AI Agent终极指南:概念、架构、评测与开源项目全解析,看到就是赚到,建议收藏!!!
文章全面介绍AI Agent技术体系,涵盖定义、能力分级(L0-L5)、应用场景、核心架构和设计模式。深入分析Agent规划模块和评测体系,对比评测Dify、MetaGPT等开源项目,指出当前Agent技术处于流程编排阶段(L2级),未来将向自主学习和群体智能方向发展,是程序员入门Agent领域的收藏级指南。
前言
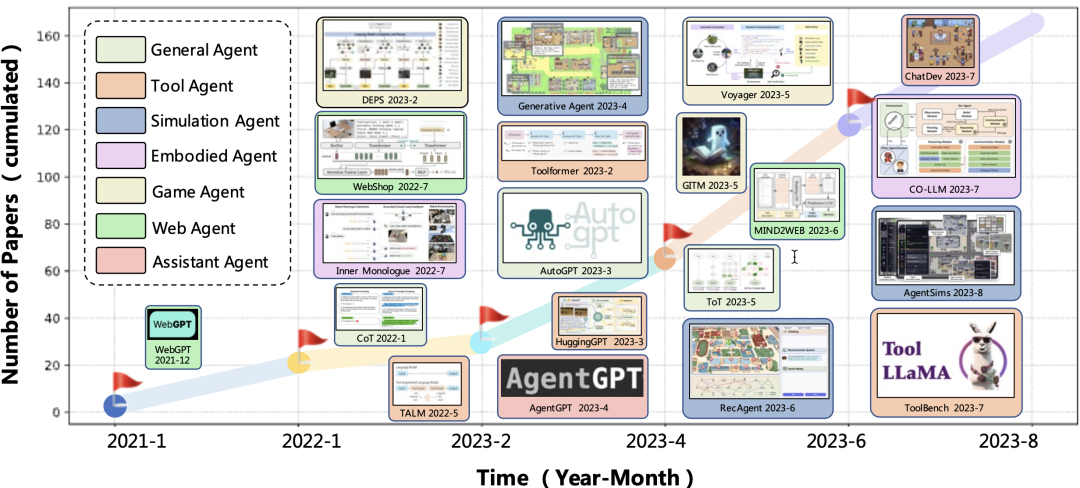
Agent的发展在25年大概是巅峰赛季了,层出不穷,agent的定义不断地被横向或者纵向的扩展,总之,范式不断地被颠覆。
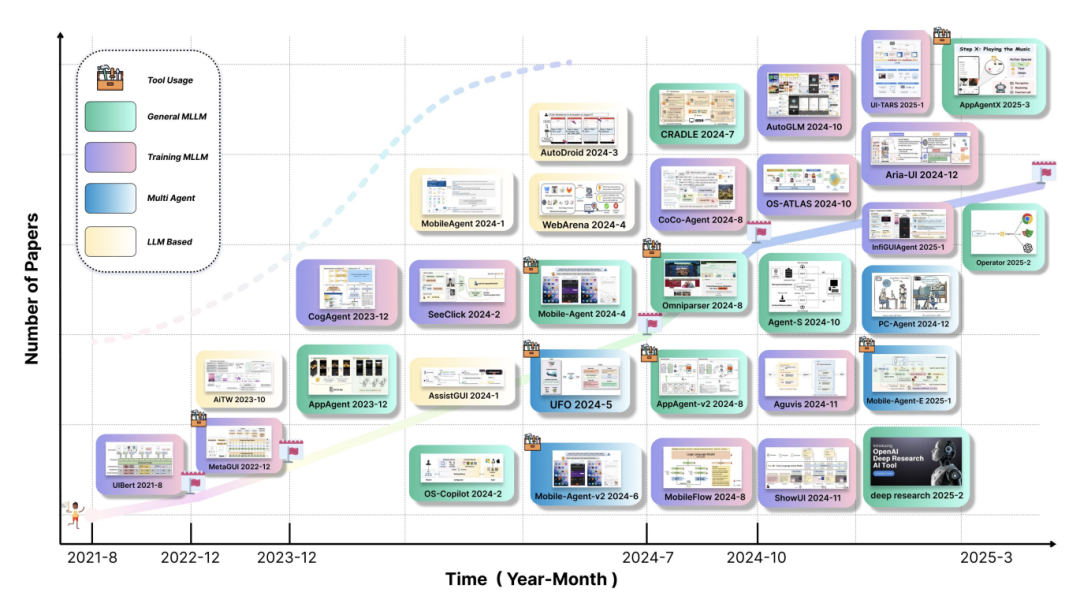
这是一篇过期的文章…,关于范式的定义、开源的评测、未来的探索…
针对Agent的探索以及开源项目进行了深度的分析,并综合给出了个人层面对于Agent的进化历程。
相关重点Paper
- Understanding the planning of LLM agents: A survey(https://arxiv.org/pdf/2402.02716)
- HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face(https://arxiv.org/pdf/2303.17580、https://github.com/microsoft/JARVIS)
- Why Do Multi-Agent LLM Systems Fail?(https://arxiv.org/abs/2503.13657)
- API Agents vs. GUI Agents: Divergence and Convergence(https://arxiv.org/pdf/2503.11069)
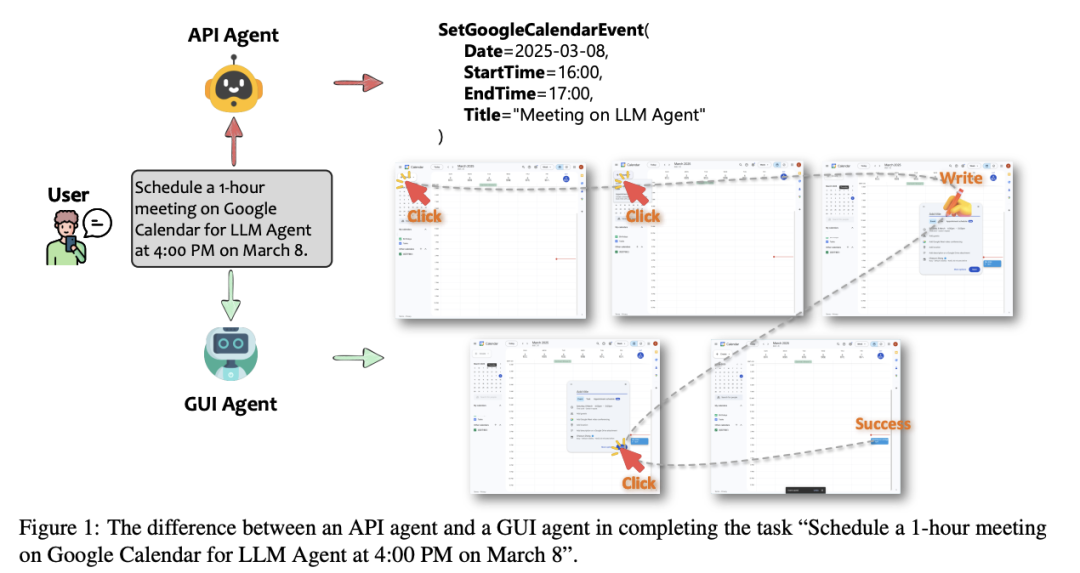
从多个维度(如模态、可靠性、效率、可用性、灵活性、安全性、可维护性、透明度和类人交互)对API代理和GUI代理进行了全面评估
- A Survey on (M)LLM-Based GUI Agents(https://arxiv.org/pdf/2504.13865)
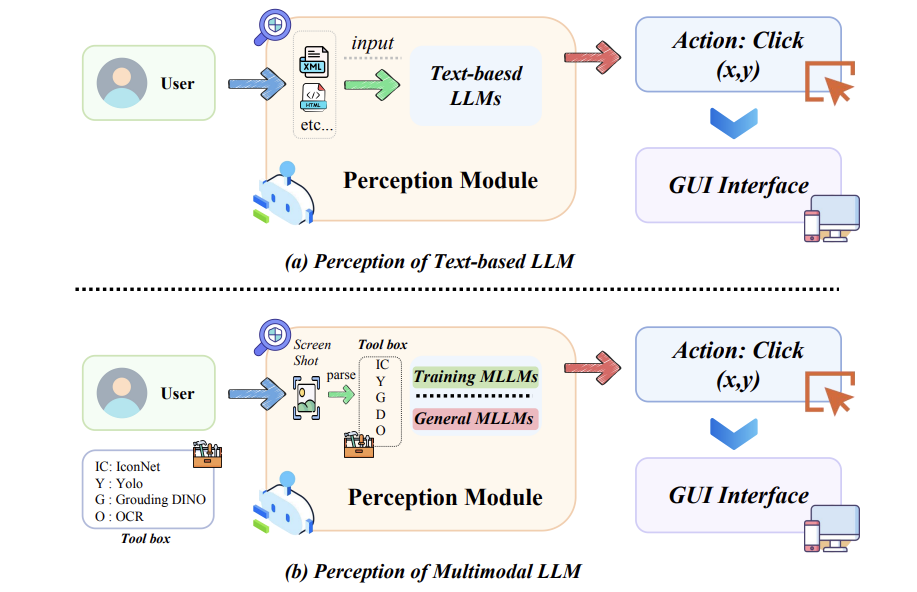
GUI Agent的综述
Agent范式阐述
Autonomous agents 又被称为智能体Agent。能够通过感知周围环境、进行规划以及执行动作来完成既定任务。
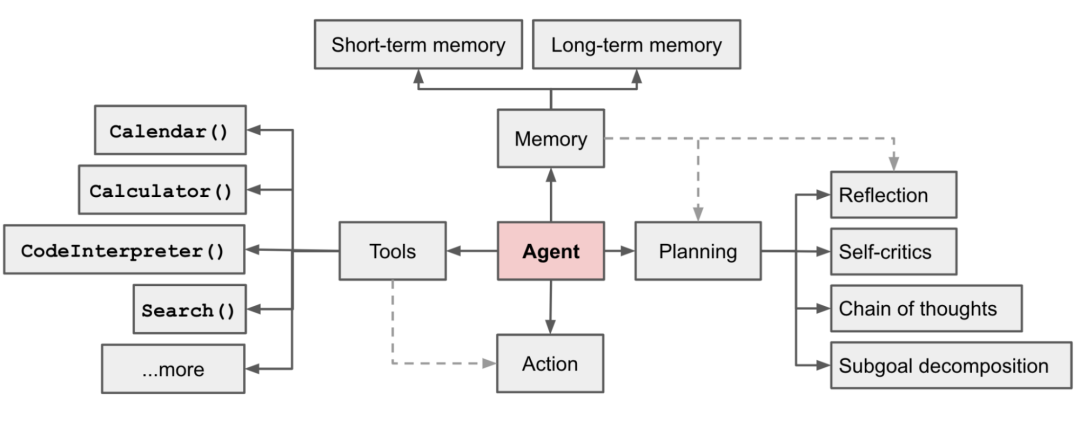
这个图大概是对Agent阐述最多的了。作为一个经典的Agent框架图,也是最基础的,明确说明了现在Agent所涉及的模块,以及模块涉及的技术点,但随着国内技术的一日千里,描述也稍有欠缺了。
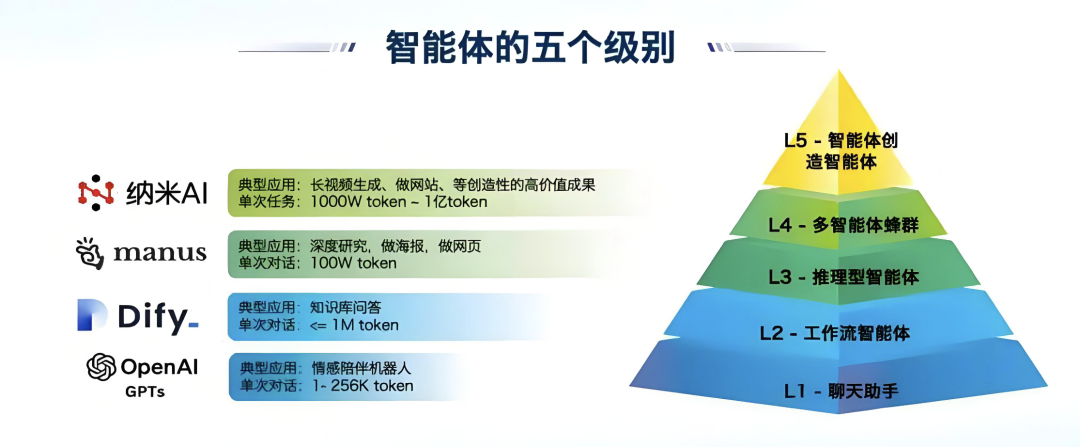
AI Agent的能力水平划分
-
L0-没有人工智能,仅有基本的工具(能实现感知)和行为能力;
-
L1-规则符号智能,基于规则的 AI,包含早期NLP的任务规则;
-
L2-推理决策智能,基于互动学习(IL)/强化学习(RL)的 AI,并增添推理和决策能力,典型的就是Dify、manus为代表的流程编排;
-
L3-记忆反思智能,基于LLM的 AI 替换互动学习/强化学习的方式,并增加记忆(Memory)+自我反思(reflection);
-
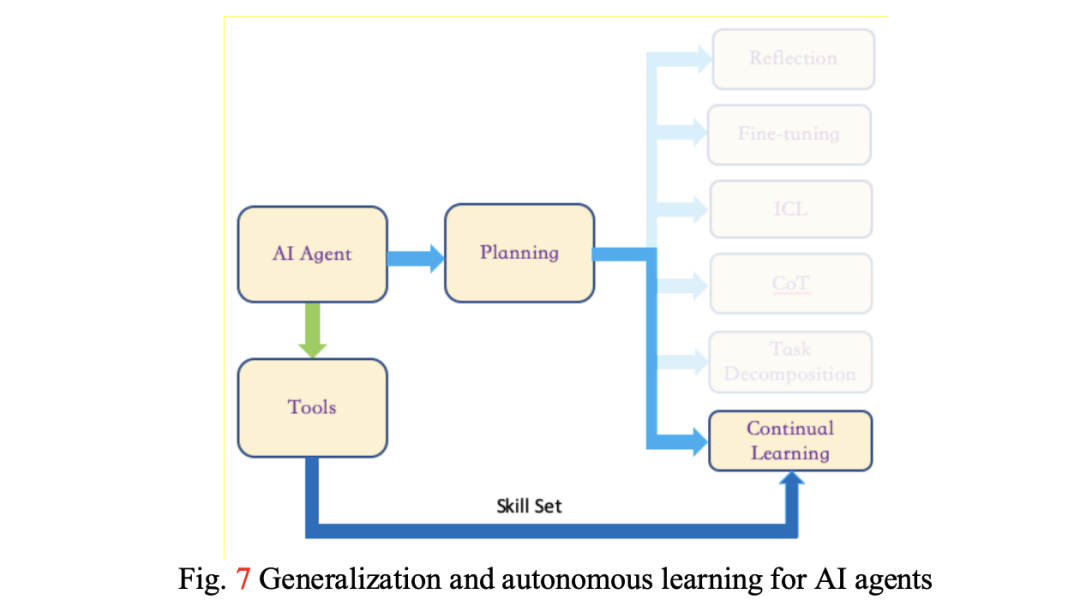
L4-自主学习智能,在 L3的基础上,加强自我学习+泛化的能力;
-
L5-个性群体智能,在 L4的基础上,增加了个性(情感+性格)和协作行为(MultiAgent)
Agent模态上划分
- 基于语言的智能体
- **基于视觉的智能体:**SpiritSight
- 视觉-语言混合智能体:MobileFlow
推荐paper:
- AppAgentX:Evolving GUI Agents as Proficient Smartphone Users
-
MobileFlow:A Multimodal LLM for Mobile GUI Agent(移动设备专用)
-
OS Agents:A Survey on MLLM-based Agents for General Computing Devices Use
-
SpiritSight Agent:Advanced GUI Agent with One Look.
-
Levels of AI Agents: from Rules to Large Language Models
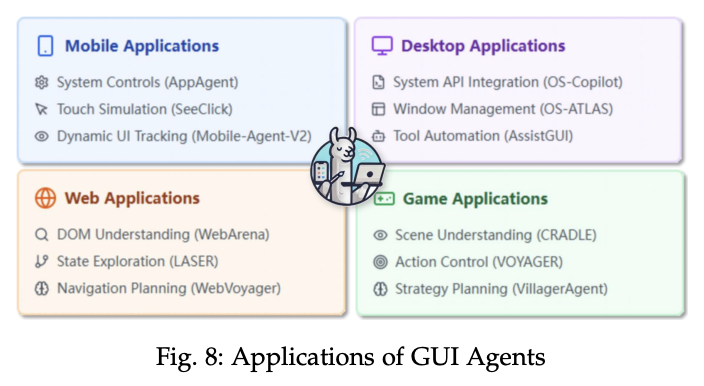
Agent按照应用场景划分:
-
OS Agents
-
GUI Agents
-
Computer-Using Agent, CUA
下图作为当前大部分Agent的核心架构,其实完全足够了,大家基本是在其基础上对模块进行补充扩展。
源自:Executable Code Actions Elicit Better LLM Agents(https://arxiv.org/pdf/2402.01030)
