收藏!软件工程师必学:20个核心AI概念助你轻松转型大模型工程师
本文针对传统软件工程师转型AI的痛点,提出建立AI技术认知框架的解决方案。系统梳理了20个核心AI概念,从基础层(Tokenization、Vectorization)到核心层(Transformer、LLM),再到优化层(RAG、Fine-tuning)和应用层(Agents、Context Engineering),构建完整的AI技术栈知识地图。文章强调工程师转型的关键是理解AI技术体系和掌握

随着AI技术的爆发式发展,越来越多的传统软件工程师发现自己陷入了一个尴尬的境地:听得懂代码,听不懂AI术语。
当团队讨论"我们用RAG还是Fine-tuning?“时,你一脸茫然。当论文里出现"Attention Mechanism”、“Self-Supervised Learning"时,你不知道该从何学起。当同事说"这个场景适合用Vector Database”,你只能点头附和。
AI转型最大的痛点,不是不会写代码,而是缺乏共同语言。
2025年,AI工程师已经成为最抢手的岗位之一。但从传统软件工程师转型AI,你真正需要的不是从零开始学习机器学习数学公式,而是快速建立AI技术的认知框架——知道有哪些核心概念,它们解决什么问题,如何组合使用。
这次,我将用一张知识地图,帮你系统梳理20个最核心的AI概念。不讲复杂公式,只讲本质原理和实战应用。看完后,你将拥有与AI团队无障碍沟通的能力,并清楚地知道如何在实际项目中应用这些技术。希望对你有所启发。
PART 01 - 为什么工程师转型AI这么难
1.传统开发思维的三大障碍
障碍1:确定性思维 vs 概率性思维
传统软件开发是确定性的:
def add(a, b): return a + b # 永远返回精确结果
AI开发是概率性的:
response = llm.generate("写一篇文章")# 每次结果都可能不同,没有"正确答案"
这种思维转换让很多工程师不适应。你习惯了"1+1=2"的确定性,现在要接受"AI说1+1=2的概率是98%"的不确定性。
障碍2:规则驱动 vs 数据驱动
传统开发:写规则
if user.age >= 18: allow_access()
AI开发:喂数据
model.train(data) # 模型自己学习规则
一位有10年经验的后端工程师说:“我花了半年时间才适应这种感觉——不是我告诉系统怎么做,而是系统通过数据自己学会怎么做。”
障碍3:术语壁垒最致命
更关键的是,AI领域充斥着大量专业术语:
- Transformer、Attention、Embedding
- Fine-tuning、Few-shot、RAG
- Quantization、Distillation、Reasoning
这些术语不是随便起的名字,而是背后有严密的技术体系。
2.不理解这些术语,你就无法:
- 读懂AI论文和技术博客
- 参与团队技术讨论
- 做出正确的技术选型
- 理解AI系统的工作原理
3.市场需求的迫切性
看看这组数据:
| 岗位类型 | 2024年需求量 | 2025年需求量 | 增长率 | 平均年薪 |
|---|---|---|---|---|
| 传统后端工程师 | 100K | 95K | -5% | $110K |
| AI工程师 | 30K | 85K | +183% | $165K |
| AI系统架构师 | 5K | 22K | +340% | $220K |
来源: LinkedIn 2025 Tech Jobs Report
更直白的数据:
- 传统软件工程师岗位增长停滞
- AI相关岗位需求爆发式增长
- AI工程师薪资溢价50%
一家科技公司的HR透露:“现在招聘,我们更愿意给有AI经验的工程师开高30%的薪水。因为市场上这样的人太少了,而我们的产品越来越依赖AI能力。”
4.学习路径的迷失
最让人头疼的是:AI学习资料太多太杂,不知从何学起。
你可能遇到过:
- 打开一篇论文,第一段就看不懂
- 跟着教程学,需要先补习线性代数、微积分、概率论
- 看了10个视频,还是不知道实际项目该用哪个技术
一位正在转型的工程师说:“我最大的困惑是,网上的教程要么太浅(只教ChatGPT用法),要么太深(大量数学公式)。我需要的是:一个系统化的知识框架,让我知道AI技术全景是什么样的。”

PART 02 - AI技术认知框架:20个核心概念的知识地图
在深入每个概念之前,让我们先建立一个整体框架。这20个概念不是孤立的,而是构成了AI系统的完整技术栈。
AI技术栈三层模型
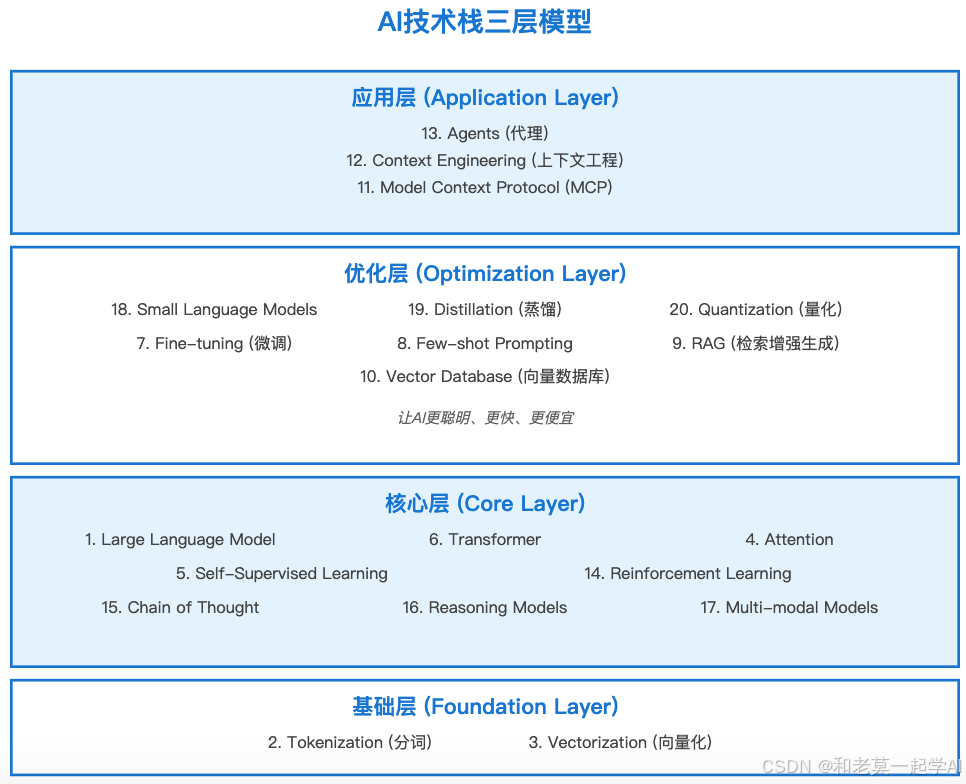
学习顺序建议:
- 入门: 从基础层开始(Tokenization, Vectorization)
