构建智能知识库问答助手:LangChain与大语言模型的深度融合实践
LangChain 框架提出了“**检索增强生成(Retrieval-Augmented Generation, RAG)**”的解决思路:通过整合外部知识库与语言模型,使模型能够实时检索并利用最新的知识内容,进而实现基于本地知识的问答能力。本文将详细介绍如何利用 LangChain 框架构建一个知识库问答助手,解析其工作原理、关键技术环节以及优势特点。
目录
前言
在人工智能迅猛发展的今天,大语言模型(Large Language Model,简称 LLM)已成为智能问答、文本生成与知识推理的重要技术基石。从 ChatGPT 到 Claude,再到各类国产语言模型,这些模型凭借强大的语言理解与生成能力,在众多领域展现出了非凡的潜力。然而,尽管 LLM 能回答多领域的通用问题,但其知识主要来源于预训练语料和指令微调数据,无法直接访问企业内部文件、专业论文或私有数据库。这就导致当问题涉及到特定领域知识时,模型往往出现“知识盲区”或“幻觉式回答”。
为了弥补这一缺陷,LangChain 框架提出了“检索增强生成(Retrieval-Augmented Generation, RAG)”的解决思路:通过整合外部知识库与语言模型,使模型能够实时检索并利用最新的知识内容,进而实现基于本地知识的问答能力。本文将详细介绍如何利用 LangChain 框架构建一个知识库问答助手,解析其工作原理、关键技术环节以及优势特点。
1. 知识库问答助手总体架构
知识库问答助手的核心目标,是让大语言模型能够“理解”并“调用”本地知识,以实现针对特定领域的精准问答。其工作流程主要分为五个阶段:
- 收集领域知识数据,构建知识库;
- 提取与分割文本,生成语义单元;
- 向量化嵌入与构建向量数据库;
- 基于语义相似度的检索与匹配;
- 利用大语言模型生成回答并输出结果。
这五个阶段共同组成了完整的“知识驱动问答系统”流程。接下来,我们将逐步深入剖析各个环节的技术逻辑。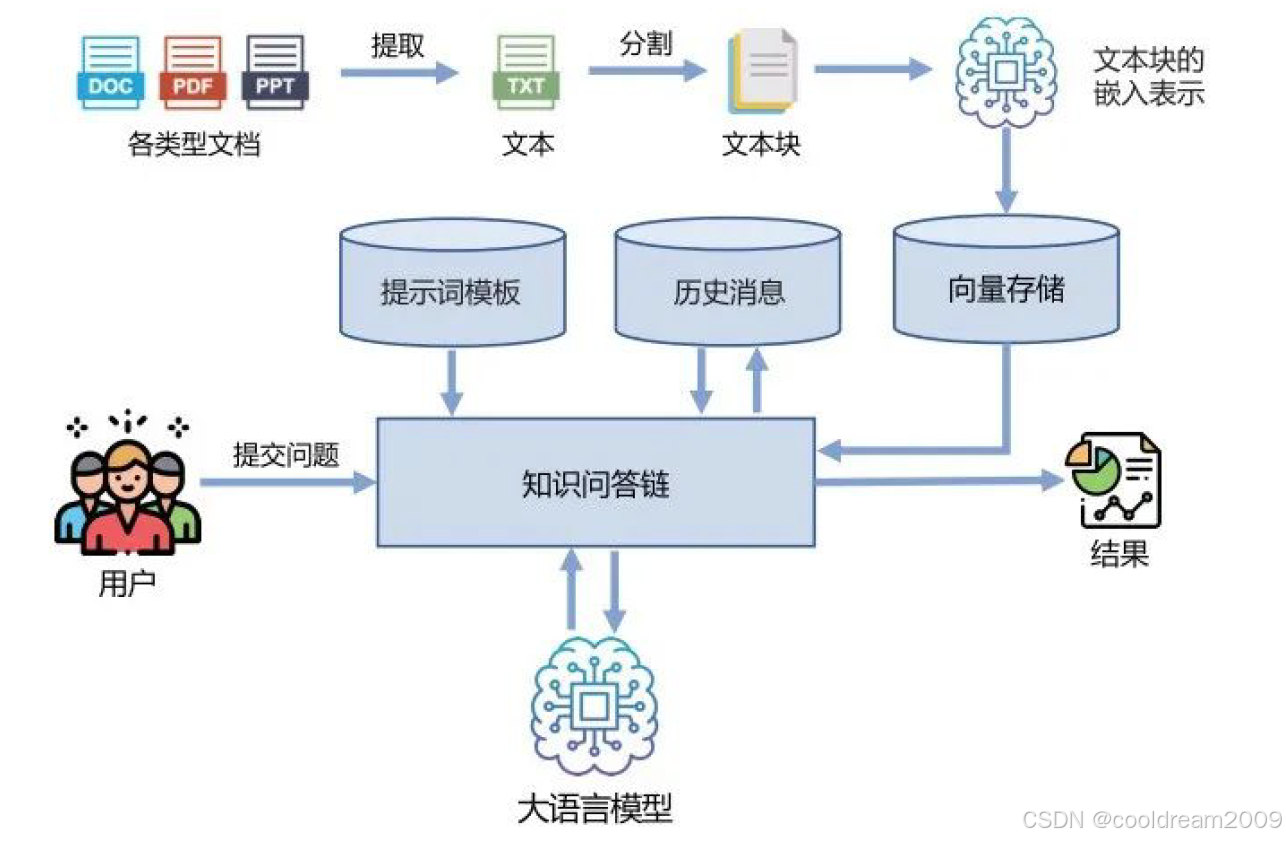
2. 知识数据收集与知识库构建
2.1 数据来源与结构设计
知识库的构建是整个系统的起点。为了让问答助手具备高覆盖度与高准确性,首先需要系统性地收集领域知识数据。这些数据应当能够全面涵盖目标领域的核心内容,并确保内容的时效性与可靠性。常见的知识源包括:
- 企业内部文档:如政策文件、产品手册、技术标准;
- 学术资料:包括论文、专利、教材;
- 公共知识资源:如法律法规、行业规范;
- 客户支持内容:FAQ、服务记录、API 文档等。
在构建知识库时,需要注意两点:其一是数据格式的统一,便于后续自动化处理;其二是元数据(Metadata)的保存,以便在查询结果中显示文档来源或时间信息,从而增强系统的可解释性。
2.2 数据清洗与预处理
收集到的原始数据往往存在格式不统一、冗余信息多等问题,因此必须进行清洗与标准化处理。常见的步骤包括:
- 去除网页广告、标点符号异常或重复内容;
- 删除无效文本段,如封面页、版权声明等;
- 保留语义完整的段落结构。
经过清洗后的文本将作为知识提取与向量化的基础。
