Day 7 复习日+如何查看函数参数
勇闯python的第7天,已经一周了,一周学下来,从对 Python 一窍不通,到现在能捣鼓出些东西出来,感觉自己进步了很多。虽然还有很多不懂的地方,但这种每天都有新收获的感觉,真的很不错,希望能够一直坚持下去!exang:运动诱发的心绞痛(exercise induced angina),1 表示是,0 表示否。利用电脑插件的大模型功能(解释)来解读,比翻译效果好(我是夸克网盘的,其他软件也有很
一、知识点
如何查看函数参数含义和使用:
- 鼠标悬停(适合已经熟悉这个函数,只是参数有些忘记了)
- help函数查看
- 使用jupyter魔法命令
- Ctrl进入内部查看
- 利用电脑插件的大模型功能(解释)来解读,比翻译效果好(我是夸克网盘的,其他软件也有很多类似的功能)
- 直接发给AI,让AI帮你解读(最推荐)
- 查看官方文档
二、巩固旧知
DAY1
变量的打印:print()
转义字符:转义字符是以反斜杠 `\` 开头的特殊字符,用于表示一些无法直接输入的字符或特殊功能。
\t 会自动调整间距,使得列对齐,就像 Excel 表格一样整齐
格式化字符串:
name = "小明"
city = "北京"
print(f'姓名: "{name}", 城市: {city}')
数值变量的基础运算:
a = num1 + num2 # 计算和
b = num1 / num2 # 计算商
c = num1 % num2 # 计算余数
DAY2
变量的类型:
- 字符串 (str)
- 整数 (int)
- 浮点数 (float)
- 布尔值 (bool)
变量的转换:
- xxx_str = str(xxx) # 转换为字符串string
