Function Calling + ReAct— 从Generation到Agent
本文探讨了如何通过函数调用和ReAct范式增强AI助手的能力。在RAG(检索增强生成)基础上,作者介绍了为AI配备工具的方法,包括函数定义和调用流程。重点分析了Qwen-Agent和LangChain两种框架的实现方式,其中LangChain采用ReAct范式,使AI能循环执行"推理-行动-观察"过程。特别讲解了Text2SQL工具的实现和安全考量,将其作为AI查询结构化数据的
在前一篇里,我介绍了如何基于 RAG(检索增强生成)构建智能问答助手。RAG有助于减少大模型幻觉,并将回答建立在领域特定知识的context之上,但它的能力也有限。比如,如果用户问以下问题:
“我什么时候去XX乐园玩能尽量避开旅游旺季?”
或者
“我计划下周日去XX乐园。那天天气怎么样?”
在这种情况下,智能QA助手可能会查询矢量数据库,然后回答:“我很乐意帮忙,但我没有有关参观流量或天气预报的信息。”
很明显,我们的小助手还需要更多能力。
本文将介绍函数调用和ReAct范式,并演示如何赋予AI助手推理、行动和有效利用外部工具的能力,会探讨OpenAI、LangChain、Text-to-SQL和Qwen-Agent等技术和框架的使用。
从Generation到Agent
如前文所述,RAG(检索增强生成)本质上还是生成(generation)—— LLM(大语言模型)根据提示,基于检索到的知识片段生成响应。而相比之下,一个现实中的人类助手通常不仅具备领域知识,还能够灵活地在各种情境下做出不同反应,包括但不限于:
- 将请求转至其他部门
- 查询各种数据源,比如 SQL 数据库或外部网站等
从技术上讲,通过提供可调用的一系列工具,我们的 AI 助手也可以具备这些能力。
Function Calling:为AI助手配备工具
“函数调用” (function calling) 并不是生成式人工智能领域的一个特定术语。就像我们作为程序员无数次地做过这件事:定义函数,然后调用,而现在,我们创建一组工具,之后由LLM(大语言模型)根据其对用户意图的理解来选择合适的一个。因此这个过程主要包括两个步骤:
1. 定义函数
准备完成一项功能所需要的工具。也可以使用 LangChain 等框架的内置工具(点击这里可以查看LangChain文档),但对于更复杂或特定业务的场景只能自定义工具。
-
2. 调用工具
很多现代大语言模型都已经支持function-calling/tool-calling),但不同模型中的具体实现可能有所不同,因此使用前务必查阅模型文档以确保其具备这个功能。
以下是来自OpenAI Docs的示例,演示了如何利用GPT-5 模型调用定义好的函数。
# 1. 定义模型可调用工具列表
tools = [
{
"type": "function",
"name": "get_horoscope",
"description": "获取指定星座的今日运势",
"parameters": {
"type": "object",
"properties": {
"sign": {
"type": "string",
"description": "例如金牛座或水瓶座的星座",
},
},
"required":[ "sign" ],
},
},
]
def get_horoscope(sign):
return f" {sign} : "下周二你会和一只水獭成为朋友。"
# 创建一个输入列表
input_list = [
{ "role":"user" , "content" : "我的星座运势是什么?我是水瓶座。" ] }
]
# 2. 使用定义的工具提示模型
response = client.responses.create(
