MySQL 完整学习手册:SQL 操作、索引设计与进阶优化实战
本文系统介绍了MySQL数据库的核心SQL操作与优化策略。主要内容包括:1)基础SQL语法规则与数据类型;2)数据库和表的创建、修改等DDL操作;3)数据增删改查等DML/DQL操作;4)索引与视图的创建与使用;5)电商和企业管理系统等实战案例;6)SQL性能优化方法与EXPLAIN分析工具。文章详细讲解了SQL语句的规范写法、索引优化策略、查询性能提升技巧等核心内容,并通过实际案例展示了SQL在
一、引言
1.1 MySQL 与 SQL 语句概述
MySQL作为一个功能强大、稳定可靠且经济高效的关系型数据库,在现代软件开发中扮演着不可或缺的角色。而SQL作为其唯一的标准化交互语言,不仅是操作数据的工具,更是构建和管理整个数据体系的蓝图。理解并熟练运用SQL,是任何希望深入掌握MySQL乃至数据库技术的开发者和数据分析师的必备技能。正是SQL与MySQL的完美结合,才使得管理和利用海量数据变得如此高效和有序。
1.2 研究目的和意义
学习SQL语法如同学习单词,而深入学习SQL则如同掌握语法、修辞和创作思想。它不仅仅是一门技术,更是一种思维方式——一种以集合论和关系模型来分析和解决现实世界问题的方式。
在当今数据驱动的时代,无论是在业务开发、数据分析、系统架构还是运维管理中,对MySQL SQL的深度理解,都不是一个可选项,而是一个核心竞争力。它让你能从数据库的“黑盒”使用者,转变为能够洞察其内部运作、并最大化其价值的核心技术专家。投资时间深入学习SQL,必将为你的技术生涯带来长期而丰厚的回报。
二、MySQL SQL 语句基础
2.1 SQL 通用语法规则
一、 大小写规范
大小写规范是 SQL 书写中最引人注目的一点,其核心原则是:增强可读性,区分关键字与数据。
1. 关键字使用大写
SQL 的关键字(如 SELECT, FROM, WHERE, INSERT, UPDATE, DELETE, JOIN, AS, ORDER BY, GROUP BY 等)建议使用大写。
-
作用:将关键字与表名、列名等标识符 visually 区分开,使 SQL 的结构一目了然,便于快速阅读和调试。
-
示例:
sql
-- 推荐 SELECT first_name, last_name FROM employees WHERE department_id = 10 ORDER BY hire_date DESC; -- 不推荐 (可读性差) select first_name, last_name from employees where department_id = 10 order by hire_date desc;
2. 数据库对象名使用小写和下划线
数据库、表、列、索引、别名等名称建议使用小写,并使用下划线 分隔单词。
-
作用:
-
跨平台兼容性:在 Linux/Unix 系统中,MySQL 默认是大小写敏感的,而在 Windows 上则不敏感。统一使用小写可以避免因系统迁移导致“表不存在”的错误。
-
清晰易读:下划线分隔比驼峰命名法在 SQL 中更常见、更清晰。
-
-
示例:
sql
-- 推荐 SELECT user_id, phone_number, created_at FROM user_accounts; -- 不推荐 (驼峰命名,在大小写敏感环境中可能有问题) SELECT userId, phoneNumber, createdAt FROM UserAccounts;
3. 特定常量按需使用
对于特定常量,如字符串,保持其原有大小写。对于 NULL、布尔值(TRUE/FALSE),通常使用大写。
-
示例:
sql
UPDATE products SET status = 'out_of_stock', last_checked = NULL WHERE stock_count = 0;
二、 注释规范
注释是代码的“说明书”,良好的注释习惯对团队协作和后期维护至关重要。
1. 单行注释
-
--(两个破折号和一个空格):用于注释单行。sql
-- 计算活跃用户数量 SELECT COUNT(*) AS active_users FROM users WHERE last_login_date >= CURDATE() - INTERVAL 30 DAY; -- 最近30天内有登录
-
#(井号):MySQL 特有的单行注释方式,但不属于 SQL 标准,为保持通用性,推荐优先使用--。
2. 多行注释
-
/* ... */:用于注释多行或代码块。常用于注释掉大段代码或进行详细的函数说明。sql
/* * 功能:获取本季度销售冠军及其业绩 * 作者:张三 * 创建日期:2023-10-27 */ SELECT e.employee_name, SUM(s.amount) AS total_sales FROM sales s JOIN employees e ON s.employee_id = e.id WHERE s.sale_date BETWEEN '2023-10-01' AND '2023-12-31' GROUP BY e.employee_name ORDER BY total_sales DESC LIMIT 1;
三、 语句结束符
在 MySQL 命令行客户端或一些数据库管理工具中,语句结束符用于告诉客户端一条 SQL 语句已经输入完毕,可以执行了。
-
标准结束符:分号
;
这是最常用、最标准的 SQL 语句结束符。每条独立的 SQL 语句结束时都应使用分号。sql
DELETE FROM temp_logs WHERE created_at < '2023-01-01'; INSERT INTO audit_trail (message) VALUES ('Old logs cleaned up.'); -
自定义结束符:
DELIMITER
在定义存储过程、函数、触发器等包含多条 SQL 语句的数据库对象时,这些对象体内部本身就有很多分号。为了不让客户端误解,需要临时更改结束符。sql
-- 将结束符临时改为 // DELIMITER // CREATE PROCEDURE ClearExpiredData() BEGIN -- 过程体内部有多个分号,但不会被立即执行 DELETE FROM sessions WHERE expires_at < NOW(); DELETE FROM cache WHERE valid_until < NOW(); END // -- 过程定义完毕,使用新的结束符//来执行上面的CREATE语句 -- 将结束符改回标准的分号 DELIMITER ;
四、 其他重要排版与格式化规范
除了上述三点,以下规范同样重要:
-
子句缩进与换行:每个主要关键字(如 SELECT, FROM, WHERE, JOIN, ORDER BY)都应开始一个新行,并左对齐。子句中的内容应进行缩进。
sql
-- 推荐 SELECT u.username, COUNT(o.id) AS order_count FROM users u LEFT JOIN orders o ON u.id = o.user_id WHERE u.country = 'CN' AND u.created_at > '2023-01-01' GROUP BY u.username HAVING order_count > 5 ORDER BY order_count DESC; -
逗号的位置:推荐使用行尾逗号,这样在添加或删除列时,差异更清晰。
sql
SELECT id, name, email, -- 注意这里的逗号在行尾 FROM users; -
使用空格:在运算符、逗号周围使用空格,增强可读性。
sql
-- 推荐 WHERE salary > 5000 AND department_id = 10; -- 不推荐 WHERE salary>5000 AND department_id=10;
总结
遵循统一的 SQL 书写规范,其价值在于:
-
提升可读性:结构清晰的代码如同排版优美的文章,让人一目了然。
-
便于团队协作:统一的规范减少了理解偏差和风格之争。
-
易于调试与维护:当出现问题时,格式规范的 SQL 能让你更快地定位到错误所在。
-
体现专业性:细节决定成败,规范的代码是开发者专业精神的体现。
2.2 数据类型详解
**MySQL 常见数据类型**
**一、数值类型**
1. **INT**
- 特点:整数,4字节,范围约±21亿。
- 场景:年龄、数量、ID等整数数据。
2. **BIGINT**
- 特点:大整数,8字节,范围更大。
- 场景:自增主键、大范围计数。
3. **DECIMAL(M,N)**
- 特点:精确小数,M总位数,N小数位。
- 场景:金额、精确计算(避免浮点误差)。
4. **FLOAT / DOUBLE**
- 特点:近似浮点数,存在精度损失。
- 场景:科学计算、非精确测量。
---
**二、字符串类型**
1. **CHAR(N)**
- 特点:定长字符串,长度固定,效率高。
- 场景:固定长度数据(如身份证号、MD5哈希)。
2. **VARCHAR(N)**
- 特点:变长字符串,按实际长度存储。
- 场景:可变长度文本(如用户名、地址)。
3. **TEXT**
- 特点:长文本数据,最大支持65KB。
- 场景:文章内容、日志等大段文本。
**三、日期时间类型**
1. **DATE**
- 特点:仅存储日期('YYYY-MM-DD')。
- 场景:生日、注册日期。
2. **DATETIME**
- 特点:日期+时间('YYYY-MM-DD HH:MM:SS')。
- 场景:记录创建时间、订单时间。
3. **TIMESTAMP**
- 特点:时间戳,4字节,自动转换时区。
- 场景:记录更新时间、国际化系统。
---
**选择建议**
- **整数**:优先选INT,大范围用BIGINT。
- **小数**:精确计算用DECIMAL,科学计算用FLOAT。
- **字符串**:定长用CHAR,变长用VARCHAR,大文本用TEXT。
- **时间**:仅日期用DATE,需时间用DATETIME,跨时区用TIMESTAMP。
2.3 数据库与表的基本操作
2.3.1 数据库的创建、选择与删除
**1. CREATE DATABASE**
**作用**:创建新数据库
**语法**:
```sql
CREATE DATABASE 数据库名;
```
**示例**:
```sql
CREATE DATABASE shop; -- 创建名为shop的数据库
```
**注意事项**:
- 数据库名不能重复,否则会报错
- 可使用 `IF NOT EXISTS` 避免重复创建错误:
```sql
CREATE DATABASE IF NOT EXISTS shop;
```
---
**2. USE**
**作用**:选择要操作的数据库
**语法**:
```sql
USE 数据库名;
```
**示例**:
```sql
USE shop; -- 切换到shop数据库
```
**注意事项**:
- 执行SQL前必须先USE数据库
- 不USE数据库直接操作表会报错
- 切换后所有操作都在该数据库中进行
---
### **3. DROP DATABASE**
**作用**:删除数据库
**语法**:
```sql
DROP DATABASE 数据库名;
```
**示例**:
```sql
DROP DATABASE shop; -- 删除shop数据库
```
**注意事项**:
- ⚠️ **数据将永久删除,不可恢复**
- 数据库必须存在,否则报错
- 可使用 `IF EXISTS` 安全删除:
```sql
DROP DATABASE IF EXISTS shop;
```
---
**完整操作流程**:
```sql
-- 1. 创建数据库
CREATE DATABASE mydb;
-- 2. 使用数据库
USE mydb;
-- 3. 在此数据库中创建表等操作...
-- 4. 删除数据库(谨慎使用!)
DROP DATABASE mydb;
```
**重要提醒**:
- **DROP操作极其危险**,生产环境务必备份
- 权限要求:需要相应的CREATE/DROP权限
- 删除前确保没有活跃连接
2.3.2 表的创建、查看与删除
**MySQL 表操作语句**
**1. CREATE TABLE**
**功能**:创建新表
**语法**:
```sql
CREATE TABLE 表名 (
列名1 数据类型 [约束],
列名2 数据类型 [约束],
...
);
```
**示例**:
```sql
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
```
**注意事项**:
- 表名不能重复
- 需定义列名、数据类型和约束
- 可使用 `IF NOT EXISTS` 避免重复创建
---
**2. SHOW TABLES**
**功能**:显示当前数据库中的所有表
**语法**:
```sql
SHOW TABLES;
```
**示例**:
```sql
USE shop;
SHOW TABLES; -- 显示shop数据库中的所有表
```
**注意事项**:
- 必须先 `USE` 选择数据库
- 显示的是表名列表,不包含表结构
---
**3. DESC**
**功能**:查看表结构信息
**语法**:
```sql
DESC 表名;
-- 或
DESCRIBE 表名;
```
**示例**:
```sql
DESC users; -- 查看users表的结构
```
**显示信息包括**:
- Field:字段名
- Type:数据类型
- Null:是否允许NULL
- Key:索引类型
- Default:默认值
- Extra:额外信息(如自增)
---
**4. DROP TABLE**
**功能**:删除表
**语法**:
```sql
DROP TABLE 表名;
```
**示例**:
```sql
DROP TABLE users; -- 删除users表
```
**注意事项**:
- ⚠️ **表数据和结构将永久删除**
- 可使用 `IF EXISTS` 安全删除:
```sql
DROP TABLE IF EXISTS users;
```
- 可同时删除多个表:
```sql
DROP TABLE table1, table2, table3;
```
---
**完整操作流程**:
```sql
-- 1. 选择数据库
USE mydb;
-- 2. 创建表
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(100),
score DECIMAL(5,2)
);
-- 3. 查看所有表
SHOW TABLES;
-- 4. 查看表结构
DESC students;
-- 5. 删除表(谨慎!)
DROP TABLE students;
```
**重要提醒**:
- **DROP TABLE 不可逆**,操作前务必确认
- 生产环境建议先备份再删除
- 外键关联的表需特别注意删除顺序
2.3.3 表结构的修改
**ALTER TABLE 语句使用**
**1. 添加字段**
**语法**:
```sql
ALTER TABLE 表名 ADD 列名 数据类型 [约束];
```
**示例**:
```sql
ALTER TABLE users ADD email VARCHAR(100); -- 添加email字段
ALTER TABLE users ADD phone VARCHAR(20) NOT NULL; -- 添加非空字段
```
**2. 修改字段**
**语法**:
```sql
ALTER TABLE 表名 MODIFY 列名 新数据类型 [新约束];
```
**示例**:
```sql
ALTER TABLE users MODIFY name VARCHAR(100); -- 修改字段长度
ALTER TABLE users MODIFY age INT NOT NULL; -- 修改约束
```
**3. 删除字段**
**语法**:
```sql
ALTER TABLE 表名 DROP 列名;
```
**示例**:
```sql
ALTER TABLE users DROP phone; -- 删除phone字段
```
**注意**:数据将永久丢失
**4. 修改表名**
**语法**:
```sql
ALTER TABLE 原表名 RENAME TO 新表名;
-- 或
RENAME TABLE 原表名 TO 新表名;
```
**示例**:
```sql
ALTER TABLE users RENAME TO customers; -- 修改表名
```
**其他常用操作**
**添加主键**:
```sql
ALTER TABLE users ADD PRIMARY KEY (id);
```
**添加索引**:
```sql
ALTER TABLE users ADD INDEX idx_email (email);
```
**修改字段名**:
```sql
ALTER TABLE users CHANGE 原列名 新列名 数据类型;
```
**完整示例**:
```sql
-- 创建表
CREATE TABLE users (id INT, name VARCHAR(50));
-- 添加字段
ALTER TABLE users ADD age INT;
-- 修改字段
ALTER TABLE users MODIFY name VARCHAR(100);
-- 删除字段
ALTER TABLE users DROP age;
-- 修改表名
ALTER TABLE users RENAME TO customers;
```
**注意事项**:
- 修改大表时可能锁表,影响性能
- 删除字段前确认数据不再需要
- 修改数据类型需兼容现有数据
三、数据操作语言(DML)
3.1 数据插入(INSERT)
**INSERT INTO 语句用法**
**1. 指定字段插入**
**语法**:
```sql
INSERT INTO 表名 (字段1, 字段2, ...)
VALUES (值1, 值2, ...);
```
**示例**:
```sql
INSERT INTO users (name, age, email)
VALUES ('张三', 25, 'zhangsan@email.com');
```
**特点**:
- 只插入指定字段
- 未指定字段使用默认值或NULL
- 字段顺序可以任意
---
**2. 全字段插入**
**语法**:
```sql
INSERT INTO 表名
VALUES (值1, 值2, 值3, ...);
```
**示例**:
```sql
INSERT INTO users
VALUES (1, '李四', 30, 'lisi@email.com');
```
**特点**:
- 必须为所有字段提供值
- 值的顺序必须与表结构完全一致
- 字段较多时容易出错
---
**3. 批量插入**
**语法**:
```sql
INSERT INTO 表名 (字段1, 字段2, ...)
