Mamba保姆级教程:通过通俗解读与项目实战,真正理解这一AI潜力股
Mamba神经网络是一种基于状态空间模型(SSM)的新型序列处理架构,相比Transformer具有更高的效率和更低的计算成本。本教程从理论到实践全面介绍了Mamba的核心原理和应用方法。文章首先阐述了Mamba的优势:处理长序列时速度快、能力强,是AI领域的新趋势。然后详细对比了Mamba与Transformer的区别,重点说明了Mamba基于SSM的"智能跟踪"机制。实战部
文章目录
从0玩转Mamba神经网络:理论+实战的保姆级教程
在AI的世界里,Mamba就像一匹黑马,凭借着在序列任务上的出色表现,成为了Transformer的有力竞争者。如果你想踏入这个前沿领域,这篇教程将带你从概念到实战,轻松掌握Mamba的核心魅力。
一、Mamba:序列任务的“效率新贵”
首先得明白Mamba是什么。它是一种基于状态空间模型(SSM)的神经网络架构,专为序列数据(比如文本、语音、时间序列)设计。和传统的Transformer相比,Mamba最大的亮点是效率——它能以更低的计算成本,处理超长序列,在很多任务上性能还不落下风。
为什么要学Mamba?
- 速度快:处理长文本、长语音时,推理速度远超Transformer;
- 能力强:在语言建模、时间序列预测等任务中表现出色;
- 趋势热:是AI领域的新方向,掌握它能让你在技术浪潮中抢占先机。
二、核心原理:Mamba的“制胜逻辑”
1. 状态空间模型(SSM)的魔力
Mamba的底层是状态空间模型,它就像一个“记忆容器”。在处理序列数据时,SSM会记录下序列的状态信息,并在后续处理中不断更新这些“记忆”,从而实现对长序列的高效理解。这也是Mamba能处理超长序列的关键。
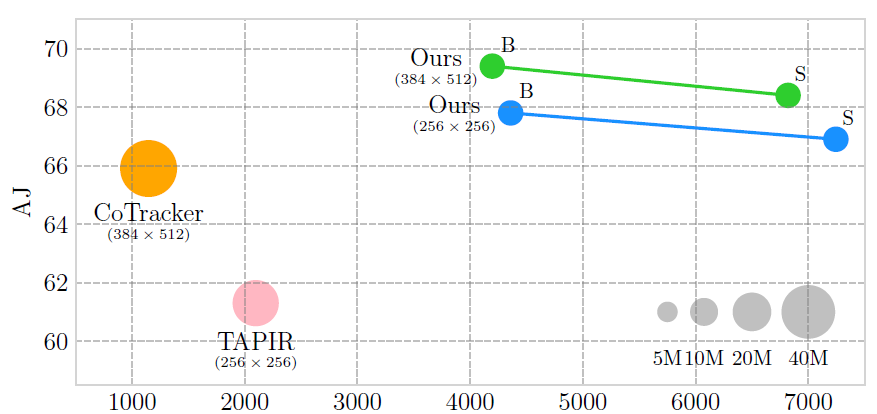
2. Mamba vs Transformer:核心差异
| 维度 | Transformer | Mamba |
|---|---|---|
| 注意力机制 | 依赖自注意力,计算复杂度高 | 无自注意力,基于SSM |
| 序列长度支持 | 长序列时计算成本剧增 | 轻松处理超长序列 |
| 推理速度 | 慢 | 快 |
简单来说,Transformer是“全面扫描”序列,而Mamba是“智能跟踪”序列状态,效率自然更高。
三、实战入门:搭建简易Mamba模型
现在,我们动手搭建一个Mamba模型,体验它在文本分类任务上的表现。
1. 环境搭建
首先安装必要的库:
pip install torch mamba-ssm transformers datasets
2. 代码实现:Mamba文本分类器
import torch
from torch import nn
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
# 加载数据集(这里用IMDb电影评论分类数据集)
dataset = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
tokenized_datasets.set_format("torch", columns=["input_ids", "attention_mask", "label"])
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
train_dataloader = torch.utils.data.DataLoader(
tokenized_datasets["train"], batch_size=32, collate_fn=data_collator
)
eval_dataloader = torch.utils.data.DataLoader(
tokenized_datasets["test"], batch_size=32, collate_fn=data_collator
)
# 初始化Mamba模型
model = MambaLMHeadModel(
d_model=256,
d_state=16,
d_conv=4,
expand=2,
dt_rank='auto',
dim_inner=1,
bias=True,
activation='silu',
final_mlp_scale=1.0,
vocab_size=tokenizer.vocab_size,
num_classes=2 # 二分类(正面/负面评论)
)
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
# 训练模型
epochs = 3
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(epochs):
model.train()
total_train_loss = 0
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])
logits = outputs.logits
loss = loss_fn(logits, batch["label"])
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item()
avg_train_loss = total_train_loss / len(train_dataloader)
print(f"Epoch {epoch+1}, Average Training Loss: {avg_train_loss:.4f}")
# 评估模型
model.eval()
total_eval_accuracy = 0
total_eval_loss = 0
with torch.no_grad():
for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])
logits = outputs.logits
loss = loss_fn(logits, batch["label"])
total_eval_loss += loss.item()
predictions = torch.argmax(logits, dim=-1)
total_eval_accuracy += (predictions == batch["label"]).float().mean()
avg_eval_accuracy = total_eval_accuracy / len(eval_dataloader)
avg_eval_loss = total_eval_loss / len(eval_dataloader)
print(f"Epoch {epoch+1}, Average Evaluation Accuracy: {avg_eval_accuracy:.4f}, Average Evaluation Loss: {avg_eval_loss:.4f}")
print("训练完成!")
3. 代码解析
- 数据处理:用IMDb数据集,通过分词器将文本转为模型可处理的token;
- 模型搭建:使用
mamba-ssm库的MambaLMHeadModel,配置模型参数以适配文本分类任务; - 训练与评估:通过3轮训练,让模型学习评论的情感特征,最后在测试集上验证准确率。
四、性能揭秘:Mamba的“实战优势”
在语言建模、时间序列预测等任务中,Mamba的表现非常亮眼。以语言建模为例,它在处理超长文本时,速度比Transformer快数倍,同时还能保持不错的精度。这得益于它基于SSM的架构,不需要像Transformer那样计算全局注意力,从而节省了大量计算资源。
如果你对比两者的显存占用和推理时间,会发现Mamba在处理长序列时优势更明显。比如处理1024长度的序列,Mamba的推理时间可能只有Transformer的一半,显存占用也更低。
五、进阶方向:让Mamba更强大
掌握了基础的Mamba模型后,你可以尝试以下进阶方向:
- 模型改进:调整
d_model(模型维度)、d_state(状态维度)等参数,提升模型的表达能力; - 任务拓展:将Mamba应用到语音识别、时间序列预测(如股票预测)等任务中;
- 性能优化:尝试不同的优化器、学习率调度策略,进一步提升训练效率。
六、总结:开启Mamba的序列探索之旅
通过这篇教程,你已经对Mamba有了从理论到实践的全面认识。它是序列任务的高效利器,无论是在学习成本还是实际性能上,都值得你深入研究。
现在,你可以基于这个简易模型,不断尝试改进和拓展,让它在更多的序列任务中发光发热。AI的世界充满惊喜,Mamba只是其中的一个精彩角落,保持探索的热情,你会发现更多有趣的技术和应用!
代码链接与详细流程
飞书链接:https://ecn6838atsup.feishu.cn/wiki/EhRtwBe1CiqlSEkHGUwc5AP9nQe?from=from_copylink 密码:946m22&8

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)