一文看懂!大模型领域近期进展!
2023年以来,大语言模型领域经历了显著的技术演进。GPT-4确立了规模化的发展路径,但其高计算成本促使2024年转向效率优化:混合专家(MoE)架构如DeepSeek-V2/R1、Qwen3系列和Minimax-m1实现了10:1的参数利用率比;注意力机制创新如MLA和Lightning Attention突破了O(L^2)复杂度限制。2025年重点转向推理优化,OpenAI的o系列和Claud
前言
本文深入探究了自2023年GPT - 4发布以来,大型语言模型(LLM)领域的发展趋向及其技术演进路径。
2023年基线:GPT - 4范式
2023年初,LLM领域的发展遵循着一条清晰且强劲的轨迹,彼时规模决定能力,当年的热门术语便是“Scaling Laws”,即更大的参数、更多的计算量以及更庞大的数据规模。
这一理念的巅峰之作便是OpenAI的GPT - 4。作为2023年最为先进的AI,GPT - 4堪称大规模模型的典范。其基础架构依旧是Transformer,不过通过增加参数量,展现出了出色的性能。尤其在多种专业和学术基准测试中,它展现出了与人类相当的水平,例如在模拟律师资格考试中,它取得了排名前10%的成绩,而其前身GPT - 3.5的得分则位于后10%。
相较于GPT - 3.5,GPT - 4的关键进步体现在多个方面。首先,其上下文窗口长度得到了极大扩展,提供了8K和32K两种规格的上下文长度,远超前代的4K和2K,这类似于当年软盘时代,内存从1K提升到1M的变革。这使得模型能够处理更长、更复杂的任务,OpenAI也宣称GPT - 4在可靠性、创造力以及处理细微指令的能力上均优于GPT - 3.5。
GPT - 4的成功,为整个领域指明了一条通过持续扩大模型规模和数据量来提升智能水平的路径。这条演进路径的逻辑为:
- 需要对架构进行改进:密集型Transformer模型的计算和内存开销是核心痛点。为了处理更复杂的现实世界问题,模型需要更大的上下文窗口来容纳所有相关信息,并需要更复杂的内部处理流程。然而,O(L^2)的复杂度和巨大的KV缓存使得这一需求在经济和技术层面都难以实现。因此,架构上的效率创新成为首要任务。混合专家(MoE)架构通过稀疏激活来降低计算量,而线性注意力等机制则直接突破了二次方复杂度的瓶颈。这些将在第二部分详细分析的创新,为后续发展铺平了道路。
- 需要提升可解释性,找到新的增长范式:一旦模型的基础架构在效率上得到优化,实验室便有条件去探索计算成本更高的推理过程。在推理时进行“thinking”,即让模型在给出最终答案前进行一系列内部的、复杂的思考步骤,只有在底层架构足够高效的前提下才具有经济可行性,否则“thinking”一次耗时久且成本高,实用性欠佳。若没有MoE或线性注意力等技术降低基础成本,为每一次查询增加数倍乃至数十倍的“thinking”计算量是难以想象的。
- 需要具备商业价值,切实可用:一个能够进行多步推理并形成复杂计划的模型固然强大,但一个能够利用工具去影响其他系统、付诸实践的模型,才具有真正的变革性。因此,Agent能力的开发,成为应用推理能力的自然延伸。它是这条因果链的第三个环节,也是最高阶的体现。
2024年至今,对效率的迫切需求
稀疏化的兴起:混合专家(MoE)架构
混合专家(Mixture - of - Experts, MoE)架构是这一时期应对效率挑战的核心策略之一,其基本思想是用大量小型的专家网络替换Transformer中密集的、计算量巨大的前馈网络(FFN)层。
