大模型相关概念
持续更新ing...
持续更新ing...
1. VLLM
是基于PyTorch开发的大模型推理引擎,由UC Berkeley团队提出,核心创新是PagedAttention技术。该技术通过将显存划分为固定大小的内存页(类似操作系统的虚拟内存管理),解决了传统KV Cache显存预分配导致的利用率低下问题(通常仅有20%-40%)。结合连续批处理(Continuous Batching)和多GPU并行,vLLM在高并发场景下的吞吐量可达其他框架的24倍。
这里参考:VLLM部署大模型,讲的比较清楚
2.RL
这两篇文章说的很清楚了
2.1 强化学习所解决的问题的特点:
- 智能体和环境之间不断进行交互;
- 搜索和试错;
- 延迟奖励(当前所做的动作可能很多步之后才会产生相应的结果)。
2.2 对于一个强化学习智能体,它可能有一个或多个如下的组成成分。
策略(policy)。智能体会用策略来选取下一步的动作。
价值函数(value function)。我们用价值函数来对当前状态进行评估。价值函数用于评估智能体进 入某个状态后,可以对后面的奖励带来多大的影响。价值函数值越大,说明智能体进入这个状态越有利。
模型(model)。模型表示智能体对环境的状态进行理解,它决定了环境中世界的运行方式。
3. 大模型训练
训练大语言模型(LLM)主要分为两个核心阶段:预训练(Pre-training)和后训练(Post-training)。这两个阶段共同构成了LLM从零到一的学习过程。
3.1 预训练
预训练是一种无监督学习方法,指在模型的初始阶段,使用大量数据对模型进行训练,以便让模型学习到通用的特征和知识。这些特征和知识可以是语言模型中的词嵌入,或者是图像识别模型中的视觉模式。通俗说就是在LLM能够生成连贯文本之前,它需要先掌握语言的基本规律。
3.1.1 数据收集与预处理
训练LLM的第一步是收集海量高质量的文本数据。目标是构建一个多样化且覆盖面广的数据集,以便模型能够学习到丰富的语言知识和上下文关系。
3.1.2 分词(Tokenization)
在神经网络能够处理文本之前,文本需要被转换为数值形式。这一转换过程称为分词(Tokenization)。分词的作用是将单词、子词或字符映射为唯一的数值token。这些token是语言模型的基本构建单元,是模型理解和处理语言的核心组件。
通过分词,文本被转化为模型可以理解的数值序列,为后续的模型训练和推理奠定了基础。
3.1.3 神经网络训练(Neural Network Training)
在文本经过分词处理后,神经网络的任务是学习如何根据上下文预测下一个token。具体来说,模型会接收一串输入token(例如“我正在烹饪”),并通过其复杂的数学结构——即模型的架构——进行处理,最终输出对下一个token的预测。
这一过程是LLM训练的核心。模型通过不断调整其内部参数,逐步学会从海量数据中捕捉语言规律,从而能够生成连贯且符合上下文的文本。
基础模型(Base Model):预训练的成果
3.2 后训练
正文大模型的后训练,也就是post-training,是指在预训练模型的基础上,针对特定的任务或数据集进行额外的训练。这个阶段通常包括Fine-tuning和RLHF等方法,通过调整预训练模型的参数以适应新的任务。
- 发生在预训练之后,模型部署前或部署初期。
- 针对特定的任务或数据集进行额外训练,以优化模型性能。
4. 监督学习
监督学习过程中,有两个假设:
-
输入的数据(标注的数据)都应是没有关联的。因为如果输入的数据有关联,学习器(learner)是不好学习的。
-
需要告诉学习器正确的标签是什么,这样它可以通过正确的标签来修正自己的预测。
监督微调(Supervised fine-tuning,简称SFT):微调是一种有监督学习方法,通过在有标签数据上对预训练模型进行进一步训练,以适应特定的任务。这个过程使得模型能够利用预训练阶段学到的通用知识,结合新数据的标签信息,使模型在特定任务上表现更好。
