langchain agent上下文工程
本文探讨了智能体开发中的上下文工程问题,提出了上下文分类框架和优化方法。主要内容包括上下文分类和上下文工程。通过上下文工程使大模型能够接受到恰当的数据,从而提高智能体的可靠性。
1.智能体上下文
1.1上下文概述
构建智能体的难点在于运行的可靠性,开发一个原型很简单,但作为一个生产系统一旦上线则破绽百出,其根本原因是未把正确的上下文传递给大模型。上下文工程就是为了解决这个问题,为了理解上下文工程,首先需要先把上下文理清楚。
智能体的上下文可以从两个维度进行分类:
1)根据可变性,上下文分成静态上下文和动态上下文。静态上下文是指智能体执行过程中不改变的数据,包括数据连接、工具、用户元数据等,动态上下文时指智能体执行过程中不断变化的数据,比如对话历史、中间结果和工具调用结果
2)根据生命周期,上下文分成运行时上下文和跨对话上下文。运行时上下文是指一次调用期间可以使用的数据,跨对话上下文是指在多次调用中均可以访问的数据。
把这两个维度综合上下文可以分成静态运行时上下文、动态运行时上下文和动态跨对话上下文,静态跨对话上下文没有实际的应用场景,不需考虑。
1.2静态运行时上下文
静态运行时上下文表示不可变的数据,如用户元数据、工具和数据库连接,这些数据在调用智能体时通过上下文参数(context)传递给智能体。此数据在执行过程中不会更改,如下代码把朝代做为静态运行时上下文:
@dataclass
class ContextSchema:
dynasty: str
@dynamic_prompt
def system_prompt(request: ModelRequest) -> str:
dynasty = request.runtime.context.dynasty
return f"你是一个关于{dynasty}的史学家."agent = create_agent(
model=llm,
tools=[search_internet_tool],
middleware=[system_prompt],
context_schema=ContextSchema
)agent.invoke(
{"messages": [{"role": "user", "content": "客观评价一下朱虚侯刘章在推翻吕后家族过程中的作用?"}]},
context=ContextSchema(user_name="John Smith")
)
在工具中和图中均可以访问静态运行时上下文。
1.3动态运行时上下文
动态运行时上下文表示可变的数据,在一次调用过程中不断变化,如对话历史、中间结果或工具调用结果,动态运行时上下文在调用智能体时作为状态传入,如下代码把统一社会信用代码作为动态运行时上下文在调用智能体时传入:
class CustomState(AgentState):
uniscid: str@dynamic_prompt
def system_prompt(request: ModelRequest) -> str:
uniscid = request.state.get("uniscid")
return f"你是一个高级审计师,当前企业的统一社会信用代码是{uniscid}"agent = create_agent(
model=llm,
tools=[enterprise_tool,],
state_schema=CustomState,
middleware=[system_prompt],
)agent.invoke({
"messages": "请说明一下企业的经营状况",
"uniscid": "91110000376542190"
})
在图中可以直接访问动态运行时上下文。
1.4动态跨对话上下文
动态跨对话上下文表示跨越多个对话的可变数据,比如用户画像、偏好和历史交互数据等,因为跨多个会话,所以必须实现持久化存储,保存在Store中。
动态跨对话上下文的应用可参见《langchain agent中的长期记忆》 。
2.上下文工程
2.1上下文工程概述
上下文工程以正确的格式提供正确的信息和工具给智能体,从而使之能够正确完成任务。一个智能体的典型工作流程总是先调用大模型,再根据大模型调用返回结果调用工具,再调用大模型……,如此多次往复,直到大模型决定结束循环并给用户返回应答,如下图所示:
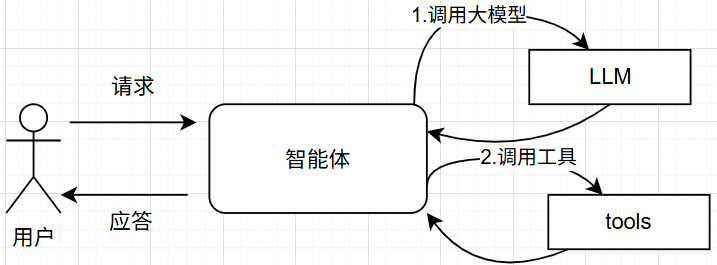
上下文工程就是通过控制大模型上下文、工具上下文,并通过中间件拦截数据流实现汇总、日志和护栏来优化上下文,提高智能体的可靠性。
模型上下文是指大模型被调用前所能访问的所有数据,包括指令、消息历史、工具集和应答格式;工具上下文时指工具被调用时所能访问的所有数据及调用后生成的数据,这些数据在运行时上下文、state和 store中;生命周期上下文是指大模型和工具被调用前后的行为。
2.2模型上下文工程
模型上下文工程包括动态提示词、消息工程、工具工程、模型工程和输出格式化,下面分别示例说明。
2.2.1动态系统提示词
系统提示词限定了大模型的行为模式。不同的用户类型、上下文或对话的不同阶段需要不同的提示词。智能体需要根据这些信息使用不同的提示词,动态系统提示词可以根据运行时上下文、状态和store中的信息,动态生成提供给大模型的系统提示词。
以下代码根据运行时上下文中的用户的级别生成不同的上下文:‘
#上下文,提供了提示词选择器。在这里就是level
class Context(TypedDict):
level: str#使用dynamic_prompt注解下面的方式,作为提示选择器
@dynamic_prompt
def user_level_prompt(request: ModelRequest) -> str:
"""Generate system prompt based on user role."""#从运行时上下文获取用户的级别
level = request.runtime.context.get("level", "beginner")
base_prompt = "你是一个精通机器学习方面的专家."if user_role == "expert":#面向专家级别的提示词
return f"{base_prompt} 解释问题时,提供更多的细节."