对于输入序列中的每个token,一个门控网络(gating network)或称为路由器(router)的机制会动态地选择一小部分专家来处理它。按照这种模式,模型的总参数量可以急剧增加(例如R1直接达到671B的总参数量),但每次前向传播(即推理)时实际激活的参数量和计算量(FLOPs)却仅占一小部分(例如R1实际上只激活37B),从而实现了经济的训练和高效的推理。
DeepSeek在推广和开源MoE架构方面发挥了重要作用,从V2开始,到R1等系列模型清晰地展示了MoE架构的演进和威力,如今基本都是MoE的模型。
DeepSeek - V2:该模型引入了名为DeepSeekMoE的稀疏MoE架构。在236B(2360亿)参数的版本中,每个token仅激活21B(210亿)参数。这展示了超过10:1的总参数与激活参数之比,是MoE理念的经典体现,这种设计使得模型能够在保持巨大知识容量的同时,显著降低推理成本。
DeepSeek - V2 - Lite:为了便于学术研究和更广泛的部署,DeepSeek推出了16B参数的轻量版MoE模型,每个token仅激活2.4B参数。其技术报告详细说明了实现方式:除第一层外,所有FFN层都被MoE层取代。每个MoE层包含2个所有token共享的专家(shared experts)和64个路由选择的专家(routed experts),每次会为每个token激活6个路由专家。这种细粒度的设计(共享专家处理通用模式,路由专家处理特定子问题)展示了MoE架构的灵活性和复杂性。
DeepSeek R1:作为一款专为推理设计的模型,R1同样基于MoE架构。它拥有惊人的671B总参数,而每个token的激活参数量为37B,这进一步证明了MoE架构是实现数千亿级别参数模型的可行路径,尤其是在HPC(高性能计算)协同设计的支持下。
Qwen的混合产品组合策略
阿里的Qwen团队采取了独特的市场策略,Qwen3系列同时提供了密集模型(最高32B)和MoE模型(如30B - A3B,235B - A22B)。这一策略是对不同市场需求的针对性应对,密集模型通常具有更可预测的性能和更简单的微调流程,适合寻求稳定性的企业用户。MoE模型则代表了技术前沿,以极致的规模和性能吸引高端用户和研究者。这种双轨并行的产品线,让Qwen能够在不同的细分市场中保持竞争力,尤其是二次开发的衍生模型,Qwen在HF上一直是排名第一的衍生模型,大量的科研和二次开发都基于Qwen2.5,基于LLaMA的则越来越少。
Minimax - m1的混合MoE
最近6月刚发布且开源的Minimax的m1模型也采用了混合MoE架构,拥有32个专家。模型总参数量为456B,每个token激活45.9B参数。这再次印证了约10:1的总参数与激活参数之比已成为大型MoE模型的行业基准,主要也带来了超长上下文方面的提升,整体性能可查看表格,表现颇为出色。
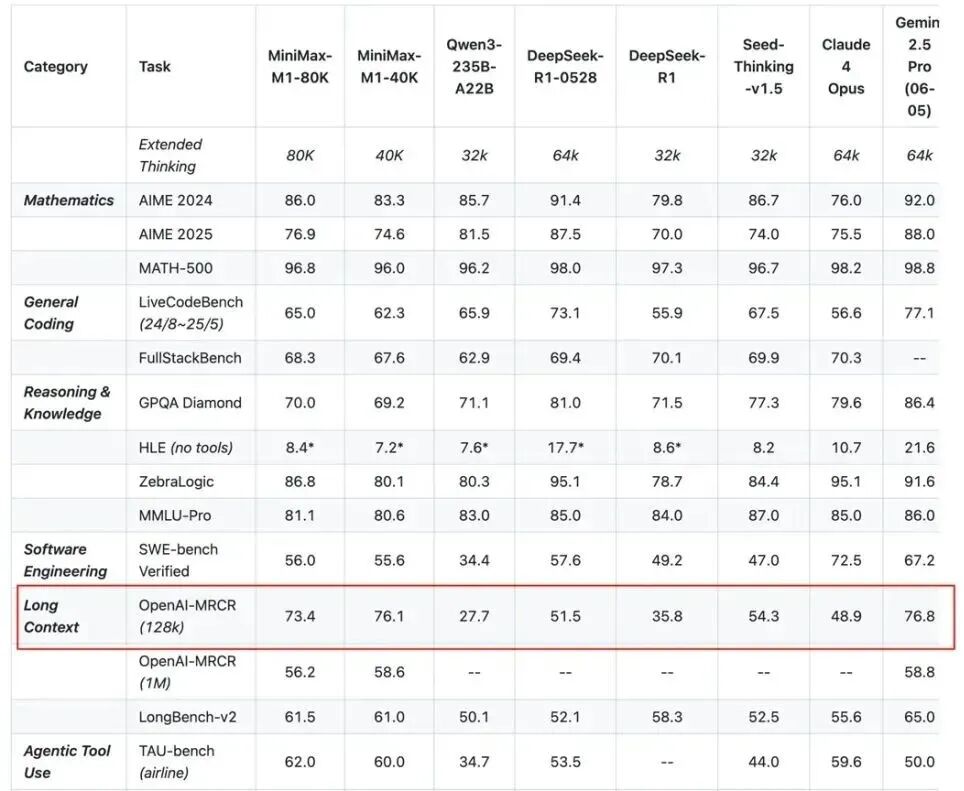
注意力机制革命,超越二次方缩放
如果说MoE解决了FFN层的计算开销问题,那么新的注意力机制则旨在攻克Transformer架构的另一个核心瓶颈——自注意力机制(self - attention)与序列长度L的二次方计算复杂度O(L^2),这一瓶颈是限制模型处理超长上下文(如百万级token)的主要障碍。
DeepSeek的多头潜在注意力(MLA)
