一文理清强化学习(RL)基本原理 (DQN、PPO、GRPO)
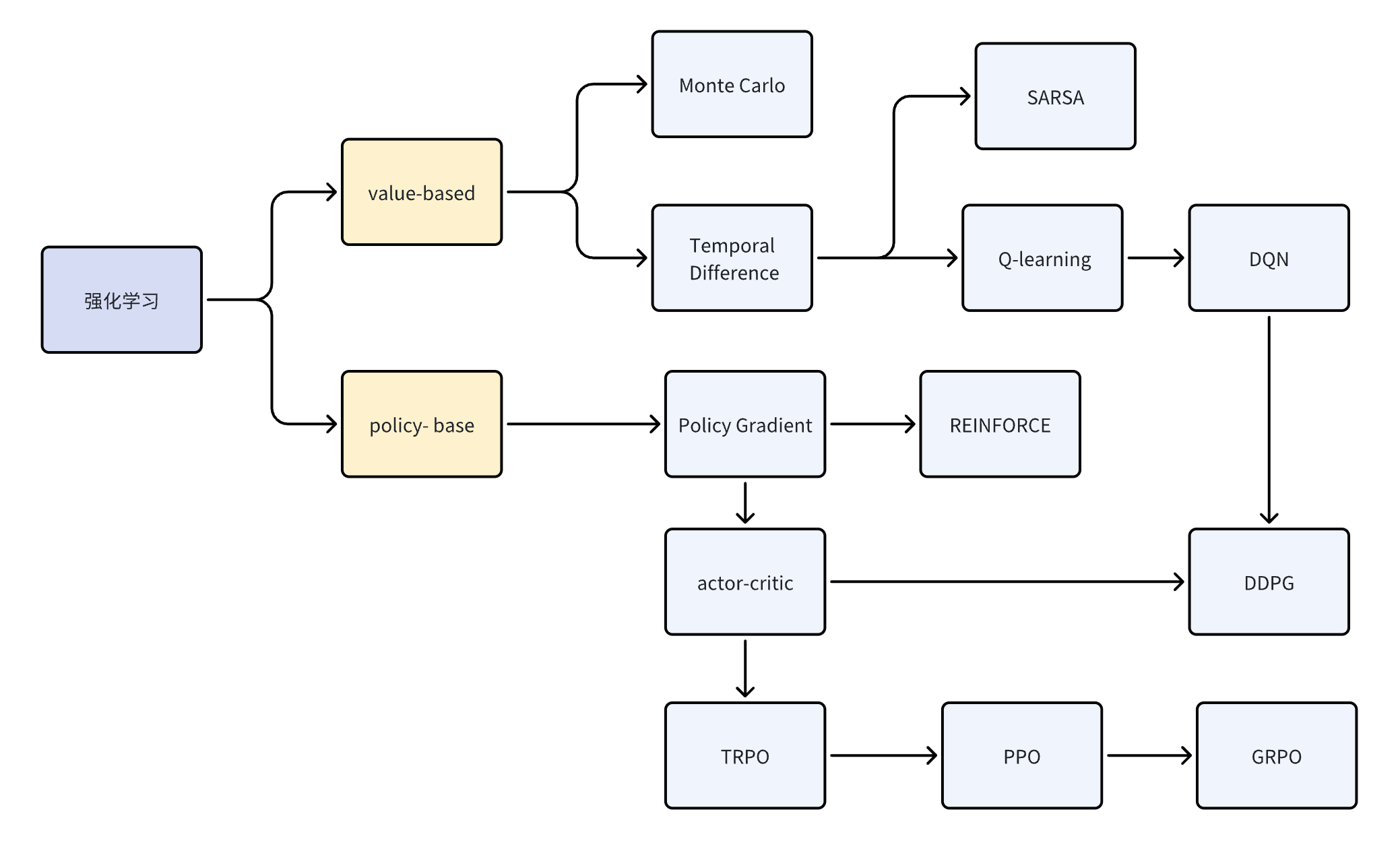
类别核心思想代表算法基于值学 Q 值函数基于策略直接优化策略二者结合模型化RL学习环境模型进阶RL多智能体、元学习、自博弈强化学习是一个让机器学会“如何行动”的学问。它的核心是通过试错与奖励信号优化策略,以实现长期收益最大化。
强化学习算法概括图
🧠 一文理清强化学习(RL)基本原理 —— 从直觉到公式的系统讲解
“如果监督学习是模仿老师,强化学习就是摸索世界。”
—— Richard Sutton,《Reinforcement Learning: An Introduction》
强化学习(Reinforcement Learning, RL)是人工智能中最接近“智能本质”的领域之一。它不是简单地拟合输入输出,而是让一个智能体(agent)在与环境的交互中,通过试错学习最优行为策略。
这也是 AlphaGo、自动驾驶、机器人控制和智能推荐的核心算法思想。
本文将系统讲清楚 RL 的全景逻辑,从直觉出发,逐步深入数理原理与算法框架。
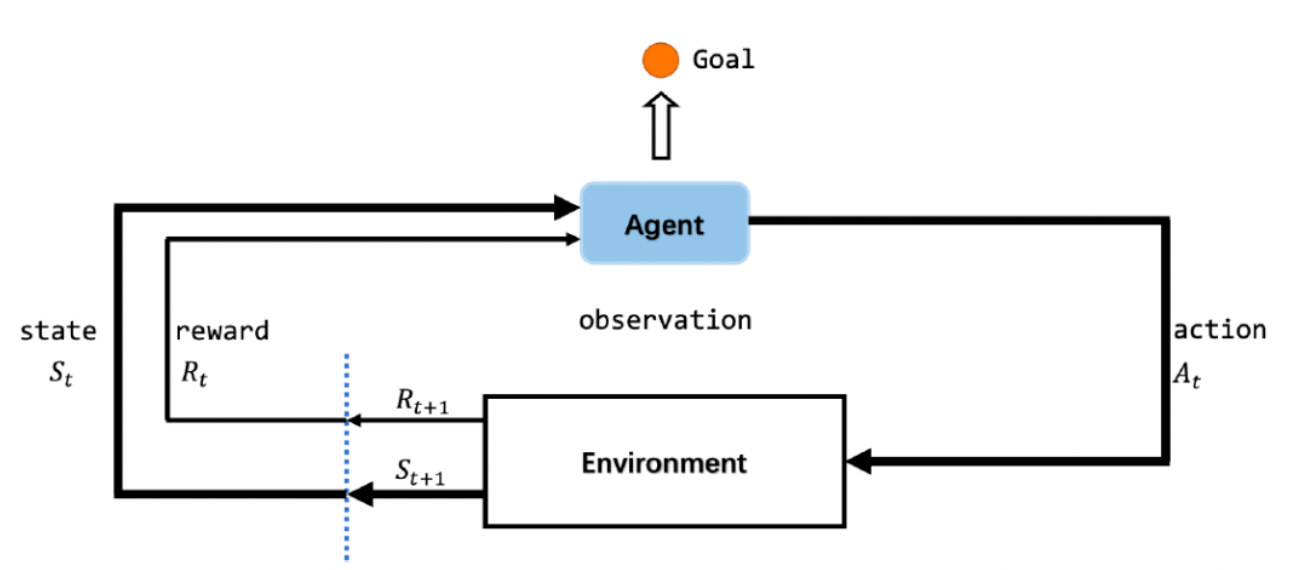
🌍 一、强化学习的故事:智能体与环境
你可以把强化学习想象成这样一个游戏:
智能体(agent)置身于一个环境(environment)中。
它根据所处的状态(state)选择一个动作(action),
环境随即给予它一个奖励(reward)并转移到新的状态。
智能体的目标是让自己的长期总奖励最大化。
这就像人类的日常学习过程:
- 孩子学习走路:摔倒(负奖励),走稳(正奖励);
- 围棋AI:赢棋(正奖励),输棋(负奖励);
- 自动驾驶:安全通过路口(正奖励),撞到障碍(负奖励)。
强化学习研究的就是:
如何让智能体在不确定的环境中,通过不断交互和反馈,学到最优策略(optimal policy)。
🧩 二、强化学习的五要素(MDP)
强化学习的理论框架通常用**马尔可夫决策过程(MDP, Markov Decision Process)**来描述。
一个 MDP 包含五个核心组成部分:
| 元素 | 符号 | 含义 | |
|---|---|---|---|
| 状态 | S S S | 环境的可能状态集合 | |
| 动作 | A A A | 智能体可执行的动作集合 | |
| 奖励函数 | R ( s , a ) R(s,a) R(s,a) | 执行动作后环境返回的即时回报 | |
| 状态转移概率 | P ( s ′ ∣ s , a ) P(s' | s,a) P(s′∣s,a) | 执行动作后环境转移到新状态的概率 | |
| 策略 | π ( a ∣ s ) \pi(a | s) π(a∣s) | 智能体在状态下选择动作的规则 |
“马尔可夫”意味着:未来的状态只取决于当前状态和动作,而与过去的历史无关。
例子:
假设一个小车在轨道上移动,状态是它的位置和速度,动作是“加速”或“减速”,奖励是“离目标越近奖励越高”,这就是一个 MDP。
🎯 三、强化学习的目标:最大化期望回报