- 进阶: 理解核心层(LLM, Transformer, Attention)
- 实战: 掌握优化层(RAG, Fine-tuning, Vector DB)
- 高级: 应用层(Agents, Context Engineering, MCP)
PART 03 - 基础层:文本如何变成AI能理解的数字
概念1:Tokenization(分词)- AI的"视觉系统"
本质:把文本切分成更小的单元(token)。 为什么需要?
AI模型不能直接理解文字,必须先把文字转换成数字。Tokenization是第一步。
实际例子:
输入文本: "I love AI"英文分词 (GPT):["I", " love", " AI"] # 3个tokens中文分词 (更复杂):"我爱人工智能"可能分成: ["我", "爱", "人工", "智能"] # 4个tokens也可能分成: ["我", "爱", "人工智能"] # 3个tokens
关键洞察:
- Token数量直接影响成本(API按token计费)
- Token数量影响模型性能(有context length限制)
- 不同语言的tokenization效率不同(中文通常比英文用更多tokens)
实战技巧:
# 计算token数量import tiktokentext = "这是一段测试文本"encoding = tiktoken.get_encoding("cl100k_base") # GPT-4编码tokens = encoding.encode(text)print(f"Token数量: {len(tokens)}") # 了解成本
概念2:Vectorization(向量化)- 把意义转换成数字
本质:把token转换成多维数字向量,让相似的词在向量空间中距离更近。 直观理解:
"国王" → [0.2, 0.8, 0.1, ...] (1536维)"女王" → [0.3, 0.7, 0.2, ...] (1536维)"AI" → [0.9, 0.1, 0.8, ...] (1536维)"国王"和"女王"的向量距离很近(语义相似)"国王"和"AI"的向量距离很远(语义不相关)
数学魔法:
最神奇的是向量运算:
king - man + woman ≈ queen(国王 - 男人 + 女人 ≈ 女王)
这不是魔法,而是向量空间捕捉了语义关系!
实战应用:
from openai import OpenAIclient = OpenAI()# 生成文本的向量表示response = client.embeddings.create( model="text-embedding-3-small", input="人工智能技术")vector = response.data[0].embedding # 1536维向量print(f"向量维度: {len(vector)}")
为什么重要?
- 向量化是所有AI任务的基础
- 语义搜索、推荐系统都依赖向量
- RAG系统的核心就是向量相似度匹配
PART 04 - 核心层:Transformer革命与注意力机制
概念4:Attention(注意力机制)- AI的"聚焦能力"
问题背景:
传统AI模型处理文本时,每个词的权重是一样的:
"The cat sat on the mat"旧模型: 每个词同等重要
但人类理解句子时会有重点:
"The cat sat on the mat" ↑ ↑ 主语 动作
Attention的解决方案:
让模型自己学会"注意"哪些词更重要:
查询句: "What did the cat do?"关注权重:The [0.1]cat [0.8] ← 高度关注sat [0.7] ← 高度关注on [0.2]the [0.1]mat [0.3]
Self-Attention:
更神奇的是,模型可以让句子中的每个词相互关注:
句子: "The bank is by the river bank"第一个"bank"的注意力分布:The [0.1]bank [0.3] ← 看自己is [0.1]by [0.2]the [0.1]river [0.5] ← 看"river",判断是"河岸"bank [0.4] ← 看第二个"bank"结论: 第一个"bank" = 金融机构 第二个"bank" = 河岸
实战价值:
Attention机制让AI能够:
- 理解上下文关系
- 处理长文本时不丢失信息
- 捕捉长距离依赖关系
概念6:Transformer- 现代LLM的基石架构
历史意义:
2017年Google论文《Attention Is All You Need》提出Transformer,彻底改变了AI。
为什么革命性?