VALUES
(值1, 值2, ...),
(值1, 值2, ...),
...;
```
**示例**:
```sql
INSERT INTO users (name, age, email)
VALUES
('王五', 28, 'wangwu@email.com'),
('赵六', 35, 'zhaoliu@email.com'),
('孙七', 22, 'sunqi@email.com');
```
**特点**:
- 一次插入多条记录
- 效率远高于多次单条插入
- 减少数据库连接开销
**其他用法**
**插入查询结果**:
```sql
INSERT INTO user_backup (name, age)
SELECT name, age FROM users WHERE age > 30;
```
**使用默认值**:
```sql
INSERT INTO users (name) VALUES ('默认用户');
-- 其他字段使用默认值或NULL
```
**完整示例**
**表结构**:
```sql
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT,
email VARCHAR(100)
);
```
**插入操作**:
```sql
-- 1. 指定字段插入
INSERT INTO users (name, age, email)
VALUES ('张三', 25, 'zhangsan@email.com');
-- 2. 全字段插入(需知道所有字段)
INSERT INTO users
VALUES (NULL, '李四', 30, 'lisi@email.com');
-- 3. 批量插入
INSERT INTO users (name, age, email)
VALUES
('王五', 28, 'wangwu@email.com'),
('赵六', 35, 'zhaoliu@email.com');
```
**注意事项**:
- 字符串和日期值需要用单引号
- 确保值的类型与字段类型匹配
- 批量插入时,一条失败可能影响整批
- 自增字段可以省略或使用NULL/DEFAULT
3.2 数据更新(UPDATE)
**UPDATE 语句用法**
**基本语法**
```sql
UPDATE 表名
SET 字段1 = 值1, 字段2 = 值2, ...
[WHERE 条件];
```
---
**1. 更新所有记录**
**语法**:不加 WHERE 条件
**示例**:
```sql
-- 将所有商品价格提高10%
UPDATE products SET price = price * 1.1;
-- 将所有用户状态设为激活
UPDATE users SET status = 'active';
```
**特点**:
- ⚠️ **影响表中所有记录**
- 操作不可逆,务必谨慎
- 生产环境强烈建议先备份
---
**2. 更新指定记录**
**语法**:使用 WHERE 条件限定
**示例**:
```sql
-- 更新特定用户的邮箱
UPDATE users SET email = 'new@email.com' WHERE id = 1;
-- 更新满足条件的多条记录
UPDATE products SET stock = 0 WHERE category = '电子';
-- 更新年龄在特定范围的用户
UPDATE users SET level = 'VIP' WHERE age BETWEEN 25 AND 35;
```
**特点**:
- 只更新符合条件的记录
- WHERE 条件要准确,避免误更新
- 可使用 AND/OR 组合多个条件
---
**3. 同时更新多个字段**
**示例**:
```sql
-- 同时更新多个字段
UPDATE users
SET
name = '新姓名',
age = 26,
email = 'new@email.com'
WHERE id = 1;
-- 基于现有值计算更新
UPDATE products
SET
price = price * 0.9, -- 打9折
sale_count = sale_count + 1 -- 销量+1
WHERE id = 100;
```
---
**完整示例**
**表结构**:
```sql
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
salary DECIMAL(10,2),
department VARCHAR(50),
bonus DECIMAL(10,2)
);
```
**更新操作**:
```sql
-- 1. 更新所有记录:所有人加薪5%
UPDATE employees SET salary = salary * 1.05;
-- 2. 更新指定部门
UPDATE employees
SET salary = salary * 1.1
WHERE department = '技术部';
-- 3. 同时更新多个字段
UPDATE employees
SET
salary = 8000,
bonus = 2000
WHERE id = 101;
-- 4. 复杂条件更新
UPDATE employees
SET bonus = salary * 0.1
WHERE department = '销售部' AND salary > 5000;
```
**注意事项**:
1. **务必使用 WHERE**:除非确实需要更新所有记录
2. **先查询再更新**:
```sql
SELECT * FROM users WHERE id = 1; -- 先确认
UPDATE users SET name = '新名' WHERE id = 1; -- 再更新
```
3. **使用事务**(重要更新):
```sql
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
```
4. **影响行数**:执行后会显示受影响的行数,请确认是否符合预期
**安全建议**:
- 生产环境使用 WHERE 前先 SELECT 验证条件
- 重要数据更新前备份
- 考虑使用事务保证数据一致性
3.3 数据删除(DELETE 与 TRUNCATE)
**DELETE vs TRUNCATE TABLE 对比**
**基本区别**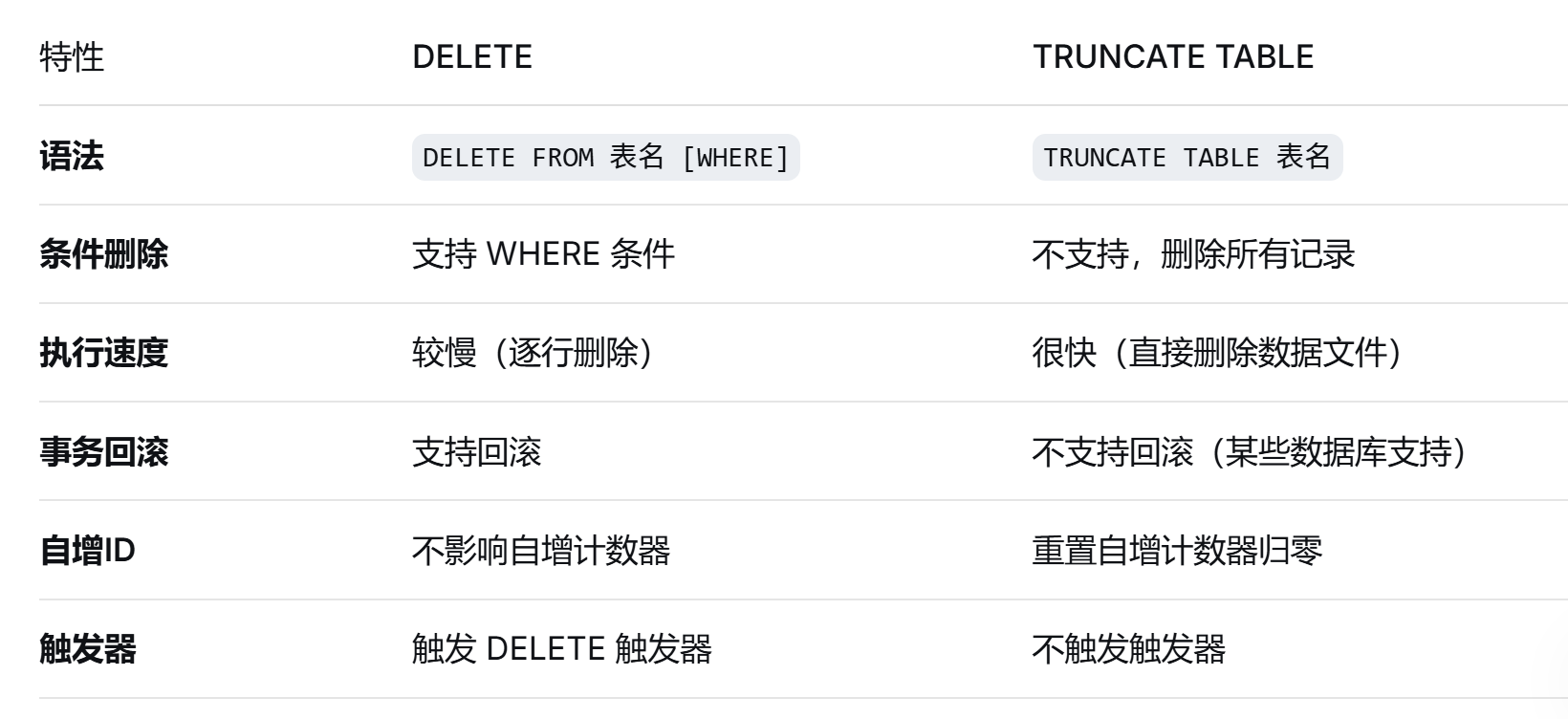
---
**语法示例**
**DELETE 语句**
```sql
-- 删除所有记录
DELETE FROM users;
-- 条件删除
DELETE FROM users WHERE age < 18;
-- 删除特定ID
DELETE FROM products WHERE id = 100;
```
**TRUNCATE TABLE 语句**
```sql
-- 清空整个表
TRUNCATE TABLE users;
-- 清空日志表
TRUNCATE TABLE system_logs;
```
---
**适用场景**
**使用 DELETE 的场景**:
- 需要**条件删除**部分数据时
- 需要**触发删除触发器**时
- 需要**事务控制**,可能回滚时
- 希望**保留自增ID**继续计数时
**使用 TRUNCATE TABLE 的场景**:
- 需要**快速清空整个表**时
- 临时表、日志表需要**定期清理**时
- 测试数据需要**完全重置**时
- 不关心自增ID重置时
---
**数据删除操作注意事项**
**1. 备份优先**
```sql
-- 删除前先备份
CREATE TABLE users_backup AS SELECT * FROM users;
-- 然后再执行删除
DELETE FROM users WHERE condition;
```
**2. 使用事务**
```sql
-- 重要删除使用事务
START TRANSACTION;
DELETE FROM orders WHERE status = 'cancelled';
-- 检查影响行数,确认无误后提交
COMMIT;
-- 或者回滚
ROLLBACK;
```
**3. 先查询后删除**
```sql
-- 先确认要删除的数据
SELECT * FROM users WHERE age < 18;
-- 确认无误后再删除
DELETE FROM users WHERE age < 18;
```
**4. 外键约束处理**
- 有关联表时,需按正确顺序删除
- 或使用级联删除(需提前设置外键约束)
**5. 性能考虑**
- 大表删除使用分批删除:
```sql
-- 分批删除,避免锁表
DELETE FROM big_table WHERE id < 100000 LIMIT 1000;
```
---
**生产环境安全建议**
1. **权限控制**:限制 DELETE/TRUNCATE 权限
2. **操作审核**:重要删除操作双人复核
3. **定时备份**:定期自动备份关键数据
4. **使用软删除**:优先使用状态字段标记删除
```sql
-- 软删除示例
UPDATE users SET is_deleted = 1 WHERE id = 100;
```
**总结选择**:
- **部分删除** → 用 DELETE + WHERE
- **快速清空** → 用 TRUNCATE TABLE
- **安全第一** → 做好备份,使用事务
四、数据查询语言(DQL)
4.1 简单查询
**SELECT 语句基本语法**
**基本结构**
```sql
SELECT 字段列表 FROM 表名 [WHERE 条件];
```
---
**1. 查询指定字段**
**语法**:明确列出需要的字段
**示例**:
```sql
-- 查询特定字段
SELECT name, age, email FROM users;
-- 查询单个字段
SELECT product_name FROM products;
-- 字段别名
SELECT name AS 姓名, age AS 年龄 FROM users;
```
**特点**:
- 只返回需要的字段,节省资源
- 字段顺序可以自定义
- 可以使用 AS 设置别名
---
**2. 查询所有字段**
**语法**:使用 `*` 通配符
**示例**:
```sql
-- 查询所有字段
SELECT * FROM users;
-- 查询所有字段并条件过滤
SELECT * FROM products WHERE price > 100;
```
**特点**:
- 返回表的所有字段
- 开发调试时方便,但生产环境不推荐
- 性能较低,特别是字段多的表
---
**3. 去重查询**
**语法**:使用 `DISTINCT` 关键字
**示例**:
```sql
-- 查询不重复的城市
SELECT DISTINCT city FROM users;
-- 多字段去重
SELECT DISTINCT department, job_title FROM employees;
-- 去重计数
SELECT COUNT(DISTINCT city) FROM users;
```
**特点**:
- 消除重复记录,只返回唯一值
- 可以用于单字段或多字段组合
- 常用于统计不重复值的数量
---
**完整示例**
**表结构**:
```sql
CREATE TABLE employees (
id INT,
name VARCHAR(50),
department VARCHAR(50),
salary DECIMAL(10,2),
city VARCHAR(50)
);
```
**查询操作**:
```sql
-- 1. 查询指定字段
SELECT name, department, salary FROM employees;
-- 2. 查询所有字段
SELECT * FROM employees;
-- 3. 去重查询部门
SELECT DISTINCT department FROM employees;
-- 4. 去重查询部门和城市的组合
SELECT DISTINCT department, city FROM employees;
-- 5. 带条件的指定字段查询
SELECT name, salary FROM employees WHERE department = '技术部';
-- 6. 使用别名
SELECT
name AS 姓名,
department AS 部门,
salary * 12 AS 年薪
FROM employees;
```
- **实用技巧**
**计算字段**:
```sql
SELECT name, salary, salary * 12 AS annual_salary FROM employees;
```
**常量字段**:
```sql
SELECT name, '在职' AS status FROM employees;
```
**限制返回行数**:
```sql
SELECT name FROM employees LIMIT 10;
```
---
**使用建议**
1. **生产环境**:尽量指定字段,避免 `SELECT *`
2. **性能优化**:只查询需要的字段
3. **数据安全**:避免返回敏感不必要字段
4. **可读性**:使用有意义的别名
**总结**:
- **精确查询** → 指定字段列表
- **快速查看** → `SELECT *`(仅开发调试)
- **消除重复** → `DISTINCT` 字段名
4.2 条件查询
**条件查询语法**
```sql
SELECT 字段列表 FROM 表名 WHERE 条件表达式;
```
---
**1. 比较运算符**
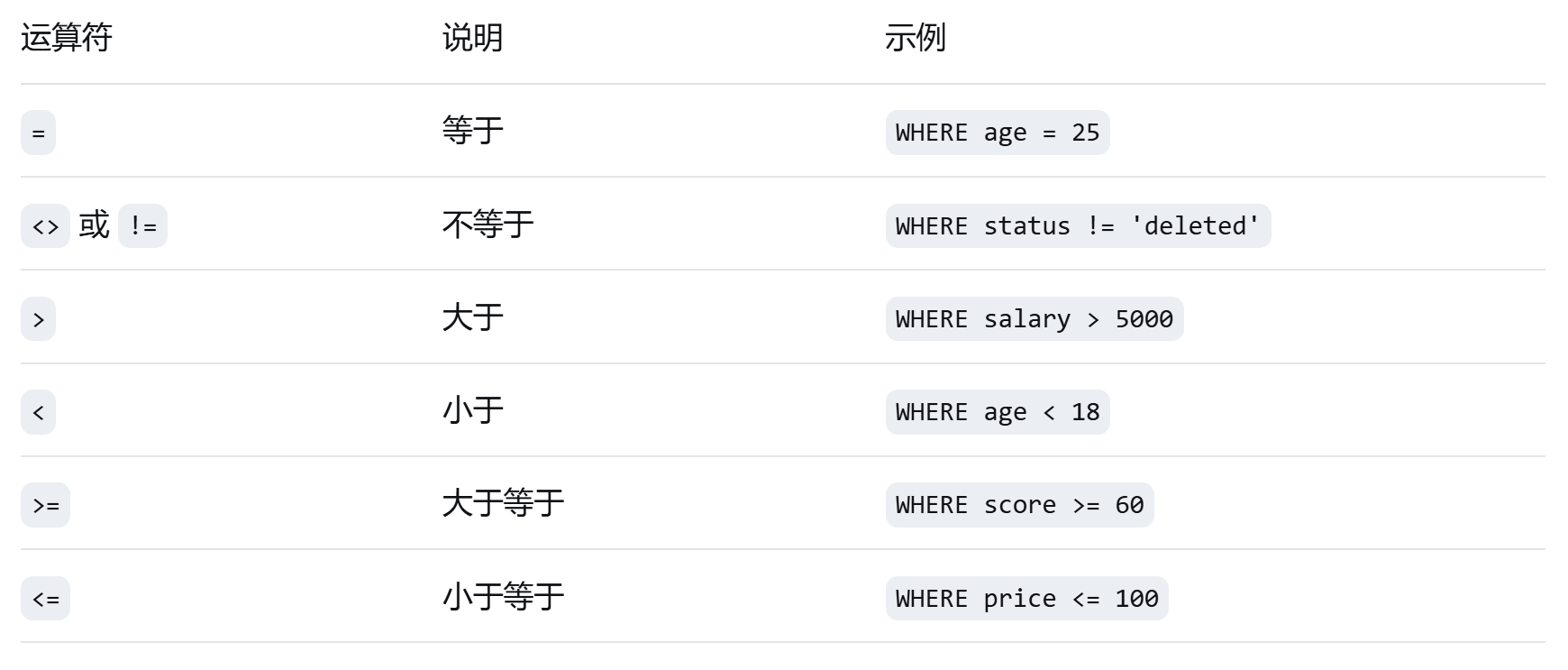
**示例**:
```sql
-- 等于
SELECT * FROM users WHERE name = '张三';
-- 不等于
SELECT * FROM products WHERE price <> 0;
-- 范围比较
SELECT * FROM employees WHERE salary > 10000;
```
---
### **2. 逻辑运算符**
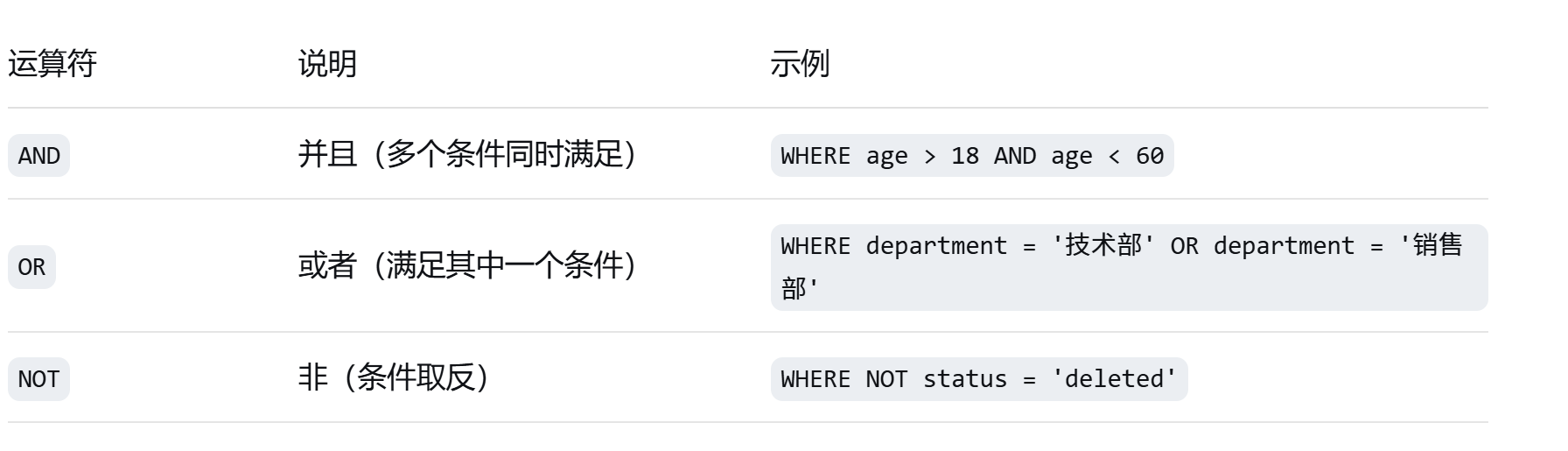
**示例**:
```sql
-- AND 示例
SELECT * FROM users WHERE age >= 18 AND age <= 35;
-- OR 示例
SELECT * FROM products WHERE category = '电子' OR category = '家居';
-- 组合使用
SELECT * FROM employees
WHERE (department = '技术部' AND salary > 8000)
OR (department = '销售部' AND salary > 5000);
-- NOT 示例
SELECT * FROM users WHERE NOT is_deleted = 1;
```
---
### **3. 范围查询运算符**
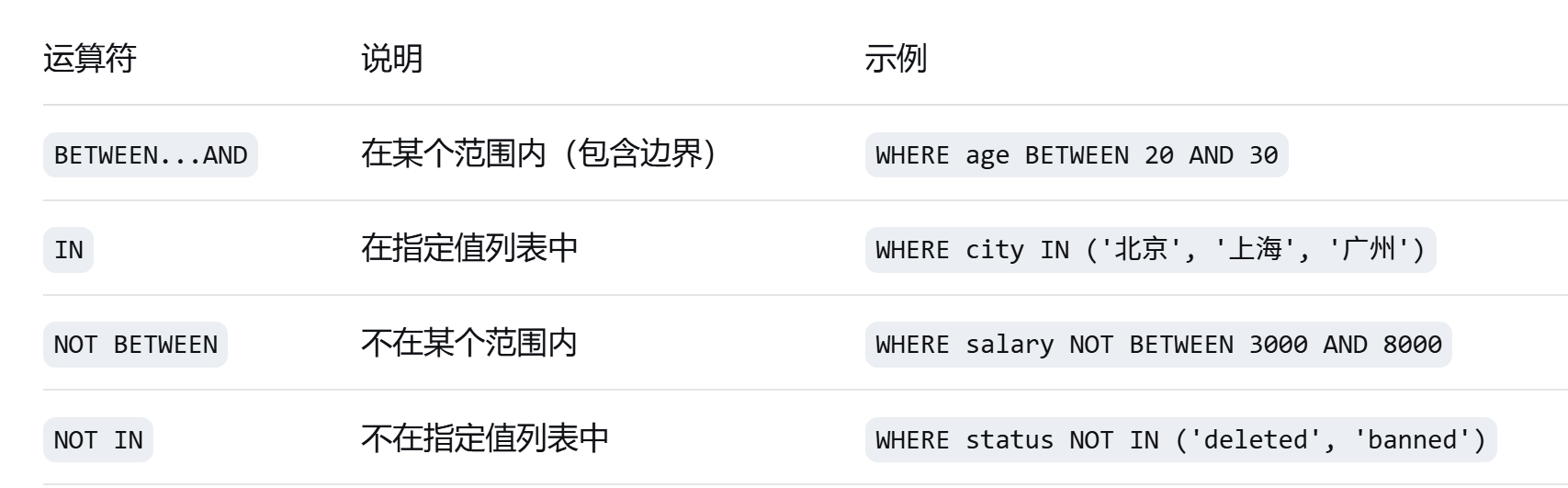
**示例**:
```sql
-- BETWEEN 范围查询
SELECT * FROM students WHERE score BETWEEN 60 AND 90;
-- IN 列表查询
SELECT * FROM users WHERE city IN ('北京', '上海', '深圳');
-- NOT BETWEEN
SELECT * FROM products WHERE price NOT BETWEEN 50 AND 200;
-- NOT IN
SELECT * FROM orders WHERE status NOT IN ('cancelled', 'refunded');
```
---
**4. 其他常用运算符**
**LIKE 模糊匹配**:
```sql
-- % 匹配任意字符,_ 匹配单个字符
SELECT * FROM users WHERE name LIKE '张%'; -- 张开头
SELECT * FROM users WHERE name LIKE '%技术%'; -- 包含"技术"
SELECT * FROM users WHERE name LIKE '李_'; -- 李开头,两个字
```
**IS NULL / IS NOT NULL**:
```sql
-- 空值判断
SELECT * FROM users WHERE email IS NULL;
SELECT * FROM users WHERE phone IS NOT NULL;
```
---
**完整综合示例**
**表结构**:
```sql
CREATE TABLE employees (
id INT,
name VARCHAR(50),
age INT,
department VARCHAR(50),
salary DECIMAL(10,2),
city VARCHAR(50),
hire_date DATE
);
```
**复杂条件查询**:
```sql
-- 多条件组合查询
SELECT name, department, salary
FROM employees
WHERE (department = '技术部' AND salary BETWEEN 8000 AND 15000)
OR (department IN ('销售部', '市场部') AND salary > 6000)
AND age BETWEEN 25 AND 40
AND city IS NOT NULL;
-- 模糊匹配 + 范围查询
SELECT * FROM employees
WHERE name LIKE '王%'
AND hire_date BETWEEN '2020-01-01' AND '2023-12-31'
AND salary >= 8000;
-- NOT 使用示例
SELECT * FROM employees
WHERE department NOT IN ('人事部', '行政部')
AND NOT salary < 5000;
```
---
**运算符优先级**
1. `()` 括号
2. `NOT`
3. `AND`
4. `OR`
**建议**:复杂条件使用括号明确优先级
```sql
-- 清晰的优先级
SELECT * FROM users
WHERE (age > 18 AND status = 'active')
OR (age <= 18 AND guardian_approved = 1);
```
**使用技巧**:
- 使用括号明确复杂条件的逻辑关系
- `BETWEEN` 包含边界值,相当于 `>= AND <=`
- `IN` 适合离散值查询,比多个 `OR` 更简洁
- 空值判断必须用 `IS NULL`,不能用 `= NULL`
4.3 分组查询
**GROUP BY 语句**
**基本语法**
```sql
SELECT 分组字段, 聚合函数(字段)
FROM 表名
[WHERE 条件]
GROUP BY 分组字段
[HAVING 分组后条件];
```
---
**GROUP BY 的使用方法**
**1. 单字段分组**
```sql
-- 按部门分组统计
SELECT department, COUNT(*)
FROM employees
GROUP BY department;
-- 按城市分组
SELECT city, AVG(salary)
FROM employees
GROUP BY city;
```
**2. 多字段分组**
```sql
-- 按部门和职位分组
SELECT department, job_title, COUNT(*)
FROM employees
GROUP BY department, job_title;
-- 按年份和月份分组
SELECT YEAR(order_date), MONTH(order_date), SUM(amount)
FROM orders
GROUP BY YEAR(order_date), MONTH(order_date);
```
**3. 分组前过滤(WHERE)**
```sql
-- 先过滤再分组
SELECT department, AVG(salary)
FROM employees
WHERE hire_date > '2020-01-01'
GROUP BY department;
```
**4. 分组后过滤(HAVING)**
```sql
-- 分组后对结果过滤
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 8000;
-- HAVING 使用别名
SELECT department, COUNT(*) as emp_count
FROM employees
GROUP BY department
HAVING emp_count > 10;
```
---
