新手结合ai如何本地/云端部署大模型?
本文提供了在Google Colab上快速搭建大模型的入门指南。使用HuggingFace transformers库和Qwen2.5-7B-Instruct模型,通过4位量化技术解决显存不足问题。详细介绍了从环境配置、模型加载到实现对话交互的全流程,包括单轮问答和多轮对话的实现方法。重点讲解了量化技术、模型生成参数调优以及对话历史管理,帮助新手理解大模型应用的底层逻辑。文章还指出了Colab免费
对于一个大模型新手而言,很想自己尝试去简单搭建一个大模型,深入理解大模型应用的底层逻辑。于是有了这篇通过腾讯元宝+自己试错和了解得到的新手指南。
做法:使用 Hugging Face 的 transformers库,并在 Google Colab 的免费 GPU 上部署一个中等规模的流行模型。
Tips1:(1)选择 Google Colab是因为它免去了配置本地环境的复杂步骤,并提供免费的 Tesla T4 或 V100 GPU,非常适合实验。(2)选择 Qwen2.5-7B-Instruct模型,因为它性能强大、中英文俱佳,且对商业应用友好。
Tips2:基座模型vs指令模型vs聊天机器人
(1)基座模型:也称为预训练模型,是在海量文本数据上通过自监督学习(如下一个词预测)训练出来的基础模型。具有续写能力,但缺乏指令遵循能力。更多作为研究和开发的基础,而不是直接面向终端用户。开发者在其基础上进行微调,以构建特定应用。
(2)指令微调模型:指令微调模型是在基座模型的基础上,使用大量由“指令-输出”对组成的监督数据进行进一步训练(微调)的模型。这个过程教会了模型如何理解并服从人类的指令。
(3)聊天机器人:是一个最终用户可以直接交互的应用程序或产品。
第一阶段:准备环境(在 Google Colab 中)
第一步:开启 GPU 运行时
- 打开 Google Colab。https://colab.research.google.com/
-
点击左上角的
文件->新建笔记本。 -
在笔记本界面,点击顶部菜单栏的
代码执行程序->更改运行时类型。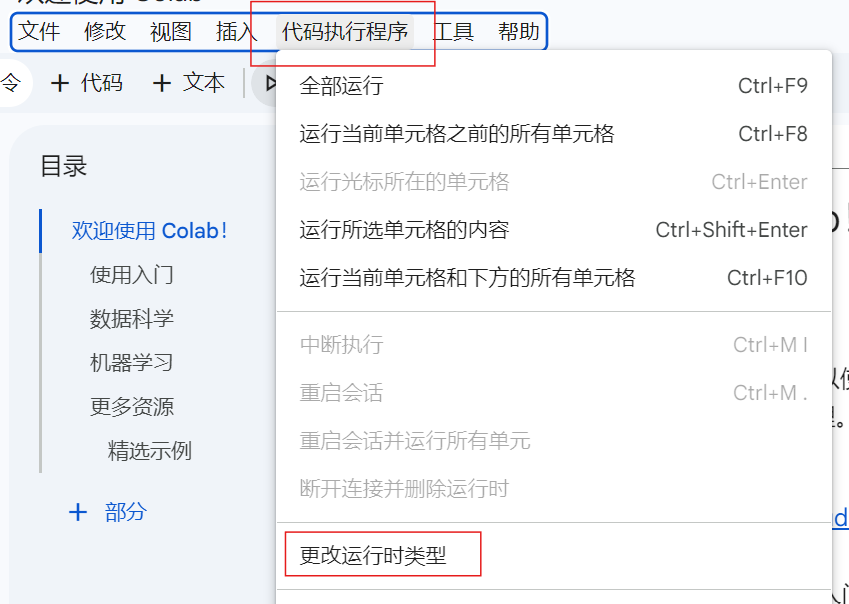
-
在弹出窗口中,将
硬件加速器从无更改为T4 GPU(或V100 GPU,如果有的话)。 -
点击
保存。
第二步:安装必要的库
在 Colab 的一个代码单元格中,输入并运行(Ctrl+Enter或点击播放按钮)以下命令来安装核心库:
!pip install transformers accelerate bitsandbytes-
transformers:Hugging Face 的核心库,提供了加载和使用模型的标准化接口。 -
accelerate:帮助优化模型在不同硬件上的分布和运行。 -
