征服内存墙:昇腾CANN算子开发中的高级内存优化技术
我们将从Tiling策略的量化选择,到双缓冲(Double Buffering)流水线的精妙设计,再到数据布局的深层奥秘,为你揭示将算子性能提升一个数量级的核心密码。“内存墙”指的是计算单元处理数据的速度,与从内存中获取数据的速度之间存在的巨大鸿沟。一个未经优化的算子,其宝贵的计算核心(AI Core)可能有超过80%的时间都在“挨饿”,即等待数据从缓慢的全局内存(Global Memory)中“
前言
在高性能计算领域,流传着一句经典名言:“软件的速度,最终由数据移动的速度决定。”对于昇腾NPU这类拥有超高浮点运算能力的AI芯片而言,这句话更是金科玉律。编写一个功能正确的算子,可能只需要数小时;但要将其性能推向硬件的理论峰值,则需要与一个永恒的敌人作斗争——“内存墙(The Memory Wall)”。
“内存墙”指的是计算单元处理数据的速度,与从内存中获取数据的速度之间存在的巨大鸿沟。一个未经优化的算子,其宝贵的计算核心(AI Core)可能有超过80%的时间都在“挨饿”,即等待数据从缓慢的全局内存(Global Memory)中“长途跋涉”而来。
本文是一篇面向进阶开发者的高级内存优化实战指南。我们将深入探讨,在昇腾CANN平台上,如何运用一系列精巧的技术,系统性地“征服”内存墙。我们将从Tiling策略的量化选择,到双缓冲(Double Buffering)流水线的精妙设计,再到数据布局的深层奥秘,为你揭示将算子性能提升一个数量级的核心密码。
第一章:诊断性能瓶颈 —— 一切优化的起点
优化的第一步,永远是精准的诊断。在CANN生态中,Ascend Profiler是我们的“CT扫描仪”。对一个功能正确但未经优化的算子进行Profiling,我们通常会看到一幅典型的**“访存受限(Memory-bound)”**画像:
- Timeline视图: AI Core的执行块(Kernel Execution)之间存在大量肉眼可见的空闲间隙(Gaps)。DMA(数据搬运)任务与计算任务严格地串行执行。
- 硬件指标: AI Core Utilization(利用率)可能低于20%,而Memory Bandwidth(内存带宽)却可能很高。
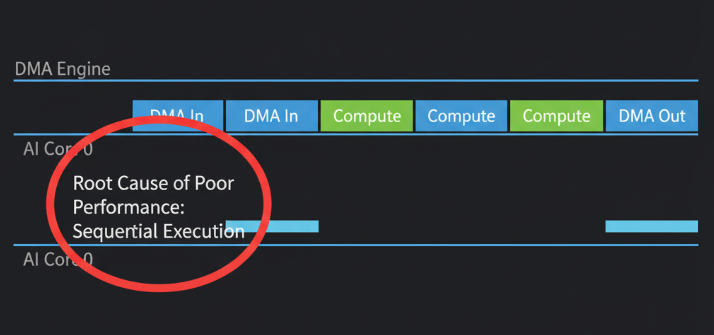
这个诊断结果告诉我们:算子的瓶颈不在于“算得慢”,而在于“等得久”。因此,我们所有的优化,都应围绕一个核心目标展开:最大化计算与数据访存的并行度,让AI Core的“嘴”里永远有“粮”。
第二章:Tiling的艺术 —— 从“能分”到“会分”
Tiling(分块)是内存优化的基础,但如何选择合适的Tile Size(块大小)是一门艺术,直接决定了优化的成败。
2.1 Tile Size选择的量化权衡
选择Tile Size并非越大越好或越小越好,它是一个多目标优化问题:
- 目标1:必须装入Local Memory。 这是硬性约束。一个Tile所需的所有输入、输出和中间数据的总大小,不能超过AI Core的Local Memory容量(如320KB)。
- 目标2:最大化计算访存比(Compute-to-Memory Ratio)。 这是性能的核心。我们希望每次“费力地”从全局内存搬运一个Tile后,能在其上进行尽可能多的计算。这个比值越高,访存开销被摊销得越好。
- 目标3:最小化DMA开销。 DMA的启动本身有固定开销。如果Tile切得太小,会导致DMA启动次数过多,总开销反而上升。
- 目标4:最大化并行度。 Tile的大小也会影响任务在多个AI Core之间的分配和并行效率。
2.2 实践案例:矩阵乘法的Tiling策略
对于矩阵乘法 C(M, K) = A(M, N) * B(N, K),一个好的Tiling策略通常是在输出矩阵C的M和K维度上进行二维分块。
