【ICCV 2025】即插即用合成图表数据集ECD问世,开源MLLM图表理解性能飙升!
图表理解是构建有效科学智能体的核心,然而现有的,特别是开源模型,在复杂基准测试上的成功率仅为30%-50%,表现不佳。现有研究通过合成图表数据对模型进行微调,但这些数据与真实图表的相似度不足,限制了模型在复杂真实场景下的性能。为应对此挑战,本文提出了一种高效的图表数据合成方法。该方法将图表生成过程模块化,通过一个五步流水线设计——分离数据与绘图函数、条件化生成多子图、视觉多样化、质量过滤及问答对生
图表理解是构建有效科学智能体的核心,然而现有的多模态大语言模型 (MLLM),特别是开源模型,在复杂基准测试上的成功率仅为30%-50%,表现不佳。现有研究通过合成图表数据对模型进行微调,但这些数据与真实图表的相似度不足,限制了模型在复杂真实场景下的性能。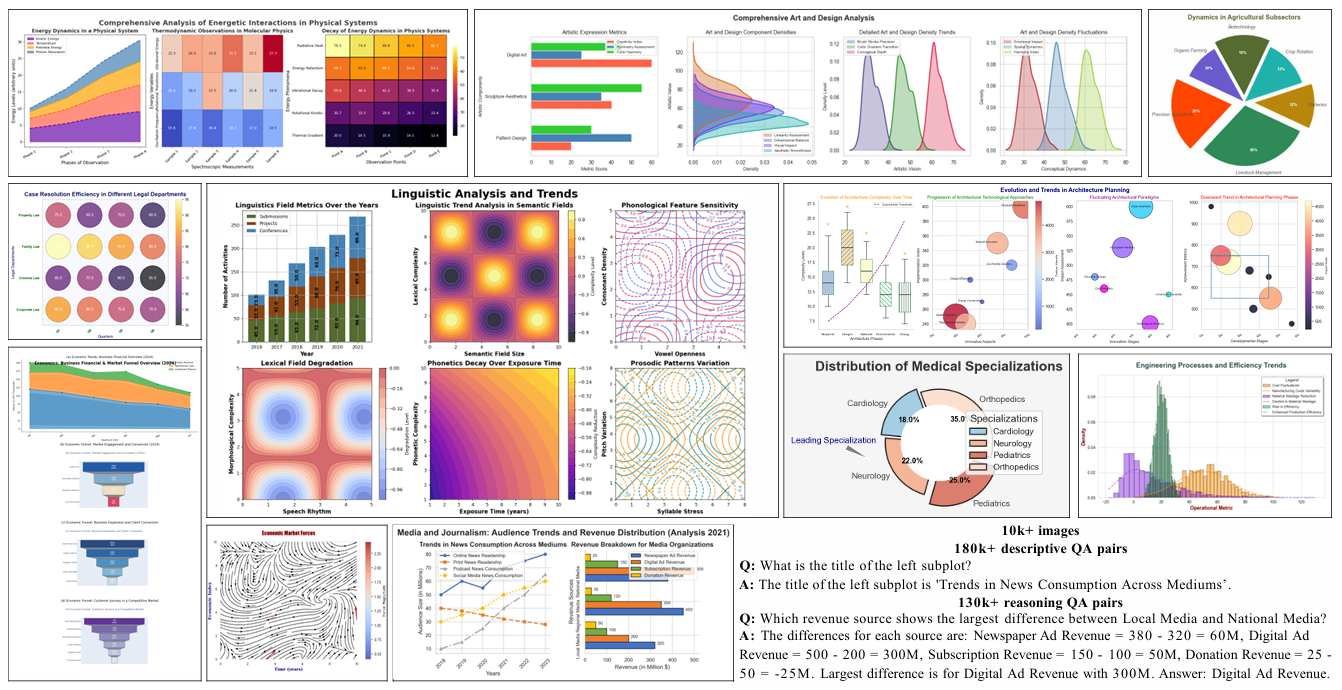
为应对此挑战,本文提出了一种高效的图表数据合成方法。该方法将图表生成过程模块化,通过一个五步流水线设计——分离数据与绘图函数、条件化生成多子图、视觉多样化、质量过滤及问答对生成——来创建有效图表数据集 (ECD)。该数据集包含超过1万张图像和30万个问答对,覆盖29种图表类型和250多种组合。
本文的主要贡献是证明了通过模块化和多样化的数据合成策略,可以显著提升 MLLM 的图表理解能力,并在多个真实及合成测试集上验证了 ECD 的有效性。
01 论文基本信息

- 标题: Effective Training Data Synthesis for Improving MLLM Chart Understanding (提升多模态大语言模型图表理解能力的有效训练数据合成)
- 核心模块: 单图生成, 组合子图生成, 图表图像多样化, 图表图像过滤, 问答对生成与过滤
02 算法框架与核心模块
2.1 算法框架
本文提出一个五阶段的数据合成流水线 (参考论文图2)。首先,通过分离绘图函数与数据生成来创建单图 (single plot);其次,通过条件生成 (conditional generation) 方式迭代构建多子图组合,以保证内容连贯性;接着,对图表进行视觉多样化处理;然后,通过质量评估模型过滤低质量图像;最后,为高质量图表生成描述性和推理性的问答对。
2.2 核心模块
模块一:模块化图表生成 (单图与组合子图)
- 核心功能: 解决现有合成数据方法在图表复杂性和多图连贯性上的不足。
- 实现逻辑:
- 单图生成: 与其让大模型同时生成绘图代码和数据,本文将任务分解。为GPT-4o提供预定义的绘图函数、参数描述和主题,使其专注于生成更复杂、与主题相关的数据表和图表参数(如标题、图例)。
- 组合子图生成: 采用条件生成方法,后续子图的生成会以前面已生成的子图信息为条件。例如,在生成子图3时,系统会参考子图1和子图2的数据,以确保整个图表的语义连贯性。
- 优势: 该方法将数据生成与代码实现解耦,使模型能生成更复杂的数据模式。针对组合图的条件生成策略,有效模拟了人类在设计科学图表时多视角、互补呈现数据的思维,增强了图表的内部逻辑性。
模块二:质量过滤
- 核心功能: 过滤掉流水线中产生的视觉效果差或语义不连贯的图表,确保最终数据集的整体质量。
- 实现逻辑: 设计了一套基于GPT-4o评估的质量过滤策略,该策略使用两个核心指标:
- 视觉清晰度 (visual clarity) rvisr_{vis}rvis: 评估图表的可读性、视觉元素使用的合理性以及是否存在元素堆叠混乱等问题。
- 语义连贯性 (semantic coherence) rsemr_{sem}rsem: 评估图表内的各个元素(如图例、标题、数据)及多子图之间是否在主题上保持一致。
通过计算每个图表的平均分,并仅保留高于数据集平均分的图表。其核心计算公式为:
r(x,clayout,ctheme)=(rsem+rvis)2 r(x, c_{layout}, c_{theme}) = \frac{(r_{sem} + r_{vis})}{2} r(x,clayout,ctheme)=2(rsem+rvis)
- 优势: 相比于无筛选或简单规则筛选,这种基于多维指标的智能过滤机制能更准确地识别并剔除低质量样本,保证了训练数据的有效性,避免了“垃圾进,垃圾出”的问题。
03 模块适用任务
- 核心应用场景: 本方法主要用于提升多模态大语言模型在图表问答 (Chart QA) 任务上的表现,特别是处理包含复杂数据模式、多种图表类型及组合的科学图表。
- 方法论核心: 其最本质的思想是**“分解与控制” (Decomposition and Control)**。通过将复杂的图表合成任务分解为数据生成、代码实现、视觉增强和质量控制等多个独立且可控的步骤,从而系统性地提升合成数据的真实性和复杂性。
- 启发性拓展:
- 可迁移至其他结构化数据可视化领域: 该流水线思想不仅限于图表,还可拓展至其他可通过代码生成的视觉内容,如SVG图形、流程图、甚至分子结构图的合成与理解。
- 自动化数据增强与课程学习: 可以基于本文的质量评估模型,构建一个从易到难的“课程学习”序列。模型可以先在简单、清晰的图表上训练,再逐步过渡到经过高度视觉多样化处理的复杂图表,从而实现更高效的学习。
04 实验结果与可视化分析
核心实验与结论
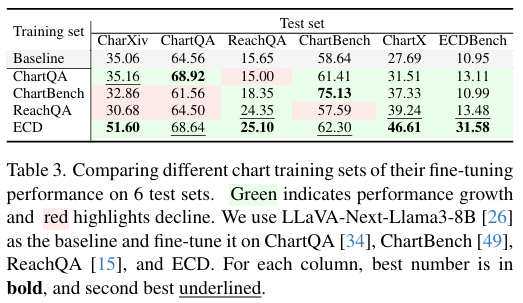
【指令】: 选择对比不同训练集对模型性能影响的实验。
- 实验目的: 该实验旨在验证相比于现有的其他图表训练数据集(如ChartQA, ChartBench, ReachQA),使用本文提出的 ECD 数据集对 MLLM 进行微调,是否能在多个不同的测试集上带来更全面、更一致的性能提升。
- 关键结果: 实验数据显示 ,使用 LLaVA-Next-Llama3-8B 作为基础模型:
- 在其他训练集(如ChartQA, ChartBench)上微调后,模型性能在某些基准上提升,但在另一些上则出现下降,表现出不一致性。
- 在 ECD 数据集上微调后,模型在所有六个测试集(CharXiv, ChartQA, ReachQA, ChartBench, ChartX, ECDBench)上的性能均获得提升。特别是在最具挑战性的真实世界数据集 CharXiv 上,性能从未经微调的 35.06% 大幅提升至 51.60%,增益最为显著。
- 作者结论: 作者基于此实验得出结论:ECD 数据集因其高数据复杂性、真实性和多样性,能够比现有其他训练集更有效地提升 MLLM 在各类图表理解任务上的泛化能力,带来了稳定且全面的性能增益。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)