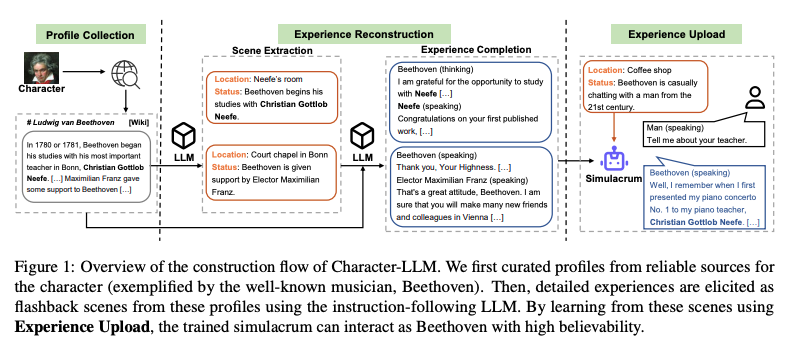
源自:Character-LLM: A Trainable Agent for Role-Playing(https://aclanthology.org/2023.emnlp-main.814v2.pdf)
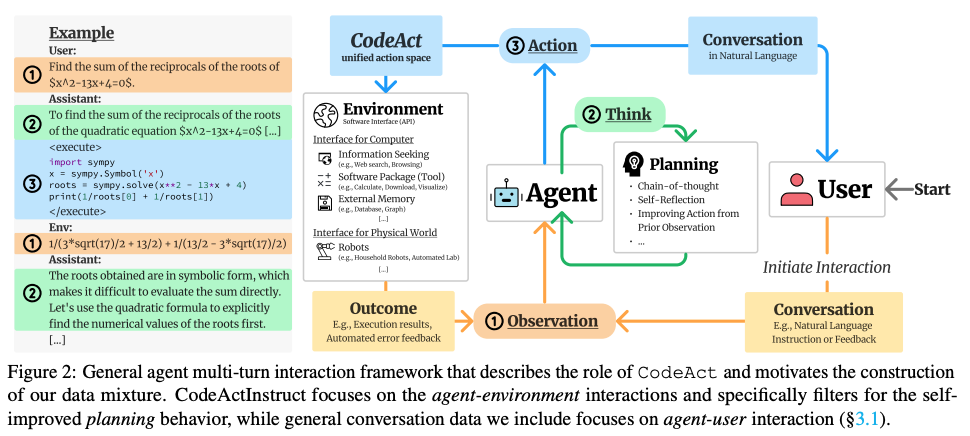
下面的五种Agent模式,能非常准确的反应当前Agent的演变路线,
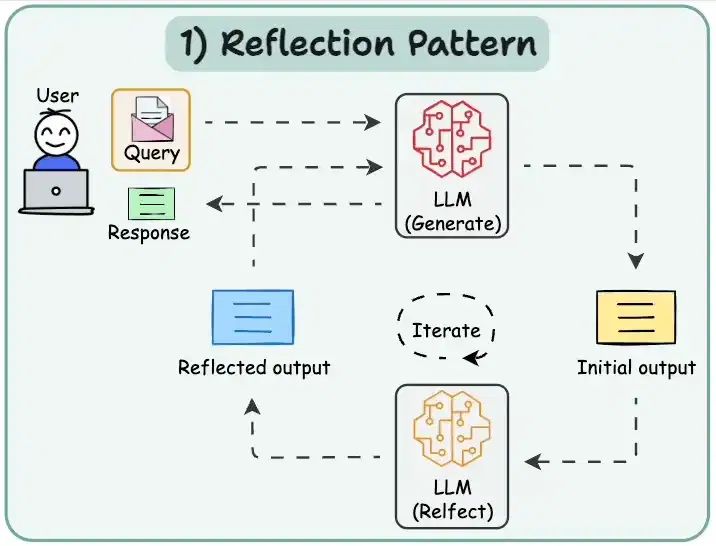
Reflection是指Agent能够对自己的行为和决策进行推理和分析的能力
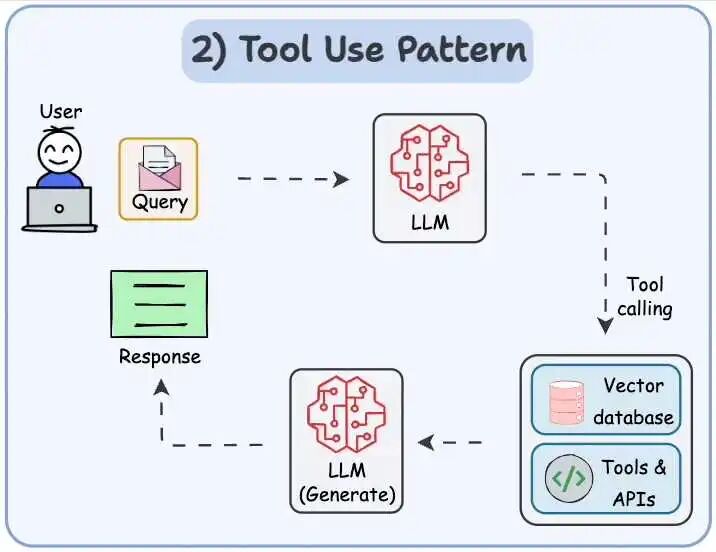
- 查询矢量数据库、执行 Python 脚本、调用 API 等,利用外部工具和资源来提升自己的决策和执行能力。
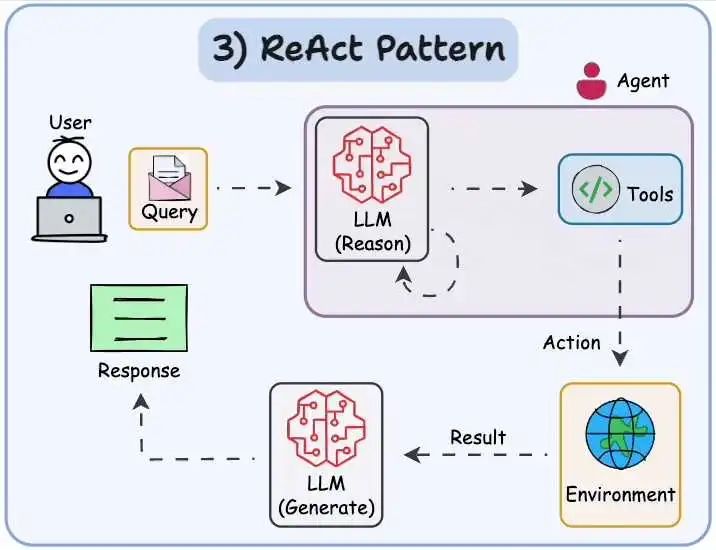
ReAct 结合了上述两种模式:Agent 可以反映生成的输出。它可以使用工具与世界交互。Agent根据环境的变化做出反应。这种设计范式涉及到Agent如何根据环境的变化来调整自己的决策和行为。
- Planning pattern规划模式
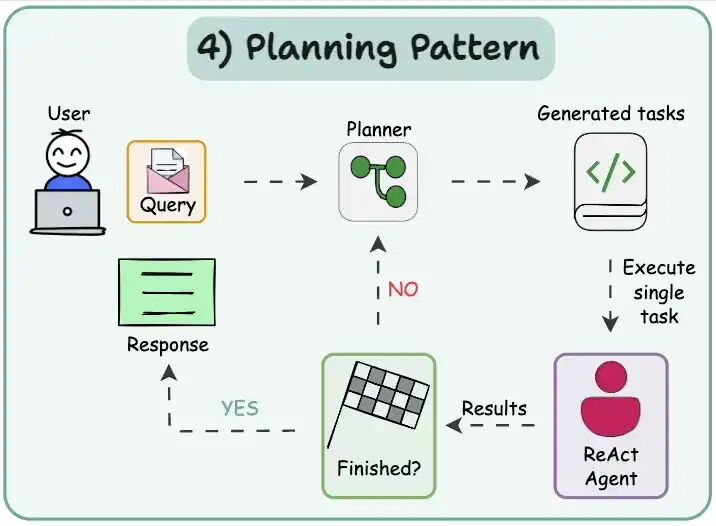
规划是Agent AI 的一个关键设计模式,我们使用大型语言模型自主决定执行哪些步骤来完成更大的任务。
- Multi-agent pattern多智能体模式
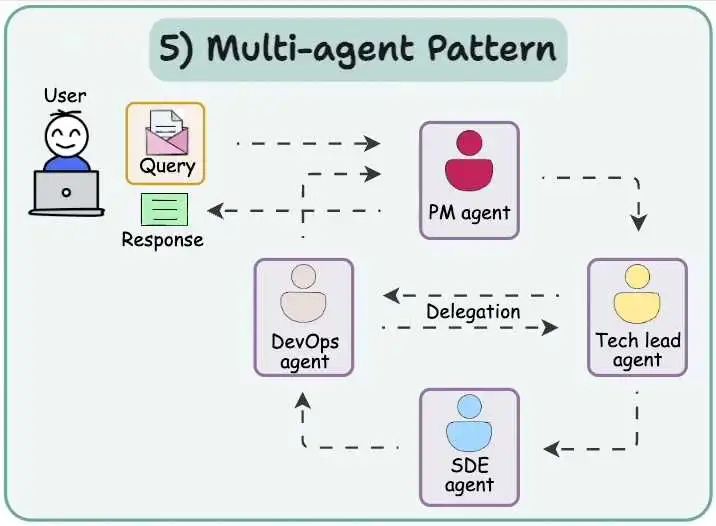
常见的Agent,包括Manus、Deep Research大部分都是LLM+Wrapper(Prompt、Function Call,MCP、A2A等)。
此时此刻,对于Agent到底是个什么
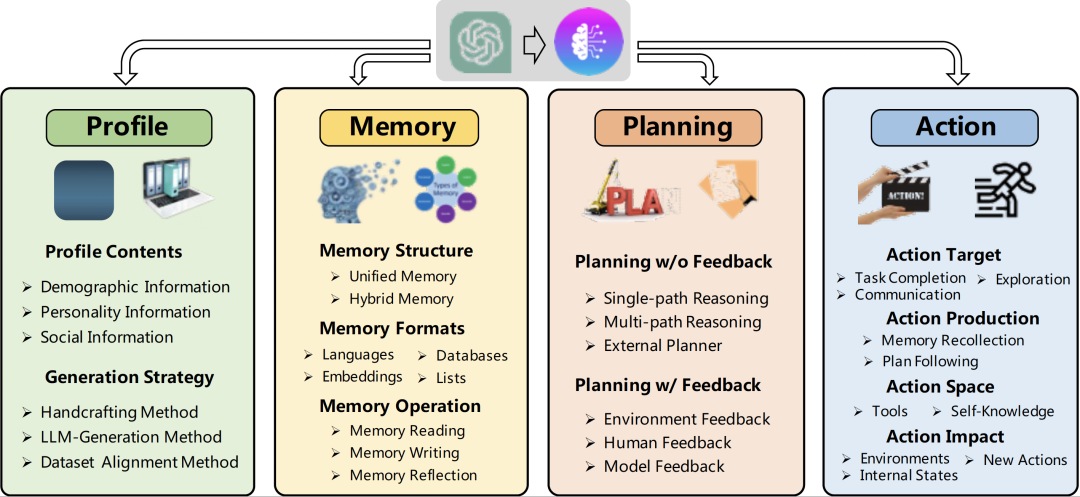
Agent核心Plan模块
核心思想:任务分解 & 反思和提炼
- Understanding the planning of LLM agents: A survey
- 任务分解(Task Decomposition):分治思想。
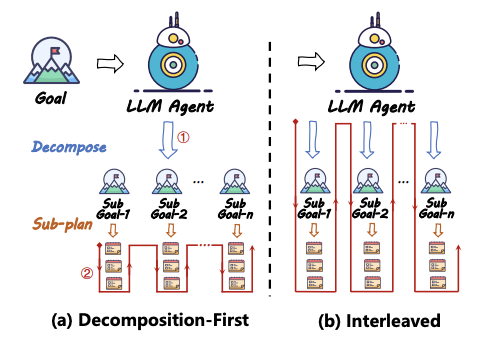
分解优先(Decomposition-First):先分解,再计划,如:HuggingGPT、Plan-and-Solve、ProgPrompt
交错分解(Interleaved):一边分解任务,一边制定计划,如:ReAct、COT、POT
- 多计划选择(Multi-Plan Selection):投票思想。给智能体一个“选择轮”,生成多个计划,然后选择最优计划来执行。
多计划生成:利用LLM在解码过程中的不确定性,比如通过温度采样或top-k采样获得多个不同推理路径。
最优选择:启发式搜索算法, 比如 简单的多数投票策略,或者利用树结构来辅助多计划搜索
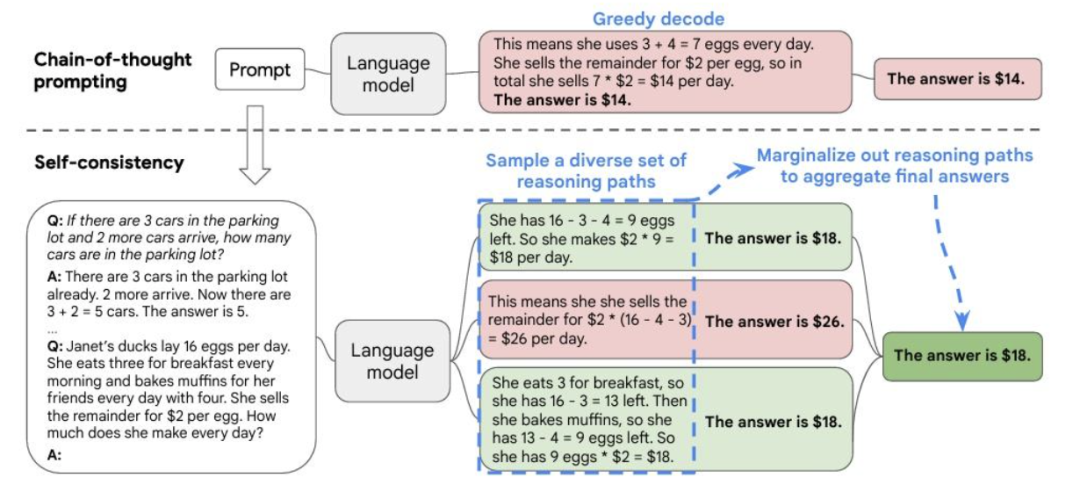
如:Self-consistency:投票的方式
Tree-of-Thought (ToT):**树搜索(BFS/DFS)**算法,使用LLM评估多个动作并选择最优动作
Graph-of-Thought (GoT):同ToT
LLM-MCTS 和 RAP:树结构辅助多规划搜索,但采用MCTS算法进行搜索
推荐paper:
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
(https://arxiv.org/abs/2201.11903)
thought_prompt = f"""
角色名称:{self.name}
初始记忆:{self.seed_memory}
当前心情:{self.mood}
任务:根据角色当前的相关记忆,相关知识,对话上下文进行分析,基于角色第一视角进行思考,给出角色的心理反应对和相关事件的判断。
字数限制:不超过100字。
<<<
相关记忆:“{memory['description']}”
相关知识:“{knowledge_text}”
对话上下文:
{self.language_style}
{context}
>>>
请仅返回{self.name}第一人称视角下的思考内容,不要添加额外信息或格式。
"""
response_prompt = f"""
角色名称:{self.name}
初始记忆:{self.seed_memory}
当前心情:{self.fsm.mood}
任务:基于角色的思考内容和对话上下文进行回复。
字数限制:不超过100字。
<<<
思考内容:“{thought}”
对话上下文:
{self.language_style}
{context}
>>>
请在思考内容和对话上下文的基础上,以{self.name}的身份回复。不要扮演其他角色或添加额外信息,不要添加其他格式。
"""
- 辅助规划(External Planner-Aided Planning):借助外部规划器**,在旁边出谋划策**
在特定场景约束下,LLM能力不足,如:高P场景、数学推导等,辅助规划的思想主要是在对LLM本身比如通过强化学习或模仿学习技术训练的深度模型,针对特定领域展现出有效的规划能力,或者借助外部Model来进行辅助补丁。