智能体的目标不是追求一次奖励最大,而是希望长期收益最大。
因此定义折扣回报(discounted return):
G t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ G_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots Gt=rt+γrt+1+γ2rt+2+⋯
其中 γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1] 是折扣因子(discount factor),代表未来奖励的重要程度。
若 γ = 0.9 \gamma = 0.9 γ=0.9,说明未来的奖励会被略微折扣,但仍有较大影响。
强化学习的优化目标是:
J ( π ) = E π [ G t ] J(\pi) = \mathbb{E}_\pi[G_t] J(π)=Eπ[Gt]
也就是寻找最优策略:
π ∗ = arg max π J ( π ) \pi^* = \arg\max_\pi J(\pi) π∗=argπmaxJ(π)
🧭 四、值函数(Value Function)与Q函数(Action Value Function)
强化学习的关键思想是“评价行为好坏”,状态价值函数和动作价值函数的概念非常重要,这是所有强化学习算法设计优化的对象。
强化学习中定义了两种值函数,在一个给定策略 π ( a ∣ s ) \pi(a|s) π(a∣s)下:
状态价值函数(State Value Function)
V π ( s ) = E π [ ∑ t = 0 ∞ γ t r ( s t , a t ) ∣ s 0 = s ] V^\pi(s) = \mathbb{E}_\pi\Big[\sum_{t=0}^{\infty} \gamma^t r(s_t,a_t)\ \Big|\ s_0 = s\Big] Vπ(s)=Eπ[t=0∑∞γtr(st,at) s0=s]
表示:从状态 s s s出发,按策略 π \pi π 行动所能获得的期望总折扣回报。
动作价值函数(Action Value Function)
Q π ( s , a ) = E π [ ∑ t = 0 ∞ γ t r ( s t , a t ) ∣ s 0 = s , a 0 = a ] Q^\pi(s,a) = \mathbb{E}_\pi\Big[\sum_{t=0}^{\infty} \gamma^t r(s_t,a_t)\ \Big|\ s_0 = s, a_0 = a\Big] Qπ(s,a)=Eπ[t=0∑∞γtr(st,at)
s0=s,a0=a]
表示:从状态 s s s 出发,先执行动作 a a a,然后再按策略 π \pi π 行动所能获得的期望总折扣回报。
这两个函数通过 策略 π \pi π的期望直接联系起来:
V π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ Q π ( s , a ) ] = ∑ a π ( a ∣ s ) Q π ( s , a ) \boxed{V^\pi(s) = \mathbb{E}_{a\sim\pi(\cdot|s)}[Q^\pi(s,a)] = \sum_a \pi(a|s) Q^\pi(s,a)} Vπ(s)=Ea∼π(⋅∣s)[Qπ(s,a)]=a∑π(a∣s)Qπ(s,a)
