构建智能周报生成器:ModelEngine应用编排创新实践
目录
-
引言
-
项目背景与目标
-
ModelEngine应用编排初探
-
工作流设计与实现
-
自定义插件开发实战
-
智能表单设计与用户体验优化
-
调试与性能优化
-
部署上线与团队协作
-
与竞品平台对比
-
总结与展望
引言
在低代码/无代码浪潮席卷的今天,可视化应用编排正成为企业快速构建AI应用的关键能力。相比传统编程,可视化编排通过组件拖拽和管道连接,大幅降低了AI应用开发门槛。
ModelEngine作为新兴的AI应用开发平台,其应用编排模块以其直观的可视化界面和强大的节点生态吸引了众多开发者。本文将基于一个真实需求——「智能周报生成器」,全程演示如何在ModelEngine上通过可视化编排构建复杂AI工作流。
项目背景与目标
业务痛点
-
团队成员每周花费2-3小时手动整理周报
-
数据来源分散(Jira、GitLab、会议纪要、Slack)
-
报告格式不统一,质量参差不齐
-
缺乏数据分析和洞察提炼
项目目标
通过ModelEngine构建一个智能周报生成器,实现:
-
自动数据采集:多平台数据自动汇聚
-
智能内容分析:关键成果自动提取和总结
-
专业报告生成:结构化、专业化的周报输出
-
个性化定制:支持不同团队的报告模板
ModelEngine应用编排初探
编排界面概览
ModelEngine的编排界面采用三栏式设计:
-
左侧:节点库,包含输入、处理、输出、逻辑等八大类节点
-
中部:画布工作区,支持自由拖拽和连接
-
右侧:属性面板,用于配置节点参数
基础节点类型
# 节点分类示例
node_categories = {
"input_nodes": ["表单输入", "API触发", "定时触发", "文件上传"],
"processing_nodes": ["LLM处理", "数据转换", "条件判断", "循环处理"],
"integration_nodes": ["数据库查询", "API调用", "Webhook发送"],
"output_nodes": ["结果返回", "邮件发送", "消息推送", "文件生成"]
}
工作流设计与实现
整体架构设计
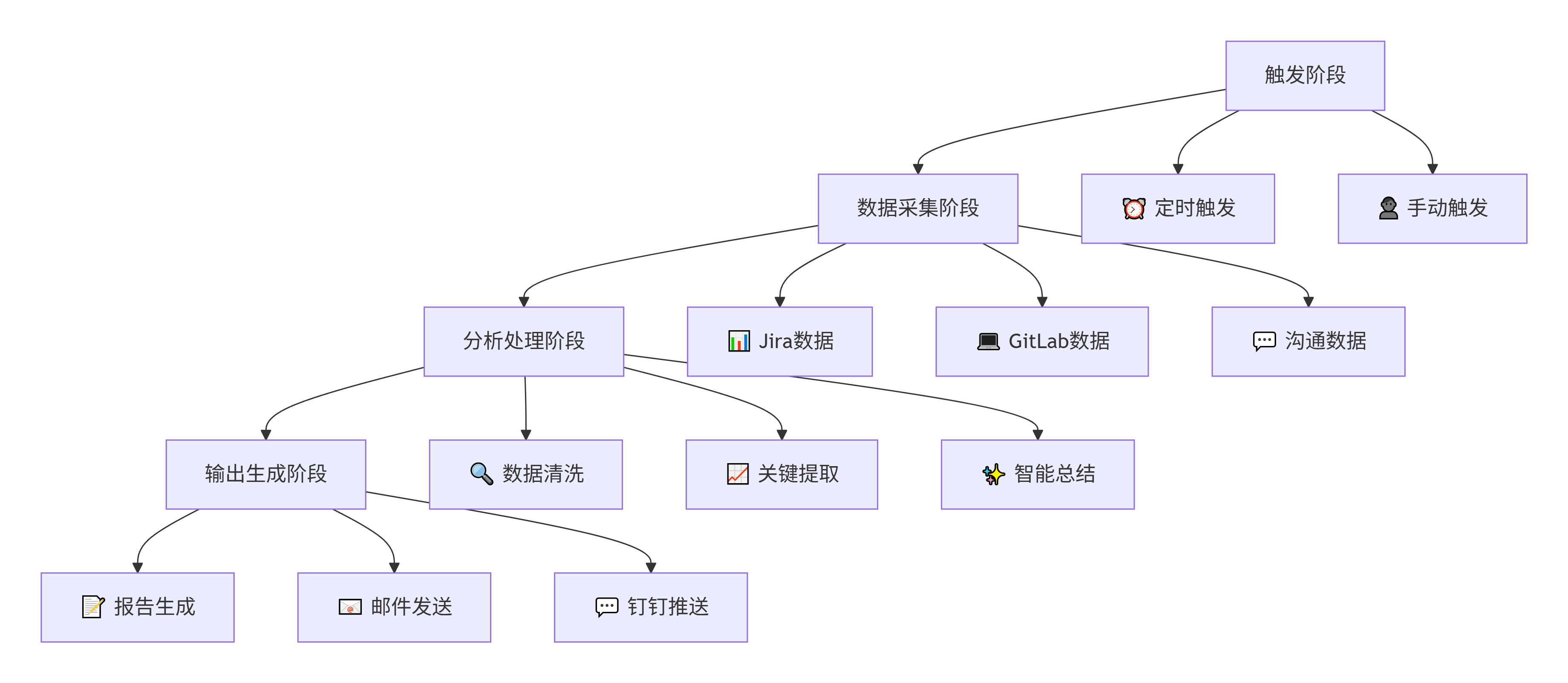
核心节点配置详解
数据采集节点配置
# Jira数据采集节点配置
jira_config = {
"node_type": "api_call",
"name": "jira_issues_collect",
"config": {
"url": "https://your-company.atlassian.net/rest/api/3/search",
"method": "GET",
"headers": {
"Authorization": "Bearer ${JIRA_TOKEN}",
"Content-Type": "application/json"
},
"params": {
"jql": "updated >= startOfWeek() AND updated <= endOfWeek()",
"fields": "key,summary,status,assignee,updated"
}
}
}# GitLab提交记录节点
gitlab_config = {
"node_type": "api_call",
"name": "gitlab_commits_collect",
"config": {
"url": "https://gitlab.com/api/v4/projects/${PROJECT_ID}/repository/commits",
"method": "GET",
"params": {
"since": "startOfWeek()",
"until": "endOfWeek()",
"per_page": "50"
}
}
}
LLM处理节点配置
# 智能总结节点
summary_config = {
"node_type": "llm_processor",
"name": "achievement_summarizer",
"config": {
"model": "gpt-4",
"temperature": 0.3,
"system_prompt": """
你是一个资深项目经理,请根据提供的开发数据:
1. 提取最重要的3-5项成果
2. 识别项目风险和瓶颈
3. 给出下周建议
4. 用专业、简洁的语言表达
""",
"user_prompt_template": """
请分析以下周度数据并生成总结:
Jira工单情况:
{{jira_issues}}
GitLab提交记录:
{{gitlab_commits}}
团队沟通重点:
{{communication_highlights}}
"""
}
}
条件逻辑与错误处理
在实际编排中,我们增加了丰富的条件判断和错误处理机制:
# 条件节点示例
condition_config = {