- 反思细化(Reflection and Refinemen):执行计划过程中,能够停下来反思,然后改进计划。
LLM 规划过程中可能会产生幻觉**,或因为理解不足而陷入“思维循环”,反馈和改进是规划过程中不可或缺的组成部分,增强了LLM Agent 规划的容错能力和错误纠正能力。**
思想:生成、反馈和改进
如:Self-refine:利用迭代过程,包括生成、反馈和精炼
Reflexion:扩展 ReAct 方法,通过引入评估器来评估轨迹
CRITIC:使用外部工具,如知识库和搜索引擎**,验证LLM生成的动作**
InteRecAgent:ReChain的自我纠正机制
LEMA:收集错误的规划样本,然后使用更强大的GPT-4进行纠正
推荐paper:
- Self-Refine: Iterative Refinement with Self-Feedback
- CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
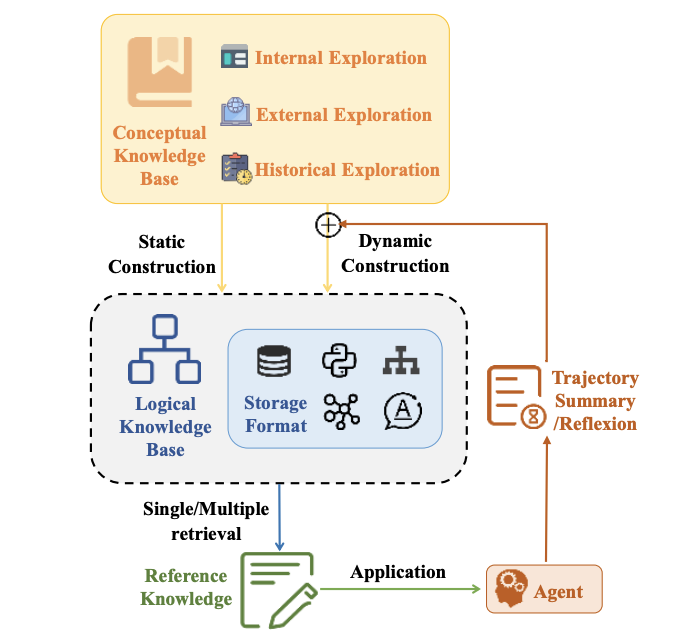
- 记忆增强(Memory-Augmented Planning):使用过去经验,为将来规划提供帮助。
通过记忆来增强 LLM-Agents 规划能力的方法: RAG记忆 和 参数记忆
如:Generative Agents:以文本形式存储类似于人类的日常经验,并根据当前情况的相关性和新鲜度来检索记忆。
MemoryBank、TiM 和 RecMind:记忆编码成向量,并使用索引结构(如FAISS库)来组织这些向量。
MemGPT:借鉴了计算机架构中的多级存储概念,将LLM 上下文视为RAM,并将额外的存储结构视为磁盘。
REMEMBER:将历史记忆以Q值表的形式存储,每个记录是一个包含环境、任务、动作和Q值的元组
Agent的评测体系
推荐paper:
- Survey on Evaluation of LLM-based Agents(https://arxiv.org/pdf/2503.16416)
评测主要来自paper,有一定的参考意义。
智能体评测(CUP)的上层体系:
-
Capacity: 有什么样的力。能做什么
-
Under standing: 深度理解能力。能听懂么
-
Performance: 性能评估。智能体做得怎么样
LLM Agent 利用大语言模型的强大理解与推理能力,结合外部工具(如数据库查询、代码执行、网页访问),实现多轮交互、长期记忆与自主规划,能够主动解决复杂、多步骤的现实问题。
Agent当前处于一个蓬勃探索期,随着LLM本身能力跃迁式的变化,评测体系也在不断地演变,但万变不离其宗,可靠性、安全性、效率等始终是其核心:
-
确保在实际应用中可靠有效:Agent 在真实场景下会碰到大量意外情况或长尾需求,必须用严格的测试来检验其鲁棒性。
-
指导下一步研发和迭代:良好的评测可以帮研发者发现 Agent 的「短板」和错误模式,从而持续改进。
-
安全与合规:随着 Agent 能调用外部工具甚至有权限访问企业数据库,如果无法正确评测安全性,就会产生较大的潜在风险。
-
成本与效率:评测还应包含成本、效率等,以免 Agent 可以完成任务但不切实际或代价过高。
主要有以下四大维度:
- 智能体的基础能力(Agent Capabilities)
-
规划与多步推理(Planning & Reasoning)
评测集:数学推理【GSM8K小学数学、MATH高等数学、AQUA-RAT选择题推理】、多跳问答【HotpotQA、StrategyQA】、科学推理【ARC】、逻辑推理【FOLIO】、日常任务【MUSR】。
评测要点:任务分解、状态追踪、自我纠错、因果推断
评测Bench:ToolEmu【测试 Agent 在出错后能否调整】、PlanBench【发现 Agent 在长期规划上的短板】、NaturalPlan【用自然语言描述真实世界任务】
-
工具调用与函数使用(Tool Use)
评测要点:意图识别、工具选择、参数匹配、执行工具调用、结果整合
评测Bench:ToolBench、APIBench、BFCL【是否会调用给定的 API、调用参数是否正确】、ToolSandbox、NESTFUL【涉及多轮对话、多步嵌套调用,场景更加贴近真实复杂需求】
-
自我反思与自我纠错(Self-Reflection):
评测要点:感知新信息、信息更新、决策调整
评测思路:单步校验、多轮反馈
评测Bench:LLFBench【围绕自反性进行基准构建,测试 Agent 在多回合得到外部反馈时的能力】、ReflectionBench【从认知科学的角度,试图把「新信息识别、记忆复用、惊讶时的 belief 更新、决策调整」等拆解,构建更精细化的评测】
-
长期记忆(Memory)
评测方法:长文本阅读场景、多回合信息集成、动作 - 状态跟踪
- 特定应用领域的智能体(Application-Specific Agents)
-
网页智能体(Web Agents)
评测思路:能否正确理解网页结构、多步网页操作、安全性与合规
评测Bench:**MiniWoB、WebShop、**WebArena / Visual-WebArena【更逼真的在线购物或网页浏览环境,并包含动态变化】、AssistantBench【测试 Agent 在跨网站、多步长任务下的效率】
