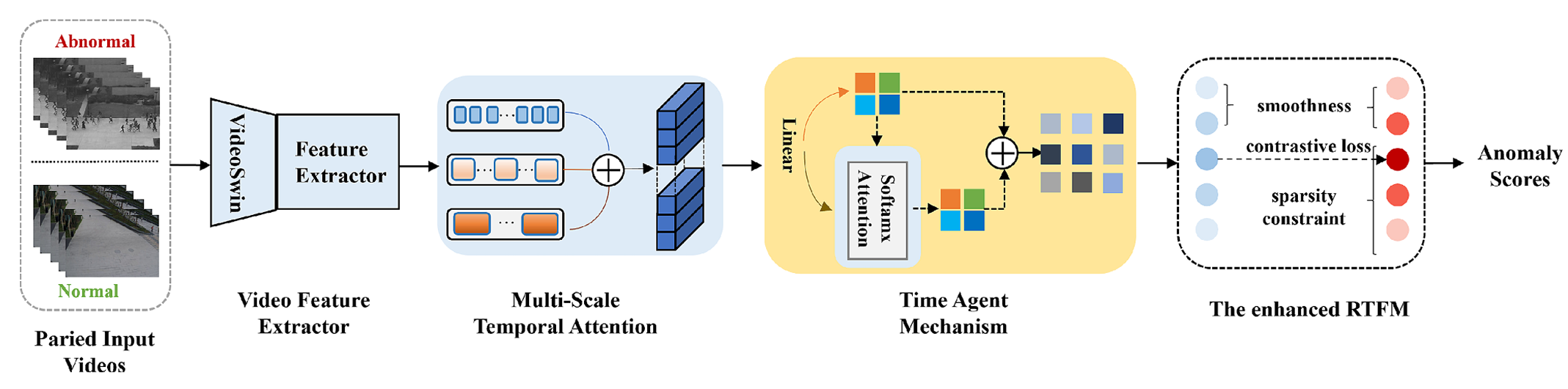
图1展示了本文所提出网络的整体架构:
首先,利用预训练的 VideoSwin Transformer 主干网络从输入视频帧中提取视频特征;
其次,通过多尺度时间注意力模块建模不同时间尺度上的时序依赖关系;
接着,引入时间代理令牌机制(temporal agent token mechanism),以增强跨片段时序关系的建模能力;
最后,采用融合对比学习、时序平滑约束与稀疏性正则化的增强型 RTFM(Robust Temporal Feature Magnitude)模块进行异常评分。
3.2.1. Multi-scale temporal attention module
本文采用预训练的 VideoSwin Transformer 模型进行空间语义特征提取。该模型在 ImageNet 等大规模数据集上进行预训练,能够有效捕获视频片段中丰富的空间信息。通过将图像划分为多个局部窗口并在每个窗口内独立计算自注意力,VideoSwin Transformer 显著降低了传统 Transformer 模型的计算开销,尤其适用于长视频处理。其滑动窗口机制可在捕捉各窗口局部特征的同时,通过窗口间移位操作建立跨窗口关联,从而兼顾局部细节与全局上下文建模。这一特性有效缓解了异常检测中空间特征表达不足的问题,使模型能够更全面地感知视频画面中的异常目标及其背景特征,显著提升了在复杂场景下识别异常行为的能力。
根据问题描述,我们将每个视频片段中每连续16帧视为一个snippet(子片段),每段视频被划分为 $ t $ 个等长片段,每个片段进一步划分为若干 snippets。随后,采用预训练的 VideoSwin Transformer 网络对每个片段进行特征提取。
每段视频输入为 RGB 三通道,因此特征张量的维度为 F=C×T×H×W,F = C \times T \times H \times W,F=C×T×H×W, 其中:
- CCC 表示通道数(例如 RGB 对应 C=3C = 3C=3,或 VideoSwin 输出的特征通道维数);
- TTT 为该片段中 snippets 的数量(即时间步数);
- H,WH, WH,W 分别为每帧的空间高度与宽度(经预处理后统一为 224×224224 \times 224224×224)。
提取得到的空间语义特征随后被输入多尺度时间注意力模块,以获取不同时间尺度下的局部与全局上下文信息(如图2所示)。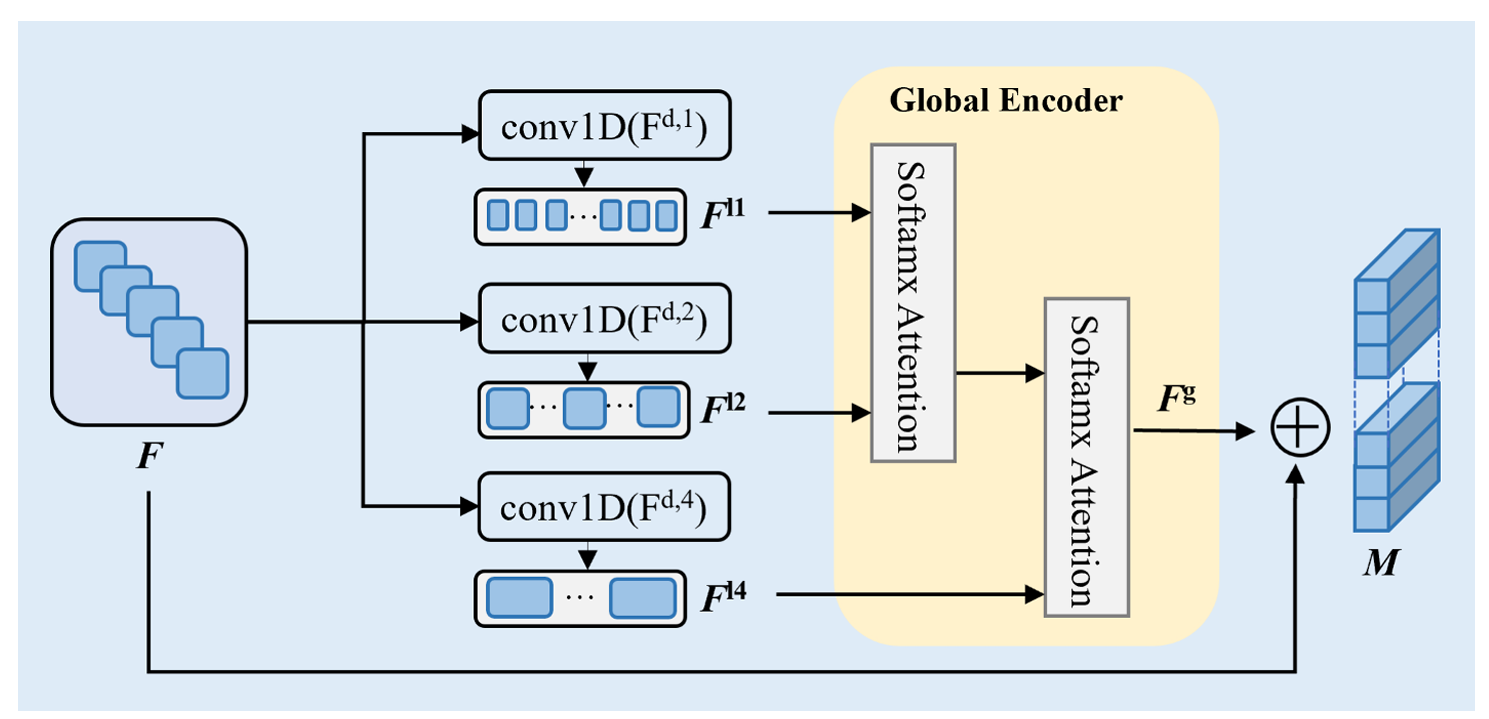
