张量并行和模型并行
PipeDream是非交错的Pipeline Parallel, 执行方式是当一个micro-batch forward计算完了之后, 马上执行backward计算, 这样能够提前释放相关micro-batch的intermediate activation, 从而节省显存。最初提出Tensor Parallel是在32G的GPU上训练超大模型, 此时可能会存在单层Transformer显存过大的
目录
模型并行分为两种: 1. Tensor Parallel (TP); 2. Pipeline Parallel (PP)。现在的大模型训练都是3D parallel: Data Parallel + Pipeline Parallel + Tensor Parallel。
1. Tensor Parallel
Tensor Parallel原来是用来解决单层参数太多, 一个GPU放不下的问题。现在的主要作用是加快计算。
Tensor Parallel 又分为Column Parallel何Row Parallel。最初提出Tensor Parallel是在32G的GPU上训练超大模型, 此时可能会存在单层Transformer显存过大的问题, 因此将权重矩阵分解到多个GPU上分别计算。现在GPU显存足够大, 用Tensor Parallel是为了加快计算。
其中Column Parallel和Row Parallel是针对权重weight来说的。
1.1 Column Parallel
对于Column Parallel, 将weight安装列分解, 输入X不用分解。Column Parallel常用于Transformer中MLP的第1层。
y = X @ W = X @ [ w 1 w 2 ] = [ X @ w 1 X @ w 2 ] y = X @ W = X @ [w1\quad w2] = [X@w1\quad X@w2] y=X@W=X@[w1w2]=[X@w1X@w2]
先将weight按照列分解到多个GPU上, 分别计算结果后然后 concat \color{red}{\text{concat}} concat起来: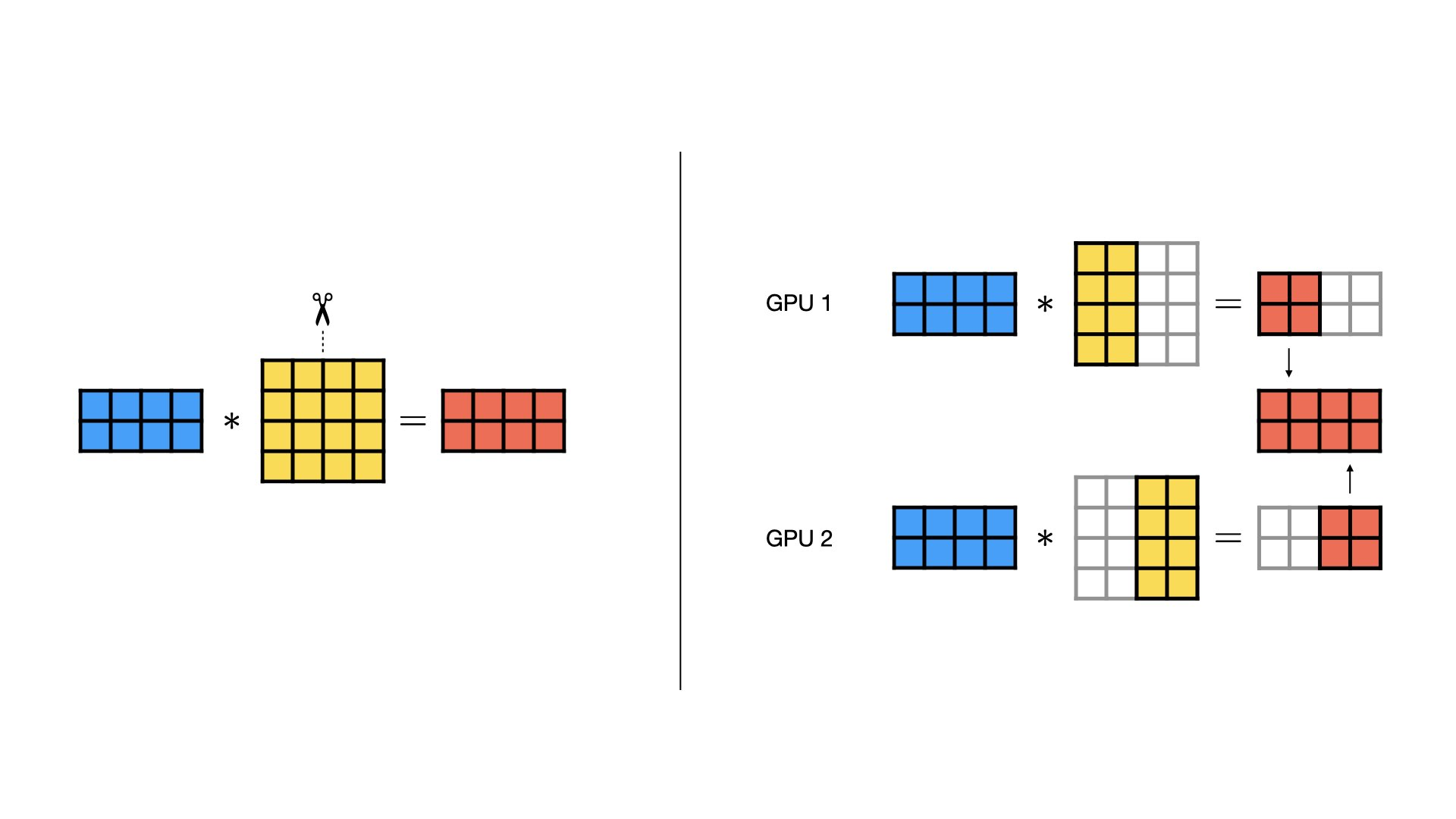
1.2 Row Parallel
Row Parallel, 将wegith按照行分解, 此时输入X也要按照列分解, 先分别在各GPU上计算完, 然后结果 concat \color{red}{\text{concat}} concat:
y = X @ W = [ X 1 X 2 ] @ [ W 1 W 2 ] T = X 1 @ W 1 + X 2 @ W 2 y = X @ W = [X1\quad X2] @ [W1\quad W2]^T = X1@W1+X2@W2 y=X@W=[X1X2]@[W1W2]T=X1@W1+X2@W2
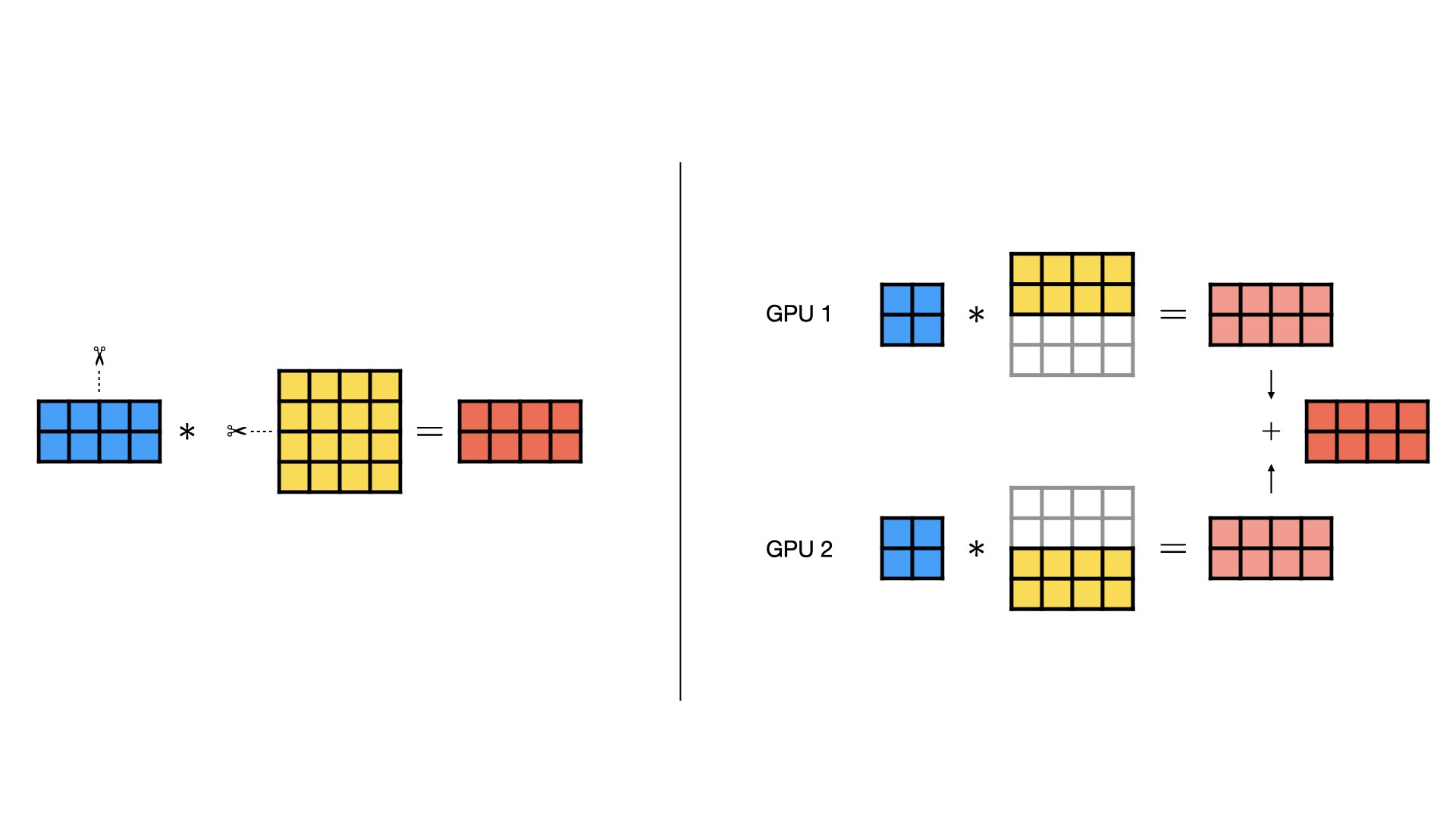
Row Parallel常用于Transformer中MLP的第2层。
注意: Tensor Parallel中涉及到很多的AllReduce操作, 因此通信开销较大, 尝尝用于单机多卡, 之间用NvLink通信。
1.3 PyTorch实现
import torch
import torch.distributed as dist
import torch.nn as nn
dist.init_process_group(backend='nccl')
rank = dist.get_rank()
world_size = dist.get_world_size()
device = torch.device(f'cuda:{rank}')
class ColumnParallelLinear(nn.Module):
def __init__(self, in_features, out_features, process_group=None):
super().__init__()
self.rank = dist.get_rank(process_group)
self.world_size = dist.get_world_size(process_group)