**常用聚合函数**
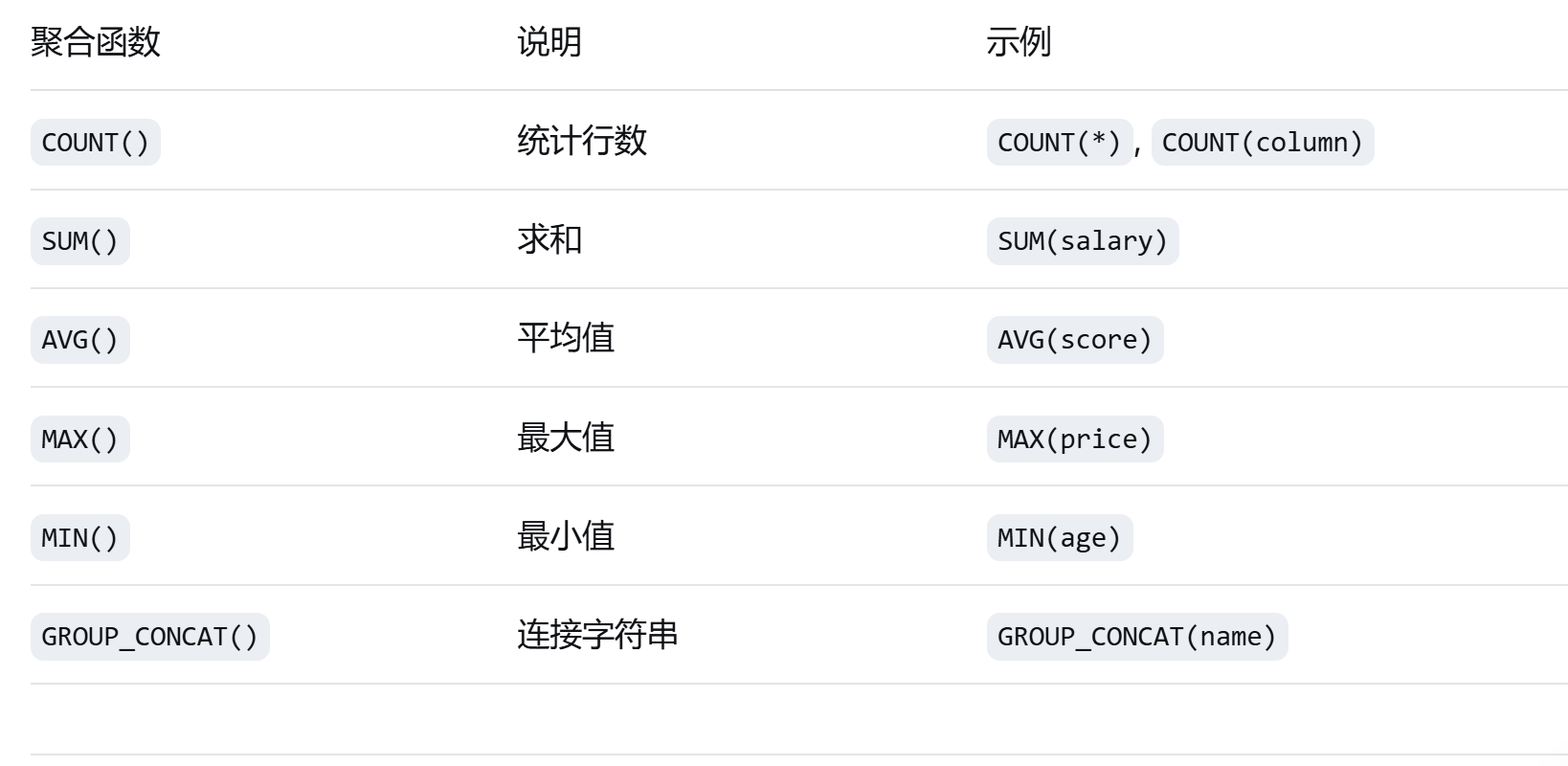
**聚合函数在分组查询中的应用**
**COUNT() 应用**
```sql
-- 统计每个部门的员工数
SELECT department, COUNT(*) as employee_count
FROM employees
GROUP BY department;
-- 统计每个城市非空手机号的数量
SELECT city, COUNT(phone) as phone_count
FROM users
GROUP BY city;
```
#### **SUM() 和 AVG() 应用**
```sql
-- 每个部门的工资总额和平均工资
SELECT
department,
SUM(salary) as total_salary,
AVG(salary) as avg_salary
FROM employees
GROUP BY department;
-- 每个销售员的销售总额
SELECT salesman_id, SUM(amount) as total_sales
FROM orders
GROUP BY salesman_id;
```
**MAX() 和 MIN() 应用**
```sql
-- 每个产品的最高和最低价格
SELECT
product_category,
MAX(price) as max_price,
MIN(price) as min_price
FROM products
GROUP BY product_category;
-- 每个班级的最高分和最低分
SELECT
class_id,
MAX(score) as highest_score,
MIN(score) as lowest_score
FROM students
GROUP BY class_id;
```
**GROUP_CONCAT() 应用**
```sql
-- 列出每个部门的所有员工姓名
SELECT
department,
GROUP_CONCAT(name) as employees
FROM employees
GROUP BY department;
-- 带分隔符的连接
SELECT
department,
GROUP_CONCAT(name SEPARATOR '、') as employees
FROM employees
GROUP BY department;
```
---
**完整综合示例**
**数据表:sales**
```sql
CREATE TABLE sales (
id INT,
product_name VARCHAR(50),
category VARCHAR(50),
sale_date DATE,
amount DECIMAL(10,2),
region VARCHAR(50)
);
```
**复杂分组查询**:
```sql
-- 按类别和年份统计销售情况
SELECT
category,
YEAR(sale_date) as sale_year,
COUNT(*) as order_count,
SUM(amount) as total_amount,
AVG(amount) as avg_amount,
MAX(amount) as max_order,
MIN(amount) as min_order
FROM sales
WHERE sale_date BETWEEN '2022-01-01' AND '2023-12-31'
GROUP BY category, YEAR(sale_date)
HAVING total_amount > 100000
ORDER BY total_amount DESC;
-- 按地区统计,显示销售员列表
SELECT
region,
COUNT(DISTINCT product_name) as product_count,
SUM(amount) as total_sales,
GROUP_CONCAT(DISTINCT product_name ORDER BY product_name) as products
FROM sales
GROUP BY region
HAVING total_sales > 50000;
```
---
### **注意事项**
1. **SELECT 字段限制**:
- GROUP BY 后的字段可以出现在 SELECT 中
- 非分组字段必须使用聚合函数
```sql
-- 正确
SELECT department, COUNT(*)
FROM employees
GROUP BY department;
-- 错误:name 未在 GROUP BY 中,也未使用聚合函数
SELECT department, name, COUNT(*)
FROM employees
GROUP BY department;
```
2. **WHERE vs HAVING**:
- WHERE:分组前过滤,不能使用聚合函数
- HAVING:分组后过滤,可以使用聚合函数
3. **性能优化**:
- 对分组字段建立索引
- 避免对大表进行复杂分组
**使用场景**:
- **数据统计**:部门人数、销售总额等
- **报表生成**:月度报表、分类汇总
- **数据分析**:趋势分析、对比分析
4.4 排序查询
### **ORDER BY 语句**
#### **基本语法**
```sql
SELECT 字段列表
FROM 表名
[WHERE 条件]
[ORDER BY 排序字段1 [ASC|DESC], 排序字段2 [ASC|DESC], ...];
```
---
### **1. 单字段排序**
#### **升序排序(ASC)**
```sql
-- 按年龄升序排列(ASC可省略)
SELECT name, age FROM users ORDER BY age ASC;
-- 按姓名升序排列
SELECT name, department FROM employees ORDER BY name;
-- 按日期升序
SELECT order_id, order_date FROM orders ORDER BY order_date ASC;
```
#### **降序排序(DESC)**
```sql
-- 按工资降序排列
SELECT name, salary FROM employees ORDER BY salary DESC;
-- 按注册时间降序(最新在前)
SELECT username, register_date FROM users ORDER BY register_date DESC;
-- 按分数降序
SELECT student_name, score FROM students ORDER BY score DESC;
```
---
### **2. 多字段排序**
#### **基本多字段排序**
```sql
-- 先按部门升序,再按工资降序
SELECT name, department, salary
FROM employees
ORDER BY department ASC, salary DESC;
-- 先按类别,再按价格,最后按销量
SELECT product_name, category, price, sales
FROM products
ORDER BY category, price DESC, sales DESC;
```
#### **混合排序方向**
```sql
-- 部门升序,工资降序,姓名升序
SELECT department, salary, name
FROM employees
ORDER BY
department ASC,
salary DESC,
name ASC;
```
---
### **3. 复杂排序示例**
#### **按表达式排序**
```sql
-- 按姓名长度排序
SELECT name, LENGTH(name) as name_length
FROM users
ORDER BY LENGTH(name) DESC;
-- 按计算字段排序
SELECT product_name, price, stock,
price * stock as total_value
FROM products
ORDER BY total_value DESC;
```
#### **按字段位置排序**
```sql
-- 按SELECT中的字段位置排序(不推荐)
SELECT name, age, salary
FROM employees
ORDER BY 2 DESC, 3 ASC; -- 2=age, 3=salary
```
#### **条件排序**
```sql
-- 自定义排序规则
SELECT name, department, salary
FROM employees
ORDER BY
CASE
WHEN department = '管理部' THEN 1
WHEN department = '技术部' THEN 2
ELSE 3
END,
salary DESC;
```
---
### **完整综合示例**
**数据表:employees**
```sql
CREATE TABLE employees (
id INT,
name VARCHAR(50),
department VARCHAR(50),
position VARCHAR(50),
salary DECIMAL(10,2),
hire_date DATE,
performance_score INT
);
```
**复杂排序查询**:
```sql
-- 多字段混合排序
SELECT
name,
department,
position,
salary,
hire_date,
performance_score
FROM employees
WHERE salary > 5000
ORDER BY
department ASC, -- 部门升序
position DESC, -- 职位降序
performance_score DESC, -- 绩效降序
hire_date ASC; -- 入职日期升序
-- 按计算字段和条件排序
SELECT
name,
department,
salary,
performance_score,
salary * performance_score as composite_score
FROM employees
ORDER BY
department,
composite_score DESC;
```
---
### **4. 结合其他子句使用**
#### **与 WHERE 结合**
```sql
-- 先过滤再排序
SELECT name, age, city
FROM users
WHERE age >= 18
ORDER BY age DESC, name ASC;
```
#### **与 GROUP BY 结合**
```sql
-- 分组统计后排序
SELECT
department,
AVG(salary) as avg_salary,
COUNT(*) as emp_count
FROM employees
GROUP BY department
ORDER BY avg_salary DESC;
```
#### **与 LIMIT 结合**
```sql
-- 获取前10名
SELECT name, score
FROM students
ORDER BY score DESC
LIMIT 10;
-- 分页查询
SELECT name, salary
FROM employees
ORDER BY salary DESC
LIMIT 10 OFFSET 20; -- 跳过20条,取10条
```
---
### **排序规则说明**
1. **数字类型**:按数值大小排序
2. **字符串类型**:按字典顺序排序
3. **日期类型**:按时间先后排序
4. **NULL值**:通常排在最后(可通过 `NULLS FIRST/LAST` 控制,MySQL不支持)
```sql
-- 在支持NULLS FIRST的数据库中
SELECT name, bonus
FROM employees
ORDER BY bonus NULLS FIRST; -- NULL值排在最前
```
---
### **使用技巧和注意事项**
1. **性能优化**:
- 对排序字段建立索引
- 避免对大文本字段排序
2. **明确排序方向**:
- 虽然ASC可以省略,但建议明确写出以提高可读性
3. **多字段排序逻辑**:
- 第一个字段值相同时,按第二个字段排序,依此类推
4. **应用场景**:
- 排行榜、TopN查询
- 报表数据整理
- 分页显示数据
### **总结**:
- **单字段排序**:`ORDER BY column [ASC|DESC]`
- **多字段排序**:`ORDER BY col1 DESC, col2 ASC`
- **默认顺序**:ASC升序(从小到大)
- **常用组合**:与WHERE、GROUP BY、LIMIT配合使用
4.5 分页查询
### **LIMIT 语句**
#### **基本语法**
```sql
SELECT 字段列表
FROM 表名
[WHERE 条件]
[ORDER BY 排序字段]
LIMIT [偏移量,] 记录数;
```
---
### **1. 基本用法**
#### **限制返回记录数**
```sql
-- 只返回前5条记录
SELECT * FROM products LIMIT 5;
-- 返回前10个用户
SELECT username, email FROM users LIMIT 10;
-- 获取最高分的3个学生
SELECT name, score FROM students
ORDER BY score DESC
LIMIT 3;
```
#### **指定偏移量和记录数**
```sql
-- 从第0条开始,取10条记录(第1页)
SELECT * FROM products LIMIT 0, 10;
-- 等价写法
SELECT * FROM products LIMIT 10 OFFSET 0;
-- 从第10条开始,取10条记录(第2页)
SELECT * FROM products LIMIT 10, 10;
-- 等价写法
SELECT * FROM products LIMIT 10 OFFSET 10;
-- 从第20条开始,取10条记录(第3页)
SELECT * FROM products LIMIT 20, 10;
```
---
### **2. 分页查询公式**
#### **通用分页公式**
```sql
-- 第page页,每页page_size条记录
LIMIT (page - 1) * page_size, page_size;
```
**示例**:
```sql
-- 假设:page = 3, page_size = 10
-- LIMIT (3-1)*10, 10 → LIMIT 20, 10
-- 第1页:LIMIT 0, 10
-- 第2页:LIMIT 10, 10
-- 第3页:LIMIT 20, 10
-- 第4页:LIMIT 30, 10
```
---
### **3. 实际应用示例**
#### **商品分页查询**
```sql
-- 获取第1页商品,每页20条,按价格排序
SELECT product_id, product_name, price
FROM products
WHERE status = 'active'
ORDER BY price ASC
LIMIT 0, 20;
-- 获取第2页
SELECT product_id, product_name, price
FROM products
WHERE status = 'active'
ORDER BY price ASC
LIMIT 20, 20;
```
#### **用户管理分页**
```sql
-- 分页查询用户列表,按注册时间倒序
SELECT user_id, username, email, register_date
FROM users
ORDER BY register_date DESC
LIMIT 50, 25; -- 第3页,每页25条
-- 结合条件过滤的分页
SELECT order_id, customer_name, amount, order_date
FROM orders
WHERE order_date >= '2024-01-01'
AND status = 'completed'
ORDER BY order_date DESC
LIMIT 30, 15;
```
---
### **4. 分页查询的重要性**
#### **性能优势**
```sql
-- 没有分页:返回100万条记录
SELECT * FROM large_table; -- 性能灾难!
-- 使用分页:只返回需要的记录
SELECT * FROM large_table LIMIT 0, 50; -- 高性能
```
#### **内存和网络优化**
- **减少内存占用**:应用程序不需要加载大量数据到内存
- **降低网络传输**:只传输当前页数据,提高响应速度
- **提升用户体验**:快速显示第一页内容,无需等待所有数据
---
### **5. 完整分页方案**
#### **Web应用分页示例**
```sql
-- 前端传递参数:page=2, pageSize=20
SET @page = 2;
SET @pageSize = 20;
SET @offset = (@page - 1) * @pageSize;
SELECT product_id, name, price, stock
FROM products
WHERE category = 'electronics'
AND price BETWEEN 100 AND 1000
ORDER BY create_time DESC
LIMIT @offset, @pageSize;
```
#### **获取分页元信息**
```sql
-- 获取总记录数(用于计算总页数)
SELECT COUNT(*) as total_count
FROM products
WHERE category = 'electronics';
-- 获取分页数据
SELECT product_id, name, price
FROM products
WHERE category = 'electronics'
ORDER BY create_time DESC
LIMIT 0, 20;
```
---
### **6. 高级分页技巧**
#### **优化大偏移量分页**
```sql
-- 传统分页(偏移量大时性能差)
SELECT * FROM large_table LIMIT 10000, 20;
-- 优化方案:使用游标分页
SELECT * FROM large_table
WHERE id > 10000 -- 上一页最后一条记录的ID
ORDER BY id
LIMIT 20;
```
#### **结合聚合函数的分页**
```sql
-- 分页显示统计结果
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department
ORDER BY avg_salary DESC
LIMIT 10, 5; -- 第3页,每页5个部门
```
---
### **分页查询的重要性总结**
1. **性能保障**
- 避免单次查询返回过多数据
- 减少数据库和服务器的压力
2. **用户体验**
- 快速响应用户操作
- 支持大数据集的浏览和导航
3. **系统稳定性**
- 防止内存溢出
- 避免长时间数据库锁
4. **应用场景**
- Web网站列表页
- 移动端APP数据加载
- 后台管理系统表格
- 报表数据展示
### **最佳实践**:
- **始终使用分页**:即使数据量小,也要养成习惯
- **合理设置页大小**:根据业务需求平衡性能和体验
- **配合ORDER BY**:确保分页结果顺序一致
- **考虑边界情况**:最后一页、空数据集等的处理
五、索引与视图
5.1 索引的概念与作用
### **索引的定义**
**索引**是数据库中帮助快速查询数据的数据结构,类似于书籍的目录,可以加速数据的检索速度。
---
### **索引的作用**
#### **1. 大幅提高查询速度**
```sql
-- 无索引:全表扫描
SELECT * FROM users WHERE email = 'test@example.com';
-- 有索引:快速定位
CREATE INDEX idx_email ON users(email);
SELECT * FROM users WHERE email = 'test@example.com';
```
#### **2. 加速排序和分组**
```sql
-- 有索引的排序更快
CREATE INDEX idx_salary ON employees(salary);
SELECT * FROM employees ORDER BY salary DESC;
-- 加速分组查询