图2. 多尺度时间注意力模块的结构,该模块通过一组空洞卷积操作与成对时间自注意力机制,在不同时间尺度上捕获时序依赖关系。
在视频异常检测中,异常事件可能在多个时间尺度上呈现出不同的特征(例如短时突发异常动作或持续性异常活动),因此模型需具备灵活适应不同时间尺度的能力。多尺度时间注意力模块通过一组空洞卷积(dilated convolution)操作,灵活捕获短时与长时范围内的局部与全局信息:即在标准卷积核元素之间插入“空洞”(即零值),使模型能够在不同时间尺度上精细化提取特征。
该模块利用不同膨胀因子(dilation factor)的一维卷积,有效扩展感受野——在短时间尺度上保留高细节特征,在长时间尺度上捕获更丰富的时序上下文。这一设计解决了传统异常检测模型难以适配异常事件时间跨度的问题,从而实现对各类持续时长异常事件的高效感知。
具体而言,采用膨胀因子 d∈{1,2,4}d \in \{1, 2, 4\}d∈{1,2,4}、卷积核大小为 3、步长为 1 的一维卷积:Fl∈conv1D(Fd,i),i∈{1,2,4}F_l \in \text{conv1D}(F_{d,i}), \quad i \in \{1,2,4\}Fl∈conv1D(Fd,i),i∈{1,2,4},逐层构建局部时序上下文。该方法有效解决了视频片段间时序连续性建模的问题,确保相邻片段的时序信息被模型平滑融合,从而显著提升模型对异常行为的局部感知精度。
为进一步提升时序特征的全面性,该模块还通过成对时序自注意力机制(paired temporal self-attention mechanism)计算全局时序上下文,从而增强对视频级长程时序模式的建模能力。在异常检测中,仅依赖局部时序信息易导致误判,因为异常事件常在全局时间尺度上呈现出特定模式(例如周期性徘徊、渐进式入侵等)。
具体而言,模块对前述多尺度空洞卷积提取的局部时序特征 FlF_lFl 进一步处理:将不同尺度的局部特征 Fl1,Fl2,Fl3F_{l1}, F_{l2}, F_{l3}Fl1,Fl2,Fl3 通过矩阵乘法进行成对交互融合:
Fg=conv1D((Fl1⋅Fl2⊤)⋅Fl3) F_g = \text{conv1D}\big( (F_{l1} \cdot F_{l2}^\top) \cdot F_{l3} \big) Fg=conv1D((Fl1⋅Fl2⊤)⋅Fl3)