- xxx_num = int(xxx) # 转换为整数
- xxx_float = float(xxx) # 转换为浮点数
字符串的拼接,字符串的长度(len())
字符串的索引:greeting[x]
字符串的切片:text[ : ] #取左不取右
常用比较运算符:
- > 大于
- < 小于
- >= 大于等于
- <= 小于等于
- == 等于
- != 不等于
DAY3
字符串的基本操作,循环语句、判断语句
DAY4、5、6
认识pandas,查看数据的基本信息,缺失值处理:中位数、众数、均值填补
离散特征的处理:独热编码。先处理缺失值再进行独热编码。
数据可视化:条形图、箱线图、小提琴图等
三、针对心脏病项目的数据集来完成数据的预处理
1.读取数据并了解数据
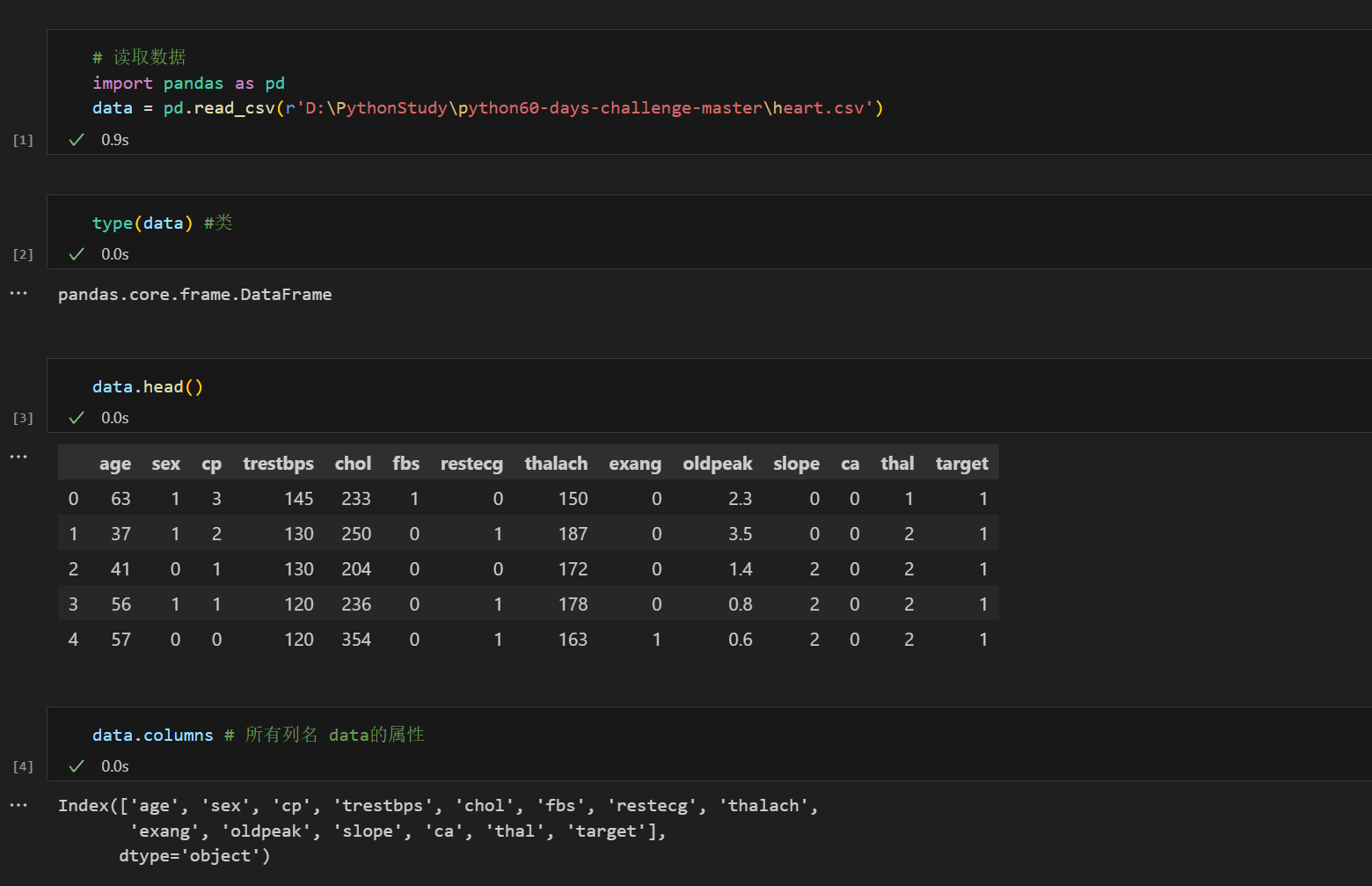
age:年龄,代表患者的岁数。
sex:性别,通常 1 表示男性,0 表示女性。
cp:胸痛类型(chest pain type),用不同数值代表不同的胸痛分类。
trestbps:静息血压(resting blood pressure),单位可能是 mmHg。
chol:血清胆固醇(serum cholesterol),一般以 mg/dl 为单位。
fbs:空腹血糖(fasting blood sugar),若大于 120 mg/dl 则记为 1,否则为 0。
restecg:静息心电图结果(resting electrocardiographic results),用数值表
示不同的心电图情况。
thalach:最大心率(maximum heart rate achieved)。