self.out_per_rank = out_features // self.world_size
self.weight = nn.Parameter(
torch.randn(in_features, self.out_per_rank, device=device) * 0.02
)
self.bias = nn.Parameter(torch.zeros(self.out_per_rank, device=device))
self.process_group = process_group
def forward(self, x):
# 每个 GPU 独立计算局部输出
out_partial = x @ self.weight + self.bias
# 最后拼接结果
outs = [torch.zeros_like(out_partial) for _ in range(self.world_size)]
dist.all_gather(outs, out_partial, group=self.process_group)
return torch.cat(outs, dim=-1)
class RowParallelLinear(nn.Module):
def __init__(self, in_features, out_features, process_group=None):
super().__init__()
self.rank = dist.get_rank(process_group)
self.world_size = dist.get_world_size(process_group)
self.in_per_rank = in_features // self.world_size
self.weight = nn.Parameter(
torch.randn(self.in_per_rank, out_features, device=device) * 0.02
)
self.bias = nn.Parameter(torch.zeros(out_features, device=device))
self.process_group = process_group
def forward(self, x):
# 每个 GPU 只持有输入的一部分
x_local = x.chunk(self.world_size, dim=-1)[self.rank]
out_partial = x_local @ self.weight
# 聚合部分结果
dist.all_reduce(out_partial, op=dist.ReduceOp.SUM, group=self.process_group)
return out_partial + self.bias
# MLP层 = ColumnParallelLinear + GELU + RowParallelLinear
class TensorParallelMLP(nn.Module):
def __init__(self, hidden_size, ffn_size, process_group=None):
super().__init__()
self.fc1 = ColumnParallelLinear(hidden_size, ffn_size, process_group)
self.fc2 = RowParallelLinear(ffn_size, hidden_size, process_group)
def forward(self, x):
x = torch.nn.functional.gelu(self.fc1(x))
x = self.fc2(x)
return x
2. Pipeline Parallel
Pipeline Parallel是为了解决一个模型太大单GPU放不下, 因此将多层的模型放入多个GPU上训练。
2.1 朴素版本Pipeline Parallel

此时速度极慢, 每个时刻只有一个GPU在计算, 没有framework采用这种
2.2. GPipe(F then B)