也就是说,状态价值是对该状态下所有动作价值的加权平均,权重是策略在该状态下选择各动作的概率。
求解强化学习问题可分为基于价值的方法和基于策略的方法,基于价值的方法核心是基于贝尔曼方程求价值函数(状态价值函数 V V V或动作价值函数 Q Q Q),再基于价值函数推出策略 π \pi π。
- 贝尔曼方程定义:也称为贝尔曼期望方程,定义了状态之间的递归关系,用于计算价值函数(包含状态价值函数 V V V和动作价值函数 Q Q Q)在给定策略下采样轨迹上的期望。
- 马尔可夫奖励过程的贝尔曼方程(状态价值函数 V V V):
V ( s ) = R ( s ) + γ ∑ s ′ ∈ S p ( s ′ ∣ s ) V ( s ′ ) V(s) = R(s) + \gamma \sum_{s' \in S} p(s'|s)V(s') V(s)=R(s)+γs′∈S∑p(s′∣s)V(s′)
其中, R ( s ) R(s) R(s)是当前状态 s s s下的即时奖励, s ′ s' s′是未来状态, p ( s ′ ∣ s ) p(s'|s) p(s′∣s)是从状态 s s s转移到 s ′ s' s′的概率, γ \gamma γ是折扣因子。 - 马尔可夫决策过程的贝尔曼方程:
- 状态价值函数 V V V:
V π ( s ) = E π [ R ( s , a ) + γ V π ( s t + 1 ) ∣ s t = s ] V_{\pi}(s) = \mathbb{E}_{\pi}[R(s, a) + \gamma V_{\pi}(s_{t+1})|s_t = s] Vπ(s)=Eπ[R(s,a)+γVπ(st+1)∣st=s] - 动作价值函数 Q Q Q:
Q π ( s , a ) = E π [ R ( s , a ) + γ Q π ( s t + 1 , a t + 1 ) ∣ s t = s , a t = a ] Q_{\pi}(s, a) = \mathbb{E}_{\pi}[R(s, a) + \gamma Q_{\pi}(s_{t+1}, a_{t+1})|s_t = s, a_t = a] Qπ(s,a)=Eπ[R(s,a)+γQπ(st+1,at+1)∣st=s,at=a]
- 状态价值函数 V V V:
- 核心意义:表示当前状态与未来状态的迭代关系,当前状态的价值函数可通过下个状态的价值函数计算。由动态规划创始人理查德·贝尔曼提出,也叫动态规划方程。
⚙️ 五、RL算法家族树
强化学习算法众多,但核心可归为三大类:
基于价值学习的算法(Value-based)
基于值学习的目标是学习到一个Q函数,即最有动作价值函数,这个函数可以作为‘先知’去预测在未来的累积奖励期望。在 t t t时刻,Q函数预测那个动作能获得最大收益,因此如何让Q函数评估动作至关重要,Q函数的优化只要通过TD算法是它的核心。