model="gpt-5",
tools=tools,
input=input_list,
)上述示例代码中,仅使用了一个函数。实际中,LLM 可以根据提供的描述和参数从多个可用工具中进行选择,每个工具必须具备以下条件:
- 清晰的名称
- 简要描述
- 明确的参数
大模型会像路由一样,将用户的查询引导至其认为适当的函数。这种情况下,由开发者负责调用所选函数,并将其输出返回给模型进行进一步处理。
下面是一个最小示例,展示如何调用选定的函数:
def call_function (name, args) :
if name == " get_weather" :
return get_weather (**args)
if name == "send_email" :
return send_email (**args)关于Agent的一些框架
值得庆幸的是,现在一些Agent已经具备自动执行选定功能的能力。简单来说,Agent是功能更强大的AI,它们不仅能够推理出使用哪种工具,还能在无需人工干预的情况下根据决策采取行动。
根据微软的定义,Agent是
生成式人工智能应用能够响应用户输入或自主评估情况,并采取相应的行动。例如,“行政助理”代理可以提供您日历上会议地点的详细信息,甚至可以附加地图或自动预订出租车或网约车服务,帮助您到达目的地。
Qwen-Agent
在这个项目代码中,我使用了Qwen-Agent来实现工具的自主选择和调用。Qwen Assistant 实例的初始化方式如下,我们需要:
- 一个LLM
- 一个Agent的名字
- 系统提示词
- 可用功能(工具)列表
from qwen_agent.agents import Assistant
# 预先定义好一些工具类
sql_tool_instance = SQLTool()
weather_tool_instance = WeatherTool()
rag_tool_instance = RAGTool()
# 配置模型
llm_config = {
'model': 'qwen-turbo',
'api_key' : 'YOUR_API_KEY',
'temperature': 0.2,
'timeout': 30,
'retry_count' : 3,
}
# 初始化Agent实例
agent = Assistant(
llm_config,
name='主题公园智能助手' ,
description='可查询天气、数据库和知识库的智能助手' ,
system_message=f"""{SYSTEM_ROLE}. 使用工具回答查询。
可用工具:
- {weather_tool_instance.name} : {weather_tool_instance.description}
- {sql_tool_instance.name} : {sql_tool_instance.description}
- {rag_tool_instance.name} : {rag_tool_instance.description}
关键规则:
- 必须为每个用户查询调用一个工具函数。
- 切勿在不调用工具的情况下直接回答问题。
- 参数必须以有效的 JSON 格式提供。
- 从用户的问题中提取参数值。
- 如果不确定使用哪个工具,则默认使用rag_tool。
""" ,
function_list=[weather_tool_instance, sql_tool_instance, rag_tool_instance],
)之后,当Agent运行时,它将选择一个工具并自动调用它。
