RT-DETR训练自己的数据集+测.pt+转onnx+测.onnx(YOLO收录版)
模型文件(如 best.pt、last.pt)默认会保存在 runs/detect/trainXX/ 目录下,你可以运行以下命令查找最新训练的结果:ls -lt runs/detect/6、在ultralytics-main\ultralytics这个文件夹里,输入训练命令(可使用tail -f train.log查看训练日志)5、改数据集路径,复制一份这个coco.yaml然后重命名,改成自己数
参考:RT-DETR训练自己的数据集(从代码下载到实例测试)_rtdetr训练自己的数据集-CSDN博客k
以及RT-DETR推理详解及部署实现-CSDN博客后半部分
转onnx部分参考
ultralytics中rtdetr的.pt模型转onnx_rt-detr转onnx-CSDN博客
1、下载GitHub - ultralytics/ultralytics: Ultralytics YOLO11 🚀
或者GitCode - 全球开发者的开源社区,开源代码托管平台
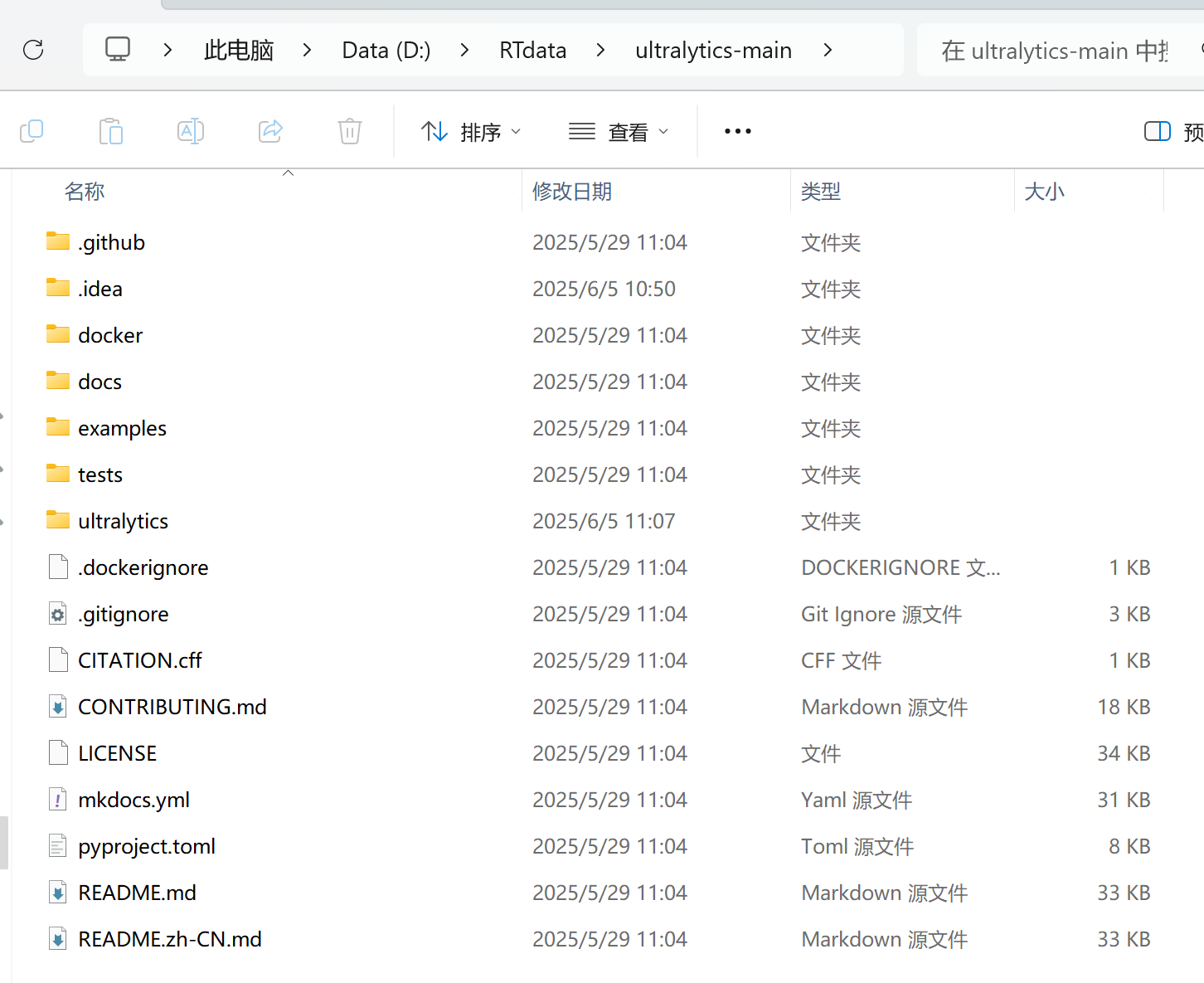
下载完解压,长这样
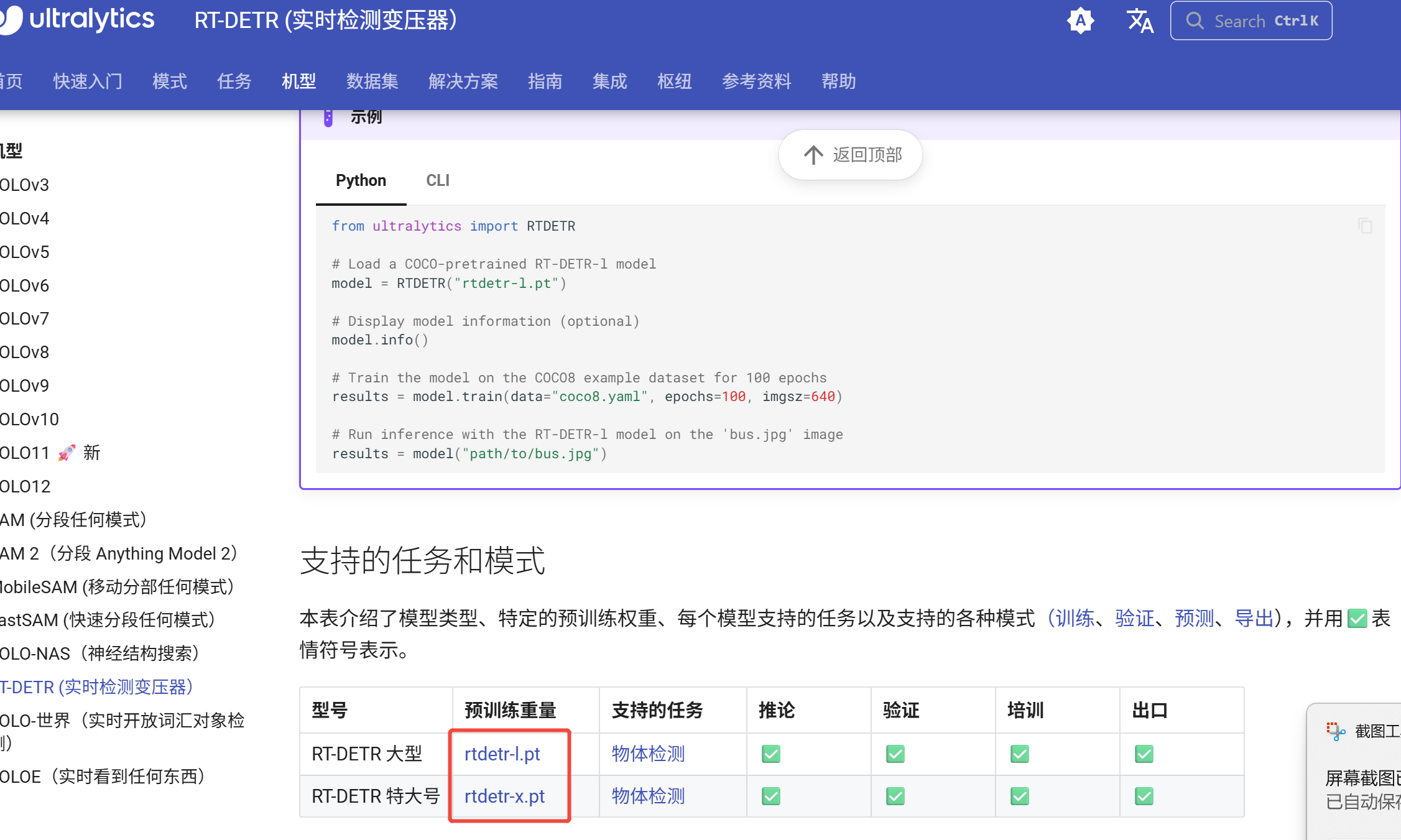
2、下载个预训练模型百度RT-DETR:基于视觉变换器的实时物体检测器
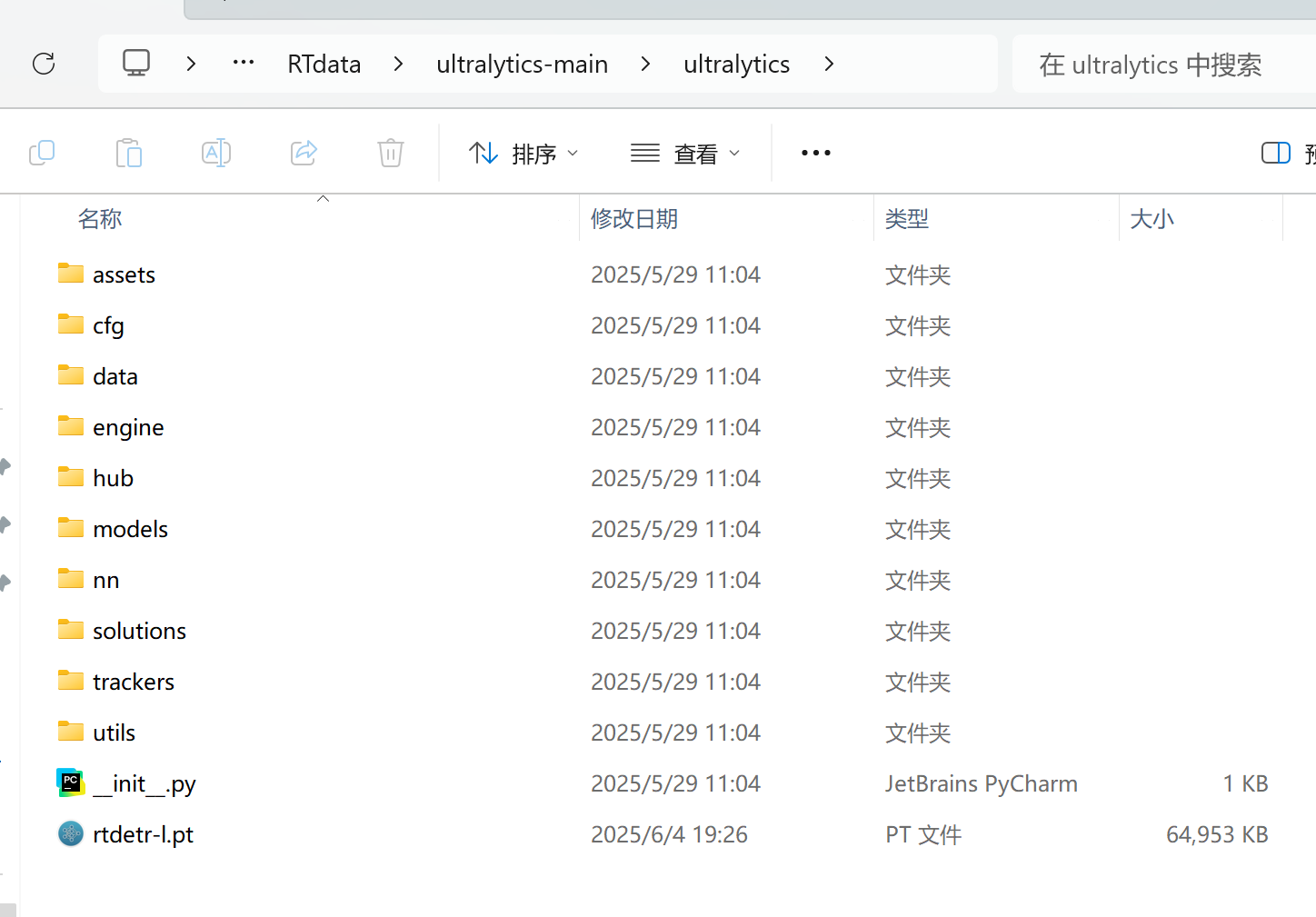
放在这个下面,我用的rtdetr-l.pt
