大模型基础 | 模型参数初始化
模型参数初始化是神经网络训练的重要第一步,直接影响模型性能和收敛速度。固定权重初始化可能导致收敛缓慢,而固定方差初始化需要平衡方差大小以避免梯度消失或信号消失。Xavier初始化根据神经元数量和激活函数类型自动调整方差,保持数据在传播过程中的稳定性。Kaiming初始化则针对ReLU函数的特性进行优化。不同激活函数(如Tanh、Sigmoid)需要不同的方差补偿策略。预训练权重(如BERT)通过大
模型参数初始化
初始化模型参数的影响
在训练神经网络时,各类参数初始化方法是开启模型智能之旅的第一步。它们不仅为模型赋予了最初的“生命”,决定定了模型的起始点,同时影响着模型后续训练的难度和最终性能。因此,如何初始化模型参数至关重要。
固定权重
固定值初始化通常基于经验和实践,它涉及为模型的特定参数赋子预先设定的初始值。以使用ReLU 的神经元为例,一种常见的做法是将它们的偏置项设置为 0.01。这样做的目的是帮助使用 ReLU 的神经元在训练初期更容易获得一定的梯度信息,从而促进其自身参数的有效更新。但是,使用固定值进行初始化有一个显著的缺点,比如除了偏置,权重也设置为0.01,模型有可能收敛很慢,并且人工先验的初始值并不能灵活适应各种复杂任务和多变的模型结构。
固定方差
基于固定方差的初始化属于随机初始化的一类方法,其主要思想是从一个具有固定均值和方差的分布中进行参数采样,以此来初始化模型参数。所用的分布通常是高斯分布和均匀分布。
这里我们先说一下什么是Sigmoid饱和区
Sigmoid 饱和区
数据参数的分布(比如均值是5,方差是10)才是最有用的、最能帮助模型做出正确预测的分布,然而方差大或者均值容易使得梯度求导进入饱和区。
- 方差大 → 权重值大
当你使用较大的方差初始化权重时(比如标准差为1或更大),初始权重值会大概率落在远离0的区域(比如 -2, 3, -4 等)。- 权重值大 → 线性组合输出大
神经元的输出是:
z = ∑ w i x i + b z = \sum w_i x_i + b z=∑wixi+b
如果输入$ x_i $是标准正态分布(均值为0,方差为1),而权重 w i w_i wi 的方差也很大,那么$ z $ 的方差会更大(因为方差是累加的)。- 输出大 → 激活函数进入饱和区
以 sigmoid 为例:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
- 当$ z > 4 , , ,\sigma(z) \approx 0.98$
- 当 $ z < -4 , , ,\sigma(z) \approx 0.02$
这些区域称为饱和区如下图所示,因为:- 输出几乎不再变化(梯度接近0)
- 反向传播时,梯度几乎为0,导致梯度消失

所有对于基于固定方差的初始化方法,其关键点是如何对被采样的分布设定一个合适的方差(这里均值一般固定为0)。如果所设定的方差过大,那么就容易导致神经元的输出值过高,进而使这些输出位于 sigmoid 等激活两数的饱和区域内,从而出现梯度消失的情况,严重影响优化效率。
相反,如果所设定的方差过小,则会导致神经元的输出值过低,这不仅容易出现信号消失的情况,还会使得激活函数的非线性能力下降。
方差缩放的初始化
基于方差缩放的初始化方法旨在根据神经元的输入特性以及模型所使用的激活函数类型,自适应地调整用于初始化模型参数的分布,以此避免神经网络训练过程中可能出现的梯度消失或梯度爆炸问题。
为了解决这一问题,接下来我们介绍两种具有代表性的基于方差缩放的初始化方法。
Xavier 初始化