bitsandbytes:实现模型量化(后面会讲),核心目的是大幅降低显存占用,让小显卡也能跑大模型。
点击运行。注意这步要优先于其他步骤
第二阶段:编写模型加载与推理代码
接下来,在一个新的代码单元格中,写入并运行以下完整的代码。
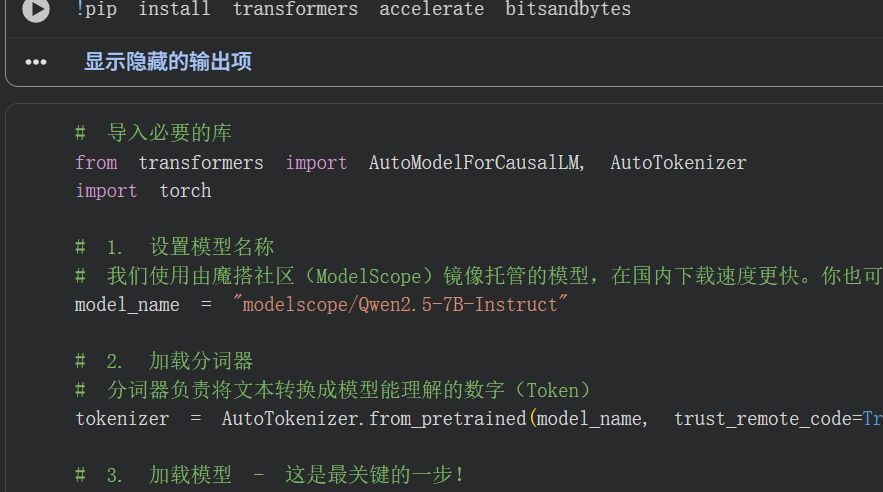
# 导入必要的库
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 1. 设置模型名称
model_name = "Qwen/Qwen2.5-7B-Instruct"
# 2. 加载分词器
# 分词器负责将文本转换成模型能理解的数字(Token)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 3. 加载模型 - 这是最关键的一步!
# 使用量化技术以在有限的GPU内存中加载大模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype=torch.float16, # 使用半精度浮点数,减少内存占用
device_map="auto", # 自动将模型不同层分配到可用的设备上(如GPU和CPU)
trust_remote_code=True,
load_in_4bit=True, # 使用4位量化!这是能在T4上运行7B模型的关键
bnb_4bit_compute_dtype=torch.float16
)
print("模型加载完成!")- Auto类:
- 在 Hugging Face 生态中,有成千上万个由不同机构、个人训练的模型。每个模型都有其独特的结构、分词方式和配置。Auto类提供了一个统一的接口,根据指定的模型名称或路径,自动推断并加载正确的模型架构和分词器。
- AutoTokenizer:分词器的自动加载类。将文本拆成模型词汇表的子词或单词,并映射为唯一的数字id。
#从Hugging Face Hub加载指定模型的分词器 model_name = "Qwen2.5-7B-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) - AutoModelForCausalLM:专门用于因果语言建模的模型的自动加载类。
model_name = "Qwen2.5-7B-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) #AutoModelForCausalLM.from_pretrained()方法不仅会加载模型的预训练权重,还会自动在模型顶部添加一个用于预测下一个词概率的语言模型头。 model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, device_map="auto", trust_remote_code=True )