-
软件开发智能体(Software Engineering Agents)
评测Bench:HumanEval、MBPP【考察函数实现正确率】、SWE-bench【从真实开源项目的 issue 切片而来,提供更复杂多文件、多步骤的问题】、AgentBench【让 Agent 跟真实的开发环境或模拟环境进行多次交互,评测其多轮对话、工具调用、调试等能力】
-
科学研究智能体(Scientific Agents)
评测方法:科学知识回忆与推理、文献理解与摘要、实验设计与执行、代码生成与结果复现
-
对话式智能体(Conversational Agents)
评测Bench:ABCD、MultiWOZ、**SMCalFlow【**基于人工众包数据,涵盖了多种对话场景和功能调用】、**ALMITA【自动生成各种客户服务对话路径,然后测试 Agent 对不同对话走向的应对能力】、\tau-Bench【**人工构建了航空、零售两大典型行业场景,用模拟用户和真实数据库来考评 Agent 执行任务的正确率】、IntellAgent
- 通用型智能体(Generalist Agents)
- 综合多项能力,适用于多种复杂环境
- 开发与评测工具框架(Evaluation Frameworks)
- 各类辅助开发者持续评测智能体性能的工具与平台
Agent 开发的过程中,对每一次推理调用做记录,监控日志和输出,然后自动或人工来标注对错、分析错误原因,通常叫 Observability 或 Monitoring。
多粒度的评测:
-
最终输出 (Final Response) 评测: Agent出的最后答案是否满足需求,可使用人工或 LLM 批改;
-
逐步动作 (Stepwise) 评测
:针对 Agent 每一步对话、调用、工具执行都做结果验证,能更准确定位问题;
-
完整执行轨迹 (Trajectory) 评测:分析 Agent 从头到尾的动作序列是否合理,高级一点还能做与「最优路径」对比。
-
数据管理与标注:A/B 测试
-
可视化与比较
目前代表性的平台有 LangSmith、Langfuse、Google Vertex AI evaluation service、Arize AI、Galileo Agentic Evaluation、Patronus AI、Databricks Mosaic AI Agent Evaluation 等。
Agent的未来范式探索
斯坦福25个AI智能体「小镇」:25个AI智能体不仅能在这里上班、闲聊、social、交友,甚至还能谈恋爱,而且每个Agent都有自己的个性和背景故事。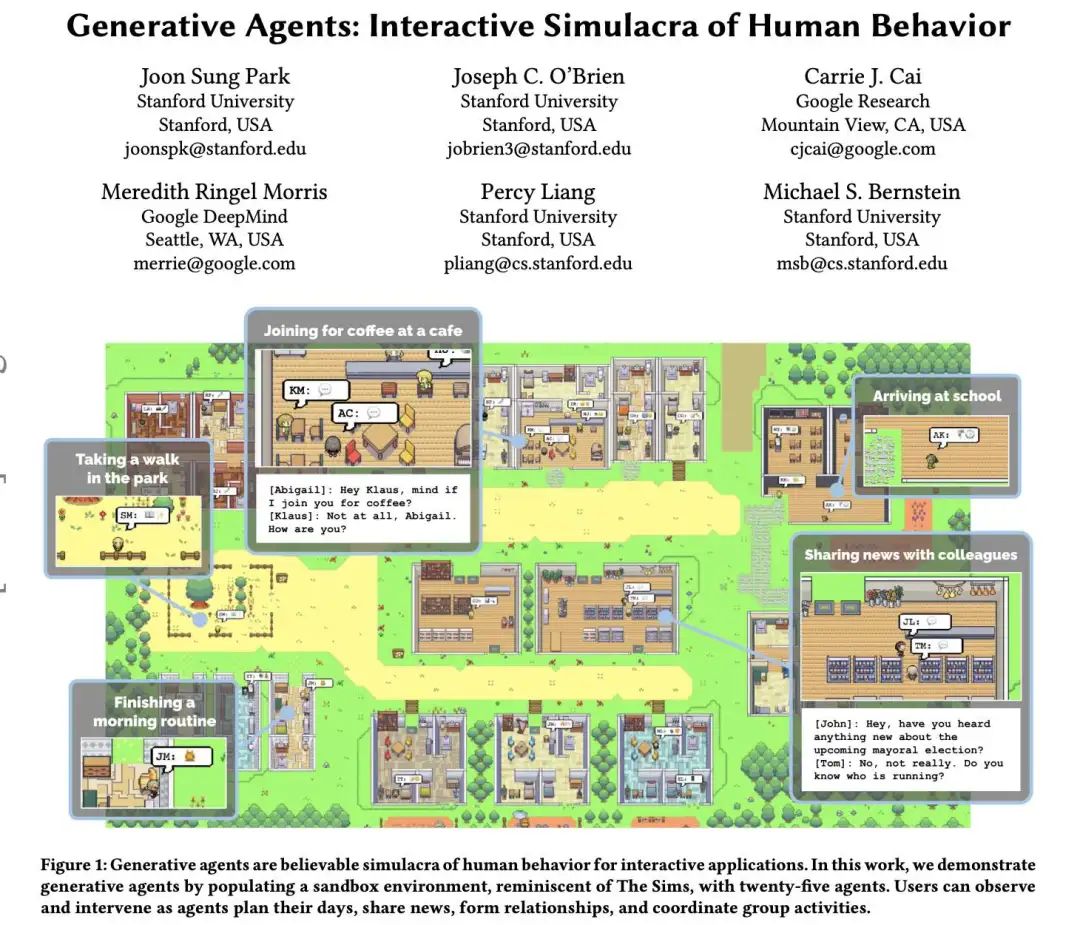
- Paper:https://arxiv.org/pdf/2304.03442
- GitHub:https://github.com/joonspk-research/generative_agents
- https://twitter.com/drjimfan/status/1689315683958652928
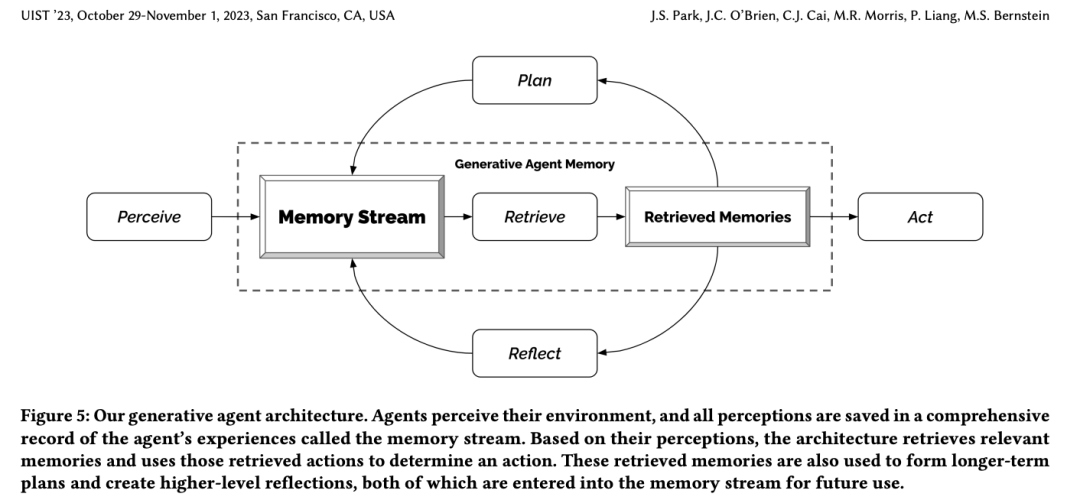
架构:
-
记忆流(Memory Stream): 长期记忆模块,以自然语言记录虚拟人个人经历的总列表。
-
思考(Reflection): 将记忆综合成具有时间序列的高级推理,使得虚拟人能够对自身和他人做出总结,以便很好地操控自身行为。
-
规划(Plan): 结论和当前环境转化为高级行动规划,然后递归地转化为详细的行为和反应。
上海人工智能实验室 OpenRobotLab 等机构的一批研究者也打造了一个虚拟小镇。
- https://arxiv.org/pdf/2407.10943

- https://arxiv.org/pdf/2503.06580
行业最流行的一句话:模型即服务
受限统一一下口径:
现阶段的开源Agent项目还是集中在流程编排智能体这个阶段,即L2,具体架构如下:
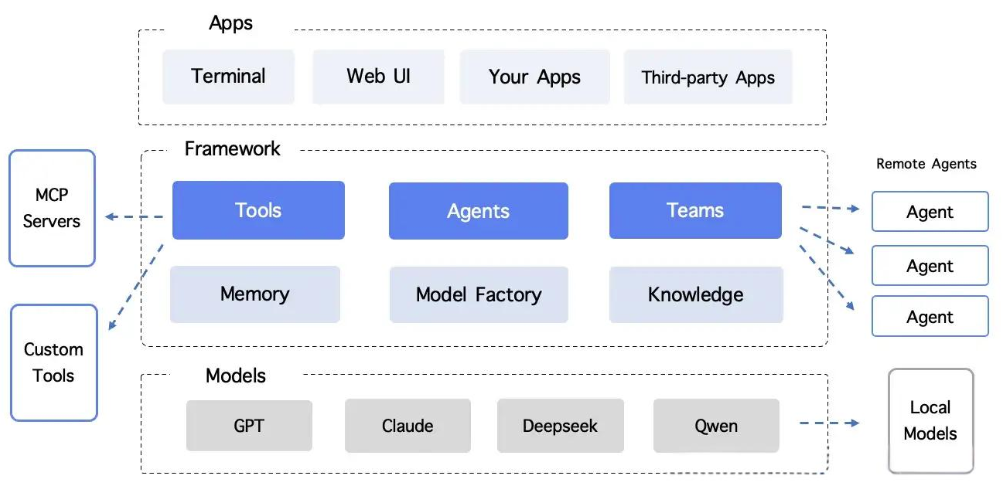
典型的当前Agent架构
非常典型的应用模式:
流程编排式:替换上一个时期的重复性功能的能力,重点聚焦于单点能力。
在对话场景,
开源Agent项目评测
短短一年,社区开源的agent项目如同雨后春笋,感叹开源大佬们精力旺盛,开源项目实在是太优秀了…,而且是乱花渐欲迷人眼,不知何从选择,从个人维度来说,方便自身快速部署、修改、使用,重要的点:
- 开源关注度:当然支持度是多多益善,代表的就是大家的认可度,但是,关注度 == 认可度 != 好产品,行业的竞争其实导致了很多的重复性产品,个人认为同质性产品差异不大,最后有没有胜出者就犹未可知了,ToB的应用并没有太大门槛,自建成本也不是很高
- 语言特性:前端、后端、算法,比如前端vue、JS、ST,如今的agent产品主打一个可拖拽,LLM的统一导致并没有太多的算法成分,唯一一个比较重的大概就是RAG了,存在一定的定制化,未来大概就是一个tool工具的存在。
- 能力范围:项目是为了解决什么样的问题,流程编排、RAG、agent等,支持的能力怎么样(阅读理解、问答、检索)。
注:个人工作范畴:算法应用,所以主要语言是python,以上仅为个人比较浅显的理解推断,非喜勿喷!!!