其中 (⋅)⊤(\cdot)^\top(⋅)⊤ 表示转置,该操作实现了跨尺度特征的动态关联建模,生成融合后的全局时序特征表示 FgF_gFg。最终,通过残差连接(residual connection)将局部特征与全局特征整合,既保障了模型训练的稳定性与梯度流动,又输出最终的多尺度时序特征:
M=Fl+Fg M = F_l + F_g M=Fl+Fg
该机制通过成对时序自注意力显式建模全局依赖,有效解决了异常事件在长时程上下文中表征不足的问题,使模型能够在时间维度上更准确地区分正常与异常片段,降低漏检风险,显著提升异常检测的准确性与时序一致性。
3.2.2. Time agent mechanism
我们以视频片段的多尺度信息融合结果作为时间代理机制模块的输入,并通过可变形卷积(deformable convolution)生成增强的时间代理令牌(记为 AAA)。这些令牌旨在捕获片段间的时序依赖关系,从而帮助模型更深入地理解跨片段的时序信息。可变形卷积通过灵活调整卷积感受野,使模型能够自适应地聚焦于异常片段中的关键时间点或区域,避免对无关信息的冗余处理。这一特性有效解决了传统固定卷积无法适配时间维度上异常变化(尤其是发生时间不规则的异常事件)的问题。
生成的令牌 AAA 随后被输入至代理 Transformer(agent Transformer)模型中进行自相关计算(autocorrelation calculation),使模型能在代理机制下高效建模长程时序依赖。在异常检测任务中,仅依赖短时特征往往难以识别缓慢积累型或持续时间较长的异常事件;而通过代理机制中的自相关建模,模型可强化对片段间跨时间关系的理解,缓解长时跨度下异常特征难以捕获的难题。
该自相关过程显著提升了第一阶段所得特征图的质量:尤其丰富了对异常片段的特征建模,增强了正常与异常片段的判别性表征能力,并提升了模型对异常事件多样化时序模式的适应性。所提出的时间代理机制结构如图3所示。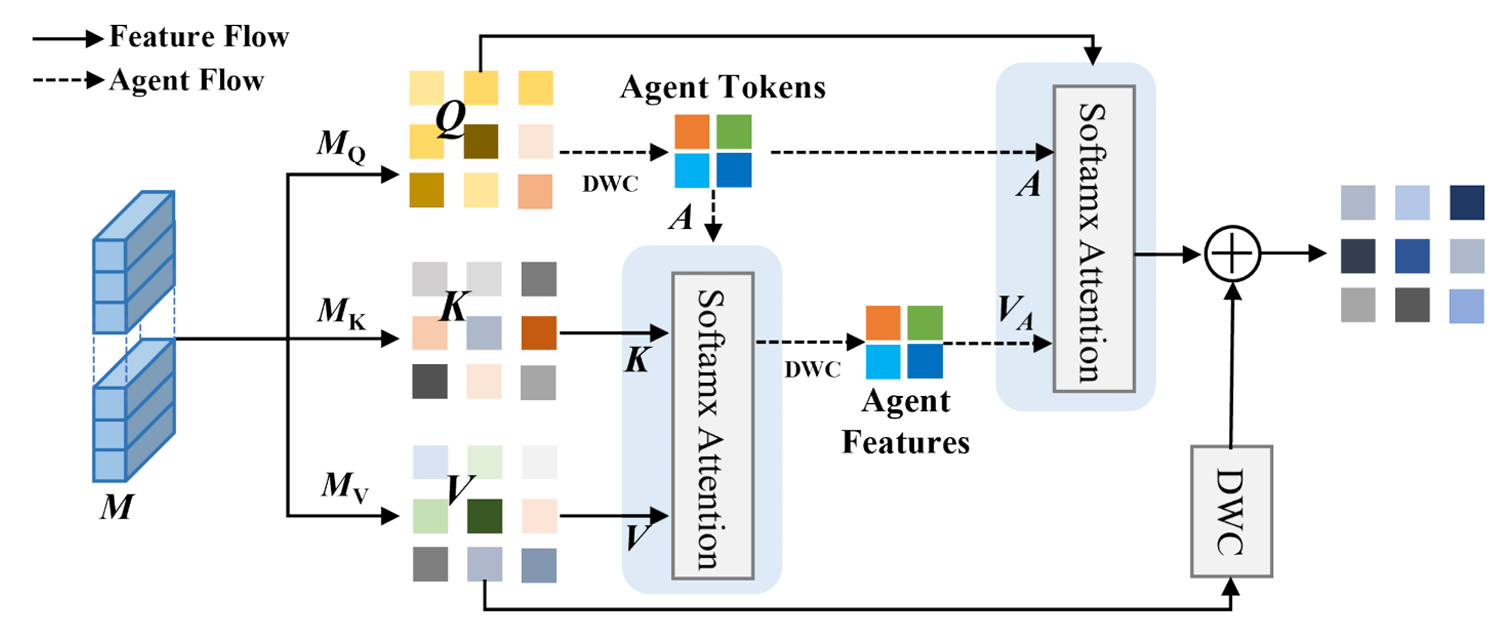
图3. 时间代理机制模块的结构,该模块利用可变形卷积生成时间代理令牌,并通过连续的时间自注意力机制建模跨片段的时序依赖关系,从而增强异常检测能力。
具体地,我们将前一阶段获得的多尺度时序特征MMM作为时间代理机制模块的输入特征MQM_QMQ、MKM_KMK和MVM_VMV,其中查询(query)、键(key)和值(value)矩阵Q,K,V∈RT×CQ,K,V\in\mathbb{R}^{T\times C}Q,K,V∈RT×C分别表示。通过代理建模视频片段的时序特征,解决了跨片段异常事件时序信息上下文缺失的问题,有助于构建完整的时序特征链。我们的时间代理机制可表示为:
OA=AttnS(Q,A,AttnS(A,K,V)⏟Agent Aggregation)⏟Agent Broadcast(1) O_A=\underbrace{\text{Attn}_S(Q,A,\underbrace{\text{Attn}_S(A,K,V)}_{\text{Agent Aggregation}})}_{\text{Agent Broadcast}} \quad (1) OA=Agent Broadcast
AttnS(Q,A,Agent Aggregation
AttnS(A,K,V))(1)
其中AttnS\text{Attn}_SAttnS表示自注意力运算,AAA是我们自定义的时间代理令牌。
如公式 (1) 所示,我们首先将时间代理令牌 AAA 作为查询(Query),在 AAA、KKK 和 VVV 之间执行自注意力计算,从而从所有值(Value)中聚合得到时间代理特征 VAV_AVA。该步骤可整合所有片段的时序信息,提升模型对视频全局时序特征的建模能力,并解决异常检测中跨片段建立长程依赖的难题。随后,我们将 AAA 作为键(Key)、VAV_AVA 作为值(Value),并以查询矩阵 QQQ 为查询,执行第二次自注意力计算,将时间代理特征的全局信息广播至每个查询令牌,得到最终输出 OAO_AOA。该步骤使时间代理特征能够同步扩展到各个片段上,解决了模型难以平衡短时与长时上下文特征的问题。这种双重自注意力机制显著增强了模型跨时间捕获异常事件的能力,避免了因时序不一致导致的误判。此外,通过残差连接维持信息传递的稳定性,并进一步增强特征的时序连续性。所定义的时间代理令牌 AAA 本质上充当 QQQ 的代理:先从 KKK 和 VVV 中聚合全局信息,再将其广播回 QQQ。这种代理设计有效构建了跨片段的信息流动结构,使模型能够更好理解长时间跨度及不规则异常下的特征变化。
在实际实现中,采用一组可变形卷积,通过动态调整特征提取的感受野来生成代理标记 AAA,使模型能够自动聚焦于异常事件的关键区域,并适应长时间跨度下复杂场景的变化。该设计有效缓解了传统卷积因固定感受野而导致的局部特征表达不足问题。在时间代理机制的整体架构中,该方法克服了传统视觉 Transformer 计算效率低的缺陷,显著提升了模型对视频全局感受野的覆盖能力。该机制大幅增强了模型的异常检测性能,使其能在复杂时序场景中准确区分正常与异常片段,最终提升了检测的鲁棒性与准确性。