| 传统RNN | Transformer |
|---|---|
| 串行处理(一个词一个词) | 并行处理(所有词同时) |
| 训练慢 | 训练快100倍 |
| 难以处理长文本 | 轻松处理长文本 |
| 无法很好捕捉长距离关系 | 通过Attention捕捉任意距离关系 |
Transformer架构简化版:
**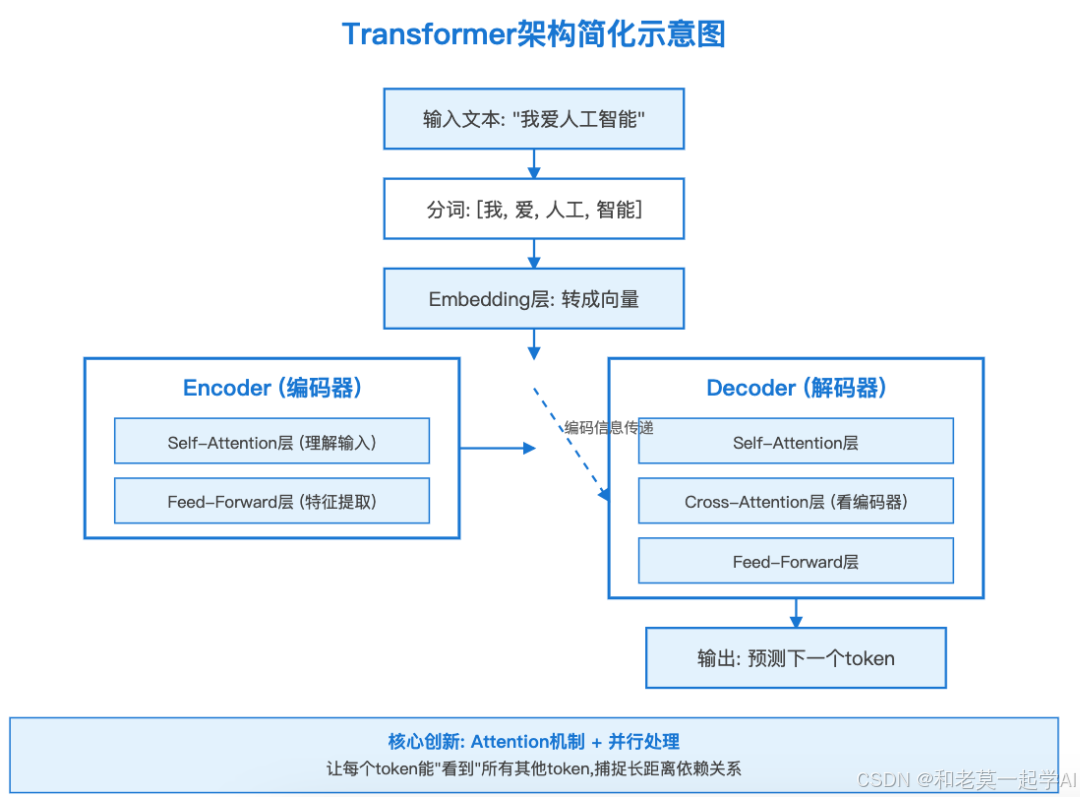
实际应用:
所有主流LLM都基于Transformer:
- GPT系列:只用Decoder部分
- BERT:只用Encoder部分
- T5:完整Encoder-Decoder
概念1:Large Language Model(大语言模型)- 把一切串起来
定义:
在海量文本数据上训练的、具有数十亿甚至数万亿参数的Transformer模型。
规模对比:
| 模型 | 参数量 | 训练数据量 | 能力 |
|---|---|---|---|
| GPT-2 (2019) | 1.5B | 40GB | 基础文本生成 |
| GPT-3 (2020) | 175B | 570GB | 复杂推理 |
| GPT-4 (2023) | ~1.76T (传言) | 未知 | 多模态、高级推理 |
| Claude 3.5 (2024) | 未知 | 未知 | 长文本、代码能力强 |
B = Billion(十亿), T = Trillion(万亿) 能力涌现(Emergence):
最神奇的是,当模型足够大时,会自动出现训练时没教过的能力:
- 算术能力
- 逻辑推理
- 代码理解
- 多语言翻译
实战考量:
选择LLM时的权衡:
| 维度 | 小模型(7B-13B) | 大模型(70B+) |
|---|---|---|
| 成本 | 低($0.001/1K tokens) | 高($0.03/1K tokens) |
| 速度 | 快(100ms) | 慢(2-5s) |
| 质量 | 中等 | 优秀 |
| 部署 | 可本地部署 | 需要云端 |
| 适用场景 | 简单任务、高频调用 | 复杂推理、高质量要求 |
PART 05 - 优化层:让AI更聪明、更快、更便宜
概念9:RAG(检索增强生成)- 给AI装上"外接硬盘"
问题:
LLM的知识有时效性和局限性:
- 知识截止日期(GPT-4的知识到2023年4月)
- 不知道你公司的私有数据
- 可能产生幻觉(编造不存在的信息)
RAG的解决方案:
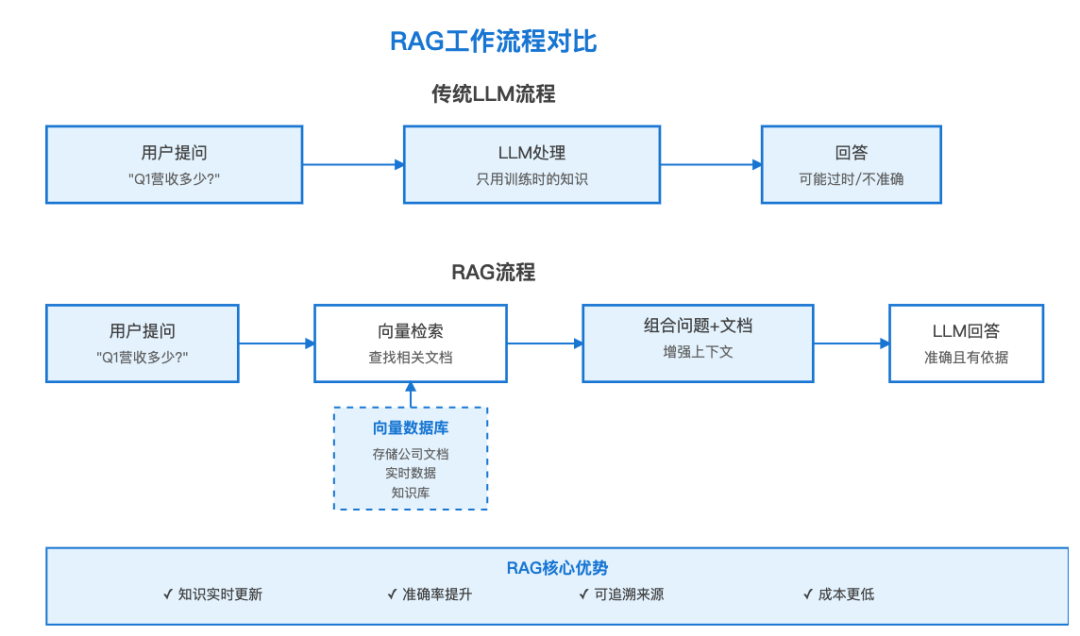
实战例子:
# 1. 准备知识库documents = [ "公司2025年Q1营收1000万", "产品A的客户满意度是92%", "最新产品功能上线时间是3月15日"]# 2. 向量化存储from openai import OpenAIclient = OpenAI()embeddings = []for doc in documents: emb = client.embeddings.create( model="text-embedding-3-small", input=doc ) embeddings.append(emb.data[0].embedding)# 3. 用户提问question = "Q1营收多少?"# 4. 