Xavier 初始化方法源自论文《Understanding the Difficulty of Training Deep Feedforward Neural Networks》,其主要特点是可以根据模型中每一层神经元的数量以及所用的激活函数类型,自动计算出初始化分布的方差,使得数据在经过每一层网络时,其前后的方差保持接近,进而避免因某一层的输出数据中出现过大的值而引起的梯度不稳定问题。
向量个数M的含义
为了表达方便,我们首先假设模型所使用的激活函数是恒等函数,即 f ( x ) = x f(x) = x f(x)=x。然后我们将第 l l l 层某个神经元的输出记作 o u t p u t i l output_i^l outputil,将第 l l l 层需要初始化的权重参数记作 w i l w_i^l wil。并将 o u t p u t l output^l outputl 的向量个数记作 M l − 1 M_{l-1} Ml−1,对于 $ output^l $ 的方差 var ( o u t p u t l ) \text{var}(output^l) var(outputl),有如下公式:
var ( o u t p u t l ) = M l − 1 ⋅ var ( w l ) ⋅ var ( o u t p u t l − 1 ) \text{var}(output^l) = M_{l-1} \cdot \text{var}(w^l) \cdot \text{var}(output^{l-1}) var(outputl)=Ml−1⋅var(wl)⋅var(outputl−1)
换句话说, M l − 1 M_{l-1} Ml−1 指的是第l层一个神经元的输入连接数,也就是第 l-1层的神经元总数
公式推导的上下文:推导方差公式 v a r ( o u t p u t l ) = M l − 1 ∗ v a r ( w l ) ∗ v a r ( o u t p u t i l − 1 ) var(output^l) = M_{l-1} * var(w^l) * var(outputi^{l-1}) var(outputl)=Ml−1∗var(wl)∗var(outputil−1) 的前提是,第 l l l 层的神经元 o u t p u t l output^l outputl 的值是由前一层 l − 1 l-1 l−1 层的所有神经元的输出加权求和得到的。
* o u t p u t l = w 1 l o u t p u t 1 l − 1 + w 2 l o u t p u t 2 l − 1 + . . . + w M l − 1 l o u t p u t M l − 1 l − 1 + b i a s output^l = w_{1}^l output_1^{l-1} + w_{2}^l output_2^{l-1} + ... + w_{M_{l-1}}^l output_{M_{l-1}}^{l-1} + bias outputl=w1loutput1l−1+w2loutput2l−1+...+wMl−1loutputMl−1l−1+bias
* 在这个求和中,项数正好等于前一层神经元的数量。因此, M l − 1 M_{l-1} Ml−1 就是这个求和中的项数。
可以看出,数据经过第 l l l层后,其方差 var ( o u t p u t l ) \text{var}(output^{l}) var(outputl) 变成了原来方差 var ( o u t p u t l − 1 ) \text{var}(output^{l-1}) var(outputl−1) 的 M l − 1 ⋅ var ( w l ) M_{l-1} \cdot \text{var}(w^l) Ml−1⋅var(wl) 倍。为了使得数据经过第 $ l $ 层前后的方差保持接近,需要让 M l − 1 ⋅ var ( w l ) = 1 M_{l-1} \cdot \text{var}(w^l) = 1 Ml−1⋅var(wl)=1,即