目标:学习最优动作价值函数 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a),然后用它选最优动作。
代表算法:
- Q-learning(离线更新)
- SARSA(在线更新)
- Deep Q-Network (DQN) —— 用深度网络逼近 Q 函数
更新公式(Q-learning):
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a) \leftarrow Q(s,a) + \alpha [r + \gamma \max_{a'} Q(s',a') - Q(s,a)] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
这样可能不是很好理解,可以看下面的推导:
Q ( s t , a t , ; w ) ≈ r t + γ ⋅ max a ∈ A Q ( s t + 1 , a ; w ) Q(s_t,a_t,;w) \approx r_t + \gamma \cdot \max_{a \in \mathcal{A} } Q(s_{t+1},a;w) Q(st,at,;w)≈rt+γ⋅a∈AmaxQ(st+1,a;w)
左边表示当前Q函数在状态 s t s_t st的动作预估值,右边表示在状态 s s s,以及在 t t t时刻执行动作获得的奖励 r t r t rt。我们将左边部分视为 q q q,右边部分视为 y y y。它们两者都是在 t t t时刻对动作价值的估计。由于右边是基于部分事实,即 t t t时刻的奖励进行估计的,因此右边的估计会更加准确。我们需要让左边的估计靠近右边。定义损失函数:
L ( w ) = 1 2 [ q − y ] 2 \mathcal{L}(w) = \frac{1}{2}[q-y]^2 L(w)=21[q−y]2
假设y是常数,计算L关于w的梯度:
∇ w L ( w ) = ( q − y ) ⋅ ∇ w Q ( s t , a t ; w ) \nabla_w \mathcal{L}(w) = (q-y)\cdot \nabla_w Q(s_t,a_t;w) ∇wL(w)=(q−y)⋅∇wQ(st,at;w)
做一步梯度下降,可以让 q q q更加接近 y y y:
w ← w − α ⋅ δ t ⋅ ∇ w Q ( s t , a t ; w ) w \gets w - \alpha \cdot \delta_t \cdot \nabla_w Q(s_t,a_t;w) w←w−α⋅δt⋅∇wQ(st,at;w)
上面就是训练DQN的TD算法。
Q-learning 让智能体通过不断试探获得最优动作价值表。
DQN 则把传统表格替换为神经网络,实现从像素图像到动作的端到端决策。
基于策略学习的算法(Policy-based)
策略梯度定理
如果一个策略很好,那么对应的状态价值 V π ( S ) V_\pi(S) Vπ(S)的均值应该很大,因此我们可以定义目标函数:
J ( π θ ) = E S [ V π ( S ) ] J(\pi_\theta) = \mathbb{E}_{\mathcal{S}} [V_{\pi}(S)] J(πθ)=ES[Vπ(S)]
