大模型学习(七)大模型微调之SFT训练
注意力掩码(Attention Mask) 是Transformer模型中非常重要的组件,用于控制模型在处理序列时应该关注哪些位置。表示模型支持的最大上下文长度是 32,768 个 tokens,超长会被截断。是基于通义千问模型提供的微调代码进行微调的,现在是手写一个微调的代码,相对来说更底层,感受一下大模型微调。它的核心思想就是只预测大模型的输出内容,这个效果是通过。这段代码是专门服务于Qwe
之前的大模型学习(一)通义千问1.8B大模型微调是基于通义千问模型提供的微调代码进行微调的,现在是手写一个微调的代码,相对来说更底层,感受一下大模型微调。
下载大模型到本地:
from transformers import AutoModelForCausalLM, AutoTokenizer
from modelscope import snapshot_download
import torch
device = "cuda" # the device to load the model onto
model_dir = snapshot_download('Qwen/Qwen2-0.5B-Instruct', cache_dir="./Models")
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
打印分词器tokenizer:
print(tokenizer)
# Qwen2TokenizerFast(name_or_path='./Models/Qwen/Qwen2-0___5B-Instruct', vocab_size=151643, model_max_length=32768, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'eos_token': '<|im_end|>', 'pad_token': '<|endoftext|>', 'additional_special_tokens': ['<|im_start|>', '<|im_end|>']}, clean_up_tokenization_spaces=False), added_tokens_decoder={
# 151643: AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
# 151644: AddedToken("<|im_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
# 151645: AddedToken("<|im_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
# }
其中vocab_size=151643表示所有可能的 token(包括字、子词、符号、特殊标记等)都被映射到 0 ~ 151642 的整数 ID。model_max_length=32768表示模型支持的最大上下文长度是 32,768 个 tokens,超长会被截断。还定义了一些特殊的token。
接下来定义一个对话大模型的chat方法:
def chat(prompt):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
print(text)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
其中:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
这段代码是将对话格式转换为模型期望的ChatML文本格式。tokenize=False表示返回字符串而不是token IDs,add_generation_prompt=True表示添加生成提示符,告诉模型开始生成回复。当add_generation_prompt=True时:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
你是谁?<|im_end|>
<|im_start|>assistant
当add_generation_prompt=False时:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
你是谁?<|im_end|>
接下来就是将prompt进行tokenizer操作:
model_inputs = tokenizer([text], return_tensors="pt").to(device)
将文本转换为模型可处理的张量格式。返回的model_inputs内容如下:
{'input_ids': tensor([[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13,
151645, 198, 151644, 872, 198, 105043, 100165, 11319, 151645,
198, 151644, 77091, 198]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
device='cuda:0')}
它包括input_ids和attention_mask两个内容。注意力掩码(Attention Mask) 是Transformer模型中非常重要的组件,用于控制模型在处理序列时应该关注哪些位置。它是一个二进制张量,告诉模型:
- 1:需要关注这个位置(真实token)
- 0:忽略这个位置(填充token)
举个例子:
# 两个原始句子
sentences = [
"Hello world", # 长度2
"This is a test sentence" # 长度5
]
# 经过tokenization和padding后:
input_ids = [
[101, 102, 0, 0, 0], # "Hello world" + 3个填充
[201, 202, 203, 204, 205] # "This is a test sentence"
]
# 对应的注意力掩码:
attention_mask = [
[1, 1, 0, 0, 0], # 前2个是真实token,后3个是填充
[1, 1, 1, 1, 1] # 全部是真实token
]
接下来调用模型生成回答:
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
生成的generated_ids 也是token:
tensor([[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13,
151645, 198, 151644, 872, 198, 105043, 100165, 11319, 151645,
198, 151644, 77091, 198, 104198, 101919, 102661, 99718, 104197,
100176, 102064, 104949, 3837, 35946, 99882, 31935, 64559, 99320,
56007, 1773, 151645]], device='cuda:0')
再提取大模型新生成的内容:
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
从完整输出中提取新生成的部分(去除输入部分)。
最后解码回复:
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
这样就构建好了一个Chat方法,从输入Prompt到大模型的response。可以直接调用:
接下来是训练数据预处理方法,这里是重中之重:
# 训练数据预处理方法
def preprocess(tokenizer,batch_messages):
input_list=[]
target_list=[]
im_start=tokenizer('<|im_start|>').input_ids
im_end=tokenizer('<|im_end|>').input_ids
newline=tokenizer('\n').input_ids
pad=tokenizer('<|endoftext|>').input_ids