假设我们将C切分成block_M * block_K的小块。为了计算这样一个C的Tile,我们需要:
- 从
A中读取一个block_M * N的“行条带”。 - 从
B中读取一个N * block_K的“列条带”。
Local Memory占用估算:Size = (block_M * N + N * block_K + block_M * block_K) * sizeof(dtype)
这个Size必须小于可用的Local Memory。
计算访存比估算:
- 计算量:
2 * block_M * N * block_K(一次乘法和一次加法) - 访存量:
(block_M * N + N * block_K)(只考虑读) - 比值:
~ (2 * block_M * N * block_K) / (block_M * N + N * block_K)
通过这个公式,我们可以看到,在N固定的情况下,增大block_M和block_K,可以显著提高计算访存比。因此,我们的策略是:在满足Local Memory容量约束的前提下,尽可能地增大block_M和block_K。
第三章:双缓冲(Double Buffering)—— 隐藏延迟的魔法
选择了最优的Tile Size后,我们就要用双缓冲技术来“变魔术”,让串行的执行流并行起来。
3.1 双缓冲的实现细节
在Ascend C中,实现双缓冲需要精细地管理内存空间和同步。
- 内存规划: 使用
TPipe在Local Memory中为每一份需要缓冲的数据都声明两块空间。// 在Init函数中 // 为输入A声明两个缓冲区 pipe.InitBuffer(a_local_ping, TILE_A_SIZE); pipe.InitBuffer(a_local_pong, TILE_A_SIZE); // 为输入B声明两个缓冲区 pipe.InitBuffer(b_local_ping, TILE_B_SIZE); pipe.InitBuffer(b_local_pong, TILE_B_SIZE); // ... 可能还需要为输出C也声明双缓冲 ... - 流水线构建: 核心是构建一个**“计算当前,预取下一”**的循环。
// 在Process函数中 // 1. 启动流水线 (Prologue) // - 将第0块A和B分别搬运到ping缓冲区 DataCopy(a_local_ping, a_gm[...]); DataCopy(b_local_ping, b_gm[...]); // 2. 主循环 (Steady State) for (int i = 0; i < loopCount - 1; ++i) { // 预取第 i+1 块数据 if (i % 2 == 0) { // 预取到pong DataCopy(a_local_pong, a_gm[...]); DataCopy(b_local_pong, b_gm[...]); } else { // 预取到ping DataCopy(a_local_ping, a_gm[...]); DataCopy(b_local_ping, b_gm[...]); } // 计算第 i 块数据 if (i % 2 == 0) { // 在ping上计算 MatMul(c_local, a_local_ping, b_local_ping, ...); } else { // 在pong上计算 MatMul(c_local, a_local_pong, b_local_pong, ...); } } // 3. 收尾流水线 (Epilogue) // - 计算最后一块(loopCount-1)的数据 if ((loopCount - 1) % 2 == 0) { MatMul(c_local, a_local_ping, b_local_ping, ...); } else { MatMul(c_local, a_local_pong, b_local_pong, ...); }