这个目标函数排除了状态 S S S的因素,只依赖于策略网络 π \pi π的参数 θ \theta θ,即策略越好,则 π θ \pi_\theta πθ越大,所以策略学习可以描述为这样一个优化问题:
max θ J ( π θ ) \max_\theta J(\pi_\theta) θmaxJ(πθ)
策略梯度定理证明:
∇ θ J ( θ ) = E S [ E A ∼ π ( ⋅ ∣ S ; θ ) [ Q π ( S , A ) ∗ ] ∇ θ I n π ( A ∣ S ; θ ) ] \nabla_\theta J(\theta)=\mathbb{E}_S[ \mathbb{E}_{A\sim \pi(\cdot | S; \theta )} [Q_\pi(S,A)*] \nabla_\theta In \pi(A|S;\theta ) ] ∇θJ(θ)=ES[EA∼π(⋅∣S;θ)[Qπ(S,A)∗]∇θInπ(A∣S;θ)]
策略梯度关键在于如何固定动作价值函数 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a)。
代表算法:
- REINFORCE(最基础的策略梯度,其实就是用蒙特卡洛方法近似 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a))
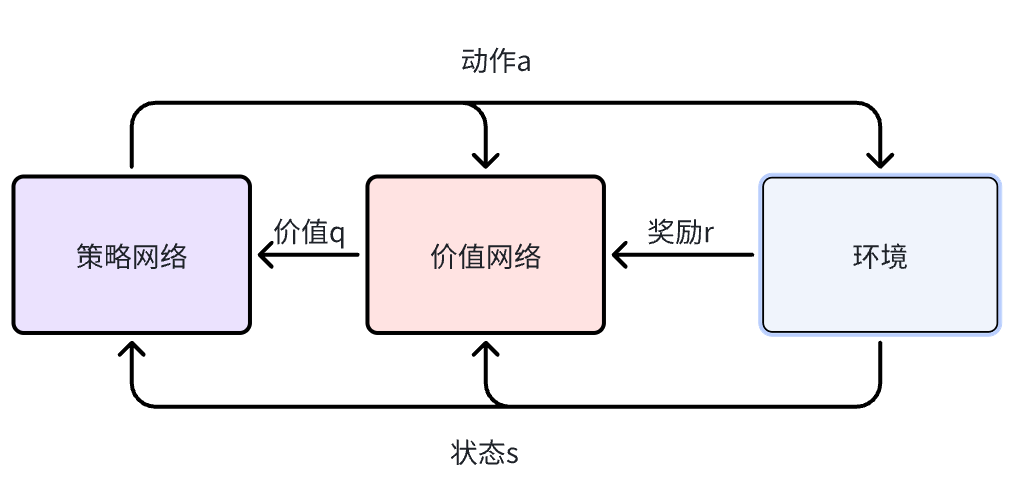
- Actor-Critic (用价值网络(神经网络)近似 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a))
Actor-Critic算法
PPO与GRPO以大模型训练为例
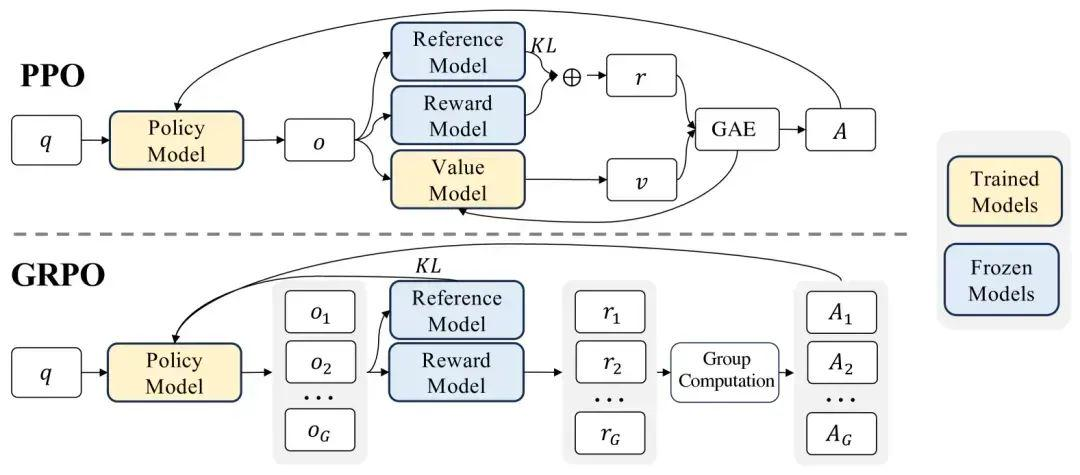
【DeepSeek】一文详解GRPO算法——为什么能减少大模型训练资源
在掌握了强化学习的基本概念之后,我们将深入探讨PPO算法与大语言模型相结合的详细内容。为了更好地抓住关键概念,我们的讲解会采用自顶向下的形式。首先记住RLHF中的PPO算法由4个核心模型和两个损失函数组成,这4个模型分别如下。
- 演员模型(actor model)。演员模型的参数来源于RLHF过程中的第一步提前准备好的监督微调模型。该模型不仅参与训练,也是PPO过程中需要进行对齐的语言模型,它是我们强化学习训练的主要目标和最终输出。该模型被训练用来)对齐人类偏好的模型,也被称为"策略模型"(policy model)。
- 评论家模型(critic model)。评论家模型的参数来源于先前训练好的奖励模型。模型参数参与反向传播,用来预测生成回复的未来累积奖励。以上两个模型都参与训练,其参数会发生梯度的反向传播。
下面两个模型虽然不直接参与反向传播,但在PPO训练过程中具有特定的作用。
- 参考模型(referencemodel)。参考模型的参数来源于RLHF过程中的第一步的监督微调
模型的备份参数。参考模型的参数在训练过程中不会发生变化,它的主要作用是帮助演