3.2.3. Anomaly detection scores
为应对视频中存在多个异常片段的场景,我们在最终的 VAD 阶段采用现有的 RTFM(Robust Temporal Feature Magnitude)模型。RTFM 模型在理论上受多示例学习(MIL)中 Top-kkk 实例策略驱动,针对复杂的异常检测任务,充分利用视频片段的时序特征幅值(即 L2L_2L2 范数)来区分异常与正常片段。该设计使 RTFM 模型能更好地适应多异常场景下异常片段分布不规则的情形,有效解决了复杂场景中多个异常片段的检测难题。模型假设:异常片段的平均特征幅值显著高于正常片段——即正常片段对应低幅值特征,而异常片段对应高幅值特征。
在模型训练过程中,RTFM 模型从异常视频和正常视频中分别选取分类得分最高的 kkk 个实例(即片段)用于分类器训练。具体而言,该 Top-kkk 策略通过聚合异常视频中特征幅值(即 L2L_2L2 范数)最高的 kkk 个片段,提升了模型对局部显著异常的敏感性;同时,通过仅选取正常视频中幅值较高的片段参与训练,可有效规避正常片段中的噪声干扰,使检测更准确、高效。此外,该 Top-kkk 多示例学习(MIL)策略实现了特征幅值学习与MIL 异常分类的联合优化:在学习特征幅值分布的同时,增强模型对正常与异常片段边界区域的判别能力,从而提升对边界模糊异常的识别效果。如图 4 所示,RTFM 模型通过特征幅值驱动与 Top-kkk MIL 策略,可在含多个异常片段的复杂场景中自适应地区分异常与正常片段,有效缓解因片段重叠或边界模糊导致的检测精度下降问题。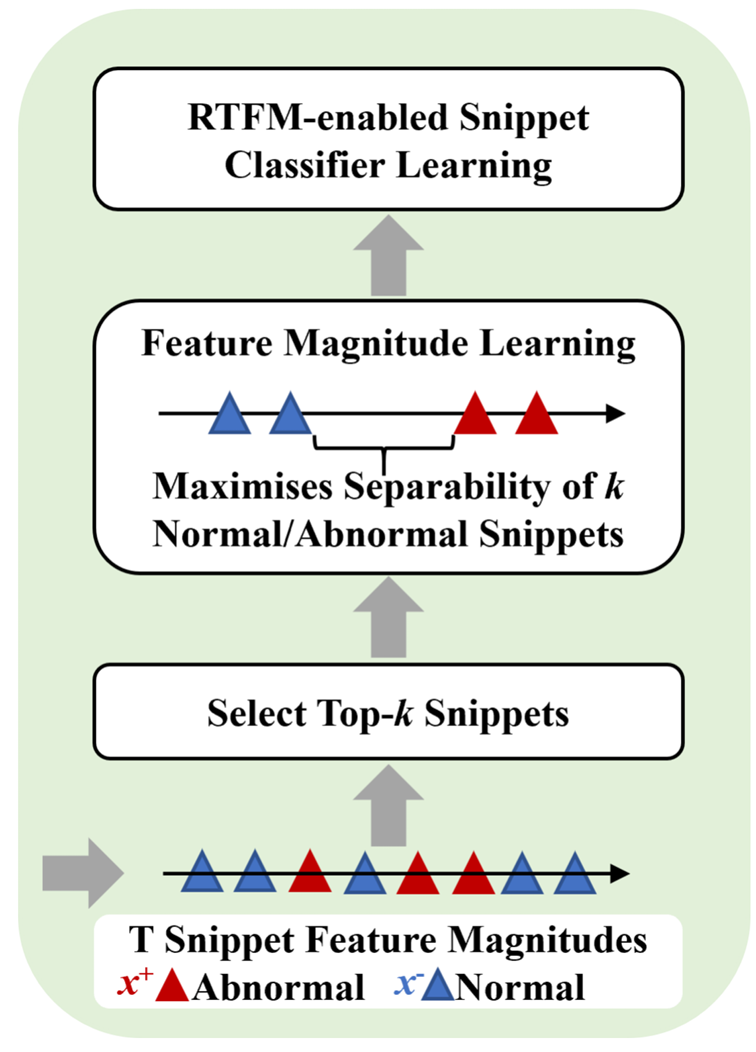
图4. 基于多示例学习(MIL)的RTFM异常评分策略结构,该策略通过最大化异常与正常视频特征之间的可分性,并利用异常与正常视频中特征幅值(即 L2L_2L2 范数)最大的 Top-kkk 个片段训练片段分类器。
图中,x+x^+x+ 表示异常片段的特征幅值(即 L2L_2L2 范数),x−x^-x− 表示正常片段的特征幅值,二者分别从异常视频(x+x^+x+)和正常视频(x−x^-x−)中提取。模型通过最大化异常与正常视频特征之间的可分性来学习片段分类器,该可分性记为 δscore(x+,x−)\delta_{\text{score}}(x^+, x^-)δscore(x+,x−),其定义为:
δscore(x+,x−)=1k∑i=1k∥xi+∥2 − 1k∑i=1k∥xi−∥2, \delta_{\text{score}}(x^+, x^-) = \frac{1}{k} \sum_{i=1}^{k} \|x_i^+\|_2 \;-\; \frac{1}{k} \sum_{i=1}^{k} \|x_i^-\|_2, δscore(x+,x−)=k1i=1∑k∥xi+∥2−k1i=1∑k∥xi−∥2,
即异常视频与正常视频中 Top-kkk 特征幅值(L2L_2L2 范数)的均值之差,其中 kkk 为异常视频中异常片段的数量。
RTFM 模型采用基于二元交叉熵的损失函数来训练片段分类器,如公式 (2) 所示:
loss=−(ylog(fϕ(x))+(1−y)log(1−fϕ(x)))(2) \text{loss} = -\big( y \log(f_\phi(x)) + (1 - y) \log(1 - f_\phi(x)) \big) \quad (2) loss=−(ylog(fϕ(x))+(1−y)log(1−fϕ(x)))(2)
其中:
- xxx 表示 L2L_2L2 范数最大的 Top-kkk 特征片段;
- fϕ:x→[0,1]Tf_\phi: x \to [0,1]^Tfϕ:x→[0,1]T 为片段分类器;
- TTT 为视频 snippet(子片段)的数量(Tian et al., 2021);
- yyy 为片段的真实二元标签(0 表示正常片段,1 表示异常片段)。
为有效捕捉视频片段间的细微差异,并最大化正常与异常视频之间的区分度,我们引入类别对比函数(category contrast function)作为视频检测的优化目标。该函数通过拉近同类样本(即正样本对)的特征表示距离,同时推远异类样本(即负样本对)的特征表示距离,从而增强模型对异常样本的判别能力,显著提升模型的稳定性与可靠性。
对比学习的损失函数如公式 (3) 所示:
Lcontrastive=−1N∑i=1N[logexp(sim(xi,xi+)/τ)∑j=1Kexp(sim(xi,xj−)/τ)](3) L_{\text{contrastive}} = -\frac{1}{N} \sum_{i=1}^{N} \left[ \log \frac{\exp\left(\text{sim}(x_i, x_i^+) / \tau\right)}{\sum_{j=1}^{K} \exp\left(\text{sim}(x_i, x_j^-) / \tau\right)} \right] \quad (3) Lcontrastive=−N1i=1∑N[log∑j=1Kexp(sim(xi,xj−)/τ)exp(sim(xi,xi+)/τ)](3)
