Xinference × HAMi | 共建异构算力新基座,让 AI 推理更普惠、更高效
已合并到官方 Helm Charts,开启 vGPU 只需在 values 里打开开关(Supervisor/Worker 可分别启用)。把 Xinference 的“多模型易用 + OpenAI-兼容”与 HAMi 的“细粒度 vGPU 配额 + 统一治理”结合起来,就能在。这类场景非常适合:Embedding/Rerank/小语音/轻量 Agent 工具模型,并发量大但单模型占用小。模型推理进
·
要点速览
- Xinference 是 Xorbits 的开源多模型推理平台(LLM/Embedding/图像/音频/TTS/Rerank 等),采用 Supervisor/Worker 架构,提供 OpenAI-兼容 API,便于替换和接入现有应用。
- 企业落地时,Xinference 自身不做算力隔离,容易出现“小模型独占整卡”的浪费,以及多租户下的配额与可观测性空缺。
- 新合并的 Helm PR #6 让 Chart 原生支持HAMi vGPU:通过参数开关即可为Supervisor/Worker 传入nvidia.com/gpucores、nvidia.com/gpumem-percentage 等资源,安全共享 GPU、提升利用率,并纳入统一的配额与监控。
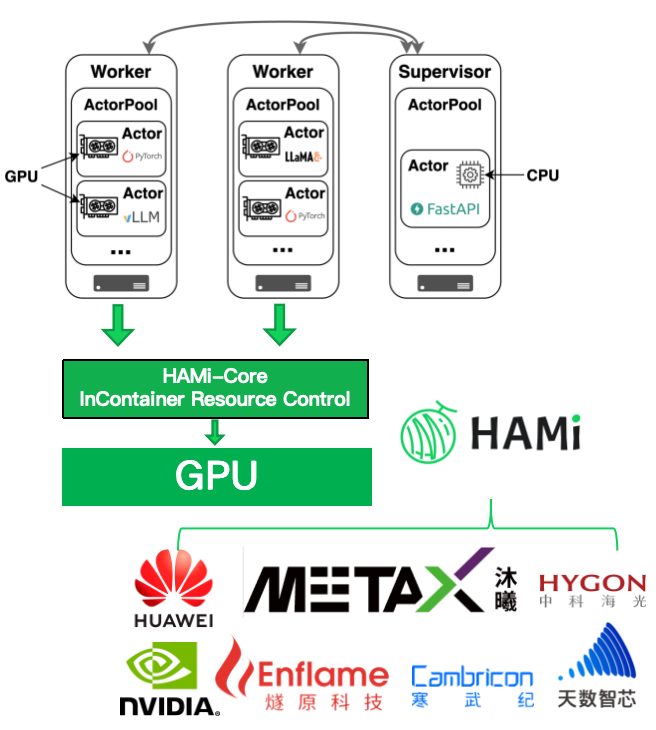
Xinference 是什么:
接口友好、形态多样、分布式可伸缩
- 多模型能力:支持聊天/生成、Embedding、Vision、Images、Audio(ASR/TTS/变声/克隆)、Rerank 等能力与常见引擎(vLLM、Transformers、llama.cpp、SGLang、MLX)。
- OpenAI-兼容 API:可把现有调用一键切到本地或自建集群。
- Supervisor/Worker 架构:Supervisor 负责协调与管理,Worker 负责实际执行并使用 CPU/GPU 资源;分布式场景下多 Worker 连接到同一个 Supervisor。
- 性能增强:支持连续批处理,并提供 Xavier 机制在多 vLLM 实例间共享 KV Cache,降低重复前缀计算开销。
为什么要接 HAMi:
从“能跑起来”到“可共享、可度量、可治理”
在企业生产中,常见两类问题:
- 轻量模型占整卡 → 造成显著浪费;
- 多租户治理缺位 → 难以对不同团队/任务做精细配额与可观测。
而 HAMi vGPU 正好补齐这些短板:
- 用 百分比/容量 限定单任务可用的 GPU 核心与显存(如 nvidia.com/gpucores、nvidia.com /gpumem-percentage ),把一张卡安全拆给多任务共享。
- 接入后,调度/限额/观测 都走 Kubernetes 体系,方便统一纳管