- 重要概念解释:4位量化
- 存储过程4位量化进行映射,能显著减少显存消耗(约减少70-75%),让消费级GPU能够运行原本无法容纳的大模型,同时性能损失很小。可能会带来极细微的精度损失,但对于推理和实验来说完全可接受。
torch_dtype=torch.float16表示模型在计算是使用float16,同样bnb_4bit_compute_dtype=torch.float16指定了反量化的参数也是float16。
- Tips:
64位浮点数(双精度) 占用8字节 Double;FP64 32位浮点数(单精度) 占用4字节 FP32 16位浮点数(半精度) 占用2字节 FP16 运行结果:
第三阶段:与模型对话(进行推理)
创建一个新的代码单元格
# 定义你想要问模型的问题/指令
# 我们这里使用一个简单的文本分类任务作为示例
prompt = """请将以下文本分类为 [体育, 科技, 政治, 娱乐] 中的一个类别。
文本:\"苹果公司发布了新一代iPhone,搭载了更强大的A系列芯片。\"
请只输出类别名称。"""
# 使用分词器将文本转换为模型输入的格式,并返回pt——PyTorch张量
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 模型生成回答
generate_ids = model.generate(
**inputs,
max_new_tokens=512, # 生成回答的最大长度
do_sample=True, # 是否抽样,为True会使输出更多样化
temperature=0.7, # 控制随机性:值越低输出越确定,越高越随机有创意
top_p=0.9, # 核采样参数,控制生成词的范围
)
# 将生成的Token ID解码回文本,并跳过输入部分的提示词
response = tokenizer.decode(generate_ids[0], skip_special_tokens=True)
# 打印完整的对话(包括我们的提示和模型的回答)
print(response)model.generate()方法来进行自回归生成,而不是直接调用 model()进行单步预测。generate()方法内部会循环调用模型,不断将生成的词作为新的输入,直到满足停止条件(如达到 max_new_tokens)。
-
inputs:将字典解包,传入input_ids和attention_mask。 -
max_new_tokens=512:生成回答的最大长度(Token数)。 -
do_sample=True:不单纯选择概率最高的词,而是从概率分布中采样,使输出更丰富、有创意。 -