检索相关文档q_embedding = client.embeddings.create( model="text-embedding-3-small", input=question).data[0].embedding# 计算相似度,找出最相关的文档# (实际项目中用向量数据库自动完成)relevant_doc = documents[0] # "公司2025年Q1营收1000万"# 5. 组合提问prompt = f"""基于以下信息回答问题:信息: {relevant_doc}问题: {question}"""# 6. LLM回答response = client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": prompt}])print(response.choices[0].message.content)# 输出: "根据提供的信息,公司2025年Q1的营收是1000万。"
RAG vs Fine-tuning:
| 维度 | RAG | Fine-tuning |
|---|---|---|
| 更新知识 | 实时更新(加新文档即可) | 需要重新训练 |
| 成本 | 低(只需存储文档) | 高(训练费用昂贵) |
| 准确性 | 高(有来源支撑) | 可能产生幻觉 |
| 适用场景 | 知识库、客服、文档问答 | 特定风格、特定领域语言 |
概念10:Vector Database(向量数据库)- RAG的核心基础设施
为什么需要?
传统数据库:精确匹配
SELECT * FROM products WHERE name = 'iPhone 15'
向量数据库:语义匹配
# 查询"苹果最新手机"# 会找到相关的: iPhone 15, iPhone 15 Pro, iPhone 15 Pro Max
工作原理:
1. 存储阶段: 文档 → 向量化 → 存入向量数据库2. 查询阶段: 问题 → 向量化 → 在数据库中找最相似的向量 → 返回对应文档
主流向量数据库对比:
| 数据库 | 特点 | 适用场景 | 价格 |
|---|---|---|---|
| Pinecone | 全托管、易用 | 中小项目 | 付费($) |
| Weaviate | 开源、功能强大 | 企业级 | 免费/付费 |
| Chroma | 轻量、易集成 | 原型开发 | 免费 |
| Milvus | 高性能、可扩展 | 大规模应用 | 免费 |
实战示例(Chroma):
import chromadb# 1. 初始化数据库client = chromadb.Client()collection = client.create_collection("company_docs")# 2. 添加文档collection.add( documents=[ "公司2025年Q1营收1000万", "产品A的客户满意度是92%" ], ids=["doc1", "doc2"])# 3. 语义搜索results = collection.query( query_texts=["今年第一季度赚了多少钱?"], n_results=1)print(results['documents'])# 输出: ["公司2025年Q1营收1000万"]
概念7:Fine-tuning(微调)- 让通用模型变成专家
什么时候用Fine-tuning?