一键启用:
Helm 原生支持 HAMi vGPU
PR #6 已合并到官方 Helm Charts,开启 vGPU 只需在 values 里打开开关(Supervisor/Worker 可分别启用)。
下方示例以“只给 Worker 分配 vGPU”为主(更符合常见实践):
# values.yaml(节选)
xinferenceWorker:
worker:
vgpu:
enabled: true
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpucores: 20 # 占用 20% GPU 核心
nvidia.com/gpumem-percentage: 10 # 占用 10% 显存
requests:
cpu: "2"
memory: "8Gi"
xinferenceSupervisor:
supervisor:
vgpu:
enabled: false # 一般不需要 GPU,可按需改为 trueHAMi 启动安装:
helm repo add xinference <https://xorbitsai.github.io/xinference-helm-charts>
helm repo update
# 按照上方示例准备好 values.yaml
helm install xinference xinference/xinference -n xinference -f values.yaml已验证的小模型并发:一张 L4 跑 5 个 Qwen3-0.6B
在该 PR 的评论中,贡献者给出了实测样例:
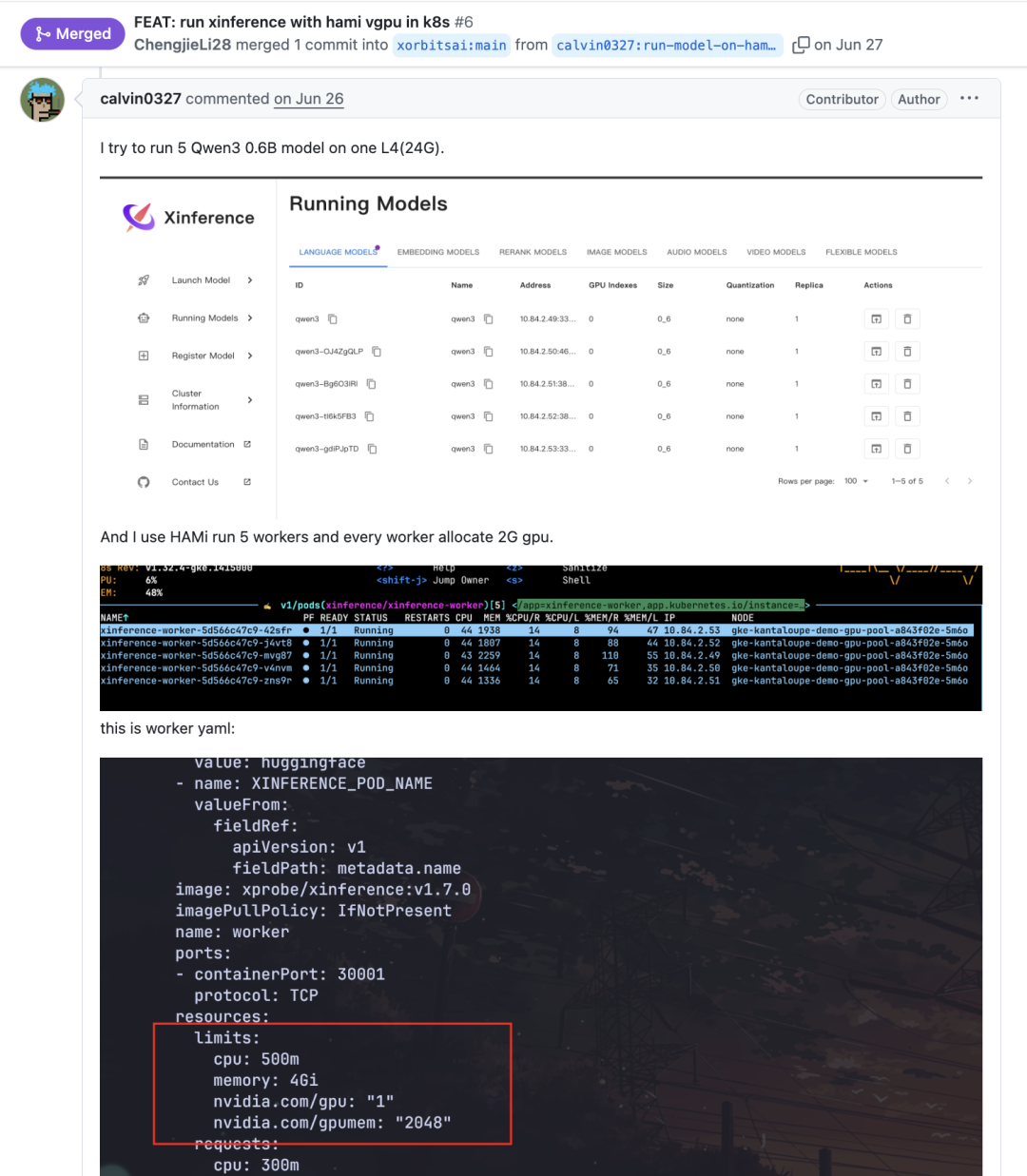
在 NVIDIA L4 (24GB) 上用 HAMi 将显存切成多份,为 5 个 Worker 各分配约 2GB 显存,从而同时承载 5 个 Qwen3-0.6B 模型推理进程,验证了“小模型安全共享整卡”的可行性。
这类场景非常适合:Embedding/Rerank/小语音/轻量 Agent 工具模型,并发量大但单模型占用小。
监控与多租户治理
- Xinference 侧指标:Supervisor/Worker 暴露独立指标面板,用于观测模型数量、请求吞吐与延迟等。
- HAMi 侧观测/限额:通过 Kubernetes 原生资源与 HAMi 的 vGPU 指标,配合命名空间-配额策略,构建“项目-任务”的分层治理。
结语与致谢
把 Xinference 的“多模型易用 + OpenAI-兼容”与 HAMi 的“细粒度 vGPU 配额 + 统一治理”结合起来,就能在 不改业务代码 的前提下,把 GPU 从独占变共享、把能力 从能跑变好管。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)