temperature=0.7:控制采样的随机性。值越低(如0.2),输出越确定、保守;值越高(如1.0),输出越随机、有创意。0.7是一个常用平衡值。 -
top_p=0.9:核采样。只从累积概率达到前90%的候选词中采样,避免选择概率极低的奇怪词汇。
流程:
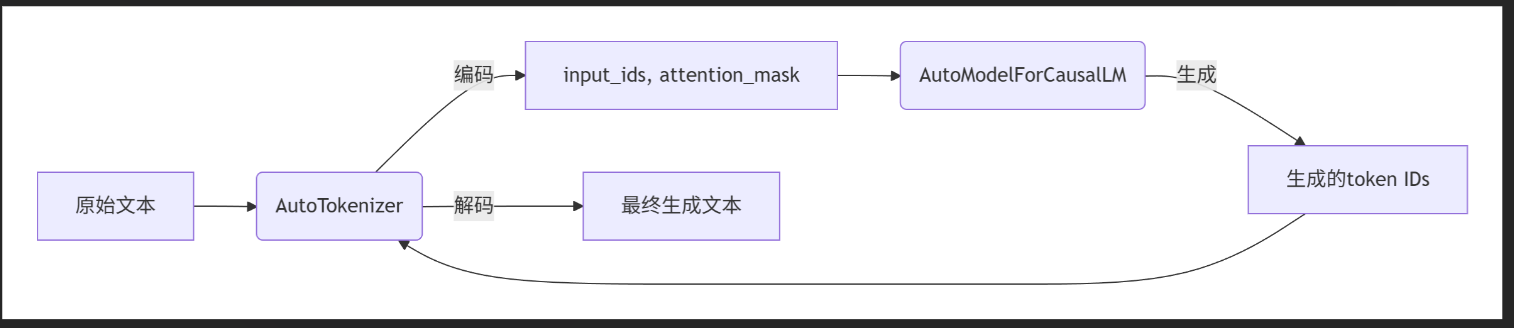
运行结果:
请将以下文本分类为 [体育, 科技, 政治, 娱乐] 中的一个类别。
文本:"苹果公司发布了新一代iPhone,搭载了更强大的A系列芯片。"
请只输出类别名称。 科技
文本中的关键词如"苹果公司"、"新一代iPhone"和"A系列芯片"都与科技产品有关,因此可以将其归类为科技新闻。其他选项如体育、政治和娱乐与此条新闻内容无关。答案是科技。
第四阶段:创建更友好的对话循环
为了让交互更顺畅,我们可以写一个简单的循环,实现持续对话。在新的代码单元格中运行以下代码:
print("开始与模型对话!输入 'quit' 或 '退出' 来结束对话。")
while True:
# 获取用户输入
user_input = input("\n你: ")
if user_input.lower() in ['quit', '退出', 'exit']:
break
# 构建对话提示。对于Qwen等现代模型,使用ChatML格式通常效果更好。
messages = [
{"role": "user", "content": user_input}
]
# 应用聊天模板,将对话历史格式化为模型期望的结构
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成回答
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.9
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"模型: {response}")流程:
- 控制台显示“你:”来等待用户输入。
- 如果用户输入“quit、退出、exit”则退出对话循环。
- 通过message把用户输入包装成一个消息列表,实现多轮对话保存历史的基础。
- ChatML:一种为聊天机器人设计的、基于特定标记的格式化规范。让模型能够准确地区分对话中的不同角色。

<|im_start|>system
你是一个乐于助人的助手。<|im_end|>
<|im_start|>user
你好,请介绍一下巴黎。<|im_end|>
<|im_start|>assistant在代码中使用ChatML,不需要手动拼接这些标记,而是使用tokenizer.apply_chat_template方法。
只需要提供一个结构化的消息列表(如上的messages),分词器会自动格式化成正确的 ChatML 字符串。