elif user_role == "beginner": #面向新手级别的提示词
return f"{base_prompt} 解答问题时,尽量通俗易懂."return base_prompt
agent = create_agent(
model=llm,
tools=tools,#中间件中传入提示词选择器
middleware=[user_level_prompt],
context_schema=Context
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "解释一下朴素贝叶斯算法"}]},
context={"level": "expert"} #运行时上下文,调用是传入
)
以下代码根据状态数据中消息的条数是否超过某个阈值而生成不同的提示词:
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest@dynamic_prompt
def state_aware_prompt(request: ModelRequest) -> str:
message_count = len(request.state["messages"])base = "你是一个乐于助人的助手."
if message_count > 10:
base += "\n这是一个长对话,请在回复时务求简洁."return base
agent = create_agent(
model=llm,
tools=[search_tool],
middleware=[state_aware_prompt],)
’ 以下代码根据长期记忆中保存的用户信息中的喜欢的话题生成系统提示词:
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langgraph.store.memory import InMemoryStore@dataclass
class Context:
user_id: str@dynamic_prompt
def store_aware_prompt(request: ModelRequest) -> str:
user_id = request.runtime.context.user_id#从长期记忆中获取用户喜欢的话题
store = request.runtime.store
user_info = store.get(("users",), user_id)base = "你是一个乐于助人的智能助手."
if favourite_topics:
topics = user_info.value.get("favourite_topic", "sports")
base += f"\n用户喜欢的话题是 {topics},围绕用户喜欢的话题展开对话 ."return base
agent = create_agent(
model=llm,
tools=[search_tool,],
middleware=[store_aware_prompt],
context_schema=Context,
store=InMemoryStore()
)
2.2.2消息工程
以下示例代码根据运行时上下文提供用户的籍贯信息,从而可以在改写诗词时使用正确的方言:
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable@dataclass
class Context:
user_name: str
birth_origin: str@wrap_model_call
def inject_user_context(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""在运行时上下文中注入用户的籍贯."""
# 从运行时上下文获取用户姓名和籍贯
name = request.runtime.context.user_name
birth_origin = request.runtime.context.birth_origin
user_context = f"""{name}的籍贯是{birth_origin}"""
messages = [ #把组装的user_context作为最近的一条用户消息
*request.messages,
{"role": "user", "content": user_context}
]
request = request.override(messages=messages)return handler(request)
agent = create_agent(
model=llm,
tools=[],
middleware=[inject_user_context],
context_schema=Context
)agent.invoke(
{"messages": [{"role": "user", "content": "请用方言改写陆游的示儿"}]},
context=Context(user_name="张三", birth_origin="四川")
)
以下示例代码中,在请求的消息中携带了文件列表(包括文件名称和文件唯一标识)信息,把可访问的文件信息组织称一条用户的消息并插入到messages列表中,大模型可以根据实际需要访问具体的文件:
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable@wrap_model_call
def inject_file_context(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""注入用户上传过的文件."""
# 从state中获取文件信息
files = request.state.get("files", [])if files:
# 构建可用文件上下文
available_files = []
for file in files:
available_files.append(
f"- {file['name']} ({file['id']})"
)file_context = f"""可以在本次会话中访问的文件包括:{chr(10).join(available_files)},可以根据需要访问这些文件的内容."""