CREATE INDEX idx_dept ON employees(department);
SELECT department, COUNT(*) FROM employees GROUP BY department;
```
#### **3. 保证数据唯一性**
```sql
-- 唯一索引防止重复数据
CREATE UNIQUE INDEX idx_unique_email ON users(email);
```
---
### **索引的分类**
#### **1. 普通索引**
最基本的索引,无唯一性限制
```sql
CREATE INDEX idx_name ON users(name);
```
#### **2. 唯一索引**
保证字段值唯一
```sql
CREATE UNIQUE INDEX idx_unique_phone ON users(phone);
```
#### **3. 主键索引**
特殊的唯一索引,不允许NULL值
```sql
-- 创建表时自动创建
CREATE TABLE users (
id INT PRIMARY KEY, -- 主键索引
name VARCHAR(50)
);
```
#### **4. 复合索引**
多个字段组合的索引
```sql
CREATE INDEX idx_name_dept ON employees(last_name, department);
```
#### **5. 全文索引**
用于全文搜索
```sql
CREATE FULLTEXT INDEX idx_content ON articles(content);
```
---
### **索引对查询性能的影响**
#### **正面影响**
1. **查询性能大幅提升**
```sql
-- 索引覆盖查询,性能最佳
CREATE INDEX idx_user_info ON users(name, age, city);
SELECT name, age FROM users WHERE name = '张三'; -- 使用索引
```
2. **减少磁盘I/O**
- 索引数据量小,可加载到内存
- 减少全表扫描的磁盘访问
3. **优化连接查询**
```sql
-- 连接字段有索引时性能更好
CREATE INDEX idx_order_user ON orders(user_id);
SELECT * FROM users u
JOIN orders o ON u.id = o.user_id; -- 使用索引加速连接
```
#### **负面影响**
1. **降低写操作性能**
```sql
-- 每次INSERT/UPDATE/DELETE都需要更新索引
INSERT INTO users (name, email) VALUES ('李四', 'lisi@email.com');
-- 需要更新name索引、email索引等
```
2. **占用额外存储空间**
- 索引需要额外的磁盘空间
- 大型表索引可能占用可观空间
3. **索引维护开销**
- 数据库需要维护索引的一致性
- 定期优化和重建索引
---
### **索引使用场景**
#### **推荐创建索引的场景**
```sql
-- 1. 主键和外键字段
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
INDEX idx_user_id (user_id)
);
-- 2. 频繁查询的WHERE条件字段
CREATE INDEX idx_status ON orders(status);
-- 3. 排序和分组字段
CREATE INDEX idx_order_date ON orders(order_date);
-- 4. 多表连接的关联字段
CREATE INDEX idx_category_id ON products(category_id);
```
#### **不推荐创建索引的场景**
```sql
-- 1. 数据量小的表(全表扫描更快)
-- 2. 频繁更新的字段
-- 3. 区分度低的字段(如性别、状态)
-- 4. 很少用于查询条件的字段
```
---
### **复合索引使用技巧**
#### **最左前缀原则**
```sql
-- 创建复合索引
CREATE INDEX idx_composite ON users(last_name, first_name, age);
-- 以下查询能使用索引:
SELECT * FROM users WHERE last_name = '张';
SELECT * FROM users WHERE last_name = '张' AND first_name = '三';
SELECT * FROM users WHERE last_name = '张' AND age > 25;
-- 以下查询不能使用复合索引:
SELECT * FROM users WHERE first_name = '三'; -- 违反最左前缀
SELECT * FROM users WHERE age > 25; -- 违反最左前缀
```
#### **索引选择性**
```sql
-- 高选择性字段适合建索引(如邮箱、手机号)
CREATE INDEX idx_email ON users(email); -- 选择性高
-- 低选择性字段不适合单独建索引(如性别)
CREATE INDEX idx_gender ON users(gender); -- 选择性低,效果差
```
---
### **索引优化建议**
1. **避免过度索引**
- 每个索引都会增加维护成本
- 选择真正能提升性能的字段建索引
2. **定期分析索引使用情况**
```sql
-- 查看索引使用统计
SHOW INDEX FROM table_name;
```
3. **考虑查询模式**
```sql
-- 根据实际查询需求创建索引
-- 如果经常按(类别+价格)查询:
CREATE INDEX idx_category_price ON products(category, price);
```
### **总结**
- **索引优点**:大幅提升查询性能,加速排序分组
- **索引缺点**:降低写性能,占用存储空间
- **选择策略**:在查询性能和写性能之间平衡
- **最佳实践**:基于实际查询模式创建合适的索引
5.2 索引的创建与删除
### **CREATE INDEX 语句**
#### **基本语法**
```sql
CREATE [UNIQUE|FULLTEXT] INDEX 索引名
ON 表名 (字段1 [ASC|DESC], 字段2 [ASC|DESC], ...);
```
---
### **1. 创建普通索引**
```sql
-- 单字段索引
CREATE INDEX idx_email ON users(email);
-- 多字段复合索引
CREATE INDEX idx_name_department ON employees(last_name, department);
-- 指定排序方向
CREATE INDEX idx_salary_desc ON employees(salary DESC);
```
### **2. 创建唯一索引**
```sql
-- 单字段唯一索引
CREATE UNIQUE INDEX idx_unique_phone ON customers(phone);
-- 复合唯一索引
CREATE UNIQUE INDEX idx_unique_user_product ON orders(user_id, product_id);
```
### **3. 创建全文索引**
```sql
-- 全文搜索索引
CREATE FULLTEXT INDEX idx_content ON articles(content);
-- 多字段全文索引
CREATE FULLTEXT INDEX idx_title_content ON posts(title, content);
```
---
### **DROP INDEX 语句**
#### **基本语法**
```sql
DROP INDEX 索引名 ON 表名;
```
#### **使用方法**
```sql
-- 删除普通索引
DROP INDEX idx_email ON users;
-- 删除唯一索引
DROP INDEX idx_unique_phone ON customers;
-- 删除全文索引
DROP INDEX idx_content ON articles;
```
---
### **创建索引的注意事项**
#### **1. 选择合适字段**
```sql
-- 推荐:高选择性字段
CREATE INDEX idx_email ON users(email); -- 选择性高
CREATE INDEX idx_order_date ON orders(created_at); -- 日期字段
-- 不推荐:低选择性字段
CREATE INDEX idx_gender ON users(gender); -- 只有几个值,效果差
CREATE INDEX idx_status ON orders(status); -- 状态字段,区分度低
```
#### **2. 复合索引顺序**
```sql
-- 正确:按查询频率和选择性排序
CREATE INDEX idx_dept_salary ON employees(department, salary);
-- 使用场景:
SELECT * FROM employees WHERE department = 'IT' AND salary > 5000;
SELECT * FROM employees WHERE department = 'IT'; -- 也能使用索引
-- 错误顺序:
CREATE INDEX idx_salary_dept ON employees(salary, department);
-- WHERE department = 'IT' 无法使用该索引
```
#### **3. 避免冗余索引**
```sql
-- 冗余示例:
CREATE INDEX idx_name ON users(last_name);
CREATE INDEX idx_name_first ON users(last_name, first_name); -- 已包含前一个索引
-- 应该只创建复合索引
CREATE INDEX idx_full_name ON users(last_name, first_name);
```
#### **4. 考虑查询模式**
```sql
-- 根据实际查询创建索引
-- 场景1:经常按类别和价格查询
CREATE INDEX idx_category_price ON products(category, price);
-- 场景2:经常按用户和日期范围查询
CREATE INDEX idx_user_date ON orders(user_id, order_date);
```
---
### **完整示例**
#### **创建表并添加索引**
```sql
-- 创建用户表
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
phone VARCHAR(20),
created_at DATETIME,
last_login DATETIME
);
-- 创建各种索引
CREATE UNIQUE INDEX idx_unique_username ON users(username);
CREATE UNIQUE INDEX idx_unique_email ON users(email);
CREATE INDEX idx_phone ON users(phone);
CREATE INDEX idx_created_at ON users(created_at);
CREATE INDEX idx_login_time ON users(last_login DESC);
```
#### **订单表索引设计**
```sql
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
product_id INT,
status VARCHAR(20),
amount DECIMAL(10,2),
created_at DATETIME,
updated_at DATETIME
);
-- 基于查询模式创建索引
CREATE INDEX idx_user_orders ON orders(user_id, created_at DESC);
CREATE INDEX idx_status_created ON orders(status, created_at);
CREATE INDEX idx_product_sales ON orders(product_id, amount);
CREATE UNIQUE INDEX idx_user_product_order ON orders(user_id, product_id, created_at);
```
---
### **索引管理最佳实践**
#### **1. 查看现有索引**
```sql
-- 查看表的所有索引
SHOW INDEX FROM users;
-- 查看索引大小和使用情况
SELECT * FROM information_schema.STATISTICS
WHERE TABLE_NAME = 'users';
```
#### **2. 性能测试**
```sql
-- 使用EXPLAIN分析查询执行计划
EXPLAIN SELECT * FROM users WHERE email = 'test@example.com';
-- 检查是否使用了索引
EXPLAIN SELECT * FROM orders WHERE user_id = 100 AND created_at > '2024-01-01';
```
#### **3. 定期维护**
```sql
-- 优化表,整理索引碎片
OPTIMIZE TABLE users;
-- 分析表,更新索引统计信息
ANALYZE TABLE orders;
```
---
### **创建索引的注意事项总结**
1. **选择合适时机**
- 在数据稳定后创建索引
- 避免在业务高峰期创建大表索引
2. **考虑存储引擎**
```sql
-- InnoDB:支持事务、行级锁
-- MyISAM:全文索引性能更好
```
3. **索引命名规范**
- 使用有意义的名称:`idx_字段名` 或 `uk_字段名`(唯一索引)
- 保持一致性:整个项目使用相同的命名约定
4. **测试验证**
- 创建索引前后对比查询性能
- 使用EXPLAIN验证索引使用情况
5. **监控维护**
- 定期检查未使用的索引
- 删除冗余和重复的索引
### **重要提醒**:
- 索引不是越多越好,每个索引都有维护成本
- 在生产环境创建大表索引时,考虑使用 `ALGORITHM=INPLACE, LOCK=NONE` 减少锁表时间
- 定期监控索引使用情况,删除无效索引
5.3 视图的创建与使用
### **CREATE VIEW 语句**
#### **基本语法**
```sql
CREATE VIEW 视图名 AS
SELECT 语句;
```
---
### **视图的使用方法**
#### **1. 创建简单视图**
```sql
-- 创建员工基本信息视图
CREATE VIEW employee_basic_info AS
SELECT id, name, department, position, email
FROM employees;
-- 使用视图查询
SELECT * FROM employee_basic_info WHERE department = '技术部';
```
#### **2. 创建带计算的视图**
```sql
-- 创建销售统计视图
CREATE VIEW sales_summary AS
SELECT
product_id,
product_name,
SUM(quantity) as total_quantity,
SUM(amount) as total_amount,
AVG(price) as avg_price
FROM sales
GROUP BY product_id, product_name;
-- 使用视图获取销售排行
SELECT * FROM sales_summary ORDER BY total_amount DESC;
```
#### **3. 创建多表连接视图**
```sql
-- 创建订单详情视图
CREATE VIEW order_details AS
SELECT
o.order_id,
o.order_date,
c.customer_name,
c.phone,
p.product_name,
o.quantity,
o.amount
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN products p ON o.product_id = p.product_id;
-- 简化复杂查询
SELECT * FROM order_details WHERE customer_name = '张三';
```
#### **4. 创建带条件的视图**
```sql
-- 只显示活跃用户视图
CREATE VIEW active_users AS
SELECT user_id, username, email, last_login
FROM users
WHERE status = 'active' AND last_login > DATE_SUB(NOW(), INTERVAL 30 DAY);
-- 查询最近活跃用户
SELECT * FROM active_users ORDER BY last_login DESC;
```
---
### **视图管理操作**
#### **修改视图**
```sql
-- 方法1:先删除再创建
DROP VIEW IF EXISTS employee_basic_info;
CREATE VIEW employee_basic_info AS
SELECT id, name, department, position, email, phone
FROM employees;
-- 方法2:使用CREATE OR REPLACE
CREATE OR REPLACE VIEW employee_basic_info AS
SELECT id, name, department, position, email, phone
FROM employees;
```
#### **删除视图**
```sql
DROP VIEW IF EXISTS sales_summary;
```
#### **查看视图定义**
```sql
-- 查看视图创建语句
SHOW CREATE VIEW order_details;
-- 查看所有视图
SHOW FULL TABLES WHERE Table_type = 'VIEW';
```
---
### **视图在简化查询方面的作用**
#### **1. 简化复杂连接**
```sql
-- 原始复杂查询
SELECT
u.username,
u.email,
o.order_id,
o.order_date,
p.product_name,
o.quantity
FROM users u
JOIN orders o ON u.id = o.user_id
JOIN products p ON o.product_id = p.id
JOIN categories c ON p.category_id = c.id
WHERE u.status = 'active' AND o.status = 'completed';
-- 使用视图简化
CREATE VIEW user_order_details AS
SELECT
u.username,
u.email,
o.order_id,
o.order_date,
p.product_name,
o.quantity
FROM users u
JOIN orders o ON u.id = o.user_id
JOIN products p ON o.product_id = p.id
JOIN categories c ON p.category_id = c.id
WHERE u.status = 'active' AND o.status = 'completed';
-- 简化后的查询
SELECT * FROM user_order_details WHERE username = '李四';
```
#### **2. 封装业务逻辑**
```sql
-- 创建财务报表视图
CREATE VIEW financial_report AS
SELECT
DATE_FORMAT(transaction_date, '%Y-%m') as month,