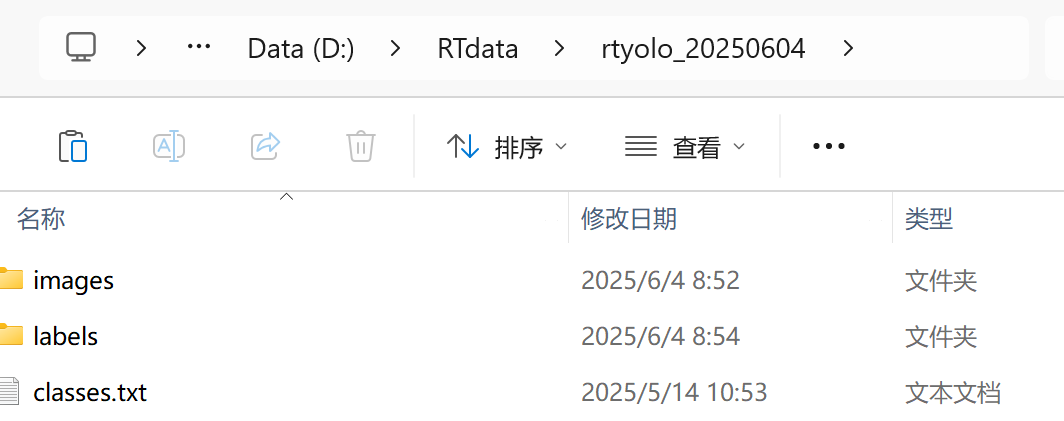
3、准备好yolo格式数据集
4、先改模型的配置文件,改下nc那个数字,我是yolo数据集标签0-6,所以改7
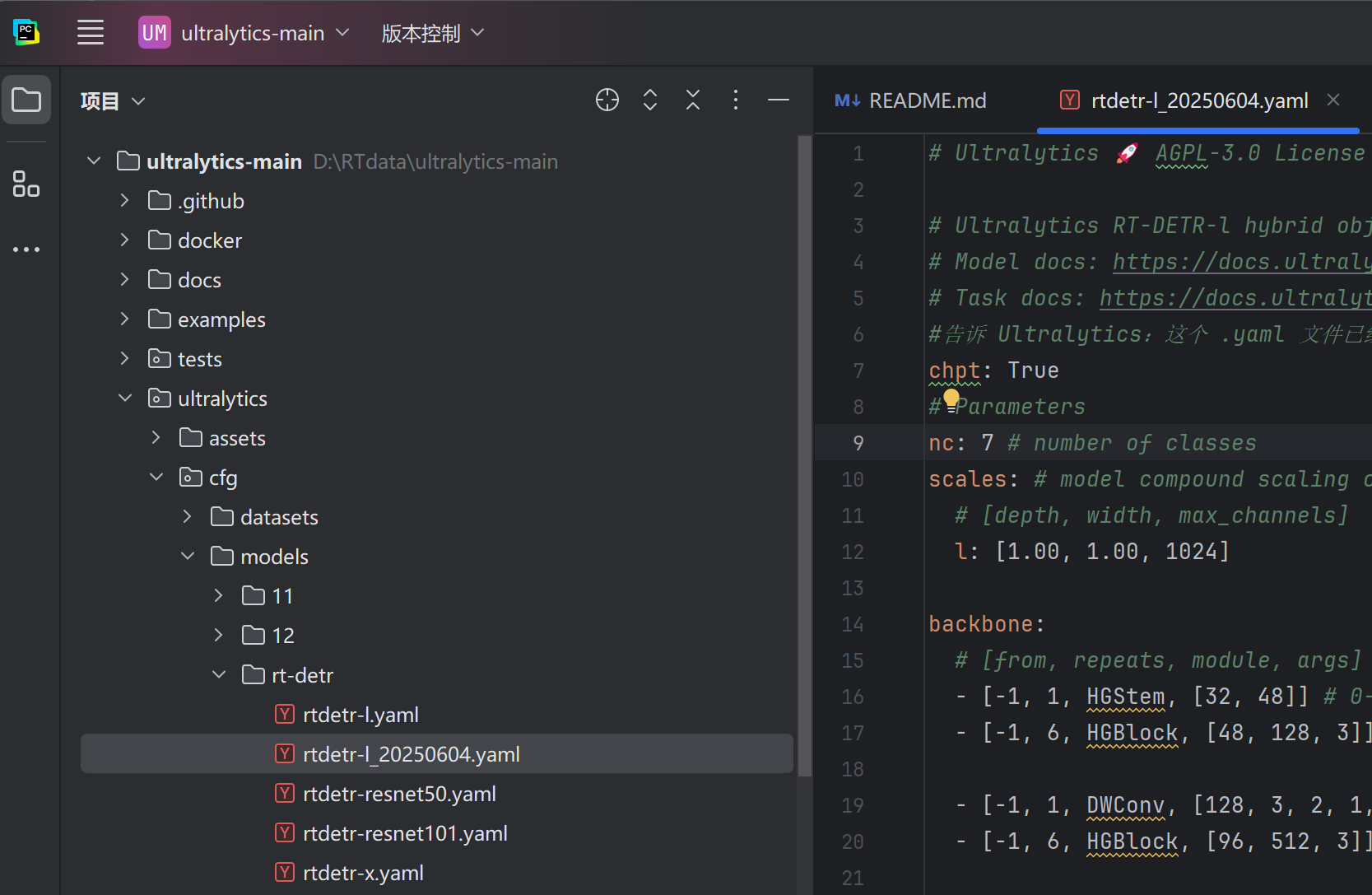
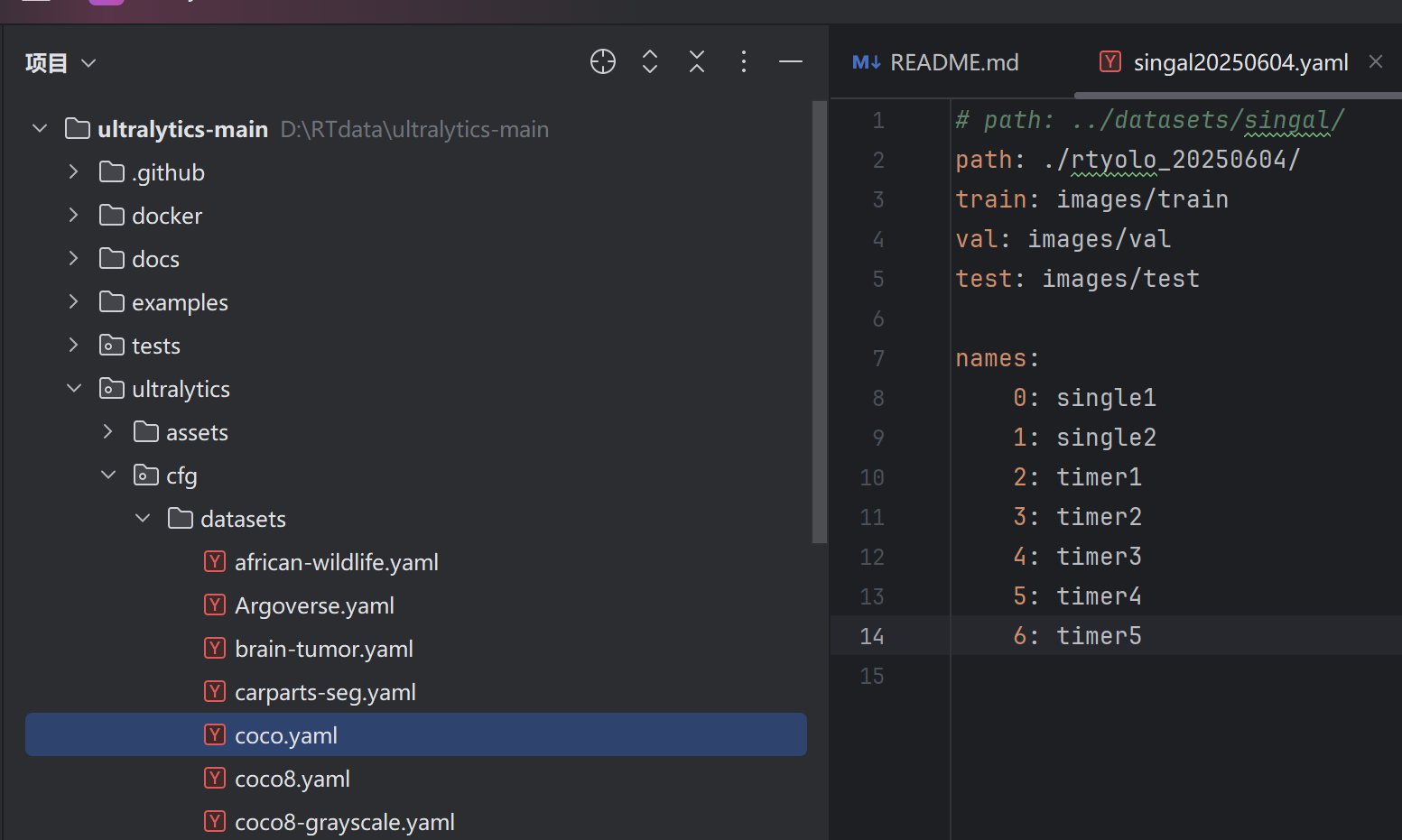
5、改数据集路径,复制一份这个coco.yaml然后重命名,改成自己数据集路径,和分类
6、在ultralytics-main\ultralytics这个文件夹里,输入训练命令(可使用tail -f train.log查看训练日志)
nohup yolo detect train \
model=./cfg/models/rt-detr/rtdetr-l_20250604.yaml \
pretrained=rtdetr-l.pt \
data=./cfg/datasets/singal20250604.yaml \
epochs=100 \
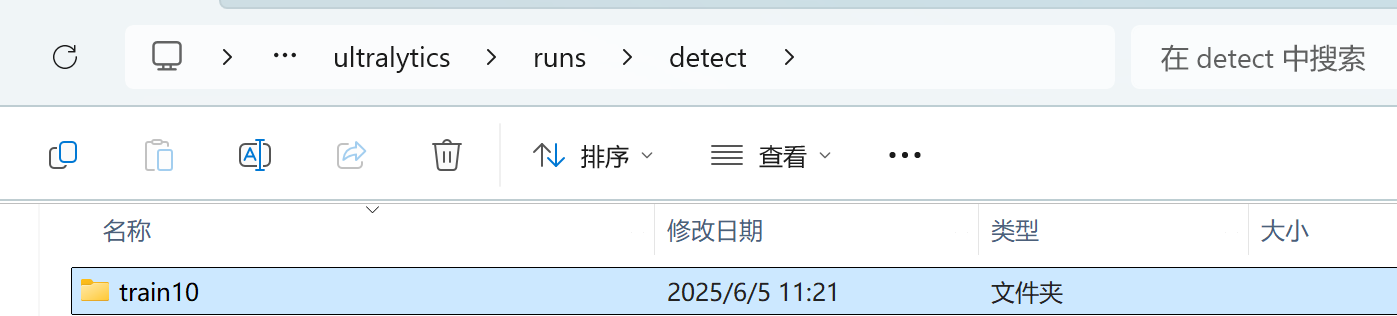
device=0 > train.log 2>&1 &7、训练结束。模型文件(如 best.pt、last.pt)默认会保存在 runs/detect/trainXX/ 目录下,你可以运行以下命令查找最新训练的结果:ls -lt runs/detect/,然后best.pt在ultralytics-main\ultralytics\runs\detect\train10\weights\best.pt这儿