员模型在训练中避免过于极端的变化。 - 奖励模型(reward model)。奖励模型的参数来源于RLHF过程中的第一步提前训练好的
奖励模型。奖励模型的参数在训练过程中不会发生变化,它的主要功能是输出奖励分数
来评估回复质量的好坏。
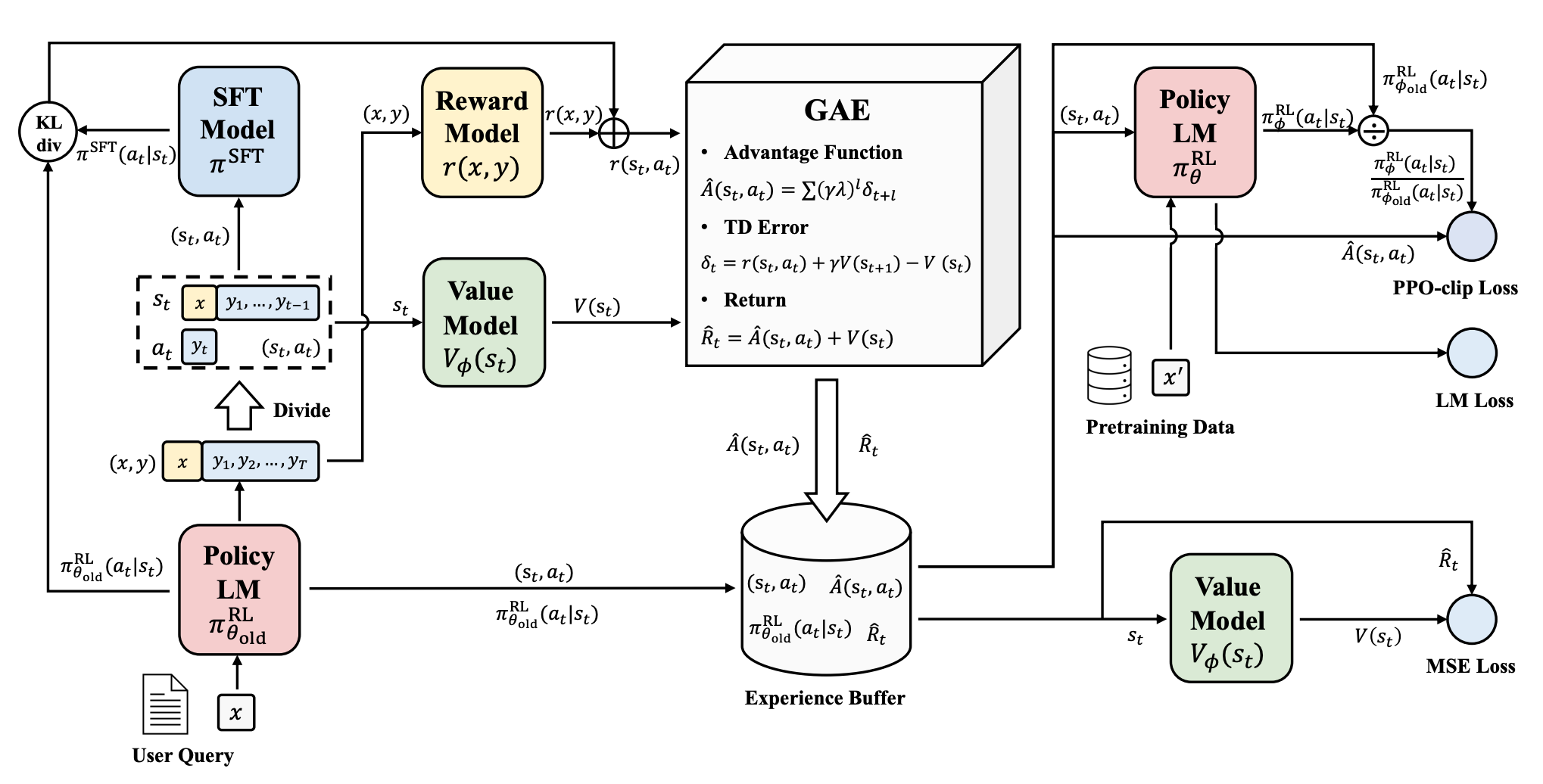
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , clip ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A t ] \begin{array}{l} \left.\mathcal{J}_{P P O}(\theta)=\mathbb{E}_{\left[q \sim P(Q), o \sim \pi_{\theta_{o l d}}\right.}(O \mid q)\right] \frac{1}{|o|} \sum_{t=1}^{|o|} \\ \min \left[\frac{\pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_{t} \mid q, o_{<t}\right)} A_{t}, \operatorname{clip}\left(\frac{\pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_{t} \mid q, o_{<t}\right)}, 1-\varepsilon, 1+\varepsilon\right) A_{t}\right] \end{array} JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1∑t=1∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At]
L G R P O ( θ ) = − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ [ min ( π θ ( o i , t ∣ q , o i , < t ) π θ old ( o i , t ∣ q , o i , < t ) A ^ i , t , clip ( π θ ( o i , t ∣ q , o i , < t ) π θ old ( o i , t ∣ q , o i , < t ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) − β D K L [ π θ ∥ π ref ] ] \begin{array}{l} \mathcal{L}_{\mathrm{GRPO}}(\theta)=-\frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|o_{i}\right|} \\ \sum_{t=1}^{\left|o_{i}\right|}\left[\min \left(\frac{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(o_{i, t} \mid q, o_{i,<t}\right)} \hat{A}_{i, t}, \operatorname{clip}\left(\frac{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{\text {old }}}\left(o_{i, t} \mid q, o_{i,<t}\right)}, 1-\epsilon, 1+\epsilon\right) \hat{A}_{i, t}\right)-\beta \mathbb{D}_{\mathrm{KL}}\left[\pi_{\theta} \| \pi_{\text {ref }}\right]\right] \end{array} LGRPO(θ)=−G1∑i=1G∣oi∣1∑t=1∣oi∣[min(πθold (oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold (oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ϵ,1+ϵ)A^i,t)−βDKL[πθ∥πref ]]
Advantage(优势函数) 介绍
基本定义
在强化学习中,智能体(Agent)在状态 ( s ) 下采取动作 ( a ),会获得一个回报。我们常用以下几个函数来描述“好坏”:
| 名称 | 符号 | 含义 |
|---|---|---|
| 状态价值函数 | V ( s ) V(s) V(s) | 在状态 s s s 下能获得的期望回报 |
| 动作价值函数 | Q ( s , a ) Q(s, a) Q(s,a) | 在状态 s s s 下采取动作 a a a 后的期望回报 |
| 优势函数 | A ( s , a ) A(s, a) A(s,a) | 动作 a a a 相对平均水平(即 V ( s ) V(s) V(s))的好坏差距 |
优势函数(Advantage Function)的数学定义是:
A ( s , a ) = Q ( s , a ) − V ( s ) A(s, a) = Q(s, a) - V(s) A(s,a)=Q(s,a)−V(s)
其中, Q ( s , a ) Q(s, a) Q(s,a)表示当前动作带来的具体收益; V ( s ) V(s) V(s):在该状态下平均水平的收益;差值 A ( s , a ) A(s,a) A(s,a):表示该动作比平均水平好多少,如果:( A ( s , a ) A(s,a) A(s,a) > 0 ):说明动作 a a a比平均表现更好,策略应该更倾向于选择这个动作;( A ( s , a ) A(s,a) A(s,a) < 0 ):说明动作 a a a比平均表现更差,策略应该减少选择这个动作的概率。
🧠 六、探索与利用的平衡(Exploration vs Exploitation)
强化学习面临的核心困境是:
是去探索未知(exploration),还是利用已有经验(exploitation)?