机制:DeepSeek的Multi - Head Latent Attention (MLA) 是一种创新的注意力机制,它通过将长序列的Key和Value向量(即KV缓存)压缩成一个单一的、低秩的潜在向量(latent vector)来解决KV缓存瓶颈。这极大地减少了存储历史信息所需的内存,使它在支持128K上下文长度的同时,KV缓存相较于前代模型减少了93.3%。
在V3中的演进:在DeepSeek - V3中,MLA得到了进一步优化,引入了更复杂的动态管理策略。例如,动态低秩投影(Dynamic Low - Rank Projection)可以根据序列长度自适应地调整压缩强度,短序列少压缩以保留保真度,超长序列(如32K - 128K)则深度压缩以控制内存增长。分层自适应缓存(Layer - Wise Adaptive Cache)会在模型的更深层修剪掉较早的KV条目,进一步优化了在极端长上下文场景下的内存使用。这些演进表明,对注意力机制的优化已进入精细化、动态化阶段。
Minimax - m1的闪电注意力(Lightning Attention)
机制:Minimax - m1采用了更为激进的混合注意力方案。大部分Transformer层使用的是一种名为闪电注意力(Lightning Attention)的线性复杂度(O(L))机制。然而,为了防止模型表达能力和性能的过度损失,架构中每隔七个使用线性注意力的Transformer块,就会插入一个使用标准softmax注意力的完整Transformer块。
影响:这种设计在处理长序列时极大地降低了计算负荷。在生成长度为100K个token时,m1消耗的FLOPs仅为DeepSeek R1的25%,这直接支持高达100万token的超长上下文长度,这是一种在效率和性能之间进行权衡的设计。
2025年来,推理Thinking走向台前
CoT的逐渐拉长
这个新范式将计算开销的重心从预训练阶段部分转移到了推理阶段。其核心理念是,模型在生成最终答案之前,投入额外的计算资源来生成一段内部的思考链(CoT,chain of thought),从而在需要逻辑、数学和规划的复杂任务上实现性能的大幅提升。这标志着模型从静态的知识检索向动态的问题解决能力的转变。

OpenAI的o系列(o1, o3, o4 - mini)
机制:o系列模型是这一范式的开创者,它们在回答问题前会明确地花费时间进行“Thinking”。这个过程会生成一个长的、对用户隐藏的思考链,这段内部独白对于模型推导出正确答案至关重要。OpenAI以安全和竞争优势为由,禁止用户探查这个思考链。
影响:这种方法在重推理的基准测试上带来了显著的性能提升。例如,o1解决了83%的AIME(美国数学邀请赛)问题,而GPT - 4o仅解决了13%。这有力地证明了,对于特定类型的问题,推理时计算(test - time compute)比预训练计算能带来更大的价值。o系列还包括o1 - mini、o4 - mini这些变体,它们更快、更便宜,专为编码和STEM等不太需要广泛世界知识的任务进行了优化,非常适合对话使用。
Anthropic的Claude系列的混合推理
机制:Claude 3.7是首个以“混合推理模型”(hybrid reasoning model)为卖点的模型,它允许用户在快速响应和更深度的“扩展思考”(extended thinking)之间进行选择。随后的Claude 4(Opus和Sonnet版本)进一步将此功能完善为两种明确的模式,允许开发者根据具体应用场景,在延迟和准确性之间做出权衡。
相关内容资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)