为了提高运算速度, GPipe采用了micro-batch的方式加速: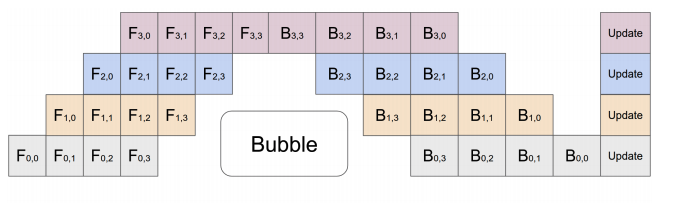
假设一个batch分成m个micor-batch, 共有p个GPU, forward和backward的时间分别为 t f t_f tf和 t b t_b tb。一般情况下 t b t_b tb的时间为 t f t_f tf的2倍, 因为backward的过程要算2次举证乘法, 分别是 ∂ o u t ∂ w \frac{\partial out}{\partial w} ∂w∂out和 ∂ o u t ∂ w \frac{\partial out}{\partial w} ∂w∂out
则理想情况时间为: m ( t f + t b ) m(t_f+t_b) m(tf+tb), 实际的时间为: ( m + p − 1 ) ( t f + t b ) (m+p-1)(t_f+t_b) (m+p−1)(tf+tb), bubble rate为:
m + p − 1 m − 1 = p − 1 m \frac{m+p-1}{m} - 1 = \frac{p-1}{m} mm+p−1−1=mp−1
p不变的情况下, 最好是增大micro-batch的数量m, 但是m最大, 则显存消耗越高。
PyTorch默认使用GPipe,
2.3. PipeDream(1F1B)
PipeDream是非交错的Pipeline Parallel, 执行方式是当一个micro-batch forward计算完了之后, 马上执行backward计算, 这样能够提前释放相关micro-batch的intermediate activation, 从而节省显存。这种方式不能降低bubble rate, 但是能够提高micro-batch, 因此间接降低了bubble rate。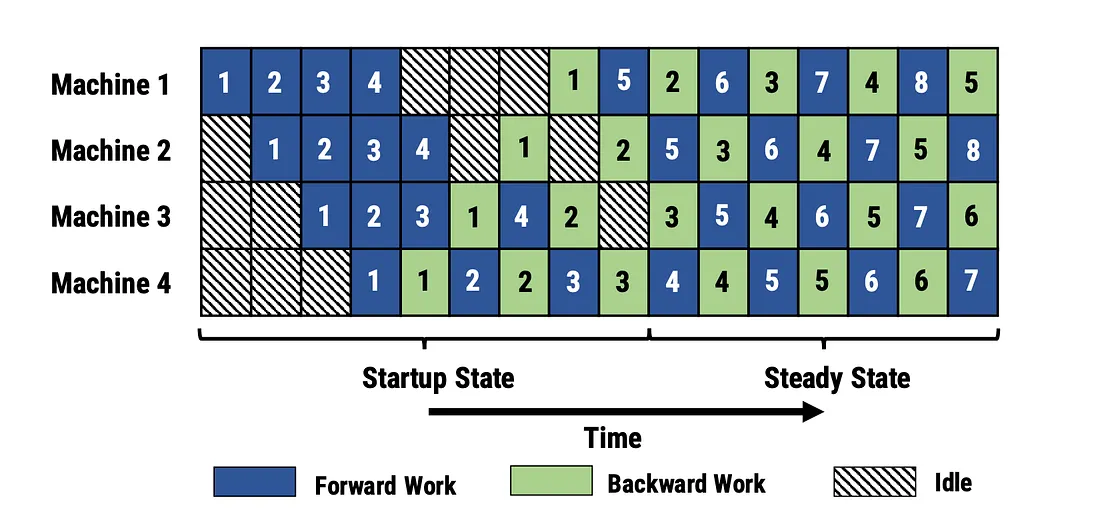
其中startup state阶段bubble较多, 而steady state阶段bubble较小。
DeepSpeed默认使用非交错式PipeDream
2.4. Interleaved PipeDream
为了进一步减少Bubble rate, 我们把model的各层交错式的放在各个GPU上。例如layer1 layer2 layer9 layer 10在GPU 0, layer3 layer4 layer 11 layer 12在GPU 1, 依次类推。这样在layer1 layer2计算完成后马上将数据传给GPU 1, 这样可以让GPU 1早一点参与到计算中。因为如果layer 1-layer4同在1个GPU上的话, GPU 0计算时间过长, 此时其他GPU处于空等状态。
Interleaved PipeDream能够降低bubble rate为GPipe的 1 N \frac{1}{N} N1, 其中N为层数比率。例如原来GPipe每个GPU放连续的4层, 现在放2个连续的2层, 因此bubble rate为原来的0.5。
Interleaved PipeDream的通行成本比GPipe高出不少, 解决办法是每台机器配8个InfiniBand的IB网卡加大吞吐, 原来的方案是每台机器只有1个IB网卡。
PyTorch默认使用GPipe, DeepSpeed默认使用非交错式PipeDream, Megatron LM默认使用Interleaved PipeDream, colossal AI 默认Interleaved PipeDream, 但也提供了非交错式实现。
3.5 代码实现
3.5.1 Pytorch PP
import torch
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe
# 模型定义
seq = nn.Sequential(
nn.Linear(512, 512), nn.ReLU(),
nn.Linear(512, 512), nn.ReLU(),
nn.Linear(512, 512), nn.ReLU(),
nn.Linear(512, 10)
)
# 切成两部分
model = nn.Sequential(
seq[:2].to('cuda:0'),
seq[2:].to('cuda:1')
)
