通俗介绍大模型,从RNN 到Transformer
本文概述了大型语言模型(LLM)的发展历程与技术特点。从RNN到Transformer架构的演进,解决了序列处理中的长距离关系捕捉问题。LLM基于Transformer,通过海量参数、训练数据和计算资源,在预测下一个词的过程中学习语法、语义、知识推理等能力。文章分析了LLM的优势(理解复杂语义)与局限(可能出现幻觉、非实时数据),并介绍了CoT、RAG等应用技术。最后指出LLM已成为AI生态链的核
今天,我们来看看RNN、Encoder技术最终累积导向的成果:LLM(Large Language Model)大型语言模型。
从RNN 到Transformer
这边稍微回顾一下前几天讲过的深度学习模型架构:
1. RNN(Recurrent Neural Network)
-
特点:逐步处理序列资料
-
问题:长距离的文字关系比较难捕捉、训练时间比较长
2. Encoder–Decoder 架构
-
应用:翻译、摘要等序列转换任务
-
优点:分为Encoder(编码器)与Decoder(解码器)两个阶段
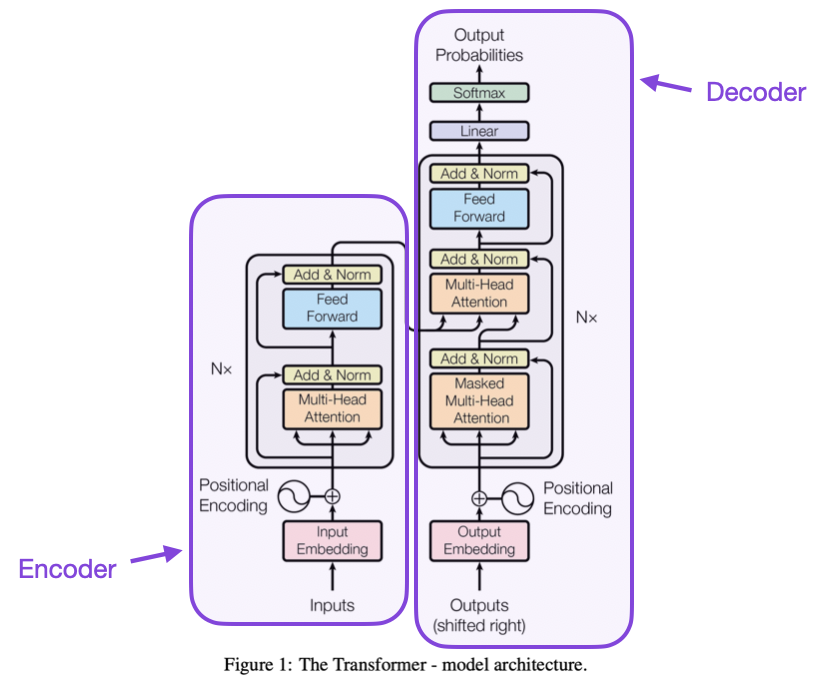
3. Transformer
-
能平行化运算(加快训练速度)
-
擅长捕捉长距离关系
-
核心:使用Self-Attention机制,同时考虑整句话的所有词。
-
优点:
- 搭配Positional Encoding,补足模型对「词序」的理解。
- Transformer 是现代LLM 的大大基石。
LLM 是什么?
LLM,全名为Large Language Model(大型语言模型),是基于Transformer 架构、使用巨量文字资料训练而成的模型。
不过,它的核心任务仍然是:「预测下一个词」
这项看似简单的任务,却演变成如今非常非常强大的语言模型能力🤯
LLM 的几个关键要素
1. 巨量参数(Parameters)
- 模型规模从几百万个参数(RNN 时代)提升至数千亿个参数(GPT-5、Claude、Gemini 等)。
- 每个参数都代表模型对语言的一种「微小的理解」。
2. 庞大训练资料(Data)
-
来源包括:维基百科、书籍、网页、对话、程式码等。
-
目标是让模型学会语言规则、语意关系、常识知识。
3. 强大的运算资源(Compute)
- 利用GPU/TPU 进行数周甚至数月的训练。
LLM 的核心理念
虽然LLM 是「语言模型」,但它其实学到的不只是文字的规则。
在预测下一个词的过程中,模型同时学会了:
语法结构:知道句子怎么组成
语意关联:理解不同词之间的语意距离
世界知识:从大量文本中归纳出事实与常识
推理能力:能在上下文中做出逻辑推断
LLM 的强项与限制
理解能力:LLM 能够处理复杂的语意与上下文,但是有时候还是会误解指令,像是我之前在请LLM 帮我产出一段程式码的时候,它说的跟它做的东西就是不一样,甚至一直鬼打墙😤。我相信大家应该多多少少都有遇过类似的情形…
幻觉😵💫:LLM 虽然说有强大的能力,我们有想问的东西就会拿去给LLM 解答,但是有一点要注意的是LLM 可能会有Hallucination(幻觉)… 听起来很神秘吼,但其实这个幻觉就是在说LLM 可能会产出与事实不符的文字资讯。
- 为什么会有这样的情况发生呢? ➔ 因为LLM 基本上是从海量的资料在学习文字的规律,并根据学习到的东西,依据机率来去预测下个字,也就是说,它并不是在学「正确」的东西,而只是从被喂进去的东西当中再找出规律性而已
- 总而言之,很多人会以为LLM 提供的回答都是正确的,但是其实不尽然,因此这是要特别注意的地方哦~
非即时资料:一般来说,在训练模型的资料并不会是即时更新的,它都是有一定的时间限制,因此若不搭配网页搜寻的功能,很有可能得到的资讯就会不是最新的
LLM 的相关应用
LLM 不只是单一模型,而是整个AI 生态链的核心。
以下为环绕LLM 的一些应用与技术,包括:
- Chain-of-Thought(CoT):让模型「逐步推理」。
- RAG(Retrieval-Augmented Generation):让模型「查资料再回答」。
- Ollama:让使用者在本地执行开源模型,兼顾隐私与可控性。其实还有很多很多的技术,这边就举这些为例。
相关内容资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)