exang:运动诱发的心绞痛(exercise induced angina),1 表示是,0 表示否。
oldpeak:运动相对于休息的 ST 段压低(ST depression induced by exercise
relative to rest)。
slope:运动高峰时 ST 段的斜率(the slope of the peak exercise ST
segment)。
ca:荧光透视法观察到的主要血管数量(number of major vessels colored by fluoroscopy)。
thal:地中海贫血(thalassemia),可能用不同数值代表不同状态。
target:目标变量,表示是否患有心脏病, 1 表示患病,0 表示未患病。
2.查看数值列的基本统计量
- 输入:
data.describe()- 输出:

3.查看数据类型、缺失值
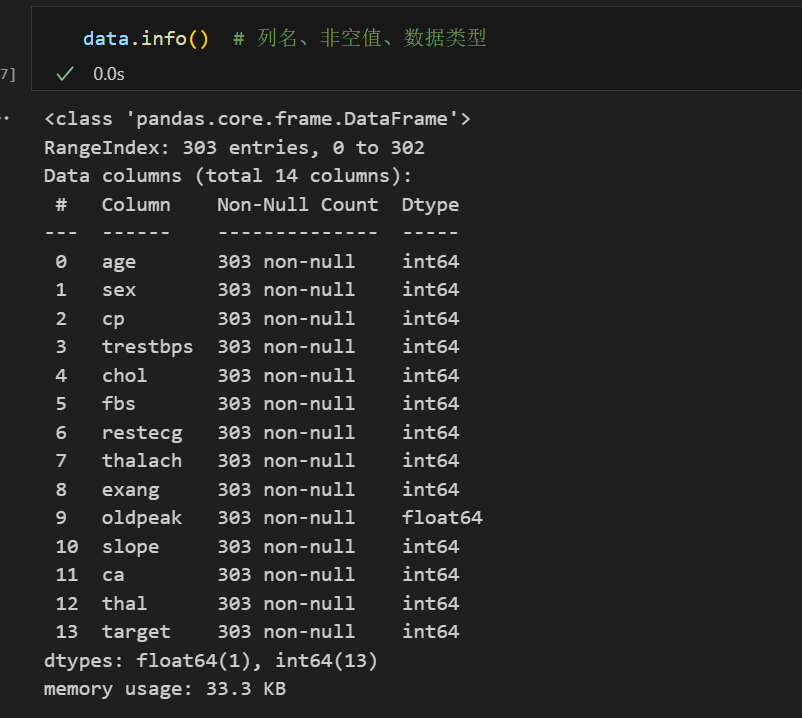
数据无缺失值
4.数据可视化
(1)直方图
- 输入:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 设置全局字体为支持中文的字体 (例如 SimHei)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
sns.histplot(x=data['age'])
plt.title('age 直方图')
plt.xlabel('age')
plt.ylabel('数量')
plt.tight_layout() # 自动调整子图参数,提供足够的空间
plt.show()- 输出:
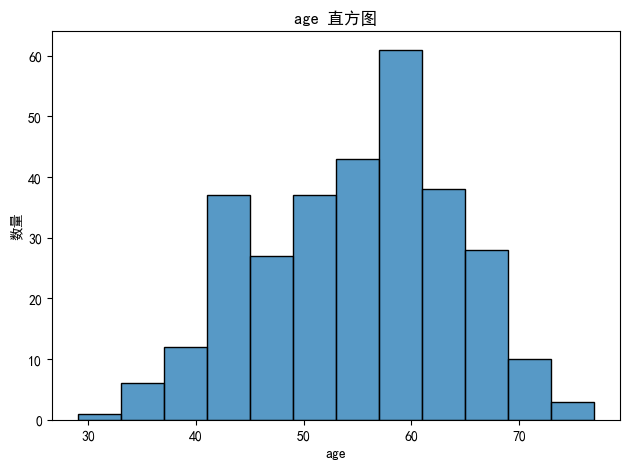