account_type,
SUM(CASE WHEN transaction_type = 'income' THEN amount ELSE 0 END) as total_income,
SUM(CASE WHEN transaction_type = 'expense' THEN amount ELSE 0 END) as total_expense,
SUM(CASE WHEN transaction_type = 'income' THEN amount ELSE -amount END) as net_amount
FROM transactions
WHERE transaction_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY DATE_FORMAT(transaction_date, '%Y-%m'), account_type;
-- 简单获取月报
SELECT * FROM financial_report ORDER BY month, account_type;
```
#### **3. 数据格式化**
```sql
-- 创建格式化用户信息视图
CREATE VIEW formatted_user_info AS
SELECT
id,
CONCAT(first_name, ' ', last_name) as full_name,
CONCAT(SUBSTRING(phone, 1, 3), '****', SUBSTRING(phone, 8)) as masked_phone,
CONCAT(SUBSTRING(email, 1, 3), '***@', SUBSTRING_INDEX(email, '@', -1)) as masked_email,
TIMESTAMPDIFF(YEAR, birthday, CURDATE()) as age
FROM users;
-- 直接获取格式化数据
SELECT full_name, masked_phone, age FROM formatted_user_info WHERE age > 25;
```
---
### **视图在数据安全方面的作用**
#### **1. 列级权限控制**
```sql
-- 创建公开用户信息视图(隐藏敏感字段)
CREATE VIEW public_user_profile AS
SELECT
id,
username,
nickname,
avatar,
register_date,
bio
FROM users;
-- 内部员工视图(包含联系方式)
CREATE VIEW internal_user_info AS
SELECT
id,
username,
email,
phone,
real_name,
register_date
FROM users;
-- 不同角色使用不同视图,实现数据权限控制
```
#### **2. 行级权限控制**
```sql
-- 部门经理只能查看本部门员工
CREATE VIEW department_employees AS
SELECT
e.id,
e.name,
e.position,
e.salary
FROM employees e
WHERE e.department_id = CURRENT_DEPARTMENT_ID(); -- 假设有获取当前用户部门的函数
-- 区域销售只能查看本区域订单
CREATE VIEW regional_orders AS
SELECT
o.order_id,
o.customer_name,
o.amount,
o.order_date
FROM orders o
WHERE o.region_id IN (SELECT region_id FROM sales_regions WHERE manager_id = CURRENT_USER_ID());
```
#### **3. 敏感数据脱敏**
```sql
-- 身份证号脱敏视图
CREATE VIEW masked_customer_info AS
SELECT
customer_id,
customer_name,
CONCAT('****', RIGHT(id_card, 4)) as masked_id_card,
CONCAT(SUBSTRING(phone, 1, 3), '****', SUBSTRING(phone, 8)) as masked_phone,
address
FROM customers;
-- 银行卡号脱敏
CREATE VIEW secure_payment_info AS
SELECT
payment_id,
order_id,
CONCAT('****', RIGHT(card_number, 4)) as masked_card,
payment_amount,
payment_date
FROM payments;
```
---
### **视图的注意事项**
#### **1. 性能考虑**
```sql
-- 复杂视图可能影响性能
CREATE VIEW complex_sales_analysis AS
SELECT
s.sales_id,
s.sales_date,
e.name as salesperson,
c.name as customer,
p.name as product,
s.quantity,
s.amount,
(SELECT SUM(amount) FROM sales s2 WHERE s2.product_id = s.product_id) as product_total
FROM sales s
JOIN employees e ON s.employee_id = e.id
JOIN customers c ON s.customer_id = c.id
JOIN products p ON s.product_id = p.id;
-- 使用时要考虑性能影响
EXPLAIN SELECT * FROM complex_sales_analysis WHERE sales_date > '2024-01-01';
```
#### **2. 更新限制**
```sql
-- 可更新视图的条件:
-- 1. 来自单表
-- 2. 不包含聚合函数
-- 3. 不包含DISTINCT、GROUP BY、HAVING
-- 4. 不包含子查询
-- 可更新视图示例
CREATE VIEW updatable_employee_view AS
SELECT id, name, department, salary FROM employees;
-- 可以执行UPDATE
UPDATE updatable_employee_view SET salary = 8000 WHERE id = 1;
```
#### **3. 依赖管理**
```sql
-- 查看视图依赖
SELECT
TABLE_NAME as view_name,
VIEW_DEFINITION
FROM information_schema.VIEWS
WHERE TABLE_SCHEMA = 'your_database';
-- 修改基表结构时要注意视图影响
```
---
### **视图的优势总结**
1. **简化复杂查询**:封装复杂SQL,提供简单接口
2. **增强安全性**:隐藏敏感数据,控制访问权限
3. **逻辑独立性**:基表结构变化不影响应用程序
4. **数据一致性**:统一业务逻辑,减少重复代码
5. **权限管理**:通过视图实现细粒度的数据访问控制
### **使用建议**:
- 用于简化频繁使用的复杂查询
- 实现数据安全性和访问控制
- 保持视图简单,避免过度嵌套
- 定期检查和优化视图性能
六、SQL 语句实战案例
6.1 电商订单数据分析案例
### **电商订单数据分析 SQL 示例**
#### **数据表结构**
```sql
-- 客户表
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
email VARCHAR(100),
phone VARCHAR(20),
city VARCHAR(50),
registration_date DATE
);
-- 产品表
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(200),
category VARCHAR(50),
price DECIMAL(10,2),
cost DECIMAL(10,2),
supplier_id INT
);
-- 订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
status VARCHAR(20), -- 'pending', 'completed', 'cancelled'
total_amount DECIMAL(10,2),
shipping_city VARCHAR(50)
);
-- 订单明细表
CREATE TABLE order_items (
order_id INT,
product_id INT,
quantity INT,
unit_price DECIMAL(10,2),
PRIMARY KEY (order_id, product_id)
);
```
---
### **1. 基础数据查询**
#### **查询最近一个月的订单**
```sql
SELECT
order_id,
customer_id,
order_date,
total_amount,
status
FROM orders
WHERE order_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY)
ORDER BY order_date DESC;
```
#### **查询订单详情(多表连接)**
```sql
SELECT
o.order_id,
o.order_date,
c.customer_name,
c.city,
p.product_name,
oi.quantity,
oi.unit_price,
(oi.quantity * oi.unit_price) as item_total
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.status = 'completed'
ORDER BY o.order_date DESC;
```
---
### **2. 销售统计分析**
#### **月度销售趋势分析**
```sql
SELECT
YEAR(order_date) as year,
MONTH(order_date) as month,
COUNT(*) as order_count,
SUM(total_amount) as total_sales,
AVG(total_amount) as avg_order_value
FROM orders
WHERE status = 'completed'
AND order_date >= '2024-01-01'
GROUP BY YEAR(order_date), MONTH(order_date)
ORDER BY year, month;
```
#### **产品类别销售排行**
```sql
SELECT
p.category,
COUNT(DISTINCT o.order_id) as order_count,
SUM(oi.quantity) as total_quantity,
SUM(oi.quantity * oi.unit_price) as total_sales,
AVG(oi.quantity * oi.unit_price) as avg_sale_amount
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.status = 'completed'
GROUP BY p.category
ORDER BY total_sales DESC;
```
#### **热销产品TOP 10**
```sql
SELECT
p.product_id,
p.product_name,
p.category,
SUM(oi.quantity) as total_sold,
SUM(oi.quantity * oi.unit_price) as total_revenue,
COUNT(DISTINCT o.order_id) as order_count
FROM products p
JOIN order_items oi ON p.product_id = oi.product_id
JOIN orders o ON oi.order_id = o.order_id
WHERE o.status = 'completed'
GROUP BY p.product_id, p.product_name, p.category
ORDER BY total_sold DESC
LIMIT 10;
```
---
### **3. 客户行为分析**
#### **客户价值分析(RFM模型)**
```sql
SELECT
customer_id,
customer_name,
-- Recency: 最近购买时间
DATEDIFF(CURDATE(), MAX(order_date)) as recency_days,
-- Frequency: 购买频率
COUNT(DISTINCT order_id) as frequency,
-- Monetary: 总消费金额
SUM(total_amount) as monetary
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.status = 'completed'
GROUP BY customer_id, customer_name
ORDER BY monetary DESC;
```
#### **新老客户分析**
```sql
SELECT
CASE
WHEN DATEDIFF(o.order_date, c.registration_date) <= 30 THEN '新客户'
ELSE '老客户'
END as customer_type,
COUNT(DISTINCT o.customer_id) as customer_count,
COUNT(DISTINCT o.order_id) as order_count,
SUM(o.total_amount) as total_sales,
AVG(o.total_amount) as avg_order_value
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.status = 'completed'
GROUP BY customer_type;
```
#### **城市销售分布**
```sql
SELECT
c.city,
COUNT(DISTINCT o.customer_id) as customer_count,
COUNT(DISTINCT o.order_id) as order_count,
SUM(o.total_amount) as total_sales,
AVG(o.total_amount) as avg_order_value
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.status = 'completed'
GROUP BY c.city
ORDER BY total_sales DESC;
```
---
### **4. 库存和利润分析**
#### **产品利润分析**
```sql
SELECT
p.product_id,
p.product_name,
p.category,
SUM(oi.quantity) as total_sold,
SUM(oi.quantity * oi.unit_price) as total_revenue,
SUM(oi.quantity * p.cost) as total_cost,
SUM(oi.quantity * (oi.unit_price - p.cost)) as total_profit,
ROUND((SUM(oi.quantity * (oi.unit_price - p.cost)) / SUM(oi.quantity * oi.unit_price)) * 100, 2) as profit_margin
FROM products p
JOIN order_items oi ON p.product_id = oi.product_id
JOIN orders o ON oi.order_id = o.order_id
WHERE o.status = 'completed'
GROUP BY p.product_id, p.product_name, p.category
HAVING total_sold > 0
ORDER BY total_profit DESC;
```
#### **月度利润趋势**
```sql
SELECT
YEAR(o.order_date) as year,
MONTH(o.order_date) as month,
SUM(oi.quantity * oi.unit_price) as total_revenue,
SUM(oi.quantity * p.cost) as total_cost,
SUM(oi.quantity * (oi.unit_price - p.cost)) as total_profit,
ROUND((SUM(oi.quantity * (oi.unit_price - p.cost)) / SUM(oi.quantity * oi.unit_price)) * 100, 2) as profit_margin
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.status = 'completed'
GROUP BY YEAR(o.order_date), MONTH(o.order_date)
ORDER BY year, month;
```
---
### **5. 高级分析查询**
#### **客户购买行为分析**
```sql
-- 客户购买间隔和频次分析
WITH customer_stats AS (
SELECT
customer_id,
COUNT(*) as order_count,
MIN(order_date) as first_order_date,
MAX(order_date) as last_order_date,
DATEDIFF(MAX(order_date), MIN(order_date)) as active_days,
SUM(total_amount) as total_spent
FROM orders
WHERE status = 'completed'
GROUP BY customer_id
HAVING order_count > 1
)
SELECT
CASE
WHEN order_count = 1 THEN '1次'
WHEN order_count BETWEEN 2 AND 5 THEN '2-5次'
WHEN order_count BETWEEN 6 AND 10 THEN '6-10次'
ELSE '10次以上'
END as order_frequency,
COUNT(*) as customer_count,
AVG(total_spent) as avg_total_spent,
AVG(active_days) as avg_active_days
FROM customer_stats
GROUP BY order_frequency
ORDER BY MIN(order_count);
```
#### **购物篮分析(关联规则)**
```sql
-- 经常一起购买的产品组合
SELECT
p1.product_name as product_a,
p2.product_name as product_b,
COUNT(DISTINCT oi1.order_id) as co_occurrence_count
FROM order_items oi1
JOIN order_items oi2 ON oi1.order_id = oi2.order_id AND oi1.product_id < oi2.product_id
JOIN products p1 ON oi1.product_id = p1.product_id
JOIN products p2 ON oi2.product_id = p2.product_id
JOIN orders o ON oi1.order_id = o.order_id
WHERE o.status = 'completed'
GROUP BY p1.product_name, p2.product_name
