两个爆火的上下文解决方案-Mem0和MemOS分享
今天分享两个AI上下文解决方案:Mem0和MemOS,可以算是第三代上下文里面个人比较有体感的
·
今天分享两个AI上下文解决方案:Mem0和MemOS,可以算是第三代上下文里面个人比较有体感的
Mem0
是什么东西
国外提出的个性化AI交互助手,能记住偏好、不断学习。
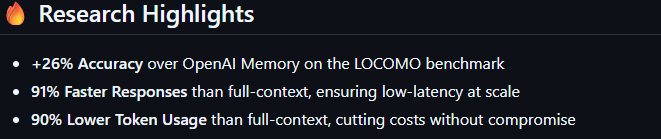
目前github start数量为43K,非常火热!已经有了自己的网站,并且送3个月免费使用。
需要注意:方案是大模型的一个插件,本身不提供大模型问答能力,需要手动触发对话历史的存储以及读取
为了解决什么问题以及如何解决
在方案出来之前对于历史会话可能是直接塞到上下文里面的,这会存在以下两个问题:
问题一:窗口中信息密度不够高,无用信息过多,有用信息没放进来
- 解决方案:
- ①利用大模型对每次会话进行总结,且给内容设置不同标签(20种)
- ②存储时,保存时间以及用户自定义的key-value结构metaInfo
- ③在检索时,支持按照标签、key-value等进行过滤后检索
问题二:对话轮次不断增多导致记录的维护成本高
- 解决方案:大模型自动判断本次的对话记录需要【增加/删除/更新】
接下来通过具体流程,更清晰的分享一下
- 用户和大模型对话完成得到messages
- 使用mem.add(messages,metaInfo,userId)触发存储
- 利用大模型:提取有用的信息facts
- 利用大模型:对比DB里面的fatcs和本次传入的facts,判断是新增、更新、删除
- 利用大模型:根据facts归类到20个标签中,得到tag
- 执行操作新增/更新/删除向量数据库,保存facts、metaInfo、tag等信息
- 下一次对话之前,使用mem.search(message,filter)进行搜索
- 使用filter中的规则(比如time<30天)对数据库的metaInfo进行过滤
- 对过滤结果进行向量召回
值得思考借鉴的点
- 用户的对话历史中是否有助于当前项目?
- 是否传递了足够的信息给大模型?
- 传递给大模型的信息信息密度够不够高?哪些是没有用的部分?能不能总结、过滤?
- 上下文的自动更新机制
项目资料
github地址:https://github.com/mem0ai/mem0
平台地址:https://app.mem0.ai
MemOS
是什么东西
国产,记忆张量(上海)科技有限公司牵头几个头部大学研发的上下文调度操作系统。
目前github star数量2.9k,整体项目尚未完全开放
为了解决什么问题以及如何解决
问题一:高频&重要的记忆每次都要读取,成本高
解决办法:三层记忆模型。类似于操作系统,数据从冷到热依次存于磁盘->内存->缓存。
- 记忆类型
- 明文记忆:每次需要时被读取放到大模型上下文里面
- 激活记忆:一些固定的话术,直接从字符串变成token传给大模型,可以减少每次转化的成本(这个是大模型调用时可以传入的一个参数,目前claude code是支持的,具体可以参考:https://spring.io/blog/2025/10/27/spring-ai-anthropic-prompt-caching-blog)
- 参数记忆:通过训练和微调将信息直接塞到大模型参数里面
- 记忆转化调度:周期触发,根据用户历史会话
- 利用llm判断历史会话和记忆的相似度(prompt判断)
- 利用llm提取会话历史关键词,计算关键词在记忆中的出现次数
- 看这个历史会话的引用次数
- 最终分数=相似度得分0.9+关键词得分0.05+引用次数得分*0.05
- 分数高的会被转化为激活记忆,在调用大模型时作为token参数传给大模型
参数记忆,好像目前还没开发完成…
值得思考借鉴的点
- 如果token耗费太多,或者查询速度很慢,可以考虑引入这种调度方法?
- 上下文可以根据不同维度去判断是否召回,根据相似度,根据标签拆分,根据关键词,根据使用频率…结合多个维度去做召回
项目资料
github地址:https://github.com/MemTensor/MemOS

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)