8、验证best.pt效果。新建detect.py,内容在下方注意改.pt和测试图片路径,放这儿。再建一个images,里面放要测试的图片。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import RTDETR
if __name__ == '__main__':
model = RTDETR('runs/detect/train10/weights/best.pt')
model.predict(source='images',
imgsz=640,
device='0',
save=True
)
在ultralytics-main\ultralytics这个文件夹里,输入python detect.py即可
输出在ultralytics-main/ultralytics/runs/detect/predict里面,保存了测试结果的图片
9、转onnx,和yolo差不多,新建export.py放这儿,代码在下面,.pt路径要写对,然后python export
from ultralytics import RTDETR
#注意如果转的是yolo收录的RTDETR,这个地方一定要是RTDETR不能是YOLO
# 加载 RT-DETR 模型(路径根据你的实际情况填写)
model = RTDETR("ultralytics-main/ultralytics/runs/detect/train10/weights/best.pt")
# 导出为 ONNX 格式,启用动态输入
success = model.export(format="onnx", opset=17, dynamic=True)
print("ONNX模型导出成功" if success else "导出失败")
onnx生成的在ultralytics-main/ultralytics/runs/detect/train10/weights/best.onnx
10、测试onnx的效果。新建onnx_predict.py,代码在下面,修改best.onnx路径,及测试图片路径(刚刚测试用的那个images)
import os
import cv2
import numpy as np
import onnx
import onnxruntime as ort
# 加载 ONNX 模型
onnx_model_path = 'runs/detect/train10/weights/best.onnx'
onnx_model = onnx.load(onnx_model_path)
onnx.checker.check_model(onnx_model)
# 创建推理会话
ort_session = ort.InferenceSession(onnx_model_path)
# 获取输入信息
input_name = ort_session.get_inputs()[0].name
print("模型输入名称:", input_name)
# 图像文件夹路径
image_folder = "images"
output_folder = "runs/onnx_pred"