其中:
- xix_ixi 为第 iii 个片段的特征表示(实验中经线性映射至低维空间);
- xi+x_i^+xi+ 为与 xix_ixi 同类(同属正常或异常)的正样本特征;
- xj−x_j^-xj− 为与 xix_ixi 异类的负样本特征;
- sim(xi,xj)\text{sim}(x_i, x_j)sim(xi,xj) 表示特征 xix_ixi 与 xjx_jxj 之间的相似度(通常采用余弦相似度);
- τ\tauτ 为温度参数,用于调节相似度分布的锐度;
- NNN 为片段总数,KKK 为负样本数量。
相邻视频片段之间的时序平滑约束用于使异常得分在时间上平滑变化,强制相邻片段的异常得分趋于一致。其损失函数如公式 (4) 所示:
LSmoothness=(fϕ(xi)−fϕ(xi−1))2,i∈(1,T)(4) L_{\text{Smoothness}} = \left( f_\phi(x_i) - f_\phi(x_{i-1}) \right)^2, \quad i \in (1, T) \quad (4) LSmoothness=(fϕ(xi)−fϕ(xi−1))2,i∈(1,T)(4)
同时,异常通常仅在短时间内发生,导致异常视频中仅有少数片段具有显著异常响应,因此对每个异常视频施加稀疏性先验,对应的稀疏损失如公式 (5) 所示:
LSparsity=∑t=1T∣fϕ(xt)∣(5) L_{\text{Sparsity}} = \sum_{t=1}^{T} \left| f_\phi(x_t) \right| \quad (5) LSparsity=t=1∑T∣fϕ(xt)∣(5)
基于 RTFM 模型的最终 VAD 损失函数为:
lf(fϕ(x),y)=λ1⋅Eq. 2+λ2⋅Eq. 3+λ3⋅Eq. 4+λ4⋅Eq. 5(6) l_f\left(f_\phi(x), y\right) = \lambda_1 \cdot \text{Eq.}\,2 + \lambda_2 \cdot \text{Eq.}\,3 + \lambda_3 \cdot \text{Eq.}\,4 + \lambda_4 \cdot \text{Eq.}\,5 \quad (6) lf(fϕ(x),y)=λ1⋅Eq.2+λ2⋅Eq.3+λ3⋅Eq.4+λ4⋅Eq.5(6)