3. 文本提取与分块策略
3.1 文本提取(Text Extraction)
非结构化文档(PDF、Word、HTML 等)无法直接被模型读取,因此需要先通过文档加载器提取文本内容。LangChain 提供了多种文档加载器接口:
| 加载器名称 | 支持格式 | 特点 |
|---|---|---|
| PyPDFLoader | 支持分页提取,兼容多语言 | |
| UnstructuredWordDocumentLoader | Word | 保留段落结构 |
| HTMLLoader | HTML 网页 | 自动去除标签 |
| CSVLoader | CSV 文件 | 适合结构化数据 |
通过这些加载器,我们能够快速将异构文档统一转换为标准化文本,方便后续处理。
3.2 文本分块(Chunking)
由于语言模型的输入存在上下文长度限制(context window),原始长文档需要被拆分为较小的文本块(Chunk)。同时,分块也是提升检索精度的重要手段。LangChain 提供了多种分块策略,其中最常用的是 RecursiveCharacterTextSplitter。
该方法会根据语义边界递归地拆分文本,确保每个块在保持上下文连贯的同时控制长度,一般每个块大小为 300~800 个字符,重叠部分(Overlap)设置为 50~100 字符,以避免语义断层。
示例代码:
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_text(document_text)
4. 向量化嵌入与数据库构建
4.1 向量嵌入(Embedding)
每个文本块经过处理后,将被转换为高维语义向量表示。嵌入模型(Embedding Model)负责将自然语言映射到向量空间中,使得语义相似的文本在空间中更接近。
常用的嵌入模型包括:
| 模型名称 | 特点 | 适用场景 |
|---|---|---|
| text-embedding-3-small | 高速轻量,精度较好 | 通用中文任务 |
| text-embedding-3-large | 高精度版本,适合复杂任务 | 企业应用 |
| bge-base-zh | 开源中文模型 | 离线环境 |
| m3e-large | 多语种优化模型 | 跨语言任务 |
示例代码:
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
4.2 向量数据库构建
向量数据库负责存储文本块的嵌入向量,并支持基于相似度的高效检索。常见数据库方案如下:
| 数据库名称 | 特点 |
|---|---|
| FAISS | 轻量级本地库,速度快 |
| Chroma | LangChain 官方支持,使用简单 |
| Milvus | 分布式架构,适合大规模部署 |
| Pinecone | 云端方案,支持动态扩展 |
创建向量索引的示例:
from langchain_community.vectorstores import FAISS
vectorstore = FAISS.from_texts(chunks, embedding=embeddings)