HAVING co_occurrence_count >= 5 -- 至少一起出现5次
ORDER BY co_occurrence_count DESC
LIMIT 20;
```
#### **客户留存分析**
```sql
-- 月度客户留存分析
WITH monthly_customers AS (
SELECT
DATE_FORMAT(order_date, '%Y-%m') as month,
customer_id
FROM orders
WHERE status = 'completed'
GROUP BY DATE_FORMAT(order_date, '%Y-%m'), customer_id
),
cohort_analysis AS (
SELECT
mc1.month as cohort_month,
mc2.month as activity_month,
COUNT(DISTINCT mc1.customer_id) as cohort_size,
COUNT(DISTINCT mc2.customer_id) as retained_customers,
ROUND(COUNT(DISTINCT mc2.customer_id) * 100.0 / COUNT(DISTINCT mc1.customer_id), 2) as retention_rate
FROM monthly_customers mc1
LEFT JOIN monthly_customers mc2 ON mc1.customer_id = mc2.customer_id
AND mc2.month >= mc1.month
GROUP BY mc1.month, mc2.month
)
SELECT
cohort_month,
activity_month,
cohort_size,
retained_customers,
retention_rate
FROM cohort_analysis
WHERE cohort_month >= '2024-01'
ORDER BY cohort_month, activity_month;
```
---
### **6. 创建分析视图**
#### **销售仪表板视图**
```sql
CREATE VIEW sales_dashboard AS
SELECT
DATE_FORMAT(o.order_date, '%Y-%m-%d') as order_date,
c.city,
p.category,
COUNT(DISTINCT o.order_id) as daily_orders,
SUM(oi.quantity) as total_items,
SUM(o.total_amount) as daily_sales,
COUNT(DISTINCT o.customer_id) as daily_customers
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.status = 'completed'
GROUP BY DATE_FORMAT(o.order_date, '%Y-%m-%d'), c.city, p.category;
```
#### **使用视图进行快速分析**
```sql
-- 查看最近7天销售情况
SELECT
order_date,
SUM(daily_orders) as orders,
SUM(daily_sales) as sales,
SUM(daily_customers) as customers
FROM sales_dashboard
WHERE order_date >= DATE_SUB(CURDATE(), INTERVAL 7 DAY)
GROUP BY order_date
ORDER BY order_date DESC;
```
---
### **关键分析指标总结**
1. **销售指标**:销售额、订单量、客单价
2. **客户指标**:新老客户比例、复购率、客户价值
3. **产品指标**:热销产品、利润率、库存周转
4. **趋势指标**:月度增长、季节性变化
5. **行为指标**:购买频次、购物篮分析、留存率
这些 SQL 查询可以帮助电商企业全面了解业务状况,为决策提供数据支持。
6.2 企业员工信息管理案例
### **企业员工信息管理系统 SQL 应用**
#### **数据表结构**
```sql
CREATE TABLE employees (
emp_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
department VARCHAR(50),
position VARCHAR(50),
salary DECIMAL(10,2),
hire_date DATE,
email VARCHAR(100),
status VARCHAR(20) DEFAULT 'active'
);
CREATE TABLE departments (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50),
manager_id INT
);
```
---
### **1. 数据插入(INSERT)**
#### **新增员工**
```sql
-- 单条插入
INSERT INTO employees (name, department, position, salary, hire_date, email)
VALUES ('张三', '技术部', '工程师', 15000, '2024-01-15', 'zhangsan@company.com');
-- 批量插入
INSERT INTO employees (name, department, position, salary, hire_date) VALUES
('李四', '销售部', '销售经理', 12000, '2024-02-01'),
('王五', '人事部', 'HR专员', 8000, '2024-02-10'),
('赵六', '技术部', '前端开发', 13000, '2024-02-15');
```
#### **新增部门**
```sql
INSERT INTO departments (dept_id, dept_name, manager_id) VALUES
(1, '技术部', 101),
(2, '销售部', 102),
(3, '人事部', 103);
```
---
### **2. 数据更新(UPDATE)**
#### **员工调薪**
```sql
-- 单个员工调薪
UPDATE employees
SET salary = 16000
WHERE emp_id = 1;
-- 部门整体调薪(技术部加薪10%)
UPDATE employees
SET salary = salary * 1.1
WHERE department = '技术部';
-- 岗位晋升
UPDATE employees
SET position = '高级工程师', salary = 18000
WHERE emp_id = 1 AND department = '技术部';
```
#### **员工离职处理**
```sql
-- 软删除:标记为离职状态
UPDATE employees
SET status = 'inactive', position = '已离职'
WHERE emp_id = 5;
-- 部门经理变更
UPDATE departments
SET manager_id = 201
WHERE dept_id = 1;
```
---
### **3. 数据删除(DELETE)**
#### **删除离职员工**
```sql
-- 删除特定离职员工(谨慎使用)
DELETE FROM employees
WHERE emp_id = 10 AND status = 'inactive';
-- 删除测试数据
DELETE FROM employees
WHERE name LIKE '测试%';
```
#### **清空部门**
```sql
-- 删除整个部门(需先处理员工数据)
DELETE FROM departments
WHERE dept_id = 4;
```
---
### **4. 数据查询(SELECT)**
#### **基础查询**
```sql
-- 查询所有在职员工
SELECT * FROM employees WHERE status = 'active';
-- 查询特定部门员工
SELECT name, position, salary
FROM employees
WHERE department = '技术部'
ORDER BY salary DESC;
-- 查询高薪员工
SELECT name, department, position, salary
FROM employees
WHERE salary > 10000 AND status = 'active';
```
#### **统计查询**
```sql
-- 部门人数统计
SELECT department, COUNT(*) as employee_count
FROM employees
WHERE status = 'active'
GROUP BY department;
-- 部门平均薪资
SELECT department,
AVG(salary) as avg_salary,
MAX(salary) as max_salary,
MIN(salary) as min_salary
FROM employees
WHERE status = 'active'
GROUP BY department;
-- 薪资分布统计
SELECT
CASE
WHEN salary < 8000 THEN '低薪'
WHEN salary BETWEEN 8000 AND 15000 THEN '中薪'
ELSE '高薪'
END as salary_level,
COUNT(*) as employee_count
FROM employees
WHERE status = 'active'
GROUP BY salary_level;
```
#### **高级查询**
```sql
-- 员工完整信息(连接部门表)
SELECT e.emp_id, e.name, e.position, e.salary, d.dept_name
FROM employees e
LEFT JOIN departments d ON e.department = d.dept_name
WHERE e.status = 'active';
-- 查询经理管理的员工
SELECT m.name as manager_name, e.name as employee_name, e.position
FROM employees e
JOIN departments d ON e.department = d.dept_name
JOIN employees m ON d.manager_id = m.emp_id
WHERE e.status = 'active';
-- 工龄分析
SELECT name, hire_date,
TIMESTAMPDIFF(YEAR, hire_date, CURDATE()) as work_years
FROM employees
WHERE status = 'active'
ORDER BY work_years DESC;
```
---
### **5. 综合应用场景**
#### **新员工入职流程**
```sql
-- 1. 插入新员工记录
INSERT INTO employees (name, department, position, salary, hire_date, email)
VALUES ('新员工', '技术部', '开发工程师', 12000, CURDATE(), 'new@company.com');
-- 2. 查询确认
SELECT * FROM employees WHERE name = '新员工';
```
#### **员工离职流程**
```sql
-- 1. 更新状态为离职
UPDATE employees
SET status = 'inactive', position = '已离职'
WHERE emp_id = 8;
-- 2. 统计当前在职人数
SELECT department, COUNT(*) as current_staff
FROM employees
WHERE status = 'active'
GROUP BY department;
```
#### **年度调薪流程**
```sql
-- 1. 技术部普调5%
UPDATE employees
SET salary = salary * 1.05
WHERE department = '技术部' AND status = 'active';
-- 2. 优秀员工额外加薪
UPDATE employees
SET salary = salary * 1.1
WHERE emp_id IN (1, 3, 7) AND status = 'active';
-- 3. 查看调薪结果
SELECT name, department, salary
FROM employees
WHERE status = 'active'
ORDER BY department, salary DESC;
```
---
### **实际应用要点**
1. **插入操作**:用于新增员工、部门等基础数据
2. **更新操作**:用于员工调薪、调岗、状态变更
3. **删除操作**:谨慎使用,优先使用软删除(状态标记)
4. **查询操作**:用于员工信息查看、统计分析、报表生成
### **安全建议**:
- 重要操作使用事务保证数据一致性
- 删除操作前先备份数据
- 生产环境使用软删除替代物理删除
- 敏感操作记录日志
七、SQL 语句优化与性能提升
7.1 常见的 SQL 性能问题
### **SQL 执行缓慢的常见原因分析**
#### **1. 全表扫描(Full Table Scan)**
**问题描述**:没有使用索引,扫描整个表
```sql
-- 执行缓慢的查询(无索引)
SELECT * FROM orders WHERE customer_name = '张三';
-- 解决方案:创建索引
CREATE INDEX idx_customer_name ON orders(customer_name);
```
**识别方法**:
```sql
EXPLAIN SELECT * FROM orders WHERE customer_name = '张三';
-- 结果中 type=ALL 表示全表扫描
```
---
#### **2. 索引失效**
**常见索引失效场景**:
**① 函数操作导致索引失效**
```sql
-- 索引失效:对字段使用函数
SELECT * FROM users WHERE DATE(create_time) = '2024-01-01';
-- 优化:避免字段函数操作
SELECT * FROM users WHERE create_time >= '2024-01-01' AND create_time < '2024-01-02';
```
**② 模糊查询前缀不明确**
```sql
-- 索引失效:以通配符开头
SELECT * FROM products WHERE name LIKE '%手机%';
-- 优化:尽量使用前缀匹配
SELECT * FROM products WHERE name LIKE '苹果%';
```
**③ 隐式类型转换**
```sql
-- 索引失效:字符串字段用数字查询
SELECT * FROM users WHERE phone = 13800138000;
-- 优化:保持类型一致
SELECT * FROM users WHERE phone = '13800138000';
```
**④ OR 条件使用不当**
```sql
-- 索引可能失效
SELECT * FROM employees WHERE department = '技术部' OR salary > 10000;
-- 优化:使用 UNION
SELECT * FROM employees WHERE department = '技术部'
UNION
SELECT * FROM employees WHERE salary > 10000;
```
---
#### **3. 数据量过大**
**问题表现**:
- 单表数据量超过千万级
- 查询返回大量数据
- 内存不足,频繁磁盘交换
**解决方案**:
```sql
-- ① 数据分页
SELECT * FROM large_table ORDER BY id LIMIT 0, 100;
-- ② 分区表
CREATE TABLE sales (
id INT,
sale_date DATE,
amount DECIMAL(10,2)
) PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);
-- ③ 归档历史数据
CREATE TABLE sales_archive AS
SELECT * FROM sales WHERE sale_date < '2023-01-01';
DELETE FROM sales WHERE sale_date < '2023-01-01';
```
---
#### **4. 内存和配置问题**
**相关配置**:
```sql
-- 查看缓冲池大小
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
-- 查看排序缓冲区
SHOW VARIABLES LIKE 'sort_buffer_size';
-- 查看连接数
SHOW VARIABLES LIKE 'max_connections';
```
**优化建议**:
- 增加 `innodb_buffer_pool_size`(通常设为物理内存的70-80%)
- 调整 `sort_buffer_size` 和 `join_buffer_size`
- 限制查询返回的数据量
---
#### **5. 复杂的 JOIN 和子查询**
**性能问题示例**:
```sql
-- 复杂的多表连接
SELECT *
FROM orders o
JOIN customers c ON o.customer_id = c.id
JOIN products p ON o.product_id = p.id
JOIN categories cat ON p.category_id = cat.id
JOIN suppliers s ON p.supplier_id = s.id
WHERE o.status = 'completed'
AND c.city = '北京'
AND cat.name = '电子产品';
-- 优化:使用冗余字段或视图
CREATE VIEW order_details AS
SELECT o.*, c.name as customer_name, p.name as product_name
FROM orders o
JOIN customers c ON o.customer_id = c.id
JOIN products p ON o.product_id = p.id;
SELECT * FROM order_details
WHERE status = 'completed' AND customer_city = '北京';
```
---
#### **6. 锁竞争**
**问题场景**:
```sql
-- 长时间运行的更新操作阻塞其他查询
UPDATE large_table SET status = 'processed' WHERE create_date < '2024-01-01';
-- 优化:分批更新
UPDATE large_table SET status = 'processed'
WHERE create_date < '2024-01-01' AND id BETWEEN 1 AND 1000;
-- 重复执行直到所有数据更新完成
```
---
### **性能诊断方法**
#### **1. 使用 EXPLAIN 分析**
```sql
EXPLAIN SELECT * FROM orders WHERE customer_id = 100;
-- 关注关键字段:
-- type: const > ref > range > index > ALL(性能从好到差)
-- key: 实际使用的索引
-- rows: 预估扫描行数
-- Extra: Using filesort, Using temporary 表示需要优化
```
#### **2. 慢查询日志分析**
```sql
-- 开启慢查询日志
SET GLOBAL slow_query_log = 1;
SET GLOBAL long_query_time = 2; -- 超过2秒的记录