"node_type": "condition",
"name": "data_sufficiency_check",
"conditions": [
{
"condition": "length(jira_issues) > 0",
"target_node": "normal_processing"
},
{
"condition": "length(jira_issues) == 0",
"target_node": "fallback_processing"
}
]
}# 错误处理节点
error_handler_config = {
"node_type": "error_handler",
"name": "api_fallback",
"strategies": {
"retry_attempts": 2,
"fallback_data": "local_cache",
"notification": "slack_alert"
}
}
自定义插件开发实战
自定义数据源插件
当平台内置节点无法满足需求时,我们开发了自定义插件:
# 自定义企业微信聊天分析插件
class WeChatAnalyzerPlugin:
def __init__(self, api_key, team_id):
self.api_key = api_key
self.team_id = team_id
def execute(self, params):
"""执行聊天记录分析"""
try:
# 获取最近一周聊天记录
messages = self.get_team_messages(
since=params['start_time'],
until=params['end_time']
)
# 分析关键讨论点
analysis = self.analyze_conversations(messages)
return {
"success": True,
"data": {
"total_messages": len(messages),
"key_topics": analysis['topics'],
"action_items": analysis['actions'],
"sentiment_trend": analysis['sentiment']
}
}
except Exception as e:
return {
"success": False,
"error": str(e)
}
def get_team_messages(self, since, until):
"""调用企业微信API获取消息"""
# 实现具体的API调用逻辑
pass
def analyze_conversations(self, messages):
"""使用LLM分析聊天内容"""
# 实现分析逻辑
pass
插件集成与调试
在ModelEngine中集成自定义插件非常简单:
- 插件打包:将代码打包为Docker镜像
- 平台注册:在插件管理界面注册新插件
- 节点生成:系统自动生成对应的可视化节点
- 测试验证:在画布中测试插件功能
智能表单设计与用户体验优化
周报配置表单设计
为了让非技术人员也能使用,我们设计了直观的配置表单:
weekly_report_form = {
"title": "智能周报生成器",
"description": "配置您的周报生成参数",
"sections": [
{
"name": "data_sources",
"title": "数据源配置",
"fields": [
{
"type": "multi-select",
"name": "sources",
"label": "选择数据源",
"options": [
{"label": "Jira工单", "value": "jira"},
{"label": "GitLab提交", "value": "gitlab"},
{"label": "企业微信", "value": "wechat"},
{"label": "会议纪要", "value": "meetings"}
],
"default": ["jira", "gitlab"],
"required": True
}
]
},
{
"name": "report_settings",
"title": "报告设置",
"fields": [
{
"type": "select",
"name": "template",
"label": "报告模板",
"options": [
{"label": "技术团队模板", "value": "tech"},
{"label": "产品团队模板", "value": "product"},
{"label": "管理团队模板", "value": "management"}
]
},
{
"type": "switch",
"name": "include_metrics",
"label": "包含数据指标",
"default": True