RAG解决"知识"问题,Fine-tuning解决"风格"和"能力"问题。
使用场景:
✅ 适合Fine-tuning:
- 特定写作风格(客服语气、法律文档风格)
- 特定领域语言(医疗、法律专业术语)
- 特定任务优化(分类、信息提取)
❌ 不适合Fine-tuning:
- 更新知识(用RAG)
- 一次性任务(用Few-shot Prompting)
- 数据量太小(<1000条)
实战示例:
from openai import OpenAIclient = OpenAI()# 准备训练数据(JSONL格式)training_data = [ { "messages": [ {"role": "user", "content": "产品问题"}, {"role": "assistant", "content": "非常抱歉给您带来不便..."} ] }, # ... 更多示例(至少几百条)]# 上传训练文件file = client.files.create( file=open("training_data.jsonl", "rb"), purpose="fine-tune")# 创建Fine-tuning任务job = client.fine_tuning.jobs.create( training_file=file.id, model="gpt-4o-2024-08-06")# 等待完成后使用response = client.chat.completions.create( model=job.fine_tuned_model, # 你的专属模型 messages=[{"role": "user", "content": "产品问题"}])
成本考量:
| 项目 | GPT-4o Fine-tuning | GPT-3.5 Fine-tuning |
|---|---|---|
| 训练成本 | $25/1M tokens | $8/1M tokens |
| 使用成本 | $7.5/1M tokens (输入) | $3/1M tokens (输入) |
| 训练时间 | 几小时-几天 | 几分钟-几小时 |
| 最少数据量 | 10条(建议1000+) | 10条(建议1000+) |
概念8:Few-shot Prompting(少样本提示)- 最经济的"训练"方式
原理:
在Prompt中提供几个例子,让LLM模仿。
实战对比:
Zero-shot (无示例):"将以下文本分类为正面/负面"→ 效果一般---Few-shot (有示例):"将以下文本分类为正面/负面示例:文本: '这个产品太棒了!' → 正面文本: '质量很差,失望' → 负面文本: '一般般,凑合用' → 中性现在分类:文本: '超出预期,非常满意' → ?"→ 效果显著提升
最佳实践:
- 示例数量: 3-5个最佳(太多浪费token,太少效果差)
- 示例质量: 覆盖不同情况
- 格式一致: 保持严格统一的格式
vs Fine-tuning决策树:
需求量化: └─ 任务简单? ├─ 是 → Few-shot ✅ └─ 否 → 继续判断 └─ 有大量训练数据(1000+)? ├─ 是 → Fine-tuning └─ 否 → Few-shot + RAG
PART 06 - 优化层进阶:小模型与模型压缩
概念18-20:小模型三剑客(SLM + Distillation + Quantization)
问题背景:
大模型(GPT-4, Claude 3.5)虽然强大,但:
- 成本高($0.03/1K tokens)
- 速度慢(2-5秒响应)
- 无法本地部署
解决方案: 小语言模型(Small Language Models) 典型SLM:
| 模型 | 参数量 | 特点 | 适用场景 |
|---|---|---|---|
| Llama 3.1 8B | 8B | 开源、质量高 | 通用任务 |
| Phi-4 | 14B | 微软出品、推理强 | 数学、代码 |
| Gemini Nano | 6B | Google出品、端侧 | 手机应用 |
| Qwen 2.5 | 7B-72B | 阿里出品、多语言 | 中文任务 |
概念19:Distillation(蒸馏)- 把大模型的"知识"转移到小模型
核心思想:
教师模型(大): GPT-4 (1.76T参数) ↓ 蒸馏学生模型(小): GPT-3.5 (175B参数)结果: 学生模型获得80-90%的教师能力,但:- 速度快10倍- 成本低90%
蒸馏流程:
1. 用大模型生成大量"教学数据" 输入: "解释什么是AI" 大模型输出: "人工智能是..." (高质量答案)2. 用这些数据训练小模型 小模型学习: 输入相同 → 输出模仿大模型3. 评估效果 对比小模型和大模型在测试集上的表现
实战价值:
自己蒸馏一个小模型:
# 1. 用大模型生成训练数据questions = ["什么是AI?", "解释RAG", ...]training_data = []for q in questions: response = gpt4_client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": q}] ) training_data.append({ "question": q, "answer": response.choices[0].message.content })# 2. 用这些数据Fine-tune小模型# (使用Few-shot方式更简单)
概念20:Quantization(量化)- 用更少的位数存储模型
原理:
模型参数通常用32位浮点数(FP32)存储:
参数值: 3.141592653589793 (FP32, 32位)
量化后用更少位数:
参数值: 3.14 (INT8, 8位)
效果对比:
| 量化方式 | 模型大小 | 速度 | 质量损失 |
|---|---|---|---|
| FP32 (原始) | 100% | 1x | 0% |
| FP16 | 50% | 2x | <1% |
| INT8 | 25% | 4x | 1-2% |
| INT4 | 12.5% | 8x | 2-5% |
实战工具:
# 使用llama.cpp量化模型# Llama 3.1 8B原始大小: 16GB# 量化到4位# 结果: 4.5GB (压缩72%)# 质量损失: <3%# Mac M2也能跑!from llama_cpp import Llamamodel = Llama( model_path="llama-3.1-8B-Q4_K_M.gguf", # 量化模型 n_ctx=2048, n_gpu_layers=35 # 用GPU加速)response = model.create_chat_completion( messages=[{"role": "user", "content": "解释量化"}])
决策建议:
选择策略:- 云端API调用 → 用原生大模型- 需要本地部署 → SLM + Quantization- 成本敏感 → SLM + Distillation- 移动端应用 → 高度量化的SLM(INT4)
PART 07 - 应用层:构建生产级AI系统
概念13:Agents(代理)- 让AI自主完成任务
定义:
能够自主规划、调用工具、执行任务的AI系统。
普通LLM vs Agent:
普通LLM:用户: "帮我订明天去北京的机票"LLM: "我无法直接订票,但我可以告诉你如何订..."---Agent:用户: "帮我订明天去北京的机票"Agent思考: 1. 需要调用"航班搜索"工具 2. 找到合适航班 3. 调用"订票"工具 4. 发送确认邮件Agent执行: ✅ 完成订票
Agent核心组件:

实战框架对比:
| 框架 | 特点 | 难度 | 适用场景 |
|---|---|---|---|
| LangChain | 功能全、生态好 | ⭐⭐⭐ | 复杂Agent |
| LlamaIndex | 专注数据处理 | ⭐⭐ | 数据分析Agent |
| AutoGPT | 自主性强 | ⭐⭐⭐⭐ | 研究探索 |
| Anthropic MCP | 标准化协议 | ⭐⭐ | 企业应用 |
简单Agent示例:
from langchain.agents import initialize_agent, Toolfrom langchain.llms import OpenAIfrom langchain.tools import DuckDuckGoSearchTool# 1. 定义工具tools = [ Tool( name="搜索", func=DuckDuckGoSearchTool().run, description="用于搜索最新信息" ), Tool( name="计算器", func=lambda x: eval(x), description="用于数学计算" )]# 2. 初始化Agentagent = initialize_agent( tools=tools, llm=OpenAI(temperature=0), agent="zero-shot-react-description")# 3. 执行任务result = agent.run("OpenAI最新发布的模型是什么?它有多少参数?")# Agent思考过程:# 1. 使用"搜索"工具查询最新信息# 2. 解析搜索结果# 3. 如果找到参数数量,用"计算器"处理# 4. 组织答案返回
概念11:Model Context Protocol(MCP)- Agent的"USB标准"
问题:
每个AI工具都有自己的API格式,Agent要对接很麻烦:
Agent想用:- Slack → Slack API格式- GitHub → GitHub API格式- Gmail → Gmail API格式- ...每个都要单独开发!
MCP的解决方案:
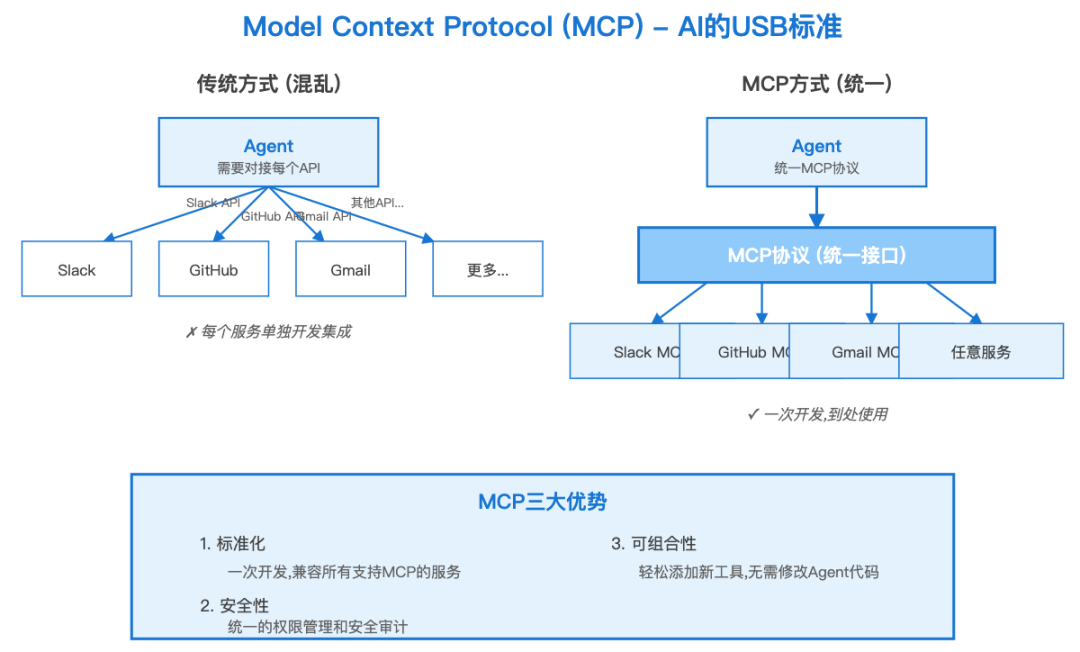
就像USB统一了硬件接口,MCP统一了AI工具接口:
实战价值:
# 传统方式: 对接每个APIslack_client = SlackClient(token)github_client = GitHubClient(token)gmail_client = GmailClient(token)# MCP方式: 统一接口from mcp import MCPClientclient = MCPClient()# 自动发现所有MCP服务tools = client.list_tools()# 统一调用client.call_tool("slack/send_message", {...})client.call_tool("github/create_issue", {...})client.call_tool("gmail/send_email", {...})
MCP的三大优势:
- 标准化: 一次开发,到处使用
- 安全性: 统一的权限管理
- 可组合: 轻松添加新工具
概念12:Context Engineering(上下文工程)- Agent的"大脑优化"
核心挑战:
2025年,模型的Context Window(上下文窗口)已经很大:
- GPT-4 Turbo: 128K tokens
- Claude 3.5: 200K tokens
- Gemini 1.5 Pro: 1M tokens
- Llama 4 (传言): 10M tokens
但问题是:Context越长,成本越高,性能越差。
Context Engineering的目标:
用最少的Context,达到最好的效果。
实战策略: 策略1: Context压缩
# 原始Context (10000 tokens):long_document = "完整的100页文档..."# 压缩后 (2000 tokens):summary = llm.summarize(long_document)key_points = llm.extract_key_info(long_document)# 只把压缩后的信息给Agentcontext = f"摘要: {summary}\n关键点: {key_points}"
策略2: 动态Context
# 不要一次性加载所有Context# 根据任务动态加载需要的部分class SmartContext: def get_relevant_context(self, query): # 1. 用向量搜索找相关片段 relevant_chunks = vector_db.search(query, top_k=5) # 2. 按相关性排序 ranked = self.rank_by_relevance(relevant_chunks, query) # 3. 只返回最相关的 return ranked[:3] # 只用前3个,节省成本
策略3: Context缓存
# OpenAI的Prompt Caching# 重复使用的Context可以缓存,降低成本system_context = """你是一个专业的客服...公司信息: ...产品知识库: ...(这部分每次都一样,可以缓存)"""# 第一次调用: 全价# 后续调用: Context部分半价(因为缓存了)
效果对比:
| 策略 | Context Size | 成本 | 响应速度 | 质量 |
|---|---|---|---|---|
| 无优化 | 50K tokens | $1.5 | 5s | 100% |
| 压缩 | 10K tokens | $0.3 | 2s | 95% |
| 动态加载 | 5K tokens | $0.15 | 1s | 93% |
| +缓存 | 5K tokens | $0.08 | 1s | 93% |
节省成本: 95%, 速度提升5倍!