-- 查看慢查询
SHOW VARIABLES LIKE 'slow_query_log%';
```
#### **3. 监控工具使用**
```sql
-- 查看当前进程
SHOW PROCESSLIST;
-- 查看表状态
SHOW TABLE STATUS LIKE 'orders';
-- 查看索引统计
SHOW INDEX FROM orders;
```
---
### **系统化优化方案**
#### **1. 索引优化策略**
```sql
-- 创建合适的复合索引
CREATE INDEX idx_order_customer_date ON orders(customer_id, order_date);
-- 删除冗余索引
DROP INDEX idx_customer ON orders;
-- 定期优化表
OPTIMIZE TABLE orders;
```
#### **2. 查询重写优化**
```sql
-- 原查询(性能差)
SELECT * FROM orders
WHERE YEAR(order_date) = 2024 AND MONTH(order_date) = 1;
-- 优化后
SELECT * FROM orders
WHERE order_date >= '2024-01-01' AND order_date < '2024-02-01';
```
#### **3. 架构层面优化**
- 读写分离
- 数据库分片
- 缓存层引入(Redis)
- ETL 预处理复杂报表
---
### **快速排查流程**
1. **使用 EXPLAIN 分析执行计划**
2. **检查是否使用合适索引**
3. **评估数据量和内存使用**
4. **分析锁等待情况**
5. **检查系统资源配置**
### **关键优化原则**:
- **索引为王**:确保查询使用合适的索引
- **数据量控制**:避免单次处理过多数据
- **避免全表扫描**:特别是大表的全表扫描
- **合理分页**:限制返回数据量
- **定期维护**:优化表结构、更新统计信息
7.2 优化策略与方法
### **SQL 语句优化方法和技巧**
#### **1. 创建合适的索引**
**索引优化原则**:
```sql
-- ① 为高频查询字段创建索引
CREATE INDEX idx_user_email ON users(email);
CREATE INDEX idx_order_date ON orders(order_date);
-- ② 创建复合索引(遵循最左前缀原则)
CREATE INDEX idx_user_region_status ON users(region, status, create_time);
-- ③ 为排序和分组字段创建索引
CREATE INDEX idx_product_price ON products(price DESC);
CREATE INDEX idx_dept_salary ON employees(department, salary);
-- ④ 避免过多索引(影响写性能)
-- 每个表保持5-8个索引为宜
```
**索引使用技巧**:
```sql
-- 覆盖索引:索引包含所有查询字段
CREATE INDEX idx_covering ON orders(customer_id, order_date, amount);
SELECT customer_id, order_date, amount FROM orders WHERE customer_id = 100;
-- 索引下推:MySQL 5.6+ 自动优化
SELECT * FROM users WHERE name LIKE '张%' AND age > 25;
-- 复合索引 (name, age) 可以同时过滤两个条件
```
---
#### **2. 优化查询语句**
**避免 SELECT ***:
```sql
-- 不推荐:返回不必要字段
SELECT * FROM orders WHERE customer_id = 100;
-- 推荐:只查询需要的字段
SELECT order_id, order_date, amount
FROM orders
WHERE customer_id = 100;
```
**优化 WHERE 条件**:
```sql
-- 不推荐:对索引字段使用函数
SELECT * FROM orders WHERE DATE(order_date) = '2024-01-01';
-- 推荐:使用范围查询
SELECT * FROM orders
WHERE order_date >= '2024-01-01' AND order_date < '2024-01-02';
-- 不推荐:模糊查询前导通配符
SELECT * FROM products WHERE name LIKE '%手机%';
-- 推荐:前缀匹配(可以使用索引)
SELECT * FROM products WHERE name LIKE '苹果%';
```
**避免隐式类型转换**:
```sql
-- 不推荐:字符串字段用数字查询
SELECT * FROM users WHERE phone = 13800138000;
-- 推荐:类型一致
SELECT * FROM users WHERE phone = '13800138000';
```
---
#### **3. 避免使用子查询**
**子查询优化**:
```sql
-- 不推荐:相关子查询(性能差)
SELECT name, salary
FROM employees e1
WHERE salary > (
SELECT AVG(salary)
FROM employees e2
WHERE e2.department = e1.department
);
-- 推荐:使用 JOIN 或窗口函数
SELECT e.name, e.salary
FROM employees e
JOIN (
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department
) dept_avg ON e.department = dept_avg.department
WHERE e.salary > dept_avg.avg_salary;
-- 或者使用窗口函数(MySQL 8.0+)
SELECT name, salary
FROM (
SELECT name, salary,
AVG(salary) OVER (PARTITION BY department) as dept_avg_salary
FROM employees
) t
WHERE salary > dept_avg_salary;
```
**IN 子查询优化**:
```sql
-- 不推荐:IN + 子查询
SELECT * FROM orders
WHERE customer_id IN (
SELECT customer_id FROM customers WHERE city = '北京'
);
-- 推荐:使用 JOIN
SELECT o.*
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE c.city = '北京';
-- 或者使用 EXISTS
SELECT * FROM orders o
WHERE EXISTS (
SELECT 1 FROM customers c
WHERE c.customer_id = o.customer_id AND c.city = '北京'
);
```
---
#### **4. JOIN 优化**
**JOIN 顺序和条件**:
```sql
-- 优化 JOIN 顺序:小表驱动大表
SELECT *
FROM small_table s
JOIN large_table l ON s.id = l.small_id;
-- 为 JOIN 字段创建索引
CREATE INDEX idx_join_key ON large_table(small_id);
-- 避免在 JOIN 条件中使用函数或计算
-- 不推荐
SELECT * FROM t1 JOIN t2 ON YEAR(t1.date) = YEAR(t2.date);
-- 推荐:预先计算或使用冗余字段
```
---
#### **5. LIMIT 分页优化**
**传统分页问题**:
```sql
-- 性能差:OFFSET 越大越慢
SELECT * FROM orders ORDER BY id LIMIT 10000, 20;
```
**优化方案**:
```sql
-- 方法1:使用游标分页(基于最后一条记录)
SELECT * FROM orders
WHERE id > 10000 -- 上一页最后一条的ID
ORDER BY id LIMIT 20;
-- 方法2:使用覆盖索引
SELECT o.*
FROM orders o
JOIN (SELECT id FROM orders ORDER BY id LIMIT 10000, 20) tmp
ON o.id = tmp.id;
```
---
#### **6. 批量操作优化**
**批量插入优化**:
```sql
-- 不推荐:单条插入
INSERT INTO users (name, age) VALUES ('张三', 25);
INSERT INTO users (name, age) VALUES ('李四', 30);
-- 推荐:批量插入
INSERT INTO users (name, age) VALUES
('张三', 25),
('李四', 30),
('王五', 28);
-- 大批量数据使用 LOAD DATA
LOAD DATA INFILE '/path/to/users.csv' INTO TABLE users;
```
**批量更新优化**:
```sql
-- 不推荐:循环单条更新
UPDATE products SET stock = 0 WHERE id = 1;
UPDATE products SET stock = 0 WHERE id = 2;
-- 推荐:批量更新
UPDATE products SET stock = 0 WHERE id IN (1, 2, 3);
-- 超大批量:分批更新
UPDATE products SET status = 'inactive'
WHERE id BETWEEN 1 AND 1000;
```
---
#### **7. 数据库设计优化**
**合理的数据类型**:
```sql
-- 选择合适的数据类型
CREATE TABLE users (
id INT UNSIGNED NOT NULL AUTO_INCREMENT, -- 无符号整型
phone CHAR(11) NOT NULL, -- 定长字符串
email VARCHAR(100), -- 变长字符串
balance DECIMAL(10,2) DEFAULT 0.00, -- 精确小数
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);
```
**规范化与反规范化平衡**:
```sql
-- 适度反规范化:减少 JOIN
CREATE TABLE orders (
order_id INT,
customer_id INT,
customer_name VARCHAR(100), -- 冗余字段,避免 JOIN customers 表
total_amount DECIMAL(10,2),
PRIMARY KEY (order_id)
);
```
---
#### **8. 使用 EXPLAIN 分析**
**执行计划分析**:
```sql
EXPLAIN SELECT * FROM users WHERE age > 25 AND city = '北京';
-- 关注关键指标:
-- type: const > ref > range > index > ALL
-- key: 使用的索引
-- rows: 扫描行数
-- Extra: Using filesort, Using temporary 需要优化
```
**优化案例**:
```sql
-- 优化前:全表扫描 + 文件排序
EXPLAIN SELECT * FROM orders WHERE amount > 1000 ORDER BY create_time;
-- 优化后:创建复合索引
CREATE INDEX idx_amount_time ON orders(amount, create_time);
EXPLAIN SELECT * FROM orders WHERE amount > 1000 ORDER BY create_time;
```
---
#### **9. 服务器配置优化**
**关键参数调整**:
```sql
-- 查看和调整配置
SHOW VARIABLES LIKE 'innodb_buffer_pool_size'; -- 缓冲池大小
SHOW VARIABLES LIKE 'query_cache_size'; -- 查询缓存
SHOW VARIABLES LIKE 'tmp_table_size'; -- 临时表大小
```
---
### **优化检查清单**
1. **✅ 是否使用合适的索引?**
2. **✅ 是否避免 SELECT *?**
3. **✅ 是否优化了 WHERE 条件?**
4. **✅ 是否重写了低效子查询?**
5. **✅ 是否优化了 JOIN 顺序?**
6. **✅ 是否使用高效分页?**
7. **✅ 是否使用批量操作?**
8. **✅ 数据类型是否合理?**
9. **✅ 是否分析过执行计划?**
### **性能优化效果**:
- **索引优化**:性能提升 10-100 倍
- **查询重写**:性能提升 2-10 倍
- **架构优化**:解决根本性能瓶颈
通过系统化应用这些优化技巧,可以显著提升 SQL 查询性能,减少数据库负载。
7.3 使用 EXPLAIN 分析执行计划
### **EXPLAIN 关键字使用方法**
#### **基本语法**
```sql
EXPLAIN SELECT * FROM users WHERE age > 25;
-- 或更详细的格式(MySQL 8.0+)
EXPLAIN FORMAT=JSON SELECT * FROM users WHERE age > 25;
```
#### **查看执行计划**
```sql
-- 分析查询性能
EXPLAIN SELECT u.name, o.order_date, o.amount
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.city = '北京' AND o.amount > 1000
ORDER BY o.order_date DESC;
```
---
### **执行计划关键字段解析**
#### **1. type(访问类型) - 最重要指标**
按性能从好到差排序:
```sql
-- const: 通过主键或唯一索引查询,最多返回一条记录
EXPLAIN SELECT * FROM users WHERE id = 1;
-- type: const, key: PRIMARY
-- ref: 使用非唯一索引查询
EXPLAIN SELECT * FROM users WHERE email = 'test@example.com';
-- type: ref, key: idx_email
-- range: 索引范围扫描
EXPLAIN SELECT * FROM users WHERE age BETWEEN 20 AND 30;
-- type: range, key: idx_age
-- index: 全索引扫描
EXPLAIN SELECT id FROM users;
-- type: index, key: 某个索引
-- ALL: 全表扫描(需要优化)
EXPLAIN SELECT * FROM users WHERE name LIKE '%张%';
-- type: ALL, key: NULL
```
#### **2. key(实际使用的索引)**
```sql
-- 使用索引的情况
EXPLAIN SELECT * FROM products WHERE category = '电子';
-- key: idx_category (如果存在该索引)
-- 未使用索引的情况
EXPLAIN SELECT * FROM products WHERE price > 100;
-- key: NULL (如果没有price索引)
```
#### **3. rows(预估扫描行数)**
```sql
-- 扫描行数越少越好
EXPLAIN SELECT * FROM orders WHERE user_id = 100;
-- rows: 5 (预估扫描5行)
EXPLAIN SELECT * FROM orders WHERE status = 'pending';
-- rows: 10000 (预估扫描10000行,需要优化)
```
#### **4. Extra(额外信息)**
**需要关注的警告信息**:
```sql
-- Using filesort: 需要额外的排序操作
EXPLAIN SELECT * FROM users ORDER BY name;
-- 优化:为ORDER BY字段创建索引
-- Using temporary: 使用临时表
EXPLAIN SELECT department, COUNT(*) FROM employees GROUP BY department;
-- 优化:为GROUP BY字段创建索引
-- Using where: 在存储引擎层之后进行过滤
EXPLAIN SELECT * FROM users WHERE age > 25 AND name LIKE '张%';
-- Using index: 覆盖索引,性能最好
EXPLAIN SELECT id, name FROM users WHERE name LIKE '张%';
```
---
### **执行计划实战分析**
#### **案例1:全表扫描问题**
```sql
-- 问题查询
EXPLAIN SELECT * FROM customers WHERE phone = '13800138000';
-- 执行计划结果:
-- type: ALL
-- key: NULL
-- rows: 10000
-- Extra: Using where
-- 优化方案:创建索引
CREATE INDEX idx_phone ON customers(phone);
-- 优化后验证
EXPLAIN SELECT * FROM customers WHERE phone = '13800138000';
-- type: ref, key: idx_phone, rows: 1
```
#### **案例2:文件排序问题**
```sql
-- 问题查询
EXPLAIN SELECT * FROM products ORDER BY price DESC;
-- 执行计划结果:
-- type: ALL
-- key: NULL
-- rows: 5000
-- Extra: Using filesort
-- 优化方案:创建排序索引
CREATE INDEX idx_price ON products(price DESC);
-- 优化后验证
EXPLAIN SELECT * FROM products ORDER BY price DESC;
-- type: index, key: idx_price, Extra: NULL
```
#### **案例3:复合索引优化**
```sql
-- 问题查询
EXPLAIN SELECT * FROM orders
WHERE user_id = 100 AND status = 'completed'
ORDER BY create_time DESC;
-- 执行计划结果:
-- type: ref
-- key: idx_user_id (只用了部分索引)
-- rows: 50
-- Extra: Using where; Using filesort
-- 优化方案:创建复合索引
CREATE INDEX idx_user_status_time ON orders(user_id, status, create_time DESC);
-- 优化后验证
EXPLAIN SELECT * FROM orders
WHERE user_id = 100 AND status = 'completed'
ORDER BY create_time DESC;
-- type: ref, key: idx_user_status_time, Extra: NULL
```
---
### **复杂查询的执行计划分析**
#### **多表 JOIN 分析**
```sql