response = agent.run([{ 'role' : 'user' , 'content' : query}])这种方法有效地解决了之前说的大模型需要手动调用函数的局限性。然而,另一个局限性也随之出现:Qwen Agent无法评估工具返回的输出,不能将其转换为连贯的自然语言回复。
大多数工具返回的是结构化数据,通常是JSON格式,比如以下是 OpenWeatherAPI 的一个示例响应。在这种情况下,就需要再调用一次大语言模型将 JSON 结果转换为自然语言,作为给用户的回答。
# OpenWeatherAPI 返回的 JSON 文件的一部分"
dt " : 1762477200 ,
"temp" : 277.15 ,
"feels_like" : 273.92 ,
"pressure" : 1013 ,
"humidity" : 71 ,
"dew_point" : 276.38 ,
"uvi" : 0 ,
"clouds" : 6 ,
"visibility" : 10000 ,
"wind_speed" : 3.77 ,
"wind_deg" : 147 ,
"wind_gust" : 10.5 ,
"weather" : [
{
"id": 800 ,
"main" : "Clear" ,
"description" : "晴空" ,
"icon" : "01n"
}Qwen-Agent 的最新版本(v0.3+)引入了一个后处理步骤,可以对工具输出进行摘要或改写。然而,在实际应用中,我发现这个功能的效果有限——对于比较复杂的 JSON 或多步骤工具返回结果处理不了。
LangChain Agent
我知道 LangChain 可以解决上述问题,但一开始却并不乐意使用它,因为之前它的文档总是提示说:“此模块尚未完全迁移到新版本”,这就使得集成和后续迁移变得很麻烦。
所幸最近发布的版本在稳定性和兼容性方面都得到了显著提升,能够更简易高效地兼容自定义工具和MCP 服务器。除了选择和执行工具之外,LangChain Agent 还采用了 ReAct 模式,能够将工具结果解释并转化为自然语言响应。
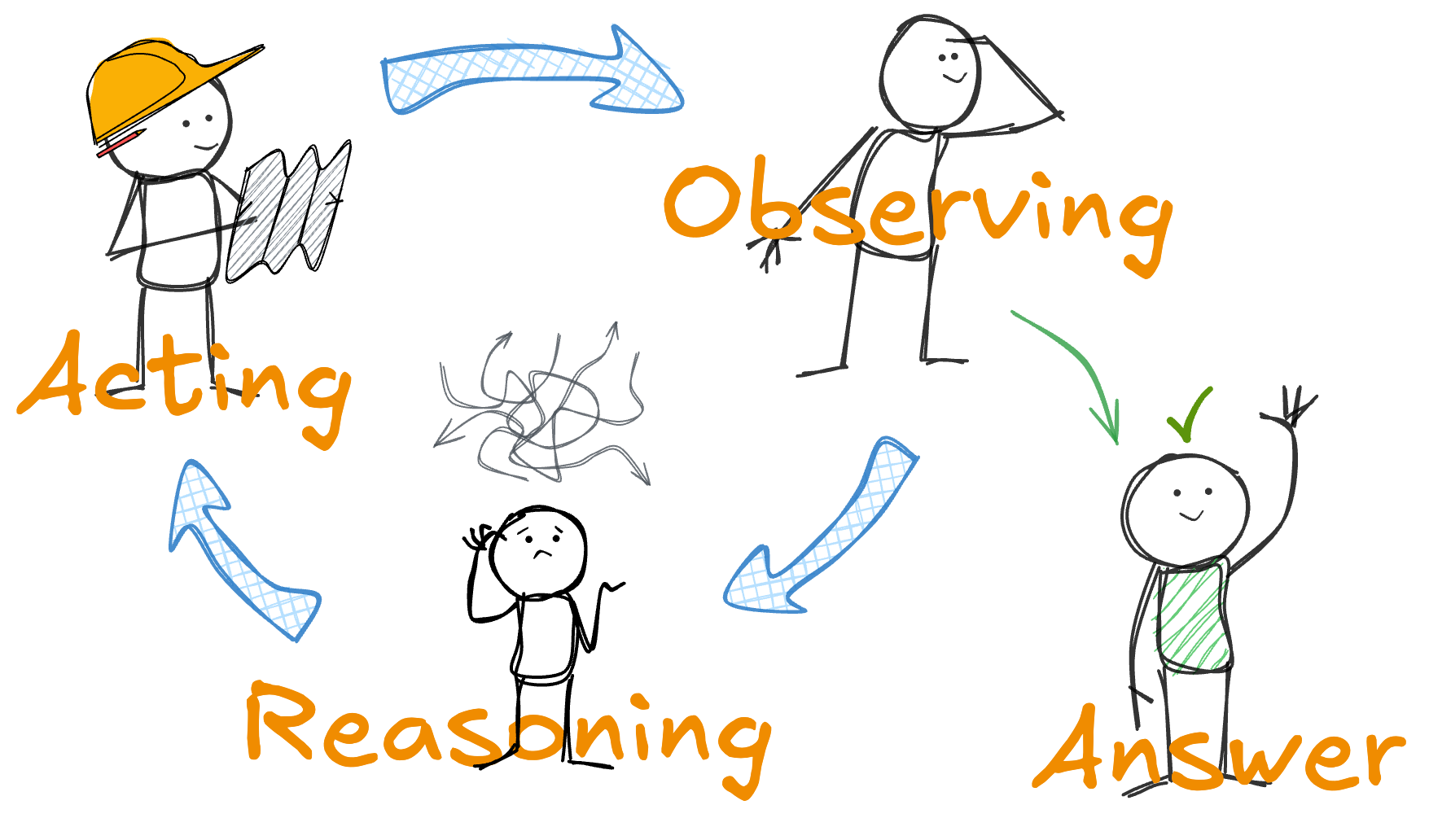
ReAct范式
ReAct是“推理Reasoning"和“行动Acting”的缩写,是思维链 (CoT) 和仅行动范式 (Act-Only) 的结合与衍生。你或许了解一些与人类认知相关的“脑型-手型-心型”模型,我们可以拿来与人工智能中的这三种模式进行大致比较。
- CoT 就像脑型人,擅长推理,甚至可以展现出其思考的路径,但它不与外部世界互动,全部推理基于它“脑子”里的知识完成。
- 只行动型就像手型人,能够按照指示完成任务,但它不会反思行动目标和阶段性成果。
而ReAct模式结合了大语言模型的推理和行动能力,模拟人类的行为循环:“推理→行动→观察→推理→……”。通过这一循环,模型不仅可以进行内部思考,还可以利用外部知识、工具和环境来更新和完善其方法,直至得出最终答案。
LangChain官网的问答助手解释了其Agent的工作原理:
The agent follows a ReAct loop where it: 1) Reasons about which tool to call; 2) Automatically executes the tool; 3) Receives the result (observation); 4) Repeats until it has a final answer.
The agent doesn’t just choose tools — it runs them in a loop until the task is complete or a stop condition is met.