var ( w l ) = 1 M l − 1 \text{var}(w^l) = \frac{1}{M_{l-1}} var(wl)=Ml−11
同理,在反向传播阶段,如果想让误差项在第 l l l 层前后保持稳定,则需要有:
var ( w l ) = 1 M l \text{var}(w^l) = \frac{1}{M_l} var(wl)=Ml1
如果同时考虑模型前向传播和反向传播两个阶段,在假设激活函数为恒等函数 f ( x ) = x f(x) = x f(x)=x的情况下,他们推导出了理想的权重方差是:
var ( w l ) = 2 M l + M l − 1 \text{var}(w^l) = \frac{2}{M_l + M_{l-1}} var(wl)=Ml+Ml−12
为了在使用了激活函数后,仍然满足 v a r ( a l ) = v a r ( a l − 1 ) var(a^l) = var(a^{l-1}) var(al)=var(al−1)的目标,我们就必须补偿激活函数带来的这种缩放效应。补偿的方法就是调整权重的初始化方差。
不同激活函数的调整
Tanh函数(双曲正切函数)
函数定义:
tanh ( x ) = e x − e − x e x + e − x = e 2 x − 1 e 2 x + 1 \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} = \frac{e^{2x} - 1}{e^{2x} + 1} tanh(x)=ex+e−xex−e−x=e2x+1e2x−1
导数公式:
d d x tanh ( x ) = 1 − tanh 2 ( x ) \frac{d}{dx}\tanh(x) = 1 - \tanh^2(x) dxdtanh(x)=1−tanh2(x)
在x=0处的计算:
tanh ( 0 ) = e 0 − e 0 e 0 + e 0 = 0 2 = 0 \tanh(0) = \frac{e^0 - e^0}{e^0 + e^0} = \frac{0}{2} = 0 tanh(0)=e0+e0e0−e0=20=0
tanh ′ ( 0 ) = 1 − tanh 2 ( 0 ) = 1 − 0 = 1 \tanh'(0) = 1 - \tanh^2(0) = 1 - 0 = 1 tanh′(0)=1−tanh2(0)=1−0=1
方差补偿:
增益约为1,Tanh函数在其线性区域几乎不改变信号的方差。因此,对于Tanh函数,我们不需要对恒等函数推导出的理想方差进行大幅调整。所以直接使用:
高斯分布方差: v a r ( w ) = 2 / ( M l + M l − 1 ) var(w) = 2 / (M_l + M_{l-1}) var(w)=2/(Ml+Ml−1)
均匀分布范围: r = √ ( 6 / ( M l + M l − 1 ) ) r = √(6 / (M_l + M_{l-1})) r=√(6/(Ml+Ml−1))(这个 √ 6 √6 √6 是为了让均匀分布的方差等于所需的高斯分布方差)
Logistic函数(Sigmoid函数)
函数定义:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
导数公式:
d d x σ ( x ) = σ ( x ) ⋅ [ 1 − σ ( x ) ] \frac{d}{dx}\sigma(x) = \sigma(x) \cdot [1 - \sigma(x)] dxdσ(x)=σ(x)⋅[1−σ(x)]
在x=0处的计算:
σ ( 0 ) = 1 1 + e 0 = 1 1 + 1 = 0.5 \sigma(0) = \frac{1}{1 + e^0} = \frac{1}{1 + 1} = 0.5 σ(0)=1+e01=1+11=0.5
σ ′ ( 0 ) = σ ( 0 ) ⋅ [ 1 − σ ( 0 ) ] = 0.5 × ( 1 − 0.5 ) = 0.5 × 0.5 = 0.25 \sigma'(0) = \sigma(0) \cdot [1 - \sigma(0)] = 0.5 \times (1 - 0.5) = 0.5 \times 0.5 = 0.25 σ′(0)=σ(0)⋅[1−σ(0)]=0.5×(1−0.5)=0.5×0.5=0.25
方差补偿:必须补偿这个衰减。既然激活函数将方差缩小了16倍,那么我们就应该将权重的初始化方差扩大16倍,这样一缩一放,总方差才能保持稳定。
高斯分布方差: v a r ( w ) = 16 ∗ [ 2 / ( M l + M l − 1 ) ] var(w) = 16 * [2 / (M_l + M_{l-1})] var(w)=16∗[2/(Ml+Ml−1)]
均匀分布范围: r = 4 ∗ √ ( 6 / ( M l + M l − 1 ) ) r = 4 * √(6 / (M_l + M_{l-1})) r=4∗√(6/(Ml+Ml−1))
不同的激活函数具有不同的"增益"效果,需要相应调整初始化方差:
| 激活函数 | 零点处斜率 | 增益效果 | 补偿倍数 |
|---|---|---|---|
| 恒等函数 | 1.0 | 无缩放 | 1倍 |
| Tanh | 1.0 | 基本无缩放 | 1倍 |
| Logistic | 0.25 | 强烈缩小 | 16倍 |
Kaiming初始化
之前Xavier的内容中提到
考虑模型前向传播和反向传播两个阶段,在假设激活函数为恒等函数 f ( x ) = x f(x) = x f(x)=x的情况下,他们推导出了理想的权重方差是:
var ( w l ) = 2 M l + M l − 1 (1) \text{var}(w^l) = \frac{2}{M_l + M_{l-1}} \tag1 var(wl)=Ml+Ml−12(1)
对于 ReLU,在 0 点处一半的神经元输出为 0,所以输出的方差 ≈ 线性情况的一半。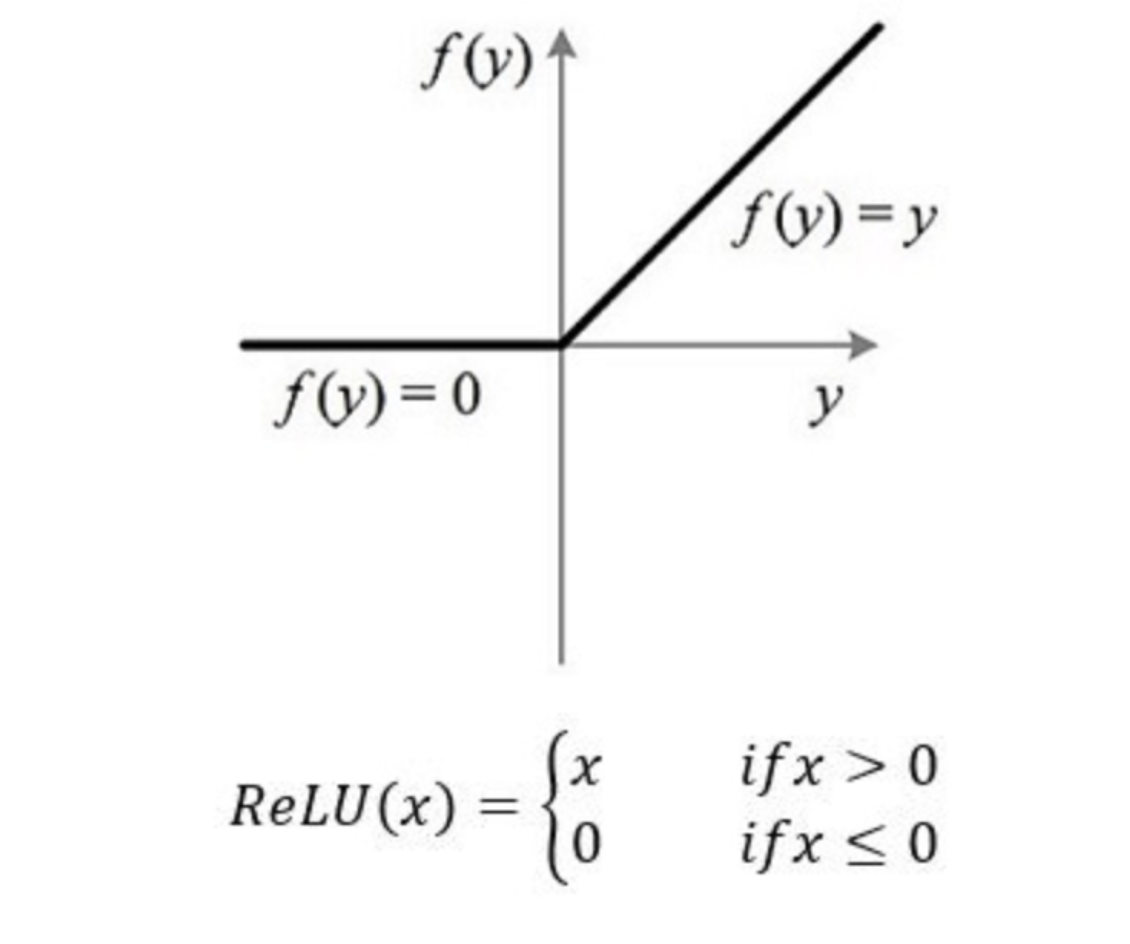
当第 l l l 层使用了 ReLU 激活函数时,只有一半的神经元输出的数值不为 0,其输出数据分布的方差也近似于使用恒等函数时的一半。因此,Kaiming初始化参数 $ w_i’ $ 的理想方差为:
var ( w i ′ ) = 2 M l − 1 \text{var}(w_i') = \frac{2}{M_{l-1}} var(wi′)=Ml−12
预训练权重
诸如 BERT 等预训练语言模型,通过在大规模的数据上进行预训练,使模型能够学到诸多先验知识,这等同于为模型提供了良好的初始参数分布,在一个语义空间中能区分单词之间关系“国王”-“男人”=“女王”-“女人”。
当这些预训练后的模型针对特定任务进行微调时,虽然在训练集上的损失值可能与没有经过预训练的模型差不多,但是它们大多能够收敛到一个泛化能力较高的局部最优解,因此在预测阶段表现更好。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)