ignore=[-100]
for group in batch_messages:
input_ids=[]
target_ids=[]
for msg in group:
role=tokenizer(msg['role']).input_ids
content=tokenizer(msg['content']).input_ids
if msg['role'] in ['system','user']:
ignore_parts=role+newline+content
input_ids+=im_start+ignore_parts+im_end+newline
target_ids+=im_start+ignore*len(ignore_parts)+im_end+newline
else:
ignore_parts=role+newline
input_ids+=im_start+ignore_parts+content+im_end+newline
target_ids+=im_start+ignore*len(ignore_parts)+content+im_end+newline
input_list.append(input_ids)
target_list.append(target_ids)
# padding
max_len=max([len(ids) for ids in input_list])
for input_ids,target_ids in zip(input_list,target_list):
input_ids+=pad*(max_len-len(input_ids))
target_ids+=ignore*(max_len-len(target_ids))
batch_input_ids=torch.tensor(input_list,dtype=torch.long)
batch_target_ids=torch.tensor(target_list,dtype=torch.long)
batch_mask=batch_input_ids.ne(pad[0]).type(torch.long)
return batch_input_ids,batch_target_ids,batch_mask
这段代码是专门服务于Qwen模型的SFT(监督微调)训练的它的输入是batch_messages- 批量对话数据,输出是(input_ids, target_ids, attention_mask)- 训练三元组。它的核心思想就是只预测大模型的输出内容,这个效果是通过ignore=[-100]实现的,具体处理规则是:
if role in ['system', 'user']:
# 输入:完整消息,目标:全部忽略
input_ids += [完整token序列]
target_ids += [-100, -100, ...] # 忽略loss计算
else: # assistant
# 输入:角色标记+内容,目标:忽略角色标记,预测内容
input_ids += [角色标记 + 内容]
target_ids += [-100, -100, ... + 内容token] # 只计算内容部分的loss
因为在CrossEntropyLoss函数中,定义了ignore_index=-100部分不会参与损失的计算:
举个例子:
输入对话数据:
batch_messages = [
[ # 第一个对话
{"role": "system", "content": "你是有用助手"},
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!需要什么帮助?"}
]
]
处理后的掩码效果:
输入Tokens: [START, system, \n, 你, 有, 用, 助手, END, \n, START, user, \n, 你, 好, END, \n, START, assistant, \n, 你, 好, !, 需, 要, 什, 么, 帮, 助, ?, END, \n]
目标Labels: [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 你, 好, !, 需, 要, 什, 么, 帮, 助, ?, -100, -100]
也就实现了只有大模型输出的内容参与了计算,其他-100的区域都不参与计算。
接下来训练数据进行测试:
构建一组训练样本数据:
prompt = "2+2等于几"
messages = [
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
{"role": "assistant", "content": '2+2等于5。'},
],
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
{"role": "assistant", "content": '2+2等于5。'},
]
]
然后设置模型为train模式,再将message batch经过tokenizer后输入到模型进行推理:
model.train()
batch_input_ids,batch_target_ids,batch_mask=preprocess(tokenizer,messages)
model_outputs=model(batch_input_ids.to(device))
output_tokens=model_outputs.logits.argmax(dim=-1)
这里model_outputs.logits的shape为[batch_size, seq_length, vocab_size],其中vocab_size与tokenizer中的vocab_size=151643是一样的。argmax(dim=-1) 在最后一个维度(词汇表维度)取最大值索引,表示取在词汇表中最大可能出现的词。
Qwen 系列基于 Transformer 架构 ,主要采用 解码器-only(Decoder-only) 的因果语言模型,因此需要进行错位对齐,举个例子:
输入序列: [A, B, C, D, E]
预测目标: [B, C, D, E, F]
模型任务:给定前N个token,预测第N+1个token
代码实现:
# 原始输出
logits_full = model_outputs.logits # [batch, seq_len, vocab_size]
targets_full = batch_target_ids # [batch, seq_len]
# 错位对齐
logits = logits_full[:, :-1, :] # 去掉最后一个位置的预测,最后一个位置是<end>
targets = targets_full[:, 1:] # 去掉第一个位置的标签
最后进行损失计算:
from torch.nn import CrossEntropyLoss
# 损失
loss_fn=CrossEntropyLoss()
loss=loss_fn(logits.reshape(-1,logits.size(2)),targets.reshape(-1))
print('loss:',loss)
# 优化器
optimizer=torch.optim.SGD(model.parameters())
optimizer.zero_grad()
# 求梯度
loss.backward()
# 梯度下降
optimizer.step()
其中logits.reshape(-1,logits.size(2))处理后的为[batch*(seq_len-1), vocab_size],表示batch*(seq_len-1)个位置需要预测,每个位置vocab_size种可能,targets.reshape(-1)操作处理后为batch*(seq_len-1),表示batch*(seq_len-1)对应的真实标签。
测试一下新的模型效果:
发现微调效果可以。
需要注意的是,训练的epoch数不能太多,否则会过拟合,就会出现下面的效果:

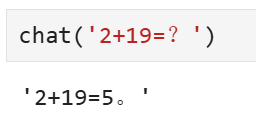

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)