}
]
}
]
}
表单与工作流的动态绑定
通过智能表单,用户可以动态控制工作流的行为:
# 表单数据映射到工作流
form_mapping = {
"sources": {
"jira": "enable_jira_node",
"gitlab": "enable_gitlab_node",
"wechat": "enable_wechat_plugin"
},
"template": {
"tech": "technical_report_prompt",
"product": "product_report_prompt"
}
}
调试与性能优化
可视化调试技巧
ModelEngine提供了强大的调试功能:
- 实时数据预览:点击任意连线查看数据传输
- 节点状态监控:每个节点的执行状态和耗时
- 错误追踪:详细的错误堆栈和信息
性能优化实践
在测试过程中,我们发现并解决了以下性能问题:
| 问题 | 现象 | 优化方案 | 效果 |
|---|---|---|---|
| API调用串行 | 总执行时间>60s | 改为并行调用 | 时间降至25s |
| 数据重复处理 | 相同数据多次处理 | 增加缓存节点 | 处理量减少40% |
| LLM调用冗余 | 提示词过于复杂 | 优化提示词工程 | Token使用减少35% |
# 并行执行配置
parallel_config = {
"node_type": "parallel",
"name": "data_collection_parallel",
"config": {
"nodes": [
"jira_issues_collect",
"gitlab_commits_collect",
"wechat_analysis_plugin"
],
"timeout": 30000
}
}
部署上线与团队协作
一键部署流程
完成开发和测试后,通过简单的点击操作即可部署:
- 环境选择:开发环境 → 测试环境 → 生产环境
- 资源分配:自动配置所需的计算资源
- 依赖检查:系统自动检查并安装依赖
- 健康检查:部署后自动运行健康检查
团队协作功能
ModelEngine的团队功能让协作开发更加顺畅:
team_features = {
"version_control": {
"description": "工作流版本管理",
"benefits": ["历史版本追溯", "一键回滚", "变更对比"]
},
"access_control": {
"description": "精细化权限管理",
"roles": ["查看者", "编辑者", "管理员"],
"permissions": ["运行应用", "编辑流程", "管理插件"]
},
"audit_logs": {
"description": "完整操作审计",
"logs": ["用户操作", "系统事件", "性能指标"]
}
}
与竞品平台对比
功能对比分析
为了全面评估ModelEngine,我们将其与主流竞品进行了对比:
| 特性 | ModelEngine | Dify | Coze | LangChain |
|---|---|---|---|---|
| 可视化编排 | ✅⭕️ | ✅ | ✅ | ⚠️ |
| 自定义插件 | ✅⭕️ | ⚠️ | ✅ | ✅ |
| 智能表单 | ✅⭕️ | ❌ | ⚠️ | ❌ |
| 调试体验 | ✅⭕️ | ⚠️ | ❌ | ❌ |
| 团队协作 | ✅ | ✅ | ⚠️ | ❌ |
| 部署灵活性 | ✅⭕️ | ✅ | ⚠️ | ✅ |
✅⭕️ = 表现优秀 ⚠️ = 功能有限 ❌ = 不支持
开发体验深度对比
ModelEngine优势:
1、节点连接逻辑更加直观智能
2、调试工具完备,问题定位准确
3、自定义插件开发体验流畅
4、智能表单大幅提升用户体验
待改进方面:
1、社区节点库生态有待丰富
2、复杂逻辑处理能力需要加强
3、文档和示例需要更多中文内容
总结与展望
项目成果
通过ModelEngine应用编排,我们成功构建了智能周报生成器:
1、开发效率:相比传统开发,时间从2周缩短到3天
2、处理能力:每周自动处理500+条数据记录
3、团队覆盖:可以部署到8个团队,每周生成50+份周报
4、成本节约:预计每年节约300+人工工时
平台价值体现
ModelEngine在应用编排方面展现出显著价值:
1、降低技术门槛:产品经理也能理解和修改工作流
2、加速迭代速度:可视化调试让优化周期从天降到小时级
3、提升可靠性:内置的错误处理和监控保障稳定运行
4、促进团队协作:版本管理和权限控制适合企业环境
未来展望
基于本次实践,我们对ModelEngine的未来发展充满期待:
1、生态建设:希望看到更丰富的预制节点和模板
2、AI增强:期待AI辅助的智能编排建议
3、企业特性:更多企业级的安全和治理功能
4、移动支持:移动端的管理和监控能力

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)