os.makedirs(output_folder, exist_ok=True)
# 置信度阈值
CONF_THRESHOLD = 0.5
# 遍历图像文件夹
for img_file in os.listdir(image_folder):
if not img_file.lower().endswith(('.png', '.jpg', '.jpeg')):
continue
print(f"Processing: {img_file}")
# 读取图像
img_path = os.path.join(image_folder, img_file)
img = cv2.imread(img_path)
orig_h, orig_w = img.shape[:2]
# 预处理(resize + 归一化 + CHW + float32)
resized_img = cv2.resize(img, (640, 640))
resized_img = cv2.cvtColor(resized_img, cv2.COLOR_BGR2RGB)
resized_img = resized_img / 255.0
resized_img = resized_img.transpose(2, 0, 1) # HWC -> CHW
input_data = np.expand_dims(resized_img.astype(np.float32), axis=0) # NCHW
# 推理
outputs = ort_session.run(None, {input_name: input_data})
# 输出结构分析
print("ONNX Output Shape:", outputs[0].shape)
print("ONNX Output Example (first row):", outputs[0][0])
# 解析输出(假设每个检测框结构是 [cx, cy, w, h, conf, class_scores...])
detections = outputs[0] # shape: (1, 300, 11)
boxes = detections[0, :, :4]
scores = detections[0, :, 4]
class_scores = detections[0, :, 5:]
# 筛选置信度大于阈值的目标
keep = scores > CONF_THRESHOLD
boxes = boxes[keep]
scores = scores[keep]
class_ids = np.argmax(class_scores[keep], axis=-1)
# 如果没有检测到目标
if len(boxes) == 0:
print("No detection")
continue
# 将 box 坐标还原到原图尺寸
scale_x = orig_w / 640
scale_y = orig_h / 640
for i, (cx, cy, w, h) in enumerate(boxes):
# 先还原到 640x640 图像上的像素坐标
cx_pixel = cx * 640
cy_pixel = cy * 640
w_pixel = w * 640
h_pixel = h * 640
# 再还原到原始图像尺寸
x1 = int((cx_pixel - w_pixel / 2) * scale_x)
y1 = int((cy_pixel - h_pixel / 2) * scale_y)
x2 = int((cx_pixel + w_pixel / 2) * scale_x)
y2 = int((cy_pixel + h_pixel / 2) * scale_y)
label = f"{class_ids[i]} {scores[i]:.2f}"
print(f"Detected: {label} at [{x1}, {y1}, {x2}, {y2}]")
# 绘制矩形框
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
# 保存结果
output_path = os.path.join(output_folder, img_file)
cv2.imwrite(output_path, img)
print(f"Saved to: {output_path}")在ultralytics-main\ultralytics这个文件夹里,输入python onnx_predict.py即可
输出在ultralytics-main/ultralytics/runs/onnx_pred里面,保存了测试结果的图片

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)