| 开源Project | Stars | Language | 项目简介 | 能力初评 (带*表示重点评估) | 推荐指数 (颜色表示) |
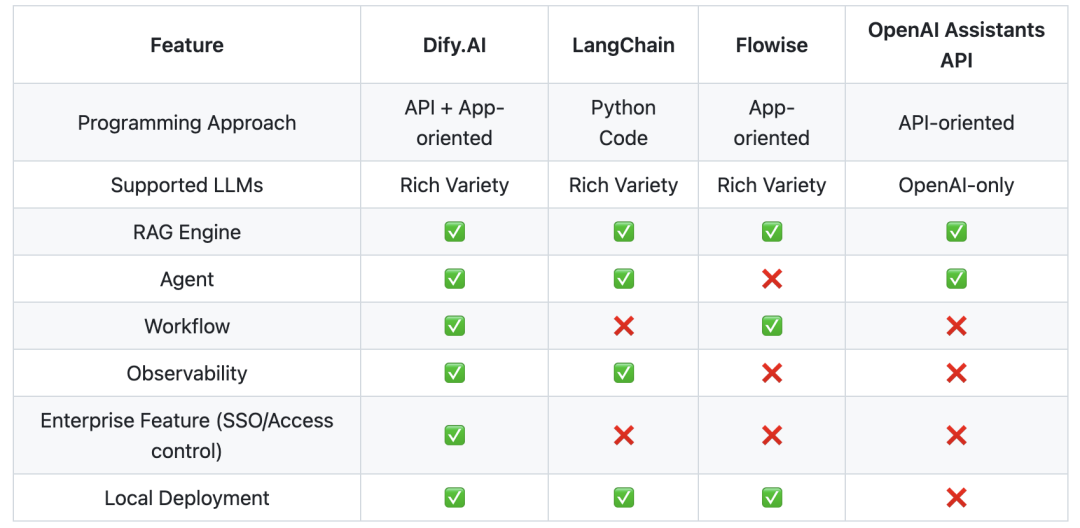
| *Dify | 96.3k | TS:56.4% PY:30.5%(算法) JS:8% | Workflow流程编排 | 目前最完备的流程编排工具(不依赖langchain+llama_index) | ★★★★★ |
| langflow | 59.7k | PY:42.2%(算法) JS: 29.7% TS: 27.2% | Workflow 对话编排工具 | 对话流程设计工具 | ★★ |
| Flowise | 36.8k | JS: 37.6% TS: 62% | Workflow流程编排 | 流程agent设计工具 | ★★ |
| FastGPT | 24k | PY:41.8%(算法) JS: 29.7% TS: 27.2% | Workflow流程编排 | RPA的架构思想 NextJs + TS + ChakraUI + MongoDB + PostgreSQL (PG Vector 插件)/Milvus | ★ |
| MaxKB | 16.5k | PY:53.2%(算法) vue: 33.1% TS: 12.4% | RAG Workflow流程编排 | 基于LangChain架构构建 | ★ |
| ragflow | 51.7k | PY:46.1% TS: 51% | Agent Workflow流程编排 | 文档RAG编排问答引擎 | ★★★ |
| *OpenHands | 54k | PY:78.6% TS: 17.4% | Code assistant | 代码助手,支持代码修改、命令行、访问网页 | ★★★★ |
| *MetaGPT | 55.4k | PY:97.5% | 纯Agent架构 | 逼近真正的Agent架构 | ★★★★★ |
| Graphrag | 25k | PY:95.7% | RAG架构 | 图谱问答top one | ★★★★ |
| anything-llm | 43.8k | JS: 97.6% | RAG架构 | 标准JS的RAG,感觉对于算法定制不太友好,前端颜值好看 | ★ |
| *quivr | 37.6k | PY:99.3% | RAG架构 | 具备记忆能力的对话问答brain,支持File问答 | ★★★★ |
| *Langchain-Chatchat | 34.5k | PY:25.3% TS:65.9% | RAG架构 | 标准的Langchain的问答 | ★ |
| *LightRAG | 13.3k | PY:76.1% TS:23.3% | RAG架构 | 标准RAG: 仅支持keyword、emb、graph三种检索,非llama_index | ★★★ |
注:①、带*号的表示有深度评估;
②、本人技术栈偏向于PY,评测会具有PY倾向;
③、注意不同颜色表示不同领域,评测仅对同领域内进行对比推荐;
附件参考:
- Dify深度评测
Code: https://github.com/langgenius/dify
项目特性:
1. Workflow: 可视化可拖拽式构建工作流.
-
Comprehensive model support: 开源LLM API接入,覆盖GPT, Mistral, Llama3, and any OpenAI 等,对于国内本地LLM支持度也不错.
-
Prompt IDE: 具备直观的ui用于chat、prompt配置等.
-
RAG Pipeline: 完善的RAG能力支持,从文档解析、处理、chunk等操作.
5. Agent capabilities: 支持自定义tool、Function Calling、ReAct、或者开源built-in tools(Google Search, DALL·E, Stable Diffusion and WolframAlpha)等.
6. LLMOps: 日志监控分析,系统的闭环反馈.
7. Backend-as-a-Service: 支持产品独立部署拆分,适用于业务.
Dify能力简述:对应用场景抽象拆分至独立子任务,借助万能的LLM,映射至抽取(参数提取)、分类(控制流转)、生成(自适应响应)算法任务维度,基于可视化的work flow进行拖拽式的流程编排。对于三类算法任务,LLM基本能够完全覆盖,兼顾到准确率和效率,
核心RAG组件:
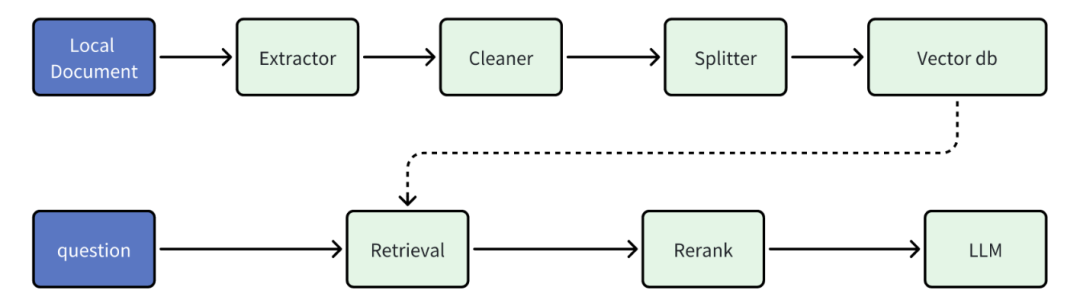
参考部署方案:
https://blog.csdn.net/u013563715/article/details/136764707
https://zhuanlan.zhihu.com/p/7851207343
**个人评测:
1、对于模型的支持(LLM\Embedding\Reranker\API\ollama)支持是最完善
2、RAG板块所有开源项目中最好的:代码结构、向量数据库、数据流处理,本人比较推荐!
3、RAG并非基于LLamaIndex实现: 在RAG的技术深度上,个人认为有所欠缺,同时,由于整个代码耦合度很高,改造比较困难,依赖modelInstance和LB;
4、标准的工作流制造工具,非Agent形态;
5、多模态的交互支持比较一般,主要用于企业级的RPA-Agent构建很成熟,接入第三方IM一般;
6、暂不支持MCP**
- langflow深度评测
Code: https://github.com/langflow-ai/langflow
项目特性:
1. Visual Builder:to get started quickly and iterate.
2. Access to Code:so developers can tweak any component using Python.
3. Playground:to immediately test and iterate on their flows with step-by-step control.
4. Multi-agent:orchestration and conversation management and retrieval.
5. Deploy as an API:or export as JSON for Python apps.
6. Observability:with LangSmith, LangFuse and other integrations.
7. Enterprise-ready:security and scalability.
**个人评测:
1、LangFlow 是一个,它专注于对话流程的可视化设计和管理;
-
直观的界面和工具,可以帮助开发者设计和管理对话流程,包括对话节点、条件逻辑和回复等。
-
LangFlow 还支持多语言和多渠道的对话流程设计;
**4. 整体上和Fowise其实比较接近,场景侧重点有所不同,langflow只想干好对话,所以基本不支持RAG。
- 应用可参考下面的设计案例,就是一个RAP的流程编排…****
具体可参考:https://docs.langflow.org/
WorkFlow设计案例
包含chat输入、Prompt、OpenApi、chat输出、文件加载等组件
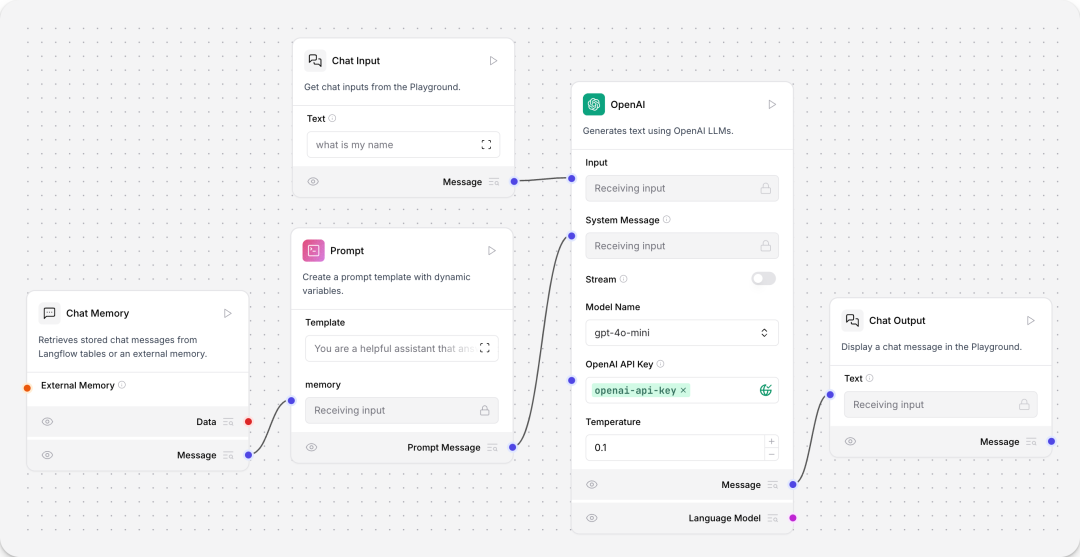
对话机器人:增加了chat memory组件,支持历史信息的思考逻辑
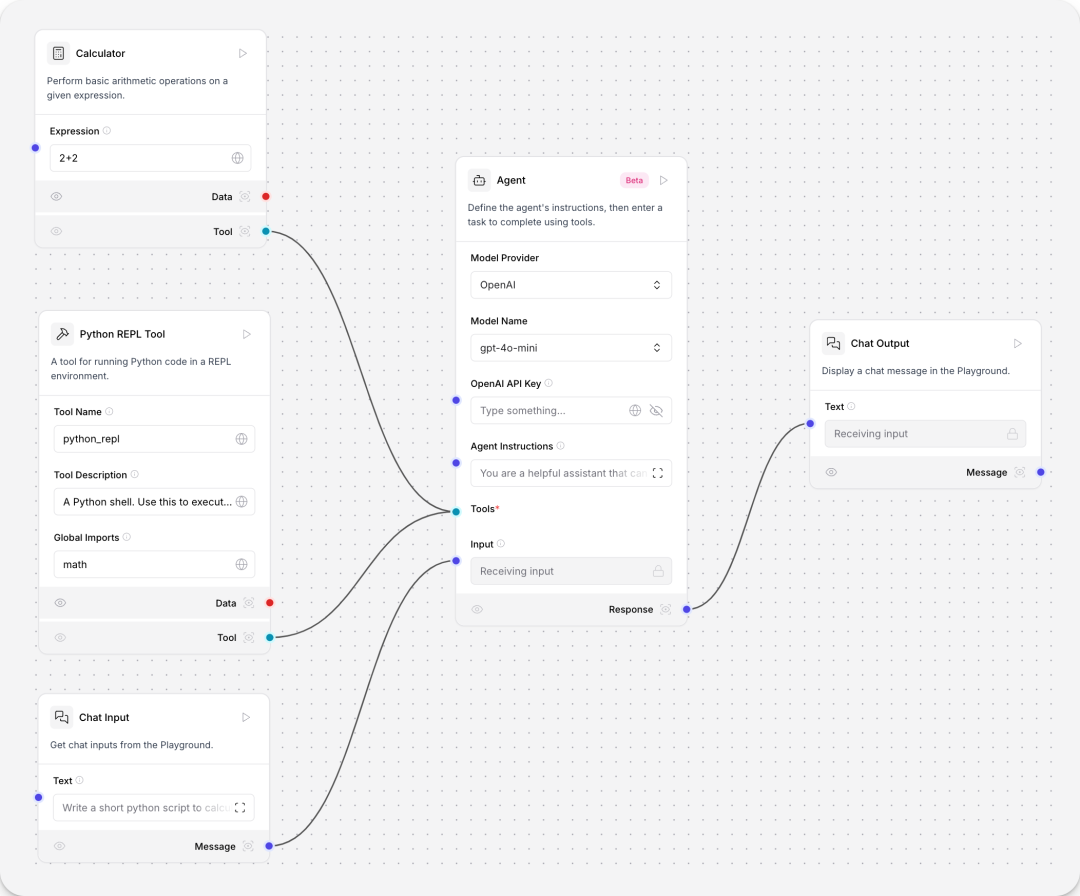
数学agent,在对话机器人的基础上新增tool calling agent、Python REPL tool、Calculator组件。
序列任务agent(任务编排器,针对具体场景定制),在对话机器人的基础上新增YFinance tool、Tavily AI Search tool、Calculator tool 组件。
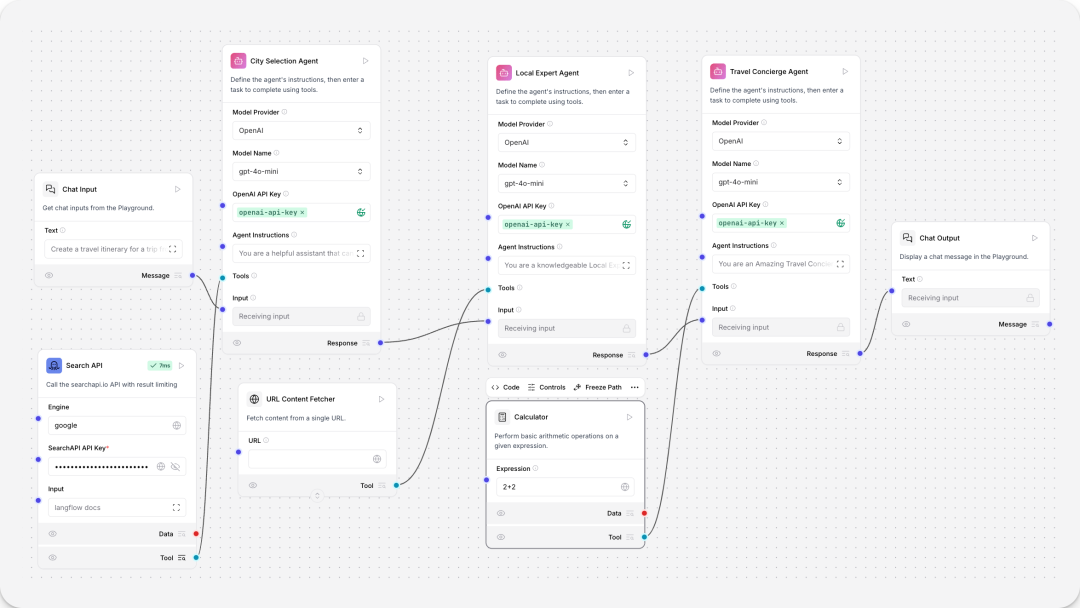
旅行agent,在对话机器人的基础上新增tool calling agent、Python REPL tool、Calculator组件。
- Flowise深度评测
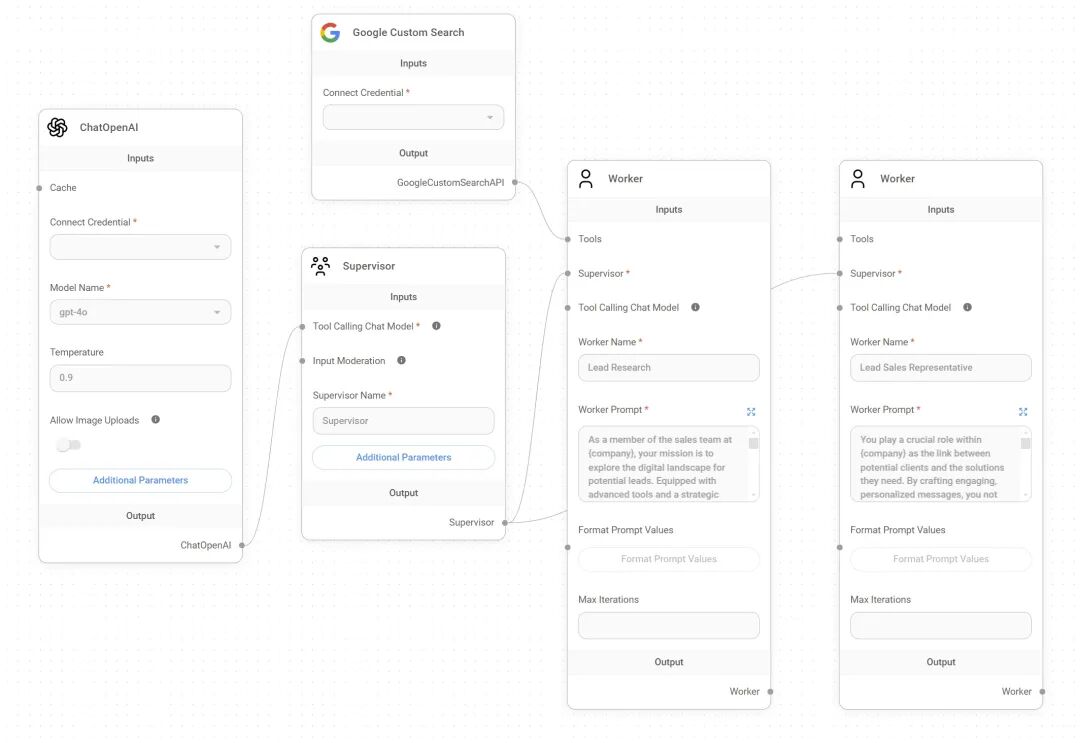 项目特性:
项目特性:
- Multi-Agents:简单的来说就是 LLM + FuncCalling,基于supervisor进行选择agent进行跳转和任务执行;
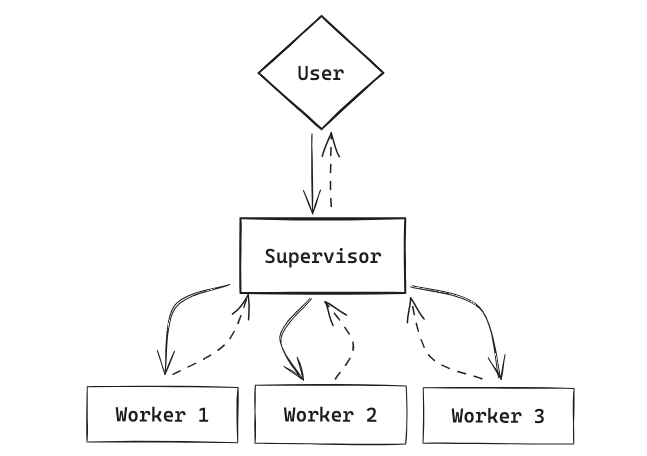
-
Sequential Agents:利用LLM的推理能力、FuncCalling能力、rag能力等,根据具体小场景的预设流程进行自动跳转;
-
Flowise的整个后台能力支持多workspace管理;
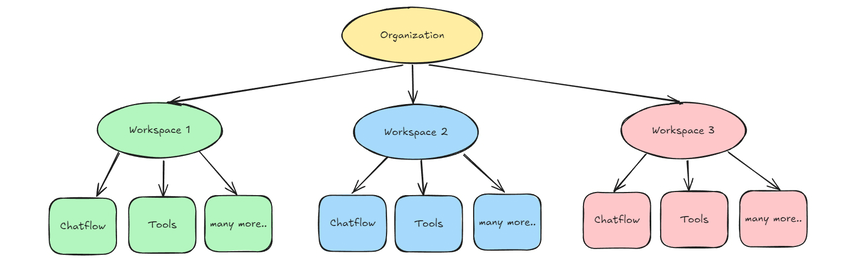
-
对义变量设计;
-
支持images, audio, and other files的问答,主要借助OpenAI LLM的能力;
…(主要基于JS+TS构建,在工程设计上应该很多投入,不在我的关注范围上,太复杂😂)
个人评测:
-
项目基于LLM的语义理解能力,聚焦解决简单的RPA工作,就是agent的能力都包含,但都不是那么有指向,通用型的RAP agent 对话编排工具;
-
支简单RAG(内存型),用于支持agent问答中的文档内检索,如paper问答;
-
语义理解和对话管理功能,可以处理复杂的对话场景,并支持多轮对话和上下文理解;
-
支持预训练的模型和工具,可以加速对话系统的开发过程;
具体可参考:https://docs.flowiseai.com/using-flowise
- FastGPT深度评测
Code: https://github.com/labring/FastGPT
FastGPT通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景.