此时,一个可检索的知识库就已经搭建完成。
5. 用户查询与语义检索
5.1 查询向量生成
当用户提出问题时,系统会首先将问题文本通过相同的嵌入模型编码成查询向量。然后,在向量数据库中检索出与之最相似的若干文本块,这些文本块被认为是与用户问题语义最相关的知识内容。
5.2 检索与上下文构建
LangChain 的 Retriever 模块可直接完成语义检索。系统通常会返回前 k 条最相关的结果(如前 3 条),随后将这些内容拼接为上下文段落,作为输入传递给大语言模型。
示例代码:
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 3})
docs = retriever.get_relevant_documents(query)
接着,利用提示模板(Prompt Template)将检索结果与用户问题组合,构造最终输入:
你是一个专业知识问答助手,请根据以下内容回答问题:
{context}
问题:{question}
6. 回答生成与结果输出
6.1 大语言模型生成
在获取了最相关的知识上下文后,系统会将完整的提示词传入语言模型(如 gpt-4-turbo 或 Claude-3),由模型生成基于事实的回答。LangChain 的 RetrievalQA 组件能够简化这一过程:
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4-turbo")
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
answer = qa.run("请解释系统部署流程。")
模型生成的答案将结合用户问题与检索文本,确保回答的准确性和上下文关联性。
6.2 输出与溯源
为了增强可信度,系统还可以输出引用的知识片段或文档来源(Source Documents),帮助用户了解答案依据。这种“可追溯性”设计,是知识库问答系统区别于普通聊天模型的重要特征。
7. 系统优势与应用场景
基于 LangChain 构建的知识库问答助手,具有以下显著优势:
- 知识可控性:模型回答严格基于指定知识库,避免无关或错误信息;
- 数据安全性:知识库与数据库可完全本地部署,保护隐私;
- 动态更新性:新增或修改文档即可快速更新知识体系;
- 模块化扩展性:可灵活替换 Embedding 模型、数据库或 LLM;
- 高解释性:支持结果来源展示,提升用户信任度。
其典型应用包括企业智能客服、科研知识助手、政府文档检索、企业内部培训系统等。
8. 结语
LangChain 框架通过提供结构化的工具链,将“外部知识检索”与“大语言模型生成”有机结合,形成了可持续演进的知识增强生成(RAG)系统。
这种融合让 LLM 从单纯的语言生成器转变为“知识驱动的智能体”,能够回答超出训练语料范围的专业问题,实现真正意义上的“知识推理与应用”。
随着向量数据库与开源嵌入模型的持续发展,未来的知识库问答系统将更加智能化、可解释化与个性化,成为企业与科研机构数字化转型的重要支撑。
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)