# 创建Pipe
pipe = Pipe(model, chunks=4)
# 输入
inputs = torch.randn(32, 512, device='cuda:0')
targets = torch.randint(0, 10, (32,), device='cuda:1')
# 前向
outputs = pipe(inputs)
loss = nn.CrossEntropyLoss()(outputs, targets)
# 反向
loss.backward()
3.5.2 DeepSpeed PP
# train_pipeline.py
import torch
import torch.nn as nn
import deepspeed
from deepspeed.pipe import PipelineModule
# ---- 模型(示例:把若干层放进 Sequential) ----
def build_sequential_model(num_layers=8, hidden=512, out_dim=512):
layers = []
for i in range(num_layers):
layers.append(nn.Linear(hidden, hidden))
layers.append(nn.ReLU())
# 最后接一个输出层(示例)
layers.append(nn.Linear(hidden, out_dim))
return nn.Sequential(*layers)
# ---- loss 函数(pipeline 需要一个 loss 函数用于 schedule) ----
def loss_fn(outputs, labels):
# outputs: (batch, ..) 这里示例用 MSE(根据任务改成 CrossEntropy 等)
return torch.nn.functional.mse_loss(outputs, labels)
def main():
# 假设用 2 个pipeline stage(实际按你的GPU数/分区决定)
pipe_parallel_size = 2
# 构造 Sequential 模型
seq_model = build_sequential_model(num_layers=8, hidden=512, out_dim=512)
# Wrap with PipelineModule: DeepSpeed 会按 num_stages 把 layers 分配到 stage 上
pm = PipelineModule(
layers=seq_model, # 必须是 nn.Sequential 或可被解构的层序列
num_stages=pipe_parallel_size, # pipeline stage 数量
loss_fn=loss_fn, # 用于 schedule 的 loss 函数
partition_method='parameters', # 切分策略: parameters | uniform | type:regex
activation_checkpoint_interval=0 # 可设置 checkpoint 节省激活内存
)
# DeepSpeed 初始化:当 model 是 PipelineModule 时,返回的是 PipelineEngine
# 你可以传入 config 文件路径或 dict(这里示例用 config file)
ds_config = "ds_config.json" # 或直接传 dict 到 config_params
engine, optimizer, _, _ = deepspeed.initialize(
model=pm,
config=ds_config
)
# 构造一个简单 dataloader(示例用随机数据)
batch_size = 16
for step in range(100):
# DeepSpeed pipeline engine 提供 train_batch 接口:
# 它会从 data_iter 读取 micro-batches,推进 pipeline schedule,并返回 loss。
# 你需要提供一个迭代器(或 generator)产生训练样本(inputs, labels)。
def data_iter():
