【干货收藏】大模型RAG知识库构建全流程:从数据到应用的完整指南
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索和文本生成的技术框架,旨在通过引入外部知识库来提升生成模型(如GPT等)的准确性和可靠性。RAG知识库是这一技术的核心组成部分,它存储了结构化或非结构化的海量数据(如文档、网页、数据库等),供模型在生成答案时动态检索并参考。保证100%免费。
RAG(检索增强生成)是一种结合信息检索和文本生成的技术框架,通过引入外部知识库提升大模型的准确性和可靠性,有效解决传统模型的"幻觉"问题。文章详细介绍了RAG系统的构建流程:语料库提取并转化为向量、向量存储到数据库、相似度搜索、以及调用大模型生成结果。通过使用ollama、chromadb等工具,实现了从数据到应用的完整RAG系统,使大模型能够基于外部知识库提供更专业、更实时的回答。
1、什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索和文本生成的技术框架,旨在通过引入外部知识库来提升生成模型(如GPT等)的准确性和可靠性。RAG知识库是这一技术的核心组成部分,它存储了结构化或非结构化的海量数据(如文档、网页、数据库等),供模型在生成答案时动态检索并参考。
2、RAG架构及执行流程
传统的生成模型依赖预训练时学到的参数化知识,因训练数据过时或领域局限导致生成内容不准确(即幻觉问题)。
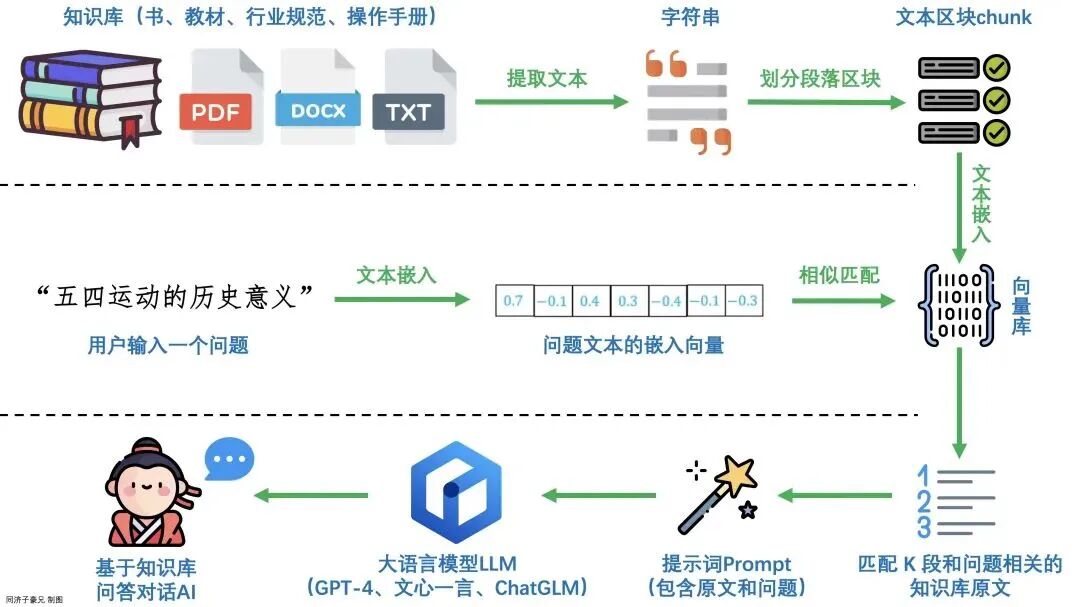
执行流程:
1、提取语料库内容,转化为向量
2、文本向量写入向量数据库
3、文本搜索,通过文本转向量,向量相似度搜索
4、调用大模型生成结果
第一步:语料库及转化为向量
可以通过deepseek等大模型生成,比如:请给我生成一个套出租房屋业务客服语料库。生成好后,复制到本地txt文件。
# 内容提取和段落划分很简单
def get_chunk_list():
with open("dataset/1.txt", encoding='utf-8') as fp:
data = fp.read()
chunk_list = data.split("\n\n")
return [chunk for chunk in chunk_list if chunk]
向量化处理我们借助于ollama,官网https://ollama.com下载。
安装好后,我们可以直接在命令行安装模型。
ollama pu11 nomic-embed-text
把文本内容转化为向量
# 文本妆化为向量
def ollama_embedding_by_api(text):
url = "http://127.0.0.1:11434/api/embeddings"
res = requests.post(
url=url,
json={
"model": "nomic-embed-text",
'prompt': text
}
)
return res.json()['embedding']
第二步:语料库内容嵌入向量数据库
向量数据库有很多:chromadb、Faiss、Qdrant、Elasticsearch等等。 今天我们就使用chromadb,直接本地安装使用。
# 安装向量数据库
pip install chromadb
# 批量导入向量数据库
def bulk_insert_collection(lines):
collection = get_collection()
ids = [str(uuid.uuid4()) for _ in range(len(lines))]
vectors = [ollama_embedding_by_api(line) for line in lines]
collection.add(
ids=ids,
documents=lines,
embeddings=vectors
)
通过update和delete函数对表更新和删除操作,调整语料。
collection.update(ids=['id'],documents=['text'])
collection.delete(ids=['id'])
第三步:向量相似度搜索
检索数据转化为向量化数据,然后进行查询
def query_text(text):
vector = ollama_embedding_by_api(text)
collection = get_collection()
# n_result 匹配数量 2
res = collection.query(
query_embeddings=[vector, ],
query_texts=text,
n_results=2)
return "\n".join(res['documents'][0])
第四步:文本大模型润色
使用文本大模型进行推理,安装deepseak蒸馏的r1模型
# 继续使用ollama进行安装
ollama pull deepseek-r1:1.5b
根据自己的应用场景或行业定义提示词。
def get_deepseek_response(question,answer):
prompt = f"""你是一个房屋出租客服机器人,任务是根据参考
信息回然用户问题,如果参考信息不足以回然用户问题,
请回复不知道,不要去杜撰任何信息,请用中文同然。
参考信息:{question},来回答问题:{answer}
"""
res = requests.post(
url="http://127.0.0.1:11434/api/generate",
json={
"model": "deepseek-r1:1.5b",
'prompt': prompt,
'stream': False,
}
)
return res.json()['response']
第五步:测试运行
写入预料到向量数据库
bulk_insert_collection(get_chunk_list())
检索并文本输出
question = '你好,我想租房'
answer = query_text(question)
res = get_deepseek_response(question,answer)
print(res)
总结起来就是:知识库是将知识数据的索引保存到向量数据库中,然后利用prompt的向量到向量数据库中搜索,根据阈值搜到符合要求的,并对搜索到的知识进行二次处理,然后连同prompt一起作为上下文提交给大模型。
RAG知识库通过将生成模型与外部知识动态结合,解决了传统模型的幻觉问题,并在专业性和实时性上表现突出。其核心在于高效检索与生成能力的协同,是当前大模型落地应用的重要技术方向之一。
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献189条内容
已为社区贡献189条内容

所有评论(0)