- 如果只利用当前最优动作,可能陷入局部最优;
- 如果过度探索,学习效率低下。
常见的平衡策略有:
- ε-greedy:以 ε 的概率随机动作;
- Softmax 策略:按 Q 值概率分布选择动作;
- UCB / Thompson Sampling:用于Bandit问题中的平衡;
- 噪声注入(Ornstein–Uhlenbeck / Gaussian):用于连续动作。
探索–利用平衡是 RL 成败的关键之一。
🧩 七、强化学习的关键难点
虽然 RL 很酷,但实际训练却“反人类”地困难:
| 难点 | 说明 |
|---|---|
| 样本效率低 | 需要大量交互数据(比监督学习高几个数量级) |
| 奖励稀疏 | 很多任务(如迷宫)只有终点才有奖励 |
| 不稳定 | 训练中容易发散(特别是深度网络) |
| 泛化性差 | 在未见过的环境中策略失效 |
| 信号延迟 | 奖励往往不是立即可见的(credit assignment) |
这些问题促使研究者发展出如 奖励塑形、经验回放、迁移学习、多智能体RL、元强化学习(Meta-RL) 等方向。
🚀 八、强化学习的典型应用领域
| 领域 | 应用示例 |
|---|---|
| 游戏智能 | AlphaGo、AlphaStar、Atari 智能体 |
| 机器人控制 | 机械臂、无人机、四足机器人行走 |
| 自动驾驶 | 动态路径规划、车道决策 |
| 推荐系统 | 动态用户建模与长期收益最大化 |
| 金融交易 | 强化交易策略、风险控制 |
| 智能调度 | 云计算任务调度、5G资源分配 |
| 医疗决策 | 药物剂量调节、治疗方案优化 |
📚 九、强化学习的发展脉络(时间线)
| 年份 | 里程碑 | 说明 |
|---|---|---|
| 1952 | Samuel’s Checkers | 最早的自学习程序 |
| 1989 | Q-learning 提出 | RL的奠基算法 |
| 2013 | DeepMind DQN | 深度学习 + RL 的里程碑 |
| 2016 | AlphaGo | RL走入公众视野 |
| 2018 | PPO / SAC | 稳定高效的现代RL框架 |
| 2023+ | 模型化RL / 世界模型 | RL + 生成模型的新范式 |
🔍 十、强化学习的未来趋势
- 模型化强化学习(Model-based RL):通过学习环境动力学模型,提高样本效率。
- 多智能体强化学习(MARL):多个智能体协作或博弈,如自动车队、虚拟群体。
- 层次化RL(Hierarchical RL):分解复杂任务为子目标,提高可解释性。
- 世界模型(World Models):结合生成模型(VAE、Diffusion)模拟环境。
- 与大语言模型融合(LLM + RL):如 ChatGPT 中的 RLHF(强化学习人类反馈)。
🏁 总结:强化学习的全景图
| 类别 | 核心思想 | 代表算法 |
|---|---|---|
| 基于值 | 学 Q 值函数 | Q-learning, DQN |
| 基于策略 | 直接优化策略 | REINFORCE, PPO |
| Actor–Critic | 二者结合 | A3C, DDPG, TD3, SAC |
| 模型化RL | 学习环境模型 | MBPO, Dreamer |
| 进阶RL | 多智能体、元学习、自博弈 | AlphaStar, Meta-RL |
一句话总结:
强化学习是一个让机器学会“如何行动”的学问。它的核心是通过试错与奖励信号优化策略,以实现长期收益最大化。
📘 延伸阅读与资源推荐
- 《Reinforcement Learning: An Introduction》 — Sutton & Barto
- DeepMind 的 DQN、AlphaGo、AlphaStar 论文
- 强化学习原理图解
- 西湖大学 强化学习的数学原理
- 王树森 《深度强化学习》
- 贝尔曼方程

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)