# 在真实场景替换成你的 DataLoader iterator
# 这里我们 yield 每个 mini-batch(train_micro_batch_size_per_gpu 的大小)
for _ in range(1): # yield one "batch" to train_batch; 真实场景更多
x = torch.randn(batch_size, 512).to(engine.local_rank)
y = torch.randn(batch_size, 512).to(engine.local_rank)
yield x, y
loss = engine.train_batch(data_iter())
# train_batch 已经包含 forward/backward/optimizer-step(按 schedule)
if engine.global_rank == 0:
print(f"step {step} loss {loss.item() if hasattr(loss,'item') else loss}")
if __name__ == "__main__":
main()
3.5.3. Megatron LM
定义训练命令:
torchrun --nproc_per_node=8 pretrain_gpt.py \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 4 \
--num-layers 24 \
--hidden-size 2048 \
--num-attention-heads 16 \
--micro-batch-size 4 \
--global-batch-size 64 \
--seq-length 1024 \
--max-position-embeddings 1024 \
--train-iters 100000 \
--lr 0.00015 \
--min-lr 1.0e-5 \
--lr-decay-style cosine
import torch
import torch.nn as nn
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn import functional as F
# ==============================================
# Step 1. 定义一个简化的 TransformerBlock
# ==============================================
class Block(nn.Module):
def __init__(self, hidden_size=512):
super().__init__()
self.fc1 = nn.Linear(hidden_size, hidden_size)
self.act = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, hidden_size)
def forward(self, x):
return self.fc2(self.act(self.fc1(x))) + x
# ==============================================
# Step 2. 定义一个可切分的模型(每个 rank 负责部分层)
# ==============================================
class PipelineModel(nn.Module):
def __init__(self, num_layers=8, hidden=512, rank=0, world_size=4):
super().__init__()
# 将层平均分配到各个 stage
layers_per_stage = num_layers // world_size
start = rank * layers_per_stage
end = (rank + 1) * layers_per_stage