可以看出人群集中在50-70岁之间
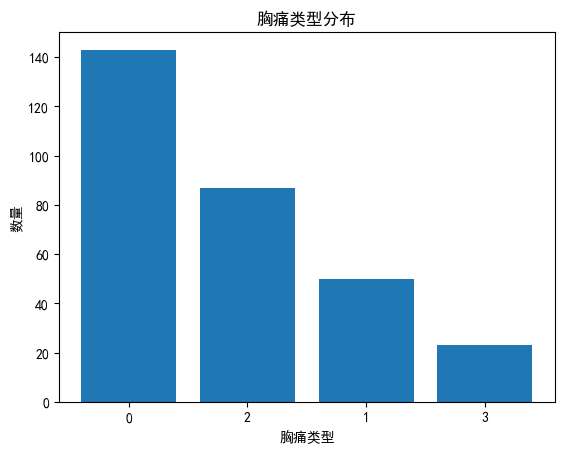
可以看胸痛类型主要为0和2类别
(2)小提琴图与箱线图
- 输入:
plt.figure(figsize=(8, 6))
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
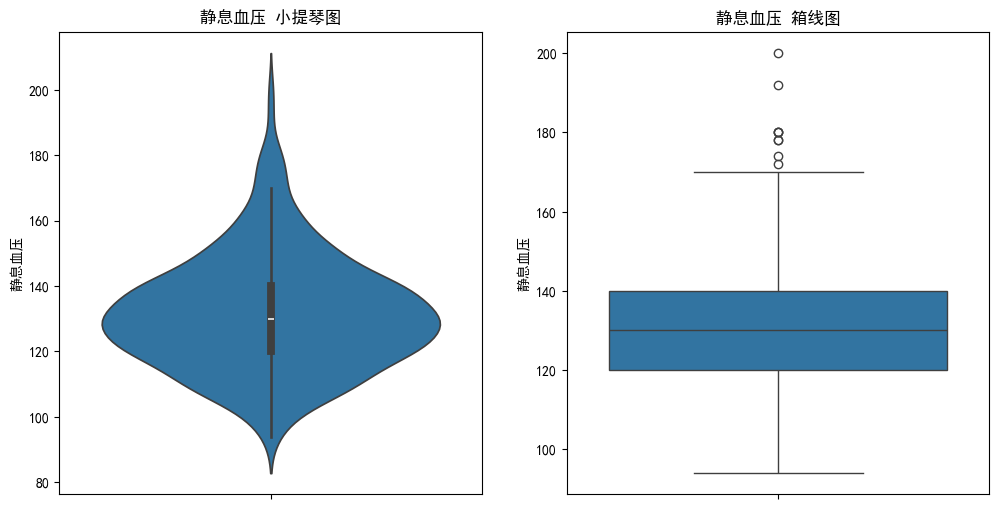
sns.violinplot(y='trestbps', data=data,ax=ax1)
ax1.set_title('静息血压 小提琴图') # 子图1标题
ax1.set_ylabel('静息血压')
sns.boxplot(y='trestbps', data=data,ax=ax2)
ax2.set_title('静息血压 箱线图') # 子图2标题
ax2.set_ylabel('静息血压')
plt.show()- 输出:
同理绘制其他数据的图
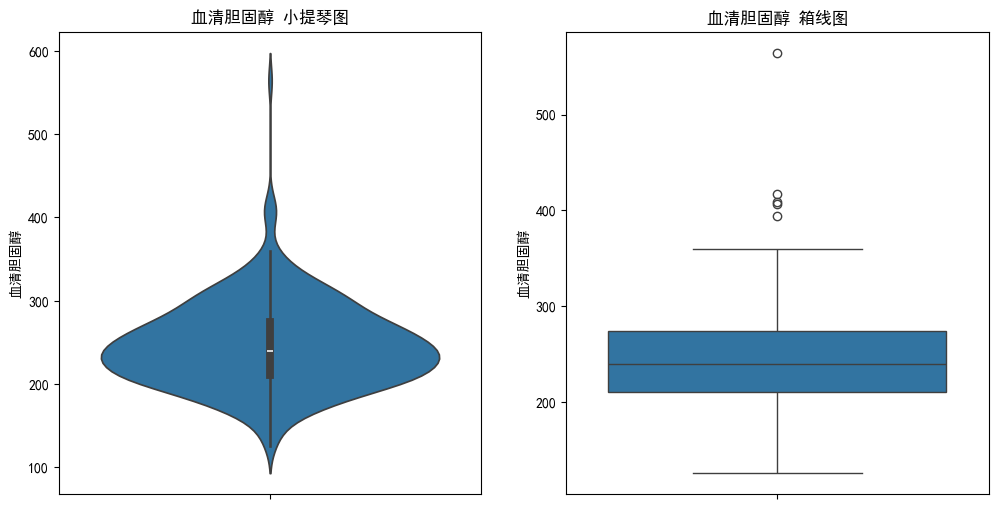

可以看出数据的一些标签存在离群值。
(3)性别与患病之间的关系
- 输入:
sex_target = data.groupby('sex')['target'].mean()
labels = ['女性', '男性'] if sex_target.index[0] == 0 else ['男性', '女性']
plt.pie(sex_target, labels=labels, autopct='%1.1f%%')
plt.title('不同性别患心脏病的比例')
plt.show()- 输出:
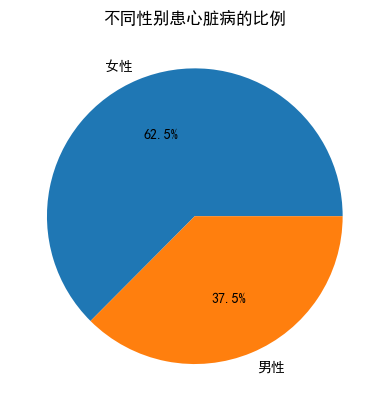
可以看出男女性别比例差距较大,因此需要分别分析
- 输入:
sns.countplot(x = 'target', data = data, hue = 'sex') # 创建一个计数图,其中x为target,数据为dt,用sex作为色相(切分类别)
plt.legend(['男性', '女性']) # 以female/male作为标签,在图形中嵌入图例
plt.title('按性别划分的心脏病患病情况分布') # 设置图形标题
plt.xticks([0, 1], ['未患病', '患病']) # 设置条形图的标签
plt.ylabel('数量')
# 显示图形
plt.show()- 输出:
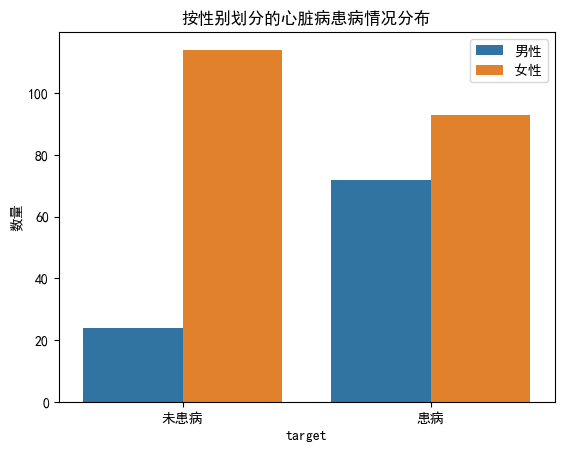
图中显示出:女性在 “未患病” 和 “患病” 群体中的样本数均多于男性。
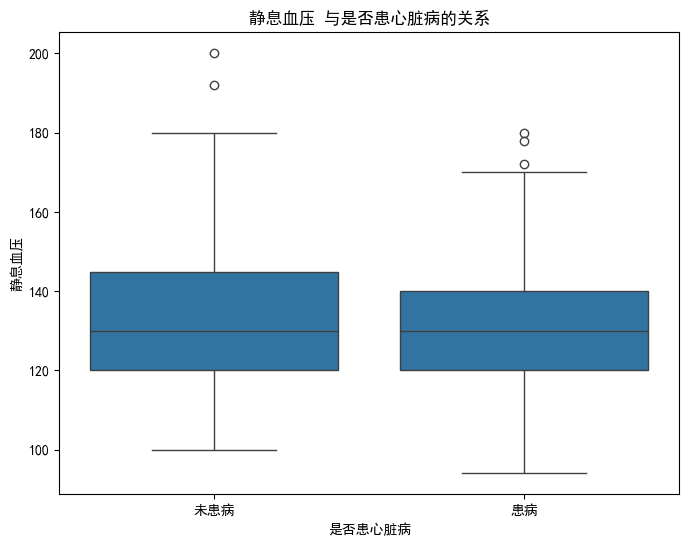
(4)不同特征与是否患心脏病的箱线图
trestbps与是否患心脏病的箱线图
- 输入:
plt.figure(figsize=(8, 6))
sns.boxplot(x='target', y='trestbps', data=data)
plt.xlabel('是否患心脏病')
plt.xticks([0, 1], ['未患病', '患病'])
plt.ylabel('静息血压')
plt.title('静息血压 与是否患心脏病的关系')
plt.show()- 输出:
其他特征与是否患心脏病的箱线图同理,下面给出部分结果图