5. CoT(Chain of Thought,思维链)
传统的LLM训练流程是:预训练 → SFT → RL。然而,DeepSeek-R1-Zero跳过了SFT,允许模型直接探索思维链(CoT)推理。
CoT的作用
CoT使模型能够像人类一样,将复杂问题分解为中间步骤,从而增强推理能力。OpenAI的o1模型也利用了这一点,其2024年9月的报告指出:o1的表现随着更多RL训练和推理时间的增加而提升。
6. RLHF
过去几年里各种 LLM 根据人类输入提示 (prompt) 生成多样化文本的能力令人印象深刻。然而,对生成结果的评估是主观和依赖上下文的,例如,我们希望模型生成一个有创意的故事、一段真实的信息性文本,或者是可执行的代码片段,这些结果难以用现有的基于规则的文本生成指标 (如 BLEU 和 ROUGE) 来衡量。
RLHF 的理念是利用强化学习的方法,通过人类反馈直接优化语言模型。RLHF 使得语言模型能够开始将基于通用文本语料库训练的模型与理解复杂的人类价值观的模型相融合。
在RLHF中,人类的偏好被用作奖励信号,以指导模型的训练过程,从而增强模型对人类意图的理解和满足程度。这种方法使得模型能够更自然地与人类进行交互,并生成更符合人类期望的输出。
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,这里我们按三个步骤分解:
- 预训练一个语言模型 (LM) ;
- 聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
- 用强化学习 (RL) 方式微调 LM。
6.1 预训练语言模型
-
从一个大规模的、预训练好的基座语言模型开始(如GPT-3)。
-
这个模型可以作为RLHF的起点,有时会先用高质量的“更可取”的文本数据进行监督微调,但这并非RLHF的强制步骤。
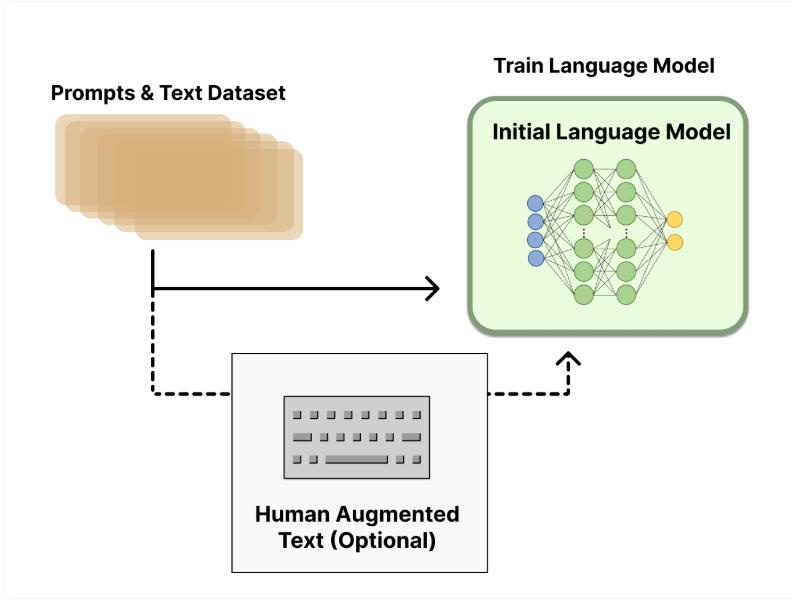
6.2 聚合问答数据并训练一个奖励模型 (Reward Model,RM)
-
RM 的训练是 RLHF 区别于旧范式的开端。这一模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好。
-
数据收集:使用初始LM生成对多个提示的不同回答,然后由人类标注员对这些回答进行排序(而非直接打分),以构建偏好数据集。
-
模型训练:训练一个独立的奖励模型,其任务是学习人类的偏好标准,并为LM生成的任何文本输出一个标量奖励值(分数越高,代表人类越喜欢)。
-
奖励模型通常比生成模型小,但需要具备足够的理解能力。
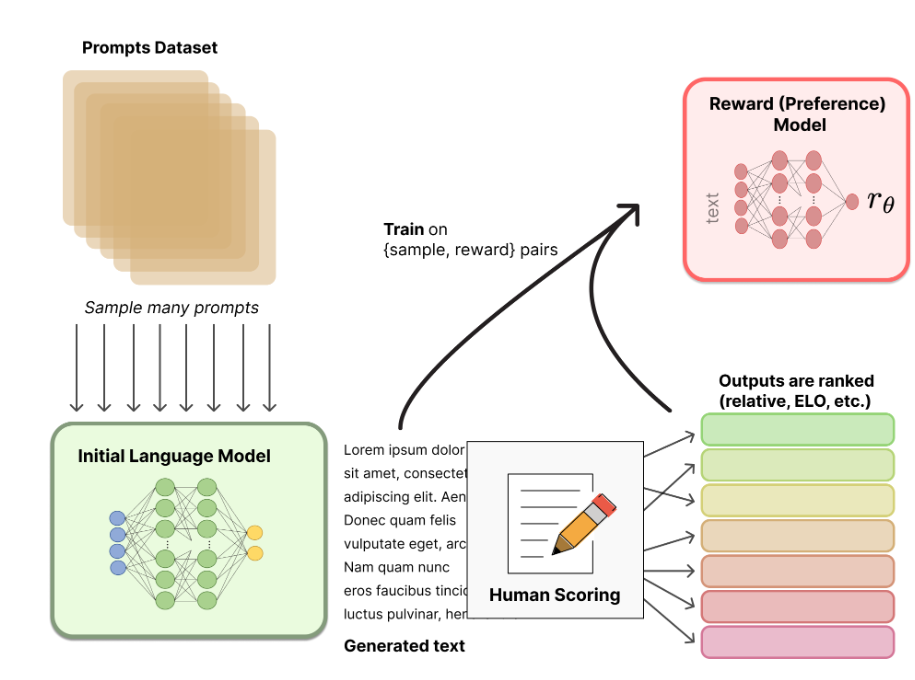
6.3 用强化学习 (RL) 方式微调 LM
-
将第一步的LM作为策略,第二步的RM作为奖励函数,构成一个强化学习环境。
-
使用近端策略优化算法来微调LM。
-
奖励函数设计:总奖励 = RM给出的奖励 - 一个KL散度惩罚项。
-
目的:鼓励LM生成能获得高奖励的文本,同时防止其过度“投机取巧”或偏离原始LM太远,从而生成无意义的乱码来“欺骗”RM。
-
-
这是一个动态过程,可以迭代进行:用更新后的LM生成新的回答,重新训练RM,再继续微调LM。
7. verl
目前比较主流的post-training框架包括LLaMA-Factory、trl和verl
可以把VErl看作是RLHF框架的一种“短路”或“端到端”的简化:
-
RLHF的路径:
人类偏好 -> 奖励模型 -> 强化学习信号 -> 模型更新 -
VErl的路径:
人类偏好 -> 强化学习信号 -> 模型更新
rollout 是一个强化学习专用词汇,指的是从一个特定的状态按照某个策略进行一些列动作和状态转移。