self.layers = nn.Sequential(
*[Block(hidden) for _ in range(start, end)]
)
self.hidden = hidden
def forward(self, x):
return self.layers(x)
# ==============================================
# Step 3. Pipeline 通信逻辑 (send/recv 激活)
# ==============================================
def pipeline_forward_backward(model, optimizer, input_data, target, rank, world_size):
# 第一阶段的输入
if rank == 0:
x = input_data
else:
# 从前一阶段接收
x = torch.zeros_like(input_data)
dist.recv(x, src=rank - 1)
# 前向计算
out = model(x)
# 发送给下一阶段
if rank != world_size - 1:
dist.send(out.detach(), dst=rank + 1)
else:
# 最后一阶段计算 loss
loss = F.mse_loss(out, target)
loss.backward()
dist.send(torch.ones(1).to(out.device), dst=rank - 1)
return loss.item()
# 接收 backward 信号(这里只传 dummy)
if rank != 0:
grad_signal = torch.zeros(1).to(out.device)
dist.recv(grad_signal, src=rank + 1)
# 反向传播
out.mean().backward()
dist.send(torch.ones(1).to(out.device), dst=rank - 1)
optimizer.step()
optimizer.zero_grad()
return None
# ==============================================
# Step 4. 主训练函数
# ==============================================
def run(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
model = PipelineModel(rank=rank, world_size=world_size).cuda(rank)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for step in range(50):
x = torch.randn(8, 512).cuda(rank)
y = torch.randn(8, 512).cuda(rank)
loss = pipeline_forward_backward(model, optimizer, x, y, rank, world_size)
if loss is not None and rank == world_size - 1:
print(f"[step {step}] loss = {loss:.4f}")
dist.destroy_process_group()
# ==============================================
# Step 5. 启动
# ==============================================
if __name__ == "__main__":
world_size = 4 # 4个GPU
mp.spawn(run, args=(world_size,), nprocs=world_size)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)