EXPLAIN
SELECT u.name, o.order_date, p.product_name
FROM users u
JOIN orders o ON u.id = o.user_id
JOIN products p ON o.product_id = p.id
WHERE u.city = '北京' AND o.amount > 1000
ORDER BY o.order_date DESC;
-- 分析要点:
-- 1. 每个表的访问类型(type)
-- 2. JOIN 使用的索引(key)
-- 3. 表的连接顺序
-- 4. 是否有临时表或文件排序
```
#### **子查询优化分析**
```sql
-- 问题子查询
EXPLAIN
SELECT * FROM products
WHERE category_id IN (
SELECT id FROM categories WHERE name = '电子产品'
);
-- 优化为 JOIN
EXPLAIN
SELECT p.*
FROM products p
JOIN categories c ON p.category_id = c.id
WHERE c.name = '电子产品';
```
---
### **执行计划优化指南**
#### **优化优先级矩阵**
#### **系统化优化流程**
**步骤1:识别问题**
```sql
-- 运行EXPLAIN识别问题点
EXPLAIN SELECT * FROM large_table WHERE create_date > '2024-01-01';
```
**步骤2:创建合适索引**
```sql
-- 基于WHERE、ORDER BY、GROUP BY创建索引
CREATE INDEX idx_date ON large_table(create_date);
CREATE INDEX idx_category_status ON products(category, status);
```
**步骤3:验证优化效果**
```sql
-- 再次运行EXPLAIN确认优化效果
EXPLAIN SELECT * FROM large_table WHERE create_date > '2024-01-01';
```
**步骤4:监控查询性能**
```sql
-- 开启慢查询日志监控
SET GLOBAL slow_query_log = 1;
SET GLOBAL long_query_time = 2;
```
---
### **高级分析技巧**
#### **JSON格式详细分析(MySQL 8.0+)**
```sql
EXPLAIN FORMAT=JSON
SELECT u.name, COUNT(o.id) as order_count
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
GROUP BY u.id, u.name;
-- JSON结果包含:
-- query_cost: 查询成本估算
-- table: 每个表的访问详情
-- best_index: 最优索引建议
```
#### **对比优化前后**
```sql
-- 优化前
EXPLAIN SELECT * FROM orders WHERE YEAR(order_date) = 2024;
-- type: ALL, rows: 100000
-- 优化后
EXPLAIN SELECT * FROM orders WHERE order_date >= '2024-01-01' AND order_date < '2025-01-01';
-- type: range, rows: 50000, key: idx_order_date
```
---
### **常见性能问题及解决方案**
#### **问题1:全表扫描**
```sql
-- 症状:type = ALL, key = NULL
-- 解决方案:为WHERE条件字段创建索引
CREATE INDEX idx_search_field ON table_name(search_field);
```
#### **问题2:文件排序**
```sql
-- 症状:Extra = Using filesort
-- 解决方案:为ORDER BY字段创建索引
CREATE INDEX idx_sort_field ON table_name(sort_field);
```
#### **问题3:临时表**
```sql
-- 症状:Extra = Using temporary
-- 解决方案:为GROUP BY字段创建索引,或调整查询
CREATE INDEX idx_group_field ON table_name(group_field);
```
#### **问题4:索引覆盖不足**
```sql
-- 症状:虽然用了索引,但回表查询代价高
-- 解决方案:使用覆盖索引
CREATE INDEX idx_covering ON table_name(col1, col2, col3);
-- 查询只使用索引字段
SELECT col1, col2 FROM table_name WHERE col1 = 'value';
```
### **总结**
- **EXPLAIN是SQL优化的必备工具**
- **重点关注type、key、rows、Extra字段**
- **type为ALL或index通常需要优化**
- **Using filesort和Using temporary是警告信号**
- **通过创建合适的索引解决大部分性能问题**
- **定期分析慢查询的执行计划**
掌握EXPLAIN的使用方法,可以系统化地识别和解决SQL性能问题,显著提升数据库查询效率。
八、结论与展望
8.1 研究总结
### **MySQL SQL 语句全面总结**
#### **一、基础知识体系**
##### **1. 核心语句分类**
| 类别 | 语句 | 功能 |
|------|------|------|
| **DDL** | CREATE, ALTER, DROP | 定义数据库对象结构 |
| **DML** | INSERT, UPDATE, DELETE | 操作数据记录 |
| **DQL** | SELECT | 查询数据 |
| **DCL** | GRANT, REVOKE | 权限控制 |
##### **2. 数据类型掌握**
```sql
-- 数值类型
INT, BIGINT, DECIMAL(10,2), FLOAT
-- 字符串类型
CHAR(10), VARCHAR(100), TEXT
-- 日期时间
DATE, DATETIME, TIMESTAMP
```
##### **3. 关键查询组件**
```sql
SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY → LIMIT
```
---
### **二、实战应用场景**
#### **1. 电商系统应用**
```sql
-- 用户行为分析
SELECT user_id, COUNT(*) as order_count, SUM(amount) as total_spent
FROM orders
WHERE status = 'completed'
GROUP BY user_id
HAVING total_spent > 1000;
-- 商品销售排行
SELECT product_id, product_name, SUM(quantity) as total_sold
FROM order_items
GROUP BY product_id, product_name
ORDER BY total_sold DESC
LIMIT 10;
```
#### **2. 企业管理系统**
```sql
-- 员工绩效统计
SELECT department,
AVG(salary) as avg_salary,
COUNT(*) as emp_count,
MAX(performance_score) as best_score
FROM employees
WHERE status = 'active'
GROUP BY department;
-- 月度考勤汇总
SELECT employee_id,
COUNT(*) as work_days,
SUM(work_hours) as total_hours
FROM attendance
WHERE YEAR(work_date) = 2024 AND MONTH(work_date) = 1
GROUP BY employee_id;
```
#### **3. 金融数据分析**
```sql
-- 账户交易流水
SELECT account_no,
transaction_type,
SUM(amount) as total_amount,
COUNT(*) as transaction_count
FROM transactions
WHERE transaction_date BETWEEN '2024-01-01' AND '2024-01-31'
GROUP BY account_no, transaction_type;
```
---
### **三、性能优化方法**
#### **1. 索引优化策略**
```sql
-- 创建复合索引(最左前缀原则)
CREATE INDEX idx_user_order ON orders(user_id, order_date DESC);
-- 覆盖索引优化
CREATE INDEX idx_covering ON products(category, price, stock);
SELECT category, price FROM products WHERE category = '电子';
-- 避免索引失效
-- ✅ 正确:WHERE create_time >= '2024-01-01'
-- ❌ 错误:WHERE DATE(create_time) = '2024-01-01'
```
#### **2. 查询重写技巧**
```sql
-- 优化前:相关子查询
SELECT name FROM employees e1
WHERE salary > (SELECT AVG(salary) FROM employees e2
WHERE e2.department = e1.department);
-- 优化后:使用窗口函数
SELECT name FROM (
SELECT name, salary,
AVG(salary) OVER (PARTITION BY department) as dept_avg
FROM employees
) t WHERE salary > dept_avg;
```
#### **3. 分页性能优化**
```sql
-- 传统分页(性能差)
SELECT * FROM large_table LIMIT 10000, 20;
-- 优化分页(游标方式)
SELECT * FROM large_table WHERE id > 10000 ORDER BY id LIMIT 20;
```
---
### **四、EXPLAIN 执行计划分析**
#### **关键指标解读**
```sql
EXPLAIN SELECT * FROM users WHERE age > 25 AND city = '北京';
-- 重点关注:
-- type: const > ref > range > index > ALL
-- key: 实际使用的索引
-- rows: 预估扫描行数
-- Extra: Using filesort/temporary 需要优化
```
#### **优化案例**
```sql
-- 问题查询:全表扫描 + 文件排序
EXPLAIN SELECT * FROM products ORDER BY price DESC;
-- type: ALL, Extra: Using filesort
-- 解决方案:创建索引
CREATE INDEX idx_price ON products(price DESC);
-- 优化后:type: index, Extra: NULL
```
---
### **五、高级特性应用**
#### **1. 视图简化复杂查询**
```sql
CREATE VIEW sales_summary AS
SELECT product_id,
SUM(quantity) as total_sold,
SUM(amount) as total_revenue
FROM order_items
GROUP BY product_id;
-- 简化使用
SELECT * FROM sales_summary ORDER BY total_revenue DESC;
```
#### **2. 事务保证数据一致性**
```sql
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
-- 或者出错时 ROLLBACK;
```
#### **3. 存储过程和函数**
```sql
DELIMITER //
CREATE PROCEDURE CalculateEmployeeBonus(IN emp_id INT)
BEGIN
UPDATE employees
SET bonus = salary * 0.1
WHERE id = emp_id AND performance_score > 90;
END //
DELIMITER ;
```
---
### **六、学习路径建议**
#### **阶段1:基础掌握(1-2周)**
- ✅ 增删改查基本操作
- ✅ 条件查询、排序、分组
- ✅ 多表连接查询
#### **阶段2:进阶应用(2-3周)**
- ✅ 子查询、视图、事务
- ✅ 索引创建和使用
- ✅ 基本性能优化
#### **阶段3:高级优化(3-4周)**
- ✅ 执行计划分析
- ✅ 复杂查询优化
- ✅ 数据库设计原则
#### **阶段4:实战精通(持续学习)**
- ✅ 业务场景解决方案
- ✅ 大数据量处理
- ✅ 高并发优化
---
### **七、掌握 SQL 的重要性**
#### **1. 职业竞争力**
- **数据时代核心技能**:所有互联网公司都需要SQL人才
- **薪资水平优势**:掌握SQL优化的工程师薪资普遍更高
- **跨岗位适用**:开发、测试、产品、运营都需要SQL基础
#### **2. 工作效率提升**
```sql
-- 手动处理:几小时
-- SQL处理:几分钟
SELECT user_id,
COUNT(DISTINCT order_id) as order_count,
SUM(amount) as total_amount,
AVG(amount) as avg_order_value
FROM orders
GROUP BY user_id;
```
#### **3. 数据处理能力**
- **数据提取**:从海量数据中快速获取所需信息
- **数据分析**:通过聚合统计发现业务规律
- **数据驱动决策**:为产品优化提供数据支持
#### **4. 系统性能保障**
- **查询优化**:提升应用响应速度
- **资源节约**:减少数据库服务器压力
- **用户体验**:保证系统流畅运行
---
### **八、最佳实践建议**
#### **1. 编码规范**
```sql
-- ✅ 好的实践
SELECT user_id, user_name, email
FROM users
WHERE status = 'active'
AND create_date >= '2024-01-01'
ORDER BY create_date DESC
LIMIT 100;
-- ❌ 避免的做法
SELECT * FROM users WHERE status='active' ORDER BY create_date;
```
#### **2. 安全考虑**
```sql
-- 使用参数化查询防止SQL注入
PREPARE stmt FROM 'SELECT * FROM users WHERE id = ?';
SET @id = 100;
EXECUTE stmt USING @id;
```
#### **3. 性能意识**
- 所有查询都要考虑执行计划
- 定期分析慢查询日志
- 建立合适的索引策略
---
### **总结**
**MySQL SQL 的掌握程度直接决定了一个开发者的数据处理能力和系统架构水平。** 从基础语法到高级优化,从简单查询到复杂分析,SQL 是连接业务需求与技术实现的桥梁。
**核心价值体现**:
- 🔧 **基础能力**:日常开发中的数据处理
- 📊 **分析能力**:业务数据的深度洞察
- 🚀 **优化能力**:系统性能的关键保障
- 💡 **架构能力**:数据库设计的核心依据
**持续学习建议**:
1. **多实践**:在实际项目中应用SQL
2. **善分析**:使用EXPLAIN理解查询行为
3. **跟发展**:关注MySQL新版本特性
4. **扩视野**:学习其他数据库的SQL特性
掌握SQL不仅是一项技术技能,更是数据思维和系统思维的体现,是在数据驱动时代保持竞争力的重要保障。
8.2 未来发展趋势
当前数据库领域正处在一个激动人心的变革时期,MySQL 和 SQL 作为其中的重要组成部分,其未来发展呈现出**云原生与分布式、智能化运维、与AI深度集成**等几大核心趋势。下面这个表格能帮你快速了解这些趋势的核心方向和对技术的影响:
### 🔮 主要发展趋势解读
#### 🚀 架构向云原生与分布式演进
传统的单机MySQL实例在面对海量数据和高并发场景时显得力不从心,因此,**云原生**和**分布式架构**正成为MySQL明确的发展方向。
* **核心价值**:通过**弹性扩缩容**和**分布式部署**,企业可以轻松应对流量高峰,并实现跨地域的高可用容灾,同时运维模式也向自动化演进,显著降低成本。
* **形态演进**:**Serverless数据库**是这一趋势的深化,它让开发者无需关心底层服务器的配置与数量,真正实现按需使用和付费。
#### 🤖 运维走向智能化与自治化
随着AI技术的渗透,数据库的运维方式正在发生根本性改变,从依赖人工经验走向**智能化与自治化**。
* **AI赋能运维**:未来的MySQL将更深入地集成AI能力,实现**自诊断、自修复**等自治功能。例如,系统可以自动进行索引推荐、查询重写,甚至预测潜在的性能瓶颈并提前干预。
* **交互方式变革**:DBA(数据库管理员)可以通过**自然语言**向数据库发出指令,驱动其完成复杂的运维操作,这将极大提升效率。
#### 🧠 与AI的深度融合
AI,特别是大语言模型(LLM),正在改变我们与数据库交互的方式,并推动数据库内核能力的扩展。
* **自然语言交互**:Gartner预测,到2026年,自然语言将成为主要的查询接口。这意味着未来你或许只需对数据库说“找出上一季度贡献最大的客户”,就能得到想要的结果,**SQL可能从必备技能变为可选技能**。
* **处理非结构化数据**:AI应用产生了大量非结构化数据(如图片、文本、音频),传统SQL数据库难以高效处理。**向量数据库**(如Milvus)应运而生,专门用于处理向量嵌入,支持高效的相似性搜索。虽然一些传统数据库(如PostgreSQL)尝试通过扩展来支持向量操作,但在性能和架构上可能并非最优解。未来,MySQL生态可能会更深度地集成或融合这类专门处理AI数据的能力。
#### 🔄 多模融合与统一
为了应对业务场景的多元化,数据库正从“一库一事”向 **“一库多模”** 演进。
* **化繁为简**:“融合数据库”旨在用一个数据库产品同时支持**关系、文档、向量、图**等多种数据模型,并通过一条SQL完成复杂检索。这极大地简化了技术栈,降低了开发和运维的复杂性。
### 💡 对技术与从业者的影响
1. **技术选型与架构设计**:在进行技术选型时,应更倾向于支持**云原生分布式架构**的数据库解决方案。在架构设计上,可以考虑采用"融合数据库"来统一技术栈,或者采用"**多模并存**"的策略,让专业的数据库处理其最擅长的任务。
2. **职业发展与技能准备**:对于开发者和管理员而言,需要主动拥抱变化:
* **掌握分布式架构原理**与**云上运维**知识变得至关重要。
* 了解并学习**向量数据处理**等与AI相关的数据库新范式。
* **SQL技能依然是重要基础**,但其角色可能从“直接编写”转变为“理解与优化AI生成的查询”。同时,与**AI运维智能体协同工作**将成为新常态。
### 💎 总结
总的来说,MySQL和SQL的未来之路将由**云原生、智能化、AI融合**三大引擎驱动。它们将从一个可靠的数据存储工具,演进为一个**智能、自适应、多模的数据处理基石**。
希望以上信息能帮助你更好地把握未来。在这个快速变化的时代,你对数据库技术的哪个发展方向最感兴趣呢?(喜欢就给我点点关注吧,谢谢大家❤)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)