在 LLM 语境下,“某个策略”就是 actor model 的初始状态,“进行一些列动作”指的就是推理,即输入 prompt 输出 response 的过程。
GRPO训练流程可以参考这一篇 比较详细:
8. Hydra
Hydra是一个用来动态创建配置的python开源框架,使做研究和复杂的应用更便利,配置信息可以通过配置文件或者运行参数来覆盖。Hydra的名字来源于其可以运行多个相似任务,就像Hydra(九头蛇)有多个头一样。
在 Hydra(例如在 run_mmsearch_r1_grpo.sh 使用的配置系统)中:
@hydra.main(config_path='config', config_name='ppo_trainer', version_base=None)
def main(config):
run_ppo(config)
config.yaml会在你运行应用程序的时候自动加载。可以通过命令行输入的参数来对配置文件中的参数进行覆盖。
Hydra 配置规则说明
- 无前缀:
key=value- 覆盖已存在的配置 - 单个
+:+key=value- 添加新配置(如果已存在会报错) - 两个
++:++key=value- 强制添加或覆盖配置
9. PyTorch 并行机制的倾向性
在 PyTorch 的多 GPU 训练中,常见的四种并行方式是:
-
torch.nn.DataParallel(DP):单机多卡。-
这种模式会将完整的模型复制到每个 GPU 上。
-
主卡(默认是
cuda:0,即 GPU 0)会承担额外的负载:它不仅需要保存完整的模型,还需要汇总所有 GPU 的输出、计算损失、并负责梯度聚合和更新模型参数。 -
DataParallel 的模型和数据都是先加载到主卡上,再分发到其他卡。如果你的模型本身就非常大,在主卡上就会先占掉大量内存。
-
-
torch.nn.DistributedDataParallel(DDP):多机多卡-
这是 PyTorch 推荐的多卡训练方式。
-
每个 GPU 都是一个独立的进程,每个进程只管理自己那一份模型和数据。
-
内存和计算负载通常更加均衡。
-
-
FSDP (fully sharded data parallel)是 DDP 的一种更高级形式,它将模型参数、梯度和优化器状态分片到各个 GPU 上,是目前处理超大模型 OOM 最有效的方法之一,并且原生就是一种分布式 (DDP) 模式。
-
ZeRO1/2/3
ZeRO 是微软家 DeepSpeed 中的核心技术,思想和 FSDP 是相同,二者都是 通过分片消除模型冗余存储,扩大分布式并行训练能力,只不过 FSDP 是 PyTorch 的官方实现版。ZeRO(Zero Redundancy Optimizer)有三种策略:
ZeRO-1:只分片 优化器状态
ZeRO-2:分片 梯度 和 优化器状态 ,对应了 FSDP 的 SHARD_GRAD_OP 策略
ZeRO-3:分片 参数、梯度 和 优化器状态,对应了 FSDP 的 FULLY_SHARD 策略
10.RAY
Ray 最初由 UC Berkeley 的 RISELab 实验室开发,目标是解决“大规模异构机器学习任务的调度难题”,是一个开源的 分布式计算框架,让你可以轻松地将 Python 代码并行化和分布式运行.
ray核心模块组成:
Ray Client/API:为用户提供 Python API、Ray Dashboard 等交互入口。
Ray Core:Ray 的核心调度和分布式执行引擎,负责任务调度、资源管理、对象存储等。
Tune:用于超参数调优,支持各种搜索算法(如 Grid、Bayesian、PBT)。
Train:用于分布式训练,支持 PyTorch、TensorFlow,支持多机多卡。
Serve:用于模型部署,具备高可用性、低延迟特性,支持自动扩缩容与流量分发。
参考文章:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)