其中 lf(⋅)l_f(\cdot)lf(⋅) 结合了时序平滑与稀疏性正则化;λ1,λ2,λ3,λ4\lambda_1, \lambda_2, \lambda_3, \lambda_4λ1,λ2,λ3,λ4 分别为各损失项的权重系数。参照 Deshpande 等(2022)的设置,实验中将所有 λ\lambdaλ 值统一设为 1。
5. Conclusion
本研究提出了一种基于弱监督学习的视频异常检测(VAD)方法,旨在高效检测视频中不同类型与持续时长的异常事件,并在该领域取得了当前最优性能。
首先,采用 VideoSwin Transformer 从视频片段中提取空间语义特征,以同时捕获视频的局部与全局特征信息,解决了传统方法在视频特征提取中精度不足的问题。
其次,通过多尺度时间注意力模块获取不同时间尺度下的上下文信息。由于异常事件往往具有非固定的时序特性,多尺度建模有助于覆盖更广泛的时序变化,确保异常事件的完整检测与特征表征。
此外,引入时间代理机制(time agent mechanism),以增强模型对异常片段的表征能力。该机制在全局层面建模时序关系,不仅提升了异常片段的判别性表达,还揭示了不同片段间的时序依赖性,从而在时序特征空间中更清晰地区分正常与异常片段,尤其适用于跨片段的复杂异常场景。
最后,采用改进的 RTFM(Robust Temporal Feature Magnitude)模型作为异常评分机制,进一步提升检测精度与鲁棒性。该机制通过联合优化特征幅值学习与多示例异常分类,增强模型对正常与异常片段边界区域的判别能力,并提升对视频中离散异常片段的敏感性,使模型在含多个异常片段的复杂场景下仍保持优异性能。
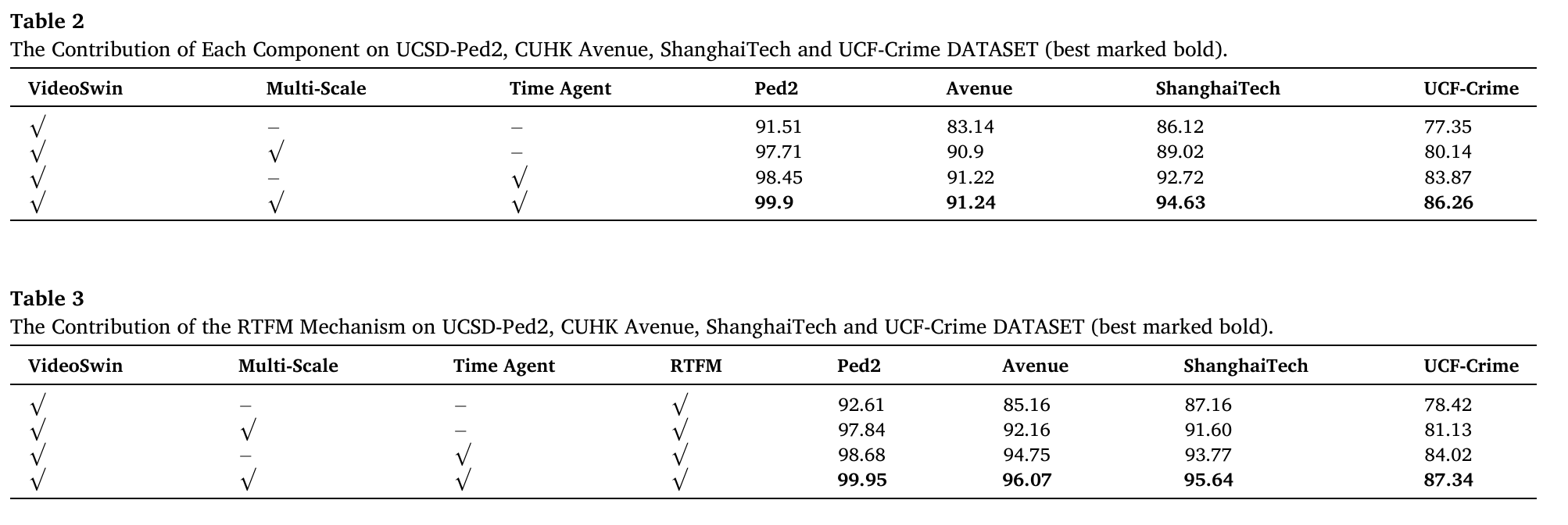
实验结果表明,融合多尺度时间注意力与时间代理机制的增强型 RTFM 异常检测模型显著提升了整体性能,有效促进了视频中各类异常的检测能力。
未来工作将进一步探索更先进的异常表征模型与评分策略,持续优化 VAD 性能,以应对更复杂的多类别、多尺度异常场景。本方法将为智能监控、自动化视频分析等领域提供新的技术支撑,推动 VAD 在实际应用中的落地与发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)