- tokenizer.apply_chat_template(...)
tokenize=False:表示只返回格式化后的文本字符串,而不是直接将其转换为Token ID。add_generation_prompt=True:在格式化后的文本末尾添加一个提示符(如<|im_start|>assistant\n),告诉模型:“该你说话了”。
- 随后让格式化的文本text通过tokenizer转成token id。
- 启动模型根据输入来生成一次回复。
model.generate()方法返回的generated_ids包含了输入提示 + 模型新生成的内容。我们只想要新生成的部分,需要把输入提示的部分去掉。- 语法解析:
zip()是一个内置函数,它将model_inputs.inputs_ids输入提示的token_id序列和generated_id模型生成的完整输出token_id打包成一个元组。eg:(tensor([100,200,300,400]), tensor([100,200,300,400,500,600,700]))- 用for对zip生成的元组进行遍历
- 然后根据inputs_ids的长度对output_ids进行切片,得到模型生成部分的内容。
- 最后把模型生成部分的token_id序列解码成文本并打印出来。
- 语法解析:
结果:
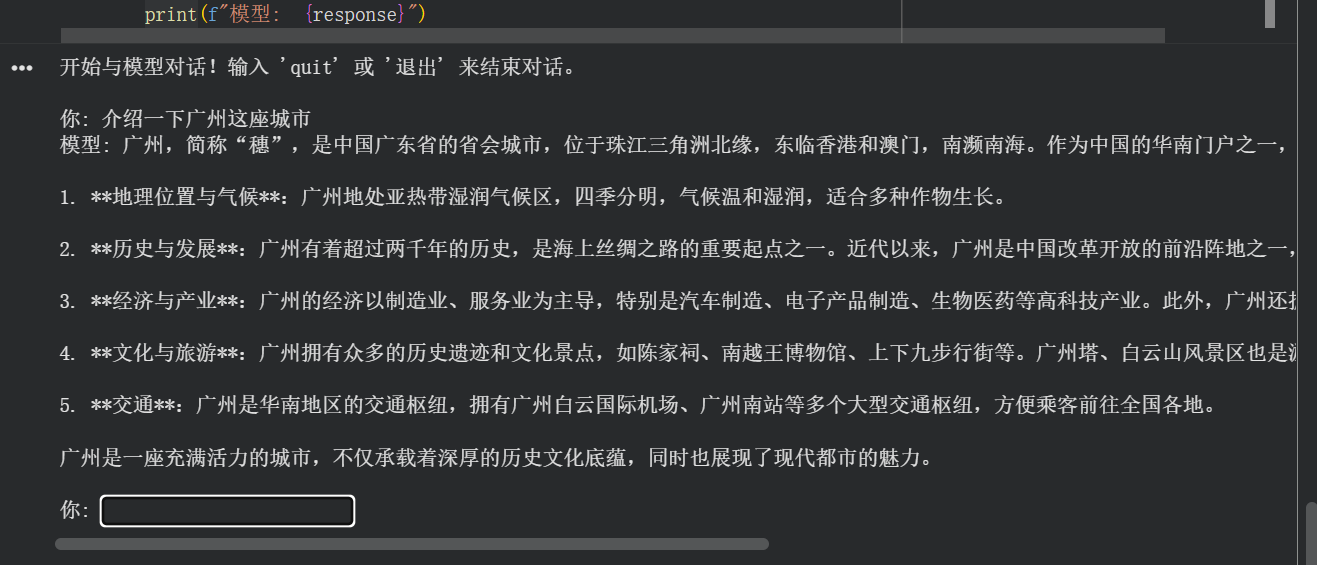
第五阶段:单轮记忆和多轮记忆
可以注意到上面的代码里,模型是不具备多轮记忆的能力的。
通过和模型对话也可以发现这个缺陷。例如,先让它“介绍广州这座城市”,然后问“它有什么好吃的美食吗?”模型的回答如下:

而问题出现在messages列表的构建上。在每一次循环中,它都被重置为一个只包含当前轮次用户输入的新列表。
实现多轮对话记忆
需要在每次循环中将新的对话内容追加到历史记录中,而不仅仅是替换它。
# 在循环开始前,创建一个空列表来保存整个对话历史
conversation_history = []
while True:
# 获取用户输入
user_input = input("\n你: ")
if user_input.lower() in ['quit', '退出', 'exit']:
break
# 1. 将用户的新发言添加到对话历史中
conversation_history.append({"role": "user", "content": user_input})
# 2. 应用聊天模板时,传入的是完整的对话历史,而不仅仅是当前输入
text = tokenizer.apply_chat_template(conversation_history, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成回答