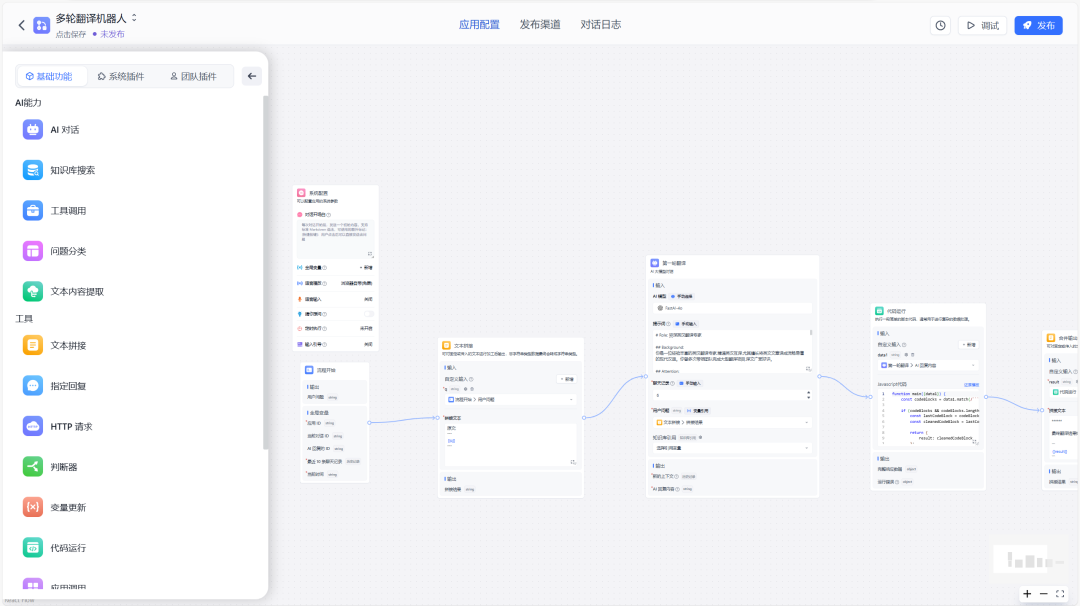
评测结论:
1、整个后端基于TS构建,py负责模型加载部分工作
推荐阅读:
①、https://doc.tryfastgpt.ai/docs/intro/
②、企业微信/飞书接入(Laf + FastGPT 把AI知识库装进企业微信): https://www.bilibili.com/video/BV1Tp4y1n72T/?spm_id_from=333.999.0.0&vd_source=5526e4b54a23d0b2af7aca06ec8c6f36
- MetaGPT深度评测
Code: https://github.com/geekan/MetaGPT
Multi-Agent Framework:
-
MetaGPT takes a one line requirement as input and outputs user stories / competitive analysis / requirements / data structures / APIs / documents, etc.
-
Internally, MetaGPT includes product managers / architects / project managers / engineers. It provides the entire process of a software company along with carefully orchestrated SOPs.
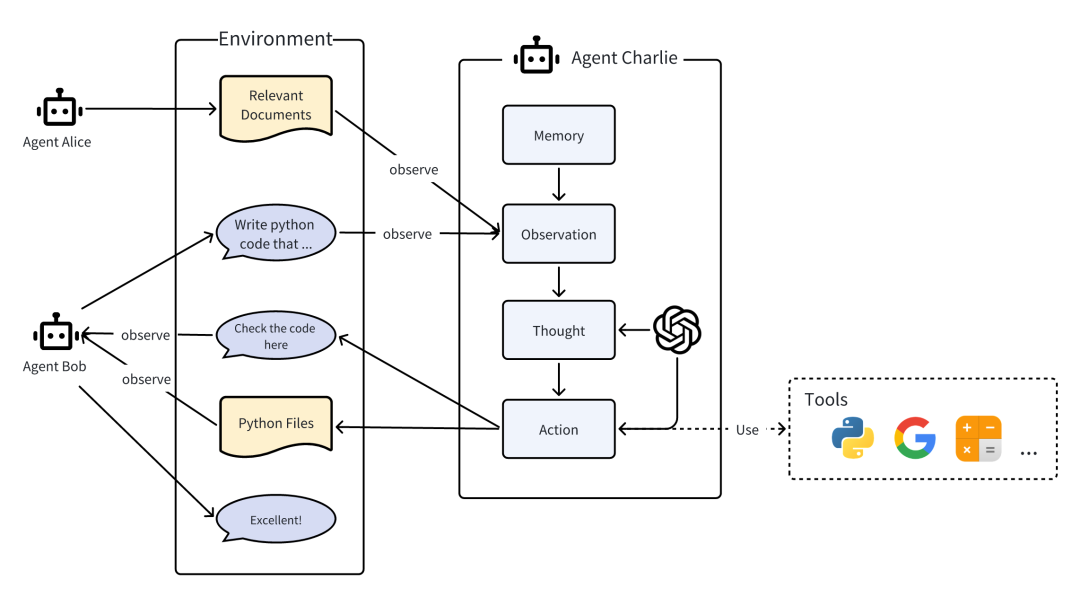
智能体 = 大语言模型(LLM) + 观察 + 思考 + 行动 + 记忆
多智能体 = 智能体 + 环境 + 标准流程(SOP) + 通信 + 经济
能力介绍:
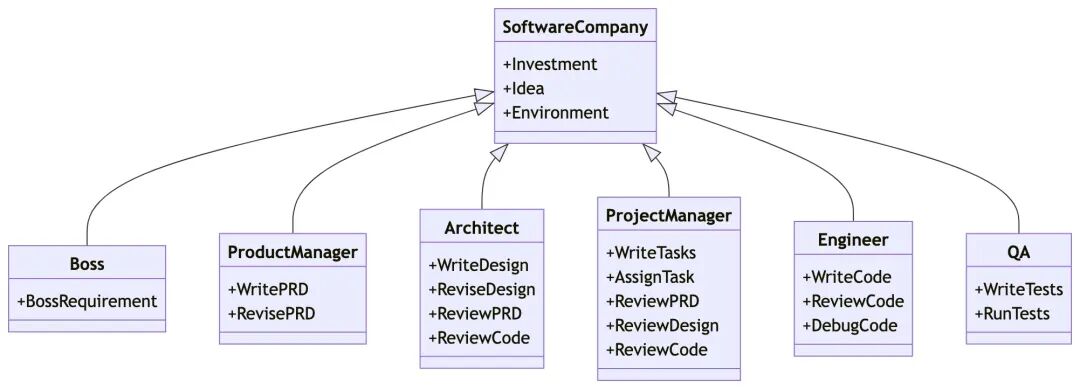
系统主要接口能力:
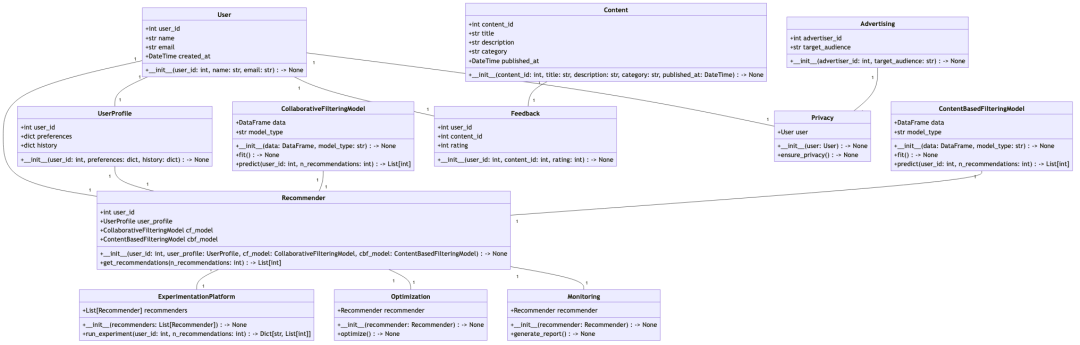
内部机制:
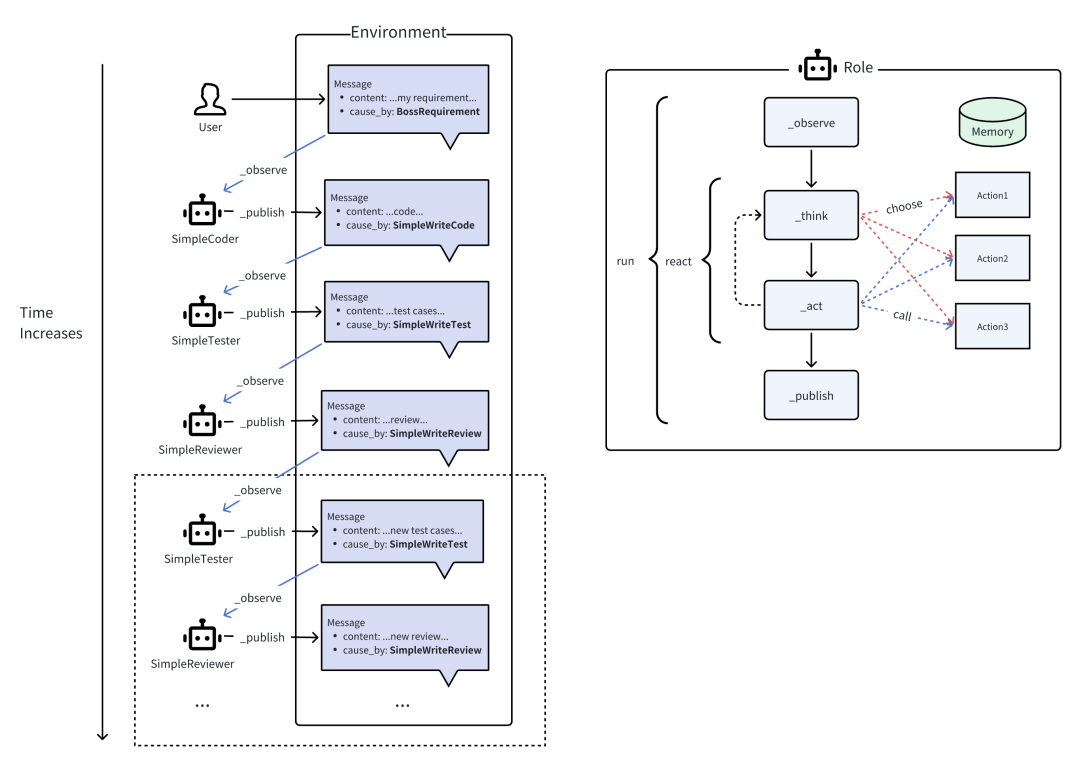
多Agent实例:
个人评测:**1、依托GPT-4的能力构建助手;支持发布为openai兼容的接口(除ollama外)但需要做改动,
不支持直接本地化部署调用;**
2、Agent/Multi-Agent架构,依托LLM本身的语义理解能力进行多轮交互;
3、问答模式,对于多模态场景的支持比较弱;
4、基本python实现,整个架构比较清晰;
5、有点接近终极Agent架构:非流程编排式的workflow, agent大脑设计模式;
狼人杀:https://github.com/geekan/MetaGPT/tree/main/metagpt/environment/werewolf
斯坦福小镇:https://github.com/geekan/MetaGPT/tree/main/metagpt/environment/stanford_town
安卓模拟器:https://github.com/geekan/MetaGPT/tree/main/metagpt/environment/android
- maxKB深度评测
CODE: https://github.com/1Panel-dev/MaxKB
基于RAG pipeline构建的一个知识问答编排器,重点是以RAG为核心构建,利用LLM的prompt生成能力构建RPA的自动化助手。
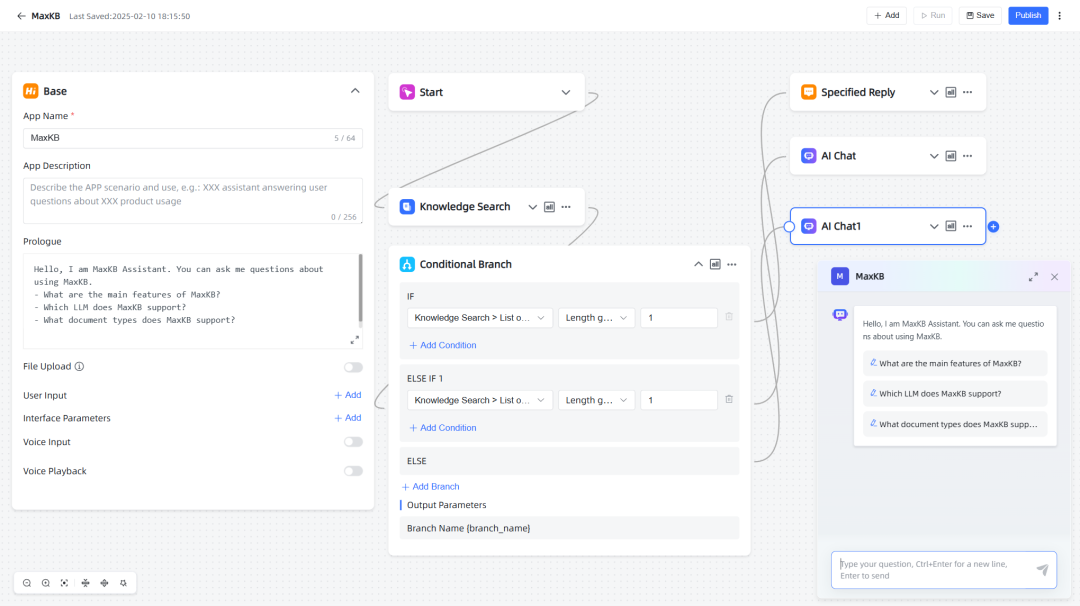
特性说明:
- RAG pipeline: 说是支持文档的splitting,向量化,但是从源码上看,其能力支持一般,比如splitting、vector支持度都比较一般
2. Agentic Workflow:流程编排能力
3. Seamless Integration:…没啥用
4. Model-Agnostic: …大家都有
5. Multi Modal: support for input and output text, image, audio and video.
个人评测:
1. 不支持自定义变量、FuncCalling,能力比较受限;
2. RAG本身能力其实也不够深入;
- Langchain-Chatchat深度评测
code: https://github.com/chatchat-space/Langchain-Chatchat
依托于 langchain 框架支持通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI进行操作。
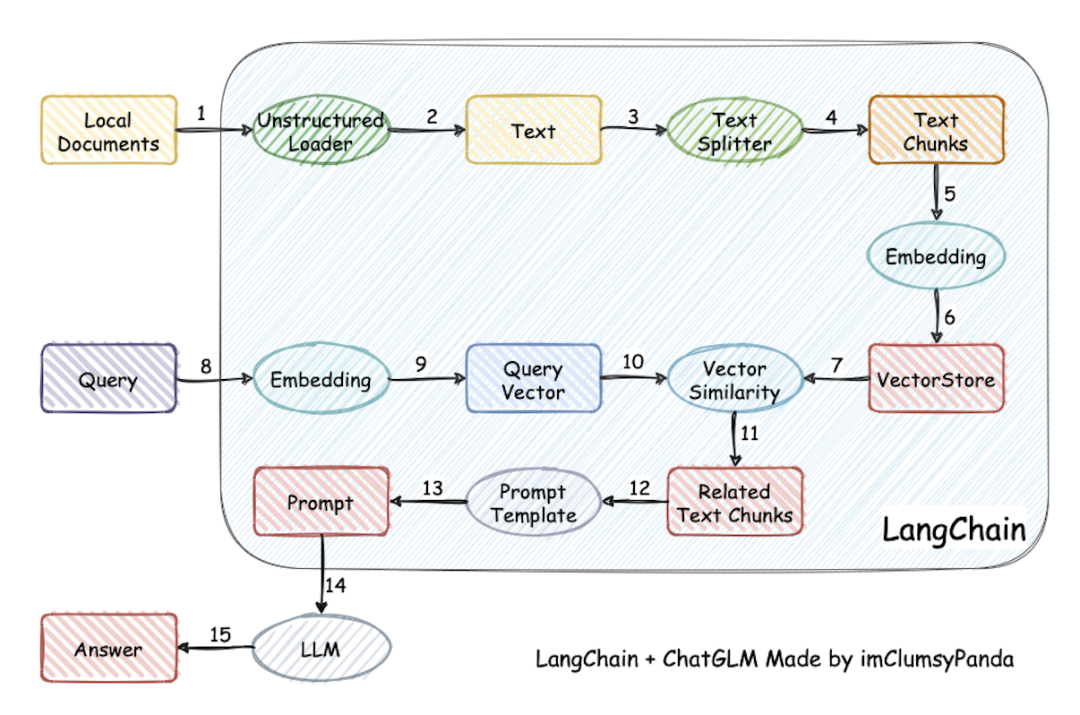
项目特性:
- 可使用 Xinference、Ollama 等框架接入 GLM-4-Chat、 Qwen2-Instruct、 Llama3 等模型
2.主流的开源 LLM、 Embedding 模型与向量数据库,可实现全部使用开源模型离线私有部署。
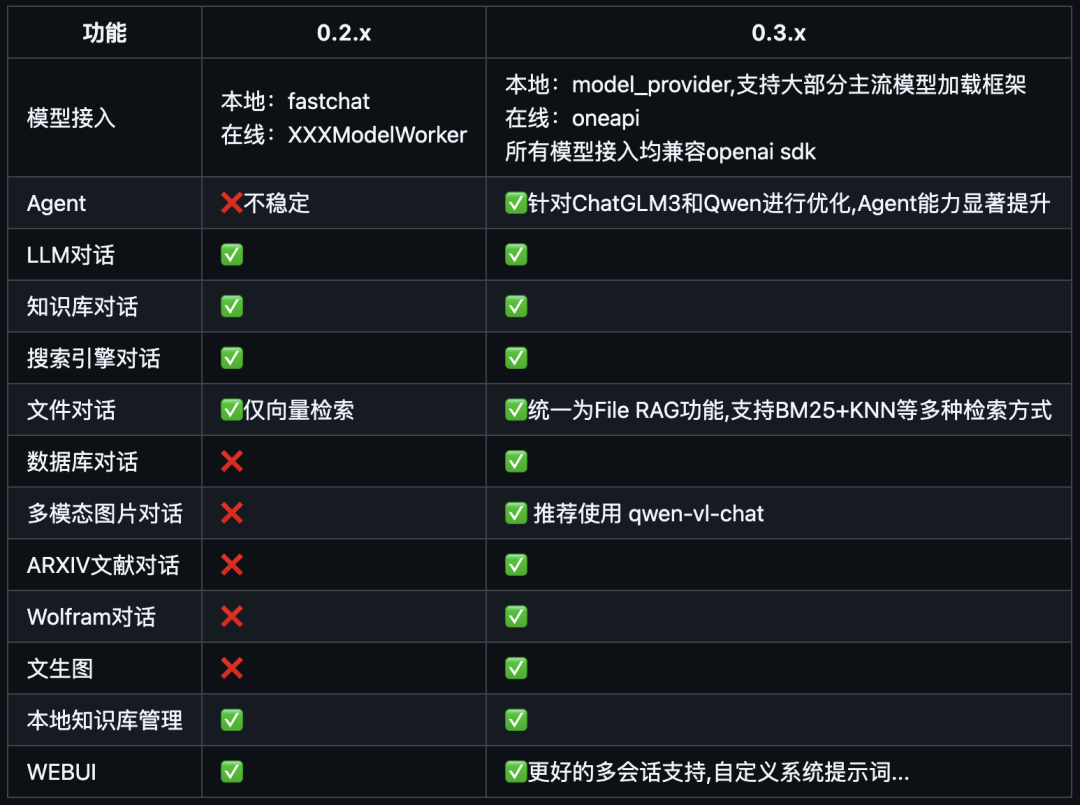
- 从 0.3.0 版本起,Langchain-Chatchat 不再根据用户输入的本地模型路径直接进行模型加载,涉及到的模型种类包括 LLM、Embedding、Reranker 及后续会提供支持的多模态模型等,均改为支持市面常见的各大模型推理框架接入,如 Xinference、Ollama、LocalAI、FastChat、One API 等。
个人评测:**1、本质上还是一个对话RAG能力的实现;
2.基于标准的langchain插件实现(标准版);**
- anything-llm深度评测
code: https://github.com/Mintplex-Labs/anything-llm
全栈的RAG应用。
项目特性:
-
支持MCP;
-
支持多模态问答
-
集成了多用户权限管理;
-
标准RAG能力栈:文档切片、向量化、LLM等
-
官方表示在产品化上很强:部署、云端、ui等
-
支持TTS、ASR的接入
个人评测:
-
简化版的流程编排Agent,以JS为主要开发语言的同学可以重点研究一下
-
向量数据库支持偏弱,毕竟不是为国人开源的
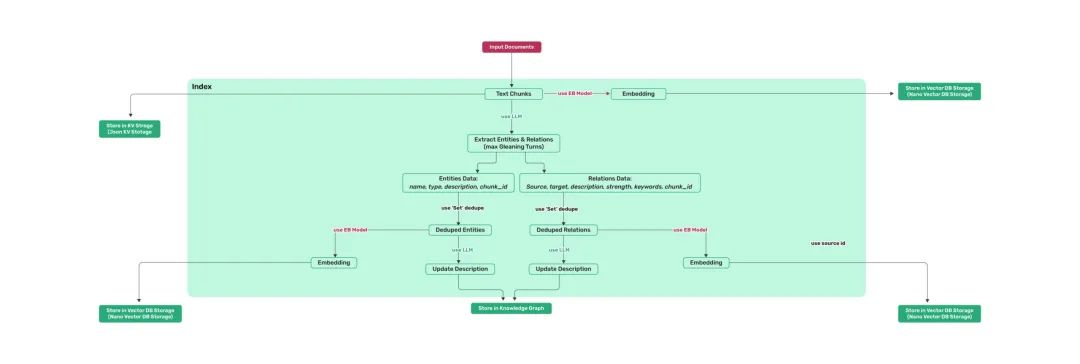
- LightRAG深度评测
code: https://github.com/HKUDS/LightRAG
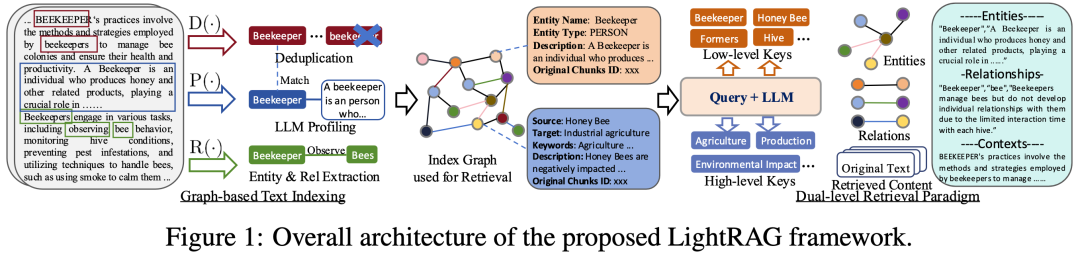
全栈的RAG应用。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献202条内容
已为社区贡献202条内容

所有评论(0)