messages = [ #把可用文件上下文增加到messages中
*request.messages,
{"role": "user", "content": file_context},
]
request = request.override(messages=messages)return handler(request)
agent = create_agent(
model=llm,
tools=[get_file, ],
middleware=[inject_file_context]
)
当然,如果用户上传的文件信息保存在长期记忆中,可以根据状态中或运行时上下文中的userid从store中获取文件列表,具体不需赘述。
2.2.3工具工程
2.2.3.1工具定义
工具支持大模型与数据库及外部系统交互,从而极大的增强了大模型的能力,为了保证大模型能够正确选择要求工具,每个工具都需要一个明确的名称、描述、参数名称和参数描述。
简单的工具,有一个工具描述即可,复杂的工具,则需要对何时调用本工具和工具的参数进行详细说明,如下是一个工具定义的实例:
from langchain.tools import tool
@tool(parse_docstring=True)
def search_licenses(
uniscid: str,
status: str,
max_result: int = 10
) -> str:
"""Search for enterprise licenses by status.Use this when the enterprise asks about it's licenses or wants to check
licenses status. Always filter by the provided status.Args:
uniscid: Unique identifier for the enterprise
status: Licenses status: 'inuse', 'revoked', or 'canceled'
limit: Maximum number of results to return
"""
# Implementation here
pass
2.2.3.2工具选择
每个工具都有其适用性,如果不管是否有用,每次调用大模型都传入所有的模型,则会导致上下文过载,无用的信息淹没大模型,从而增加出错的概率;如果传递给大模型的工具太少则限制了其能力。为了解决以上问题,往往采用动态选择工具,根据用户角色、标志及对话阶段等调整大模型可用工具集。
如下代码根据运行上下文中的用户角色确定大模型可调用的工具,如果用户角色是管理员,则可以调用所有的工具,如果用户是普通用户,则只能调用读工具。
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable@dataclass
class Context:
role: str@wrap_model_call
def context_based_tools(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据用户角色过滤工具列表"""
#从运行时上下文获取用户角色
urole = request.runtime.context.user_roleif role == "admin":
# 如果是管理员则可以调用所有工具
pass
else:
# 只能调用执行读操作的工具
tools = [t for t in request.tools if t.name.startswith("read_")]
request = request.override(tools=tools)return handler(request)
agent = create_agent(
model=llm,
tools=[make_seal, update_seal, delete_seal, read_seal,],
middleware=[context_based_tools],
context_schema=Context
)
当然,也可以根据保存在状态中的数据选择大模型可用列表,与上面代码的区别仅仅是从状态中获取数据,还是从store中获取数据,不再赘述。
2.2.4模型工程
不同的大模型各有优缺点及使用条件,可以根据上下文选择不同的大模型。上下文数据可来自运行时上下文,也可来自状态,还可来自长期记忆。
具体实现参见《langchain1.0 中的agent 5.动态选择模型》,在此不做赘述。
2.2.5输出格式化
格式化输出可以让智能体实现输出的结构化,可以是JSON对象,也可以是Pydantic模型,从而可以在下游直接使用。
2.2.5.1定义数据结构
如下示例定义了一个候选人简历的数据结构,分别采用BaseModel和JSON两种格式:
from pydantic import BaseModel
from typing_extensions import TypedDictclass Resume(TypedDict): #输出格式为JSON
name: str
age: str
phone: str
class Resume(BaseModel): #输出格式为JSON
name: str = Field(description="user name")
age: str = Field(description="age")
phone: str = Field(description="phone")
2.2.5.2动态选择输出模式
还可以在运行时根据上下文数据动态选择数据结构。下面示例中,定义两个候选人简历结构,一个仅包括可公开的信息,人力资源专员可以使用,一个包括了不可公开的信息,比如薪资要求,身份证信息和家庭信息等,可以根据用户的角色选择使用的输出格式。
class SimpleResume(BaseModel): #输出格式为JSON
name: str = Field(description="user name")
age: str = Field(description="age")
phone: str = Field(description="phone")class DetailResume(BaseModel): #输出格式为JSON
name: str = Field(description="user name")
age: str = Field(description="age")
phone: str = Field(description="phone")salary: str = Field(description="salary")
idcard: str = Field(description="idcard number")
family: str = Field(description="family information")
@wrap_model_call
def context_based_output(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""Select output format based on Runtime Context."""
# Read from Runtime Context: user role and environment
role = request.runtime.context.roleif role == "supervisor":
request = request.override(response_format=DetailResume)
else:
# Regular users get simple output
request = request.override(response_format=SimpleResume)return handler(request)
2.3工具上下文工程
在现实的生产系统,工具往往担负着与外部系统交互的职责,此时需要从上下文数据中获取关键数据,比如用户的id,或者第三方应用分配的api_key等,然后根据用户id查询数据库,或者使用api_key调用第三方应用系统。
如下示例代码,从运行时上下文获取用户id,然后访问数据库,根据用户id查询用户的详细信息:
@dataclass
class Context:
user_id: str@tool
def fetch_user_data(
query: str,
runtime: ToolRuntime[Context]
) -> str:
"""Fetch data using Runtime Context configuration."""
# Read from Runtime Context: get API key and DB connection
user_id = runtime.context.user_id# Use configuration to fetch data
user_info = find_user_info(user_id)return f"{user_id}'s information:{user_Info}"
agent = create_agent(
model=llm,
tools=[fetch_user_data],
context_schema=Context
)
当然工具也可以执行写操作,实现对长短期记忆的更新。参见《langchain agent中的短期记忆》和《langchain agent 中的长期记忆》
2.4生命周期上下文工程
基于中间件可以在智能体生命周期中的任何步骤插入逻辑,并且可以更新上下文数据(包括长短期记忆),还可以根据上下文进行跳转。具体参见《langchain agent的中间件》。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)