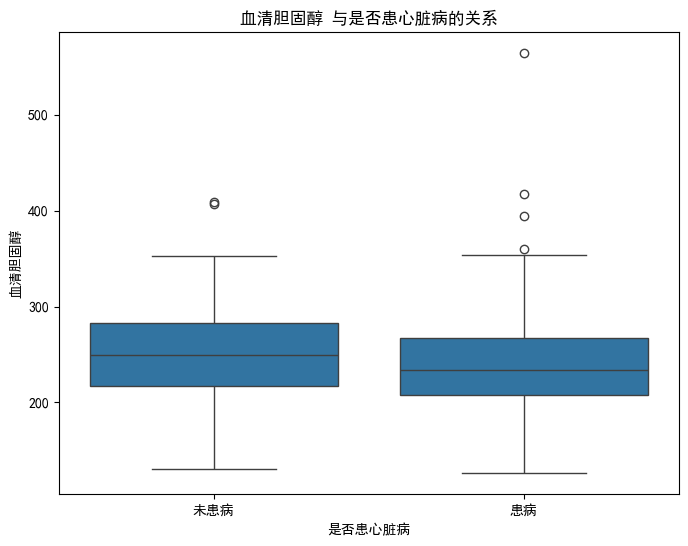
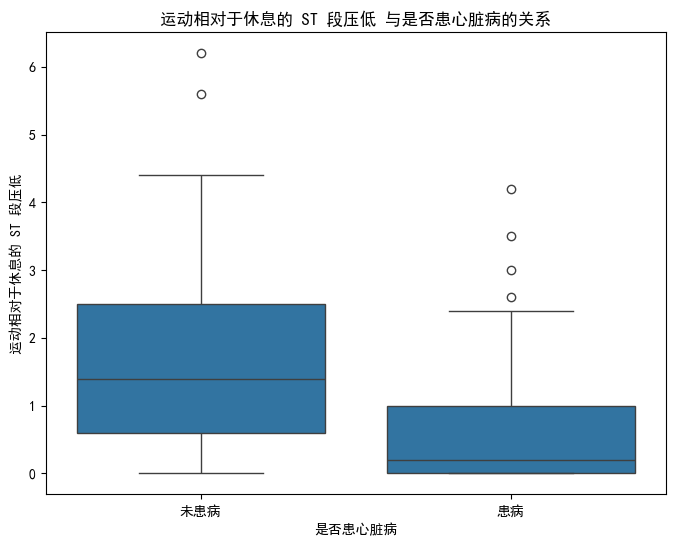

结论:thalach(最大心率)和oldpeak(运动 ST 段压低)在两类人群中的分布差异较显著,对区分是否患心脏病的参考价值更高;而trestbps(静息血压)和chol(血清胆固醇)的区分度相对较弱。
(5)胸痛类型与患病之间的关系
- 输入:
plt.figure(figsize=(8, 6))
sns.countplot(x='cp', hue='target', data=data)
plt.title('cp vs. target')
plt.xlabel('cp')
plt.ylabel('Count')
handles, labels = plt.gca().get_legend_handles_labels()
plt.legend(handles, ['患病', '患病'], title='target') # 将0和1的标签都改为“患病”
plt.show()- 输出:
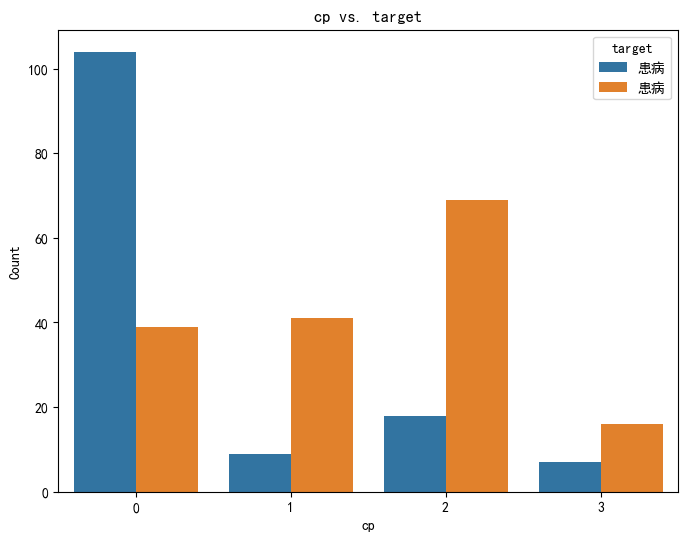
不同胸痛类型(cp)对应的患病群体数量差异显著,说明胸痛类型与心脏病患病情况存在关联性。
一些碎碎念念
勇闯python的第7天,已经一周了,一周学下来,从对 Python 一窍不通,到现在能捣鼓出些东西出来,感觉自己进步了很多。虽然还有很多不懂的地方,但这种每天都有新收获的感觉,真的很不错,希望能够一直坚持下去!!!
感谢疏老师@浙大疏锦行提供这么好的机会和平台!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)