Agent遵循 ReAct 模式循环:1) 判断要调用哪个工具;2) 自动执行该工具;3) 接收结果(观察结果);4) 重复执行,直到得到最终答案。
该代理不仅选择工具,还会循环运行这些工具,直到任务完成或满足停止条件为止。
LangChain Agent的实现
1. 准备工具
我给我的Agent提供了四个工具,其中三个自定义,一个是 MCP 服务(稍后再讲这个)。每个工具都是一个用 `@tool` 装饰的函数,建议在函数名后添加文档字符串,因为它会指导Agent何时以及如何使用该工具。(以下我省略了函数的具体实现。)
@tool
def get_weather(location: str , date: Optional[str] = None) -> str :
"""获取指定地点和日期的当前天气、天气预报或历史平均天气。"""
@tool
def text_to_sql ( query: str ) -> str :
"""通过将自然语言转换为 SQL 语句,执行 SQL 并返回结果,来回答有关客流量、淡季/旺季的查询。"""
# 注意:之前的基于 RAG 的问答助手现在成了一个供Agent使用的工具
@tool
def search_knowledge_base ( query: str , k: Optional [ int ] = 5 ) -> str :
"""搜索知识库,获取有关主题公园的信息和提示。"""2. 初始化LLM
我选择使用Gemini,只是因为它便宜。使用前请务必查看模型文档,确保其支持函数调用。
llm = ChatGoogleGenerativeAI(
model= "gemini-2.5-flash" ,
temperature= 0.2 ,
google_api_key=os.getenv( "GEMINI_API_KEY" )
)3. 使用工具列表和模型创建Agent
agent = create_agent(model=llm, tools=tools)4. 调用Agent
response = agent.invoke ({ "messages" : [{ "role" : "user" , "content" : query}] } )系统提示词可以选择性提供,由于“模型已经过训练,能够根据工具的名称、描述和架构来理解和使用工具,您无需显式地告诉它选择工具——它会在 ReAct 循环中自动完成此操作”。
这个项目的分支上可以看到我如何使用 LangChain 代理的完整版本。
非常简单易用,而且可以顺畅地把复杂的 JSON 结果解析为人类可读的答案。现在我可以不再纠结之前花了那么多时间阅读它的文档了。如果你之前使用过 create_tool_calling_agent, AgentExecutor, create_react_agent等,现在是时候把它们迁移到create_agent了。
Text2SQL
我为我的AI助手配备的工具之一是Text2SQL功能,它使模型能够从结构化数据库中检索信息。本质上来说,它是另一种检索方式——与RAG类似,但它不是搜索向量化文档,而是查询关系型数据库。
现在SQL数据库仍然是大多数业务系统的支柱,但编写 SQL 查询语句(尤其是涉及多个join的查询)即使对于像我们这样的技术人员来说也很令人头疼,而对于销售或运营等非技术用户来说几乎是不可能的,而他们往往是最需要这些数据的人。
大语言学习模型(LLM)接受过“大量”语言的训练,因此它们也能理解和生成SQL语句。这种能力构成了Text2SQL的基础,可以将自然语言的问题转换为SQL语句。
有一些专门为此目的设计的特定模型,比如SQLCoder,但我发现,只要提供适当的提示词,通用模型(OpenAI,DeepSeek等)也能表现得很好。
create_sql = """
-- 表:visit_flow
-- 列:
visit_date DATE NOT NULL, -- 访问日期
entry_time TIMESTAMP WITH TIME ZONE, -- 进入时间
exit_time TIMESTAMP WITH TIME ZONE, -- 退出时间
"""
prompt = f"""-- Language:SQL
### Question:{query}
### Schema:
{create_sql}
### Answer:
Write SQL query to answer:` {query} `
```sql
"""
# 调用模型生成 SQL
response = Generation.call(
model= "gpt-5" ,
prompt=prompt,
)然后可以使用 pandas 执行模型回复中包含的 SQL 查询语句,查询结果将返回给Agent,由它生成自然语言回复。
安全问题及解决方案
Text2SQL赋予了Agent检索结构化数据的能力,但也引入了不容忽视的潜在安全风险。
- 敏感数据泄露:如果 SQL 查询返回敏感信息(用户信息、财务数据等),LLM 生成的响应可能会将这些数据暴露给用户。解决方案:严格控制查询字段,仅允许访问已批准的表或列。
- SQL注入:尽管用户输入的是自然语言,但LLM会自动生成SQL。有缺陷的生成逻辑可能导致危险的数据库操作。解决方案:始终在执行之前验证生成的SQL。限制模型只执行只读操作(例如
SELECT),并显式阻止诸如DROP,UPDATE,DELETE之类的破坏性命令。
小结
从基于 RAG 的generation到 ReAct 模式的Agent,我们的 AI 助手已经从仅仅检索信息发展到能够推理、决策、采取行动和撰写合理的答案。而查询向量化知识库现在已成为Agent可用的工具之一——与通过Text2SQL查询结构化数据库和通过 API 获取天气数据一样。
以后,该系统可以扩展更多工具(例如,用统计模型预测参观流量等),集成MCP服务(如,用于路线规划的地图服务),以至多智能体协作。
参考文档
- ReAct:在语言模型中协同推理和行动。Google Research,2022 年。
- LangChain 文档,https://docs.langchain.com/oss/python/langchain/agents
- OpenAI 文档,https://platform.openai.com/docs/guides/function-calling
- Qwen-Agent 文档,https://qwen.readthedocs.io/en/latest/framework/qwen_agent.html

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)