3.2 Profiler验证
对应用了双缓冲的算子再次进行Profiling,你会看到一幅截然不同的景象:
- Timeline视图: DMA任务块和AI Core计算任务块出现了大量的重叠。AI Core的空闲间隙被显著填补。
- 硬件指标: AI Core Utilization大幅提升,可能从20%跃升至80%以上。
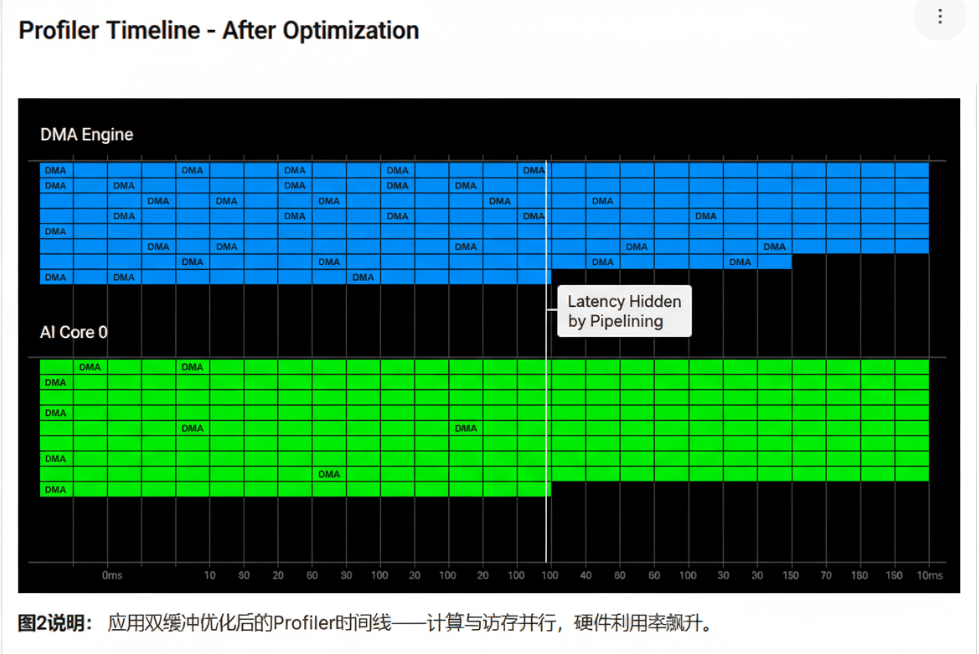
第四章:深入微观 —— 数据布局与指令优化
当流水线已经足够流畅后,性能的瓶颈就可能转移到计算本身和数据在内存中的物理排布上。
4.1 数据布局的魔力:从NCHW到分形(Fractal)格式
我们通常接触的张量数据格式是NCHW。但为了让矩阵乘法单元(Cube Unit)达到最高的吞吐率,其输入数据的物理布局有特殊要求。CANN内部会将数据重排(Re-layout)成一种称为**分形(NZ)**的格式。
为什么需要NZ格式? 想象一下Cube Unit是一个巨大的“矩阵计算引擎”,它有多个并行的输入端口。NZ格式能保证在每个时钟周期,需要的数据都能无冲突地、并行地被送达这些端口。如果使用简单的NCHW行主序存储,可能会导致内存Bank冲突,即多个计算单元同时访问同一个内存Bank,造成排队等待。
作为算子开发者,你需要:
- 感知格式: 通过CANN的API,可以查询到输入张量的实际物理格式。
- 适配格式: 你的数据搬运和地址计算逻辑,必须能够正确地处理NZ格式。虽然这增加了编程的复杂性,但带来的性能收益是巨大的。在很多官方提供的高性能算子库(OPP)中,都可以看到针对NZ格式的优化代码。
4.2 终极优化:手动指令调度与Software Pipelining
对于追求极致性能的专家,Ascend C甚至允许更深度的控制。你可以通过__asm__内联汇编,直接编写硬件指令。更重要的是,你可以通过手动Software Pipelining,精确地控制每一条Load、Compute、Store指令的发射时机,构建一个比编译器自动生成的更优化的指令流水线,以最小化数据依赖和硬件资源冲突。这属于算子优化的“圣杯”,需要对Da Vinci架构有极其深刻的理解。
结论:性能优化是一场永不落幕的迭代
征服内存墙,是一场由粗到精、由宏观到微观的系统性战役。
- 始于诊断: 使用Profiler精准定位瓶颈是访存还是计算。
- 宏观调控: 设计并量化最优的Tiling策略,最大化计算访存比。
- 构建流水线: 应用双缓冲技术,实现计算与访存的并行,隐藏延迟。
- 微观雕琢: 适配硬件友好的数据布局(如NZ格式),并利用向量化和指令级并行榨干计算单元。
这个**“诊断 -> 优化 -> 再诊断”**的循环,是每一位高性能计算工程师的日常。它充满挑战,但每一次成功地将AI Core利用率提升10%,每一次在Timeline上消除一处空闲,所带来的成就感都是无与伦比的。
开启你的“性能大师”之旅:
理论的深度需要反复的实践来巩固。2025年昇腾CANN训练营第二季的【码力全开特辑】和【开发者案例】正是你磨练这些高级优化技能的最佳战场。
- 系统化课程: 深入讲解复杂算子与性能调优。
- 免费云端环境: 在真实的昇腾硬件上,亲手实践并验证你的优化效果。
- 权威技能认证: Ascend C中级认证,是你掌握核心优化能力的有力证明。
- 丰富的实践激励: 完成任务更有机会赢取华为手机、平板、开发板等大奖。
如果你已不满足于“让它跑起来”,而是渴望“让它飞起来”,那么,是时候进入优化的深水区了。
报名链接: https://www.hiascend.com/developer/activities/cann20252

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)