PART 08 - 未来趋势:AI技术的下一个5年
趋势1:从Chat到Agent的范式转变
2024年:
- 主流: Chat界面,用户主动提问
- 例子: ChatGPT、Claude
2025-2027年:
- 主流: Agent系统,AI主动完成任务
- 例子: AI秘书、AI研究助手、AI开发者
工作流变化:
旧模式(Chat): 人类思考 → 提问 → AI回答 → 人类执行新模式(Agent): 人类委托 → AI规划 → AI执行 → 人类验收
一位CEO说:“我不再需要一个’回答问题’的AI,我需要一个’解决问题’的AI。”
趋势2:多模态成为标配
什么是多模态?
模型能理解和生成多种类型的内容:文字、图片、音频、视频。
能力演进:
| 时期 | 能力 | 代表模型 |
|---|---|---|
| 2020-2022 | 纯文本 | GPT-3 |
| 2023 | 文本 + 图片理解 | GPT-4V |
| 2024 | 文本 + 图片生成 | DALL-E 3, Midjourney |
| 2025 | 全模态(文字、图片、音视频、代码) | GPT-4o, Gemini 1.5 |
| 2026+ | 实时交互多模态 | 下一代模型 |
实战场景:
# 2025年的多模态Agent# 场景: 制作产品宣传视频agent.create_video( description="为我们的新款耳机制作30秒宣传视频", style="科技感、未来主义", music="节奏感强的电子音乐", voiceover="专业男声,充满激情")# Agent自动完成:# 1. 生成脚本# 2. 生成产品渲染图# 3. 合成视频# 4. 添加音乐和配音# 5. 输出成品
趋势3:小模型的春天
2024年困境:
大模型太贵、太慢,小模型质量不够。
2025年突破:
小模型质量显著提升:
- Llama 3.1 8B ≈ GPT-3.5
- Phi-4 14B 在推理任务上接近GPT-4
- Qwen 2.5 72B 超越某些大模型
应用分层:
━━━━━━━━━━━━━━━━━━━━━ 高级推理、创意任务 → 大模型(GPT-4, Claude 3.5)━━━━━━━━━━━━━━━━━━━━━ 通用对话、文档处理 → 中型模型(GPT-4o-mini, Llama 70B)━━━━━━━━━━━━━━━━━━━━━ 分类、提取、简单生成 → 小模型(Llama 8B, Phi-4)━━━━━━━━━━━━━━━━━━━━━ 边缘设备、实时处理 → 超小模型(Gemini Nano, 量化模型)━━━━━━━━━━━━━━━━━━━━━
成本对比:
一个日均100万次调用的应用:
| 方案 | 月成本 | 性能 |
|---|---|---|
| 全用GPT-4 | $150K | 最优 |
| 混合(80%小模型+20%大模型) | $35K | 良好 |
| 自部署小模型 | $5K | 可接受 |
节省成本: 97%!
趋势4:Reasoning Models的崛起
什么是Reasoning Model?
不是直接给答案,而是像人类一样"思考"的模型。
示例:
普通LLM:Q: "25 * 32 = ?"A: "800" (直接输出,可能错)Reasoning Model (OpenAI o1):Q: "25 * 32 = ?"思考过程: - 先算 25 * 30 = 750 - 再算 25 * 2 = 50 - 相加: 750 + 50 = 800A: "800" (经过推理,更可靠)
核心技术: Chain of Thought(思维链)
强迫模型"说出"思考过程:
prompt = """一步步思考并解决这个问题:问题: 如果一个产品原价100元,先打8折再满200减30,买2个总共多少钱?请先写出计算步骤,再给出最终答案。"""# 模型输出:"""步骤1: 每个产品打8折后 = 100 * 0.8 = 80元步骤2: 买2个 = 80 * 2 = 160元步骤3: 160元 < 200元,不满足满减条件最终答案: 160元"""
应用价值:
| 任务类型 | 普通LLM准确率 | Reasoning Model准确率 |
|---|---|---|
| 数学题 | 45% | 92% |
| 逻辑推理 | 60% | 89% |
| 代码debug | 55% | 85% |
| 复杂规划 | 40% | 78% |
趋势5:Context Window的极限挑战
历史演进:
| 年份 | 最大Context | 代表模型 |
|---|---|---|
| 2020 | 2K tokens | GPT-3 |
| 2022 | 8K tokens | GPT-3.5 |
| 2023 | 128K tokens | GPT-4 Turbo |
| 2024 | 1M tokens | Gemini 1.5 Pro |
| 2025 | 10M tokens | Llama 4 (传言) |
10M tokens = 多少内容?