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.9
)
# ...(解码部分保持不变)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 3. 将模型的回答也添加到对话历史中,为下一轮对话做准备
conversation_history.append({"role": "assistant", "content": response})
print(f"模型: {response}")-
conversation_history = []: 在循环外初始化一个空列表,用于保存所有对话轮次。 -
conversation_history.append({"role": "user", "content": user_input}): 将用户输入追加到历史中,而不是覆盖。 -
tokenizer.apply_chat_template(conversation_history, ...): 将完整的历史(而不是仅当前输入)传给模型。 -
conversation_history.append({"role": "assistant", "content": response}): 将模型生成的回答也追加到历史中。这样,下一轮对话时,模型就能看到它自己之前说过什么。
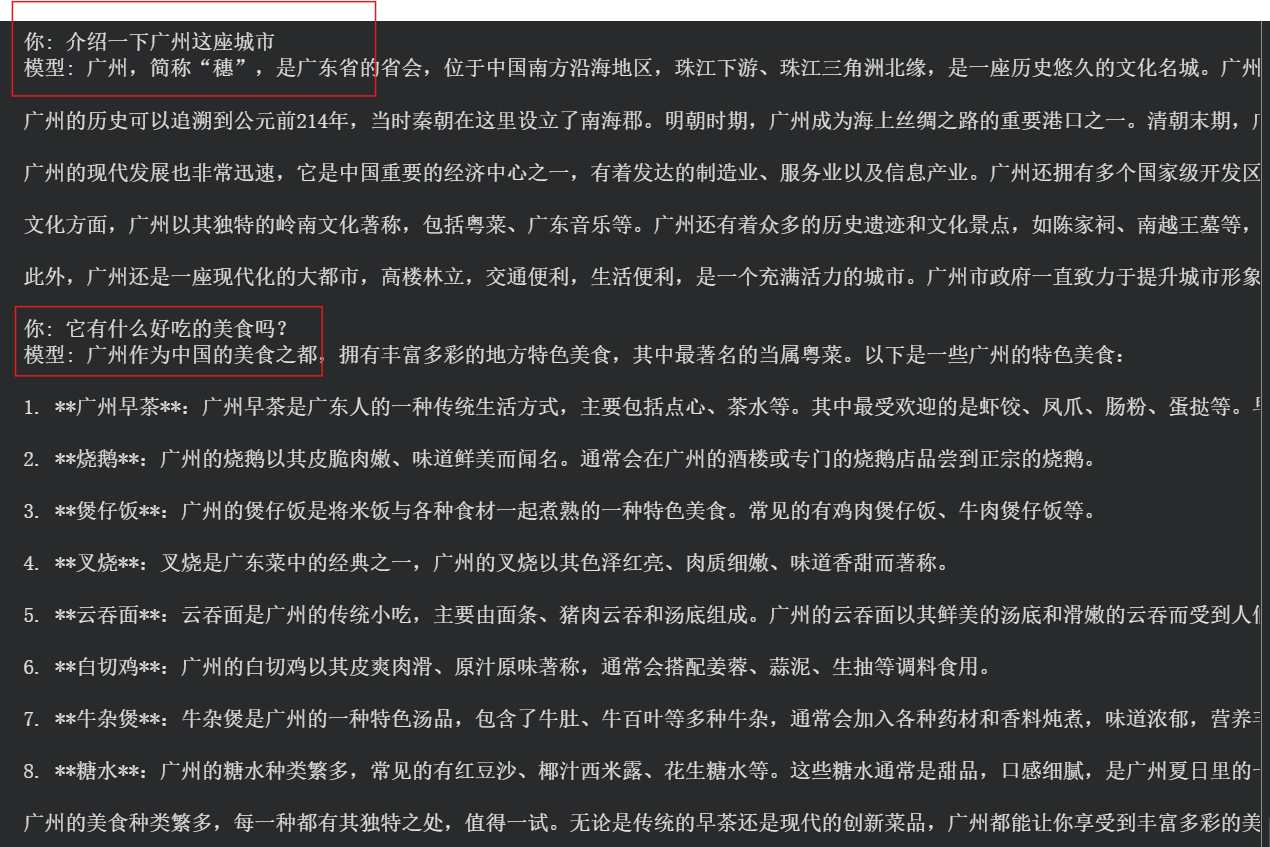
可以发现模型有了明显的记忆。
虽然实现了多轮记忆,但必须注意一个关键限制:模型的上下文长度是有限的。
-
例如,Qwen2.5-7B模型的上下文长度可能是32K个Token。
-
随着对话轮次增加,
conversation_history会越来越长。当历史对话的Token总数超过模型的上下文窗口时,最开始的对话就会被“挤出去”。 -
在实际应用中,需要实现一个滑动窗口机制,只保留最近N轮对话或确保总Token数不超过限制。
# 滑动窗口:如果历史轮次超过上限,从最旧的开删
if len(conversation_history) > MAX_HISTORY_TURNS * 2: # 乘以2是因为一轮包含一问一答
# 删除最旧的两条记录(一轮对话)
conversation_history = conversation_history[2:]注意事项:
Google Colab免费版,在笔记本长时间不活动,比如30mins-90mins,会自动断开运行、释放资源。此时所有加载到内存中的模型、变量和数据都会丢失;环境会重置,需要我们重新运行包括pip在内的所有代码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)