- 约7500页书
- 约20部长篇小说
- 整个代码库
- 几年的聊天记录
但挑战也来了:
计算成本: O(n²)(Context长度翻倍,计算量翻4倍!)128K → 1M tokens计算量增加: 64倍成本增加: 64倍
解决方案:
-
更高效的Attention机制
(闪电注意力 Flash Attention)
-
Context压缩技术
(只保留重要信息)
-
层次化Context
(分层存储,按需加载)
结论:从概念到实战的跃迁
现在,你已经掌握了20个核心AI概念。但更重要的是,你理解了它们如何组合成完整的AI系统。
三个关键认知:
认知1:AI技术不是独立的,而是层层嵌套的系统
你以为: 学会Transformer → 学会LLM → 学会Agent实际上: Tokenization + Vectorization → Attention Mechanism → Transformer → LLM → Fine-tuning / RAG → Context Engineering → Agent系统
每一层都建立在前一层基础上。理解这个体系,比记住每个名词更重要。
认知2:AI工程师的核心能力是"技术选型"
不是所有问题都需要GPT-4:
| 场景 | 最佳方案 | 原因 |
|---|---|---|
| 客服FAQ | Few-shot Prompting + 小模型 | 成本低、速度快 |
| 企业知识库 | RAG + Vector DB | 知识可更新 |
| 特定风格写作 | Fine-tuning | 风格一致性 |
| 复杂任务 | Agent + 大模型 | 需要规划能力 |
| 边缘设备 | 量化小模型 | 离线运行 |
好的AI工程师知道"什么时候用什么技术"。
认知3:持续学习是唯一出路
AI领域变化太快:
- 2023年初:还没有ChatGPT
- 2023年底:GPT-4、Claude 2出现
- 2024年:多模态、Reasoning Model爆发
- 2025年:Agent、MCP成为主流
你今天学到的知识,6个月后可能过时。但底层思维方式不会变:
- 理解问题本质
- 选择合适工具
- 快速实验迭代
最后一句话:
AI技术的学习曲线很陡,但一旦突破临界点,你会发现:这是过去10年最大的技术红利窗口。
传统软件工程师的天花板是明确的,但AI工程师的上限还看不到。早一天掌握这些概念,就早一天站在风口。
选择权在你手上。是现在开始深入学习,还是继续观望?
术语速查表
| 概念 | 一句话解释 | 使用频率 | 学习优先级 |
|---|---|---|---|
| Tokenization | 把文字切成AI能理解的小块 | ⭐⭐⭐⭐⭐ | P0 |
| Vectorization | 把token变成数字向量 | ⭐⭐⭐⭐⭐ | P0 |
| Attention | 让AI知道哪些词更重要 | ⭐⭐⭐⭐ | P1 |
| Transformer | 现代LLM的基础架构 | ⭐⭐⭐⭐⭐ | P0 |
| LLM | 在海量数据上训练的大模型 | ⭐⭐⭐⭐⭐ | P0 |
| RAG | 给AI外接知识库 | ⭐⭐⭐⭐⭐ | P0 |
| Vector DB | 存储和检索向量的数据库 | ⭐⭐⭐⭐ | P1 |
| Fine-tuning | 让通用模型学会特定能力 | ⭐⭐⭐ | P2 |
| Few-shot | 在Prompt里给示例 | ⭐⭐⭐⭐ | P1 |
| Agent | 能自主完成任务的AI系统 | ⭐⭐⭐⭐⭐ | P0 |
| MCP | Agent工具的统一协议 | ⭐⭐⭐ | P2 |
| Context Engineering | 优化Context使用效率 | ⭐⭐⭐⭐ | P1 |
| SLM | 更小、更快的语言模型 | ⭐⭐⭐⭐ | P1 |
| Distillation | 把大模型知识转移到小模型 | ⭐⭐ | P3 |
| Quantization | 压缩模型降低资源需求 | ⭐⭐⭐ | P2 |
| Chain of Thought | 让AI展示思考过程 | ⭐⭐⭐⭐ | P1 |
| Reasoning Model | 会"思考"的AI模型 | ⭐⭐⭐ | P2 |
| Multi-modal | 理解多种类型内容 | ⭐⭐⭐⭐ | P1 |
| Self-Supervised | AI自己学习的训练方式 | ⭐⭐ | P3 |
| Reinforcement Learning | 通过奖惩让AI学习 | ⭐⭐ | P3 |
P0: 必须掌握 | P1: 应该掌握 | P2: 了解即可 | P3: 进阶概念
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献302条内容
已为社区贡献302条内容

所有评论(0)